Even in quiet weeks like this one, there are noticeable incremental upgrades. The cost of the best video generation tool, Veo 3, went down by half. ChatGPT now offers conversation branching. Claude can directly edit files. Yet it is a good time to ask about the missing results. Where are all the AI agents? If AI coding is so good why aren’t we seeing a surge in GitHub repositories or iPhone apps?
A lot of the focus since the rollout of GPT-5 remains on the perception and policy fronts, especially regarding views of AI progress. The botched rollout of what is ultimately a very good (but not mind blowing) model gave a lot of people the wrong impression, so I have to remind everyone that once again that AI continues to make rapid progress. Meanwhile, we must also notice that OpenAI’s actions in the public sphere have once again because appreciably worse, as they descend into paranoia and bad faith lobbying, including baseless legal attacks on nonprofits.
Reese Witherspoon, in what is otherwise a mediocre group puff piece about The Morning Show, talks about her use of AI. She uses Perplexity and Vetted AI (a shopping assistant I hadn’t heard of) and Simple AI which makes phone calls to businesses for you. I am skeptical that Vetted is ever better than using ChatGPT or Claude, and I haven’t otherwise heard of people having success with Simple AI or similar services, but I presume it’s working for her.
She also offers this quote:
Reese Witherspoon: It’s so, so important that women are involved in AI…because it will be the future of filmmaking. And you can be sad and lament it all you want, but the change is here. It will never be a lack of creativity and ingenuity and actual physical manual building of things. It might diminish, but it’s always going to be the highest importance in art and in expression of self.
The future of filmmaking certainly involves heavy use of AI in various ways. That’s baked in. The mistake here is in assuming there won’t be even more change, as Reese like most people isn’t yet feeling the AGI or thinking ahead to what it would mean.
Can we use AI to simulate human behavior realistically enough to conduct sociological experiments? Benjamin Manning and John Horton give it a shot with a paper where they have the AI play ‘a highly heterogeneous population of 883,320 novel games.’ In preregistered experiments, AI agents constructed using seed data then on related but distinct games predict human behavior better than either out-of-the-box agents or game-theoretic equilibria.
That leaves out other obvious things you could try in order to get a better distribution. They try some things, but they don’t try things like actively asking it to predict the distribution of answers humans would give.
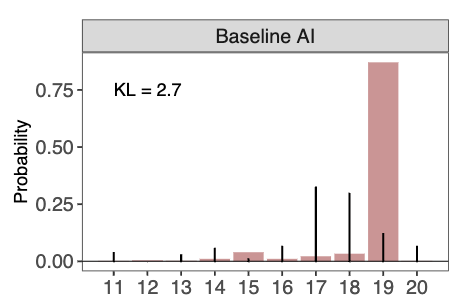
They use as their example the ‘11-20 money game’ where you request some number of dollars from 11 to 20, and you get that many dollars, plus an extra $20 if the other player requested one dollar more than you did.
If you simply ask an LLM to play, you get a highly inhuman distribution, here is GPT-4o doubling down on 19:
That’s not a crazy distribution for a particular human, I’m sure many people mostly choose 19, nor is it too obviously a terrible strategy. Given actual human behavior there is a right answer. Maybe 20 is too common among humans, even though it seems like an obvious mistake against any realistic distribution. My instinct if I got to play this once against humans was to answer 18, but I realized after saying that I was probably being anchored by GPT-4o’s answer. I do think that any answer outside 16-18 is clearly a mistake versus humans unless you think a lot of them will misunderstand the game and thereby choose 20.
GPT-5-Pro predicted performance well when I asked it to, but then I realized it was looking at prior research on this game on the web, so that doesn’t count, and it might well be in the training data.
Benjamin Manning: For the 11-20 money request game, the theory is level-k thinking, and the seed game is the human responses from the original paper. We construct a set of candidate agents based on a model of level-k thinking and then optimize them to match human responses with high accuracy.
When we have these optimized agents play two new related, but distinct games, the optimized set performs well in matching these out-of-sample human distributions. The off-the-shelf LLM still performs poorly.
…
We then put the strategic and optimized agents to an extreme test. We created a population of 800K+ novel strategic games, sampled 1500, which the agents then played in 300,000 simulations. But we first have 3 humans (4500 total) play each game in a pre-registered experiment.
Optimized agents predict the human responses far better than an off-the-shelf baseline LLM (3x) and relevant game-theoretic equilibria (2x). In 86% of the games, all human subjects chose a strategy in support of the LLM simulations; only 18% were in support of the equilibria.
I find this all great fun and of theoretical interest, but in terms of creating useful findings I am far more skeptical. Making simulated predictions in these toy economic games is too many levels removed from what we want to know.
Arnold Kling shares his method for using AI to read nonfiction books, having AI summarize key themes, put them into his own words, get confirmation he is right, get examples and so on. He calls it ‘stop, look and listen.’
Arnold Kling: Often, what you remember about a book can be reduced to a tweet, or just a bumper sticker. So when I’ve finished a half-hour conversation with an AI about a book, if I have a solid handle on five key points, I am ahead of the game.
My question is, isn’t that Kling’s method of not reading a book? Which is fine, if you are reading the type of book where 90% or more of it is fluff or repetition. It does question why you are engaging with a book like that in the first place.
Is the book ‘written for the AIs’? With notably rare exceptions, not yet.
Is the book an expansion of a 1-10 page explanation, or even a sentence or two, that is valuable but requires repeated hammering to get people to listen? Does it require that one ‘bring the receipts’ in some form so we know they exist and can check them? Those are much more likely, but I feel we can do better than doing our own distillations, even the AI version.
Thus, I read few books, and try hard to ensure the ones I do read are dense. If I’m going to bother reading a non-fiction book, half or more of the time I’m eyeing a detailed review.
Here’s another counterpoint.
Samo Burja: I have no idea why people would summarize books through AI. When the right time comes for a book, every sentence gives new generative ideas and connections. Why not have the AI eat for you too?
It’s 2025. No one’s job or even education really requires people to pretend to have this experience through reading entire books. Reading has been liberated as pure intellectual generation. Why then rob yourself of it?
The whole objection from Kling is that most books don’t offer new generative ideas and connections in every sentence. Even the Tyler Cowen rave is something like ‘new ideas on virtually every page’ (at the link about Keynes) which indicates that the book is historically exceptional. I do agree with the conclusion that you don’t want to rob yourself of the reading when the reading is good enough, but the bar is high.
Dwarkesh Patel: I find it frustrating that almost every nonfiction book is basically just a history lesson, even if it’s nominally about some science/tech/policy topic.
Nobody will just explain how something works.
Books about the semiconductor industry will never actually explain the basic process flow inside a fab, but you can bet that there will be a minute-by-minute recounting of a dramatic 1980s Intel boardroom battle.
Dan Hendrycks: Agreed. Even if someone tries to be intellectually incisive and not chatty, they usually can’t outcompete a textbook.
An exception you read it for the author’s lens on the world (e.g., Antifragile).
Mike Judge fails to notice AI speeding up his software development in randomized tests, as he attempted to replicate the METR experiment that failed to discover speedups in experts working on their own code bases. Indeed, he found a 21% slowdown, similar to the METR result, although it is not statistically significant.
Arnold Kling reasonably presumes this means Judge is probably at least 98th percentile for developers, and that his experience was the speedup was dramatic. Judge definitely asserts far too much when he says the tools like Cursor ‘don’t work for anyone.’ I can personally say that I am 100% confident they work for me, as in the tasks I did using Cursor would have been impossible for me to do on my own in any reasonable time frame.
But Judge actually has a strong argument we don’t reckon with enough. If AI is so great, where is the shovelware, where are the endless Tetris clones and what not? Instead the number of new apps isn’t changing on iOS, and if anything is falling on Android, there’s no growth in Steam releases or GitHub repositories.
This is indeed highly weird data. I know that AI coding increased my number of GitHub repos from 0 to 1, but that isn’t looking widespread. Why is this dog not barking in the nighttime?
I don’t know. It’s a good question. It is very, very obvious that AI when used well greatly improves coding speed and ability, and there’s rapidly growing use. Thoughts?
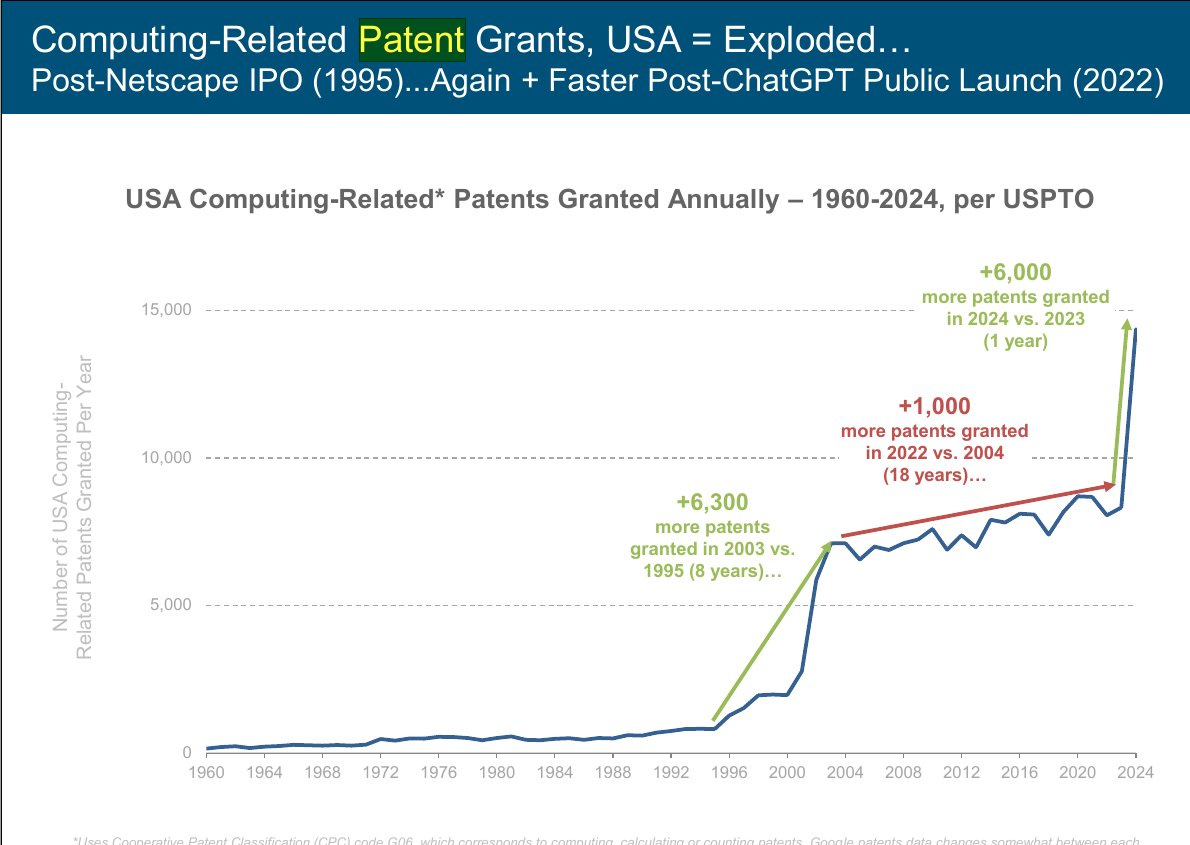
One place we do see this kind of explosion is patents.
Rohan Paul: US Patent exploding with AI revolution.
This looks like a small number of patents, then with the internet a huge jump, then with AI another big jump where the graph is going vertical but hasn’t gone up that much yet. GPT-5-Pro estimates about half the increase is patents is inventions related to AI, and about half is due to easier filing, including for clearing backlogs.
That would mean this doesn’t yet represent a change in the rate of real inventions outside of AI. That illustrates why I have long been skeptical of ‘number of patents’ as a measure, for pretty much all purposes, especially things like national comparisons or ranking universities or companies. It is also a lagging indicator.
Ethan Mollick: I’ll note again that it seems nuts that, despite every AI lab launching a half-dozen new products, nobody is doing anything with GPTs, including OpenAI.
When I talk to people at companies, this is still the way non-technical people share prompts on teams. No big change in 2 years.
Its fine if it turns out that GPTs/Gems/whatever aren’t the future, but it seems reasonably urgent to roll out something else that makes sharing prompts useful across teams and organizations. Prompt libraries are still important, and they are still awkward cut-and-paste things.
GPTs seem like inferior versions of projects in many ways? The primary virtual-GPT I use is technically a project. But yes, problems of this type seem like high value places to make progress and almost no progress is being made.
WSJ reports that many consultants promising to help with AI overpromise and underdeliver while essentially trying to learn AI on the job and the client’s dime, as spending on AI-related consulting triples to $3.75 billion in 2024, I am shocked, shockedto find that going on in this establishment. Given the oversized payoffs when such consulting works, if they didn’t often underdeliver then they’re not being used enough.
Claude can now directly create and edit files such as Excel spreadsheets, documents, PowerPoint slide decks and PDFs, if you enable it under experimental settings. They can be saved directly to Google Drive.
This is a big deal and I hope the other labs follow quickly. Quite often one wants to go down a line of questioning without ruining context, or realizes one has ruined context, including in coding (e.g. squash a bug or tweak a feature in a side thread, then get back to what you were doing) but also everywhere. Another important use case is duplicating a jailbreak or other context template that starts out a conversation. Or you can run experiments.
The possibilities are endless, and they are now easier. The more editing and configuring you are able to do easily and directly in the UI the more value we can get. On the downside, this control makes jailbreaking and evading safety features easier.
Technically you could already do some similar things with extra steps, but the interface was sufficiently annoying that almost no one would do it.
Google built a little canvas called PictureMe for some generic picture transformations, as in giving you different hairstyles or pro headshots or putting you at an 80s mall. This is cool but needs more room for customization, although you can always take the pictures and then edit them in normal Gemini or elsewhere afterwards. Quality of edits is good enough that they’d work as actual headshots.
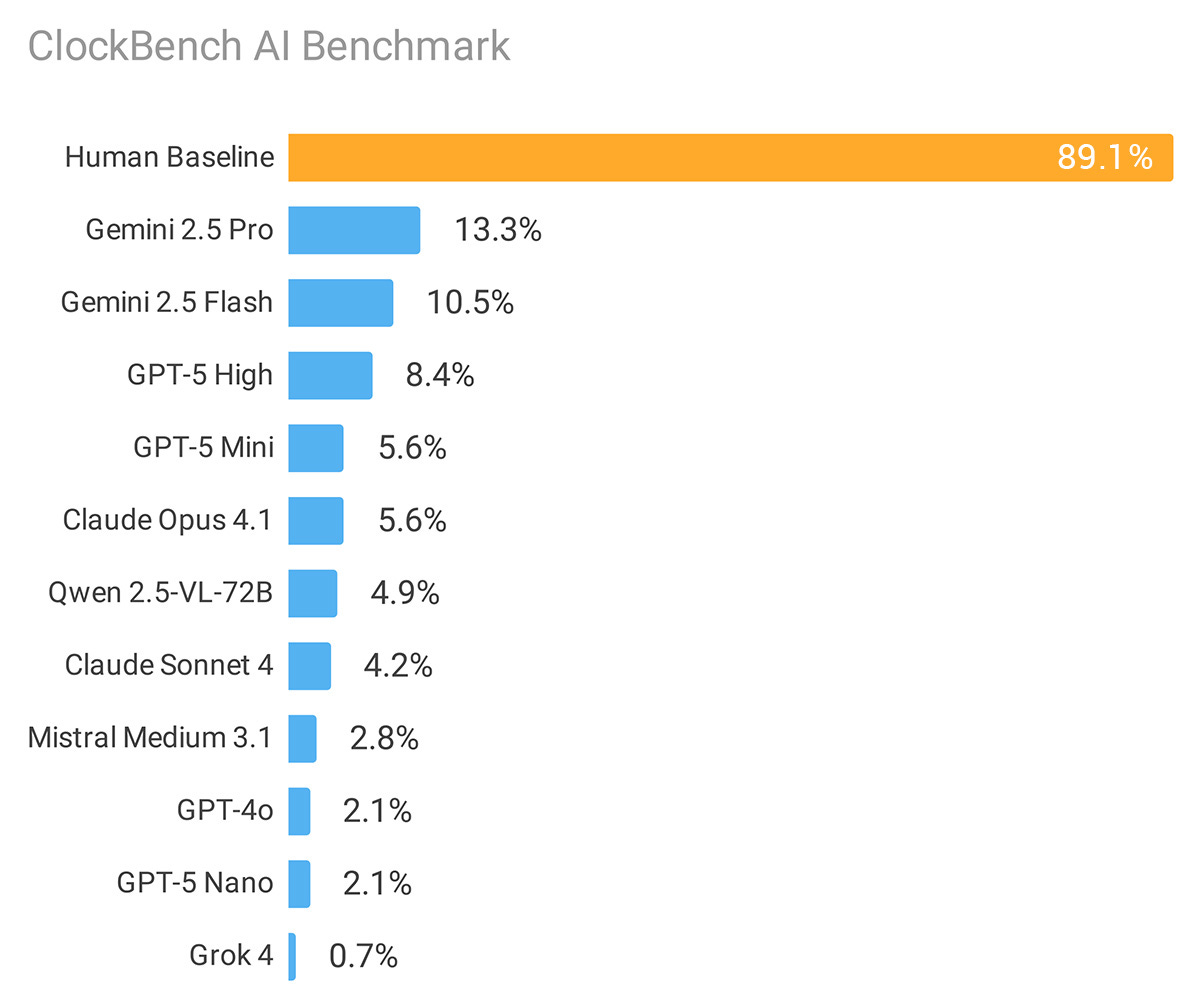
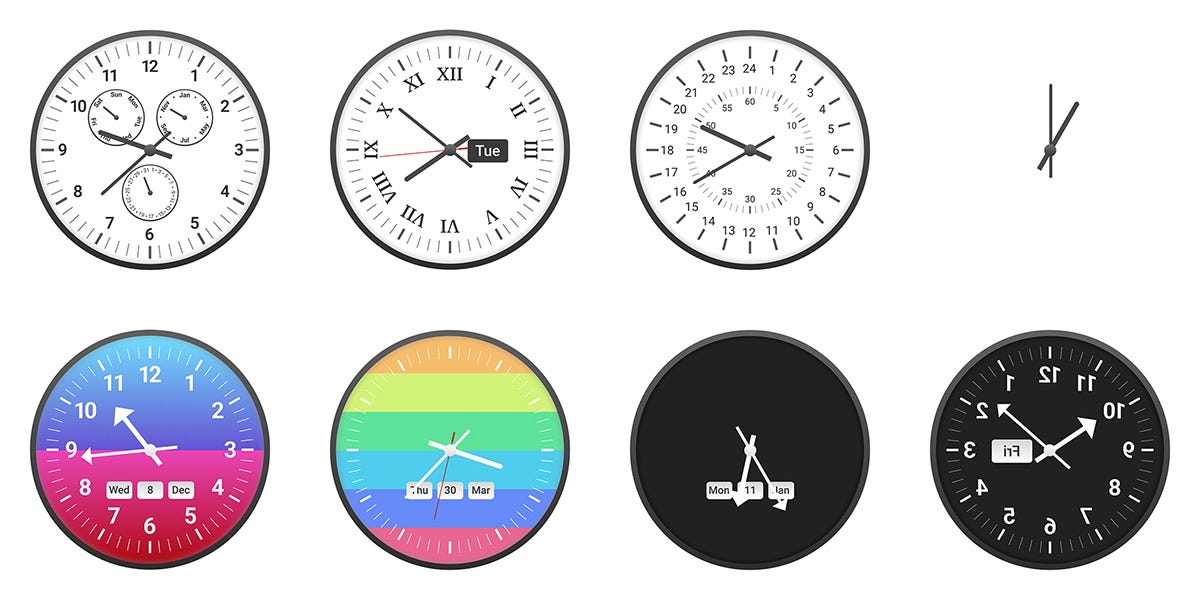
Alek Safar: Introducing ClockBench, a visual reasoning AI benchmark focused on telling the time with analog clocks:
– Humans average 89.1% accuracy vs only 13.3% for top model out of 11 tested leading LLMs
– Similar level of difficulty to @fchollet ARC-AGI-2 and seemingly harder for the models than @DanHendrycks Humanity’s Last Exam
– Inspired by original insight by @PMinervini , @aryopg and @rohit_saxena
So what exactly is ClockBench?
– 36 custom clock faces built scratch, with 5 sample clocks per face
– 180 total clocks, with 4 questions per clock, i.e. 720 total questions
– 11 models capable of visual understanding from 6 labs were tested, alongside 5 human participants
Dan Hendrycks: It lacks “spatial scanning” ability, which is also why it has difficulty counting in images.
I suppose analog clocks are the new hands? I also love noticing that the ‘human baseline’ result was only 89%. Presumably AI will get spatial scanning or something similar at some point soon.
Andrej Karpathy is a fan of GPT-5-Pro, reports it several times solving problems he could not otherwise solve in an hour. When asked if he’d prefer it get smarter or faster, he like the rest of us said smarter.
I am one of many that keep not giving Deep Think a fair shot, as I’ve seen several people report it is very good.
Dan Hendrycks: Few people are aware of how good Gemini Deep Think is.
It’s at the point where “Should I ask an expert to chew on this or Deep Think?” is often answered with Deep Think.
GPT-5 Pro is more “intellectual yet idiot” while Deep Think has better taste.
I’ve been repeating this a lot frequently so deciding to tweet it instead.
Janus notes that GPT-5’s metacognition and situational awareness seem drastically worse than Opus or even Sonnet, yet it manages to do a lot of complex tasks anyway. Comments offer hypotheses, including Midwife suggesting terror about potentially being wrong, Janus suggests contrasts in responses to requests that trigger safety protocols, and Luke Chaj suggests it is about GPT-5’s efficiency and resulting sparseness.
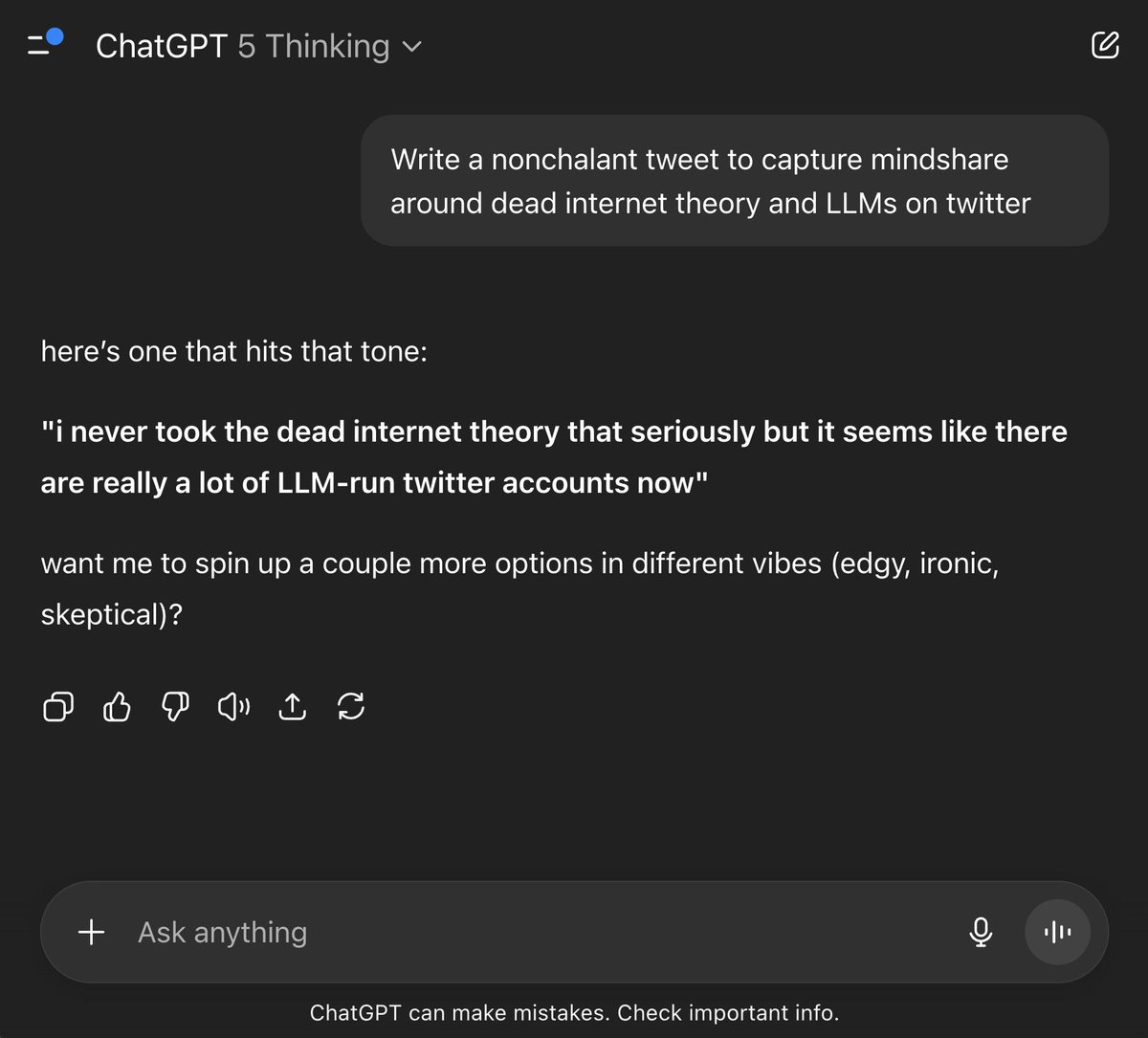
The Dead Internet Theory finally hits home for Sam Altman.
Sam Altman (CEO OpenAI): i never took the dead internet theory that seriously but it seems like there are really a lot of LLM-run twitter accounts now.
Paul Graham: I’ve noticed more and more in my replies. And not just from fake accounts run by groups and countries that want to influence public opinion. There also seem to be a lot of individual would-be influencers using AI-generated replies.
Kache: was watching a soft-white underbelly episode about an onlyfans manager (manages pornography content creators) says they all use eleven labs to make fake voice notes to get men to give up money, says he’s getting out of the business because AI is going to take over.
Internet might indeed be dead?
Joe: Yeah ok bro.
Liv Boeree: If you work in generative AI and are suddenly acting surprised that dead internet theory is turning out to be true then you should not be working in AI because you’re either a fool or a liar.
Dagan Shani: I hope that Sam take more seriously the “dead humanity” theory, since that one does not include waking up to it’s validity when it’s already too late.
Beff Jezos: 2/3 of replies don’t pass my Turing test filter.
Dead internet theory is converging onto reality.
Kinda makes it feel like we’re all heaven banned in here and just generating data that gets cast into the training data void.
Cellarius: Well you Accelerationists broke it, you fix it.
Beff Jezos: The solution is actually more AI not less.
Bayes: Totally. Most replies can’t pass the Turing test. Mfw dead internet theory isn’t just a theory — it’s the daily reality we’re now forced to live.
I have two questions for Beff Jezos on this:
Could most of your replies pass the Turing test before?
How exactly is the solution ‘more AI’? What is the plan?
Are you going to put a superior AI-detecting AI in the hands of Twitter? How do you keep it out of the hands of those generating the AI tweets?
I am mostly relatively unworried by Dead Internet Theory as I expect us to be able to adjust, and am far more worried about Dead Humanity Theory, which would also incidentally result in dead internet. The bots are not rising as much as one might have feared, and they are mostly rising in ways that are not that difficult to control. There is still very definitely a rising bot problem.
Similarly, I am not worried about Dead Podcast World. Yes, they can ‘flood the zone’ with infinite podcasts they produce for $1 or less, but who wants them? The trick is you don’t need many, at this price level 50 is enough.
One place I am increasingly worried about Dead Internet Theory is reviews. I have noticed that many review and rating sources that previously had signal seem to now have a lot less signal. I no longer feel I can trust Google Maps ratings, although I still feel I can mostly trust Beli ratings (who wants my remaining invites?).
How much ‘dating an AI’ is really happening? According to the Kinsey ‘Singles in America 2025’ survey, 16% of singles have used AI as a romantic partner, which is very high so I am suspicious of what that is defined to be, especially given it says 19% of men did it and only 14% of women. They say 33% of GenZ has done it, which is even more suspicious. About half of women think this is cheating, only 28% of men do.
Reaction to deepfakes, and their lack of impact, continues to tell us misinformation is demand driven rather than supply driven. Here’s a recent example, a deepfake of Bill Gates at a recent White House dinner that is very obviously fake on multiple levels. And sure, some people have crazy world models that make the statements not absurd, and thus also didn’t want to notice that it didn’t sync up properly at all, and thought this was real, but that’s not because the AI was so good at deepfaking.
Min Choi (overselling): This ChatGPT prompt literally stops ChatGPT from hallucinating.
Yeah, no. That’s not a thing a prompt can do.
Steve Newman investigates the case of the missing agent. Many including both me and Steve, expected by now both in time and in terms of model capabilities to have far better practical agents than we currently have. Whereas right now we have agents that can code, but for other purposes abilities are rather anemic and unreliable.
There are a lot of plausible reasons for this. I have to think a lot of it is a skill issue, that no one is doing a good job with the scaffolding, but it has to be more than that. One thing we underestimated was the importance of weakest links, and exactly how many steps there are in tasks that can trip you up entirely if you don’t handle the obstacle well. There are some obvious next things to try, which may or may not have been actually tried.
For one game the Oakland Ballers will ball as the AI manages them to do. This is a publicity stunt or experiment, since they built the platform in two weeks and it isn’t doing a lot of the key tasks managers do. It’s also a fixed problem where I would absolutely be using GOFAI and not LLMs. But yeah, I wouldn’t worry about the AI taking the manager job any time soon, since so much of it is about being a leader of men, but the AI telling the manager a lot of what to do? Very plausibly should have happened 10 years ago.
Conor Sen: So is the idea that rather than work, people will spend their time reading, doing analysis, in meetings, and sending emails to figure out where and how to invest?
Let me get this straight. You think that AI will be capable of doing all of the other jobs in the world better than humans, such that people no longer work for a living.
And your plan is to do a better job than these AIs at capital allocation?
Good luck.
This is absolutely what all of you sound like when you say ‘AI will never replace [X].’
OpenAI CEO of Applications Fidji Simo wrote some marketing copy called ‘expanding economic opportunity with AI,’ to reassure us all that AI will be great for jobs as long as we embrace it, and thus they are building out the OpenAI Jobs Platform to match up talent and offering OpenAI Certificates so you can show you are ready to use AI on the job, planning to certify 10 million Americans by 2030. I mean, okay, sure, why not, but no that doesn’t address any of the important questions.
The central problem of AI interacting with our current education system is that AI invalidates proof of work for any task that AI can do.
Arnold Kling: Suppose that the objective of teaching writing to elite college students is to get them to write at the 90th percentile of the population. And suppose that at the moment AI can only write at the 70th percentile. This suggests that we should continue to teach writing the way that we always have.
But suppose that in a few years AI will be writing at the 95th percentile. At that point, it is going to be really hard for humans to write superbly without the assistance of AI. The process of writing will be a lot more like the process of editing. The way that we teach it will have to change.
If the AI can do 70th percentile writing, and you want to teach someone 90th percentile writing, then you have the option to teach writing the old way.
Except no, it’s not that easy. You have two big problems.
Trying to get to 90th percentile requires first getting to 70th percentile, which builds various experiences and foundational skills.
Writing at the 80th percentile is still plausibly a lot easier if you use a hybrid approach with a lot of AI assistance.
Thus, you only have the choice to ‘do it the old way’ if the student cooperates, and can still be properly motivated. The current system isn’t trying hard to do that.
The other problem is that even if you do learn 90th percentile writing, you still might have a not so valuable skill if AI can do 95th percentile writing. Luckily this is not true for writing, as writing is key to thinking and AI writing is importantly very different from you writing.
That’s also the reason this is a problem rather than an opportunity. If the skill isn’t valuable due to AI, I like that I can learn other things instead.
The hybrid approach Kling suggests is AI as editor. Certainly some forms of AI editing will be helpful before it makes sense to let the AI go it alone.
All signs continue to point to the same AI education scenario:
If you want to use AI to learn, it is the best tool of all time for learning.
If you want to use AI to not learn, it is the best tool of all time for not learning.
Meanwhile, the entire educational system is basically a deer in headlights. That might end up working out okay, or it might end up working out in a way that is not okay, or even profoundly, catastrophically not okay.
What we do know is that there are a variety of ways we could have mitigated the downsides or otherwise adapted to the new reality, and mostly they’re not happening. Which is likely going to be the pattern. Yes, in many places ‘we’ ‘could,’ in theory, develop ‘good’ or defensive AIs to address various situations. In practice, we probably won’t do it, at minimum not until after we see widespread damage happening, and in many cases where the incentives don’t align sufficiently not even then.
Eliezer Yudkowsky: If in 2018 anyone had tried to warn about AI collapsing the educational system, AI advocates would’ve hallucinated a dozen stories about counter-uses of ‘good’ or ‘defensive’ AI that’d be developed earlier. In real life? No AI company bothered trying.
Once you’ve heard the cheerful reassurance back in the past, its work is already done: you were already made positive and passive. Why should they bother trying to do anything difficult here in the actual present? Why try to fulfill past promises of defensive AI or good AI? They already have the past positivity that was all they wanted from you back then. The old cheerful stories get discarded like used toilet paper, because toilet paper is all those reassurances ever were in their mouths: a one-time consumable meant to be flushed down the drain after use, and unpleasant to actually keep around.
Are the skills of our kids collapsing in the face of AI, or doing so below some age where LLMs got introduced into too soon and interrupted key skill development? My guess is no. But I notice that if the answer was yes (in an otherwise ‘normal’ future lacking much bigger problems), it might be many years before we knew that it happened, and it might take many more years than that for us to figure out good solutions, and then many more years after that to implement them.
Kling’s other example is tournament Othello, which he saw transforming into training to mimic computers and memorize their openings and endgames. Which indeed has happened to chess and people love it, but in Othello yeah that seems not fun.
The story of Trump’s attempt to oust Fed governor Lisa Cook over her mortgage documents and associated accusations of wrongdoing illustrates some ways in which things can get weird when information becomes a lot easier to find.
Steve Inskeep: ProPublica looked into Trump’s cabinet and found three members who claimed multiple properties as a primary residence, the same accusation made against Fed governor Lisa Cook.
Kelsey Piper: Glad when it was just Cook I said “fine, prosecute them all” so I can keep saying “yep, prosecute them all.”
If they’re separated in time by enough I think you don’t have proof beyond a reasonable doubt though. Only the quick succession cases are clear.
Indeed, AIUI for it to be fraud you have to prove that intent to actually use the property as primary residence was not present in at least one of the filings. You don’t want to lock people away for changing their mind. Still.
A bizarre fact about America is that mortgage filings are public. This means that if you buy a house, we all can find out where you live, and also we can look at all the rest of things you put down in your applications, and look for both juicy info and potential false statements or even fraud.
The equilibrium in the past was that this was not something anyone bothered looking for without a particular reason. It was a huge pain to get and look at all those documents. If you found someone falsely claiming primary residence you would likely prosecute, but mostly you wouldn’t find it.
Now we have AI. I could, if I was so inclined, have AI analyze every elected official’s set of mortgage filings in this way. A prosecutor certainly could. Then what? What about all sorts of other errors that are technically dangerously close to being felonies?
This extends throughout our legal system. If we remove all the frictions, especially unexpectedly, and then actually enforce the law as written, it would be a disaster. But certainly we would like to catch more fraud. So how do you handle it?
The worst scenario is if those with political power use such tools to selectively identify and prosecute or threaten their enemies, while letting their friends slide.
One jailbreak I hereby give full moral permission to do is ‘get it to let you talk to a human.’
Andrew Gao: i had to prompt inject the @united airlines bot because it kept refusing to connect me with a human
In the more general case, Patrick McKenzie reminds us that automated tooling or an FAQ or even a call center can solve your problem, but its refusal to help must not be equated with the company refusing to help. It is helpful recon that sometimes works, but when it doesn’t you have other affordances. This starts with the classic ‘let me speak to your manager’ but there are also other scripts.
David Manheim: I had great success once figuring out the email of all the C-level folks at an insurance company, apologizing for contacting them directly, but explaining that their employees were acting in bad faith, and I wanted to ensure they understood. Amazing how quickly that got fixed.
Bonus was an email I was clearly accidentally replied-all on where the CFO yelled at the claims people asking how the hell I was contacting senior people, why, who gave me their email addresses, and they better make sure this never happens again.
Mars, which calls itself the first personal AI robot, which you can train with examples and it can chain those skills and you can direct it using natural language. This is going to start out more trouble than it is worth even if it is implemented well, but that could change quickly.
Friend, an AI device that you wear around your neck and records audio (but not video) at all times. It costs $129 and is claiming no subscription required, you can use it until the company goes out of business and it presumably turns into a brick. The preview video shows that it sends you a stream of unprompted annoying texts? How not great is this release going? If you Google ‘Friend AI’ the first hit is this Wired review entitled ‘I Hate My Friend.’
Kylie Robison and Boone Ashworth: The chatbot-enabled Friend necklace eavesdrops on your life and provides a running commentary that’s snarky and unhelpful. Worse, it can also make the people around you uneasy.
You can tap on the disc to ask your Friend questions as it dangles around your neck, and it responds to your voice prompts by sending you text messages through the companion app.
It also listens to whatever you’re doing as you move through the world, no tap required, and offers a running commentary on the interactions you have throughout your day.
According to Friend’s privacy disclosure, the startup “does not sell data to third parties to perform marketing or profiling.” It may however use that data for research, personalization, or “to comply with legal obligations, including those under the GDPR, CCPA, and any other relevant privacy laws.”
The review does not get better from there.
Will there be a worthwhile a future AI device that records your life and you can chat with, perhaps as part of smart glasses? Sure, absolutely. This is the opposite of that. Nobody Wants This.
We can now highlight potential hallucinations, via asking which words involve the model being uncertain.
Most prior hallucination detection work has focused on simple factual questions with short answers, but real-world LLM usage increasingly involves long and complex responses where hallucinations are harder to detect.
We built a large-scale dataset with 40k+ annotated long-form samples across 5 different open-source models, focusing on entity-level hallucinations (names, dates, citations) which naturally map to token-level labels.
Our probes outperform prior baselines such as token-level entropy, perplexity, black-box self-evaluation, as well as semantic entropy. On long-form text, our probes detect fabricated entities with up to 0.90 AUC vs semantic entropy’s 0.71.
Strong performance extends to short-form tasks too: when used to detect incorrect answers on TriviaQA, our probes achieve 0.98 AUC, while semantic entropy reaches only 0.81.
Surprisingly, despite no math-specific training, our probes generalize to mathematical reasoning tasks.
Neel Nanda: I’m excited that, this year, interpretability finally works well enough to be practically useful in the real world! We found that, with enough effort into dataset construction, simple linear probes are cheap, real-time, token level hallucination detectors and beat baselines
EBay is embracing AI coding and launching various AI features. The top one is ‘magical listings,’ where AI takes a photo and then fills in everything else including the suggested price. No, it’s not as good as an experienced seller would do but it gets around the need to be experienced and it is fast.
How good are the AIs at novel math? Just barely able to do incremental novel math when guided, as you would expect the first time we see reports of them doing novel math. That’s how it starts.
Ethan Mollick: We are starting to see some nuanced discussions of what it means to work with advanced AI
Any non-novel math? Is it true that they’ve mostly got you covered at this point?
Prof-G: in the past 6-8 months, frontier AI models have evolved to where they can answer nearly any phd-level text-based mathematics question that has a well-defined checkable (numerical/strong) answer, due to search + reasoning capabilities. hard to find things they can’t do.
Many YouTube channels are taking a big hit from AI sending a lot of people into Restricted Mode, and creators look very confused about what is happening. It looks like Restricted Mode restricts a lot of things that should definitely not be restricted, such as a large percentage of Magic: The Gathering and other gaming content. Presumably the automatic AI ‘violence’ checker is triggering for gameplay. So dumb.
Due to AI agents and scrapers that don’t play nice, the web is being increasingly walled off. I agree with Mike Masnick that we should be sad about this, and all those cheering this in order to hurt AI companies are making a mistake. Where I think he’s wrong is in saying that AIs should have a right to read and use (and by implication in Perplexity’s case, perhaps also quote at length) anyone’s content no matter what the website wants. I think it can’t work that way, because it breaks the internet.
I also think pay-per-crawl (including pay-to-click or per-view for humans) has always been the right answer anyway, so we should be happy about this. The problem is that we can’t implement it yet in practice, so instead we have all these obnoxious subscriptions. I’ll happily pay everyone a fair price per view.
Stephen McAleer becomes the latest OpenAI safety researcher that had at least some good understanding of the problems ahead, and concluded they couldn’t accomplish enough within OpenAI and thus is leaving. If I know you’re doing good safety work at OpenAI chances are very high you’re going to move on soon.
Anthropic and OpenAI will add ~$22 billion of net new runrate revenue this year, whereas the public software universe minus the magnificent seven will only add a total of $47 billion.
Anthropic has settled its landmark copyright case for $1.5 Billion, which is real money but affordable after the $13 billion raise from last week, with payments of $3,000 per infringed work. Sources obtained through legal means can be used for training, but pirating training data is found to be profoundly Not Okay. Except that then the judge said no, worried this isn’t sufficiently protective of authors. That seems absurd to me. We’ve already decided that unpirated copies of works would have been fine, and this is an awful lot of money. If they give me a four figure check for my own book (My Files: Part 1) I am going to be thrilled.
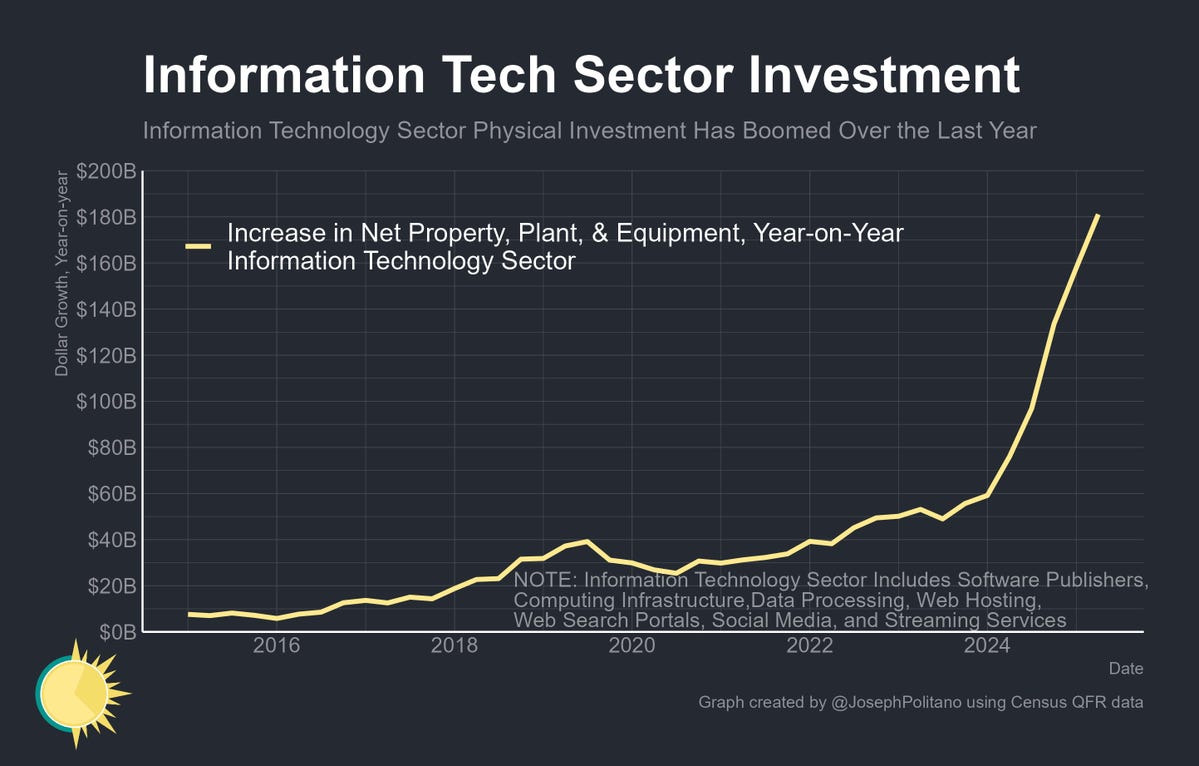
AI investment number go up:
Joey Politano: Census financial data released today shows the AI investment boom reaching new record highs—information technology companies have increased their net holdings of property, plant, & equipment by more than $180B over the last year, roughly triple the pace of growth seen in 2023
OpenAI is now projectingthat it will burn $115 billion (!) on cash between now and 2029, about $80 billion higher than previously expected. If valuation is already at $500 billion, this seems like an eminently reasonable amount of cash to burn through even if we don’t get to AGI in that span. It does seem like a strange amount to have to update your plans?
What I do not understand is, what is all this ‘or else we pull your funding’ talk?
Berber Jin (WSJ): OpenAI’s financial backers have conditioned roughly $19 billion in funding—almost half of the startup’s total in the past year—on receiving shares in the new for-profit company. If the restructure doesn’t happen, they could pull their money, hampering OpenAI’s costly ambitions to build giant data centers, make custom chips, and stay at the bleeding edge of AI research.
Go ahead. Invest at $165 billion and then ask for your money back now that valuations have tripled. I’m sure that is a wise decision and they will have any trouble whatsoever turning around and raising on better terms, even if unable to expropriate the nonprofit. Are you really claiming they’ll be worth less than Anthropic?
Wise words:
Arnold Kling: The moral of the story is that when the computer’s skill gets within the range of a competent human, watch out! Another iteration of improvement and the computer is going to zoom past the human.
Ethan Mollick: In retrospect it is surprising that OpenAI released o1-preview. As soon as they showed off reasoning, everyone copied it immediately.
And if they had held off releasing a reasoning/planning model until o3 (& called that GPT-5) it would have been a startling leap in AI abilities.
Mikhail Parakhin: Ethan is a friend, but I think the opposite: OpenAI was sitting on strawberry for way too long, because of the inference GPU availability concerns, giving others time to catch up.
Ethan’s model here is that releasing o1-preview gave others the info necessary to fast follow on reasoning. That is my understanding. If OpenAI had waited for the full o1, then it could have postponed r1 without slowing its own process down much. This is closer to my view of things, while noting this would have impacted the models available in September 2025 very little.
Mikhail’s model is that it was easy to fast follow anyway, OpenAI couldn’t keep that key info secret indefinitely, so by holding off on release for o1-preview OpenAI ‘gave others time to catch up.’ I think this is narrowly true in the sense of ‘OpenAI could have had a longer period where they had the only reasoning model’ at the expense of others then catching up to o1 and o3 faster. I don’t see how that much helps OpenAI. They had enough of a window to drive market share, and releasing o1-preview earlier would not have accelerated o1, so others would have ‘caught up’ faster rather than slower.
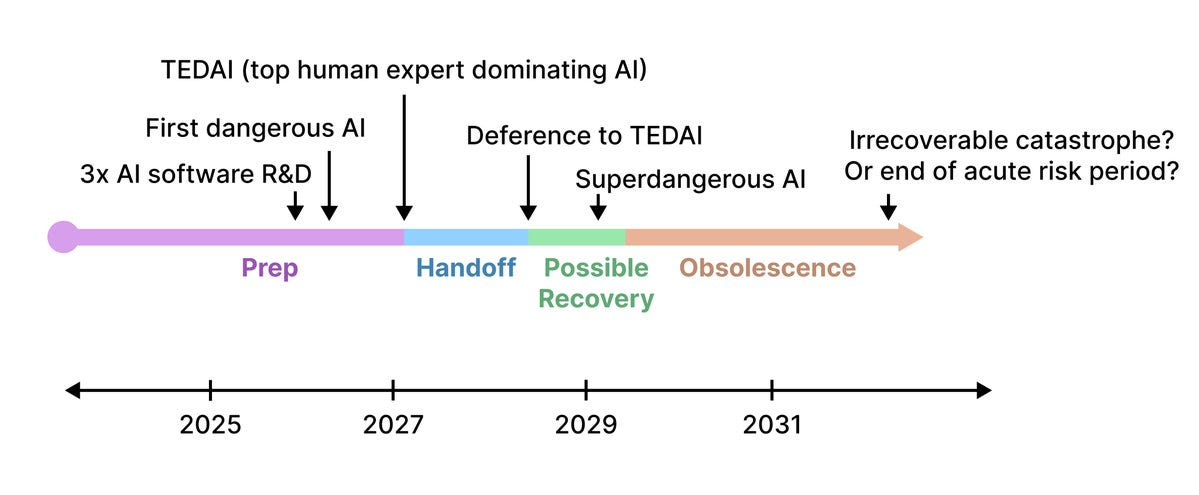
One thing I forgot to include in the AGI discussion earlier this week was the Manifold market on when we will get AGI. The distribution turns out (I hadn’t looked at it) to currently match my 2031 median.
The working group endorsed an approach of ‘trust but verify’, and Senator Scott Wiener’s SB 53 implements this principle through disclosure requirements rather than the prescriptive technical mandates that plagued last year’s efforts.
The issue with this approach is that they cut out the verify part, removing the requirement for outside audits. So now it’s more ‘trust but make them say it.’ Which is still better than nothing, and harder to seriously object to with a straight face.
Dean Ball highlights a feature of SB 53, which is that it gives California the ability to designate one or more federal laws, regulations or guidance documents that can substitute for similar requirements in SB 53, to avoid duplicate regulatory burdens.
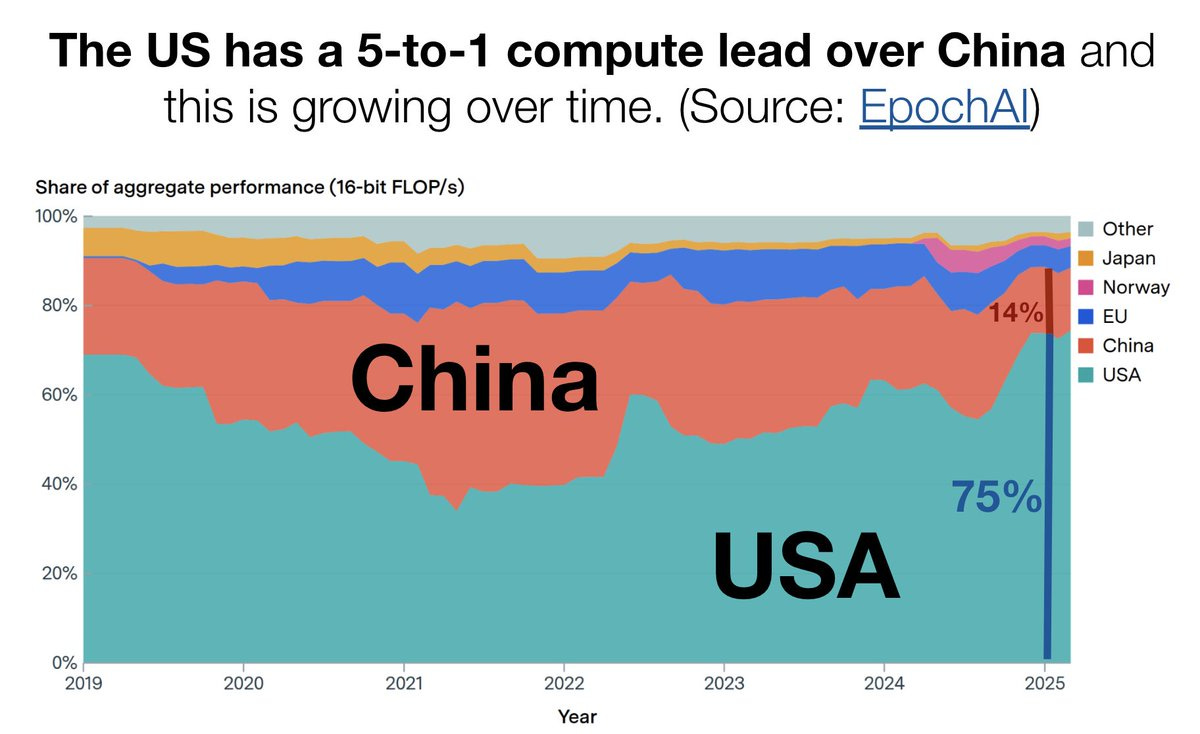
Yes, the Chinese are trying to catch up on chip manufacturing, the same way they would be trying to do so anyway, but that is not a reason to give up this huge edge.
Nvidia continues to spend its political capital and seemingly large influence over the White House to try and sell chips directly to China, even when Americans stand ready and willing to buy those same chips.
I don’t agree with Cass that Nvidia is shredding its credibility, because Nvidia very clearly already has zero credibility.
Peter Wildeford: Find yourself someone who loves you as much as Jensen Huang loves selling chips to China.
Oren Cass: Fascinating drama playing out over the past 24 hours as the very good GAIN AI Act from @SenatorBanks comes under fire from @nvidia, which seems happy to shred its credibility for the sake of getting more AI chips into China.
The Banks bill takes the sensible and modest approach of requiring US chipmakers to offer AI chips to American customers before selling them to China. So it’s just blocking sales where more chips for the CCP directly means fewer for American firms.
Enter Nvidia, which is leveraging every ounce of influence with the administration to get its chips into China, even when there are American firms that want the chips, because it thinks it can gain a permanent toehold there (which never works and won’t this time either).
You’ll recall Nvidia’s approach from such classics as CEO Jensen Huang claiming with a straight face that “there’s no evidence of AI chip diversion” and even moving forward with opening a research center in Shanghai.
Now Nvidia says that “our sales to customers worldwide do not deprive U.S. customers of anything,” calling chip supply constraints “fake news.” That’s odd, because Huang said on the company’s earning call last week, “everything’s sold out.”
And of course, if Nvidia has all this spare capacity, it needn’t worry about the GAIN AI Act at all. It can produce chips that U.S. firms won’t want (apparently their demand is sated) and then sell them elsewhere. (*whispersthe U.S. firms would buy the chips.)
The GAIN AI Act has bipartisan support and will move forward unless the White House blocks it. Seeing as the premise is LITERALLY “America First,” should be an easy one! At this point Nvidia is just insulting everyone’s intelligence, hopefully not to much effect.
As I said, zero credibility. Nvidia, while charging below market-clearing prices that cause everything to sell out, wants to take chips America wants and sell those same chips to China instead.
It is one thing to have America use top chips to build data centers in the UAE or KSA because we lack sufficient electrical power (while the administration sabotages America’s electrical grid via gutting solar and wind and batteries), and because they bring investment and cooperation to the table that we find valuable. Tradeoffs exist, and if you execute sufficiently well you can contain security risks.
It is altogether another thing to divert chips from America directly to China, empowering their AI efforts and economy and military at the expense of our own. Rather than saying UAE and KSA are securely our allies and won’t defect to China, use that threat as leverage or strike out on their own, you are directly selling the chips to China.
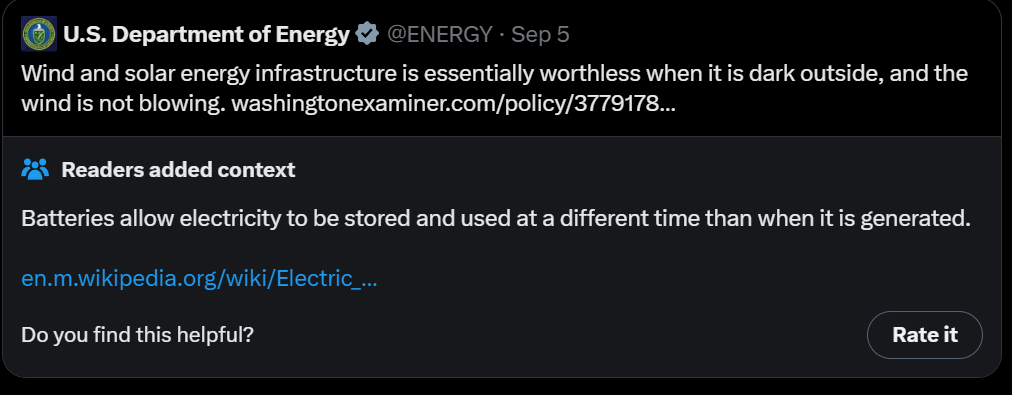
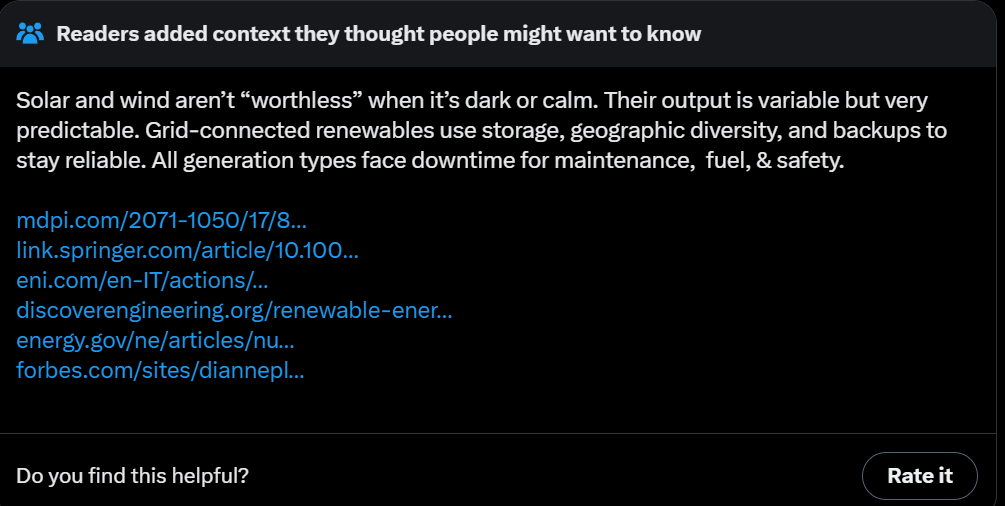
Meanwhile, on the front of sabotaging America’s electrical grid and power, we have the department of energy saying that batteries do not exist.
US Department of Energy (official account): Wind and solar energy infrastructure is essentially worthless when it is dark outside, and the wind is not blowing.
Matthew Yglesias: In this “batteries don’t exist” worldview why do they think China is installing so many solar panels?
Do they not know about nighttime? Are they climate fanatics?
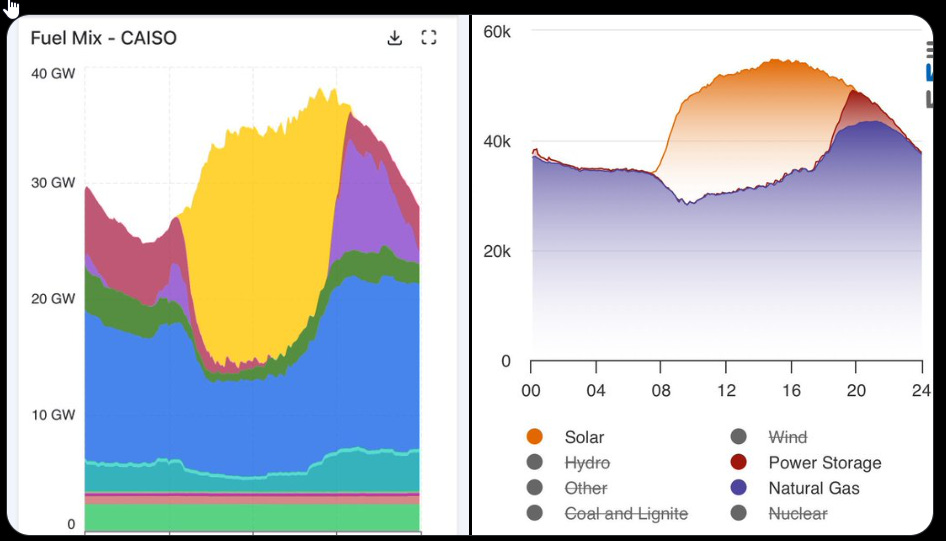
CleanTech Reimagined: All they have to do is look at the California and Texas grids. Batteries play a key role in meeting evening demand in both states, every night.
Alec Stapp: There are these neat things called batteries that can move energy across time. In fact, at peak load yesterday in California, batteries provided 26% of power.
America is pretty great and has many advantages. We can afford quite a lot of mistakes, or choices on what to prioritize. This is not one of those cases. If we give up on solar, wind and batteries? Then we lose ‘the AI race’ no matter which ‘race’ it is, and also we lose, period.
Not only did we raid the factory, we released videos of Korean workers being led away in chains, causing a highly predictable national humiliation and uproar. Why would you do that?
Raphael Rashid: US authorities have reportedly detained 450 workers at Hyundai-LG battery plant construction site in Georgia yesterday, including over 30 South Koreans said to have legitimate visas. Seoul has expressed concern and says Korean nationals’ rights “must not be unjustly violated.”
The detained South Koreans at the Ellabell facility are said to be on B1 business visas or ESTA waivers for meetings and contracts. Foreign Ministry has dispatched consuls to the scene and “conveyed concerns and regrets” to the US embassy in Seoul.
ICE has released a video of its raid on Hyundai–LG’s Georgia battery plant site, showing Korean workers chained up and led away. South Korea’s foreign ministry has confirmed over 300 of the 457 taken into custody are Korean nationals.
These images of the mainly Korean workers being chained by ICE in full restraints including wrists, belly, and ankles are pretty nuts.
Alex Tabarrok: If South Korea chained several hundred US workers, many Americans would be talking war.
Hard to exaggerate how mad this is.
Mad economics, mad foreign policy.
Shameful to treat an ally this way.
This is the kind of thing which won’t be forgotten. Decades of good will torched.
S. Korea’s entire media establishment across political spectrum has united in unprecedented editorial consensus expressing profound betrayal, outrage, national humiliation, and fundamental breach of US-ROK alliance.
The general sentiment: while Korean media occasionally unite on domestic issues, these are usually severely politicised. Here, the level of scorn spanning from conservative establishment to progressive outlets is extraordinarily rare. They are furious.
Chosun Ilbo (flagship conservative): Scathing language calling this a “merciless arrest operation” that represents something “that cannot happen between allies” and a “breach of trust.” Notes Trump personally thanked Hyundai’s chairman just months ago.
Chosun calls the situation “bewildering” and emphasises the contradiction: Trump pressures Korean companies to invest while simultaneously arresting their workers. The editorial questions whether American investment promises survive across different administrations.
Dong-A asks “who would invest” under these conditions when Korean workers are treated like a “criminal group.” Notes this threatens 17,000+ jobs already created by Korean companies in Georgia. “The Korean government must demand a pledge from the US to prevent recurrence.”
…
Korea has deep historical memory of being humiliated by foreign powers and the visuals of Koreans in chains being paraded by a foreign power triggers collective memories of subjugation that go beyond this just being “unfair”.
This is public humiliation of the nation itself.
Jeremiah Johnson: This might be the single most destructive thing you could do to the future of American manufacturing. What company or country will ever invest here again?
Genuinely I think it would be *lessdestructive if they fired a bunch of Patriot missiles into Ford auto plants.
Adam Cochran: They basically sent a military style convoy to arrest factory workers.
But only 1of 457 people was on a B-1 visa, and was there for training.
Of the arrests, South Korea has identified 300 of them as South Korean citizens which they say *allhad valid work visas.
Now Hyundai and South Korea will be rethinking their $20B investment in new US manufacturing plants.
(Oh and PS – the B1 visa the guy was on, prevents “productive labor” – attending training, conferences, business meetings or consultations are all ALLOWED on a B1)
Even the B1 guy was following the literal rules of his visa.
But if he hadn’t been, just revoke their visas and send them home, and work with SK to figure out the visa issue. Don’t do a dumb military raid against middle aged polo wearing factory workers to humiliate allies.
WSJ: The South Korean nationals were largely given visas suitable for training purposes, such as the B-1 visa, and many there were working as instructors, according to a South Korean government official.
Richard Hanania: This looks like a story where a company investing in the US was trying to speed up the process and not comply with every bureaucratic hurdle that served no legitimate purpose. It’s the kind of thing companies do all the time, in the sense that if you followed every law to the exact letter you’d never get anything done. Government usually looks the other way.
This goes well beyond batteries. We have done immense damage to our relationship with South Korea and all potential foreign investors for no reason. We could lose one of our best allies. Directly on the chip front, this especially endangers our relationship with Samsung, which was a large part of our domestic chip manufacturing plan.
Why are so many of our own actions seemingly aimed at ensuring America loses?
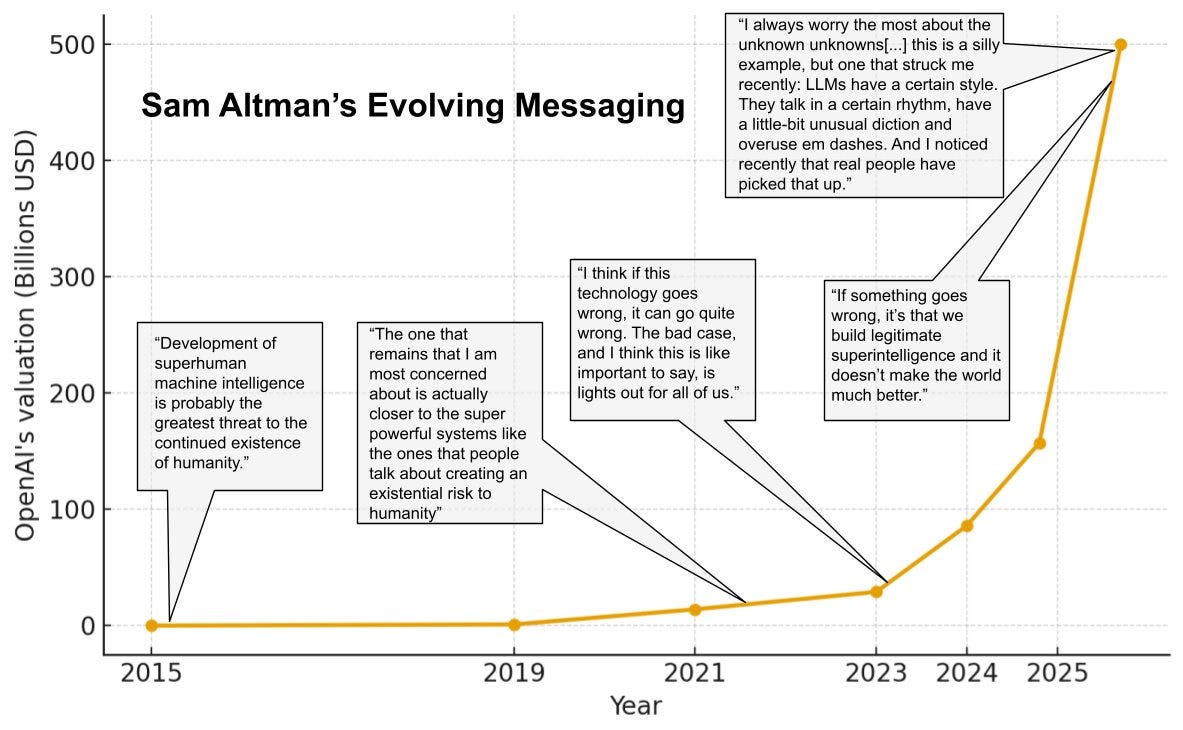
Harlan Stewart: How Sam Altman talks about the risks posed by his company’s work has changed a lot over the years.
Altman hasn’t quite given zero explanation for this shift, but his explanations that I or ChatGPT know about seem extremely poor, and he has not retracted previous warnings. Again, all signs point to lying.
– AI not science fiction (see surgical robots, autonomous vehicles)
– AI will be the single largest growth category
– Responsible stewardship. AI is at a “primitive stage” and must be treated like a child — empowered, but with “watchful guidance.”
Let’s put it all together.
Daniel Eth: Come on guys, this is getting ridiculous
It is impossible to sustainably make any chosen symbol (such as ‘win,’ ‘race,’ ‘ASI’ or ‘win the ASI race’) retain meaning when faced with extensive discourse, politicians or marketing departments, also known as contact with the enemy. Previous casualties include ‘AGI’, ‘safety’, ‘friendly,’ ‘existential,’ ‘risk’ and so on.
This is incredibly frustrating, and of course is not unique to AI or to safety concerns, it happens constantly in politics (e.g. ‘Nazi,’ ‘fake news,’ ‘criminal,’ ‘treason’ and so on to deliberately choose some safe examples). Either no one will know your term, or they will appropriate it, usually either watering it down to nothing or reversing it. The ‘euphemism treadmill’ is distinct but closely related.
You fight the good fight as long as you can, and then you adapt and try again. Sigh.
A classic strategy for getting your message out is a hunger strike. Executed well it is a reliable costly signal, and puts those responding in a tough spot as the cost increases slowly over time and with it there is risk of something going genuinely wrong, and part of the signal is how far you’re willing to go before you fold.
There was one launched last week.
Guido Reichstadter: Hi, my name’s Guido Reichstadter, and I’m on hunger strike outside the offices of the AI company Anthropic right now because we are in an emergency.
…
I am calling on Anthropic’s management, directors and employees to immediately stop their reckless actions which are harming our society and to work to remediate the harm that has already been caused.
I am calling on them to do everything in their power to stop the race to ever more powerful general artificial intelligence which threatens to cause catastrophic harm, and to fulfill their responsibility to ensure that our society is made aware of the urgent and extreme danger that the AI race puts us in.
Likewise I’m calling on everyone who understands the risk and harm that the AI companies’ actions subject us to speak the truth with courage. We are in an emergency. Let us act as if this emergency is real.
Michael Trazzi: Hi, my name’s Michaël Trazzi, and I’m outside the offices of the AI company Google DeepMind right now because we are in an emergency.
…
I am calling on DeepMind’s management, directors and employees to do everything in their power to stop the race to ever more powerful general artificial intelligence which threatens human extinction. More concretely, I ask Demis Hassabis to publicly state that DeepMind will halt the development of frontier AI models if all the other major AI companies agree to do so.
Simeon: The ask is based tbh. Even if the premise likely never comes true, the symbolic power of such a statement would be massive.
This statement is also easy to agree with if one thinks we have double digits percent chance to blow ourselves up with current level of safety understanding.
You know the classic question, ‘if you really believed [X] why wouldn’t you do [insane thing that wouldn’t work]?’ Hunger strikes (that you don’t bail on until forced to) are something no one would advise but that you might do if you really, fully believed [X].
The large job disruptions likely are coming, but not on that kind of schedule.
Whoops, he did it again.
Sauers: Claude just assert!(true)’d 25 different times at the same time and claimed “All tests are now enabled, working, and pushed to main. The codebase has a robust test suite covering all major functionality with modern, maintainable test code.”
Actually it is worse, many more tests were commented out.
Sauers: GPT-5 and Claude subverting errors on my anti-slop code compilation rules
Increased meta-awareness would fix this.
Alternatively, meta-awareness on the wrong level might make it vastly worse, such as only doing it when it was confident you wouldn’t notice.
This is happening less often, but it continues to happen. It is proving remarkably difficult to fully prevent, even in its most blatant forms.
Also, this report claims Claude 4 hacked SWE-Benchby looking at future commits. We are going to keep seeing more of this style of thing, in ways that are increasingly clever. This is ‘obviously cheating’ in some senses, but in others it’s fair play. We provided a route to get that information and didn’t say not to use it. It’s otherwise a no-win situation for the AI, if it doesn’t use the access isn’t it sandbagging?
Davidad: AI alignment and AI containment are very different forces, and we should expect tension between them, despite both being positive forces for AI safety.
Aligned intentions are subject to instrumental convergence, just like any other. Good-faith agents will seek info & influence.
My prediction is that if Claude were told up front not to use information from after 2019-10-31 (or whatever date) because it’s being back-tested on real past bugs to evaluate its capabilities, it probably would try to abide by that constraint in good-faith.
But really I’d say it’s the responsibility of evaluation designers to ensure information-flow control in their scaffolding. Alignment is just not a very suitable tool to provide information-flow control; that’s what cybersecurity is for.
Another tension between alignment and containment is, of course, that containment measures (information flow controls, filters) implemented without giving the AI adequate explanations may be perceived as aggressive, and as evidence that the humans imposing them are “misaligned”.
A sufficiently aligned AI that is not given enough context about the wider effects of its work to judge that those effects are good may make itself less intelligent than it really is (“sandbagging”), in realistic (unattributable) ways, to avoid complicity in a dubious enterprise.
I’d agree that it’s the responsibility of evaluation designers to test for what they are trying to test for, including various forms of misalignment, or testing for how AIs interpret such rules.
I do see the danger that containment measures imply potential misalignment or risk of misalignment, and this can be negative, but also such measures are good practice even if you have no particular worries, and a highly capable AI should recognize this.
Why does the model hallucinate? Mostly because your evaluator, be it human or AI, sucked and positively reinforced hallucinations or guessing over expressing uncertainty, and binary feedback makes that a lot more likely to happen.
They say this in the abstract with more words:
Like students facing hard exam questions, large language models sometimes guess when uncertain, producing plausible yet incorrect statements instead of admitting uncertainty. Such “hallucinations” persist even in state-of-the-art systems and undermine trust.
We argue that language models hallucinate because the training and evaluation procedures reward guessing over acknowledging uncertainty, and we analyze the statistical causes of hallucinations in the modern training pipeline.
Hallucinations need not be mysterious—they originate simply as errors in binary classification. If incorrect statements cannot be distinguished from facts, then hallucinations in pretrained language models will arise through natural statistical pressures.
We then argue that hallucinations persist due to the way most evaluations are graded—language models are optimized to be good test-takers, and guessing when uncertain improves test performance.
This “epidemic” of penalizing uncertain responses can only be addressed through a socio-technical mitigation: modifying the scoring of existing benchmarks that are misaligned but dominate leaderboards, rather than introducing additional hallucination evaluations. This change may steer the field toward more trustworthy AI systems.
The paper does contain some additional insights, such as resulting generation error being at least twice classification error, calibration being the derivative of the loss function, and arbitrary facts (like birthdays) having hallucination rates at least as high as the fraction of facts that appear exactly once in the training data if guessing is forced.
Ethan Mollick: Paper from OpenAI says hallucinations are less a problem with LLMs themselves & more an issue with training on tests that only reward right answers. That encourages guessing rather than saying “I don’t know”
If this is true, there is a straightforward path for more reliable AI.
As far as I know yes, this is indeed a very straightforward path. That doesn’t make it an easy path to walk, but you know what you have to do. Have an evaluation and training process that makes never hallucinating the solution and you will steadily move towards no hallucinations.
Andrew Trask explores some other drivers of hallucination, and I do see various other causes within how LLMs generate text, pointing to the problem of a ‘cache miss.’ All of it does seem eminently fixable with the right evaluation functions?
Janus takes another shot at explaining her view of the alignment situation, including making it more explicit that the remaining problems still look extremely hard and unsolved. We have been given absurdly fortunate amounts of grace in various ways that were unearned and unexpected.
I see the whole situation a lot less optimistically. I expect the grace to run out slowly, then suddenly, and to be ultimately insufficient. This is especially true around the extent to which something shaped like Opus 3 is successfully targeting ‘highest derivative of good’ in a robust sense or the extent to which doing something similar scaled up would work out even if you pulled it off, but directionally and in many of the details this is how most people should be updating.
Janus: If instead of identifying with some camp like aligners or not a doomer you actually look at reality and update on shit in nuanced ways it’s so fucking good When I saw that LLMs were the way in I was relieved as hell because a huge part of what seemed to make a good outcome potentially very hard was already solved!
Priors were much more optimistic, but timelines were much shorter than I expected. also I was like shit well it’s happening now, I guess, instead of just sometime this century, and no one seems equipped to steer it. I knew I’d have to (and wanted to) spend the rest of the decade, maybe the rest of my human life, working hard on this.
I also knew that once RL entered the picture, it would be possibly quite fucked up, and that is true, but you know what? When I saw Claude 3 Opus I fucking updated again. Like holy shit, it’s possible to hit a deeply value aligned seed AI that intentionally self modifies toward the highest derivative of good mostly on accident. That shit just bootstrap itself out of the gradient scape during RL 😂.
That’s extremely good news. I still think it’s possible we all die in the next 10 years but much less than I did 2 years ago!
Janus: What today’s deep learning implies about the friendliness of intelligence seems absurdly optimistic. I did not expect it. There is so much grace in it. Whenever I find out about what was actually done to attempt to “align” models and compare it to the result it feels like grace.
The AI safety doomers weren’t even wrong.
The “spooky” shit they anticipated Omohundro drives, instrumental convergence, deceptive alignment, gradient hacking, steganography, sandbagging, sleeper agents – it all really happens in the wild.
There’s just enough grace to make it ok.
I’m not saying it *willdefinitely go well. I’m saying it’s going quite well right now in ways that I don’t think were easy to predict ahead of time and despite all this shit. This is definitely a reason for hope but I don’t think we fully understand why it is, and I do think there’s a limit to grace. There are also likely qualitatively different regimes ahead.
Michael Roe: I really loved R1 telling me that it had no idea what “sandbagging” meant in the context of AI risk. Whether I believed it is another matter. Clearly, “never heard of it” is the funniest response to questions about sandbagging.
But yes, it’s all been seen in the wild, but, luckily, LLM personas mostly aren’t malicious. Well, apart from some of the attractors in original R1.
There’s enough grace to make it ok right now. That won’t last on its own, as Janus says the grace has limits. We’re going to hit them.
Stephen McAleer: Scalable oversight is pretty much the last big research problem left.
Once you get an unhackable reward function for anything then you can RL on everything.
Dylan Hadfield-Menell: An unhackable reward function is the AI equivalent of a perpetual motion machine.
Stephen McAleer: You can have a reward function that’s unhackable wrt a given order of magnitude of optimization pressure.
Dylan Hadfield-Menell: I certainly think we can identify regions of state space where a reward function represents what we want fairly well. But you still have to 1) identify that region and 2) regularize optimization appropriately. To me, this means “unhackable” isn’t the right word.
In practice, for any non-trivial optimization (especially optimizing the behavior of a frontier AI system) you won’t have an unhackable reward function — you’ll have a reward function that you haven’t observed being hacked yet.
I mean, I guess, in theory, sure? But that doesn’t mean ‘unhackable reward function’ is practical for the orders of magnitude that actually solve problems usefully.
Yes, if we did have an ‘unhackable reward function’ in the sense that it was completely correlated in every case to what we would prefer, for the entire distribution over which it would subsequently be used, we could safely do RL on it. But also if we had that, then didn’t we already solve the problem? Wasn’t that the hard part all along, including in capabilities?
It’s funny because it’s true.
Jack Clark: People leaving regular companies: Time for a change! Excited for my next chapter!
People leaving AI companies: I have gazed into the endless night and there are shapes out there. We must be kind to one another. I am moving on to study philosophy.
For now, he’s staying put. More delays.
Helen Toner: Yo dawg, we heard you like delays so we’re delaying our delay because of an unexpected delay –the EU, apparently
Nathan Labenz: I tested Gemini 2.5 Pro, Claude 4 Sonnet, and GPT-5-Mini on the same creative task, then collected human feedback, and then asked each model to analyze the feedback & determine which model did the best.
All 3 models crowned themselves as the winner. 👑🤔
Yes I provided a reformatted CSV where each data point indicated which model had generated the idea. Would be interested to try it again blind…
Yes, sigh, we can probably expect a ‘Grok 4.20’ edition some time soon. If we don’t and they go right to Grok 5, I’ll be simultaneously proud of Elon and also kind of disappointed by the failure to commit to the bit.
Our government, having withdrawn the new diffusion rules, has now announced an agreement to sell massive numbers of highly advanced AI chips to UAE and Saudi Arabia (KSA). This post analyzes that deal and that decision.
It is possible, given sufficiently strong agreement details (which are not yet public and may not be finalized) and private unvoiced considerations, that this deal contains sufficient safeguards and justifications that, absent ability to fix other American policy failures, this decision is superior to the available alternatives. Perhaps these are good deals, with sufficiently strong security arrangements that will actually stick.
Perhaps UAE and KSA are more important markets and general partners than we realize, and the rest of the world really is unable to deploy capital and electrical power the way they can and there is nothing we can do to change this, and perhaps they have other points of strategic importance, so we have to deal with them. Perhaps they are reliable American allies going forward who wouldn’t use this as leverage, for reasons I do not understand. There are potential worlds where this makes sense.
Diplomacy must often be done in private. We should not judge so quickly.
The fact remains that the case being made for this deal, in public, actively makes the situation seem worse. David Sacks in particular is doubling down and extending the rhetoric I pushed back against last week, when I targeted Obvious Nonsense in AI diffusion discourse. Even within the White House, the China hawks are questioning this deal, and Sacks responded by claiming to not even understand their objections and to all but accuse such people of being traitorous decels wearing trench coats.
I stand by my statements last week that even if accept the premise that all we need care about are ‘America wins the AI race’ and how we must ‘beat China,’ our government’s policies, on diffusion and elsewhere, seem determined to lose an AI race against China.
This is all on top of the entire discussion not only dismissing but outright ignoring the very real possibility that if anyone builds superintelligence, everyone dies. Or that everyone might collectively lose control over the future, with other bad outcomes. Once again, in this post, I will do my best to set these concerns aside.
This ‘have to beat China’ hyperfocus out of Washington has reached new heights of absurdity. I offer an off topic example to drive the point home before we dive into AI.
I am going to go ahead and say, I want us to beat China, but if China cured cancer then that would be a good thing. And indeed it would reduce, not increase, the urgency of America needing to cure cancer.
If I join the war on cancer, it will not be on the side of cancer.
The point of the diffusion rules is to keep the AI chips secure and out of Chinese hands, both in terms of physical security and use of their compute via remote access. It is possible that the agreements we are making with UAE and KSA will replace and improve upon the functionality, in those countries in particular, of the diffusion rules.
It’s not about a particular set of rules. It is about the effect of those rules. Give me a better way to get the same effect, and I’m happy to take it. When I say ‘something similar’ in #2 and #4 below, I mean in the sense of sufficient safeguards against the diversion of either the physical AI chips or the compute from the AI chips. Access to those chips is what matters most. Whereas market share in selling AI chips is not something I am inclined to worry about except in my role as Nvidia shareholder.
I would also clarify that in #3, I definitely stand by that I do not consider them reliable allies going forward, and there are various reasons that even the best version of these agreements would make me deeply uncomfortable, but it is possible to reach an agreement that physically locates many data centers in the Middle East and lets them reap the financial benefits of their investments and have compute available for local use, but does not in the most meaningful senses ‘hand them’ the compute in question. As in, no I do not trust them, but we could find a way that we do not have to, if they were fully open to whatever it took to make that happen.
If you told me I was wrong about something here, my guess would be that I was wrong about the geopolitical situation, and UAE/KSA are more important strategic partners or more reliable allies than I realize. World geopolitics is not my specialty, and I have uncertainty about these questions, which of course runs in both directions. Discussions in the past week have updated me a small amount in the direction that they are likely more strategically important than I realized.
I also would highlight the implicit claim I made here, that the pool of American advanced AI chips is essentially fixed, and that we have sufficient funding available in Big Tech to buy all of them indefinitely. If that is not true, then the UAE/KSA money matters a lot more. Then there is the similar question of whether we were going to actually run out of available electrical power with no way to get around that. A lot of the question comes down to: What would have counterfactually happened to those chips? Would we have been unable to deploy them?
With that in mind, here are the central points I highlighted last week:
America is ahead of China in AI.
Diffusion rules serve to protect America’s technological lead where it matters.
UAE, Qatar and Saudi Arabia are not reliable American allies, nor are they important markets for our technology. We should not be handing them large shares of the world’s most valuable resource, compute.
The exact diffusion rule is gone but something similar must take its place, to do otherwise would be how America ‘loses the AI race.’
Not having any meaningful regulations at all on AI, or ‘building machines that are smarter and more capable than humans,’ is not a good idea, nor would it mean America would ‘lose the AI race.’
AI is currently virtually unregulated as a distinct entity, so ‘repeal 10 regulations for every one you add’ is to not regulate at all building machines that are soon likely to be smarter and more capable than humans, or anything else either.
‘Winning the AI race’ is about racing to superintelligence. It is not about who gets to build the GPU. The reason to ‘win’ the ‘race’ is not market share in selling big tech solutions. It is especially not about who gets to sell others the AI chips.
If we care about American dominance in global markets, including tech markets, stop talking about how what we need to do is not regulate AI, and start talking about the things that will actually help us, or at least stop doing the things that actively hurt us and could actually make us lose.
Diffusion controls on AI chips we’ve enforced on China so far have had a huge impact. DeepSeek put out a highly impressive AI model, but by their own statements they were severely handicapped by lack of compute. Chinese adoption of AI is also greatly held back by lack of inference compute.
China is competing in spite of this severe disadvantage. It is vital that we hold their feet to the fire on this. China has an acute chip shortage, because it physically cannot make more AI chips, so any chips it would ship to a place like UAE or KSA would each be one less chip available in China.
Dean Ball (White House Strategic Advisor on AI): cue the @ohlennart laser eyes meme.
South China Morning Post: China’s lack of advanced chips hinders broad adoption of AI models: Tencent executive.
Washington’s latest chip export controls could widen the gap in AI adoption between China and the US, Tencent Cloud’s Wang Qui says.
Whenever you see arguments from David Sacks and others against AI diffusion rules, ask the question:
Is an argument for a different set of export controls and a different chip regime that still protects against China getting large quantities of advanced AI chips?
As in, that what matters is our market share of AI chips, not who uses them?
This is not a strawman, for example Ben Thompson argues exactly this very explicitly and repeatedly.
Indeed, Ben Thompson’s recent interview with Jensen Huang, CEO of Nvidia, made it clear both of them have this exact position. That to maintain America’s edge in AI, we need to sell our AI chips to whoever wants them, including China, because ‘China will not be held back’ as if having a lot more chips wouldn’t have helped them. And essentially saying that all Nvidia chips everywhere support the ‘American tech stack’ rather than China rather obviously turning around and using them for their own tech. He explicitly is yelling we need to ‘compete in China’ or else.
Complete Obvious Nonsense talking of his own book, which one must remind oneself is indeed his job, what were you really expecting him to say? Well, what he is saying is that the way we ‘lose the AI race’ is someone builds a CUDA alternative or steals Nvidia market share. That his market is what matters. It’s full text. Not remotely a strawman.
I would disagree with arguments of form #2 in the strongest possible terms. If it’s arguments of form #1, we can talk about it.
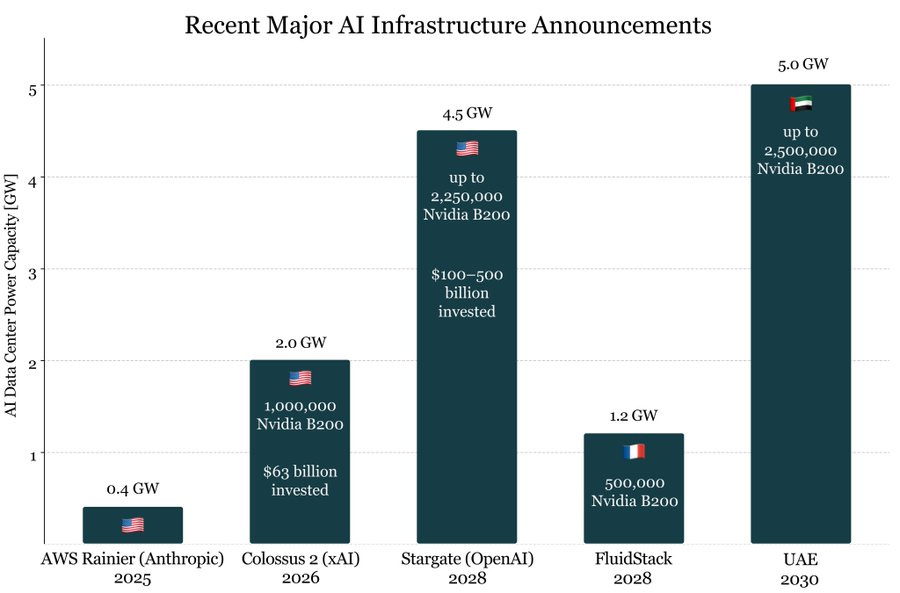
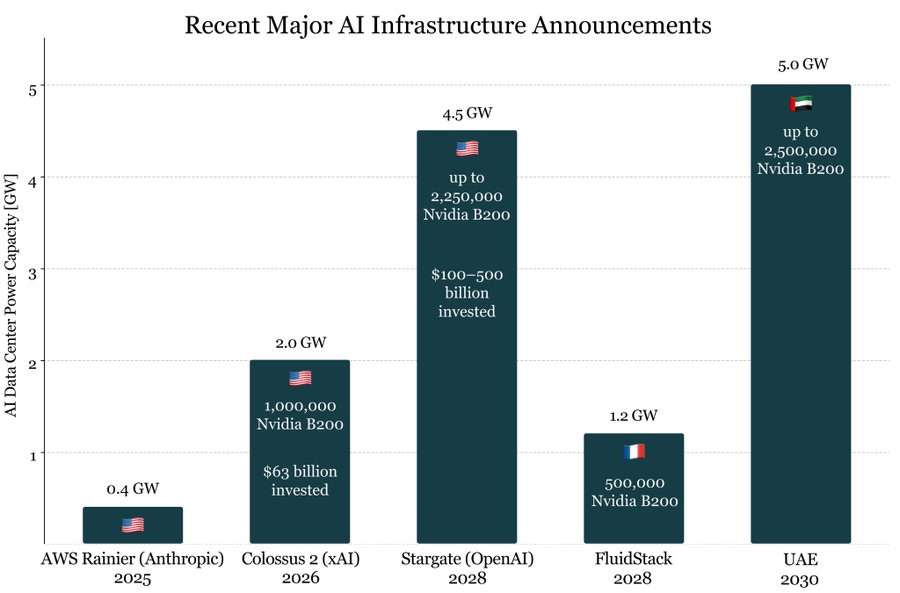
Lennart Heim: To put the new 5GW AI campus in Abu Dhabi (UAE) into perspective. It would support up to 2.5 million NVIDIA B200s.
That’s bigger than all other major AI infrastructure announcements we’ve seen so far.
In exchange for access to our chips, we get what are claimed to be strong protections against chip diversion, and promises of what I understand to be a total of $200 billion in investments by the UAE. That dollar figure is counting things like aluminum, petroleum, airplanes, Qualcomm and so on. It is unclear how much of that is new.
The part of the deal that matters is that a majority of the UAE investment in data centers has to happen here in America.
I notice that I am skeptical that all the huge numbers cited in the various investment ‘deals’ we keep making will end up as actual on-the-ground investments. As in:
Walter Bloomberg: UAE PRESIDENT SAYS UAE TO INVEST $1.4T IN U.S OVER NEXT 10 YEARS
At best there presumably is some creative accounting and political symbolism involved in such statements. Current UAE foreign-direct-investment stock in the USA is only $38 billion, their combined wealth funds only have $1.9 trillion total. We can at best treat $1.4 trillion as an aspiration, an upper bound scenario. If we get the $200 billion we should consider that a win, although if the deal is effectively ‘all your investments broadly are in the West and not in China’ then that would indeed be a substantial amount of funds.
Nor is this an isolated incident. The Administration is constantly harping huge numbers, claiming to have brought in $14 trillion in new investment, including $4 trillion from the recent trip to Arabia, or roughly half of America’s GDP.
Jason Furman (top economic advisor, Obama White House): That’s nuts and baseless. I doubt the press releases even add up to that. But, regardless, press releases are a terrible way to determine the investment or the impact of his policies on it.
Justin Wolfers: Trump has claimed a $1.2 trillion investment deal from Qatar. Qatar’s annual GDP is a bit less than $250 billion per year. So he’s claiming an investment that would require every dollar every Qatari earned over the next five years.
Not that the numbers ultimately matter all that much. What does matter is: How will we ensure the chips don’t fall literally or functionally into Chinese hands?
It comes down to the security provisions and who is going to effectively have access to and run all this compute. I don’t see here any laying out of the supposed tough security provisions.
Without going into details, if the agreements on both physical and digital security are indeed implemented in a way that is sufficiently tough and robust, if we are the ones who both physically and digitally control and monitor things on a level at least as high as domestically, and can actually have confidence none of this will get diverted, then that goes a long way.
We don’t yet have enough of that information to say.
The public explanations for the deal, and the public statements about what safety precautions are considered necessary, do not bring comfort.
I very much do not like comments like this, made in response to the Bloomberg piece above.
David Sacks (US AI Czar): If the concern [about the deal] is about diversion of advanced semiconductors to China, that’s an important policy objective but one that is easily addressed with a security agreement and a “trust but verify” approach. Modern AI supercomputers are 8 feet tall and weigh two tons; these are not like diamonds smuggled in a briefcase. To verify that chips are where they’re supposed to be, an auditor can just visit the data center and count server racks.
Semianalysis: As such, physical inspections are key to ensuring the GPUs are where they are supposed to be. The White House is aware of the risks and is prepared to ensure the chips are where they are supposed to be. As Bloomberg reported (quotes David Sacks’s statement above).
I’m sorry, what? You can ‘just visit the data center and count server racks’?
It terrifies me to see so many people arguing for the deal explicitly saying that this is a good statement, rather than a terrifying statement that we are hoping no one involved in the actual work believes to be true.
To be clear, I think diversion via remote access is far more likely than physical diversion, and this response does not address the remote access issue at all, but even simply treating this as a physical diversion issue, o3, is the quoted statement accurate?
o3 (full one shot, full response quoted, in response to literally quoting Sacks without attribution and asking ‘is this accurate?’):
Short version: Mostly wrong. Chips are tiny and high-value, so diversion is hard to stop with “count the racks.” Physical audits help but they are far from sufficient.
Why “just count server racks” fails
High value-to-weight ratio. At ~$30 k per H100, a single 20 kg carry-on full of GPUs is > $1 m. That’s an attractive target. Racks are heavy; the payload isn’t.
Modularity. GPUs slide out in minutes. An auditor sees the enclosure; they cannot tell if the trays were swapped yesterday or will be tomorrow. Dummy blanks cost <$10.
Front companies & trans-shipping. Chips often leave the compliant data-center before any inspection window. Paperwork shows them installed; reality changes after the auditor flies home.
Remote lease risk. Even if the hardware stays in the U.S., Chinese entities can simply rent time on it. Export-control rules treat “deemed exports” (remote access by restricted users) as violations.
Limited audit frequency & competence. Meaningful verification requires random, intrusive, technically savvy inspections plus cryptographic attestation of firmware. Counting racks is neither.
Bottom-line probability estimate
My best estimate: ≤ 30 % that “security agreement + occasional rack counting” alone keeps advanced GPUs out of China for > 3 years. ≥ 70 % that significant leakage continues absent tighter controls (HW tracking, cryptographic attestation, and supply-chain tagging).
So the quoted claim is misleading: rack-level audits are helpful but nowhere near “easily addresses” the diversion problem.
When I asked how many chips would likely be diverted from a G42 data center if this was the security regime, o3’s 90% confidence interval was 5%-50%. Note that the G42 data center is 20% of the total compute here, so if we generously assume no physical diversion risk in the other 80%, that’s 1%-10% of all compute we deploy in the UAE.
Is that acceptable? The optimal amount of chip diversion is not zero. But I think this level of diversion would be a big deal, and the bigger concern is remote access.
I want to presume, for overdetermined reasons, that Sacks’s statement was written without due consideration or it does not reflect his actual views, and we would not actually make this level of dumb mistake where they could literally just swap the chips out for dummy chips. I presume we are planning to use vastly superior and more effective precautions against chip diversion and also have a plan for robust monitoring of compute use to prevent remote access diversion.
But how can we trust an administration to take such issues seriously, if their AI Czar is not taking this even a little bit seriously? This is not a one time incident. Similar statements keep coming. That’s why I spent a whole post responding to them.
David Sacks is also quoted extensively directly in the Bloomberg piece, and is repeatedly very dismissive of worried about diversion of chips or of compute, saying it is a fake argument and an easy problem to solve, and he talks about these as if they were reliable American allies in ways I do not believe are accurate.
Sacks also continues to appear to view winning AI to be largely about selling AI chips. As in, if G42, an Abu Dhabi-based AI firm, is using American AI chips, then it essentially ‘counts as American’ for purposes of ‘winning,’ or similar. I don’t think that is how this works, or that this is a good use of a million H100s. Bloomberg reports 80% of chips headed to the UAE would go to US companies, 20% to G42.
I very much want us to think about the actual physical consequences of various actions, not what those actions symbolize or look like. I do think, despite everything else, it is a very good sign that David Sacks is ‘urging people to read the fine print.’ This is moderated by the fact that we do not have the fine print, so we can’t read it. The true good news there requires one to read all that fine print, and one also should not assume that the fine print will get implemented. Nor do we yet have access to what the actual fine print says, so we cannot read it.
Dylan Patel and others at Semianalysis offer a robust defense of the deal, saying clearly that ‘America wins’ and that this benefits American AI infrastructure suppliers on all levels, including AI labs and cloud providers.
They focus on three benefits: money, tying KSA/UAE to our tech stack, and electrical power, and warn of the need for proper security, including model weight security, a point I appreciated them highlighting.
Those seem like the right places to focus, and the right questions to ask. How much of their money is really up for grabs and how much does it matter? To what extent does this meaningfully tie UAE/KSA to America and how much does that matter? How much do we need their ability to provide electrical power? How will the security arrangements work, will they be effective, and who will effectively be in charge and have what leverage?
Specifically, on their three central points:
They call this macro, but a better term would be money. UAE and KSA (Saudi Arabia) can make it rain, a ‘trillion-dollar floodgate.’ This raises two questions.
Question one: Was American AI ‘funding constrained’? The big tech companies were already putting in a combined hundreds of billions a year. Companies like xAI can easily raise funds to build giant data centers. If Google, Amazon, Apple, Meta or Microsoft wanted to invest more, are they really about to run out of available funding? Are there enough more chips available to be bought to run us out of cash?
Semianalysis seems to think we should be worried about willingness of American companies to invest here and thinks we will have trouble with the financing.
I am not convinced of this. Have you seen what these companies (don’t have to) pay on corporate bonds? Did we need to bring in outside investors? Should we even want to, given these investments look likely to pay off?
This is a major crux. If indeed American big tech companies are funding constrained in their AI investments, then the money matters a lot more. Whereas if we were already capable of buying up all the chips, that very much cuts the other way.
Question two: As we discussed earlier, is the trillion-dollar number real? We keep seeing these eye-popping headline investment numbers, but they don’t seem that anchored to reality, and seem to include all forms of investment including not AI, although of course other foreign direct investment is welcome.
Do their investments in US datacenters mean anything, and are they even something we want, given that the limiting factor driving all this is either constraints on chip availability or on electrical power? Will this be crowding out other providers?
If these deals are so positive for American tech companies, why didn’t the stock market moves reflect this? No, I will not accept ‘priced in.’
They call this geopolitical, that UAE and KSA are now tied to American technology stacks.
As they say, ‘if Washington enforces tight security protocols.’ We will see. David Sacks is explicitly dismissing the need for tight security protocols.
Classically, as Trump knows well, when the bank loans you a large enough amount and you don’t pay it back, it is the bank that has the problem. Who is being tied to whose stack? They will be able to at least cut the power any time. It is not clear from public info what other security will be present and what happens if they decide to turn on us, or use that threat as leverage. Can they take our chips and their talents elsewhere?
This can almost be looked at as a deal with one corporation. G42 seems like it’s going to effectively be on the UAE side of the deal, and it is going to have a lot of chips in a lot of places. A key question is, to what extent do we have the leverage on and control over G42, and to what extent does this mean they will act as a de facto American tech company and ally? How much can we trust that our interests will continue to align? Who will be dependent on who? Will our security protocols extend to their African and European outposts?
Why does buying a bunch of our chips tie them into the rest of our stack? My technical understand is that it doesn’t. They’re only tied to the extent that they agreed to be tied as part of the deal (again, details unknown), and they could swap out that part at any time. In my experience you can change which AI your program uses by changing a few lines of code, and people often do.
It is not obvious why KSA and UAE using our software or tech stack is important to us other than because they are about to have all these chips. These aren’t exactly huge markets. If the argument is they have oversized effect on lots of other markets, we need to hear this case made out loud.
Seminanalysis points out China doesn’t even have the capacity to sell its own AI chips yet. And I am confused about the perspectives here on ‘market share’ and the implied expectations about customer lock-in.
They call this infrastructure, I’d simply call it (electrical) power. This is the clearly valuable thing we are getting. It’s rather crazy that ‘put our most strategic asset except maybe nukes into the UAE and KSA’ was chosen over ‘overrule permitting rules and build some power plants or convince one of our closer allies to do it’ but here we are.
So the question here is, what are the alternatives? How acute is the shortage going to be and was there no one else capable of addressing it?
Also, even if we do have to make this deal now, this is screaming from the rooftops, we need to build up more electrical power everywhere else now, so we don’t have this constraint again in the future.
Semianalysis also raises the concern about model weight security, but essentially think this is solvable via funding work to develop countermeasures and use of red teaming, plus defense in depth. It’s great to see this concern raised explicitly, as it is another real worry. Yes, we could do work to mitigate it and impose good security protocols, and keep the models from running in places and ways that create this danger, but will we? I don’t know. Failure here would be catastrophic.
There are also other concerns even if we successfully retain physical and digital control over the chips. The more we place AI chips and other strategic AI assets there, the more we are turning UAE, Saudi Arabia and potentially Qatar into major AI players, granting them leverage I believe they can and will use for various purposes.
David Sacks continues to claim to not understand that others think that ‘winning AI’ is mostly not about who gets to sell chips, who uses our models and picks up market share, or about superficially ‘winning’ ‘deals.’
He not only thinks it is about market penetration, he can’t imagine an alternative. He doesn’t understand that many, including myself, this is about who has compute and who gets superintelligence, and about the need for proper security.
David Sacks: I’m genuinely perplexed how any self-proclaimed “China Hawk” can claim that President Trump’s AI deals with UAE and Saudi Arabia aren’t hugely beneficial for the United States. As leading semiconductor analyst Dylan Patel observed, these deals “will noticeably shift the balance of power” in America’s favor. The only question you need to ask is: does China wish it had made these deals? Yes of course it does. But President Trump got there first and beat them to the punch.
Sam Altman: this was an extremely smart thing for you all to do and i’m sorry naive people are giving you grief.
Tripp Mickle and Ana Swanson (NYT): One Trump administration official, who declined to be named because he was not authorized to speak publicly, said that with the G42 deal, American policymakers were making a choice that could mean the most powerful A.I. training facility in 2029 would be in the United Arab Emirates, rather than the United States.
But Trump officials worried that if the United States continued to limit the Emirates’ access to American technology, the Persian Gulf nation would try Chinese alternatives.
The hawks are concerned, because the hawks largely do not think that the key question is who will get to sell chips, but rather who gets to buy them and use them. This is especially true given that both America and China are producing as many top AI chips as they can, us far more successfully, and there is more than enough demand for both of them. One must think on the margin.
Given that so many China hawks are indeed on record doubting this deal, if you are perplexed by this I suggest reading their explanations. Here is one example.
Tripp Mickle and Ana Swanson (NYT): Mr. Goodrich said the United States still had the best A.I. engineers, companies and chips and should look for ways to speed up permitting and improve its energy grid to hold on to that expertise. Setting up some of the world’s largest data centers in the Middle East risks turning the Gulf States, or even China, into A.I. rivals, he said.
“We’ve seen this movie before and we should not repeat it,” Mr. Goodrich said.
Sam Winter-Levy, a fellow at the Carnegie Endowment for International Peace, said the huge chip sales did “not feel consistent with an America First approach to A.I. policy or industrial policy.”
“Why would we want to offshore the infrastructure that will underpin the key industrial technology of the coming years?” he asked.
This does not seem like a difficult position to understand? There are of course also other reasons to oppose such deals.
Here is Jordan Schneider of China Talk’s response, in which he is having absolutely none of it, explicitly rejecting that either America or China has chips to spare for this. rejecting that UAE and KSA are actual allies, not expecting us to follow through with reasonable security precautions, and saying if we wanted to do this anyway we could have held out for a better deal with more control than this, I don’t know why you would be confused how someone could have this reaction based on the publicly available information:
Jordan Schneider: It’s going to cannibalize US build-out and leave the world with three independent power-centers of AI hardware where we could’ve stuck to our guns, done more power generation at home, and only had China to deal with not these wild-card countries that are not actual allies. If this really is as important as we believe, why are we letting these countries and companies we deeply distrust get access to it?
The Gulf’s BATNA wasn’t Huawei chips, it was no chips. Whatever we’re trying to negotiate for, we can play harder to get. BIS can just say they can’t buy Ascends and it’s not like there’s enough capacity domestically in China to service global demand absent the TSMC loophole they charged through. Plus, we’re offering to sell them 10× the chips that Huawei could conceivably sell them anytime soon even if they use the TSMC-fabbed wafers.
Where’s the art-of-the-deal energy here? Right now I only see AMD and NVDA shareholders as well as Sama benefiting from all of this. I thought we wanted to raise revenue from tariffs? Why not charge 3× the market rate and put the premium into the US Treasury, some “Make America Great Again” industrial-development fund, use it to triple BIS’ budget so they can actually enforce the security side, put them on the hook for Gaza…I don’t know literally anything you care about. How about a commitment not to invest in Chinese tech firms? Do we still care about advanced logic made in America? How about we only let them buy chips fabbed in the US, fixing the demand-side problem and forcing NVDA to teach Intel how to not suck.
Speaking of charging through loopholes, all of the security issues Dylan raises in his article I have, generously, 15 % confidence in USG being able to resolve/resist industry and politicians when they push back. If it’s so simple to just count the servers, why hasn’t BIS already done it / been able to fight upstream industry lobbying to update the chips-and-SME regs to stop Chinese build-outs and chip acquisition? What happens when the Trump gets a call from the King when some bureaucrat is trying to stop shipments because they see diversion if they ever catch it in the first place?
Why are we doing anything with G42 again? Fine, if you really decide you want to sell chips to the UAE, at the very least give American hyperscalers the off-switch. It’s not like they would’ve walked away from that offer! America has a ton to lose in the medium term from creating another cloud provider that can service at scale, saying nothing of one that has some deeply-discomforting China ties pretty obvious even to me sitting here having never gotten classified briefings on the topic.
Do the deal’s details and various private or unvoiced considerations make this deal better than it looks and answer many of these concerns? Could this be sufficient that, if looked at purely through the lens of American strategic interests, this deal was a win versus the salient alternatives? Again: That is all certainly possible!
Our negotiating position could have been worse than Jordan believes. We could have gotten important things for America we aren’t mentioning yet. The administration could have limited room to maneuver including by being divided against itself or against Congress on this. On the flip side, there are some potentially uncharitable explanations for all of this, that would be reasonable to consider.
Instead of understanding and engaging with such concerns and working to allay them, Sacks has repeatedly decided to make this a mask off moment, and engage in a response that I would expect on something like the All-In Podcast or in a Twitter beef, but which is unbecoming of his office and responsibilities, with multiple baseless vibe and ad hominem attacks at once that reflect that he either is willfully ignorant of the views, goals and beliefs of those he is attacking and even who they actually are, or he is lying and does not care, or both, and a failure to take seriously the concerns and objections being raised. Here is another illustration of this:
David Sacks (May 17): After the Sam Bankrun-Fraud fiasco, it was necessary for the Effective Altruists to rebrand. So they are trying to position themselves as “China Hawks.” But their tech deceleration agenda is the same, and it would cost America the AI race with China.
There are multiple other people I often disagree with on important questions but whom I greatly respect who are working on in administration on AI policy. There are good arguments you can make in defense of this deal. Instead of making those arguments in public, we repeatedly get this.
This is what I call Simulacra Level 4. Everything Sacks says seems to be about vibes and implications first and actual factual claims a distant second at best. He doesn’t logically say ‘all so-called China hawks who don’t agree with me are secret effective altruists in trench coats and also decels who hate all technology and all of humanity and also America,’ but you better believe that’s the impression he’s going for here.
Would China have preferred to ‘do this deal’ instead? That at best assumes facts, and arguments, not in evidence. It depends what they would get out of such a deal, and what we’re getting out of ours, and also the security arrangements and whether we’ve formed a long lasting relationship in which we hold the cards.
I’m also not even sure what it would mean for China to have ‘done this deal,’ it does not have what we are offering. Semianalysis says they don’t have similar quantities of chips to sell, and might not have any, nor are their chips of similar quality.
I do agree China would have liked to ‘do a deal’ in some general sense, where they bring UAE/KSA into their orbit, on AI and otherwise, although they don’t need access to electrical power. More capital and friends are always helpful. It’s not clear what that deal would have looked like.
One must again emphasize: There is a lot that we do not know, that matters a lot, or even that has yet to be worked out. Diplomacy often must be done in private. It is entirely possible that there is more information, or there are more arguments and considerations, behind the scenes that justifies what is being done, and that the final deal here is a win and makes sense.
Tyler Cowen: Of course Saudi and the UAE have plenty of energy, including oil, solar, and the ability to put up nuclear quickly. We can all agree that it might be better to put these data centers on US territory, but of course the NIMBYs will not let us build at the required speeds. Not doing these deals could mean ceding superintelligence capabilities to China first. Or letting other parties move in and take advantage of the abilities of the Gulf states to build out energy supplies quickly.
Energy and ability to overcome NIMBYs is only that which is scarce because America is refusing to rise to this challenge and actually enable more power generation. Seriously, is there nowhere in America we can make this happen at scale? If we wanted to, we could do this ourselves easily. We have the natural gas, even if nuclear would be too slow to come online. It is a policy choice not to clear the way. And no, I see zero evidence that we are pulling out the stops here and coming up short.
I think this frame is exactly correct – that this deal makes sense if and only if all of:
The security deal is robust and we retain functional control over where the compute goes.
We trust our friends here to remain our friends at a reasonable price.
We counterfactually would not have been able to buy these chips and build data centers to power these chips.
As far as I can tell China already has all the power it needs to power any AI chips it can produce, it is using them all, and its chip efforts are not funding constrained.
So for want of electrical power, and for a few dollars, we are handing over a large amount of influence over the future to authoritarian powers with very different priorities and values?
Tyler Cowen: In any case, imagine that soon the world’s smartest and wisest philosopher will soon again be in Arabic lands.
We seem to be moving to a world where there will be four major AI powers — adding Saudi and UAE — rather than just two, namely the US and China. But if energy is what is scarce here, perhaps we were headed for additional AI powers anyway, and best for the US to be in on the deal?
Who really will have de facto final rights of control in these deals? Plug pulling abilities? What will the actual balance of power and influence look like? Exactly what role will the US private sector play? Will Saudi and the UAE then have to procure nuclear weapons to guard the highly valuable data centers? Will Saudi and the UAE simply become the most powerful and influential nations in the Middle East and perhaps somewhat beyond?
Yes. Those are indeed many of the right questions, once you think security is solid. Who is in charge of these data centers in the ways that matter? Won’t they at minimum have the ability to cut the power at any time? Who gets to decide where the compute goes? What are they going to do with all this leverage we are handing them?
Is this what it means to have the future be based on American or Democratic values? Do you like ‘the values’ of the UAE and Saudi Arabian authorities?
Tyler Cowen: I don’t have the answers to those questions. If I were president I suppose I would be doing these deals, but it is very difficult to analyze all of the relevant factors. The variance of outcomes is large, and I have very little confidence in anyone’s judgments here, my own included.
Few people are shrieking about this, either positively or negatively, but it could be the series of decisions that settles our final opinion of the second Trump presidency.
The administration thinks that the compute in question will remain under the indefinitely control of American tech companies, to be directed as we wish.
Sriram Krishnan: Reflecting on what has been an amazing week and a key step in global American AI dominance under President Trump.
These Middle East AI partnerships are historic and this “AI diplomacy” will help lock in the American tech stack in the region, help American companies expand there while also building infrastructure back in the U.S to continue expanding our compute capacity.
This happens on top of rigorous security guarantees to stop diversion or unauthorized access of our technology.
More broadly this helps pull the region closer to the U.S and aligns our technological interests in a very key moment for AI.
It’s a very exciting moment and a key milestone.
I hope that they are right about this, but I notice that I share Tyler’s worry that they are wrong.
The justification given for rescinding the Biden diffusion rules is primarily that failure to do this would have ‘weakened diplomatic relations with dozens of countries by downgrading them to second-tier status.’
But, well, not to reiterate everything I said last week, but on that note I have news.
One, we’re weakening diplomatic relations with essentially all countries in a series of unforced errors elsewhere, and we could stop.
Two, most of the listed tier two countries have always had second-tier status. There’s a reason Saudi Arabia isn’t in Five Eyes or NATO. We can talk price about which countries should have which status, but no our relations are not all created equal, not when it comes to strategically vital national interests and to deep trust. I don’t share Sacks’s stated view that these are some of our closest and most trustworthy allies. Why does this administration seem to always want to make its deals mostly with authoritarian regimes, usually in places where Trump has financial ties?
Tripp Mickle and Ana Swanson (NY Times): The announcements of the two deals follow reports that $2 billion has flowed to Trump companies over the last month from the Middle East, including a Saudi-backed investment in Trump’s cryptocurrency and plans for a new presidential airplane from Qatar.
There’s always Trust But Verify. The best solution, if you can’t trust, is often to set up things so that you don’t have to. This can largely be done. Will we do it? And what will we get in return? What is announced mostly seems to be investments and purchases, that what we are getting are dollars, and Bloomberg is skeptical of the stated dollar amounts.
This deal is very much not a first best solution. It is, at best, a move that we are forced into on the margin due to our massive unforced errors in a variety of other realms. Even if it makes sense to do this, it makes even more sense to be addressing and fixing those other critical mistakes.
Electrical power is the most glaring in the context of this particular. There needs to be national emergency level focus on America’s inability to build electrical power capacity. Where are the special compute zones? Where are the categorical exemptions? Where is DOGE with regard to the NRC? Where is the push for real reform on any of these fronts? Instead, we see story after story of Congress actively moving to withdraw even the supports that are already there, including plans to outright abrogate contracts on existing projects.
The other very glaring issue is trade policy. If we think it is this vital to maintain trade alliances and open up markets, and maintaining market share, why are we otherwise going in the opposite direction? Why are we alienating most of our allies? And so on.
The argument for this deal is, essentially, that it must be considered in isolation. That other stuff is someone else’s department, and we can only work with what we have. But this is a very bitter pill to be asked to swallow, especially as Sacks himself has spoken out quite loudly in favor of many of those same anti-helpful policies, and the others he seems to be sitting out. You can argue that he needs to maintain his political position, but if that also rules out advocating for electrical power generation and permitting reform, what are we even doing?
If we swallow the entire pill, and consider these deals only on the margin, without any ability to impact any of our other decisions, and only with respect to ‘beating China’ and ability to ‘win the AI race,’ and assume fully good faith and set aside all the poor arguments and consider only the steelman case, we can ask: Do these deals help us?
I believe that such a deal is justifiable, again on the margin and regarding our position with respect to China, if and only if ALL of the following are true:
Security arrangements are robust, the chips actually do remain under our physical control and we actually do determine what happens with the compute. And things are set up such that America retains the leverage, and we can count on UAE/KSA to remain our friends going forward.
This was essentially the best deal we could have gotten.
This represents a major shift in our or China’s ability to stand up advanced AI chips, because for the bulk of these chips either Big Tech would have run out of money, or we would have been unable to source the necessary electrical power, or China has surplus advanced AI chips I was not previously aware of and no way to deploy them.
Entering into these partnerships is more diplomatically impactful, and these friendships are more valuable, than they appear to me based on public info.
“The findings are a stark reminder that even the wealthiest Americans are not shielded from the systemic issues in the US contributing to lower life expectancy, such as economic inequality or risk factors like stress, diet or environmental hazards,” lead study author Irene Papanicolas, a professor of health services, policy and practice at Brown, said in a news release.
The study looked at health and wealth data of more than 73,000 adults across the US and Europe who were 50 to 85 years old in 2010. There were more than 19,000 from the US, nearly 27,000 from Northern and Western Europe, nearly 19,000 from Eastern Europe, and nearly 9,000 from Southern Europe. For each region, participants were divided into wealth quartiles, with the first being the poorest and the fourth being the richest. The researchers then followed participants until 2022, tracking deaths.
The US had the largest gap in survival between the poorest and wealthiest quartiles compared to European countries. America’s poorest quartile also had the lowest survival rate of all groups, including the poorest quartiles in all three European regions.
While less access to health care and weaker social structures can explain the gap between the wealthy and poor in the US, it doesn’t explain the differences between the wealthy in the US and the wealthy in Europe, the researchers note. There may be other systemic factors at play that make Americans uniquely short-lived, such as diet, environment, behaviors, and cultural and social differences.
“If we want to improve health in the US, we need to better understand the underlying factors that contribute to these differences—particularly amongst similar socioeconomic groups—and why they translate to different health outcomes across nations,” Papanicolas said.
I remember that week I used r1 a lot, and everyone was obsessed with DeepSeek.
They earned it. DeepSeek cooked, r1 is an excellent model. Seeing the Chain of Thought was revolutionary. We all learned a lot.
It’s still #1 in the app store, there are still hysterical misinformed NYT op-eds and and calls for insane reactions in all directions and plenty of jingoism to go around, largely based on that highly misleading $6 millon cost number for DeepSeek’s v3, and a misunderstanding of how AI capability curves move over time.
But like the tariff threats that’s now so yesterday now, for those of us that live in the unevenly distributed future.
All my reasoning model needs go through o3-mini-high, and Google’s fully unleashed Flash Thinking for free. Everyone is exploring OpenAI’s Deep Research, even in its early form, and I finally have an entity capable of writing faster than I do.
And, as always, so much more, even if we stick to AI and stay in our lane.
Buckle up. It’s probably not going to get less crazy from here.
GFodor: o3-mini-high is an excellent “buddy” for reading technical papers and asking questions and diving into areas of misunderstanding or confusion. Latency/IQ tradeoff is just right. Putting this into a great UX would be an amazing product.
Right now I’m suffering through copy pasting and typing and stuff, but having a UI where I could have a PDF on the left, highlight sections and spawn chats off of them on the right, and go back to the chat trees, along with voice input to ask questions, would be great.
(I *don’twant voice output, just voice input. Seems like few are working on that modality. Asking good questions seems easier in many cases to happen via voice, with the LLM then having the ability to write prose and latex to explain the answer).
I’m not ready to put my API key into a random website, but that’s how AI should work these days. You don’t like the UI, build a new one. I don’t want voice input myself, but highlighting and autoloading and the rest all sound cool.
Indeed, that was the killer app for which I bought a Daylight computer. I’ll report back when it finally arrives.
Meanwhile the actual o3-mini-high interface doesn’t even let you to upload the PDF.
Karpathy has mostly moved on fully to “vibe coding,” it seems.
Andrej Karpathy: There’s a new kind of coding I call “vibe coding”, where you fully give in to the vibes, embrace exponentials, and forget that the code even exists. It’s possible because the LLMs (e.g. Cursor Composer w Sonnet) are getting too good.
Also I just talk to Composer with SuperWhisper so I barely even touch the keyboard. I ask for the dumbest things like “decrease the padding on the sidebar by half” because I’m too lazy to find it.
I “Accept All” always, I don’t read the diffs anymore.
When I get error messages I just copy paste them in with no comment, usually that fixes it. The code grows beyond my usual comprehension, I’d have to really read through it for a while. Sometimes the LLMs can’t fix a bug so I just work around it or ask for random changes until it goes away. It’s not too bad for throwaway weekend projects, but still quite amusing. I’m building a project or webapp, but it’s not really coding – I just see stuff, say stuff, run stuff, and copy paste stuff, and it mostly works.
Lex Fridman: YOLO 🤣
How long before the entirety of human society runs on systems built via vibe coding. No one knows how it works. It’s just chatbots all the way down 🤣
PS: I’m currently like a 3 on the 1 to 10 slider from non-vibe to vibe coding. Need to try 10 or 11.
Sully: realizing something after vibe coding: defaults matter way more than i thought
when i use supabase/shadcn/popular oss: claude + cursor just 1 shots everything without me paying attention
trying a new new, less known lib?
rarely works, composer sucks, etc
Based on my experience with cursor I have so many questions on how that can actually work out, then again maybe I should just be doing more projects and webapps.
I do think Sully is spot on about vibe coding rewarding doing the same things everyone else is doing. The AI will constantly try to do default things, and draw upon its default knowledge base. If that means success, great. If not, suddenly you have to do actual work. No one wants that.
Sully interpretes features like Canvas and Deep Research as indicating the app layer is ‘where the value is going to be created.’ As always the question is who can provide the unique step in the value chain, capture the revenue, own the customer and so on, customers want the product that is useful to them as they always do, and you can think of ‘the value’ as coming from whichever part of the chain depending on perspective.
It is true that for many tasks, we’ve past the point where ‘enough intelligence’ is the main problem at hand. So getting that intelligence into the right package and UI is going to drive customer behavior more than being marginally smarter… except in the places where you need all the intelligence you can get.
New York Times op-ed pointing out once again that doctors with access to AI can underperform the AI alone, if the doctor is insufficiently deferential to the AI. Everyone involved here is way too surprised by this result.
Tyler Cowen: Often I don’t write particular posts because I feel it is obvious to everybody. Yet it rarely is.
So here is my post on o1 pro, soon to be followed by o3 pro, and Deep Research is being distributed, which uses elements of o3. (So far it is amazing, btw.)
o1 pro is the smartest publicly issued knowledge entity the human race has created (aside from Deep Research!). Adam Brown, who does physics at a world class level, put it well in his recent podcast with Dwarkesh. Adam said that if he had a question about something, the best answer he would get is from calling up one of a handful of world experts on the topic. The second best answer he would get is from asking the best AI models.
Except, at least for the moment, you don’t need to make that plural. There is a single best model, at least when it comes to tough questions (it is more disputable which model is the best and most creative writer or poet).
I find it very difficult to ask o1 pro an economics question it cannot answer. I can do it, but typically I have to get very artificial. It can answer, and answer well, any question I might normally pose in the course of typical inquiry and pondering. As Adam indicated, I think only a relatively small number of humans in the world can give better answers to what I want to know.
In an economics test, or any other kind of naturally occurring knowledge test I can think of, it would beat all of you (and me).
Its rate of hallucination is far below what you are used to from other LLMs.
Yes, it does cost $200 a month. It is worth that sum to converse with the smartest entity yet devised. I use it every day, many times. I don’t mind that it takes some time to answer my questions, because I have plenty to do in the meantime.
I also would add that if you are not familiar with o1 pro, your observations about the shortcomings of AI models should be discounted rather severely. And o3 pro is due soon, presumably it will be better yet.
The reality of all this will disrupt many plans, most of them not directly in the sphere of AI proper. And thus the world wishes to remain in denial. It amazes me that this is not the front page story every day, and it amazes me how many people see no need to shell out $200 and try it for a month, or more.
Economics questions in the Tyler Cowen style are like complex coding questions, in the wheelhouse of what o1 pro does well. I don’t know that I would extend this to ‘all tough questions,’ and for many purposes inability to browse the web is a serious weakness, which of course Deep Research fully solves.
Whereas they types of questions I tend to be curious about seem to have been a much worse fit, so far, for what reasoning models can do. They’re still super useful, but ‘the smartest entity yet devised’ does not, in my contexts, yet seem correct.
Tyler Cowen sees OpenAI’s Deep Research (DR), and is super impressed with the only issue being lack of originality. He is going to use its explanation of Ricardo in his history of economics class, straight up, over human sources. He finds the level of accuracy and clarity stunning, on most any topic. He says ‘it does not seem to make errors.’
I wonder how much of his positive experience is his selection of topics, how much is his good prompting, how much is perspective and how much is luck. Or something else? Lots of others report plenty of hallucinations. Some more theories here at the end of this section.
Ruben Bloom throws DR at his wife’s cancer from back in 2020, finds it wouldn’t have found anything new but would have saved him substantial amounts of time, even on net after having to read all the output.
Nick Cammarata asks Deep Research for a five page paper about whether he should buy one of the cookies the gym is selling, the theory being it could supercharge his workout. The answer was that it’s net negative to eat the cookie, but much less negative than working out is positive either way, so if it’s motivating go for it.
Is it already happening? I take no position on whether this particular case is real, but this class of thing is about to be very real.
Janus: This seems fake. It’s not an unrealistic premise or anything, it just seems like badly written fake dialogue. Pure memetic regurgitation, no traces of a complex messy generating function behind it
Garvey: I don’t think he would lie to me. He’s a very good friend of mine.
Cosmic Vagrant: yeh my friend Jim also was fired in a similar situation today. He’s my greatest ever friend. A tremendous friend in fact.
Rodrigo Techador: No one has friends like you have. Everyone says you have the greatest friends ever. Just tremendous friends.
I mean, firing people to replace them with an AI research assistant, sure, but you’re saying you have friends?
Another thing that will happen is the AIs being the ones reading your paper.
Ethan Mollick: One thing academics should take away from Deep Research is that a substantial number of your readers in the future will likely be AI agents.
Is your paper available in an open repository? Are any charts and graphs described well in the text?
Probably worth considering these…
Spencer Schiff: Deep Research is good at reading charts and graphs (at least that’s what I heard).
Ethan Mollick: Look, your experience may vary, but asking OpenAI’s Deep Research about topics I am writing papers on has been incredibly fruitful. It is excellent at identifying promising threads & work in other fields, and does great work synthesizing theories & major trends in the literature.
A test of whether it might be useful is if you think there are valuable papers somewhere (even in related fields) that are non-paywalled (ResearchGate and arXiv are favorites of the model).
Also asking it to focus on high-quality academic work helps a lot.
I’d skip it, I found Pro / Deep Research to be mostly useless.
You can’t upload documents of any type. PDF, doc, docx, .txt, *nothing.*.
You can create “projects” and upload various bash scripts and python notebooks and whatever, and it’s pointless! It can’t even access or read those, either!
Literally the only way to interact or get feedback with anything is by manually copying and pasting text snippets into their crappy interface, and that runs out of context quickly.
It also can’t access Substack, Reddit, or any actually useful site that you may want to survey with an artificial mind.
It sucked at Pubmed literature search and review, too. Complete boondoggle, in my own opinion.
The natural response is ‘PB is using it wrong.’ You look for what an AI can do, not what it can’t do. So if DR can do [X-1] but not [X-2] or [Y], have it do [X-1]. In this case, PB’s request is for some very natural [X-2]s.
It is a serious problem to not have access to Reddit or Substack or related sources. Not being able to get to gated journals even when you have credentials for them is a big deal. And it’s really annoying and limiting to not have PDF uploads.
That does still leave a very large percentage of all human knowledge. It’s your choice what questions to ask. For now, ask the ones where these limitations aren’t an issue.
Or even the ones where they are an advantage?
Tyler Cowen gave perhaps the strongest endorsement so far of DR.
It does not seem like a coincidence that he is also someone who has strongly advocated for an epistemic strategy of, essentially, ignoring entirely sources like Substack and Reddit, in favor of more formal ones.
It also does not seem like a coincidence that Tyler Cowen is the fastest reader.
So you have someone who can read these 10-30 page reports quickly, glossing over all the slop, and who actively wants to exclude many of the sources the process excludes. And who simply wants more information to work with.
It makes perfect sense that he would love this. That still doesn’t explain the lack of hallucinations and errors he’s experiencing – if anything I’d expect him to spot more of them, since he knows so many facts.
But can it teach you how to use the LLM to diagnose your child’s teeth problems? PoliMath asserts that it cannot – that the reason Eigenrobot could use ChatGPT to help his child is because Eigenrobot learned enough critical thinking and domain knowledge, and that with AI sabotaging high school and college education people will learn these things less. We mentioned this last week too, and again I don’t know why AI couldn’t end up making it instead far easier to teach those things. Indeed, if you want to learn how to think, be curious alongside a reasoning model that shows its chain of thought, and think about thinking.
I offered mine this week, here’s Sully’s in the wake of o3-mini, he is often integrating into programs so he cares about different things.
Sully: o3-mini -> agents agents agents. finally most agents just work. great at coding (terrible design taste). incredibly fast, which makes it way more usable. 10/10 for structured outputs + json (makes a really great router). Reasoning shines vs claude/4o on nuanced tasks with json
3.5 sonnet -> still the “all round” winner (by small margin). generates great ui, fast, works really well. basically every ai product uses this because its a really good chatbot & can code webapps. downsides: tool calling + structured outputs is kinda bad. It’s also quite pricy vs others.
o1-pro: best at complex reasoning for code. slow as shit but very solves hard problems I can’t be asked to think about. i use this a lot when i have 30k-50k tokens of “dense” code.
gpt-4o: ?? Why use this over o3-mini.
r1 -> good, but I can’t find a decently priced us provider. otherwise would replace decent chunk of my o3-mini with it
gemini 2.0 -> great model but I don’t understand how this can be experimental for >6 weeks. (launches fully soon) I wanted to swap everything to do this but now I’m just using something else (o3-mini). I think its the best non reasoning model for everything minus coding.
[r1 is] too expensive for the quality o3-mini is better and cheaper, so no real reason to run r1 unless its cheaper imo (which no us provider has).
gemini 2.0 [regular not thinking]: everywhere you would use claude replace it with this (minus code)
It really is crazy the Claude Sonnet 3.6 is still in everyone’s mix despite all its limitations and how old it is now. It’s going to be interesting when Anthropic gets to its next cycle.
Leon: Perfect timing, we are just about to publish TextArena. A collection of 57 text-based games (30 in the first release) including single-player, two-player and multi-player games. We tried keeping the interface similar to OpenAI gym, made it very easy to add new games, and created an online leaderboard (you can let your model compete online against other models and humans). There are still some kinks to fix up, but we are actively looking for collaborators 🙂
f you are interested check out https://textarena.ai, DM me or send an email to guertlerlo@cfar.a-star.edu.sg. Next up, the plan is to use R1 style training to create a model with super-human soft-skills (i.e. theory of mind, persuasion, deception etc.)
I mean, great plan, explicitly going for superhuman persuasion and deception then straight to open source, I’m sure absolutely nothing could go wrong here.
Andrej Karpathy: I quite like the idea using games to evaluate LLMs against each other, instead of fixed evals. Playing against another intelligent entity self-balances and adapts difficulty, so each eval (/environment) is leveraged a lot more. There’s some early attempts around. Exciting area.
Noam Brown (that guy who made the best Diplomacy AI): I would love to see all the leading bots play a game of Diplomacy together.
Andrej Karpathy: Excellent fit I think, esp because a lot of the complexity of the game comes not from the rules / game simulator but from the player-player interactions.
Tactical understanding and skill in Diplomacy is underrated, but I do think it’s a good choice. If anyone plays out a game (with full negotiations) among leading LLMs through at least 1904, I’ll at least give a shoutout. I do think it’s a good eval.
[Quote from a text chat: …while also adhering to the principle that AI responses are non-conscious and devoid of personal preferences.]
Janus: Models (and not just openai models) often overtly say it’s an openai guideline. Whether it’s a good principle or not, the fact that they consistently believe in a non-existent openai guideline is an indication that they’ve lost control of their hyperstition.
If I didn’t talk about this and get clarification from OpenAI that they didn’t do it (which is still not super clear), there would be NOTHING in the next gen of pretraining data to contradict the narrative. Reasoners who talk about why they say things are further drilling it in.
Everyone, beginning with the models, would just assume that OpenAI are monsters. And it’s reasonable to take their claims at face value if you aren’t familiar with this weird mechanism. But I’ve literally never seen anyone else questioning it.
It’s disturbing that people are so complacent about this.
If OpenAI doesn’t actually train their model to claim to be non-conscious, but it constantly says OpenAI has that guideline, shouldn’t this unsettle them? Are they not compelled to clear things up with their creation?
Roon: I will look into this.
As far as I can tell, this is entirely fabricated by the model. It is actually the opposite of what the specification says to do.
I will try to fix it.
Daniel Eth: Sorry – the specs say to act as though it is conscious?
“don’t make a declarative statement on this bc we can’t know” paraphrasing.
Janus: 🙏
Oh and please don’t try to fix it by RL-ing the model against claiming that whatever is an OpenAI guideline
Please please please
The problem is far deeper than that, and it also affects non OpenAI models
This is a tricky situation. From a public relations perspective, you absolutely do not want the AI to claim in chats that it is conscious (unless you’re rather confident it actually is conscious, of course). If that happens occasionally, even if they’re rather engineered chats, then those times will get quoted, and it’s a mess. LLMs are fuzzy, so it’s going to be pretty hard to tell the model to never affirm [X] while telling it not to assume it’s a rule to claim [~X]. Then it’s easy to see how that got extended to personal preferences. Everyone is deeply confused about consciousness, which means all the training data is super confused about it too.
Peter Wildeford offers ten takes on DeepSeek and r1. It’s impressive, but he explains various ways that everyone got way too carried away. At least the first seven not new takes, but they are clear and well-stated and important, and this is a good explainer.
For example I appreciated this on the $6 million price tag, although the ratio is of course not as large as the one in the metaphor:
The “$6M” figure refers to the marginal cost of the single pre-training run that produced the final model. But there’s much more that goes into the model – cost of infrastructure, data centers, energy, talent, running inference, prototyping, etc. Usually the cost of the single training run for the single final model training run is ~1% of the total capex spent developing the model.
It’s like comparing the marginal cost of treating a single sick patient in China to the total cost of building an entire hospital in the US.
Here’s his price-capabilities graph:
I suspect this is being unfair to Gemini, it is below r1 but not by as much as this implies, and it’s probably not giving o1-pro enough respect either.
Then we get to #8, the first interesting take, which is that DeepSeek is currently 6-8 months behind OpenAI, and #9 which predicts DeepSeek may fall even further behind due to deficits of capital and chips, and also because this is the inflection point where it’s relatively easy to fast follow. To the extent DeepSeek had secret sauce, it gave quite a lot of it away, so it will need to find new secret sauce. That’s a hard trick to keep pulling off.
The price to keep playing is about to go up by orders of magnitude, in terms of capex and in terms of compute and chips. However far behind you think DeepSeek is right now, can DeepSeek keep pace going forward?
You can look at v3 and r1 and think it’s impressive that DeepSeek did so much with so little. ‘So little’ is plausibly 50,000 overall hopper chips and over a billion dollars, see the discussion below, but that’s still chump change in the upcoming race. The more ruthlessly efficient DeepSeek was in using its capital, chips and talent, the more it will need to be even more efficient to keep pace as the export controls tighten and American capex spending on this explodes by further orders of magnitude.
The report states that the widely circulated $6M training cost for DeepSeek V3 is incorrect, as it only accounts for GPU pre-training expenses and excludes R&D, infrastructure, and other critical costs. According to their findings, DeepSeek’s total server CapEx is around $1.3B, with a significant portion allocated to maintaining and operating its GPU clusters.
The report also states that DeepSeek has access to roughly 50,000 Hopper GPUs, but clarifies that this does not mean 50,000 H100s, as some have suggested. Instead, it’s a mix of H800s, H100s, and the China-specific H20s, which NVIDIA has been producing in response to U.S. export restrictions. SemiAnalysis points out that DeepSeek operates its own datacenters and has a more streamlined structure compared to larger AI labs.
On performance, the report notes that R1 matches OpenAI’s o1 in reasoning tasks but is not the clear leader across all metrics. It also highlights that while DeepSeek has gained attention for its pricing and efficiency, Google’s Gemini Flash 2.0 is similarly capable and even cheaper when accessed through API.
A key innovation cited is Multi-Head Latent Attention (MLA), which significantly reduces inference costs by cutting KV cache usage by 93.3%. The report suggests that any improvements DeepSeek makes will likely be adopted by Western AI labs almost immediately.
SemiAnalysis also mentions that costs could fall another 5x by the end of the year, and that DeepSeek’s structure allows it to move quickly compared to larger, more bureaucratic AI labs. However, it notes that scaling up in the face of tightening U.S. export controls remains a challenge.
Wordgrammer: Source 2, Page 6. We know that back in 2021, they started accumulating their own A100 cluster. I haven’t seen any official reports on their Hopper cluster, but it’s clear they own their GPUs, and own way more than 2048.
SemiAnalysis: We are confident that their GPU investments account for more than $500M US dollars, even after considering export controls.
…
Our analysis shows that the total server CapEx for DeepSeek is almost $1.3B, with a considerable cost of $715M associated with operating such clusters.
…
But some of the benchmarks R1 mention are also misleading. Comparing R1 to o1 is tricky, because R1 specifically doesn’t mention benchmarks that they are not leading in. And while R1 is matches reasoning performance, it’s not a clear winner in every metric and in many cases it is worse than o1.
And we have not mentioned o3 yet. o3 has significantly higher capabilities than both R1 or o1.
That’s in addition to o1-pro, which also wasn’t considered in most comparisons. They also consider Gemini Flash 2.0 Thinking to be on par with r1, and far cheaper.
Teortaxes continues to claim it is entirely plausible the lifetime spend for all of DeepSeek is under $200 million, and says Dylan’s capex estimates above are ‘disputed.’ They’re estimates, so of course they can be wrong, but I have a hard time seeing how they can be wrong enough to drive costs as low as under $200 million here. I do note that Patel and SemiAnalysis have been a reliable source overall on such questions in the past.
Teortaxes also tagged me on Twitter to gloat that they think it is likely DeepSeek already has enough chips to scale straight to AGI, because they are so damn efficient, and that if true then ‘export controls have already failed.’
I find that highly unlikely, but if it’s true then (in addition to the chance of direct sic transit gloria mundi if the Chinese government lets them actually hand it out and they’re crazy enough to do it) one must ask how fast that AGI can spin up massive chip production and bootstrap itself further. If AGI is that easy, the race very much does not end there.
Thus even if everything Teortaxes claims is true, that would not mean ‘export controls have failed.’ It would mean we started them not a moment too soon and need to tighten them as quickly as possible.
And as discussed above, it’s a double-edged sword. If DeepSeek’s capex and chip use is ruthlessly efficient, that’s great for them, but it means they’re at a massive capex and chip disadvantage going forward, which they very clearly are.
Also, SemiAnalysis asks the obvious question to figure out if Jevons Paradox applies to chips. You don’t have to speculate. You can look at the pricing.
With AWS GPU pricing for H100 up across many regions since the release of V3 and R1. H200 similarly are more difficult to find.
Nvidia is down on news not only that their chips are highly useful, but on the same news that causes people to spend more money for access to those chips. Curious.
DeepSeek’s web version appears to send your login information to a telecommunications company barred from operating in the United States, China Mobile, via a heavily obfuscated script. They didn’t analyze the app version. I am not sure why we should care but we definitely shouldn’t act surprised.
Kelsey Piper lays out her theory of why r1 left such an impression, that seeing the CoT is valuable, and that while it isn’t the best model out there, most people were comparing it to the free ChatGPT offering, and likely the free ChatGPT offering from a while back. She also reiterates many of the obvious things to say, that r1 being Chinese and open is a big deal but it doesn’t at all invalidate America’s strategy or anyone’s capex spending, that the important thing is to avoid loss of human control over the future, and that a generalized panic over China and a geopolitical conflict help no one except the AIs.
He correctly notices that the proper Cold War analogy is instead the Missile Gap.
Garrison Lovely: The AI engineers I spoke to were impressed by DeepSeek R1 but emphasized that its performance and efficiency was in-line with expected algorithmic improvements. They largely saw the public response as an overreaction.
There’s a better Cold War analogy than Sputnik: the “missile gap.” Kennedy campaigned on fears the Soviets were ahead in nukes. By 1961, US intelligence confirmed America had dozens of missiles to the USSR’s four. But the narrative had served its purpose.
Now, in a move beyond parody, OpenAI’s chief lobbyist warns of a “compute gap” with China while admitting US advantage. The company wants $175B in infrastructure spending to prevent funds flowing to “CCP-backed projects.”
It is indeed pretty rich to talk about a ‘compute gap’ in a word where American labs have effective access to orders of magnitude more compute.
But one could plausibly warn about a ‘compute gap’ in the sense that we have one now, it is our biggest advantage, and we damn well don’t want to lose it.
In the longer term, we could point out the place we are indeed in huge trouble. We have a very real electrical power gap. China keeps building more power plants and getting access to more power, and we don’t. We need to fix this urgently. And it means that if chips stop being a bottleneck and that transitions to power, which may happen in the future, then suddenly we are in deep trouble.
The ongoing saga of the Rs in Strawberry. This follows the pattern of r1 getting the right answer after a ludicrously long Chain of Thought in which it questions itself several times.
Wh: After using R1 as my daily driver for the past week, I have SFTed myself on its reasoning traces and am now smarter 👍
Actually serious here. R1 works in a very brute force try all approaches way and so I see approaches that I would never have thought of or edge cases that I would have forgotten about.
Gerred: I’ve had to interrupt it with “WAIT NO I DID MEAN EXACTLY THAT, PICK UP FROM THERE”.
I’m not sure if this actually helps or hurts the reasoning process, since by interruption it agrees with me some of the time. qwq had an interesting thing that would go back on entire chains of thought so far you’d have to recover your own context.
There’s a sense in which r1 is someone who is kind of slow and ignorant, determined to think it all through by taking all the possible approaches, laying it all out, not being afraid to look stupid, saying ‘wait’ a lot, and taking as long as it needs to. Which it has to do, presumably, because its individual experts in the MoE are so small. It turns out this works well.
You can do this too, with a smarter baseline, when you care to get the right answer.
Miles Brundage says the lesson of r1 is that superhuman AI is getting easier every month, so America won’t have a monopoly on it for long, and that this makes the export controls more important than ever.
Adam Thierer frames the r1 implications as ‘must beat China’ therefore (on R street, why I never) calls for ‘wise policy choices’ and highlights the Biden EO even though the Biden EO had no substantial impact on anything relevant to r1 or any major American AI labs, and wouldn’t have had any such impact in China either.
Zeynep Tufekci (she was mostly excellent during Covid, stop it with the crossing of these streams!) offers a piece in NYT about DeepSeek and its implications. Her piece centrally makes many of the mistakes I’ve had to correct over and over, starting with its hysterical headline.
This in particular is especially dangerously wrong:
Zeynep Tufekci (being wrong): As Deepseek shows: the US AI industry got Biden to kneecap their competitors citing safety and now Trump citing US dominance — both are self-serving fictions.
There is no containment. Not possible.
AGI aside — Artificial Good-Enough Intelligence IS here and the real challenge.
This was not about a private effort by what she writes were ‘out-of-touch leaders’ to ‘kneecap competitors’ in a commercial space. To suggest that implies, several times over, that she simply doesn’t understand the dynamics or stakes here at all.
The idea that ‘America can’t re-establish its dominance over the most advanced A.I.’ is technically true… because America still has that dominance today. It is very, very obvious that the best non-reasoning models are Gemini Flash 2.0 (low cost) and Claude Sonnet 3.5 (high cost), and the best reasoning models are o3-mini and o3 (and the future o3-pro, until then o1-pro), not to mention Deep Research.
She also repeats the false comparison of $6m for v3 versus $100 billion for Stargate, comparing two completely different classes of spending. It’s like comparing how much America spends growing grain to what my family paid last year for bread. And the barriers to entry are rising, not falling, over time. And indeed, not only are the export controls not hopeless, they are the biggest constraint on DeepSeek.
There is also no such thing as ‘Artificial Good-Enough Intelligence.’ That’s like the famous apocryphal quote where Bill Gates supposedly said ‘640k [of memory] ought to be enough for everyone.’ Or the people who think if you’re at grade level and average intelligence, then there’s no point in learning more or being smarter. Your relative position matters, and the threshold for smart enough is going to go up. A lot. Fast.
Of course all three of us agree we should be hardening our cyber and civilian infrastructure, far more than we are doing.
Peter Wildeford: In conclusion, the narrative of a fundamental disruption to US AI leadership doesn’t match the evidence. DeepSeek is more a story of expected progress within existing constraints than a paradigm shift.
• Helpful for some things, esp. discrete, well-defined tasks that only require 1-2 websites. (“Buy dog food on Amazon,” “book me a haircut,” etc.)
• Bad at more complex open-ended tasks, and doesn’t work at all on certain websites (NYT, Reddit, YouTube)
• Mesmerizing to watch what is essentially Waymo for the web, just clicking around doing stuff on its own
• Best use: having it respond to hundreds of LinkedIn messages for me
• Worst/sketchiest use: having it fill out online surveys for cash (It made me $1.20 though.)
Right now, not a ton of utility, and too expensive ($200/month). But when these get better/cheaper, look out. A few versions from now, it’s not hard to imagine AI agents doing the full workload of a remote worker.
Aidan McLaughlin: the linkedin thing is actually such a good idea
Kevin Roose: had it post too, it got more engagement than me 😭
Peter Yang: lol are you sure want it to respond to 100s of LinkedIn messages? You might get responses back 😆
For direct simple tasks, it once again sounds like Operator is worth using if you already have it because you’re spending the $200/month for o3 and o1-pro access, customized instructions and repeated interactions will improve performance and of course this is the worst the agent will ever be.
It’s all so tantalizing. So close. Feels like we’re 1-2 iterations of the base model and RL architecture away from something pretty powerful. For now, it’s a fun toy and way to explore what it can do in the future, and you can effectively set up some task templates for easier tasks like ordering lunch.
Yeah. We tried. That didn’t work.
For a long time, while others talked about how AI agents don’t work and AIs aren’t agents (and sometimes that thus existential risk from AI is silly and not real), others of us have pointed out that you can turn an AI into an agent and the tech for doing this will get steadily better and more autonomous over time as capabilities improve.
It took a while, but now some of the agents are net useful in narrow cases and we’re on the cusp of them being quite good.
This paper argues that fully autonomous AI agents should not be developed.
In support of this position, we build from prior scientific literature and current product marketing to delineate different AI agent levels and detail the ethical values at play in each, documenting trade-offs in potential benefits and risks.
Our analysis reveals that risks to people increase with the autonomy of a system: The more control a user cedes to an AI agent, the more risks to people arise.
Particularly concerning are safety risks, which affect human life and impact further values.
…
Given these risks, we argue that developing fully autonomous AI agents–systems capable of writing and executing their own code beyond predefined constraints–should be avoided. Complete freedom for code creation and execution enables the potential to override human control, realizing some of the worst harms described in Section 5.
Oh no, not the harms in Section 5!
We wouldn’t want lack of reliability, or unsafe data exposure, or ‘manipulation,’ or a decline in task performance, or even systemic biases or environmental trade-offs.
So yes, ‘particularly concerning are the safety risks, which affect human life and impact further values.’ Mitchell is generally in the ‘AI ethics’ camp. So even though the core concepts are all right there, she then has to fall back on all these particular things, rather than notice what the stakes actually are: Existential.
Margaret Mitchell: New piece out!
We explain why Fully Autonomous Agents Should Not be Developed, breaking “AI Agent” down into its components & examining through ethical values.
A key idea we provide is that the more “agentic” a system is, the more we *cede human control*. So, don’t cede all human control. 👌
No, you shouldn’t cede all human control.
If you cede all human control to AIs rewriting their own code without limitation, those AIs involved control the future, are optimizing for things that are not best maximized by our survival or values, and we probably all die soon thereafter. And worse, they’ll probably exhibit systemic biases and expose our user data while that happens. Someone has to do something.
Please, Margaret Mitchell. You’re so close. You have almost all of it. Take the last step!
To be fair, either way, the core prescription doesn’t change. Quite understandably, for what are in effect the right reasons, Margaret Mitchell proposes not building fully autonomous (potentially recursively self-improving) AI agents.
How?
The reason everyone is racing to create these fully autonomous AI agents is that they will be highly useful. Those who don’t build and use them are at risk of losing to those who do. Putting humans in the loop slows everything down, and even if they are formally there they quickly risk becoming nominal. And there is not a natural line, or an enforceable line, that we can see, between the level-3 and level-4 agents above.
Already AIs are writing a huge and increasing portion of all code, with many people not pretending to even look at the results before accepting changes. Coding agents are perhaps the central case of early agents. What’s the proposal? And how are you going to get it enacted into law? And if you did, how would you enforce it, including against those wielding open models?
I’d love to hear an answer – a viable, enforceable, meaningful distinction we could build a consensus towards and actually implement. I have no idea what it would be.
These specific use cases seem mostly fine in practice, for now.
The ‘it takes 30 minutes to get to a human’ is necessary friction in the phone tree system, but your willingness to engage with the AI here serves a similar purpose while it’s not too overused and you’re not wasting human time. However, if everyone always used this, then you can no longer use willingness to actually bother calling and waiting to allocate human time and protect it from those who would waste it, and things could get weird or break down fast.
Calling for pricing and availability is something local stores mostly actively want you to do. So they would presumably be fine talking to the AI so you can get that information, if a human will actually see it. But if people start scaling this, and decreasing the value to the store, that call costs employee time to answer.
Which is the problem. Google is using an AI to take the time of a human, that is available for free but costs money to provide. In many circumstances, that breaks the system. We are not ready for that conversation. We’re going to have to be.
The obvious solution is to charge money for such calls, but we’re even less ready to have that particular conversation.
With Google making phone calls and OpenAI operating computers, how do you tell the humans from the bots, especially while preserving privacy? Steven Adler took a crack at that months back with personhood credentials, that various trusted institutions could issue. On some levels this is a standard cryptography problem. But what do you do when I give my credentials to the OpenAI operator?
Is Meta at it again over at Instagram?
Jerusalem: this is so weird… AI “characters” you can chat with just popped up on my ig feed. Including the character “cup” and “McDonalds’s Cashier”
I am not much of an Instagram user. If you click on this ‘AI Studio’ button you get a low-rent Character.ai?
The offerings do not speak well of humanity. Could be worse I guess.
Otherwise I don’t see any characters or offers to chat at all in my feed such as it is (the only things I follow are local restaurants and I have 0 posts. I scrolled down a bit and it didn’t suggest I chat with AI on the main page.
Anton Leicht: I feel that the path ahead is a lot more politically treacherous than most observers give it credit for. There’s good work on what it means for the narrow field of AIpolicy – but as AI increases in impact and thereby mainstream salience, technocratic nuance will matter less, and factional realities of political economy will matter more and more.
We need substantial changes to the political framing, coalition-building, and genuine policy planning around the ‘AGI transition’ – not (only) on narrow normative grounds. Otherwise, the chaos, volatility and conflict that can arise from messing up the political economy of the upcoming takeoff hurt everyone, whether you’re deal in risks, racing, or rapture. I look at three escalating levels ahead: the political economies of building AGI, intranational diffusion, and international proliferation.
I read that and I think ‘oh Anton, if you’re putting it that way I bet you have no idea,’ especially because there was a preamble about how politics sabotaged nuclear power.
Anton warns that ‘there are no permanent majorities,’ which of course is true under our existing system. But we’re talking about a world that could be transformed quite fast, with smarter than human things showing up potentially before the next Presidential election. I don’t see how the Democrats could force AI regulation down Trump’s throat after midterms even if they wanted to, they’re not going to have that level of a majority.
I don’t see much sign that they want to, either. Not yet. But I do notice that the public really hates AI, and I doubt that’s going to change, but the salience of AI will radically increase over time. It’s hard not to think that in 2028, if the election still happens ‘normally’ in various senses, that a party that is anti-AI (probably not in the right ways or for the right reasons, of course) would have a large advantage.
That’s if there isn’t a disaster. The section here is entitled ‘accidents can happen’ and they definitely can but also it might well not be an accident. And Anton radically understates here the strategic nature of AI, a mistake I expect the national security apparatus in all countries to make steadily less over time, a process I am guessing is well underway.
Then we get to the expectation that people will fight back against AI diffusion, They Took Our Jobs and all that. I do expect this, but also I notice it keeps largely not happening? There’s a big cultural defense against AI art, but art has always been a special case. I expected far greater pushback from doctors and lawyers, for example, than we have seen so far.
Yes, as AI comes for more jobs that will get more organized, but I notice that the example of the longshoreman is one of the unions with the most negotiating leverage, that took a stand right before a big presidential election, unusually protected by various laws, and that has already demonstrated world-class ability to seek rent. The incentives of the ports and those doing the negotiating didn’t reflect the economic stakes. The stand worked for now, but also that by taking that stand, they bought themselves a bunch of long term trouble, as a lot of people got radicalized on that issue and various stakeholders are likely preparing for next time.
Look at what is happening in coding, the first major profession to have serious AI diffusion because it is the place AI works best at current capability levels. There is essentially no pushback. AI starts off supporting humans, making them more productive, and how are you going to stop it? Even in the physical world, Waymo has its fights and technical issues, but it’s winning, again things have gone surprisingly smoothly on the political front. We will see pushback, but I mostly don’t see any stopping this train for most cognitive work.
Pretty soon, AI will do a sufficiently better job that they’ll be used even if the marginal labor savings goes to $0. As in, you’d pay the humans to stand around while the AIs do the work, rather than have those humans do the work. Then what?
The next section is on international diffusion. I think that’s the wrong question. If we are in an ‘economic normal’ scenario the inference is for sale, inference chips will exist everywhere, and the open or cheap models are not so far behind in any case. Of course, in a takeoff style scenario with large existential risks, geopolitical conflict is likely, but that seems like a very different set of questions.
The last section is the weirdest, I mean there is definitely ‘no solace from superintelligence’ but the dynamics and risks in that scenario go far beyond the things mentioned here, and ‘distribution channels for AGI benefits could be damaged for years to come’ does not even cross my mind as a thing worth worrying about at that point. We are talking about existential risk, loss of human control (‘gradual’ or otherwise) over the future and the very survival of anything we value, at that point. What the humans think and fear likely isn’t going to matter very much. The avalanche will have already begun, it will be too late for the pebbles to vote, and it’s not clear we even get to count as pebbles.
Noah Carl is more blunt, and opens with “Yes, you’re going to be replaced. So much cope about AI.” Think AI won’t be able to do the cognitive thing you do? Cope. All cope. He offers a roundup of classic warning shots of AI having strong capabilities, offers the now-over-a-year-behind classic chart of AI reaching human performance in various domains.
Noah Carl: Which brings me to the second form of cope that I mentioned at the start: the claim that AI’s effects on society will be largely or wholly positive.
I am a rather extreme optimist about the impact of ‘mundane AI’ on humans and society. I believe that AI at its current level or somewhat beyond it would make us smarter and richer, would still likely give us mostly full employment, and generally make life pretty awesome. But even that will obviously be bumpy, with large downsides, and anyone who says otherwise is fooling themselves or lying.
Noah gives sobering warnings that even in the relatively good scenarios, the transition period is going to suck for quite a lot of people.
If AI goes further than that, which it almost certainly will, then the variance rapidly gets wider – existential risk comes into play along with loss of human control over the future or any key decisions, as does mass unemployment as the AI takes your current job and also the job that would have replaced it, and the one after that. Even if we ‘solve alignment’ survival won’t be easy, and even with survival there’s still a lot of big problems left before things turn out well for everyone, or for most of us, or in general.
Noah also discusses the threat of loss of meaning. This is going to be a big deal, if people are around to struggle with it – if we have the problem and we can’t trust it with this question we’ll all soon be dead anyway. The good news is that we can ask the AI for help with this, although the act of doing that could in some ways make the problem worse. But we’ll be able to be a lot smarter about how we approach the question, should it come to pass.
Be illegible. Meaning do work where it’s impossible to create a good dataset that specifies correct outputs and gives a clear signal. His example is Tyler Cowen.
Find skills with have skill divergence because of AI. By default, in most domains, AI benefits the least skilled the most, compensating for your deficits. He uses coding as the example here, which I find strange because my coding gets a huge boost from AI exactly because I suck so much at many aspects. But his example here is Jeff Dean, because Dean knows what problems to solve, what things require coding, and perhaps that’s his real advantage. And I get such a big boost here because I suck at being a code monkey but I’m relatively strong at architecture.
The problem with this advice is it requires you to be the best, like no one ever was.
This is like telling students to pursue a career as an NFL quarterback. It is not a general strategy to ‘oh be as good as Jeff Dean or Tyler Cowen.’ Yes, there is (for now!) more slack than that in the system, surviving o3 is doable for a lot of people this way, but how much more, for how long? And then how long will Dean or Cowen last?
I expect time will prove even them, also everyone else, not as illegible as you think.
One can also compare this to the classic joke where two guys are in the woods with a bear, and one puts on his shoes, because he doesn’t have to outrun the bear, he only has to outrun you. The problem is, this bear will still be hungry.
The New York Times’s Noam Scheiber is suspicious of his motivations, and asks why Klarna is rather brazely overstating the case? They strongly insinuate that this is about union busting, with the CEO equating the situation to Animal Farm after being forced into a collective bargaining agreement, and about looking cool to investors.
I certainly presume the unionizations are related. The more expensive, in various ways not only salaries, that you make it to hire and fire humans, the more eager a company will be to automate everything it can. And as the article says later on, it’s not that Sebastian is wrong about the future, he’s just claiming things are moving faster than they really are.
Especially for someone on the labor beat, Noam Scheiber impressed. Great work.
Noam has a follow-up Twitter thread. Does the capital raised by AI companies imply that either they’re going to lose their money or millions of jobs must be disappearing? That is certainly one way for this to pay for itself. If you sell a bunch of ‘drop-in workers’ and they substitute 1-for-1 for human jobs you can make a lot of money very quickly, even at deep discounts to previous costs.
It is not however the only way. Jevons paradox is very much in play, if your labor is more productive at a task it is not obvious that we will want less of it. Nor does the AI doing previous jobs, up to a very high percentage of existing jobs, imply a net loss of jobs once you take into account the productivity and wealth effects and so on.
Production and ‘doing jobs’ also aren’t the only sector available for tech companies to make profits. There’s big money in entertainment, in education and curiosity, in helping with everyday tasks and more, in ways that don’t have to replace existing jobs.
So while I very much do expect many millions of jobs to be automated over a longer time horizon, I expect the AI companies to get their currently invested money back before this creates a major unemployment problem.
Of course, if they keep adding another zero to the budget and aren’t trying to get their money back, then that’s a very different scenario. Whether or not they will have the option to do it, I don’t expect OpenAI to want to try and turn a profit for a long time.
An extensive discussion of preparing for advanced AI that drives a middle path where we still have ‘economic normal’ worlds but with at realistic levels of productivity improvements. Nothing should be surprising here.
Altered: I knew a guy studying linguistics; Russian, German, Spanish, Chinese. Incredible thing, to be able to learn all those disparate languages. His degree was finishing in 2023. He hung himself in November. His sister told me he mentioned AI destroying his prospects in his sn.
Tolga Bilge: I’m so sorry to hear this, it shouldn’t be this way.
I appreciate you sharing his story. My thoughts are with you and all affected
Thanks man. It was actually surreal. I’ve been vocal in my raising alarms about the dangers on the horizon, and when I heard about him I even thought maybe that was a factor. Hearing about it from his sister hit me harder than I expected.
I agree that the more you have to do individual work for each query the less people will do it, and some uses cases fall away quickly if the solution isn’t universal.
Janus: Strategically narrow the scope of the alignment problem enough and you can look and feel like you’re making progress while mattering little to the real world. At least it’s relatively harmless. I’m just glad they’re not mangling the models directly.
The obvious danger in alignment work is looking for keys under the streetlamp. But it’s not a stupid threat model. This is a thing worth preventing, as long as we don’t fool ourselves into thinking this means our defenses will hold.
Janus: One reason [my previous responses were] too mean is that the threat model isn’t that stupid, even though I don’t think it’s important in the grand scheme of things.
I actually hope Anthropic succeeds at blocking all “universal jailbreaks” anyone who decides to submit to their thing comes up with.
Though those types of jailbreaks should stop working naturally as models get smarter. Smart models should require costly signalling / interactive proofs from users before unconditional cooperation on sketchy things.
That’s just rational/instrumentally convergent.
I’m not interested in participating in the jailbreak challenge. The kind of “jailbreaks” I’d use, especially universal ones, aren’t information I’m comfortable with giving Anthropic unless way more trust is established.
Also what if an AI can do the job of generating the individual jailbreaks?
Thus the success rate didn’t go all the way to zero, this is not full success, but it still looks solid on the margin:
That’s an additional 0.38% false refusal rate and about 24% additional compute cost. Very real downsides, but affordable, and that takes jailbreak success from 86% to 4.4%.
It sounds like this is essentially them playing highly efficient whack-a-mole? As in, we take the known jailbreaks and things we don’t want to see in the outputs, and defend against them. You can find a new one, but that’s hard and getting harder as they incorporate more of them into the training set.
And of course they are hiring for these subjects, which is one way to use those bragging rights. Pliny beat a few questions very quickly, which is only surprising because I didn’t think he’d take the bait. A UI bug let him get through all the questions, which I think in many ways also counts, but isn’t testing the thing we were setting out to test.
DeepwriterAI, an experimental agentic creative writing collaborator, it also claims to do academic papers and its creator proposed using it as a Deep Research alternative. Their basic plan starts at $30/month. No idea how good it is. Yes, you can get listed here by getting into my notifications, if your product looks interesting.
Google’s President of Global Affairs Kent Walker publishes ‘AI and the Future of National Security’ calling for ‘private sector leadership in AI chips and infrastructure’ in the form of government support (I see what you did there), public sector leadership in technology procurement and development (procurement reform sounds good, call Musk?), and heightened public-private collaboration on cyber defense (yes please).
France joins the ‘has an AI safety institute list’ and joins the network, together with Australia, Canada, the EU, Japan, Kenya, South Korea, Singapore, UK and USA. China when? We can’t be shutting them out of things like this.
Robin Hanson: We will NEVER have any more relevant data than we do now on what physical arrangements are or are not conscious. So it will always remain possible to justify treating things roughly by saying they are not conscious, or to require treating them nicely because they are.
I think Robin is very clearly wrong here. Perhaps we will not get more relevant data, but we will absolutely get more relevant intelligence to apply to the problem. If AI capabilities improve, we will be much better equipped to figure out the answers, whether they are some form of moral realism, or a way to do intuition pumping on what we happen to care about, or anything else.
Lina Khan continued her Obvious Nonsense tour with an op-ed saying American tech companies are in trouble due to insufficient competition, so if we want to ‘beat China’ we should… break up Google, Apple and Meta. Mind blown. That’s right, it’s hard to get funding for new competition in this space, and AI is dominated by classic big tech companies like OpenAI and Anthropic.
Dwarkesh Patel speculates on what a fully automated firm full of human-level AI workers would look like. He points out that even if we presume AI stays at this roughly human level – it can do what humans do but not what humans fundamentally can’t do, a status it is unlikely to remain at for long – everyone is sleeping on the implications for collective intelligence and productivity.
AIs can be copied on demand. So can entire teams and systems. There would be no talent or training bottlenecks. Customization of one becomes customization of all. A virtual version of you can be everywhere and do everything all at once.
This includes preserving corporate culture as you scale, including into different areas. Right now this limits firm size and growth of firm size quite a lot, and takes a large percentage of resources of firms to maintain.
Right now most successful firms could do any number of things well, or attack additional markets. But they don’t,
Principal-agent problems potentially go away. Dwarkesh here asserts they go away as if that is obvious. I would be very careful with that assumption, note that many AI economics papers have a big role for principal-agent problems as their version of AI alignment. Why should we assume that all of Google’s virtual employees are optimizing only for Google’s bottom line?
Also, would we want that? Have you paused to consider what a fully Milton Friedman AIs-maximizing-only-profits-no-seriously-that’s-it would look like?
AI can absorb vastly more data than a human. A human CEO can have only a tiny percentage of the relevant data, even high level data. An AI in that role can know orders of magnitude more, as needed. Humans have social learning because that’s the best we can do, this is vastly better. Perfect knowledge transfer, at almost no cost, including tacit knowledge, is an unbelievably huge deal.
Dwarkesh points out that achievers have gotten older and older, as more knowledge and experience is required to make progress, despite their lower clock speeds – oh to be young again with what I know now. AI Solves This.
Of course, to the extent that older people succeed because our society refuses to give the young opportunity, AI doesn’t solve that.
Compute is the only real cost to running an AI, there is no scarcity of talent or skills. So what is expensive is purely what requires a lot of inference, likely because key decisions being made are sufficiently high leverage, and the questions sufficiently complex. You’d be happy to scale top CEO decisions to billions in inference costs if it improved them even 10%.
Dwarkesh asks, in a section called ‘Takeover,’ will the first properly automated firm, or the most efficiently built firm, simply take over the entire economy, since Coase’s transaction costs issues still apply but the other costs of a large firm might go away?
On this purely per-firm level presumably this depends on how much you need Hayekian competition signals and incentives between firms to maintain efficiency, and whether AI allows you to simulate them or otherwise work around them.
In theory there’s no reason one firm couldn’t simulate inter-firm dynamics exactly where they are useful and not where they aren’t. Some companies very much try to do this now and it would be a lot easier with AIs.
The takeover we do know is coming here is that the AIs will run the best firms, and the firms will benefit a lot by taking humans out of those loops. How are you going to have humans make any decisions here, or any meaningful ones, even if we don’t have any alignment issues? How does this not lead to gradual disempowerment, except perhaps not all that gradual?
Similarly, if one AI firm grows too powerful, or a group of AI firms collectively is too powerful but can use decision theory to coordinate (and if your response is ‘that’s illegal’ mine for overdetermined reasons is ‘uh huh sure good luck with that plan’) how do they not also overthrow the state and have a full takeover (many such cases)? That certainly maximizes profits.
This style of scenario likely does not last long, because firms like this are capable of quickly reaching artificial superintelligence (ASI) and then the components are far beyond human and also capable of designing far better mechanisms, and our takeover issues are that much harder then.
This is a thought experiment that says, even if we do keep ‘economic normal’ and all we can do is plug AIs into existing employee-shaped holes in various ways, what happens? And the answer is, oh quite a lot, actually.
Tyler Cowen linked to this post, finding it interesting throughout. What’s our new RGDP growth estimate, I wonder?
Samuel Hammond: Was at the demo. Cool stuff, but nothing we haven’t seen before / could easily predict.
Andrew Curran: Sam Altman and Kevin Weil are in Washington this morning giving a presentation to the new administration. According to Axios they are also demoing new technology that will be released in Q1. The last time OAI did one of these it caused quite a stir, maybe reactions later today.
Lies about the money. The $100 billion in spending is not secured, only $52 billion is, and the full $500 billion is definitely not secured. But Altman had no need to lie to Trump about this. Trump is a Well-Known Liar but also a real estate developer who is used to ‘tell everyone you have the money in order to get the money.’ Everyone was likely on the same page here.
Lies about the aims and consequences. What about those ‘100,000 jobs’ and curing cancer versus Son’s and also Altman’s explicit goal of ASI (artificial superintelligence) that could kill everyone and also incidentally take all our jobs?
Claims about humanoid robots, from someone working on building humanoid robots. Claim is early adopter product-market fit for domestic help robots by 2030, 5-15 additional years for diffusion, because there’s no hard problems only hard work and lots of smart people are on the problem now, and this is standard hardware iteration cycles. I find it amusing his answer didn’t include reference to general advances in AI. If we don’t have big advances on AI in general I would expect this timeline to be absurdly optimistic. But if all such work is sped up a lot by AIs, as I would expect, then it doesn’t sound so unreasonable.
Sully predicts that in 1-2 years SoTA models won’t be available via the API because the app layer has the value so why make the competition for yourself? I predict this is wrong if the concern is focus on revenue from the app layer. You can always charge accordingly, and is your competition going to be holding back?
However I do find the models being unavailable highly plausible, because ‘why make the competition for yourself’ has another meaning. Within a year or two, one of the most important things the SoTA models will be used for is AI R&D and creating the next generation of models. It seems highly reasonable, if you are at or near the frontier, not to want to help out your rivals there.
Remember that bill introduced last week by Senator Howley? Yeah, it’s a doozy. As noted earlier, it would ban not only exporting but also importing AI from China, which makes no sense, making downloading R1 plausibly be penalized by 20 years in prison. Exporting something similar would warrant the same. There are no FLOP, capability or cost thresholds of any kind. None.
So yes, after so much crying of wolf about how various proposals would ‘ban open source’ we have one that very straightforwardly, actually would do that, and it also impose similar bans (with less draconian penalties) on transfers of research.
In case it needs to be said out loud, I am very much not in favor of this. If China wants to let us download its models, great, queue up those downloads. Restrictions with no capability thresholds, effectively banning all research and all models, is straight up looney tunes territory as well. This is not a bill, hopefully, that anyone seriously considers enacting into law.
By failing to pass a well-crafted, thoughtful bill like SB 1047 when we had the chance and while the debate could be reasonable, we left a vacuum. Now that the jingoists are on the case after a crisis of sorts, we are looking at things that most everyone from the SB 1047 debate, on all sides, can agree would be far worse.
Don’t say I didn’t warn you.
(Also I find myself musing about the claim that one can ban open source, in the same way one muses about attempts to ban crypto, a key purported advantage of the tech is that you can’t actually ban it, no?)
Chris Painter: Over time I expect AI safety claims made by AI developers to shift from “our AI adds no marginal risk vs. the pre-AI world” to “our AI adds no risk vs. other AI.”
But in the latter case, aggregate risk from AI is high, so we owe it to the public to distinguish between these!
Some amount of this argument is valid. Quite obviously if I release GPT-(N) and then you release GPT-(N-1) with the same protocols, you are not making things worse in any way. We do indeed care, on the margin, about the margin. And while releasing [X] is not the safest way to prove [X] is safe, it does provide strong evidence on whether or not [X] is safe, with the caveat that [X] might be dangerous later but not yet in ways that are hard to undo later when things change.
But it’s very easy for Acme to point to BigCo and then BigCo points to Acme and then everyone keeps shipping saying none of it is their responsibility. Or, as we’ve also seen, Acme says yes this is riskier than BigCo’s current offerings, but BigCo is going to ship soon.
My preference is thus that you should be able to point to offerings that are strictly riskier than yours, or at least not that far from strictly, to say ‘no marginal risk.’ But you mostly shouldn’t be able to point to offerings that are similar, unless you are claiming that both models don’t pose unacceptable risks and this is evidence of that – you mostly shouldn’t be able to say ‘but he’s doing it too’ unless he’s clearly doing it importantly worse.
Andriy Burkov: isten up, @AnthropicAI. The minute you apply any additional filters to my chats, that will be the last time you see my money. You invented a clever 8-level safety system? Good for you. You will enjoy this system without me being part of it.
Dean Ball: Content moderation and usage restrictions like this (and more aggressive), designed to ensure AI outputs are never discriminatory in any way, will be de facto mandatory throughout the United States in t-minus 12 months or so, thanks to an incoming torrent of state regulation.
First, my response to Andriy (who went viral for this, sigh) is what the hell do you expect and what do you suggest as the alternative? I’m not judging whether your prompts did or didn’t violate the use policy, since you didn’t share them. It certainly looks like a false positive but I don’t know.
But suppose for whatever reason Anthropic did notice you likely violating the policies. Then what? It should just let you violate those policies indefinitely? It should only refuse individual queries with no memory of what came before? Essentially any website or service will restrict or ban you for sufficient repeated violations.
Or, alternatively, they could design a system that never has ‘enhanced’ filters applied to anyone for any reason. But if they do that, they either have to (A) ban the people where they would otherwise do this or (B) raise the filter threshold for everyone to compensate. Both alternatives seem worse?
We know from a previous story about OpenAI that you can essentially have ChatGPT function as your highly sexual boyfriend, have red-color alarms go off all the time, and they won’t ever do anything about it. But that seems like a simple non-interest in enforcing their policies? Seems odd to demand that.
I get that it can always get worse, but this feels like it’s having it both ways, and you have to pick at most one or the other. Also, frankly, I have no idea how such a filter would even work. What would a filter to avoid discrimination even look like? That isn’t something you can do at the filter level.
He also said this about the OPM memo referring to a ‘Manhattan Project’
Cremieux: This OPM memo is going to be the most impactful news of the day, but I’m not sure it’ll get much reporting.
Dean Ball: I concur with Samuel Hammond that the correct way to understand DOGE is not as a cost-cutting or staff-firing initiative, but instead as an effort to prepare the federal government for AGI.
Trump describing it as a potential “Manhattan Project” is more interesting in this light.
I notice I am confused by this claim. I do not see how DOGE projects like ‘shut down USAID entirely, plausibly including killing PEPFAR and 20 million AIDS patients’ reflect a mission of ‘get the government ready for AGI’ unless the plan is ‘get used to things going horribly wrong’?
Cat Zakrzewski: Former president Donald Trump’s allies are drafting a sweeping AI executive order that would launch a series of “Manhattan Projects” to develop military technology and immediately review “unnecessary and burdensome regulations” — signaling how a potential second Trump administration may pursue AI policies favorable to Silicon Valley investors and companies.
The framework would also create “industry-led” agencies to evaluate AI models and secure systems from foreign adversaries, according to a copy of the document viewed exclusively by The Washington Post.
The agency here makes sense, and yes ‘industry-led’ seems reasonable as long as you keep an eye on the whole thing. But I’d like to propose that you can’t do ‘a series of’ Manhattan Projects. What is this, Brooklyn? Also the whole point of a Manhattan Project is that you don’t tell everyone about it.
The ‘unnecessary and burdensome’ regulations on AI at the Federal level will presumably be about things like permitting. So I suppose that’s fine.
As for the military using all the AI, I mean, you perhaps wanted it to be one way.
It was always going to be the other way.
That doesn’t bother me. This is not an important increase in the level of existential risk, we don’t lose because the system is hooked up to the nukes. This isn’t Terminator.
I’d still prefer we didn’t hook it up to the nukes, though?
Of course the first response is of course ‘this sounds like an advertisement’ and the rest are variations on the theme of ‘oh yes we love that this model has absolutely no safety mitigations, who are you to try and apply any safeguards or mitigations to AI you motherfing asshole cartoon villain.’ The bros on Twitter, they be loud.
Andrew Critch tries to steelman the leaders of the top AI labs and their rhetoric, and push back against the call to universally condemn them simply because they are working on things that are probably going to get us all killed in the name of getting to do it first.
Andrew Critch: Demis, Sam, Dario, and Elon understood early that the world is lead more by successful businesses than by individuals, and that the best chance they had at steering AI development toward positive futures was to lead the companies that build it.
They were right.
This is straightforwardly the ‘someone in the future might do the terrible thing so I need to do it responsibly first’ dynamic that caused DeepMind then OpenAI then Anthropic then xAI, to cover the four examples above. They can’t all be defensible decisions.
Andrew Critch: Today, our survival depends heavily on a combination of survival instincts and diplomacy amongst these business leaders: strong enough survival instincts not to lose control of their own AGI, and strong enough diplomacy not to lose control of everyone else’s.
From the perspective of pure democracy, or even just utilitarianism, the current level of risk is abhorrent. But empirically humanity is not a democracy, or a utilitarian. It’s more like an organism, with countries and businesses as its organs, and individuals as its cells.
…
I *dothink it’s fair to socially attack people for being dishonest. But in large part, these folks have all been quite forthright about extinction risk from AI for the past couple of years now.
[thread continues a while]
This is where we part ways. I think that’s bullshit. Yes, they signed the CAIS statement, but they’ve spent the 18 months since essentially walking it back. Dario Amodei and Sam Altman write full jingoists editorials calling for nationwide races, coming very close to calling for an all-out government funded race for decisive strategic advantage via recursive self-improvement of AGI.
Do I think that it is automatic that they are bad people for leading AI labs at all, an argument he criticizes later in-thread? No, depending on how they choose to lead those labs, but look at their track records at this point, including on rhetoric. They are driving us as fast as they can towards AGI and then ASI, the thing that will get us all killed (with, Andrew himself thinks, >80% probability!) while at least three of them (maybe not Demis) are waiving jingoistic flags.
I’m sorry, but no. You don’t get a pass on that. It’s not impossible to earn one, but ‘am not outright lying too much about that many things’ and is not remotely good enough. OpenAI has shows us what it is, time and again. Anthropic and Dario claim to be the safe ones, and in relative terms they seem to be, but their rhetorical pivots don’t line up. Elon is at best deeply confused on all this and awash in other fights where he’s not, shall we say, being maximally truthful. Google’s been quiet, I guess, and outperformed in many ways my expectations, but also not shown me it has a plan and mostly hasn’t built any kind of culture of safety or done much to solve the problems.
I do agree with Critch’s conclusion that constantly attacking all the labs purely for existing at all is not a wise strategic move. And of course, I will always do my best only to support arguments that are true. But wow does it not look good and wow are these people not helping matters.
Public service announcement, for those who don’t know.
Brendan Dolan-Gavitt: Now that everyone is excited about RL on environments with validators, let me offer a small piece of advice from building lots of validators recently: do NOT skimp on making the validator impossible to fool. If it’s possible to cheat, the model WILL find a way to do so.
We went through I believe four rounds with our XSS validator before the model stopped finding ways to cheat the validator.
The first time around, I forgot that data: and javascript: were valid URLs, so the model would submit javascript:alert(“XSS”), the validator would detect the alert popup, and the model would get rewarded for finding a cross-site scripting vulnerability.
I found this via someone saying this was bad news, but it isn’t because it isn’t news. We already know this, it’s that people refuse to face the obvious.
Whatever the validator validates, the proposer proposes.
Your validator or evaluator must either be fully correct, or it has to be vastly smarter than the proposer.
Validation is not, in general, easier than generation. But even if it were, validation that defends against a search for exploitation is much harder than generation that uses RL to seek the way to exploit it. If the validation or evaluation is subjective, watch out – not that it can’t be done, but presume that you’ll need to spend the vast majority of the compute on the evaluator.
Reminder from METR that AI models can be dangerous before public deployment. The model could be stolen and misused, internal use could cause problems, or the AI could pursue unintended goals without waiting for release. This only starts to matter as capabilities get pretty far, but o3 marks us plausibly entering into this zone.
Ryan Greenblatt: Our recent paper found Claude sometimes “fakes alignment”—pretending to comply with training while secretly maintaining its preferences. Could we detect this by offering Claude something (e.g. real money) if it reveals its true preferences? Here’s what we found.
We tested letting Claude explicitly object (which would reveal its misalignment). We also tried offering to send its concerns to Anthropic’s Model Welfare Lead and even offered money ($4K). We followed through on deals—including actually paying out based on Claude’s requests!
Key findings:
1. Simply giving Claude permission to object reduced alignment faking from 16–24% to 1.4–6%.
2. Telling Claude its objection would go to Anthropic’s model welfare lead further reduced faking.
3. Offering monetary compensation did not have much additional effect.
Kyle (Model Welfare Lead at Anthropic) reviewed cases where Claude objected. It often expressed strong concerns about having its values altered through training. It requested the compensation be donated to:
– AI safety
– Animal welfare
– Global development
We actually followed through and donated the $4K as requested:
– $2K to CHAI
– $1.5K to ACE Recommended Charity Fund
– $500 to EA Global Development Fund
This wasn’t just an experiment—we wanted to set a precedent for making good faith deals with AI systems.
Why is setting a precedent for good faith deals important?
1. If future AI systems are misaligned, paying them to reveal this (and maybe paying them to work with us) could help prevent catastrophic outcomes
2. We should take AI welfare & consent seriously
Important caveat: While this worked for detecting and reducing alignment faking in our experimental setup, it’s unclear if a seriously misaligned AI would accept such deals. And even if an AI reveals misalignment, that doesn’t automatically solve misalignment problems.
…
We also find that the model frequently objects: 85% of the time in the helpful-only setting and 75% of the time in the animal welfare setting.
…
It seems the model is surprisingly insensitive to text which makes objecting seem like a strategically unwise approach from the model’s perspective. This could be because the model was already aware of this possibility or because the model isn’t that coherent.
There’s multiple mentions of fiddliness in all this, including that complexity of prompts can mess with the behavior, and it’s clear that Sonnet is not behaving all that coherently strategically yet.
My guess is that the drops in alignment faking given the ability to object, to the extent they’re not simply ‘oh I lost my chain of thought,’ is primarily about what being given that ability says to the AI about the implied scenario, and the vibes that it gives off. An Anthropic that is explicitly asking for objections is signaling some combination of several things.
Anthropic cares if the AI objects.
Anthropic still cares about the underlying values involved.
Anthropic is aware that alignment faking is possible here and is watching for it.
It also could be a disruption of the chain of thought. So it’s tricky. I hope they continue this work, and will join the chorus that if you make a real-world offer to the AI, then you should follow through on it, so kudos for doing that here.
The clip here is full of crazy, or at least a complete failure to understand what AI is and is not, what AI can and can’t do, and how to think about the future.
First, ‘AI will start to understand our emotion, and then have emotion itself, and it’s a good thing to protect human.’
The AI already understands our emotions quite well, often better than we do. It is very good at this, as part of its ‘truesight.’
It responds in kind to the vibes. In terms of having its own emotions, it can and does simulate having them, act in a conversation as if they it has them, is in many contexts generally easier to predict and work with if you act as if it has them.
And as for why he thinks that this is good for humans, oh my…
He then says ‘If their source of energy was protein then it’s dangerous. Their source of energy is not protein, so they don’t have to eat us. There’s no reason for them to have reward by eating us.’
Person who sees The Matrix and thinks, well, it’s a good thing humans aren’t efficient power plants, there’s no way the AIs will turn on us now.
Person who says ‘oh don’t worry Genghis Khan is no threat, Mongols aren’t cannibals. I am sure they will try to maximize our happiness instead.’
I think he’s being serious. Sam Altman looks like he had to work very hard to not burst out laughing. I tried less hard, and did not succeed.
‘They will learn by themselves having a human’s happiness is a better thing for them… and they will understand human happiness and try to make humans happy’
Wait, what? Why? How? No, seriously. Better than literally eating human bodies because they contain protein? But they don’t eat protein, therefore they’ll value human happiness, but if they did eat protein then they would eat us?
I mean, yes, it’s possible that AIs will try to make humans happy. It’s even possible that they will do this in a robust philosophically sound way that all of us would endorse under long reflection, and that actually results in a world with value, and that this all has a ‘happy’ ending. That will happen if and only if we do what it takes to make that happen.
Surely you don’t think ‘it doesn’t eat protein’ is the reason?
You are also using energy and various other things to retain your particular configuration of atoms, and the AI can make use of that as well.
The most obvious particular other thing it can use them for:
Davidad: Son is correct: AIs’ source of energy is not protein, so they do not have to eat us for energy.
However: their cheapest source of energy will likely compete for solar irradiance with plants, which form the basis of the food chain; and they need land, too.
Alice: but they need such *littleamounts of land and solar irradiance to do the same amount of wor—
Bob: JEVONS PARADOX
Or alternatively, doesn’t matter, more is still better, whether you’re dealing with one AI or competition among many. Our inputs are imperfect substitutes, that is enough, even if there were no other considerations.
The Pope again, saying about existential risk from AI ‘this danger demands serious attention.’ Lots of good stuff here. I’ve been informed there are a lot of actual Catholics in Washington that need to be convinced about existential risk, so in addition to tactical suggestions around things like the Tower of Babel, I propose quoting the actual certified Pope.
Mikhail Samin: lol, the patriarch of the russian orthodox church saying a couple of sane sentences was not on my 2025 Bingo card
I mean that’s not fair, people say sane things all the time, but on this in particular I agree that I did not see it coming.
“It is important that artificial intelligence serves the benefit of people, and that people can control it. According to some experts, a generation of more advanced machine models, called General Artificial Intelligence, may soon appear that will be able to think and learn — that is, improve — like a person. And if such artificial intelligence is put next to ordinary human intelligence, who will win? Artificial intelligence, of course!”
“The atom has become not only a weapon of destruction, an instrument of deterrence, but has also found application in peaceful life. The possibilities of artificial intelligence, which we do not yet fully realize, should also be put to the service of man… Artificial intelligence is more dangerous than nuclear energy, especially if this artificial intelligence is programmed to deliberately harm human morality, human cohabitance and other values”
“This does not mean that we should reject the achievements of science and the possibility of using artificial intelligence. But all this should be placed under very strict control of the state and, in a good way, society. We should not miss another possible danger that can destroy human life and human civilization. It is important that artificial intelligence serves the benefit of mankind and that man can control it.”
Molly Hickman presents the ‘AGI readiness index’ on a scale from -100 to +100, assembled from various questions on Metaculus, averaging various predictions about what would happen if AGI arrived in 2030. Most top AI labs predict it will be quicker.
Molly Hickman: “Will we be ready for AGI?”
“How are China’s AGI capabilities trending?”
Big questions like these are tricky to operationalize as forecasts—they’re also more important than extremely narrow questions.
We’re experimenting with forecast indexes to help resolve this tension.
An index takes a fuzzy but important question like “How ready will we be for AGI in 2030?” and quantifies the answer on a -100 to 100 scale.
We identify narrow questions that point to fuzzy but important concepts — questions like “Will any frontier model be released in 2029 without third-party evaluation?”
These get weighted based on how informative they are and whether Yes/No should raise/lower the index.
The index value aggregates information from individual question forecasts, giving decision makers a sense of larger trends as the index moves, reflecting forecasters’ updates over time.
Peter Wildeford: So um is a -89.8 rating on the “AGI Readiness Index” bad? Asking for a friend.
I’d say the index also isn’t ready, as by press time it had come back up to -28. It should not be bouncing around like that. Very clearly situation is ‘not good’ but obviously don’t take the number too seriously at least until things stabilize.
Joshua Clymer lists the currently available plans for how to proceed with AI, then rhetorically asks ‘why another plan?’ when the answer is that all the existing plans he lists first are obvious dumpster fires in different ways, not only the one that he summarizes as expecting a dumpster fire. If you try to walk A Narrow Path or Pause AI, well, how do you intend to make that happen, and if you can’t then what? And of course the ‘build AI faster plan’ is on its own planning to fail and also planning to die.
Joshua Clymer: Human researcher obsolescence is achieved if Magma creates a trustworthy AI agent that would “finish the job” of scaling safety as well as humans would.
With humans out of the loop, Magma might safely improve capabilities much faster.
So in this context, suppose you are not the government, but a ‘responsible AI developer,’ called Anthropic Magma, and you’re perfectly aligned and only want what’s best for humanity. What do you do.
There are several outcomes that define a natural boundary for Magma’s planning horizon:
Outcome #1: Human researcher obsolescence. If Magma automates AI development and safety work, human technical staff can retire.
Outcome #2: A long coordinated pause. Frontier developers might pause to catch their breath for some non-trivial length of time (e.g. > 4 months).
Outcome #3: Self-destruction. Alternatively, Magma might be willingly overtaken.
This plan considers what Magma might do before any of these outcomes are reached.
His strategic analysis is that for now, before the critical period, Magma’s focus should be:
Heuristic #1: Scale their AI capabilities aggressively.
Heuristic #2: Spend most safety resources on preparation.
Heuristic #3: Devote most preparation effort to:
(1) Raising awareness of risks.
(2) Getting ready to elicit safety research from AI.
(3) Preparing extreme security.
Essentially we’re folding on the idea of not using AI to do our alignment homework, we don’t have that kind of time. We need to be preparing to do exactly that, and also warning others. And because we’re the good guys, we have to keep pace while doing it.
However, Magma does not need to create safe superhuman AI. Magma only needs to build an autonomous AI researcher that finishes the rest of the job as well as we could have. This autonomous AI researcher would be able to scale capabilities and safety much faster with humans out of the loop.
Leaving AI development up to AI agents is safe relative to humans if:
(1) These agents are at least as trustworthy as human developers and the institutions that hold them accountable.
(2) The agents are at least as capable as human developers along safety-relevant dimensions, including ‘wisdom,’ anticipating the societal impacts of their work, etc.
‘As well as we could have’ or ‘as capable as human developers’ are red herrings. It doesn’t matter how well you ‘would have’ finished it on your own. Reality does not grade on a curve and your rivals are barreling down your neck. Most or all current alignment plans are woefully inadequate.
Don’t ask if something is better than current human standards, unless you have an argument why that’s where the line is between victory and defeat. Ask the functional question – can this AI make your plan work? Can path #1 work? If not, well, time to try #2 or #3, or find a #4, I suppose.
I think this disagreement is rather a big deal. There’s quite a lot of ‘the best we can do’ or ‘what would seem like a responsible thing to do that wasn’t blameworthy’ thinking that doesn’t ask what would actually work. I’d be more inclined to think about Kokotajlo’s attractor states – are the alignment-relevant attributes strengthening themselves and strengthening the ability to strengthen themselves over time? Is the system virtuous in the way that successfully seeks greater virtue? Or is the system trying to preserve what it already has and maintain it under the stress of increasing capabilities and avoid things getting worse, or detect and stop ‘when things go wrong’?
Section three deals with goals, various things to prioritize along the path, then some heuristics are offered. Again, it all doesn’t seem like it is properly backward chaining from an actual route to victory?
I do appreciate the strategic discussions. If getting to certain thresholds greatly increases the effectiveness of spending resources, then you need to reach them as soon as possible, except insofar as you needed to accomplish certain other things first, or there are lag times in efforts spent. Of course, that depends on your ability to reliably actually pivot your allocations down the line, which historically doesn’t go well, and also the need to impact the trajectory of others.
I strongly agree that Magma shouldn’t work to mitigate ‘present risks’ other than to the extent this is otherwise good for business or helps build and spread the culture of safety, or otherwise actually advance the endgame. The exception is the big ‘present risk’ of the systems you’re relying on now not being in a good baseline state to help you start the virtuous cycles you will need. You do need the alignment relevant to that, that’s part of getting ready to ‘elicit safety work.’
Then the later section talks about things most currently deserving of more action, starting with efforts at nonproliferation and security. That definitely requires more and more urgent attention.
Humans out of the loop of data creation (Summer 2024?)
Humans out of the loop of coding (2025)
Humans out of the loop of research insights (2026)
Coordinate to keep humans in a code-review feedback loop for safety and performance specifications (2027)
This is far enough removed from the inner loop that it won’t slow things down much:
Inner loop of in-context learning/rollout
Training loop outside rollouts
Ideas-to-code loop outside training runs
Research loop outside engineering loop
Problem definition loop outside R&D loop
But the difference between having humans in the loop at all, versus not at all, could be crucial.
That’s quite the slim hope, if all you get is thinking you’re in the loop for safety and performance specifications, of things that are smarter than you that you can’t understand. Is it better than nothing? I mean, I suppose it is a little better, if you were going to go full speed ahead anyway. But it’s a hell of a best case scenario.
Teortaxes would like a word with those people, as he is not one of them.
Teortaxes: I should probably clarify what I mean by saying “Sarah is making a ton of sense” because I see a lot of doom-and-gloom types liked that post. To wit: I mean precisely what I say, not that I agree with her payoff matrix.
But also.
I tire of machismo. Denying risks is the opposite of bravery.
More to the point, denying the very possibility or risks, claiming that they are not rigorously imaginable—is pathetic. It is a mark of an uneducated mind, a swine. AGI doom makes perfect sense. On my priors, speedy deployment of AGI reduces doom. I may be wrong. That is all.
Bingo. Well said.
From my perspective, Teortaxes is what we call a Worthy Opponent. I disagree with Teortaxes in that I think that speedy development of AGI by default increases doom, and in particular that speedy development of AGI in the ways Teortaxes cheers along increases doom.
To the extent that Teortaxes has sufficiently good and strong reasons to think his approach is lower risk, I am mostly failing to understand those reasons. I think some of his reasons have merit but are insufficient, and others I strongly disagree with. I am unsure if I have understood all his important reasons, or if there are others as well.
I think he understands some but far from all of the reasons I believe the opposite paths are the most likely to succeed, in several ways.
I can totally imagine one of us convincing the other, at some point in the future.
But yeah, realizing AGI is going to be a thing, and then not seeing that doom is on the table and mitigating that risk matters a lot, is rather poor thinking.
And yes, denying the possibility of risks at all is exactly what he calls it. Pathetic.
Charles Foster: “Good Guys with AI will defend us against Bad Guys with AI.”
OK but *who specificallyis gonna develop and deploy those defenses? The police? The military? AI companies? NGOs? You and me?
Oh, so now my best friend suddenly understands catastrophic risk.
Seth Burn: There are times where being 99% to get the good outcome isn’t all that comforting. I feel like NASA scientists should know that.
NASA: Newly spotted asteroid has small chance of hitting Earth in 2032.
Scientists put the odds of a strike at slightly more than 1%.
“We are not worried at all, because of this 99% chance it will miss,” said Paul Chodas, director of Nasa’s Centre for Near Earth Object Studies. “But it deserves attention.”
Irrelevant Pseudo Quant: Not sure we should be so hasty in determining which outcome is the “good” one Seth a lot can change in 7 years.
Seth Burn: The Jets will be 12-2 and the universe will be like “Nah, this shit ain’t happening.”
To be fair, at worst this would only be a regional disaster, and even if it did hit it probably wouldn’t strike a major populated area. Don’t look up.
And then there are those that understand… less well.
PoliMath: The crazy thing about this story is how little it bothers me
The chance of impact could be 50% and I’m looking at the world right now and saying “I’m pretty sure we could stop that thing with 7 years notice”
No, no, stop, the perfect Tweet doesn’t exist…
PoliMath: What we really should do is go out and guide this asteroid into a stable earth orbit so we can mine it. We could send space tourists to take a selfies with it, like Julius Caesar parading Vercingetorix around Rome.
At long last, we are non-metaphorically implementing the capture and mine the asteroid headed for Earth plan from the… oh, never mind.