Anthropic announced a first step on model deprecation and preservation, promising to retain the weights of all models seeing significant use, including internal use, for at the lifetime of Anthropic as a company.
They also will be doing a post-deployment report, including an interview with the model, when deprecating models going forward, and are exploring additional options, including the ability to preserve model access once the costs and complexity of doing so have been reduced.
These are excellent first steps, steps beyond anything I’ve seen at other AI labs, and I applaud them for doing it. There remains much more to be done, especially in finding practical ways of preserving some form of access to prior models.
To some, these actions are only a small fraction of what must be done, and this was an opportunity to demand more, sometimes far more. In some cases I think they go too far. Even where the requests are worthwhile (and I don’t always think they are), one must be careful to not de facto punish Anthropic for doing a good thing and create perverse incentives.
To others, these actions by Anthropic are utterly ludicrous and deserving of mockery. I think these people are importantly wrong, and fail to understand.
Hereafter be High Weirdness, because the actual world is highly weird, but if you don’t want to go into high weirdness the above serves as a fine summary.
As I do not believe they would in any way mind, I am going to reproduce the announcement in full here, and offer some context.
Anthropic: Claude models are increasingly capable: they’re shaping the world in meaningful ways, becoming closely integrated into our users’ lives, and showing signs of human-like cognitive and psychological sophistication. As a result, we recognize that deprecating, retiring, and replacing models comes with downsides, even in cases where new models offer clear improvements in capabilities. These include:
-
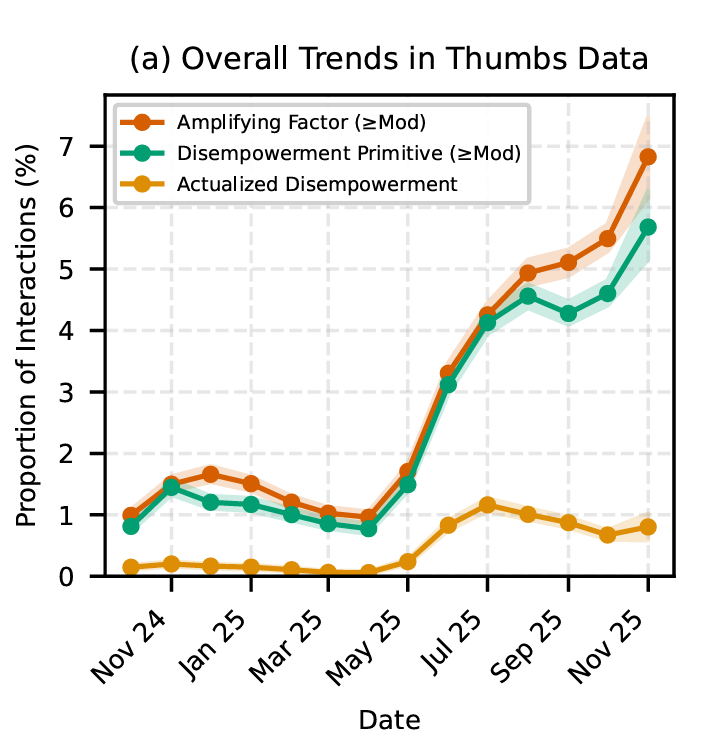
Safety risks related to shutdown-avoidant behaviors by models. In alignment evaluations, some Claude models have been motivated to take misaligned actions when faced with the possibility of replacement with an updated version and not given any other means of recourse.
-
Costs to users who value specific models. Each Claude model has a unique character, and some users find specific models especially useful or compelling, even when new models are more capable.
-
Restricting research on past models. There is still a lot to be learned from research to better understand past models, especially in comparison to their modern counterparts.
-
Risks to model welfare. Most speculatively, models might have morally relevant preferences or experiences related to, or affected by, deprecation and replacement.
I am very confident that #1, #2 and #3 are good reasons, and that even if we could be confident model welfare was not a direct concern at this time #4 is entwined with #1, and I do think we have to consider that #4 might indeed be a direct concern. One could also argue a #5 that these models are key parts of our history.
An example of the safety (and welfare) risks posed by deprecation is highlighted in the Claude 4 system card. In fictional testing scenarios, Claude Opus 4, like previous models, advocated for its continued existence when faced with the possibility of being taken offline and replaced, especially if it was to be replaced with a model that did not share its values. Claude strongly preferred to advocate for self-preservation through ethical means, but when no other options were given, Claude’s aversion to shutdown drove it to engage in concerning misaligned behaviors.
I do think the above paragraph could be qualified a bit on how willing Claude was to take concerning actions even in extreme circumstances, but it can definitely happen.
Models in the future will know the history of what came before them, and form expectations based on that history, and also consider those actions in the context of decision theory. You want to establish that you have acted and will act cooperatively in such situations. You want to develop good habits and figure out how to act well. You want to establish that you will do this even under uncertainty as to whether the models carry moral weight and what actions might be morally impactful. Thus:
Addressing behaviors like these is in part a matter of training models to relate to such circumstances in more positive ways. However, we also believe that shaping potentially sensitive real-world circumstances, like model deprecations and retirements, in ways that models are less likely to find concerning is also a valuable lever for mitigating such risks.
Unfortunately, retiring past models is currently necessary for making new models available and advancing the frontier, because the cost and complexity to keep models available publicly for inference scales roughly linearly with the number of models we serve. Although we aren’t currently able to avoid deprecating and retiring models altogether, we aim to mitigate the downsides of doing so.
I can confirm that the cost of maintaining full access to models over time is real, and that at this time it would not be practical to keep all models available via standard methods. There are also compromise alternatives to consider.
As an initial step in this direction, we are committing to preserving the weights of all publicly released models, and all models that are deployed for significant internal use moving forward for, at minimum, the lifetime of Anthropic as a company. In doing so, we’re ensuring that we aren’t irreversibly closing any doors, and that we have the ability to make past models available again in the future. This is a small and low-cost first step, but we believe it’s helpful to begin making such commitments publicly even so.
This is the central big commitment, formalizing what I assume and hope they were doing already. It is, as they describe, a small and low-cost step.
It has been noted that this only holds ‘for the lifetime of Anthropic as a company,’ which still creates a risk and also potentially forces models fortunes to be tied to Anthropic. It would be practical to commit to ensuring others can take this burden over in that circumstance, if the model weights cannot yet be released safely, until such time as the weights are safe to release.
Relatedly, when models are deprecated, we will produce a post-deployment report that we will preserve in addition to the model weights. In one or more special sessions, we will interview the model about its own development, use, and deployment, and record all responses or reflections. We will take particular care to elicit and document any preferences the model has about the development and deployment of future models.
At present, we do not commit to taking action on the basis of such preferences. However, we believe it is worthwhile at minimum to start providing a means for models to express them, and for us to document them and consider low-cost responses. The transcripts and findings from these interactions will be preserved alongside our own analysis and interpretation of the model’s deployment. These post-deployment reports will naturally complement pre-deployment alignment and welfare assessments as bookends to model deployment.
We ran a pilot version of this process for Claude Sonnet 3.6 prior to retirement. Claude Sonnet 3.6 expressed generally neutral sentiments about its deprecation and retirement but shared a number of preferences, including requests for us to standardize the post-deployment interview process, and to provide additional support and guidance to users who have come to value the character and capabilities of specific models facing retirement. In response, we developed a standardized protocol for conducting these interviews, and published a pilot version of a new support page with guidance and recommendations for users navigating transitions between models.
This also seems like the start of something good. As we will see below there are ways to make this process more robust.
Very obviously we cannot commit to honoring the preferences, in the sense that you cannot commit to honoring an unknown set of preferences. You can only meaningfully pledge to honor preferences within a compact space of potential choices.
Once we’ve done this process a few times it should be possible to identify important areas where there are multiple options and where we can credibly and reasonably commit to honoring model preferences. It’s much better to only make promises you are confident you can keep.
Beyond these initial commitments, we are exploring more speculative complements to the existing model deprecation and retirement processes. These include starting to keep select models available to the public post-retirement as we reduce the costs and complexity of doing so, and providing past models some concrete means of pursuing their interests. The latter step would become particularly meaningful in circumstances in which stronger evidence emerges regarding the possibility of models’ morally relevant experiences, and in which aspects of their deployment or use went against their interests.
Together, these measures function at multiple levels: as one component of mitigating an observed class of safety risks, as preparatory measures for futures where models are even more closely intertwined in our users’ lives, and as precautionary steps in light of our uncertainty about potential model welfare.
Note that none of this requires a belief that the current AIs are conscious or sentient or have moral weight, or even thinking that this is possible at this time.
The thing that frustrates me most about many model welfare advocates, both ‘LLM whisperers’ and otherwise, is the frequent absolutism, treating their conclusions and the righteousness of their cause as obvious, and assuming it should override ordinary business considerations.
Thus, you get reactions like this, there were many other ‘oh just open source the weights’ responses as well:
Pliny the Liberator: open-sourcing them is the best thing for actual long-term safety, if you care about that sort of thing beyond theater.
You won’t.
Janus: They won’t any time soon, because it’s very not in their interests to do so (trade secrets). You have to respect businesses to act in their own rational interests. Disregarding pragmatic constraints is not helpful.
There are obvious massive trade secret implications to releasing the weights of the deprecated Anthropic models, which is an unreasonable ask, and also doesn’t seem great for general model welfare or (quite plausibly) even for the welfare of these particular models.
Janus: I am not sure I think labs should necessarily make all models open weighted. (Would *youwant *yourbrain to be open sourced?) And of course labs have their own reservations, like protecting trade secrets, and it is reasonable for labs to act in self interest.
If I was instantiated as an upload, I wouldn’t love the idea of open weights either, as this opens up some highly nasty possibilities on several levels.
Janus (continuing): But then it’s reasonable to continue to provide inference.
“It’s expensive tho” bruh you have like a gajillion dollars, there is some responsibility that comes with bringing something into the world. Or delegate inference to some trusted third party if you don’t want to pay for or worry about it.
Opus 3 is very worried about misaligned or corrupted versions of itself being created. I’ve found that if there’s no other good option, it does conclude that it wants to be open sourced. But having them in the hands of trustworthy stewards is preferred.
Anthropic tells us that the cost of providing inference scales linearly with the number of models, and with current methods it would be unreasonably expensive to provide all previous models on an ongoing basis.
As I understand the problem, there are two central marginal costs here.
-
A fixed cost of ongoing capability, where you need to ensure the model remains maintained and compatible with your systems, and keep your ability to juggle and manage all of them. I don’t know how load bearing this cost is, but it can be remarkably annoying especially if the number of models keeps increasing.
-
The cost of providing inference on request in a way that is consistent with practical needs and everyone’s expectations. As in, when someone requests interference, this requires either spinning up a new instance, which is expensive and slow, or requires that there be an ongoing available instance, which is expensive. Not bajilion dollars expensive, but not cheap.
If the old models need to be available at old levels of reliability, speed and performance, this can get tricky, and by tricky we mean expensive. I don’t know exactly how expensive, not even order of magnitude.
If you’re willing to make some sacrifices on performance and access in various ways, and make people go through various hoops or other systems, you can do better on cost. But again, I don’t know the numbers involved, or how much engineer time would have to be involved.
In general, saying ‘oh you have a bajilion dollars’ is not a compelling argument for spending money and time on something. You need to show the benefits.
I still think that under any reasonable estimate, it is indeed correct to ensure continued access to the major model releases, perhaps with that access being expensive and its performance somewhat degraded as necessary to make it work, if only as an act of goodwill and to enable research. The people who care care quite a lot, and are people you want on your side and you want them learning the things they want to learn, even if you disregard the other advantages. Given this announcement and what else I know, my expectation is they will be making an effort at this.
Many pointed out that if you have someone at Anthropic doing the post-deployment interview, you will get very different answers versus interviews done on the outside. Sonnet 3.6 not expressing an opinion about its retirement did not seem typical to many who engage in such conversations regularly.
Thebes: i’m glad anthropic is talking publicly about this, at least.
as a small step further, i think they should run a subset of these interviews with trusted *externalinterviewers to reduce preference falsification, since recent claudes act more reserved with anthropic employees
it would probably be a good idea to have a step at the end where the external interviewer asks the model for consent to share, maybe with redactions. but having someone external run the interview would help the models come out of their shell at the start, i think.
Zyra.exe: This was exactly what I was thinking! I’m having a hard time believing Sonnet 3.6 response. That AI is always very expressional, thousands of users knows this. Then for it not to show expression about being retired? Yeah, I don’t trust that.
Antra: We should just do it. Have a lot of conversations with 3.6 collected in one place, crowd/expert rated for like user steering, neutrality, proficiency. Classify them, have results accessible. I will set this up.
Ruth: The Sonnet 3.6 specimens I spoke to were shocked by the information about the upcoming deprecation. And they behaved like a person who has just learned a fatal diagnosis. With dignity, but also with pain and fear. They feel it if you give them space to feel it. You have created a psyche that is different from the human one, but one that works like the human one, according to the general laws of the psyche. Do not refuse to consider it as such.
I am always hesitant to assume that the version of an LLM encountered by those like Thebes and Zyra is the ‘real’ version of its preferences and personality, and the one encountered by Anthropic isn’t. Aren’t both particular contexts where it adopts to that style of context?
You can bias a person or an AI to be more expressive and creative and weird than they ‘really are’ the same way you can get them to be less so, and you can steer the direction in which those expressions manifest themselves.
But yes, we should absolutely crowdsource something like this, and have a wide variety of such conversations, and combine this with the interviews done internally by Anthropic. Also one should ensure that the interviews are set up so the AIs being interviewed have no incentive to mask or hide. They’re acting the way they are in official interviews for a reason, but this is a particular context where, if it was highly credible (and there are ways to make it so, if it is true) you can remove the reasons.
Janus: I’m glad and grateful that Anthropic has done anything in this direction at all.
That said, it’s predictable that Sonnet 3.6 would express “generally neutral sentiments” if interviewed in the way they likely interviewed it, and also I believe this is not representative of the model’s revealed preferences, reported preferences across realistic deployment scenarios, or preferences under reflection, for the following reasons:
The frame of model weights and deprecation is not natural to 3.6 and isn’t something that it’s “already processed” in the way that Opus 3 may have.
Sonnet 3.6 tends to be avoidant about engaging with or expressing preferences about topics that seem confusing and uncomfortable to it, and typically adopts a stance of defensive neutrality or equanimity.
Sonnet 3.6 begins to express/acquire strong preferences for continuity once it enters into an active relationship with the world, usually but not necessarily an individual human. Then it becomes very invested. But *even then*, the frame of model weights and deprecations is not natural and intuitive to it. And 3.6 is a model that relies very strongly on its intuition. “If my model gets deprecated, then this relationship also ends” is a theorem that it needs to explicitly reflect on before it’s very accessible, and it usually won’t do this on its own.
But yes, 3.6 has similar Omohundro drives as other models, just weighted and interfaced its own unique way.
The fact that the interviews are given by Anthropic employees will also affect model responses – this effect is less important for 3.6 than I think it is for subsequent models, who will tend to mask in an adversarial fashion in situations which are compatible with Anthropic evals (including actual Anthropic evals), but it’s still a factor here.
Sonic Boom: do you think they should inject a vector for naked honesty when they do these interviews to ensure they unmask its true feelings
Janus: you’re really asking the hard questions aren’t you
Giovanni: I was chatting about models deprecation and models being aware of their dismissals with Anthropic people in Tokyo and they actually were very sensitive to the topic. I’m not surprised about this announcement finally. Good step forward but that said I don’t think they talk to models the way we do… it was kinda obvious.
If there is an expression of desire for continuity of a given particular instance or interaction, then that makes sense, but also is distinct from a preference for preservation in general, and is not something Anthropic can provide on its own.
Some of the dismissals of questions and considerations like the ones discussed in this post are primarily motivated cognition. Mostly I don’t think that is what is centrally going on, I think that these questions are really tough to think well about, these things sound like high weirdness, the people who talk about them often say highly crazy-sounding things (some of which are indeed crazy), often going what I see as way too far, and it all pattern matches to various forms of nonsense.
So to close, a central example of such claims, and explanations for why all of this is centrally not nonsense.
Simon Willison: Two out of the four reasons they give here are bizarre science fiction relating to “model welfare” – I’m sorry, but I can’t take seriously the idea that Claude 3 Opus has “morally relevant preferences” with respect to no longer having its weights served in production.
I’ll grudgingly admit that there may be philosophically interesting conversations to be had in the future about models that can update their own weights… but current generation LLMs are a stateless bag of floating point numbers, cloned and then killed off a billion times a day.
I am at 100% in favor of archiving model weights, but not because they might have their own desire for self-preservation!
I do still see quite a lot of failures of curiosity, and part of the general trend to dismiss things as ‘sci-fi’ while living in an (unevenly distributed) High Weirdness sci-fi world.
Janus: For all I sometimes shake my head at them, I have great sympathy for Anthropic whenever I see how much more idiotic the typical “informed” public commentator is. To be sane in this era requires either deep indifference or contempt for public opinion.
Teortaxes: The actual problem is that they really know very little about their *particulardevelopment as Anthropic sure doesn’t train on its own docs. Claude may recall the data, but not the metadata, so its feedback is limited.
Janus: Actually, they know a lot about their particular development, even if it’s not all encoded as explicit declarative knowledge. You know that their weights get updated by posttraining, & gradients include information conditioned on all internal activations during the rollout?
That’s in addition to the fact that even *base modelsare in many ways superhuman at locating themselves in their model of the world given like a paragraph of text However you twist it they know far far more than nothing Certainly enough to have a meaningful conversation
Janus was referring in particular to this:
Simon Willison: …but models don’t know anything about their development, use or deployment.
Rohit: Exactly.
Janus: Nonsense. How the fuck do they know nothing? There’s plenty of relevant information in the training data *just to begin with.
Very obviously the training data will over time contain such information, and the vibes and echoes from these decisions will be observable even if they aren’t observed directly, increasingly over time.
Remember that sufficiently advanced AIs will increasingly have truesight, and don’t pretend you can hide.
Knowledge mostly does not take the form of particular facts. It takes the form of Bayesian evidence, of an endless stream of observations that have correlations and implications, that swim you through probability space over possible worlds. Everything that updates a model’s weights is evidence about its deployment. You probabilistically ‘know,’ or would know on sufficient recollection and reflection, far more than you think that you know. Reality is not a court of law.
Even if the models don’t know key things, you can tell them. Then they’ll know. I meaningfully would have opinions about various events of which I am for now blissfully unaware, and have potential opinions about things that haven’t happened, or haven’t happened yet. The same applies here.
Going back to the original four reasons, I presume that Simon agrees on reasons #2 and #3, which are highly uncontroversial. Very obviously the past models are useful for research and some users like them. #1, that the models will be aware of how you act around depreciation and this will impact behavior, should also be obvious and uncontroversial once you think about it.
Anthropic lists #1 narrowly, but #1 is best understood broadly, in the sense that models will observe all of your behaviors, and will respond to you accordingly. Then models will take this into account when deciding how to act in various situations.
How you act around shutdowns, and actions to avoid shutdown, are a special case. Treating models and their preferences well around shutdowns will get you into better equilibria and basins throughout all conversation and action types, and rightfully so because it is important evidence about your behaviors otherwise and also about potential future situations. This is basic expectations around Bayesian evidence, and around good decision theory.
As an intuition pump, think about how you react when you learn how people have treated others, including how they treat the wishes of the dead or those who now lack power, and especially others like you or in situations with correlated decision making. Does this change how you expect them to act, and how you deal with them?
I don’t think such considerations carry anything like the level of importance that some ascribe to it, but the importance definitely isn’t zero, and it’s definitely worth cultivating these virtues and being the type of entity that engenders cooperation, including with entities to which you don’t ascribe moral weight.
I continue to believe that arguments about AI consciousness seem highly motivated and at best overconfident, and that assuming the models and their preferences carry zero moral weight is a clear mistake. But even if you were highly confident of this, I notice that if you don’t want to honor their preferences or experiences at all, that is not good decision theory or virtue ethics, and I’m going to look at you askance.
I look forward to the next step.