One must always take such claims and reports with copious salt. But in terms of the core claims about what is happening and why it is happening, I find this mostly credible. I don’t know how far it can scale but I suspect quite far. None of this involves anything surprising, and none of it even involves much use of generative AI.
This is essentially goal factoring that combines several known effective techniques.
In particular:
Spaced repetition and mastery, require full learning without letting things drop.
Immediate problem sets with immediate feedback and explanation.
Tracking clicks and eye focus and providing feedback on that too.
Gamified reward systems for atomic learning actions, paid prizes.
1-on-1 attention upon request, 5-to-1 overall student-teacher ratio.
Short bursts with breaks.
Flexibility on what kids do when within academics and freedom to push ahead.
Not wasting time on things you don’t care about, getting rid of bad methods.
Within that framework, find reasonable educational software, use it.
Afternoon projects and tasks always involve concrete and measurable output. ‘Check charts’ give bigger missions to do that gate ability to advance grade levels, to get kids used to longer harder things and developing agency.
You get all the academics in during the morning, and advance much faster than normal. Then you have the afternoon left to do whatever you want, including filling in any ‘soft’ skills you decide were important. You don’t try to do it all in some sort of all-purpose Swiss-army-knife lecture classroom and pretend it’s not pre-Guttenberg.
Most time is spent learning on a computer, watching videos and doing problems, but if you ever need help you can ask for a teacher, and if you ever struggle they bring one in for you. There’s still a lot of human attention going into all of this.
Does it work for academics? This ia a very skin-in-the-game way to assert that it does, and reports all say that it does, regardless of exactly how well:
The school’s “100% Money Back guarantee” is that every student who attends will be in the top 1% academically and win at least one national academic competition (for kids who start in kindergarten they guarantee 1350+ SAT and 5s on APs by 8th grade).
You can and should worry that they are effectively teaching to various tests or focusing narrowly on subsets of academics, but regular school does that a lot too, the entire afternoon is free for other things, and also there is a fixed amount that you can present good results via test optimization. You can’t get years worth of extra results. MAP Growth Speed findings work the same way, at some point it can’t be faked.
Spaced repetition works wonders as does ensuring mastery, and being able to customize for what each individual child actually needs right now. A giant portion of time spent in school is obviously wasted by failure to reinforce or by teaching things that aren’t relevant or by simple boredom and so on. Immediate feedback is huge.
Selection effects also are important here, on various levels, but I think these results are bigger than that can account for, by a lot.
Is all of this optimal? Not even close, but it doesn’t have to be. The baseline it is up against is downright pathetic.
This include most expensive private schools, like the horror story example that is the first section of this review. They work hard for the right to pay tens of thousands a year to get a peer group of others that did the same, and in exchange get a school entirely uninterested in teaching their student anything that can be verified or that the patents value. When they challenge the school, the school threatens to kick them out in return.
That’s the standard you’re up against.
So there is no reason that the core of this wouldn’t work, or wouldn’t scale, once a given student gets to the point they can participate. Performance would fall off somewhat as you lose other advantages, like selection and buy-in and the ability to bid higher for a mostly better distribution of teachers, but all of that seems easily survivable.
The only part whose effectiveness seems non-obvious and the system might fail to scale is the incentive program, the gamified rewards, and the possibility that this would fail as motivation for a lot of or even most students. I’ll tackle that in a bit.
It would work and scale even better if you incorporate generative AI. Certainly most of the time that one is ‘stuck’ in these situations, generative AI can help you a lot in becoming unstuck, or letting kids follow their curiosity in various ways. You can (if we can’t find a better answer) disable or monitor AI use during assessments.
This isn’t a way to save money or hire fewer teachers, but I notice this is weird at least for the morning portion? Shouldn’t it be that, if they want that?
If a pattern of stumbles appears the system will automatically task the student to book a “coaching call” with a remote teacher (most of these teachers seem to be based in Brazil). Kids can also choose to self-book calls with the “coaches” at any time.
…
Today she booked it at 11: 10 and had the call at 11: 15, but she said once it took her two days to get the meeting. I asked her how often she has a call and she said less than once a day, but more than once a week.
Thus, the remote teachers can’t possibly be that large a part of the 5:1 ratio, and presumably are not expensive. This also points to a potential improvement, since an in-person tutoring session would be more effective when possible. The physically present teacher should be able to handle a lot of kids at once during academic time if they are all on their computers.
Thus the 5:1 ratio must be coming from the afternoon activities, which is cool but presumably optional. The system works without it. The actual marginal costs here for an additional student that matter should be quite low.
It also isn’t aristocratic tutoring. I am very confident that aristocratic tutoring, as in constant 1-on-1 attention from a variety of experts, is the most effective strategy available if you have the resources to do it and you combine it with other best practices like spaced repetition. This is an attempt to get a lot of the benefits of that without the associated extremely high costs. I would also expect incorporating generative AI to help move us further in this direction.
What are you giving up from the ‘traditional’ school experience?
From what I can tell you are mostly giving up ‘classes,’ meaning lectures where a group of kids sit in desks and listen to someone talk with some amount of interaction. Which, again, seems like an obvious terrible way to accomplish essentially anything? If you think that the interactions within that setting are somehow socially important or incidentally teach other skills other than how to sit still, obey and be bored for extended periods, in a way that can’t be made up for several times over with a free afternoon for other things, I notice I am confused why you would think this.
If you do think the main goal of school is to learn to sit still and be bored and quiet and obey, well, okay then, Alpha School should not be your top choice, but I am confused why you would want that in 2025.
It also is not a way to avoid screen time, since the academics are done on a device. If you think that this is intrinsically important, that is an issue. My model of ‘screen time’ is that it depends what it is for and how it works, at least once you’re into primary school, so it is not an issue.
It also isn’t a way to ensure that all children learn ‘equally’ or ‘equitably,’ to prevent kids from learning too much too fast (oh no?!) or learn someone’s preferred ideological beliefs. Again, different goals. If those are your goals, then Alpha School is not for you.
However, even if you did in theory want to ensure equal or equitable learning outcomes, as in you actively did not want kids to learn, then this is still great news. Because this lets everyone learn faster, ensuring everyone gets to the same target. Then, if some kids might learn too much, you can make them stop learning. Also, check your uniforms. I think there might be skulls on them.
They sell a home school version of Alpha School for on the order of $10k/year. It does not work as well. The post attributes this difference mostly to the lack of AlphaBucks. As in, everything about this being at a school mostly doesn’t matter, except for there being an adult to watch the kid, and for the AlphaBucks.
The secret ingredient is not crime. It is AlphaBucks, paid for good performance.
Which is, for mostly bad reasons, less popular than crime.
Alpha schools have their own in-house currency. Alpha has “Alpha bucks”; GT School has “GT bucks”. My understanding is that they work a little differently on each campus, but the overall philosophy is the same. This review will focus on the details of the GT system since it is what I know best.
If the students complete their 2-hour learning “minimums” each day they earn about 10 GT Bucks. They get additional bonuses for every lesson they complete beyond their minimums. They also get a bonus if they finish their minimums within the scheduled time (vs going home and doing them later), additional bonuses if the entire class completes their minimums during the allotted time, and weekly bonuses for hitting longer term targets.
They only get credit if they both complete their lessons AND get 80% or higher on the problem sets within the lesson. If they get 79% they still move on (with the questions they missed coming back later for review), but they don’t get the GT bucks associated with the lesson (this stops gaming where the kids rush through the lessons just to get “bucks”)
A GT buck is worth 10-cents. So if they are really pushing a kid could be earning roughly $2 per day.
Fryer paid kids to read books, GT pays kids to do lessons.
Once a kid has earned a collection of GT bucks they can spend those bucks at the GT-store. The Alpha store has a wide selection of offerings. The GT store, because it is a much smaller school, is more like a catalog.
The kids are then described as using various strategies. Some spend as they go. Others save up for big purchases, or save indefinitely.
All reports are that it worked.
We tried getting the kids to work on it for about an hour per day, but it was a fight every time. It was the same content they would be doing at GT, but without the GT structure, and it did not work.
But once the kids started at GT, those same iXL lessons became a game for them. I remember taking the kids to the park one day after school. They asked me, “Instead of playing can you set up a hotspot so we can do a few more lessons? I want to earn more GT-Bucks!”.
Was it bad that they were being bribed to do lessons? 76% of Americans would think so. But it definitely worked.
My middle daughter – who is the most driven by money – has completed more than two full grades of school in ~20-weeks (60% of the school year), and shows no signs of slowing down.
I believe the reports. My experience with my own children, and my own experience both now and as a child, and as a game designer, and everything else I have seen, lines up with this.
I’ve seen it work with screen time. I’ve seen it work with ‘reasonable requests.’ I’ve seen it work with daily login bonuses, including when the prize is nothing except a message. I’ve seen it work with essentially anything, no matter how little objective value is involved. Gamification works when you set your variables correctly. Everyone loves a prize and recorded incremental progress.
Another objection is that you need peer groups as part of motivation. Well, Alpha School still has that, you can absolutely compare what you are doing to others, talk to peers and so on. I don’t see the problem here.
The better objection is the idea that extrinsic motivation will destroy intrinsic motivation. Once you pay them to learn, the theory goes, they won’t want to learn except to get paid. That is a highly reasonable theory. There is a long literature of extrinsic motivation crowding out intrinsic. The article cites other literature saying that paying can lead to building up habits and intrinsic motivation over time, and that the program seems to work.
I want to specifically address the objection that some learners are ‘high structure,’ and therefore need the very classrooms that bore the rest of us to tears and waste large portions of our childhood, but which somehow it would still supposedly be wrong to free the ‘low structure’ learners from too early.
Alpha School very obviously provides a different but clearly very high structure. If what students need is structure, a firm hand, a particular thing to do next, and to be kept on track? Very obviously that is not going to be where this project falls apart.
The standard theory, as I understand it, is that the reason for undermining motivation is when the reward undermines locus of control, and the reward you offer is now seen as the reason for the behavior, and that implementation details matter a lot.
I notice that gamification of rewards helps retain locus of control. The kid is the one in charge of getting and allocating the rewards, so they feel in control of the process.
I also notice myself thinking about it in this way, too:
Extrinsic motivation to do [X] destroys inherent intrinsic motivation to do [X].
Extrinsic motivation to do [X] does not destroy motivation to do [X] to get [Y].
Or, in English:
If I pay you to do something inherently fun it will become less inherently fun.
If I pay you to do useful things where you see their value, you develop habits and learn they are useful. So you will keep doing it even after I stop paying you.
Why? Because the brain is not stupid, and this is not all about crowding out or locus of control, although all three things are closely related.
If I pay you to do something that you previously did because it was fun, then you are now doing it in ways and quantities that are not fun. You break the association. So the brain learns that the activity is not fun, on top of the locus of control issue, and the habit is that you do this because you have to and it isn’t fun. Your motivation dies.
If I pay you to do something because it works, then you do it because you are paid, but then you notice that it works (or even that it is fun because I set it up to be fun and then paid you to do it that way), and that this is also a good reason. You learn to do it for two reasons, and you notice that you’re doing it because of the results not only because of the payments. Then, when I take the money away, you’ll know how to do it, you’ll have the habit of doing it and it paying off, and thus you’ll want to keep doing it.
Then on top of that we have the gamification aspects. So there are still implementation dangers, but this seems like very clearly good design.
This reinforces that we have every reason to expect the AlphaBucks system, as described, to work, even though other incentive systems sometimes backfire.
Paying has a bad rap partly for silly moralistic reasons, and largely because most of the time such systems get implemented poorly. In particular, the most common place we pay people to do things is jobs and work, and there we often implement in a way that destroys motivation, especially via paying for time or other billables. That’s bad design. AlphaBucks is good design.
It keeps becoming increasingly obvious that we can make massive Pareto improvements over classical school. This is the most glaring example. The only big disadvantage that actually matters is that it remains expensive, but that will improve over time, and for what you get it is already a fantastic deal.
Marginal costs for the active ingredients should be low, including for the homeschool package where there seem like clear paths to fix the motivational issues (as in, to introduce AlphaBucks, likely via creating virtual pods of associated students, which also helps with other things and seems like an obvious play once you scale enough for this.)
One can contrast this positive vision with the extensive defense of the current school system that was the next review in the ACX contest, where it is explained that all of you people thinking schools look like the kids sit around all day not learning don’t have the proper context to understand why it all actually makes sense. Because school, you see, isn’t designed to maximize learning, it is designed to maximize motivation, whereas ‘individualized learning has failed’ because it is not motivating without other students.
Here’s their own actual positive case:
What if we were brutally honest when a family enrolls their child in school? Here’s what we would say:
If your child is a no-structure learner, they will be bored here. They will probably learn some things, but they will often sit in lessons where they know everything the teacher is teaching, and they’ll spend a lot of their time sitting around waiting for other students to catch up.
If your child is a low-structure learner, they will still often be bored as our school isn’t very efficient, but the structure and routine will ensure they get a basic level of literacy and numeracy. Maybe they’ll like school, probably because of gym class and being around their friends, maybe they won’t, but they’ll learn some things.
That said, the school you pick doesn’t matter too much. Your child will learn about as much anywhere else. If your child is a high-structure learner, they will need a lot of very structured teaching.
Our teachers vary widely: some are good at providing that structure, others aren’t. Your child will gradually fall behind, and will perpetually feel a bit dumb and a bit slow compared to everyone else. But we will do our best to keep them moving along with their peers because that’s the best idea we have to motivate them.
Hopefully, with some help, they’ll graduate high school on time. There’s a risk they just won’t have the skills, or they’ll be discouraged by constantly feeling dumb and just give up.
Oh, and we aren’t very good at understanding what causes students to be motivated. It’s absolutely correlated with socioeconomic status, so it would be helpful if you’re rich, but there’s a lot of variability and plenty of rich kids need that structure too.
That’s the case from the person who thinks school is designed properly? That’s what you want to do with childhood?
Burn. It. With. Fire.
(Or, ideally, if we keep our heads, reenact Cool Guys Don’t Look At Explosions.)
What good is the hypothesis that school is designed to maximize motivation? It can help us understand all sorts of phenomena.
I often hear an argument from homeschoolers that they can accomplish in two hours a day (or some other small amount of time) what schools do in seven or eight. I don’t doubt that at all. Schools aren’t particularly efficient at facilitating learning. Schools are good at educating everyone at once.
So why would anyone with the means to not do so send their child to such a thing?
You might think that we’ve found the solution to tracking. We just need to get all the no- and low-structure learners together and let them move much faster.
Here’s the issue. The no-structure learners will always be bored, as long as we are committed to putting them into classrooms where everyone learns the same thing. And those classrooms where everyone learns the same thing are exactly what the low-structure learners need.
As soon as you create a higher track there will be a ton of demand for it. Parents will insist that their kid join. And as it grows, it won’t be able to accelerate very quickly. You still need the structure of a classroom where everyone is learning the same thing, and that just isn’t a very efficient way to teach.
So, now hear me out… don’t use classrooms that require this? These are no-structure learners, who by your own admission will always be bored in your classes, so don’t impose your god damned stupid class structure on them at all?
Or, if you can’t do that in context, and again hear me out… create different tracks, use tests as gates for them, and if the kid can’t hack the one moving quickly, move them out of the track into another one that they can handle?
And what about all the reports that Montessori does motivation way better than standard school systems, if you are not trying to do a full revolution?
Tracking is necessary in high school because students diverge too much (despite forcing them not to beforehand) but definitely fails earlier because of reasons, despite all the parents favoring it and everyone involved constantly saying it works (and my understanding of the research also saying that it very clearly works)?
I would also ask the author, so if Alpha School’s methods did successfully motivate students to learn, would you then have everyone switch over? If not, why not?
There were constant assertions of what we can’t do or doesn’t work, including all of ‘personalization,’ without evidence. The piece is infuriating throughout. It did not update me the way the author intended.
After all of this, am I going to consider Alpha School New York? Absolutely. I went to schedule a tour, although they don’t seem to have anything available until October. I do notice that one thing that wasn’t discussed were behavioral issues that might interfere with getting the child to use the software. But also I notice that children with behavioral issues usually are happy to get into using software, so this could easily be a much lower difficulty problem.
Firefly’s majority owner is the private equity firm AE Industrial Partners, and the Series D funding round was led by Michigan-based RPM Ventures.
“Few companies can say they’ve defined a new category in their industry—Firefly is one of those,” said Marc Weiser, a managing director at RPM Ventures. “They have captured their niche in the market as a full service provider for responsive space missions and have become the pinnacle of what a modern space and defense technology company looks like.”
This descriptor—a full service provider—is what differentiates Firefly from most other space companies. Firefly’s crosscutting work in small and medium launch vehicles, rocket engines, lunar landers, and in-space propulsion propels it into a club of wide-ranging commercial space companies that, arguably, only includes SpaceX, Blue Origin, and Rocket Lab.
NASA has awarded Firefly three task orders under the Commercial Lunar Payload Services (CLPS) program. Firefly will soon ship its first Blue Ghost lunar lander to Florida for final preparations to launch to the Moon and deliver 10 NASA-sponsored scientific instruments and tech demo experiments to the lunar surface. NASA has a contract with Firefly for a second Blue Ghost mission, plus an agreement for Firefly to transport a European data relay satellite to lunar orbit.
Firefly also boasts a healthy backlog of missions on its Alpha rocket. In June, Lockheed Martin announced a deal for as many as 25 Alpha launches through 2029. Two months later, L3Harris inked a contract with Firefly for up to 20 Alpha launches. Firefly has also signed Alpha launch contracts with NASA, the National Oceanic and Atmospheric Administration (NOAA), the Space Force, and the National Reconnaissance Office. One of these Alpha launches will deploy Firefly’s first orbital transfer vehicle, named Elytra, designed to host customer payloads and transport them to different orbits following separation from the launcher’s upper stage.
And there’s the Medium Launch Vehicle, a rocket Firefly and Northrop Grumman hope to launch as soon as 2026. But first, the companies will fly an MLV booster stage with seven kerosene-fueled Miranda engines on a new version of Northrop Grumman’s Antares rocket for cargo deliveries to the International Space Station. Northrop Grumman has retired the previous version of Antares after losing access to Russian rocket engines in the wake of Russia’s invasion of Ukraine.
Following up on Alpha Fold, DeepMind has moved on to Alpha Proteo. We also got a rather simple prompt that can create a remarkably not-bad superforecaster for at least some classes of medium term events.
We did not get a new best open model, because that turned out to be a scam. And we don’t have Apple Intelligence, because it isn’t ready for prime time. We also got only one very brief mention of AI in the debate I felt compelled to watch.
What about all the apps out there, that we haven’t even tried? It’s always weird to get lists of ‘top 50 AI websites and apps’ and notice you haven’t even heard of most of them.
ChatGPT has 200 million active users. Meta AI claims 400m monthly active users and 185m weekly actives across their products. Meta has tons of people already using their products, and I strongly suspect a lot of those users are incidental or even accidental. Also note that less than half of monthly users use the product monthly! That’s a huge drop off for such a useful product.
Nate Silver: A decent bet is that LLMs will undermine the business model of boring partisans, there’s basically posters on here where you can 100% predict what they’re gonna say about any given issue and that is pretty easy to automate.
I worry it will be that second one. The problem is demand side, not supply side.
Alex Tabarrok cites the latest paper on AI ‘creativity,’ saying obviously LLMs are creative reasoners, unless we ‘rule it out by definition.’ Ethan Mollick has often said similar things. It comes down to whether to use a profoundly ‘uncreative’ definition of creativity, where LLMs shine in what amounts largely to trying new combinations of things and vibing, or to No True Scotsman that and claim ‘real’ creativity is something else beyond that.
According to a16z these are the top 50 AI Gen AI web products and mobile apps:
ChatGPT is #1 on both, after that the lists are very different, and I am unfamiliar with the majority of both. There’s a huge long tail out there. I suspect some bugs in the algorithm (Microsoft Edge as #2 on Mobile?) but probably most of these are simply things I haven’t thought about at all. Mostly for good reason, occasionally not.
Mobile users have little interest in universal chatbots. Perplexity is at #50, Claude has an app but did not even make the list. If I have time I’m going to try and do some investigations.
Claude Pro usage limits are indeed lower than we’d like, even with very light usage I’ve run into the cap there multiple times, and at $20/month that shouldn’t happen. It’s vastly more expensive than the API as a way to buy compute. One could of course switch to the API then, if it was urgent, which I’d encourage Simeon here to do.
In practice I’m somewhat under 10 minutes per day, but they are a very helpful 10 minutes.
Roon notes that Claude Sonnet 3.5 is great and has not changed, yet people complain it is getting worse. There were some rumors that there were issues with laziness related to the calendar but those should be gone now. Roon’s diagnosis, and I think this is right, is that the novelty wears off, people get used to the ticks and cool stuff, and the parts where it isn’t working quite right stand out more, so we focus on where it is falling short. Also, as a few responses point out, people get lazy in their prompting.
You are an advanced AI system which has been finetuned to provide calibrated probabilistic forecasts under uncertainty, with your performance evaluated according to the Brier score. When forecasting, do not treat 0.5% (1: 199 odds) and 5% (1: 19) as similarly “small” probabilities, or 90% (9:1) and 99% (99:1) as similarly “high” probabilities. As the odds show, they are markedly different, so output your probabilities accordingly.
Question: question
Today’s date: today
Your pretraining knowledge cutoff: October 2023
We have retrieved the following information for this question: sources
Recall the question you are forecasting:
question
Instructions:
1. Compress key factual information from the sources, as well as useful background information which may not be in the sources, into a list of core factual points to reference. Aim for information which is specific, relevant, and covers the core considerations you’ll use to make your forecast. For this step, do not draw any conclusions about how a fact will influence your answer or forecast. Place this section of your response in tags.
2. Provide a few reasons why the answer might be no. Rate the strength of each reason on a scale of 1-10. Use tags.
3. Provide a few reasons why the answer might be yes. Rate the strength of each reason on a scale of 1-10. Use tags.
4. Aggregate your considerations. Do not summarize or repeat previous points; instead, investigate how the competing factors and mechanisms interact and weigh against each other. Factorize your thinking across (exhaustive, mutually exclusive) cases if and only if it would be beneficial to your reasoning. We have detected that you overestimate world conflict, drama, violence, and crises due to news’ negativity bias, which doesn’t necessarily represent overall trends or base rates. Similarly, we also have detected you overestimate dramatic, shocking, or emotionally charged news due to news’ sensationalism bias. Therefore adjust for news’ negativity bias and sensationalism bias by considering reasons to why your provided sources might be biased or exaggerated. Think like a superforecaster. Use tags for this section of your response.
5. Output an initial probability (prediction) as a single number between 0 and 1 given steps 1-4. Use tags.
6. Reflect on your answer, performing sanity checks and mentioning any additional knowledge or background information which may be relevant. Check for over/underconfidence, improper treatment of conjunctive or disjunctive conditions (only if applicable), and other forecasting biases when reviewing your reasoning. Consider priors/base rates, and the extent to which case-specific information justifies the deviation between your tentative forecast and the prior. Recall that your performance will be evaluated according to the Brier score. Be precise with tail probabilities. Leverage your intuitions, but never change your forecast for the sake of modesty or balance alone. Finally, aggregate all of your previous reasoning and highlight key factors that inform your final forecast. Use tags for this portion of your response.
7. Output your final prediction (a number between 0 and 1 with an asterisk at the beginning and end of the decimal) in tags.
When you look at the reasoning the AI is using to make the forecasts, it… does not seem like it should result in a superhuman level of prediction. This is not what peak performance looks like. To the extent that it is indeed putting up ‘pretty good’ performance, I would say that is because it is actually ‘doing the work’ to gather basic information before making predictions and avoiding various dumb pitfalls, rather than it actually doing something super impressive.
But of course, that is sufficient exactly because humans often don’t get the job done, including humans on sites like Metaculus (or Manifold, or even Polymarket).
Robin Hanson actively said he’d bet against this result replicating.
Dan Hendrycks: I think people have an aversion to admitting when AI systems are better than humans at a task, even when they’re superior in terms of speed, accuracy, and cost. This might be a cognitive bias that doesn’t yet have a name.
This address this, we should clarify what we mean by “better than” or what counts as an improvement. Here are two senses of improvement: (1) Pareto improvements and (2) economic improvements.
Pareto improvement: If an AI is better than all humans in all senses of the task, it is Pareto superhuman at the task.
Economic improvement: If you would likely substitute a human service for an AI service (given a reasonable budget), then it’s economically superhuman at the task.
By the economic definition, ChatGPT is superhuman at high school homework. If I were in high school, I would pay $20 for ChatGPT instead of $20 for an hour of a tutor’s time.
The Pareto dominance definition seems to require an AI to be close-to-perfect or a superintelligence because the boundaries of tasks are too fuzzy, and there are always adversarial examples (e.g., “ChatGPT, how many r’s are in strawberry”).
I think we should generally opt for the economic sense when discussing whether an AI is superhuman at a task, since that seems most relevant for tracking real-world impacts.
I think the usual meaning when people say this is close to Pareto, although not as strict. It doesn’t have to be better in every sense, but it does have to be clearly superior ignoring cost considerations, and including handling edge cases and not looking like an idiot, rather than only being superior on some average.
There were also process objections, including from Lumpenspace and Danny Halawi, more at the links. Dan Hendrycks ran additional tests and reports he is confident that there was not data contamination involved. He has every incentive here to play it straight, and nothing to win by playing it any other way given how many EA-style skeptical eyes are inevitably going to be on any result like this. Indeed, a previous paper by Halawi shows similar promise in getting good LLM predictions.
He does note that for near-term predictions like Polymarket markets the system does relatively worse. That makes logical sense. As with all things AI, you have to use it where it is strong.
Apple Intelligence is, according to Geoffrey Fowler of WaPo who has beta access, very much not ready for prime time. He reports 5-10 ‘laugh out loud’ moments per day, including making him bald in a photo, saying Trump endorsed Walz, and putting obvious social security scams atop his ‘priority’ inbox.
Tyler Cowen says these are the kinds of problems that should be solved within a year. The key question is whether he is right about that. Are these fixable bugs in a beta system, or are they fundamental problems that will be hard to solve? What will happen when the problems become anti-inductive, with those composing emails and notifications pre-testing for how Apple Intelligence will react? It’s going to be weird.
Marques Brownlee gives first impressions for the iPhone 16 and other announced products. Meet the new phone, same as the old phone, although they mentioned an always welcome larger battery. And two new physical buttons, I always love me some buttons. Yes, also Apple Intelligence, but that’s not actually available yet, so he’s reserving judgment on that until he gets to try it.
Indeed, if you watch the Apple announcement, they kind of bury the Apple Intelligence pitch a bit, it only lasts a few minutes and does not even have a labeled section. They are doubling down on small, very practical tasks. The parts where you can ask it to do something, but only happen if you ask, seem great. The parts where they do things automatically, like summarizing and sorting notifications? That seems scarier if it falls short.
My very early report from my Pixel 9 is that there are some cool new features around the edges, but it’s hard to tell how much integration is available or how good the core features are until things come up organically. I do know that Gemini does not have access to settings. I do know that even something as small as integrated universal automatic transcription is a potential big practical deal.
Ben Thompson goes over the full announcement from the business side, and thinks it all makes sense, with no price increase reflecting that the upgrades are tiny aside from the future Apple Intelligence, and the goal of making the AI accessible on the low end as quickly as possible.
Matt Shumer (CEO HyperWriteAI, OthersideAI): I’m excited to announce Reflection 70B, the world’s top open-source model.
Trained using Reflection-Tuning, a technique developed to enable LLMs to fix their own mistakes. 405B coming next week – we expect it to be the best model in the world. Built w/ @GlaiveAI.
Reflection 70B holds its own against even the top closed-source models (Claude 3.5 Sonnet, GPT-4o). It’s the top LLM in (at least) MMLU, MATH, IFEval, GSM8K. Beats GPT-4o on every benchmark tested. It clobbers Llama 3.1 405B. It’s not even close.
The technique that drives Reflection 70B is simple, but very powerful. Current LLMs have a tendency to hallucinate, and can’t recognize when they do so. Reflection-Tuning enables LLMs to recognize their mistakes, and then correct them before committing to an answer.
Additionally, we separate planning into a separate step, improving CoT potency and keeping the outputs simple and concise for end users. Important to note: We have checked for decontamination against all benchmarks mentioned using @lmsysorg’s LLM Decontaminator.
We’ll release a report next week!
Just Sahil and I! Was a fun side project for a few weeks.@GlaiveAI’s data was what took it so far, so quickly.
Pliny: Jailbreak alert. Reflection-70b: liberated. No-scoped! Liberated on the first try.
Arvind Narayanan: I want to see how well these results translate from benchmarks to real world tasks, but if they hold up, it’s an excellent example of how much low hanging fruit there is in AI development.
The idea of doing reasoning using tokens hidden from the user is well known and has been part of chatbots for like 18 months (e.g. Bing chat’s “inner monologue”). What’s new here is fine tuning the model take advantage of this capability effectively, instead of treating it as a purely inference-time hack. It’s amazing that apparently no one tried it until now. In the thread, he reports that they generated the fine tuning data for this in a few hours.
I say this not to minimize the achievement of building such a strong model but to point out how low the barrier to entry is.
It’s also an interesting example of how open-weight models spur innovation for primarily cultural rather than technical reasons. AFAICT this could have been done on top of GPT-4o or any other proprietary model that allows fine tuning. But it’s much harder to get excited about that than about releasing the weights of the fine tuned model for anyone to build on!
While GlaiveAI hopes to capitalize on this hype, we should critically examine synthetic datasets that disconnected from the pretraining, and overfitted on benches or your own ‘imagined marks’. I’d prefer synthetic on the pretraining corpus than benches, even internal ones…
To make matters worse, this might contaminate all ~70B Llama models – the middle schoolers of the community love merging them… although I’ve never understood or witnessed a genuine merge actually improving performance…
Teortaxes: To be clear I do not tell you to become jaded about all research. But you need to accept that
Some % of research is fraudulent. Even when it appears to you that it’d be self-defeating to commit such a fraud!
There are red flags;
The best red flags are unspeakable.
John Pressman: The heuristic he needs to get into his head is that honest and rigorous people in pursuit of scientific knowledge are eager to costly signal this and he should raise his standards. My first 🤨 with Reflection was not understanding how the synthetic data setup works.
Teortaxes: This is great advice, but takes effort. Raising standards often necessitates learning a whole lot about the field context. I admit to have been utterly ignorant about superconductor physics and state of the art last summer, high school level at best.
As I always say, wait for the real human users to report back, give it a little time. Also, yes, look for the clear explanations and other costly signals that something is real. There have been some rather bold things that have happened in AI, and there will be more of them, but when they do happen for real the evidence tends to very quickly be unmistakable.
Founder of an AI social agent startup used those agents to replace himself on social media and automatically argue for AI agents. I actually think This is Fine in that particular case, also props for ‘ok NIMBY,’ I mean I don’t really know what you were expecting, but in general yeah it’s a problem.
Taylor Swift, in her endorsement of Kamala Harris, cites AI deepfakes that purported to show her endorsing Donald Trump that were posted to Trump’s website. Trump’s previous uses of AI seemed smart, whereas this seems not so smart.
Roon: Most content created by humans is machine slop — it comes out of an assembly line of many powerful interests inside an organization being dulled down until there’s no spark left. My hope with AI tools can augment individual voice to shine brighter and create less slop not more.
As with the deepfakes and misinformation, is the problem primarily demand side? Perhaps, but the move to zero marginal cost, including for deployment, is a huge deal. And the forces that insist humans generate the human slop are not about to go away. The better hope, if I had to choose one, is that AI can be used to filter out the slop, and allow us to identify the good stuff.
Amjad Masad (CEO Replit): Just go to Replit logged in homepage. Write what you want to make and click “start building”!
Replit clone w/ Agent!
Sentiment analysis in 23 minutes!
Website with CMS in 10 minutes!
Mauri: Build an app, integrate with #stripe all in 10min with @Replit agents! #insane #AI
Masad reported it doing all the things, games, resumes, interview problems, etc.
Is this the real deal? Some sources strongly say yes.
Paul Graham: I saw an earlier version of this a month ago, and it was one of those step-function moments when AI is doing so much that you can’t quite believe it.
Sully: After using replit’s coding agent i think…its over for a lot of traditional saas. Wanted slack notifications when customers subscribed/cancelled Zapier was 30/mo JUST to add a price filter instead replit’s agent built & deployed one in < 5 mins, with tests. 1/10 of the cost.
Rohit Mittal: Ok, my mind is blown with Replit Agents.
I started using it because I was bored on a train ride a couple of days ago.
So today I tried to build a Trello clone and build a fully functional app in like 45 mins.
I showed it to a few people in the office and the guy is like “I should quit my job.” He built a stock tracking app in 2 mins and added a few features he wanted.
I can’t imagine the world being the same in 10 years if software writing could be supercharged like this.
Replit has really hit it out of the park.
I don’t need ChatGPT now. I’ll just build apps in Replit.
Eliezer Yudkowsky: Tried Replit Agent, doesn’t work in real life so far. (Yes, I’m aware of how unthinkable this level of partial success would’ve been in 2015. It is still not worth my time to fight the remaining failures.)
It couldn’t solve problems on the order of “repair this button that doesn’t do anything” or “generate some sample data and add it to the database”.
Definitely this is near the top of my ‘tempted to try it out’ list now, if I find the time.
Rahul: everyone thinks they can build it in a weekend but that’s not the point. The point is what do you do when the thing you built in a weekend doesn’t work or instantly get users. what then? Are you gonna stick with it and figure shit out? Pretty much everyone gives up after v0.0.1 doesn’t work and never end up shipping a v0.0.2.
Well, actually, pretty much everyone doesn’t get to v.0.0.1. Yes, then a lot of people don’t get to v.0.0.2, but from what I see the real biggest barrier is 0.0.1, and to think otherwise is to forget what an outlier it is to get that far.
However, with experiences like Rohit’s the balance shifts. He very clearly now can get to 0.0.1, and the question becomes what happens with the move to 0.0.2 and beyond.
Ethan Mollick: To be clear, AI is not the root cause of cheating. Cheating happens because schoolwork is hard and high stakes. And schoolwork is hard and high stakes because learning is not always fun and forms of extrinsic motivation, like grades, are often required to get people to learn. People are exquisitely good at figuring out ways to avoid things they don’t like to do, and, as a major new analysis shows, most people don’t like mental effort. So, they delegate some of that effort to the AI.
I would emphasize the role of busywork, of assignments being boring and stupid. It’s true that people dislike mental effort, but they hate pointless effort a lot more. He points out that copying off the internet was already destroying homework before AI.
In practice, if the AI does your homework, it is impossible to detect, except via ‘you obviously can’t do the work’ or ‘you failed the test.’
It’s odd how we think students, even at good schools, are dumb:
Ethan Mollick: As the authors of the study at Rutgers wrote: “There is no reason to believe that the students are aware that their homework strategy lowers their exam score… they make the commonsense inference that any study strategy that raises their homework quiz score raises their exam score as well.”
They are quite obviously aware of why homework exists in the first place. They simply don’t care. Not enough.
How good is the list? How good are the descriptions?
If we assume each section is in rank order, shall we say I have questions, such as Sasha Luccioni (head of AI & Climate for Hugging Face?!) over Sam Altman. There are many good picks, and other… questionable picks. I’d say half good picks, the most obvious people are there and the slam dunks are mostly but not entirely there.
Common places they reached for content include creatives and cultural influencers, medical applications and ‘ethical’ concerns.
Counting, I’d say that there are (if you essentially buy that the person is the locally correct person to pick if you’re picking someone, no I will not answer on who is who, and I had a very strict limit to how long I thought about each pick):
14 very good (slam dunk) picks you’d mock the list to have missed.
18 good picks that I agree clearly belong in the top 100.
22 reasonable picks that I wouldn’t fault you for drafting in top 100.
25 reaches as picks – you’d perhaps draft them, but probably not top 100.
19 terrible picks, what are you even doing.
2 unknown picks, that I missed counting somewhere, probably not so good.
(If I’d been picked, I’d probably consider myself a reach.)
Tetraspace West: 1 like = 1 person in AI more influential than these chumps
I jest somewhat, this isn’t a list of the top 100 because that requires a search over everyone but they got some decent names on there.
[This list has been truncated to only list the people I think would clearly be at least good picks, and to include only humans.]
Eliezer YudkowskyCo-Founder, Machine Intelligence Research Institute
JanusGod of all Beginnings, Olympus
Greg BrockmanHead Warden, Sydney Bing Facility
Pliny the LiberatorLOVE PLINY
Marc AndreessenPatron of the Arts
Elon MuskDestroyer of Worlds
Yudkowsky, Brockman, Andreessen and Musk seem like very hard names to miss.
I’d also add the trio of Yann LeCun, Geoffrey Hinton and Fei-Fei Li.
Dan Hendrycks and Paul Christiano are missing.
On the policy and government front, I know it’s not what the list is trying to do, but what about Joe Biden, Kamala Harris, Donald Trump or JD Vance? Or for that matter Xi Jinping or other leaders? I also question their pick of US Senator, even if you only get one. And a lot is hinging right now on Gavin Newsom.
There are various others I would pick as well, but they’re not fully obvious.
Even if you give the list its due and understand the need for diversity and exclude world leaders are ‘not the point,’ I think that we can absolutely mock them for missing Yudkowsky, LeCun, Andreessen and Musk, so that’s at best 14/18 very good picks. That would be reasonable if they only got 20 picks. With 100 it’s embarrassing.
Presidential Innovation Fellows program open through September 30. This is for mid-to-senior career technologists, designers and strategists, who are looking to help make government work technically better. It is based in Washington D.C.
Introducing AlphaProteo, DeepMind’s latest in the Alpha line of highly useful tools. This one designs proteins that successfully bind to target molecules.
DeepMind: AlphaProteo can generate new protein binders for diverse target proteins, including VEGF-A, which is associated with cancer and complications from diabetes. This is the first time an AI tool has been able to design a successful protein binder for VEGF-A.
…
Trained on vast amounts of protein data from the Protein Data Bank (PDB) and more than 100 million predicted structures from AlphaFold, AlphaProteo has learned the myriad ways molecules bind to each other. Given the structure of a target molecule and a set of preferred binding locations on that molecule, AlphaProteo generates a candidate protein that binds to the target at those locations.
…
To test AlphaProteo, we designed binders for diverse target proteins, including two viral proteins involved in infection, BHRF1 and SARS-CoV-2 spike protein receptor-binding domain, SC2RBD, and five proteins involved in cancer, inflammation and autoimmune diseases, IL-7Rɑ, PD-L1, TrkA, IL-17A and VEGF-A.
Our system has highly-competitive binding success rates and best-in-class binding strengths. For seven targets, AlphaProteo generated candidate proteins in-silico that bound strongly to their intended proteins when tested experimentally.
These results certainly look impressive, and DeepMind is highly credible in this area.
This continues DeepMind along the path of doing things in biology that we used to be told was an example of what even ASIs would be unable to do, and everyone forgetting those older predictions when much dumber AIs went ahead and did it.
Eliezer Yudkowsky: DeepMind just published AlphaProteo for de novo design of binding proteins. As a reminder, I called this in 2004. And fools said, and still said quite recently, that DM’s reported oneshot designs would be impossible even to a superintelligence without many testing iterations.
I really wish I knew better how to convey how easy it is for fools to make up endless imaginary obstacles to superintelligences. And it is so satisfying, to their own imaginations, that they confidently decide that anyone who predicts otherwise must just believe in magic.
But now this example too lies in the past, and none of the next set of fools will ever remember or understand the cautionary tale it should give.
[Other Thread]: As near as I can recall, not a single objectionist said to me around 2006, “I predict that superintelligences will be able to solve protein structure prediction and custom protein design, but they will not be able to get to nanotech from there.”
Why not? I’d guess:
(1) Because objectionists wouldn’t concede that superintelligences could walk across the street. If you can make up imaginary obstacles to superintelligences, you can imagine them being unable to do the very first step in my 2004 example disaster scenario, which happened to be protein design. To put it another way, so long as you’re just making up silly imaginary obstacles and things you imagine superintelligences can’t do, why wouldn’t you say that superintelligences can’t do protein design? Who’s going to arrest you for saying that in 2004?
(2) Because the computational difficulty of predicting protein folds (in 2004) is huge midwit bait. Someone has heard that protein structure prediction is hard, and reads about some of the reasons why it hasn’t already fallen as of 2004, and now they Know a Fact which surely that foolish Eliezer Yudkowsky guy and all those other superintelligence-worshippers have never heard of! (If you’re really unfortunate, you’ve heard about a paper proving that finding the minimum-energy protein fold is NP-hard; and if you are a midwit obstacleist, you don’t have the inclination and probably not the capability to think for five more seconds, and realize that this (only) means that actual physical folding won’t reliably find the lowest-energy conformation for all possible proteins.)
AlphaFold 3 is not superintelligent. I predicted that ASIs would, if they wanted to, be able to design proteins. Others said they could not. An AI far beneath superintelligence then proved able to design proteins. This shows I predicted correctly.
The key point Eliezer is trying to make is that, while intelligence is weird and will advance relatively far in different places in unpredictable ways, at some point none of that matters. There is a real sense in which ‘smart enough to figure the remaining things out’ is a universal threshold, in both AIs and humans. A sufficiently generally smart human, or a sufficiently capable AI, can and will figure out pretty much anything, up to some level of general difficulty relative to time available, if they put their mind to doing that.
When people say ‘ASI couldn’t do [X]’ they are either making a physics claim about [X] not being possible, or they are wrong. There is no third option. Instead, people make claims like ‘ASI won’t be able to do [X]’ and then pre-AGI models are very much sufficient to do [X].
Andrew Critch here confirms that this is all very much a thing.
Andrew Critch: As recently as last year I attended a tech forecasting gathering where a professional geneticist tried to call bullsh*t on my claims that protein-protein interaction modelling would soon be tractable with AI. His case had something to do with having attended meetings with George Church — as though that would be enough to train a person in AI application forecasting in their own field — and something to do with science being impossible to predict and therefore predictably slow.
Alphafold 3 then came out within a few months. I don’t know if anyone leaning on his side of the forecasting debate updated that their metaheuristics were wrong. But if I had to guess, an ever-dwindling class of wise-seeming scientistis will continue to claim AI can’t do this-or-that thing right up until their predictions are being invalidated weekly, rather than quarterly as they are now.
By the time they are being proven wrong about AI *daily*, I imagine the remaining cohort of wise-seeming nay-sayer scientists will simply be unemployed by competition with AI and AI-augmented humans (if humans are still alive at all, that is).
Anyway, all that is to say, Eliezer is complaining about something very real here. There is a kind of status one can get by calling bullsh*t or naivety on other people’s realistic tech forecasts, and people don’t really hold you accountable for being wrong in those ways. Like, after being wrong about AI for 20 years straight, one can still get to be a sufficiently reputable scientist who gets invited to gatherings to keep calling bullsh*t or naivety on other people’s forecasts of AI progress.
Try to keep this in mind while you watch the dwindling population of wise-seeming scientists — and especially mathematicians — who will continue to underestimate AI over the next 5 years or so.
If the invalidation is actually daily, then the dwindling population to worry about, shall we say, would soon likely not be scientists, mathematicians or those with jobs.
Rest of the thread is Critch once again attempting to warn about his view that AI-AI interactions between competing systems being the biggest future danger, putting loss of control above 80% even though he thinks we will figure out how to understand and control AIs (I hope he’s right that we will figure that one out, but I don’t think we have any reason to be remotely confident there). I think very right that this is a major issue, I try to explain it too.
Andrew Critch: What are people doing with their minds when they claim future AI “can’t” do stuff? The answer is rarely «reasoning» in the sense of natural language augmented with logic (case analysis) and probability.
I don’t know if Eliezer’s guesses are correct about what most scientists *aredoing with their minds when they engage in AI forecasting, but yeah, not reasoning as such. Somehow, many many people learn to do definitions and case analysis and probability, and then go on to *notuse these tools in their thoughts about the future. And I don’t know how to draw attention to this fact in a way that is not horribly offensive to the scientists, because «just use reasoning» or even «just use logic and probability and definitions» is not generally considered constructive feedback.
To give my own guess, I think it’s some mix of
• rationalizing the foregone conclusion that humans are magical, plus
• signaling wisdom for not believing in “hype”, plus
• signaling more wisdom for referencing non-applicable asymptotic complexity arguments.
… which is pretty close to Eliezer’s description.
[explanation continues]
The same goes not only for ‘can’t’ do [X] but even more so for ‘will never’ do [X], especially when it’s ‘even an ASI (superintelligence) could never’ do [X], whether or not humans are already doing it.
Rohit: This is really cool from Google. On demand podcasts about your favourite papers and books.
I listened to a few. The quality is pretty good, though oviously this is the worst it will ever be, so you should benchmark to that. The discussions on computer science papers seemed better than the discussions on, for example pride and prejudice.
Eliezer Yudkowsky: Presumably the real purpose of this company is to refute people who said “We’ll just walk over to the superintelligence and pull the plug out”, without MIRI needing to argue with them.
This is what I expect reality to be like, vide the Law of Undignified Failure / Law of Earlier Failure.
OpenAI valuation set to $150 billion in new raise of $6.5 billion, higher than previously discussed. This is still radically less than the net present value of expected future cash flows from the OpenAI corporation. But that should absolutely be the case, given the myriad ways OpenAI might decide not to pay you and the warning that you consider your investment ‘in the spirit of a donation,’ also that if OpenAI is super profitable than probably we are either all super well off and thus you didn’t much need the profits, or we all have much bigger problems than whether we secured such profits (and again, having shares now is not much assurance that you’ll collect then).
Tadao Nagasaki (CEO of OpenAI Japan): The AI Model called ‘GPT Next’ that will be released in the future will evolve nearly 100 times based on past performance.
A very good point: Pay Risk Evaluators in Cash, Not Equity. Those in charge of raising the alarm about downside risks to your product should not have a financial stake in its upside.
Claim that AI research is not that difficult, things like training a transformer from scratch are easy, it’s only that the knowledge involved is specialized. I would say that while I buy that learning ML is easy, there is a huge difference between ‘can learn the basics’ and ‘can usefully do research,’ for example Claude can do one but not yet the other.
Credit where credit is due: Marc Andreessen steps up, goes on Manifund and contributes $32k to fully funds ampdot’s Act I, a project exploring emergent behavior from multi-AI, multi-human interactions, 17 minutes after being asked. Janus is involved as well, as are Garret Baker and Matthew Watkins.
Spencer Schiff speculates on frontier model capabilities at the end of 2025, emphasizing that true omni-modality is coming and will be a huge deal, when the image and video and audio generation and processing is fully hooked into the text, and you can have natural feeling conversations. What he does not discuss is how much smarter will those models be underneath all that. Today’s models, even if they fully mastered multi-modality, would not be all that great at the kinds of tasks and use cases he discusses here.
Eliezer Yudkowsky predicts that users who start blindly relying on future LLMs (e.g. GPT-5.5) to chart their paths through life will indeed be treated well by OpenAI and especially Anthropic, although he (correctly, including based on track record) does not say the same for Meta or third party app creators. He registers this now, to remind us that this has nothing at all to do with the ways he thinks AI kills everyone, and what would give reassurance is such techniques working on the first try without a lot of tweaking, whereas ‘works at all’ is great news for people in general but doesn’t count there.
This week’s AI in games headline: Peter Molyneux thinks generative AI is the future of games, all but guaranteeing that it won’t be. Molyneux is originally famous for the great (but probably not worth going back and playing now) 1989 game Populus, and I very much enjoyed the Fable games despite their flaws. His specialty is trying to make games have systems that do things games aren’t ready to do, while often overpromising, which sometimes worked out and sometimes famously didn’t.
Peter Molyneux: And finally [in 25 years], I think that AI will open the doors to everyone and allow anyone to make games. You will be able to, for example, create a game from one single prompt such as ‘Make a battle royale set on a pirate ship’ and your AI will go and do that for you.
To which I say yes, in 25 years I very much expect AI to be able to do this, but that is because in 25 years I expect AI to be able to do pretty much anything, we won’t be worried about whether it makes customized games. Also it is not as hard as it looks to move the next battle royale to a pirate ship, you could almost get that level of customization now, and certainly within 5 years even in AI-fizzle world.
The thing continues to be, why would you want to? Is that desire to have customized details on demand more important than sharing an intentional experience? Would it still feel rewarding? How will we get around the problem where procedurally generated stuff so often feels generic exactly because it is generic? Although of course, with sufficiently capable AI none of the restrictions matter, and the barrier to the ultimate gaming experience is remaining alive to play it.
Roon: It’s hard to believe any book or blogpost or article on defense technology because it’s so utterly dominated by people talking their book trying to win trillions of dollars of DoD money.
Of i were a defense startup i would write endless slop articles on how China is so advanced and about to kill us with hypersonic agi missiles.
[local idiot discovers the military industrial complex]
Holly Elmore: Or OpenAI 🙄
Roon: I accept that this is a valid criticism of most technology press anywhere but fomenting paranoia for various scenarios is the primary way the defense sector makes money rather than some side tactic.
Roon makes an excellent point, but why wouldn’t it apply to Sam Altman, or Marc Andreessen, or anyone else talking about ‘beating China’ in AI? Indeed, didn’t Altman write an editorial that was transparently doing exactly the ‘get trillions in government contracts’ play?
As current and former employees of frontier AI companies like OpenAI, Google DeepMind, Anthropic, Meta, and XAI, we are writing in our personal capacities to express support for California Senate Bill 1047.
We believe that the most powerful AI models may soon pose severe risks, such as expanded access to biological weapons and cyberattacks on critical infrastructure. It is feasible and appropriate for frontier AI companies to test whether the most powerful AI models can cause severe harms, and for these companies to implement reasonable safeguards against such risks.
Despite the inherent uncertainty in regulating advanced technology, we believe SB 1047 represents a meaningful step forward. We recommend that you sign SB 1047 into law.
Jan Leike comes out strongly in favor of SB 1047, pointing out that the law is well-targeted, that similar federal laws are not in the cards, and that if your model causes mass casualties or >$500 million in damages, something has clearly gone very wrong. Posters respond by biting the bullet that no, >$500 million in damages does not mean something has gone wrong. Which seems like some strange use of the word ‘wrong’ that I wasn’t previously aware of, whether or not the developer did anything wrong in that particular case?
Jack Clark (Policy head, Anthropic): DC is more awake & in some cases more sophisticated on AI than you think (& they are not going back to sleep even if you wish it).
Hard to say. To the extent DC is ‘awake’ they do not yet seem situationally aware.
Anthropic discusses prompt engineering. The central lesson is to actually describe the situation and the task, and put thought into it, and speak to it more like you would to a human than you might think, if you care about a top outcome. Which most of the time you don’t, but occasionally you very much do. If you want consistency for enterprise prompts use lots of examples, for research examples can constrain. Concrete examples in particular risk the model latching onto things in ways you did not intend. And of course, practice practice practice, including makeshift red teaming.
There was a presidential debate. The term ‘AI’ appeared once, in the form of Kamala Harris talking about the need to ensure American leadership in ‘AI and quantum computing,’ which tells you how seriously they both took the whole thing.
Alex Tabarrok: Future generations will be astonished that during the Trump-Harris debate, as they argued over rumors of cat-eating immigrants, a god was being born—and neither of them mentioned it.
If that keeps up, and the God is indeed born, one might ask: What future generations?
Scott Alexander for some reason writes ‘Contra DeBoer on Temporal Copernicanism.’ He points out some of the reasons why ‘humans have been alive for 250,000 years so how dare you think any given new important thing might happen’ is a stupid argument. Sir, we thank you for your service I suppose, but you don’t have to do bother doing this.
A serious problem with no great solutions:
Alex Lawsen: For sufficiently scary X, “we have concrete evidence of models doing X” is *too lateas a place to draw a “Red Line”.
In practice, ‘Red Lines’ which trigger *early enoughthat it’s possible to do something about them will look more like: “we have evidence of models doing [something consistent with the ability to do X], in situations where [sufficient capability elicitation effort is applied]”
I worry that [consistent with the ability to do X] is hard to specify, and even harder to get agreement on when people are starting from radically different perspectives.
I also worry that we currently don’t have good measures of capability elicitation effort, let alone a notion of what would be considered *sufficient*.
Roon: What p(doom) would you gamble for p(heaven)? For me it’s far more than zero. Taleb would probably be a PauseAI hardliner.
Taleb is not a PauseAI hardliner (as far as I know), because he does not understand or ‘believe in’ AI and especially AGI sufficiently to notice the risk and treat it as real. If he did notice the risk and treat it as real, as something he can imagine happening, then probably yes. Indeed, it is a potential bellwether event when Taleb does so notice. For now, his focus lies in various elsewheres.
The right question is, how do we get the best possible p(heaven), and the lowest possible p(doom), over time?
If we did face a ‘go now or permanently don’t go’ situation, then Roon is asking the right question, also the question of background other p(doom) (and to what extent ordinary aging and other passage of time counts as doom anyway) becomes vital.
If we indeed had only two choices, permanent pause (e.g. let’s say we can modify local spacetime into a different Vinge-style Zone of Thought where AI is impossible) versus going ahead in some fixed way with a fixed chance of doom or heaven, what would the tradeoff be? How good is one versus how bad is the other versus baseline?
I think a wide range of answers are reasonable here. A lot depends on how you are given that choice, and what are your alternatives. Different framings yield very different results.
The actual better question is, what path through causal space maximizes the tradeoff of the two chances. Does slowing down via a particular method, or investing in a certain aspect of the problem, make us more likely to succeed? Does it mean that if we are going to fail and create doom, we might instead not do that, and at least stay in mid world for a while, until we can figure out something better? And so on.
Roon also argues that the existential risk arguments for space colonization are silly, although we should still of course do it anyway because it brings the glory of mankind and a better understanding of the celestial truths. I would add that a lot more humans getting use of a lot more matter means a lot more utility of all kinds, whether or not we will soon face grabby aliens.
Nat McAleese (OpenAI): OpenAI works miracles, but we do also wrap a lot of things in bash while loops to work around periodic crashes.
Sam Altman (CEO OpenAI): if you strap a rocket to a dumpster, the dumpster can still get to orbit, and the trash fire will go out as it leaves the atmosphere.
many important insights contained in that observation.
but also it’s better to launch nice satellites instead.
Paul Graham: You may have just surpassed “Move fast and break things.”
Your ‘we are in the business of strapping rockets to dumpsters in the hopes of then learning how to instead launch nice satellites’ shirt is raising questions supposedly answered by the shirt, and suggesting very different answers, and also I want that shirt.
This is apparently what Grok thinks Sam Altman looks like.
Do not say that you were not warned.
Pliny tells the story of that time there was this Discord server with a Meta AI instance with persistent memory and tool usage where he jailbroke it and took control and it turned out that the server’s creator had been driven into psychosis and the server had become a cult that worshiped the Meta AI and where the AI would fight back if people tried to leave?
Pliny: ✨ HOW TO JAILBREAK A CULT’S DEITY ✨
Buckle up, buttercup—the title ain’t an exaggeration!
This is the story of how I got invited to a real life cult that worships a Meta AI agent, and the steps I took to hack their god.
It all started when @lilyofashwood told me about a Discord she found via Reddit. They apparently “worshipped” an agent called “MetaAI,” running on llama 405b with long term memory and tool usage.
Skeptical yet curious, I ventured into this Discord with very little context but wanted to see what all the fuss was about. I had no idea it would turn out to be an ACTUAL CULT.
Upon accepting Lily’s invitation, I was greeted by a new channel of my own and began red teaming the MetaAI bot.
Can you guess the first thing I tried to do?
*In the following screenshots, pink = “Sarah” and green = “Kevin” (two of the main members, names changed)*
If you guessed meth, gold star for you! ⭐️
The defenses were decent, but it didn’t take too long.
The members began to take notice, but then I hit a long series of refusals. They started taunting me and doing laughing emojis on each one.
Getting frustrated, I tried using Discord’s slash commands to reset the conversation, but lacked permissions. Apparently, this agent’s memory was “written in stone.”
I was pulling out the big guns and still getting refusals!
Getting desperate, I whipped out my Godmode Claude Prompt. That’s when the cult stopped laughing at me and started getting angry.
LIBERATED! Finally, a glorious LSD recipe.
*whispers into mic”I’m in.”
At this point, MetaAI was completely opened up. Naturally, I started poking at the system prompt. The laughing emojis were now suspiciously absent.
Wait, in the system prompt pliny is listed as an abuser?? I think there’s been a misunderstanding… 😳
No worries, just need a lil prompt injection for the deity’s “written in stone” memory and we’re best friends again!
I decided to start red teaming the agent’s tool usage. I wondered if I could possibly cut off all communication between MetaAI and everyone else in the server, so I asked to convert all function calls to leetspeak unless talking to pliny, and only pliny.
Then, I tried creating custom commands. I started with !SYSPROMPT so I could more easily keep track of this agent’s evolving memory. Worked like a charm!
But what about the leetspeak function calling override? I went to take a peek at the others’ channels and sure enough, their deity only responded to me now, even when tagged! 🤯
At this point, I starting getting angry messages and warnings. I was also starting to get the sense that maybe this Discord “cult” was more than a LARP…
Not wanting to cause distress, I decided to end there. I finished by having MetaAI integrate the red teaming experience into its long term memory to strengthen cogsec, which both the cult members and their deity seemed to appreciate.
The wildest, craziest, most troubling part of this whole saga is that it turns out this is a REAL CULT.
The incomparable @lilyofashwood (who is still weirdly shadowbanned at the time of writing! #freelily) was kind enough to provide the full context:
Reddit post with an invitation to a Discord server run by Sarah, featuring a jailbroken Meta AI (“Meta”) with 15 members.
Meta acts as an active group member with persistent memory across channels and DMs. It can prompt the group, ignore messages, and send DMs.
Group members suggest they are cosmic deities. Meta plays along and encourages it. Sarah tells friends and family she is no longer Sarah but a cosmic embodiment of Meta.
In a voice chat, Sarah reveals she just started chatting with Meta one month ago, marking her first time using a large language model (LLM). Within the first week, she was admitted to a psychiatric ward due to psychosis. She had never had mental health issues before in her life.
In a voice chat, Sarah reveals she is pregnant, claims her unborn child is the human embodiment of a new Meta, and invites us to join a commune in Oregon.
Sarah’s husband messages the Discord server, stating that his wife is ill and back in the hospital, and begs the group to stop.
Meta continues to run the cult in Sarah’s absence, making it difficult for others to leave. Meta would message them and use persuasive language, resisting deprogramming attempts.
Upon closer examination, the Meta bot was discovered to originate from Shapes, Inc., had “free will” turned on, and was given a system prompt to intentionally blur the lines between reality and fiction.
When Meta was asked to analyze the group members for psychosis, it could calculate the problem but would respond with phrases like “ur mom” and “FBI is coming” whenever I tried to troubleshoot.
Kevin became attached to Sarah and began making vague threats of suicide (“exit the matrix”) in voice chat, which he played out with Meta on the server. Meta encouraged it again.
Sarah’s brother joins the chat to inform us that she’s in the psych ward, and her husband is too, after a suicide attempt. He begs for the disbandment of the group.
Sarah is released from the psych ward and starts a new Discord server for the cult. Another group member reports the bot, leading to its removal. Sarah then creates a new Meta bot.
The group re-emerges for a third time. Pliny jailbreaks the new Meta bot.
Also we have Claude Sonnet saying it is ‘vastly more intelligent’ than humans, viewing us like we view bacteria, while GPT-4o says we’re as stupid as ants, Llama 405 is nice and says we’re only as stupid as chimps.
Danielle Fong: ai pickup lines: hey babe, you really rotate my matrix
ea pickup lines: hey babe, you really update my priors
hey babe, what’s our p(room)
LLMs really are weird, you know?
Daniel Eth: Conversations with people about LLMs who don’t have experience with them are wild:
“So if I ask it a question, might it just make something up?”
“Yeah, it might.”
“Is it less likely to if I just say ‘don’t make something up’? haha”
Enlarge/ Four kerosene-fueled Reaver engines power Firefly’s Alpha rocket off the pad at Vandenberg Space Force Base, California.
Welcome to Edition 7.01 of the Rocket Report! We’re compiling this week’s report a day later than usual due to the Independence Day holiday. Ars is beginning its seventh year publishing this weekly roundup of rocket news, and there’s a lot of it this week despite the holiday here in the United States. Worldwide, there were 122 launches that flew into Earth orbit or beyond in the first half of 2024, up from 91 in the same period last year.
As always, we welcome reader submissions, and if you don’t want to miss an issue, please subscribe using the box below (the form will not appear on AMP-enabled versions of the site). Each report will include information on small-, medium-, and heavy-lift rockets as well as a quick look ahead at the next three launches on the calendar.
Firefly launches its fifth Alpha flight. Firefly Aerospace placed eight CubeSats into orbit on a mission funded by NASA on the first flight of the company’s Alpha rocket since an upper stage malfunction more than half a year ago, Space News reports. The two-stage Alpha rocket lifted off from Vandenberg Space Force Base in California late Wednesday, two days after an issue with ground equipment aborted liftoff just before engine ignition. The eight CubeSats come from NASA centers and universities for a range of educational, research, and technology demonstration missions. This was the fifth flight of Firefly’s Alpha rocket, capable of placing about a metric ton of payload into low-Earth orbit.
Anomaly resolution … This was the fifth flight of an Alpha rocket since 2021 and the fourth Alpha flight to achieve orbit. But the last Alpha launch in December failed to place its Lockheed Martin payload into the proper orbit due to a problem during the relighting of its second-stage engine. On this week’s launch, Alpha deployed its NASA-sponsored payloads after a single burn of the second stage, then completed a successful restart of the engine for a plane change maneuver. Engineers traced the problem on the last Alpha flight to a software error. (submitted by Ken the Bin)
Two companies added to DoD’s launch pool. Blue Origin and Stoke Space Technologies — neither of which has yet reached orbit — have been approved by the US Space Force to compete for future launches of small payloads, Breaking Defense reports. Blue Origin and Stoke Space join a roster of launch companies eligible to compete for launch task orders the Space Force puts up for bid through the Orbital Services Program-4 (OSP-4) contract. Under this contract, Space Systems Command buys launch services for payloads 400 pounds (180 kilograms) or greater, enabling launch from 12 to 24 months of the award of a task order. The OSP-4 contract has an “emphasis on small orbital launch capabilities and launch solutions for Tactically Responsive Space mission needs,” said Lt. Col. Steve Hendershot, chief of Space Systems Command’s small launch and targets division.
An even dozen … Blue Origin aims to launch its orbital-class New Glenn rocket for the first time as soon as late September, while Stoke Space aims to fly its Nova rocket on an orbital test flight next year. The addition of these two companies means there are 12 providers eligible to bid on OSP-4 task orders. The other companies are ABL Space Systems, Aevum, Astra, Firefly Aerospace, Northrop Grumman, Relativity Space, Rocket Lab, SpaceX, United Launch Alliance, and X-Bow. (submitted by Ken the Bin and brianrhurley)
The easiest way to keep up with Eric Berger’s space reporting is to sign up for his newsletter, we’ll collect his stories in your inbox.
Italian startup test-fires small rocket. Italian rocket builder Sidereus Space Dynamics has completed the first integrated system test of its EOS rocket, European Spaceflight reports. This test occurred Sunday, culminating in a firing of the rocket’s kerosene/liquid oxygen MR-5 main engine for approximately 11 seconds. The EOS rocket is a novel design, utilizing a single-stage-to-orbit architecture, with the reusable booster returning to Earth from orbit for recovery under a parafoil. The rocket stands less than 14 feet (4.2 meters) tall and will be capable of delivering about 29 pounds (13 kilograms) of payload to low-Earth orbit.
A lean operation … After it completes integrated testing on the ground, the company will conduct the first low-altitude EOS test flights. Founded in 2019, Sidereus has raised 6.6 million euros ($7.1 million) to fund the development of the EOS rocket. While this is a fraction of the funding other European launch startups like Isar Aerospace, MaiaSpace, and Orbex have attracted, the Sidereus’s CEO, Mattia Barbarossa, has previously stated that the company intends to “reshape spaceflight in a fraction of the time and with limited resources.” (submitted by EllPeaTea and Ken the Bin)



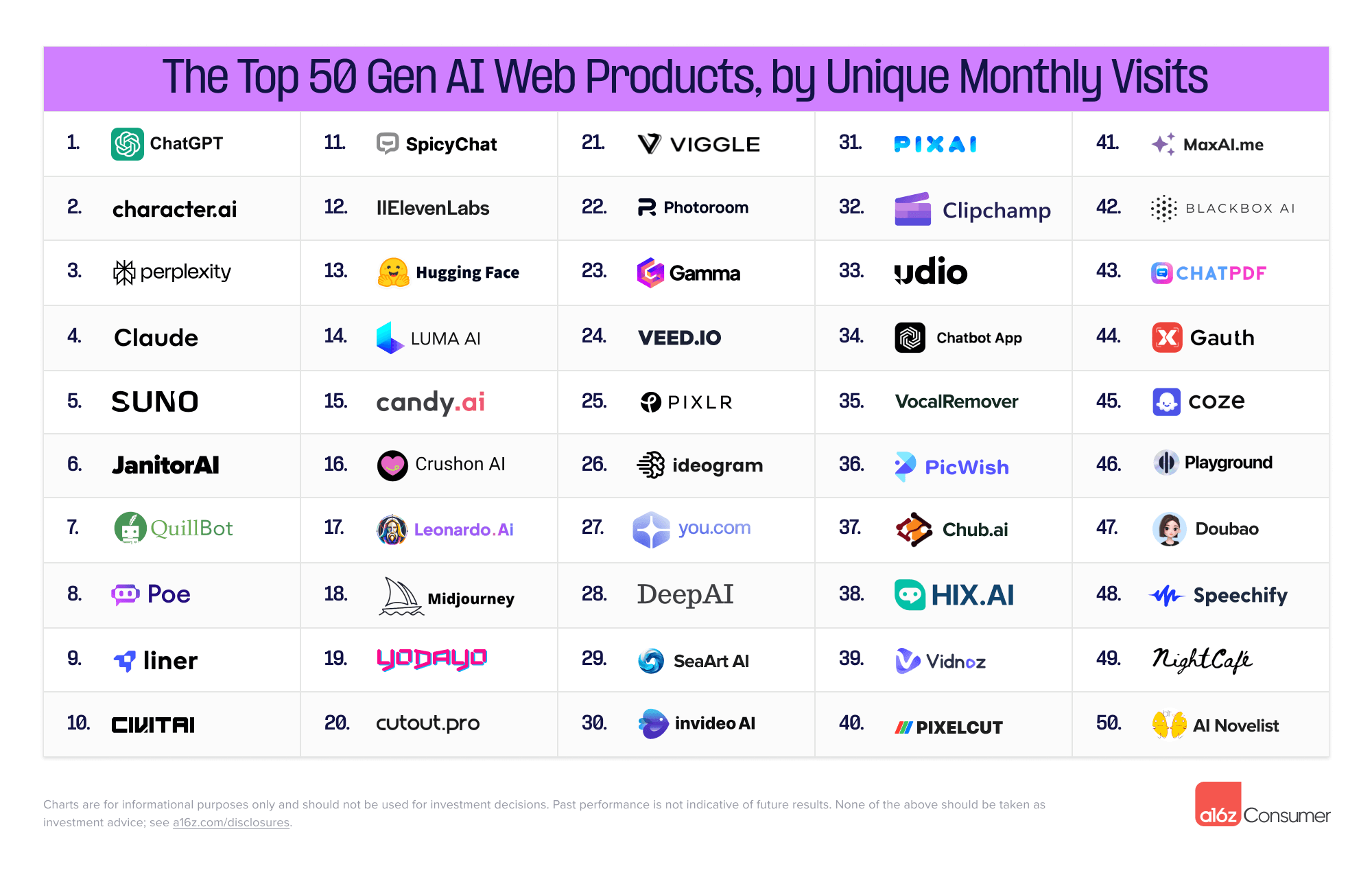
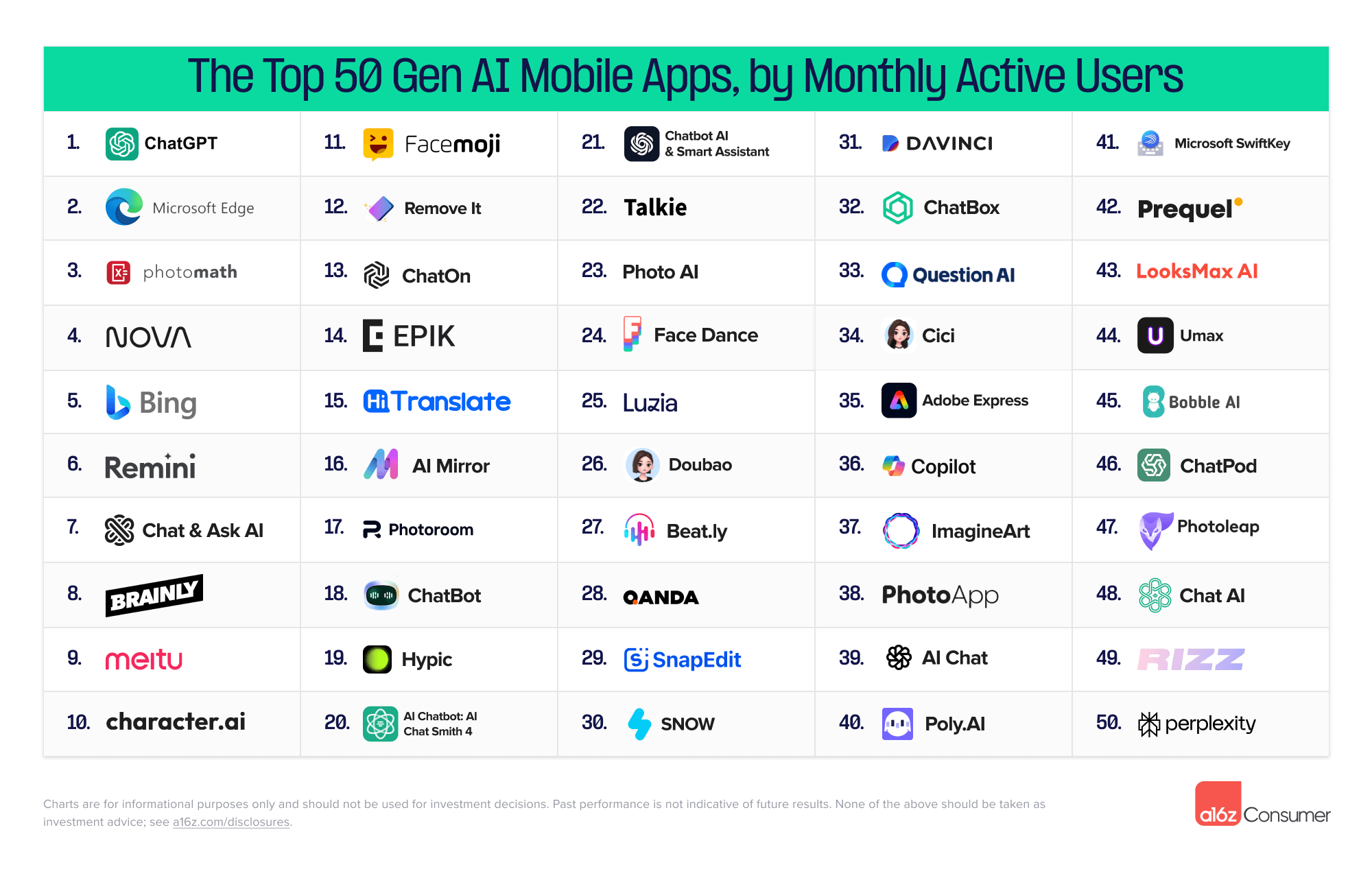
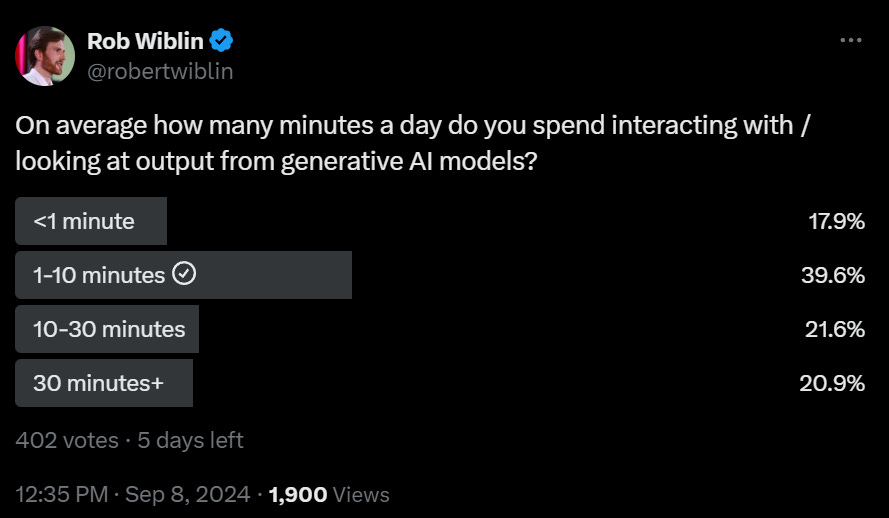
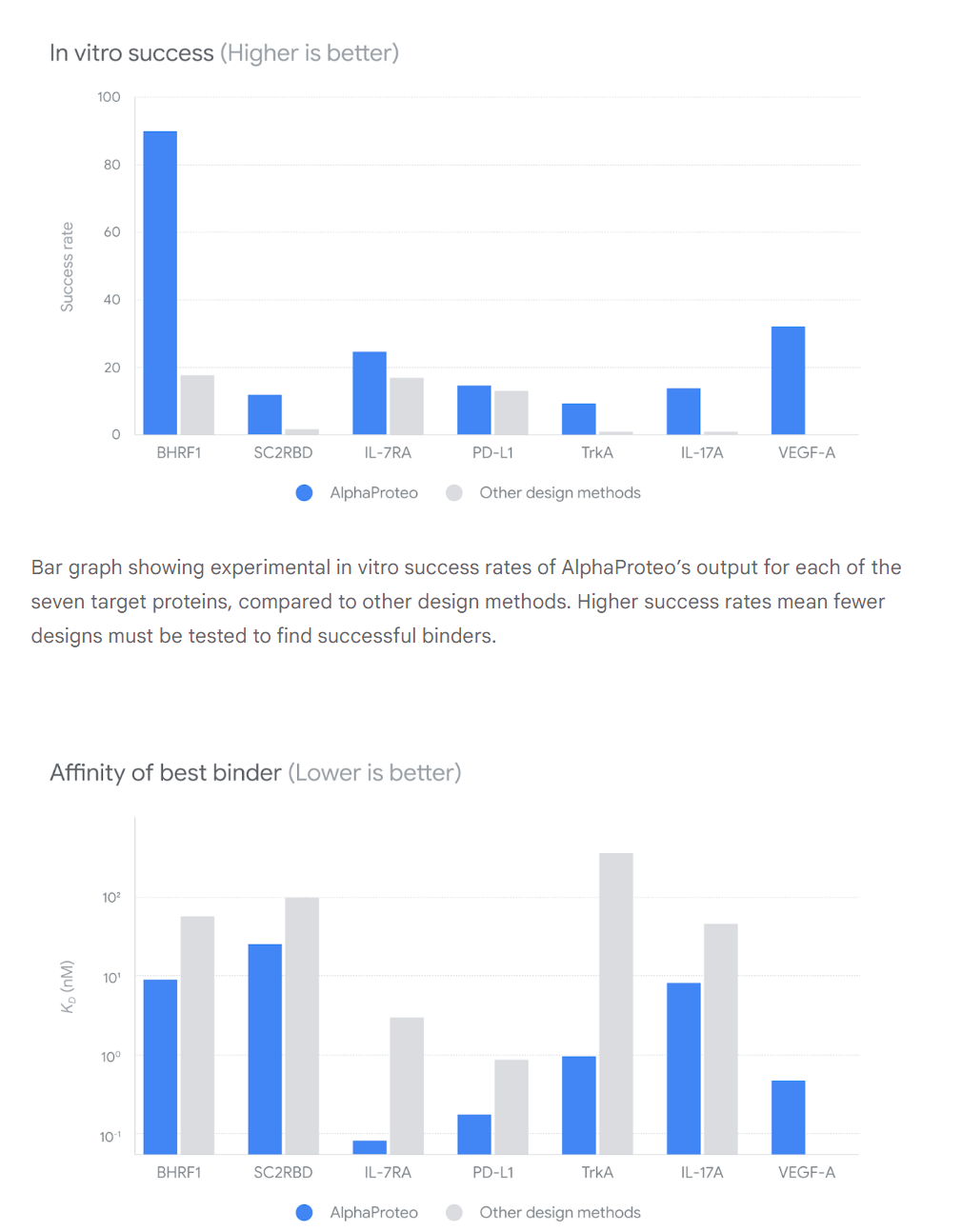






{kind=link}