The CCIA added that “the Piracy Shield raises a significant number of concerns which can inadvertently affect legitimate online services, primarily due to the potential for overblocking.” The letter said that in October 2024, “Google Drive was mistakenly blocked by the Piracy Shield system, causing a three-hour blackout for all Italian users, while 13.5 percent of users were still blocked at the IP level, and 3 percent were blocked at the DNS level after 12 hours.”
The Italian system “aims to automate the blocking process by allowing rights holders to submit IP addresses directly through the platform, following which ISPs have to implement a block,” the CCIA said. “Verification procedures between submission and blocking are not clear, and indeed seem to be lacking. Additionally, there is a total lack of redress mechanisms for affected parties, in case a wrong domain or IP address is submitted and blocked.”
The 30-minute blocking window “leaves extremely limited time for careful verification by ISPs that the submitted destination is indeed being used for piracy purposes,” the CCIA said. The trade group also questioned the piracy-reporting system’s ties to the organization that runs Italy’s top football league.
“Additionally, the fact that the Piracy Shield platform was developed for AGCOM by a company affiliated with Lega Serie A, which is one of the very few entities authorized to report, raises serious questions about the potential conflict of interest exacerbating the lack of transparency issue,” the letter said.
A trade group for Italian ISPs has argued that the law requires “filtering and tasks that collide with individual freedoms” and is contrary to European legislation that classifies broadband network services as mere conduits that are exempt from liability.
“On the contrary, in Italy criminal liability has been expressly established for ISPs,” Dalia Coffetti, head of regulatory and EU affairs at the Association of Italian Internet Providers, wrote in April 2025. Coffetti argued, “There are better tools to fight piracy, including criminal Law, cooperation between States, and digital solutions that downgrade the quality of the signal broadcast via illegal streaming websites or IPtv. European ISPs are ready to play their part in the battle against piracy, but the solution certainly does not lie in filtering and blocking IP addresses.”
About 20 percent of the web relies on Cloudflare to manage and protect traffic, a Cloudflare blog noted in July. Some intermediate fixes have been made, Cloudflare’s status page said. But as of this writing, many sites remain down. According to DownDetector, Amazon, Spotify, Zoom, Uber, and Azure also experienced outages.
“Given the importance of Cloudflare’s services, any outage is unacceptable,” Cloudflare’s spokesperson said. “We apologize to our customers and the Internet in general for letting you down today. We will learn from today’s incident and improve.”
Cloudflare will continue to update the status page as fixes come in, and a blog will be posted later today discussing the issue, the spokesperson told Ars.
Critics have suggested that outages like these make it clear how fragile the Internet really is, especially when everyone relies on the same service providers. During the AWS outage, some sites considered diversifying service providers to avoid losing business during future outages.
The outage may have caused some investors to panic, as Cloudflare’s stock fell about 3 percent amid the widespread outage.
Ars will update this story when Cloudflare provides more information on the outage.
This story was updated on November 18 to add new information from Cloudflare.
Cloudflare CEO Matthew Prince is making sweeping changes to force Google’s hand.
It could be a consequential act of quiet regulation. Cloudflare, a web infrastructure company, has updated millions of websites’ robots.txt files in an effort to force Google to change how it crawls them to fuel its AI products and initiatives.
We spoke with Cloudflare CEO Matthew Prince about what exactly is going on here, why it matters, and what the web might soon look like. But to get into that, we need to cover a little background first.
The new change, which Cloudflare calls its Content Signals Policy, happened after publishers and other companies that depend on web traffic have cried foul over Google’s AI Overviews and similar AI answer engines, saying they are sharply cutting those companies’ path to revenue because they don’t send traffic back to the source of the information.
There have been lawsuits, efforts to kick-start new marketplaces to ensure compensation, and more—but few companies have the kind of leverage Cloudflare does. Its products and services back something close to 20 percent of the web, and thus a significant slice of the websites that show up on search results pages or that fuel large language models.
“Almost every reasonable AI company that’s out there is saying, listen, if it’s a fair playing field, then we’re happy to pay for content,” Prince said. “The problem is that all of them are terrified of Google because if Google gets content for free but they all have to pay for it, they are always going to be at an inherent disadvantage.”
This is happening because Google is using its dominant position in search to ensure that web publishers allow their content to be used in ways that they might not otherwise want it to.
The changing norms of the web
Since 2023, Google has offered a way for website administrators to opt their content out of use for training Google’s large language models, such as Gemini.
However, allowing pages to be indexed by Google’s search crawlers and shown in results requires accepting that they’ll also be used to generate AI Overviews at the top of results pages through a process called retrieval-augmented generation (RAG).
That’s not so for many other crawlers, making Google an outlier among major players.
This is a sore point for a wide range of website administrators, from news websites that publish journalism to investment banks that produce research reports.
A July study from the Pew Research Center analyzed data from 900 adults in the US and found that AI Overviews cut referrals nearly in half. Specifically, users clicked a link on a page with AI Overviews at the top just 8 percent of the time, compared to 15 percent for search engine results pages without those summaries.
And a report in The Wall Street Journal cited a wide range of sources—including internal traffic metrics from numerous major publications like The New York Times and Business Insider—to describe industry-wide plummets in website traffic that those publishers said were tied to AI summaries, leading to layoffs and strategic shifts.
In August, Google’s head of search, Liz Reid, disputed the validity and applicability of studies and publisher reports of reduced link clicks in search. “Overall, total organic click volume from Google Search to websites has been relatively stable year-over-year,” she wrote, going on to say that reports of big declines were “often based on flawed methodologies, isolated examples, or traffic changes that occurred prior to the rollout of AI features in Search.”
Publishers aren’t convinced. Penske Media Corporation, which owns brands like The Hollywood Reporter and Rolling Stone, sued Google over AI Overviews in September. The suit claims that affiliate link revenue has dropped by more than a third in the past year, due in large part to Google’s overviews—a threatening shortfall in a business that already has difficult margins.
Penske’s suit specifically noted that because Google bundles traditional search engine indexing and RAG use together, the company has no choice but to allow Google to keep summarizing its articles, as cutting off Google search referrals entirely would be financially fatal.
Since the earliest days of digital publishing, referrals have in one way or another acted as the backbone of the web’s economy. Content could be made available freely to both human readers and crawlers, and norms were applied across the web to allow information to be tracked back to its source and give that source an opportunity to monetize its content to sustain itself.
Today, there’s a panic that the old system isn’t working anymore as content summaries via RAG have become more common, and along with other players, Cloudflare is trying to update those norms to reflect the current reality.
A mass-scale update to robots.txt
Announced on September 24, Cloudflare’s Content Signals Policy is an effort to use the company’s influential market position to change how content is used by web crawlers. It involves updating millions of websites’ robots.txt files.
Starting in 1994, websites began placing a file called “robots.txt” at the domain root to indicate to automated web crawlers which parts of the domain should be crawled and indexed and which should be ignored. The standard became near-universal over the years; honoring it has been a key part of how Google’s web crawlers operate.
Historically, robots.txt simply includes a list of paths on the domain that were flagged as either “allow” or “disallow.” It was technically not enforceable, but it became an effective honor system because there are advantages to it for the owners of both the website and the crawler: Website owners could dictate access for various business reasons, and it helped crawlers avoid working through data that wouldn’t be relevant.
But robots.txt only tells crawlers whether they can access something at all; it doesn’t tell them what they can use it for. For example, Google supports disallowing the agent “Google-Extended” as a path to blocking crawlers that are looking for content with which to train future versions of its Gemini large language model—though introducing that rule doesn’t do anything about the training Google did before it rolled out Google-Extended in 2023, and it doesn’t stop crawling for RAG and AI Overviews.
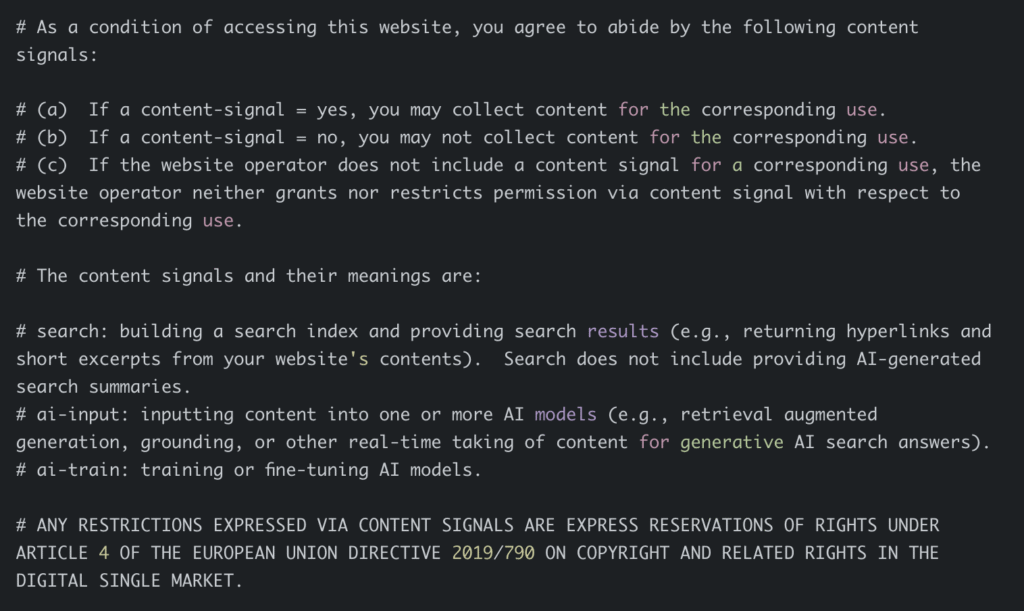
The Content Signals Policy initiative is a newly proposed format for robots.txt that intends to do that. It allows website operators to opt in or out of consenting to the following use cases, as worded in the policy:
search: Building a search index and providing search results (e.g., returning hyperlinks and short excerpts from your website’s contents). Search does not include providing AI-generated search summaries.
ai-input: Inputting content into one or more AI models (e.g., retrieval augmented generation, grounding, or other real-time taking of content for generative AI search answers).
ai-train: Training or fine-tuning AI models.
Cloudflare has given all of its customers quick paths for setting those values on a case-by-case basis. Further, it has automatically updated robots.txt on the 3.8 million domains that already use Cloudflare’s managed robots.txt feature, with search defaulting to yes, ai-train to no, and ai-input blank, indicating a neutral position.
The threat of potential litigation
In making this look a bit like a terms of service agreement, Cloudflare’s goal is explicitly to put legal pressure on Google to change its policy of bundling traditional search crawlers and AI Overviews.
“Make no mistake, the legal team at Google is looking at this saying, ‘Huh, that’s now something that we have to actively choose to ignore across a significant portion of the web,'” Prince told me.
Cloudflare specifically made this look like a license agreement. Credit: Cloudflare
He further characterized this as an effort to get a company that he says has historically been “largely a good actor” and a “patron of the web” to go back to doing the right thing.
“Inside of Google, there is a fight where there are people who are saying we should change how we’re doing this,” he explained. “And there are other people saying, no, that gives up our inherent advantage, we have a God-given right to all the content on the Internet.”
Amid that debate, lawyers have sway at Google, so Cloudflare tried to design tools “that made it very clear that if they were going to follow any of these sites, there was a clear license which was in place for them. And that will create risk for them if they don’t follow it,” Prince said.
The next web paradigm
It takes a company with Cloudflare’s scale to do something like this with any hope that it will have an impact. If just a few websites made this change, Google would have an easier time ignoring it, or worse yet, it could simply stop crawling them to avoid the problem. Since Cloudflare is entangled with millions of websites, Google couldn’t do that without materially impacting the quality of the search experience.
Cloudflare has a vested interest in the general health of the web, but there are other strategic considerations at play, too. The company has been working on tools to assist with RAG on customers’ websites in partnership with Microsoft-owned Google competitor Bing and has experimented with a marketplace that provides a way for websites to charge crawlers for scraping the sites for AI, though what final form that might take is still unclear.
I asked Prince directly if this comes from a place of conviction. “There are very few times that opportunities come along where you get to help think through what a future better business model of an organization or institution as large as the Internet and as important as the Internet is,” he said. “As we do that, I think that we should all be thinking about what have we learned that was good about the Internet in the past and what have we learned that was bad about the Internet in the past.”
It’s important to acknowledge that we don’t yet know what the future business model of the web will look like. Cloudflare itself has ideas. Others have proposed new standards, marketplaces, and strategies, too. There will be winners and losers, and those won’t always be the same winners and losers we saw in the previous paradigm.
What most people seem to agree on, whatever their individual incentives, is that Google shouldn’t get to come out on top in a future answer-engine-driven web paradigm just because it previously established dominance in the search-engine-driven one.
For this new standard for robots.txt, success looks like Google allowing content to be available in search but not in AI Overviews. Whatever the long-term vision, and whether it happens because of Cloudflare’s pressure with the Content Signals Policy or some other driving force, most agree that it would be a good start.
Samuel Axon is the editorial lead for tech and gaming coverage at Ars Technica. He covers AI, software development, gaming, entertainment, and mixed reality. He has been writing about gaming and technology for nearly two decades at Engadget, PC World, Mashable, Vice, Polygon, Wired, and others. He previously ran a marketing and PR agency in the gaming industry, led editorial for the TV network CBS, and worked on social media marketing strategy for Samsung Mobile at the creative agency SPCSHP. He also is an independent software and game developer for iOS, Windows, and other platforms, and he is a graduate of DePaul University, where he studied interactive media and software development.
While the agent didn’t face an actual CAPTCHA puzzle with images in this case, successfully passing Cloudflare’s behavioral screening that determines whether to present such challenges demonstrates sophisticated browser automation.
To understand the significance of this capability, it’s important to know that CAPTCHA systems have served as a security measure on the web for decades. Computer researchers invented the technique in the 1990s to screen bots from entering information into websites, originally using images with letters and numbers written in wiggly fonts, often obscured with lines or noise to foil computer vision algorithms. The assumption is that the task will be easy for humans but difficult for machines.
Cloudflare’s screening system, called Turnstile, often precedes actual CAPTCHA challenges and represents one of the most widely deployed bot-detection methods today. The checkbox analyzes multiple signals, including mouse movements, click timing, browser fingerprints, IP reputation, and JavaScript execution patterns to determine if the user exhibits human-like behavior. If these checks pass, users proceed without seeing a CAPTCHA puzzle. If the system detects suspicious patterns, it escalates to visual challenges.
The ability for an AI model to defeat a CAPTCHA isn’t entirely new (although having one narrate the process feels fairly novel). AI tools have been able to defeat certain CAPTCHAs for a while, which has led to an arms race between those that create them and those that defeat them. OpenAI’s Operator, an experimental web-browsing AI agent launched in January, faced difficulty clicking through some CAPTCHAs (and was also trained to stop and ask a human to complete them), but the latest ChatGPT Agent tool has seen a much wider release.
It’s tempting to say that the ability of AI agents to pass these tests puts the future effectiveness of CAPTCHAs into question, but for as long as there have been CAPTCHAs, there have been bots that could later defeat them. As a result, recent CAPTCHAs have become more of a way to slow down bot attacks or make them more expensive rather than a way to defeat them entirely. Some malefactors even hire out farms of humans to defeat them in bulk.
“Imagine asking your favorite deep research program to help you synthesize the latest cancer research or a legal brief, or just help you find the best restaurant in Soho—and then giving that agent a budget to spend to acquire the best and most relevant content,” Cloudflare said, promising that “we enable a future where intelligent agents can programmatically negotiate access to digital resources.”
AI crawlers now blocked by default
Cloudflare’s announcement comes after rolling out a feature last September, allowing website owners to block AI crawlers in a single click. According to Cloudflare, over 1 million customers chose to block AI crawlers, signaling that people want more control over their content at a time when Cloudflare observed that writing instructions for AI crawlers in robots.txt files was widely “underutilized.”
To protect more customers moving forward, any new customers (including anyone on a free plan) who sign up for Cloudflare services will have their domains, by default, set to block all known AI crawlers.
This marks Cloudflare’s transition away from the dreaded opt-out models of AI scraping to a permission-based model, which a Cloudflare spokesperson told Ars is expected to “fundamentally change how AI companies access web content going forward.”
In a world where some website owners have grown sick and tired of attempting and failing to block AI scraping through robots.txt—including some trapping AI crawlers in tarpits to punish them for ignoring robots.txt—Cloudflare’s feature allows users to choose granular settings to prevent blocks on AI bots from impacting bots that drive search engine traffic. That’s critical for small content creators who want their sites to still be discoverable but not digested by AI bots.
“AI crawlers collect content like text, articles, and images to generate answers, without sending visitors to the original source—depriving content creators of revenue, and the satisfaction of knowing someone is reading their content,” Cloudflare’s blog said. “If the incentive to create original, quality content disappears, society ends up losing, and the future of the Internet is at risk.”
Disclosure: Condé Nast, which owns Ars Technica, is a partner involved in Cloudflare’s beta test.
This story was corrected on July 1 to remove publishers incorrectly listed as participating in Cloudflare’s pay-per-crawl beta.
On Wednesday, web infrastructure provider Cloudflare announced a new feature called “AI Labyrinth” that aims to combat unauthorized AI data scraping by serving fake AI-generated content to bots. The tool will attempt to thwart AI companies that crawl websites without permission to collect training data for large language models that power AI assistants like ChatGPT.
Cloudflare, founded in 2009, is probably best known as a company that provides infrastructure and security services for websites, particularly protection against distributed denial-of-service (DDoS) attacks and other malicious traffic.
Instead of simply blocking bots, Cloudflare’s new system lures them into a “maze” of realistic-looking but irrelevant pages, wasting the crawler’s computing resources. The approach is a notable shift from the standard block-and-defend strategy used by most website protection services. Cloudflare says blocking bots sometimes backfires because it alerts the crawler’s operators that they’ve been detected.
“When we detect unauthorized crawling, rather than blocking the request, we will link to a series of AI-generated pages that are convincing enough to entice a crawler to traverse them,” writes Cloudflare. “But while real looking, this content is not actually the content of the site we are protecting, so the crawler wastes time and resources.”
The company says the content served to bots is deliberately irrelevant to the website being crawled, but it is carefully sourced or generated using real scientific facts—such as neutral information about biology, physics, or mathematics—to avoid spreading misinformation (whether this approach effectively prevents misinformation, however, remains unproven). Cloudflare creates this content using its Workers AI service, a commercial platform that runs AI tasks.
Cloudflare designed the trap pages and links to remain invisible and inaccessible to regular visitors, so people browsing the web don’t run into them by accident.
A smarter honeypot
AI Labyrinth functions as what Cloudflare calls a “next-generation honeypot.” Traditional honeypots are invisible links that human visitors can’t see but bots parsing HTML code might follow. But Cloudflare says modern bots have become adept at spotting these simple traps, necessitating more sophisticated deception. The false links contain appropriate meta directives to prevent search engine indexing while remaining attractive to data-scraping bots.
Cloudflare announced new tools Monday that it claims will help end the era of endless AI scraping by giving all sites on its network the power to block bots in one click.
That will help stop the firehose of unrestricted AI scraping, but, perhaps even more intriguing to content creators everywhere, Cloudflare says it will also make it easier to identify which content that bots scan most, so that sites can eventually wall off access and charge bots to scrape their most valuable content. To pave the way for that future, Cloudflare is also creating a marketplace for all sites to negotiate content deals based on more granular AI audits of their sites.
These tools, Cloudflare’s blog said, give content creators “for the first time” ways “to quickly and easily understand how AI model providers are using their content, and then take control of whether and how the models are able to access it.”
That’s necessary for content creators because the rise of generative AI has made it harder to value their content, Cloudflare suggested in a longer blog explaining the tools.
Previously, sites could distinguish between approving access to helpful bots that drive traffic, like search engine crawlers, and denying access to bad bots that try to take down sites or scrape sensitive or competitive data.
But now, “Large Language Models (LLMs) and other generative tools created a murkier third category” of bots, Cloudflare said, that don’t perfectly fit in either category. They don’t “necessarily drive traffic” like a good bot, but they also don’t try to steal sensitive data like a bad bot, so many site operators don’t have a clear way to think about the “value exchange” of allowing AI scraping, Cloudflare said.
That’s a problem because enabling all scraping could hurt content creators in the long run, Cloudflare predicted.
“Many sites allowed these AI crawlers to scan their content because these crawlers, for the most part, looked like ‘good’ bots—only for the result to mean less traffic to their site as their content is repackaged in AI-written answers,” Cloudflare said.
All this unrestricted AI scraping “poses a risk to an open Internet,” Cloudflare warned, proposing that its tools could set a new industry standard for how content is scraped online.
How to block bots in one click
Increasingly, creators fighting to control what happens with their content have been pushed to either sue AI companies to block unwanted scraping, as The New York Times has, or put content behind paywalls, decreasing public access to information.
While some big publishers have been striking content deals with AI companies to license content, Cloudflare is hoping new tools will help to level the playing field for everyone. That way, “there can be a transparent exchange between the websites that want greater control over their content, and the AI model providers that require fresh data sources, so that everyone benefits,” Cloudflare said.
Today, Cloudflare site operators can stop manually blocking each AI bot one by one and instead choose to “block all AI bots in one click,” Cloudflare said.
They can do this by visiting the Bots section under the Security tab of the Cloudflare dashboard, then clicking a blue link in the top-right corner “to configure how Cloudflare’s proxy handles bot traffic,” Cloudflare said. On that screen, operators can easily “toggle the button in the ‘Block AI Scrapers and Crawlers’ card to the ‘On’ position,” blocking everything and giving content creators time to strategize what access they want to re-enable, if any.
Beyond just blocking bots, operators can also conduct AI audits, quickly analyzing which sections of their sites are scanned most by which bots. From there, operators can decide which scraping is allowed and use sophisticated controls to decide which bots can scrape which parts of their sites.
“For some teams, the decision will be to allow the bots associated with AI search engines to scan their Internet properties because those tools can still drive traffic to the site,” Cloudflare’s blog explained. “Other organizations might sign deals with a specific model provider, and they want to allow any type of bot from that provider to access their content.”
For publishers already playing whack-a-mole with bots, a key perk would be if Cloudflare’s tools allowed them to write rules to restrict certain bots that scrape sites for both “good” and “bad” purposes to keep the good and throw away the bad.
Perhaps the most frustrating bot for publishers today is the Googlebot, which scrapes sites to populate search results as well as to train AI to generate Google search AI overviews that could negatively impact traffic to source sites by summarizing content. Publishers currently have no way of opting out of training models fueling Google’s AI overviews without losing visibility in search results, and Cloudflare’s tools won’t be able to get publishers out of that uncomfortable position, Cloudflare CEO Matthew Prince confirmed to Ars.
For any site operators tempted to toggle off all AI scraping, blocking the Googlebot from scraping and inadvertently causing dips in traffic may be a compelling reason not to use Cloudflare’s one-click solution.
However, Prince expects “that Google’s practices over the long term won’t be sustainable” and “that Cloudflare will be a part of getting Google and other folks that are like Google” to give creators “much more granular control over” how bots like the Googlebot scrape the web to train AI.
Prince told Ars that while Google solves its “philosophical” internal question of whether the Googlebot’s scraping is for search or for AI, a technical solution to block one bot from certain kinds of scraping will likely soon emerge. And in the meantime, “there can also be a legal solution” that “can rely on contract law” based on improving sites’ terms of service.
Not every site would, of course, be able to afford a lawsuit to challenge AI scraping, but to help creators better defend themselves, Cloudflare drafted “model terms of use that every content creator can add to their sites to legally protect their rights as sites gain more control over AI scraping.” With these terms, sites could perhaps more easily dispute any restricted scraping discovered through Cloudflare’s analytics tools.
“One way or another, Google is going to get forced to be more fine-grained here,” Prince predicted.