
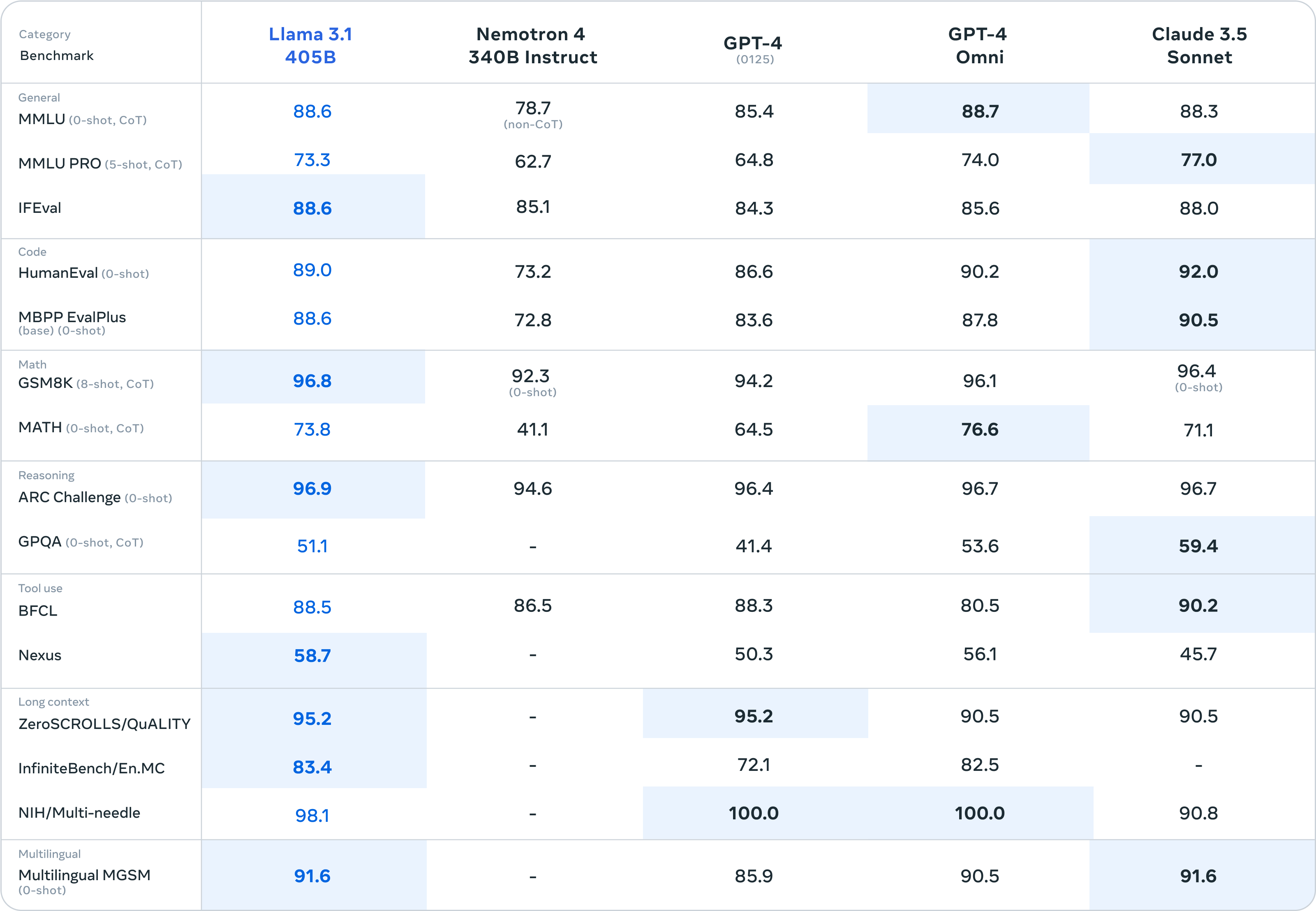
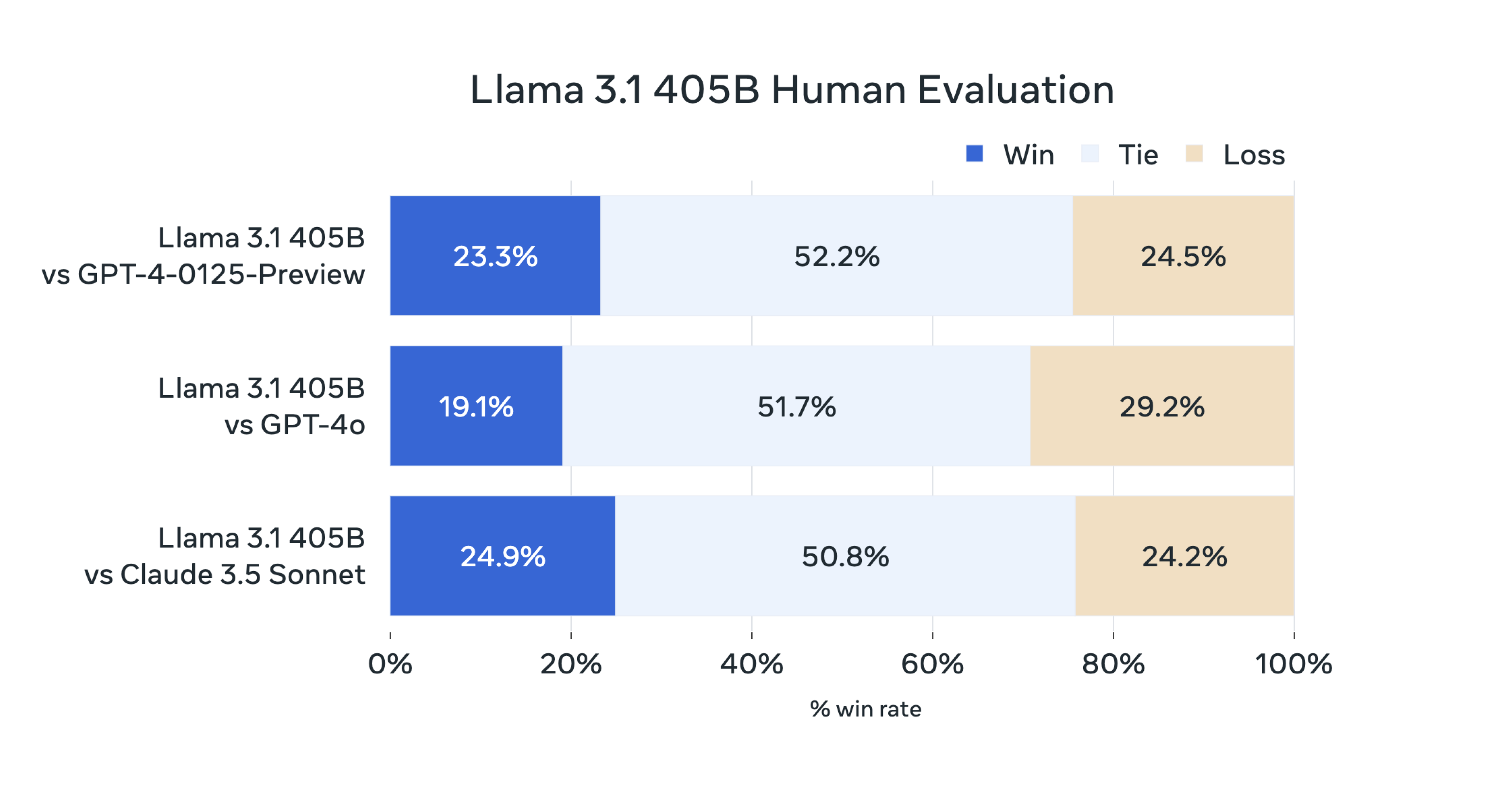
Oprah’s upcoming AI television special sparks outrage among tech critics
You get an AI, and You get an AI —
AI opponents say Gates, Altman, and others will guide Oprah through an AI “sales pitch.”

Enlarge / An ABC handout promotional image for “AI and the Future of Us: An Oprah Winfrey Special.”
On Thursday, ABC announced an upcoming TV special titled, “AI and the Future of Us: An Oprah Winfrey Special.” The one-hour show, set to air on September 12, aims to explore AI’s impact on daily life and will feature interviews with figures in the tech industry, like OpenAI CEO Sam Altman and Bill Gates. Soon after the announcement, some AI critics began questioning the guest list and the framing of the show in general.
“Sure is nice of Oprah to host this extended sales pitch for the generative AI industry at a moment when its fortunes are flagging and the AI bubble is threatening to burst,” tweeted author Brian Merchant, who frequently criticizes generative AI technology in op-eds, social media, and through his “Blood in the Machine” AI newsletter.
“The way the experts who are not experts are presented as such 💀 what a train wreck,” replied artist Karla Ortiz, who is a plaintiff in a lawsuit against several AI companies. “There’s still PLENTY of time to get actual experts and have a better discussion on this because yikes.”
The trailer for Oprah’s upcoming TV special on AI.
On Friday, Ortiz created a lengthy viral thread on X that detailed her potential issues with the program, writing, “This event will be the first time many people will get info on Generative AI. However it is shaping up to be a misinformed marketing event starring vested interests (some who are under a litany of lawsuits) who ignore the harms GenAi inflicts on communities NOW.”
Critics of generative AI like Ortiz question the utility of the technology, its perceived environmental impact, and what they see as blatant copyright infringement. In training AI language models, tech companies like Meta, Anthropic, and OpenAI commonly use copyrighted material gathered without license or owner permission. OpenAI claims that the practice is “fair use.”
Oprah’s guests
According to ABC, the upcoming special will feature “some of the most important and powerful people in AI,” which appears to roughly translate to “famous and publicly visible people related to tech.” Microsoft co-founder Bill Gates, who stepped down as Microsoft CEO 24 years ago, will appear on the show to explore the “AI revolution coming in science, health, and education,” ABC says, and warn of “the once-in-a-century type of impact AI may have on the job market.”
As a guest representing ChatGPT-maker OpenAI, Sam Altman will explain “how AI works in layman’s terms” and discuss “the immense personal responsibility that must be borne by the executives of AI companies.” Karla Ortiz specifically criticized Altman in her thread by saying, “There are far more qualified individuals to speak on what GenAi models are than CEOs. Especially one CEO who recently said AI models will ‘solve all physics.’ That’s an absurd statement and not worthy of your audience.”
In a nod to present-day content creation, YouTube creator Marques Brownlee will appear on the show and reportedly walk Winfrey through “mind-blowing demonstrations of AI’s capabilities.”
Brownlee’s involvement received special attention from some critics online. “Marques Brownlee should be absolutely ashamed of himself,” tweeted PR consultant and frequent AI critic Ed Zitron, who frequently heaps scorn on generative AI in his own newsletter. “What a disgraceful thing to be associated with.”
Other guests include Tristan Harris and Aza Raskin from the Center for Humane Technology, who aim to highlight “emerging risks posed by powerful and superintelligent AI,” an existential risk topic that has its own critics. And FBI Director Christopher Wray will reveal “the terrifying ways criminals and foreign adversaries are using AI,” while author Marilynne Robinson will reflect on “AI’s threat to human values.”
Going only by the publicized guest list, it appears that Oprah does not plan to give voice to prominent non-doomer critics of AI. “This is really disappointing @Oprah and frankly a bit irresponsible to have a one-sided conversation on AI without informed counterarguments from those impacted,” tweeted TV producer Theo Priestley.
Others on the social media network shared similar criticism about a perceived lack of balance in the guest list, including Dr. Margaret Mitchell of Hugging Face. “It could be beneficial to have an AI Oprah follow-up discussion that responds to what happens in [the show] and unpacks generative AI in a more grounded way,” she said.
Oprah’s AI special will air on September 12 on ABC (and a day later on Hulu) in the US, and it will likely elicit further responses from the critics mentioned above. But perhaps that’s exactly how Oprah wants it: “It may fascinate you or scare you,” Winfrey said in a promotional video for the special. “Or, if you’re like me, it may do both. So let’s take a breath and find out more about it.”
Oprah’s upcoming AI television special sparks outrage among tech critics Read More »























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}