On Thursday, Google made Gemini Live, its voice-based AI chatbot feature, available for free to all Android users. The feature allows users to interact with Gemini through voice commands on their Android devices. That’s notable because competitor OpenAI’s Advanced Voice Mode feature of ChatGPT, which is similar to Gemini Live, has not yet fully shipped.
Google unveiled Gemini Live during its Pixel 9 launch event last month. Initially, the feature was exclusive to Gemini Advanced subscribers, but now it’s accessible to anyone using the Gemini app or its overlay on Android.
Gemini Live enables users to ask questions aloud and even interrupt the AI’s responses mid-sentence. Users can choose from several voice options for Gemini’s responses, adding a level of customization to the interaction.
Gemini suggests the following uses of the voice mode in its official help documents:
Talk back and forth: Talk to Gemini without typing, and Gemini will respond back verbally. Brainstorm ideas out loud: Ask for a gift idea, to plan an event, or to make a business plan. Explore: Uncover more details about topics that interest you. Practice aloud: Rehearse for important moments in a more natural and conversational way.
Interestingly, while OpenAI originally demoed its Advanced Voice Mode in May with the launch of GPT-4o, it has only shipped the feature to a limited number of users starting in late July. Some AI experts speculate that a wider rollout has been hampered by a lack of available computer power since the voice feature is presumably very compute-intensive.
To access Gemini Live, users can reportedly tap a new waveform icon in the bottom-right corner of the app or overlay. This action activates the microphone, allowing users to pose questions verbally. The interface includes options to “hold” Gemini’s answer or “end” the conversation, giving users control over the flow of the interaction.
Currently, Gemini Live supports only English, but Google has announced plans to expand language support in the future. The company also intends to bring the feature to iOS devices, though no specific timeline has been provided for this expansion.
Over the weekend, the nonprofit National Novel Writing Month organization (NaNoWriMo) published an FAQ outlining its position on AI, calling categorical rejection of AI writing technology “classist” and “ableist.” The statement caused a backlash online, prompted four members of the organization’s board to step down, and prompted a sponsor to withdraw its support.
“We believe that to categorically condemn AI would be to ignore classist and ableist issues surrounding the use of the technology,” wrote NaNoWriMo, “and that questions around the use of AI tie to questions around privilege.”
NaNoWriMo, known for its annual challenge where participants write a 50,000-word manuscript in November, argued in its post that condemning AI would ignore issues of class and ability, suggesting the technology could benefit those who might otherwise need to hire human writing assistants or have differing cognitive abilities.
Writers react
After word of the FAQ spread, many writers on social media platforms voiced their opposition to NaNoWriMo’s position. Generative AI models are commonly trained on vast amounts of existing text, including copyrighted works, without attribution or compensation to the original authors. Critics say this raises major ethical questions about using such tools in creative writing competitions and challenges.
“Generative AI empowers not the artist, not the writer, but the tech industry. It steals content to remake content, graverobbing existing material to staple together its Frankensteinian idea of art and story,” wrote Chuck Wendig, the author of Star Wars: Aftermath, in a post about NaNoWriMo on his personal blog.
Daniel José Older, a lead story architect for Star Wars: The High Republic and one of the board members who resigned, wrote on X, “Hello @NaNoWriMo, this is me DJO officially stepping down from your Writers Board and urging every writer I know to do the same. Never use my name in your promo again in fact never say my name at all and never email me again. Thanks!”
In particular, NaNoWriMo’s use of words like “classist” and “ableist” to defend the potential use of generative AI particularly touched a nerve with opponents of generative AI, some of whom say they are disabled themselves.
“A huge middle finger to @NaNoWriMo for this laughable bullshit. Signed, a poor, disabled and chronically ill writer and artist. Miss me by a wide margin with that ableist and privileged bullshit,” wrote one X user. “Other people’s work is NOT accessibility.”
This isn’t the first time the organization has dealt with controversy. Last year, NaNoWriMo announced that it would accept AI-assisted submissions but noted that using AI for an entire novel “would defeat the purpose of the challenge.” Many critics also point out that a NaNoWriMo moderator faced accusations related to child grooming in 2023, which lessened their trust in the organization.
NaNoWriMo doubles down
In response to the backlash, NaNoWriMo updated its FAQ post to address concerns about AI’s impact on the writing industry and to mention “bad actors in the AI space who are doing harm to writers and who are acting unethically.”
We want to make clear that, though we find the categorical condemnation for AI to be problematic for the reasons stated below, we are troubled by situational abuse of AI, and that certain situational abuses clearly conflict with our values. We also want to make clear that AI is a large umbrella technology and that the size and complexity of that category (which includes both non-generative and generative AI, among other uses) contributes to our belief that it is simply too big to categorically endorse or not endorse.
Over the past few years, we’ve received emails from disabled people who frequently use generative AI tools, and we have interviewed a disabled artist, Claire Silver, who uses image synthesis prominently in her work. Some writers with disabilities use tools like ChatGPT to assist them with composition when they have cognitive issues and need assistance expressing themselves.
In June, on Reddit, one user wrote, “As someone with a disability that makes manually typing/writing and wording posts challenging, ChatGPT has been invaluable. It assists me in articulating my thoughts clearly and efficiently, allowing me to participate more actively in various online communities.”
A person with Chiari malformation wrote on Reddit in November 2023 that they use ChatGPT to help them develop software using their voice. “These tools have fundamentally empowered me. The course of my life, my options, opportunities—they’re all better because of this tool,” they wrote.
To opponents of generative AI, the potential benefits that might come to disabled persons do not outweigh what they see as mass plagiarism from tech companies. Also, some artists do not want the time and effort they put into cultivating artistic skills to be devalued for anyone’s benefit.
“All these bullshit appeals from people appropriating social justice language saying, ‘but AI lets me make art when I’m not privileged enough to have the time to develop those skills’ highlights something that needs to be said: you are not entitled to being talented,” posted a writer named Carlos Alonzo Morales on Sunday.
Despite the strong takes, NaNoWriMo has so far stuck to its position of accepting generative AI as a set of potential writing tools in a way that is consistent with its “overall position on nondiscrimination with respect to approaches to creativity, writer’s resources, and personal choice.”
“We absolutely do not condemn AI,” NaNoWriMo wrote in the FAQ post, “and we recognize and respect writers who believe that AI tools are right for them. We recognize that some members of our community stand staunchly against AI for themselves, and that’s perfectly fine. As individuals, we have the freedom to make our own decisions.”
Enlarge/ An ABC handout promotional image for “AI and the Future of Us: An Oprah Winfrey Special.”
On Thursday, ABC announced an upcoming TV special titled, “AI and the Future of Us: An Oprah Winfrey Special.” The one-hour show, set to air on September 12, aims to explore AI’s impact on daily life and will feature interviews with figures in the tech industry, like OpenAI CEO Sam Altman and Bill Gates. Soon after the announcement, some AI critics began questioning the guest list and the framing of the show in general.
“Sure is nice of Oprah to host this extended sales pitch for the generative AI industry at a moment when its fortunes are flagging and the AI bubble is threatening to burst,” tweeted author Brian Merchant, who frequently criticizes generative AI technology in op-eds, social media, and through his “Blood in the Machine” AI newsletter.
“The way the experts who are not experts are presented as such 💀 what a train wreck,” replied artist Karla Ortiz, who is a plaintiff in a lawsuit against several AI companies. “There’s still PLENTY of time to get actual experts and have a better discussion on this because yikes.”
The trailer for Oprah’s upcoming TV special on AI.
On Friday, Ortiz created a lengthy viral thread on X that detailed her potential issues with the program, writing, “This event will be the first time many people will get info on Generative AI. However it is shaping up to be a misinformed marketing event starring vested interests (some who are under a litany of lawsuits) who ignore the harms GenAi inflicts on communities NOW.”
Critics of generative AI like Ortiz question the utility of the technology, its perceived environmental impact, and what they see as blatant copyright infringement. In training AI language models, tech companies like Meta, Anthropic, and OpenAI commonly use copyrighted material gathered without license or owner permission. OpenAI claims that the practice is “fair use.”
Oprah’s guests
According to ABC, the upcoming special will feature “some of the most important and powerful people in AI,” which appears to roughly translate to “famous and publicly visible people related to tech.” Microsoft co-founder Bill Gates, who stepped down as Microsoft CEO 24 years ago, will appear on the show to explore the “AI revolution coming in science, health, and education,” ABC says, and warn of “the once-in-a-century type of impact AI may have on the job market.”
As a guest representing ChatGPT-maker OpenAI, Sam Altman will explain “how AI works in layman’s terms” and discuss “the immense personal responsibility that must be borne by the executives of AI companies.” Karla Ortiz specifically criticized Altman in her thread by saying, “There are far more qualified individuals to speak on what GenAi models are than CEOs. Especially one CEO who recently said AI models will ‘solve all physics.’ That’s an absurd statement and not worthy of your audience.”
In a nod to present-day content creation, YouTube creator Marques Brownlee will appear on the show and reportedly walk Winfrey through “mind-blowing demonstrations of AI’s capabilities.”
Brownlee’s involvement received special attention from some critics online. “Marques Brownlee should be absolutely ashamed of himself,” tweeted PR consultant and frequent AI critic Ed Zitron, who frequently heaps scorn on generative AI in his own newsletter. “What a disgraceful thing to be associated with.”
Other guests include Tristan Harris and Aza Raskin from the Center for Humane Technology, who aim to highlight “emerging risks posed by powerful and superintelligent AI,” an existential risk topic that has its own critics. And FBI Director Christopher Wray will reveal “the terrifying ways criminals and foreign adversaries are using AI,” while author Marilynne Robinson will reflect on “AI’s threat to human values.”
Going only by the publicized guest list, it appears that Oprah does not plan to give voice to prominent non-doomer critics of AI. “This is really disappointing @Oprah and frankly a bit irresponsible to have a one-sided conversation on AI without informed counterarguments from those impacted,” tweeted TV producer Theo Priestley.
Others on the social media network shared similar criticism about a perceived lack of balance in the guest list, including Dr. Margaret Mitchell of Hugging Face. “It could be beneficial to have an AI Oprah follow-up discussion that responds to what happens in [the show] and unpacks generative AI in a more grounded way,” she said.
Oprah’s AI special will air on September 12 on ABC (and a day later on Hulu) in the US, and it will likely elicit further responses from the critics mentioned above. But perhaps that’s exactly how Oprah wants it: “It may fascinate you or scare you,” Winfrey said in a promotional video for the special. “Or, if you’re like me, it may do both. So let’s take a breath and find out more about it.”
On Thursday, OpenAI said that ChatGPT has attracted over 200 million weekly active users, according to a report from Axios, doubling the AI assistant’s user base since November 2023. The company also revealed that 92 percent of Fortune 500 companies are now using its products, highlighting the growing adoption of generative AI tools in the corporate world.
The rapid growth in user numbers for ChatGPT (which is not a new phenomenon for OpenAI) suggests growing interest in—and perhaps reliance on— the AI-powered tool, despite frequent skepticism from some critics of the tech industry.
“Generative AI is a product with no mass-market utility—at least on the scale of truly revolutionary movements like the original cloud computing and smartphone booms,” PR consultant and vocal OpenAI critic Ed Zitron blogged in July. “And it’s one that costs an eye-watering amount to build and run.”
Despite this kind of skepticism (which raises legitimate questions about OpenAI’s long-term viability), OpenAI claims that people are using ChatGPT and OpenAI’s services in record numbers. One reason for the apparent dissonance is that ChatGPT users might not readily admit to using it due to organizational prohibitions against generative AI.
Wharton professor Ethan Mollick, who commonly explores novel applications of generative AI on social media, tweeted Thursday about this issue. “Big issue in organizations: They have put together elaborate rules for AI use focused on negative use cases,” he wrote. “As a result, employees are too scared to talk about how they use AI, or to use corporate LLMs. They just become secret cyborgs, using their own AI & not sharing knowledge”
The new prohibition era
It’s difficult to get hard numbers showing the number of companies with AI prohibitions in place, but a Cisco study released in January claimed that 27 percent of organizations in their study had banned generative AI use. Last August, ZDNet reported on a BlackBerry study that said 75 percent of businesses worldwide were “implementing or considering” plans to ban ChatGPT and other AI apps.
As an example, Ars Technica’s parent company Condé Nast maintains a no-AI policy related to creating public-facing content with generative AI tools.
Prohibitions aren’t the only issue complicating public admission of generative AI use. Social stigmas have been developing around generative AI technology that stem from job loss anxiety, potential environmental impact, privacy issues, IP and ethical issues, security concerns, fear of a repeat of cryptocurrency-like grifts, and a general wariness of Big Tech that some claim has been steadily rising over recent years.
Whether the current stigmas around generative AI use will break down over time remains to be seen, but for now, OpenAI’s management is taking a victory lap. “People are using our tools now as a part of their daily lives, making a real difference in areas like healthcare and education,” OpenAI CEO Sam Altman told Axios in a statement, “whether it’s helping with routine tasks, solving hard problems, or unlocking creativity.”
Not the only game in town
OpenAI also told Axios that usage of its AI language model APIs has doubled since the release of GPT-4o mini in July. This suggests software developers are increasingly integrating OpenAI’s large language model (LLM) tech into their apps.
And OpenAI is not alone in the field. Companies like Microsoft (with Copilot, based on OpenAI’s technology), Google (with Gemini), Meta (with Llama), and Anthropic (Claude) are all vying for market share, frequently updating their APIs and consumer-facing AI assistants to attract new users.
If the generative AI space is a market bubble primed to pop, as some have claimed, it is a very big and expensive one that is apparently still growing larger by the day.
Enlarge/ A man peers over a glass partition, seeking transparency.
The Open Source Initiative (OSI) recently unveiled its latest draft definition for “open source AI,” aiming to clarify the ambiguous use of the term in the fast-moving field. The move comes as some companies like Meta release trained AI language model weights and code with usage restrictions while using the “open source” label. This has sparked intense debates among free-software advocates about what truly constitutes “open source” in the context of AI.
For instance, Meta’s Llama 3 model, while freely available, doesn’t meet the traditional open source criteria as defined by the OSI for software because it imposes license restrictions on usage due to company size or what type of content is produced with the model. The AI image generator Flux is another “open” model that is not truly open source. Because of this type of ambiguity, we’ve typically described AI models that include code or weights with restrictions or lack accompanying training data with alternative terms like “open-weights” or “source-available.”
To address the issue formally, the OSI—which is well-known for its advocacy for open software standards—has assembled a group of about 70 participants, including researchers, lawyers, policymakers, and activists. Representatives from major tech companies like Meta, Google, and Amazon also joined the effort. The group’s current draft (version 0.0.9) definition of open source AI emphasizes “four fundamental freedoms” reminiscent of those defining free software: giving users of the AI system permission to use it for any purpose without permission, study how it works, modify it for any purpose, and share with or without modifications.
By establishing clear criteria for open source AI, the organization hopes to provide a benchmark against which AI systems can be evaluated. This will likely help developers, researchers, and users make more informed decisions about the AI tools they create, study, or use.
Truly open source AI may also shed light on potential software vulnerabilities of AI systems, since researchers will be able to see how the AI models work behind the scenes. Compare this approach with an opaque system such as OpenAI’s ChatGPT, which is more than just a GPT-4o large language model with a fancy interface—it’s a proprietary system of interlocking models and filters, and its precise architecture is a closely guarded secret.
OSI’s project timeline indicates that a stable version of the “open source AI” definition is expected to be announced in October at the All Things Open 2024 event in Raleigh, North Carolina.
“Permissionless innovation”
In a press release from May, the OSI emphasized the importance of defining what open source AI really means. “AI is different from regular software and forces all stakeholders to review how the Open Source principles apply to this space,” said Stefano Maffulli, executive director of the OSI. “OSI believes that everybody deserves to maintain agency and control of the technology. We also recognize that markets flourish when clear definitions promote transparency, collaboration and permissionless innovation.”
The organization’s most recent draft definition extends beyond just the AI model or its weights, encompassing the entire system and its components.
For an AI system to qualify as open source, it must provide access to what the OSI calls the “preferred form to make modifications.” This includes detailed information about the training data, the full source code used for training and running the system, and the model weights and parameters. All these elements must be available under OSI-approved licenses or terms.
Notably, the draft doesn’t mandate the release of raw training data. Instead, it requires “data information”—detailed metadata about the training data and methods. This includes information on data sources, selection criteria, preprocessing techniques, and other relevant details that would allow a skilled person to re-create a similar system.
The “data information” approach aims to provide transparency and replicability without necessarily disclosing the actual dataset, ostensibly addressing potential privacy or copyright concerns while sticking to open source principles, though that particular point may be up for further debate.
“The most interesting thing about [the definition] is that they’re allowing training data to NOT be released,” said independent AI researcher Simon Willison in a brief Ars interview about the OSI’s proposal. “It’s an eminently pragmatic approach—if they didn’t allow that, there would be hardly any capable ‘open source’ models.”
On Tuesday, OpenAI announced a partnership with Ars Technica parent company Condé Nast to display content from prominent publications within its AI products, including ChatGPT and a new SearchGPT prototype. It also allows OpenAI to use Condé content to train future AI language models. The deal covers well-known Condé brands such as Vogue, The New Yorker, GQ, Wired, Ars Technica, and others. Financial details were not disclosed.
One immediate effect of the deal will be that users of ChatGPT or SearchGPT will now be able to see information from Condé Nast publications pulled from those assistants’ live views of the web. For example, a user could ask ChatGPT, “What’s the latest Ars Technica article about Space?” and ChatGPT can browse the web and pull up the result, attribute it, and summarize it for users while also linking to the site.
In the longer term, the deal also means that OpenAI can openly and officially utilize Condé Nast articles to train future AI language models, which includes successors to GPT-4o. In this case, “training” means feeding content into an AI model’s neural network so the AI model can better process conceptual relationships.
AI training is an expensive and computationally intense process that happens rarely, usually prior to the launch of a major new AI model, although a secondary process called “fine-tuning” can continue over time. Having access to high-quality training data, such as vetted journalism, improves AI language models’ ability to provide accurate answers to user questions.
It’s worth noting that Condé Nast internal policy still forbids its publications from using text created by generative AI, which is consistent with its AI rules before the deal.
Not waiting on fair use
With the deal, Condé Nast joins a growing list of publishers partnering with OpenAI, including Associated Press, Axel Springer, The Atlantic, and others. Some publications, such as The New York Times, have chosen to sue OpenAI over content use, and there’s reason to think they could win.
In an internal email to Condé Nast staff, CEO Roger Lynch framed the multi-year partnership as a strategic move to expand the reach of the company’s content, adapt to changing audience behaviors, and ensure proper compensation and attribution for using the company’s IP. “This partnership recognizes that the exceptional content produced by Condé Nast and our many titles cannot be replaced,” Lynch wrote in the email, “and is a step toward making sure our technology-enabled future is one that is created responsibly.”
The move also brings additional revenue to Condé Nast, Lynch added, at a time when “many technology companies eroded publishers’ ability to monetize content, most recently with traditional search.” The deal will allow Condé to “continue to protect and invest in our journalism and creative endeavors,” Lynch wrote.
OpenAI COO Brad Lightcap said in a statement, “We’re committed to working with Condé Nast and other news publishers to ensure that as AI plays a larger role in news discovery and delivery, it maintains accuracy, integrity, and respect for quality reporting.”
Over the past week, OpenAI experienced a significant leadership shake-up as three key figures announced major changes. Greg Brockman, the company’s president and co-founder, is taking an extended sabbatical until the end of the year, while another co-founder, John Schulman, permanently departed for rival Anthropic. Peter Deng, VP of Consumer Product, has also left the ChatGPT maker.
In a post on X, Brockman wrote, “I’m taking a sabbatical through end of year. First time to relax since co-founding OpenAI 9 years ago. The mission is far from complete; we still have a safe AGI to build.”
The moves have led some to wonder just how close OpenAI is to a long-rumored breakthrough of some kind of reasoning artificial intelligence if high-profile employees are jumping ship (or taking long breaks, in the case of Brockman) so easily. As AI developer Benjamin De Kraker put it on X, “If OpenAI is right on the verge of AGI, why do prominent people keep leaving?”
AGI refers to a hypothetical AI system that could match human-level intelligence across a wide range of tasks without specialized training. It’s the ultimate goal of OpenAI, and company CEO Sam Altman has said it could emerge in the “reasonably close-ish future.” AGI is also a concept that has sparked concerns about potential existential risks to humanity and the displacement of knowledge workers. However, the term remains somewhat vague, and there’s considerable debate in the AI community about what truly constitutes AGI or how close we are to achieving it.
The emergence of the “next big thing” in AI has been seen by critics such as Ed Zitron as a necessary step to justify ballooning investments in AI models that aren’t yet profitable. The industry is holding its breath that OpenAI, or a competitor, has some secret breakthrough waiting in the wings that will justify the massive costs associated with training and deploying LLMs.
But other AI critics, such as Gary Marcus, have postulated that major AI companies have reached a plateau of large language model (LLM) capability centered around GPT-4-level models since no AI company has yet made a major leap past the groundbreaking LLM that OpenAI released in March 2023. Microsoft CTO Kevin Scott has countered these claims, saying that LLM “scaling laws” (that suggest LLMs increase in capability proportionate to more compute power thrown at them) will continue to deliver improvements over time and that more patience is needed as the next generation (say, GPT-5) undergoes training.
In the scheme of things, Brockman’s move sounds like an extended, long overdue vacation (or perhaps a period to deal with personal issues beyond work). Regardless of the reason, the duration of the sabbatical raises questions about how the president of a major tech company can suddenly disappear for four months without affecting day-to-day operations, especially during a critical time in its history.
Unless, of course, things are fairly calm at OpenAI—and perhaps GPT-5 isn’t going to ship until at least next year when Brockman returns. But this is speculation on our part, and OpenAI (whether voluntarily or not) sometimes surprises us when we least expect it. (Just today, Altman dropped a hint on X about strawberries that some people interpret as being a hint of a potential major model undergoing testing or nearing release.)
A pattern of departures and the rise of Anthropic
Anthropic / Benj Edwards
What may sting OpenAI the most about the recent departures is that a few high-profile employees have left to join Anthropic, a San Francisco-based AI company founded in 2021 by ex-OpenAI employees Daniela and Dario Amodei.
Anthropic offers a subscription service called Claude.ai that is similar to ChatGPT. Its most recent LLM, Claude 3.5 Sonnet, along with its web-based interface, has rapidly gained favor over ChatGPT among some LLM users who are vocal on social media, though it likely does not yet match ChatGPT in terms of mainstream brand recognition.
In particular, John Schulman, an OpenAI co-founder and key figure in the company’s post-training process for LLMs, revealed in a statement on X that he’s leaving to join rival AI firm Anthropic to do more hands-on work: “This choice stems from my desire to deepen my focus on AI alignment, and to start a new chapter of my career where I can return to hands-on technical work.” Alignment is a field that hopes to guide AI models to produce helpful outputs.
In May, OpenAI alignment researcher Jan Leike left OpenAI to join Anthropic as well, criticizing OpenAI’s handling of alignment safety.
Adding to the recent employee shake-up, The Information reports that Peter Deng, a product leader who joined OpenAI last year after stints at Meta Platforms, Uber, and Airtable, has also left the company, though we do not yet know where he is headed. In May, OpenAI co-founder Ilya Sutskever left to found a rival startup, and prominent software engineer Andrej Karpathy departed in February, recently launching an educational venture.
As De Kraker noted, if OpenAI were on the verge of developing world-changing AI technology, wouldn’t these high-profile AI veterans want to stick around and be part of this historic moment in time? “Genuine question,” he wrote. “If you were pretty sure the company you’re a key part of—and have equity in—is about to crack AGI within one or two years… why would you jump ship?”
Despite the departures, Schulman expressed optimism about OpenAI’s future in his farewell note on X. “I am confident that OpenAI and the teams I was part of will continue to thrive without me,” he wrote. “I’m incredibly grateful for the opportunity to participate in such an important part of history and I’m proud of what we’ve achieved together. I’ll still be rooting for you all, even while working elsewhere.”
This article was updated on August 7, 2024 at 4: 23 PM to mention Sam Altman’s tweet about strawberries.
Enlarge/ A stock photo of a robot whispering to a man.
On Tuesday, OpenAI began rolling out an alpha version of its new Advanced Voice Mode to a small group of ChatGPT Plus subscribers. This feature, which OpenAI previewed in May with the launch of GPT-4o, aims to make conversations with the AI more natural and responsive. In May, the feature triggered criticism of its simulated emotional expressiveness and prompted a public dispute with actress Scarlett Johansson over accusations that OpenAI copied her voice. Even so, early tests of the new feature shared by users on social media have been largely enthusiastic.
In early tests reported by users with access, Advanced Voice Mode allows them to have real-time conversations with ChatGPT, including the ability to interrupt the AI mid-sentence almost instantly. It can sense and respond to a user’s emotional cues through vocal tone and delivery, and provide sound effects while telling stories.
But what has caught many people off-guard initially is how the voices simulate taking a breath while speaking.
“ChatGPT Advanced Voice Mode counting as fast as it can to 10, then to 50 (this blew my mind—it stopped to catch its breath like a human would),” wrote tech writer Cristiano Giardina on X.
Advanced Voice Mode simulates audible pauses for breath because it was trained on audio samples of humans speaking that included the same feature. The model has learned to simulate inhalations at seemingly appropriate times after being exposed to hundreds of thousands, if not millions, of examples of human speech. Large language models (LLMs) like GPT-4o are master imitators, and that skill has now extended to the audio domain.
Giardina shared his other impressions about Advanced Voice Mode on X, including observations about accents in other languages and sound effects.
“It’s very fast, there’s virtually no latency from when you stop speaking to when it responds,” he wrote. “When you ask it to make noises it always has the voice “perform” the noises (with funny results). It can do accents, but when speaking other languages it always has an American accent. (In the video, ChatGPT is acting as a soccer match commentator)“
Speaking of sound effects, X user Kesku, who is a moderator of OpenAI’s Discord server, shared an example of ChatGPT playing multiple parts with different voices and another of a voice recounting an audiobook-sounding sci-fi story from the prompt, “Tell me an exciting action story with sci-fi elements and create atmosphere by making appropriate noises of the things happening using onomatopoeia.”
Kesku also ran a few example prompts for us, including a story about the Ars Technica mascot “Moonshark.”
He also asked it to sing the “Major-General’s Song” from Gilbert and Sullivan’s 1879 comic opera The Pirates of Penzance:
Frequent AI advocate Manuel Sainsily posted a video of Advanced Voice Mode reacting to camera input, giving advice about how to care for a kitten. “It feels like face-timing a super knowledgeable friend, which in this case was super helpful—reassuring us with our new kitten,” he wrote. “It can answer questions in real-time and use the camera as input too!”
Of course, being based on an LLM, it may occasionally confabulate incorrect responses on topics or in situations where its “knowledge” (which comes from GPT-4o’s training data set) is lacking. But if considered a tech demo or an AI-powered amusement and you’re aware of the limitations, Advanced Voice Mode seems to successfully execute many of the tasks shown by OpenAI’s demo in May.
Safety
An OpenAI spokesperson told Ars Technica that the company worked with more than 100 external testers on the Advanced Voice Mode release, collectively speaking 45 different languages and representing 29 geographical areas. The system is reportedly designed to prevent impersonation of individuals or public figures by blocking outputs that differ from OpenAI’s four chosen preset voices.
OpenAI has also added filters to recognize and block requests to generate music or other copyrighted audio, which has gotten other AI companies in trouble. Giardina reported audio “leakage” in some audio outputs that have unintentional music in the background, showing that OpenAI trained the AVM voice model on a wide variety of audio sources, likely both from licensed material and audio scraped from online video platforms.
Availability
OpenAI plans to expand access to more ChatGPT Plus users in the coming weeks, with a full launch to all Plus subscribers expected this fall. A company spokesperson told Ars that users in the alpha test group will receive a notice in the ChatGPT app and an email with usage instructions.
Since the initial preview of GPT-4o voice in May, OpenAI claims to have enhanced the model’s ability to support millions of simultaneous, real-time voice conversations while maintaining low latency and high quality. In other words, they are gearing up for a rush that will take a lot of back-end computation to accommodate.
Arguably, few companies have unintentionally contributed more to the increase of AI-generated noise online than OpenAI. Despite its best intentions—and against its terms of service—its AI language models are often used to compose spam, and its pioneering research has inspired others to build AI models that can potentially do the same. This influx of AI-generated content has further reduced the effectiveness of SEO-driven search engines like Google. In 2024, web search is in a sorry state indeed.
It’s interesting, then, that OpenAI is now offering a potential solution to that problem. On Thursday, OpenAI revealed a prototype AI-powered search engine called SearchGPT that aims to provide users with quick, accurate answers sourced from the web. It’s also a direct challenge to Google, which also has tried to apply generative AI to web search (but with little success).
The company says it plans to integrate the most useful aspects of the temporary prototype into ChatGPT in the future. ChatGPT can already perform web searches using Bing, but SearchGPT seems to be a purpose-built interface for AI-assisted web searching.
SearchGPT attempts to streamline the process of finding information online by combining OpenAI’s AI models (like GPT-4o) with real-time web data. Like ChatGPT, users can reportedly ask SearchGPT follow-up questions, with the AI model maintaining context throughout the conversation.
Perhaps most importantly from an accuracy standpoint, the SearchGPT prototype (which we have not tested ourselves) reportedly includes features that attribute web-based sources prominently. Responses include in-line citations and links, while a sidebar displays additional source links.
OpenAI has not yet said how it is obtaining its real-time web data and whether it’s partnering with an existing search engine provider (like it does currently with Bing for ChatGPT) or building its own web-crawling and indexing system.
A way around publishers blocking OpenAI
ChatGPT can already perform web searches using Bing, but since last August when OpenAI revealed a way to block its web crawler, that feature hasn’t been nearly as useful as it could be. Many sites, such as Ars Technica (which blocks the OpenAI crawler as part of our parent company’s policy), won’t show up as results in ChatGPT because of this.
SearchGPT appears to untangle the association between OpenAI’s web crawler for scraping training data and the desire for OpenAI chatbot users to search the web. Notably, in the new SearchGPT announcement, OpenAI says, “Sites can be surfaced in search results even if they opt out of generative AI training.”
Even so, OpenAI says it is working on a way for publishers to manage how they appear in SearchGPT results so that “publishers have more choices.” And the company says that SearchGPT’s ability to browse the web is separate from training OpenAI’s AI models.
An uncertain future for AI-powered search
OpenAI claims SearchGPT will make web searches faster and easier. However, the effectiveness of AI-powered search compared to traditional methods is unknown, as the tech is still in its early stages. But let’s be frank: The most prominent web-search engine right now is pretty terrible.
Over the past year, we’ve seen Perplexity.ai take off as a potential AI-powered Google search replacement, but the service has been hounded by issues with confabulations and accusations of plagiarism among publishers, including Ars Technica parent Condé Nast.
Unlike Perplexity, OpenAI has many content deals lined up with publishers, and it emphasizes that it wants to work with content creators in particular. “We are committed to a thriving ecosystem of publishers and creators,” says OpenAI in its news release. “We hope to help users discover publisher sites and experiences, while bringing more choice to search.”
In a statement for the OpenAI press release, Nicholas Thompson, CEO of The Atlantic (which has a content deal with OpenAI), expressed optimism about the potential of AI search: “AI search is going to become one of the key ways that people navigate the internet, and it’s crucial, in these early days, that the technology is built in a way that values, respects, and protects journalism and publishers,” he said. “We look forward to partnering with OpenAI in the process, and creating a new way for readers to discover The Atlantic.”
OpenAI has experimented with other offshoots of its AI language model technology that haven’t become blockbuster hits (most notably, GPTs come to mind), so time will tell if the techniques behind SearchGPT have staying power—and if it can deliver accurate results without hallucinating. But the current state of web search is inviting new experiments to separate the signal from the noise, and it looks like OpenAI is throwing its hat in the ring.
OpenAI is currently rolling out SearchGPT to a small group of users and publishers for testing and feedback. Those interested in trying the prototype can sign up for a waitlist on the company’s website.
Enlarge/ Elon Musk, chief executive officer of Tesla Inc., during a fireside discussion on artificial intelligence risks with Rishi Sunak, UK prime minister, in London, UK, on Thursday, Nov. 2, 2023.
On Monday, Elon Musk announced the start of training for what he calls “the world’s most powerful AI training cluster” at xAI’s new supercomputer facility in Memphis, Tennessee. The billionaire entrepreneur and CEO of multiple tech companies took to X (formerly Twitter) to share that the so-called “Memphis Supercluster” began operations at approximately 4: 20 am local time that day.
Musk’s xAI team, in collaboration with X and Nvidia, launched the supercomputer cluster featuring 100,000 liquid-cooled H100 GPUs on a single RDMA fabric. This setup, according to Musk, gives xAI “a significant advantage in training the world’s most powerful AI by every metric by December this year.”
Given issues with xAI’s Grok chatbot throughout the year, skeptics would be justified in questioning whether those claims will match reality, especially given Musk’s tendency for grandiose, off-the-cuff remarks on the social media platform he runs.
Power issues
According to a report by News Channel 3 WREG Memphis, the startup of the massive AI training facility marks a milestone for the city. WREG reports that xAI’s investment represents the largest capital investment by a new company in Memphis’s history. However, the project has raised questions among local residents and officials about its impact on the area’s power grid and infrastructure.
WREG reports that Doug McGowen, president of Memphis Light, Gas and Water (MLGW), previously stated that xAI could consume up to 150 megawatts of power at peak times. This substantial power requirement has prompted discussions with the Tennessee Valley Authority (TVA) regarding the project’s electricity demands and connection to the power system.
The TVA told the local news station, “TVA does not have a contract in place with xAI. We are working with xAI and our partners at MLGW on the details of the proposal and electricity demand needs.”
The local news outlet confirms that MLGW has stated that xAI moved into an existing building with already existing utility services, but the full extent of the company’s power usage and its potential effects on local utilities remain unclear. To address community concerns, WREG reports that MLGW plans to host public forums in the coming days to provide more information about the project and its implications for the city.
For now, Tom’s Hardware reports that Musk is side-stepping power issues by installing a fleet of 14 VoltaGrid natural gas generators that provide supplementary power to the Memphis computer cluster while his company works out an agreement with the local power utility.
As training at the Memphis Supercluster gets underway, all eyes are on xAI and Musk’s ambitious goal of developing the world’s most powerful AI by the end of the year (by which metric, we are uncertain), given the competitive landscape in AI at the moment between OpenAI/Microsoft, Amazon, Apple, Anthropic, and Google. If such an AI model emerges from xAI, we’ll be ready to write about it.
This article was updated on July 24, 2024 at 1: 11 pm to mention Musk installing natural gas generators onsite in Memphis.
In the AI world, there’s a buzz in the air about a new AI language model released Tuesday by Meta: Llama 3.1 405B. The reason? It’s potentially the first time anyone can download a GPT-4-class large language model (LLM) for free and run it on their own hardware. You’ll still need some beefy hardware: Meta says it can run on a “single server node,” which isn’t desktop PC-grade equipment. But it’s a provocative shot across the bow of “closed” AI model vendors such as OpenAI and Anthropic.
“Llama 3.1 405B is the first openly available model that rivals the top AI models when it comes to state-of-the-art capabilities in general knowledge, steerability, math, tool use, and multilingual translation,” says Meta. Company CEO Mark Zuckerberg calls 405B “the first frontier-level open source AI model.”
In the AI industry, “frontier model” is a term for an AI system designed to push the boundaries of current capabilities. In this case, Meta is positioning 405B among the likes of the industry’s top AI models, such as OpenAI’s GPT-4o, Claude’s 3.5 Sonnet, and Google Gemini 1.5 Pro.
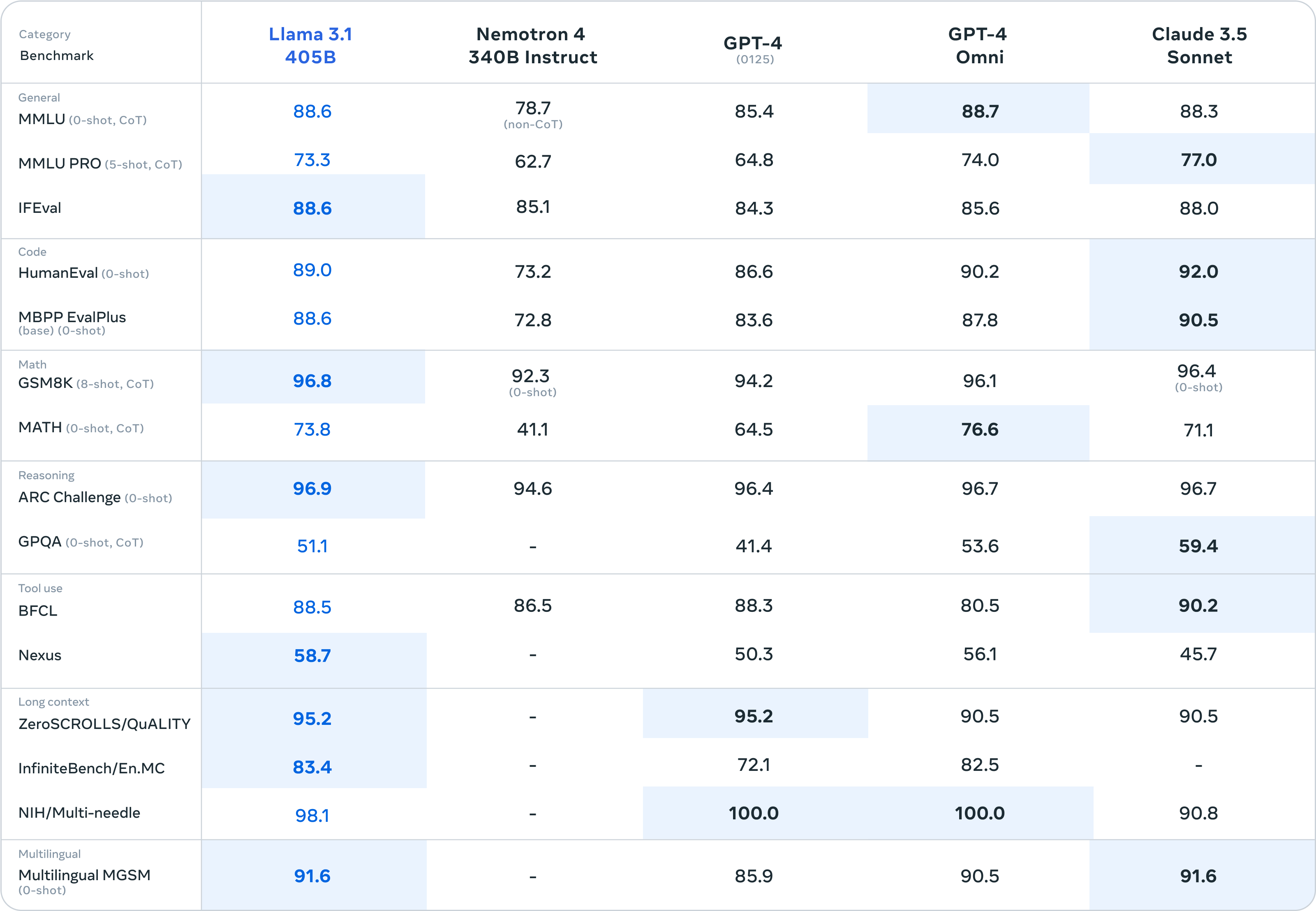
A chart published by Meta suggests that 405B gets very close to matching the performance of GPT-4 Turbo, GPT-4o, and Claude 3.5 Sonnet in benchmarks like MMLU (undergraduate level knowledge), GSM8K (grade school math), and HumanEval (coding).
But as we’ve noted many times since March, these benchmarks aren’t necessarily scientifically sound or translate to the subjective experience of interacting with AI language models. In fact, this traditional slate of AI benchmarks is so generally useless to laypeople that even Meta’s PR department now just posts a few images of charts and doesn’t even try to explain them in any detail.
Enlarge/ A Meta-provided chart that shows Llama 3.1 405B benchmark results versus other major AI models.
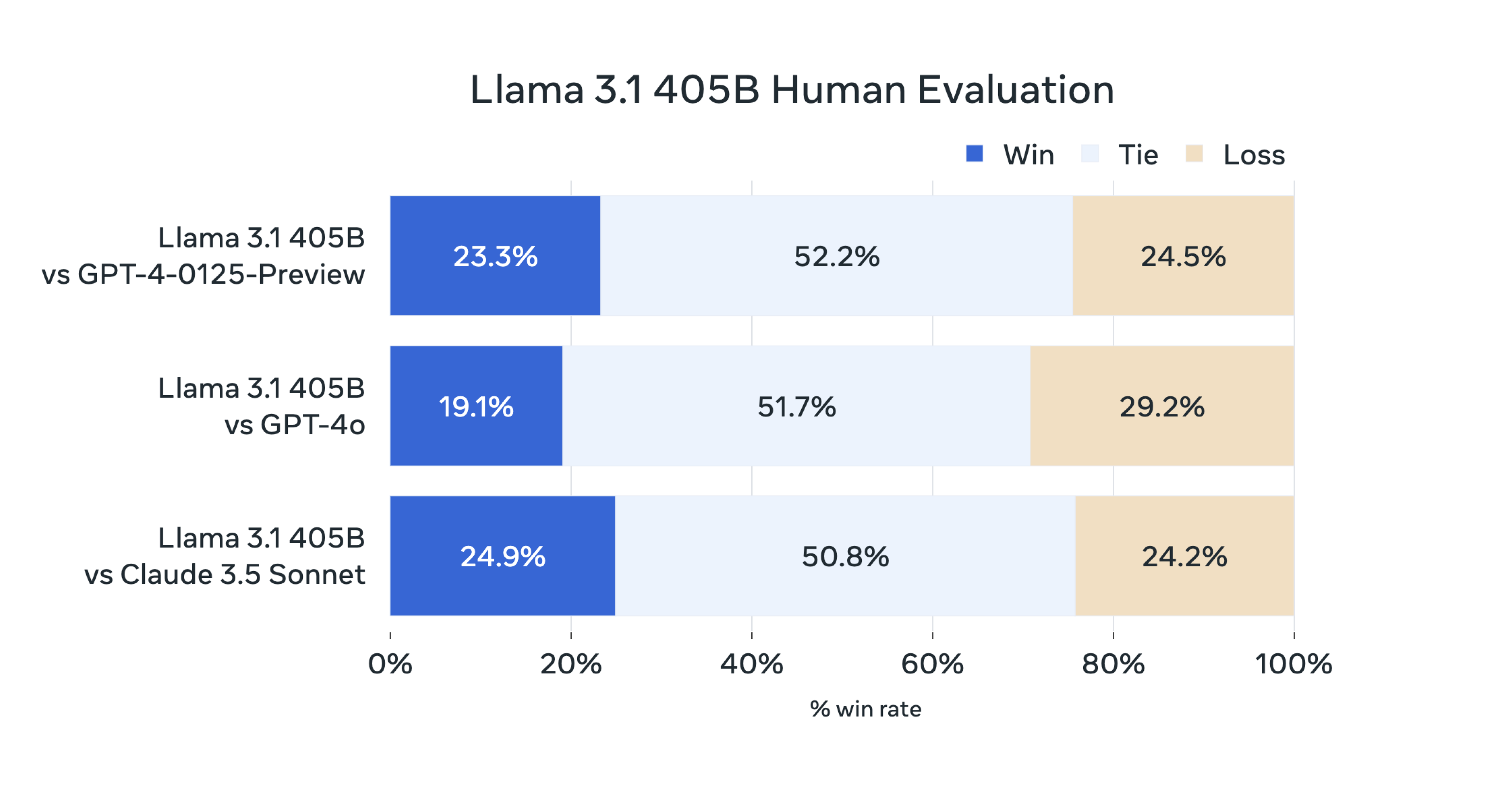
We’ve instead found that measuring the subjective experience of using a conversational AI model (through what might be called “vibemarking”) on A/B leaderboards like Chatbot Arena is a better way to judge new LLMs. In the absence of Chatbot Arena data, Meta has provided the results of its own human evaluations of 405B’s outputs that seem to show Meta’s new model holding its own against GPT-4 Turbo and Claude 3.5 Sonnet.
Enlarge/ A Meta-provided chart that shows how humans rated Llama 3.1 405B’s outputs compared to GPT-4 Turbo, GPT-4o, and Claude 3.5 Sonnet in its own studies.
Whatever the benchmarks, early word on the street (after the model leaked on 4chan yesterday) seems to match the claim that 405B is roughly equivalent to GPT-4. It took a lot of expensive computer training time to get there—and money, of which the social media giant has plenty to burn. Meta trained the 405B model on over 15 trillion tokens of training data scraped from the web (then parsed, filtered, and annotated by Llama 2), using more than 16,000 H100 GPUs.
So what’s with the 405B name? In this case, “405B” means 405 billion parameters, and parameters are numerical values that store trained information in a neural network. More parameters translate to a larger neural network powering the AI model, which generally (but not always) means more capability, such as better ability to make contextual connections between concepts. But larger-parameter models have a tradeoff in needing more computing power (AKA “compute”) to run.
We’ve been expecting the release of a 400 billion-plus parameter model of the Llama 3 family since Meta gave word that it was training one in April, and today’s announcement isn’t just about the biggest member of the Llama 3 family: There’s an entirely new iteration of improved Llama models with the designation “Llama 3.1.” That includes upgraded versions of its smaller 8B and 70B models, which now feature multilingual support and an extended context length of 128,000 tokens (the “context length” is roughly the working memory capacity of the model, and “tokens” are chunks of data used by LLMs to process information).
Meta says that 405B is useful for long-form text summarization, multilingual conversational agents, and coding assistants and for creating synthetic data used to train future AI language models. Notably, that last use-case—allowing developers to use outputs from Llama models to improve other AI models—is now officially supported by Meta’s Llama 3.1 license for the first time.
Abusing the term “open source”
Llama 3.1 405B is an open-weights model, which means anyone can download the trained neural network files and run them or fine-tune them. That directly challenges a business model where companies like OpenAI keep the weights to themselves and instead monetize the model through subscription wrappers like ChatGPT or charge for access by the token through an API.
Fighting the “closed” AI model is a big deal to Mark Zuckerberg, who simultaneously released a 2,300-word manifesto today on why the company believes in open releases of AI models, titled, “Open Source AI Is the Path Forward.” More on the terminology in a minute. But briefly, he writes about the need for customizable AI models that offer user control and encourage better data security, higher cost-efficiency, and better future-proofing, as opposed to vendor-locked solutions.
All that sounds reasonable, but undermining your competitors using a model subsidized by a social media war chest is also an efficient way to play spoiler in a market where you might not always win with the most cutting-edge tech. That benefits Meta, Zuckerberg says, because he doesn’t want to get locked into a system where companies like his have to pay a toll to access AI capabilities, drawing comparisons to “taxes” Apple levies on developers through its App Store.
Enlarge/ A screenshot of Mark Zuckerberg’s essay, “Open Source AI Is the Path Forward,” published on July 23, 2024.
So, about that “open source” term. As we first wrote in an update to our Llama 2 launch article a year ago, “open source” has a very particular meaning that has traditionally been defined by the Open Source Initiative. The AI industry has not yet settled on terminology for AI model releases that ship either code or weights with restrictions (such as Llama 3.1) or that ship without providing training data. We’ve been calling these releases “open weights” instead.
Unfortunately for terminology sticklers, Zuckerberg has now baked the erroneous “open source” label into the title of his potentially historic aforementioned essay on open AI releases, so fighting for the correct term in AI may be a losing battle. Still, his usage annoys people like independent AI researcher Simon Willison, who likes Zuckerberg’s essay otherwise.
“I see Zuck’s prominent misuse of ‘open source’ as a small-scale act of cultural vandalism,” Willison told Ars Technica. “Open source should have an agreed meaning. Abusing the term weakens that meaning which makes the term less generally useful, because if someone says ‘it’s open source,’ that no longer tells me anything useful. I have to then dig in and figure out what they’re actually talking about.”
The Llama 3.1 models are available for download through Meta’s own website and on Hugging Face. They both require providing contact information and agreeing to a license and an acceptable use policy, which means that Meta can technically legally pull the rug out from under your use of Llama 3.1 or its outputs at any time.
OpenAI recently unveiled a five-tier system to gauge its advancement toward developing artificial general intelligence (AGI), according to an OpenAI spokesperson who spoke with Bloomberg. The company shared this new classification system on Tuesday with employees during an all-hands meeting, aiming to provide a clear framework for understanding AI advancement. However, the system describes hypothetical technology that does not yet exist and is possibly best interpreted as a marketing move to garner investment dollars.
OpenAI has previously stated that AGI—a nebulous term for a hypothetical concept that means an AI system that can perform novel tasks like a human without specialized training—is currently the primary goal of the company. The pursuit of technology that can replace humans at most intellectual work drives most of the enduring hype over the firm, even though such a technology would likely be wildly disruptive to society.
OpenAI CEO Sam Altman has previously stated his belief that AGI could be achieved within this decade, and a large part of the CEO’s public messaging has been related to how the company (and society in general) might handle the disruption that AGI may bring. Along those lines, a ranking system to communicate AI milestones achieved internally on the path to AGI makes sense.
OpenAI’s five levels—which it plans to share with investors—range from current AI capabilities to systems that could potentially manage entire organizations. The company believes its technology (such as GPT-4o that powers ChatGPT) currently sits at Level 1, which encompasses AI that can engage in conversational interactions. However, OpenAI executives reportedly told staff they’re on the verge of reaching Level 2, dubbed “Reasoners.”
Bloomberg lists OpenAI’s five “Stages of Artificial Intelligence” as follows:
Level 1: Chatbots, AI with conversational language
Level 2: Reasoners, human-level problem solving
Level 3: Agents, systems that can take actions
Level 4: Innovators, AI that can aid in invention
Level 5: Organizations, AI that can do the work of an organization
A Level 2 AI system would reportedly be capable of basic problem-solving on par with a human who holds a doctorate degree but lacks access to external tools. During the all-hands meeting, OpenAI leadership reportedly demonstrated a research project using their GPT-4 model that the researchers believe shows signs of approaching this human-like reasoning ability, according to someone familiar with the discussion who spoke with Bloomberg.
The upper levels of OpenAI’s classification describe increasingly potent hypothetical AI capabilities. Level 3 “Agents” could work autonomously on tasks for days. Level 4 systems would generate novel innovations. The pinnacle, Level 5, envisions AI managing entire organizations.
This classification system is still a work in progress. OpenAI plans to gather feedback from employees, investors, and board members, potentially refining the levels over time.
Ars Technica asked OpenAI about the ranking system and the accuracy of the Bloomberg report, and a company spokesperson said they had “nothing to add.”
The problem with ranking AI capabilities
OpenAI isn’t alone in attempting to quantify levels of AI capabilities. As Bloomberg notes, OpenAI’s system feels similar to levels of autonomous driving mapped out by automakers. And in November 2023, researchers at Google DeepMind proposed their own five-level framework for assessing AI advancement, showing that other AI labs have also been trying to figure out how to rank things that don’t yet exist.
OpenAI’s classification system also somewhat resembles Anthropic’s “AI Safety Levels” (ASLs) first published by the maker of the Claude AI assistant in September 2023. Both systems aim to categorize AI capabilities, though they focus on different aspects. Anthropic’s ASLs are more explicitly focused on safety and catastrophic risks (such as ASL-2, which refers to “systems that show early signs of dangerous capabilities”), while OpenAI’s levels track general capabilities.
However, any AI classification system raises questions about whether it’s possible to meaningfully quantify AI progress and what constitutes an advancement (or even what constitutes a “dangerous” AI system, as in the case of Anthropic). The tech industry so far has a history of overpromising AI capabilities, and linear progression models like OpenAI’s potentially risk fueling unrealistic expectations.
There is currently no consensus in the AI research community on how to measure progress toward AGI or even if AGI is a well-defined or achievable goal. As such, OpenAI’s five-tier system should likely be viewed as a communications tool to entice investors that shows the company’s aspirational goals rather than a scientific or even technical measurement of progress.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}