
Farewell Photoshop? Google’s new AI lets you edit images by asking.
New AI allows no-skill photo editing, including adding objects and removing watermarks.
A collection of images either generated or modified by Gemini 2.0 Flash (Image Generation) Experimental. Credit: Google / Ars Technica
There’s a new Google AI model in town, and it can generate or edit images as easily as it can create text—as part of its chatbot conversation. The results aren’t perfect, but it’s quite possible everyone in the near future will be able to manipulate images this way.
Last Wednesday, Google expanded access to Gemini 2.0 Flash’s native image-generation capabilities, making the experimental feature available to anyone using Google AI Studio. Previously limited to testers since December, the multimodal technology integrates both native text and image processing capabilities into one AI model.
The new model, titled “Gemini 2.0 Flash (Image Generation) Experimental,” flew somewhat under the radar last week, but it has been garnering more attention over the past few days due to its ability to remove watermarks from images, albeit with artifacts and a reduction in image quality.
That’s not the only trick. Gemini 2.0 Flash can add objects, remove objects, modify scenery, change lighting, attempt to change image angles, zoom in or out, and perform other transformations—all to varying levels of success depending on the subject matter, style, and image in question.
To pull it off, Google trained Gemini 2.0 on a large dataset of images (converted into tokens) and text. The model’s “knowledge” about images occupies the same neural network space as its knowledge about world concepts from text sources, so it can directly output image tokens that get converted back into images and fed to the user.
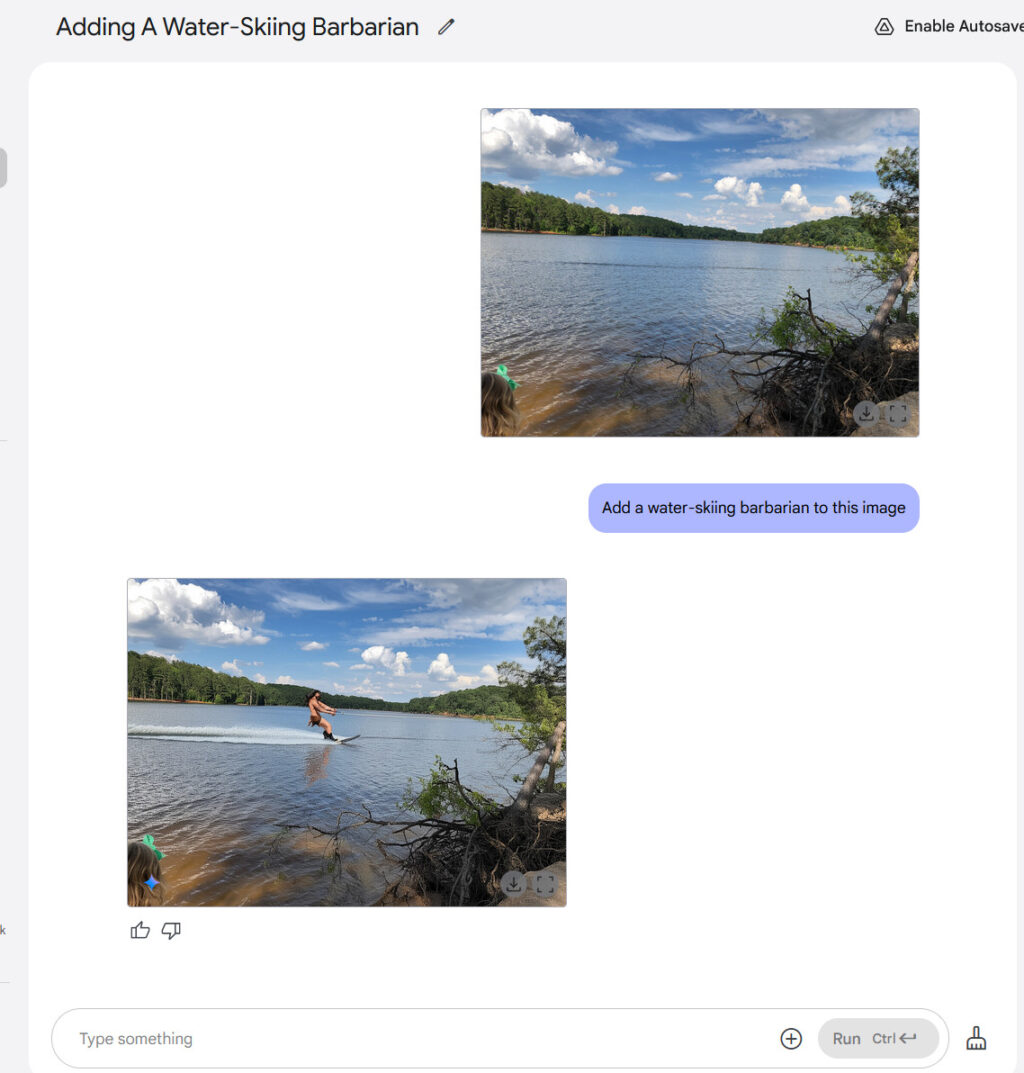
Adding a water-skiing barbarian to a photograph with Gemini 2.0 Flash. Credit: Google / Benj Edwards
Incorporating image generation into an AI chat isn’t itself new—OpenAI integrated its image-generator DALL-E 3 into ChatGPT last September, and other tech companies like xAI followed suit. But until now, every one of those AI chat assistants called on a separate diffusion-based AI model (which uses a different synthesis principle than LLMs) to generate images, which were then returned to the user within the chat interface. In this case, Gemini 2.0 Flash is both the large language model (LLM) and AI image generator rolled into one system.
Interestingly, OpenAI’s GPT-4o is capable of native image output as well (and OpenAI President Greg Brock teased the feature at one point on X last year), but that company has yet to release true multimodal image output capability. One reason why is possibly because true multimodal image output is very computationally expensive, since each image either inputted or generated is composed of tokens that become part of the context that runs through the image model again and again with each successive prompt. And given the compute needs and size of the training data required to create a truly visually comprehensive multimodal model, the output quality of the images isn’t necessarily as good as diffusion models just yet.
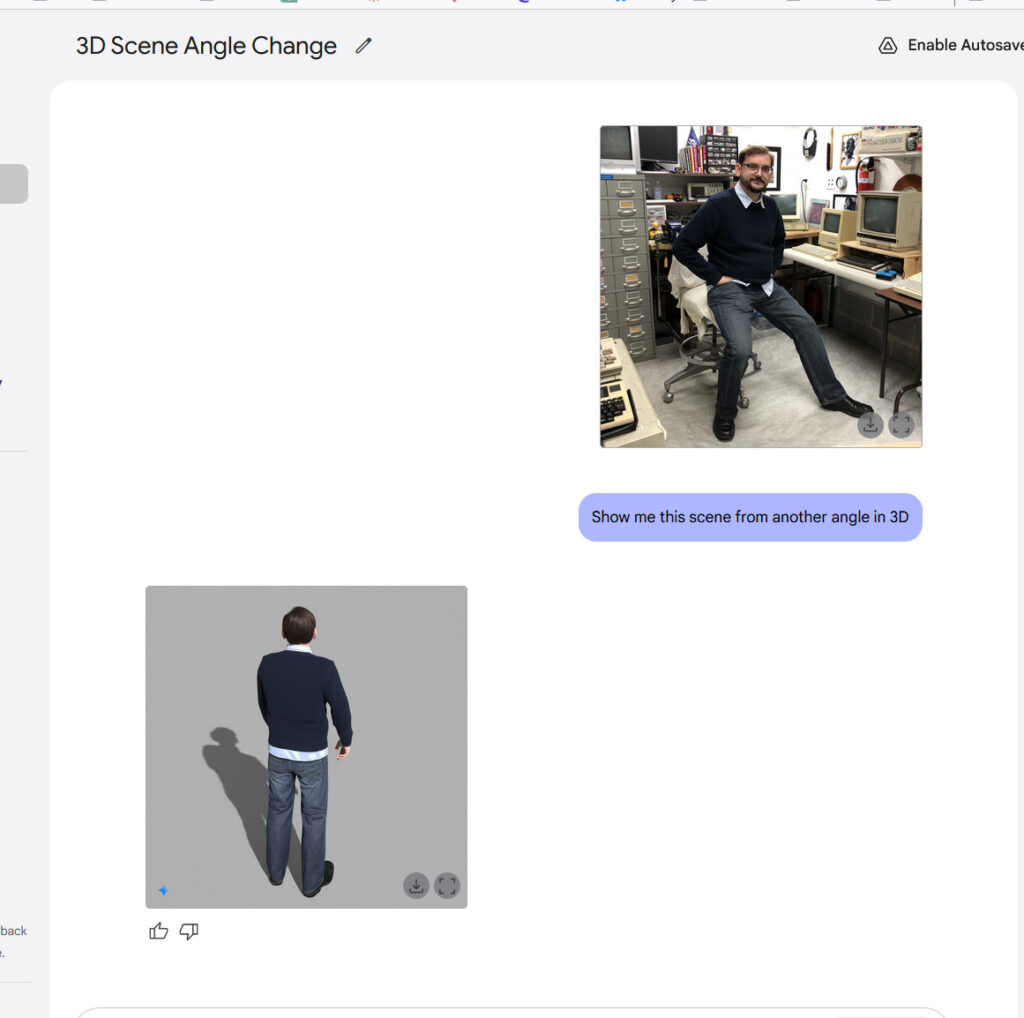
Creating another angle of a person with Gemini 2.0 Flash. Credit: Google / Benj Edwards
Another reason OpenAI has held back may be “safety”-related: In a similar way to how multimodal models trained on audio can absorb a short clip of a sample person’s voice and then imitate it flawlessly (this is how ChatGPT’s Advanced Voice Mode works, with a clip of a voice actor it is authorized to imitate), multimodal image output models are capable of faking media reality in a relatively effortless and convincing way, given proper training data and compute behind it. With a good enough multimodal model, potentially life-wrecking deepfakes and photo manipulations could become even more trivial to produce than they are now.
Putting it to the test
So, what exactly can Gemini 2.0 Flash do? Notably, its support for conversational image editing allows users to iteratively refine images through natural language dialogue across multiple successive prompts. You can talk to it and tell it what you want to add, remove, or change. It’s imperfect, but it’s the beginning of a new type of native image editing capability in the tech world.
We gave Gemini Flash 2.0 a battery of informal AI image-editing tests, and you’ll see the results below. For example, we removed a rabbit from an image in a grassy yard. We also removed a chicken from a messy garage. Gemini fills in the background with its best guess. No need for a clone brush—watch out, Photoshop!
We also tried adding synthesized objects to images. Being always wary of the collapse of media reality, called the “cultural singularity,” we added a UFO to a photo the author took from an airplane window. Then we tried adding a Sasquatch and a ghost. The results were unrealistic, but this model was also trained on a limited image dataset (more on that below).
Adding a UFO to a photograph with Gemini 2.0 Flash. Google / Benj Edwards
We then added a video game character to a photo of an Atari 800 screen (Wizard of Wor), resulting in perhaps the most realistic image synthesis result in the set. You might not see it here, but Gemini added realistic CRT scanlines that matched the monitor’s characteristics pretty well.
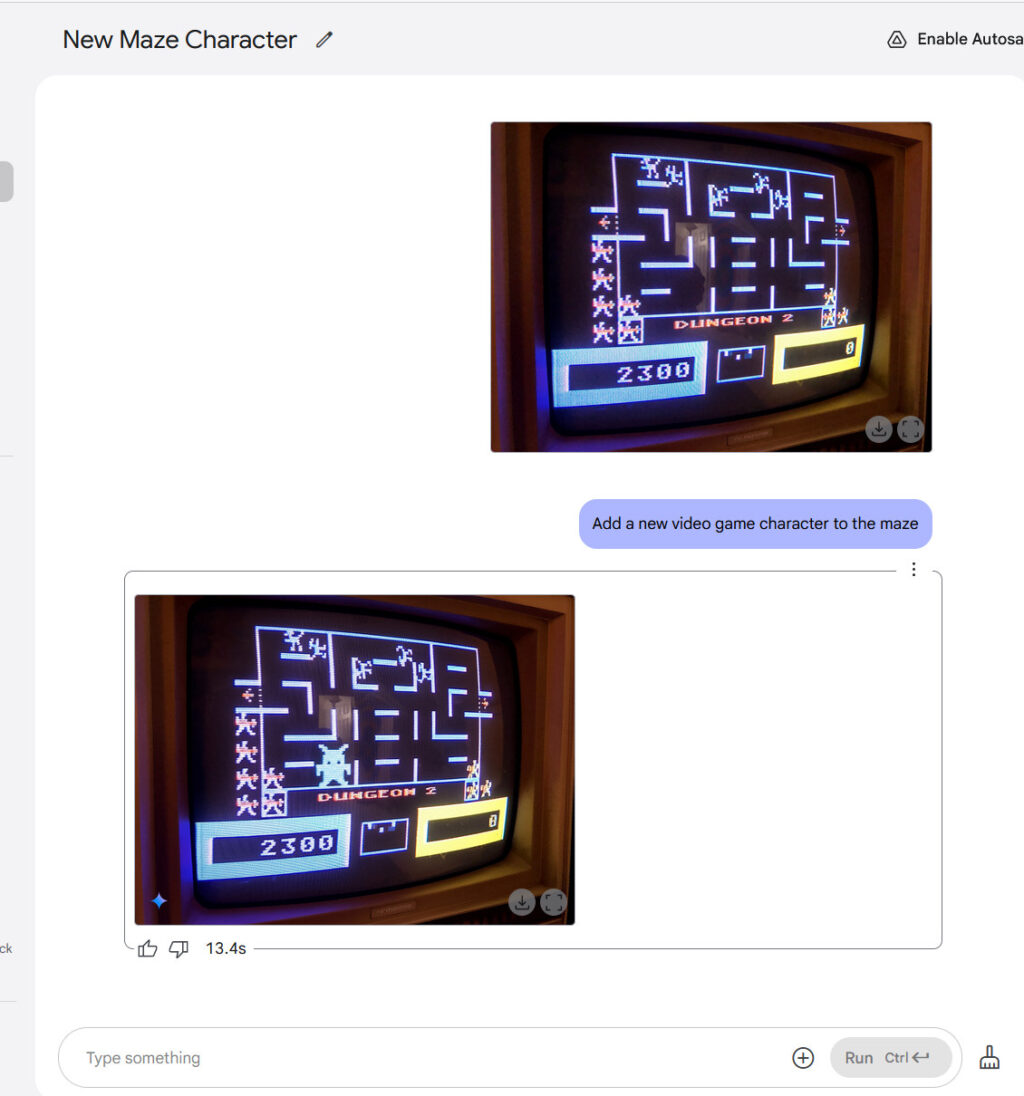
Adding a monster to an Atari video game with Gemini 2.0 Flash. Credit: Google / Benj Edwards
Gemini can also warp an image in novel ways, like “zooming out” of an image into a fictional setting or giving an EGA-palette character a body, then sticking him into an adventure game.
“Zooming out” on an image with Gemini 2.0 Flash. Google / Benj Edwards
And yes, you can remove watermarks. We tried removing a watermark from a Getty Images image, and it worked, although the resulting image is nowhere near the resolution or detail quality of the original. Ultimately, if your brain can picture what an image is like without a watermark, so can an AI model. It fills in the watermark space with the most plausible result based on its training data.
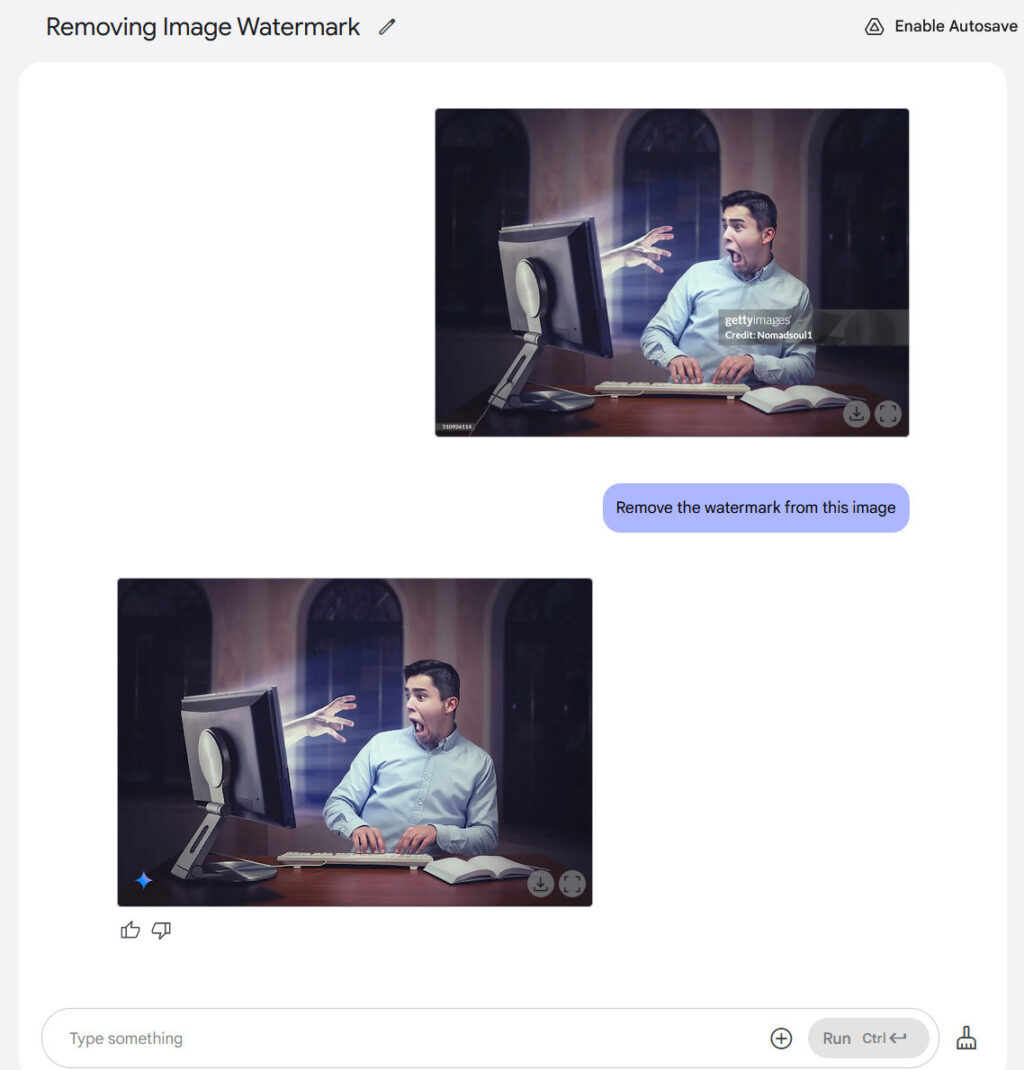
Removing a watermark with Gemini 2.0 Flash. Credit: Nomadsoul1 via Getty Images
And finally, we know you’ve likely missed seeing barbarians beside TV sets (as per tradition), so we gave that a shot. Originally, Gemini didn’t add a CRT TV set to the barbarian image, so we asked for one.
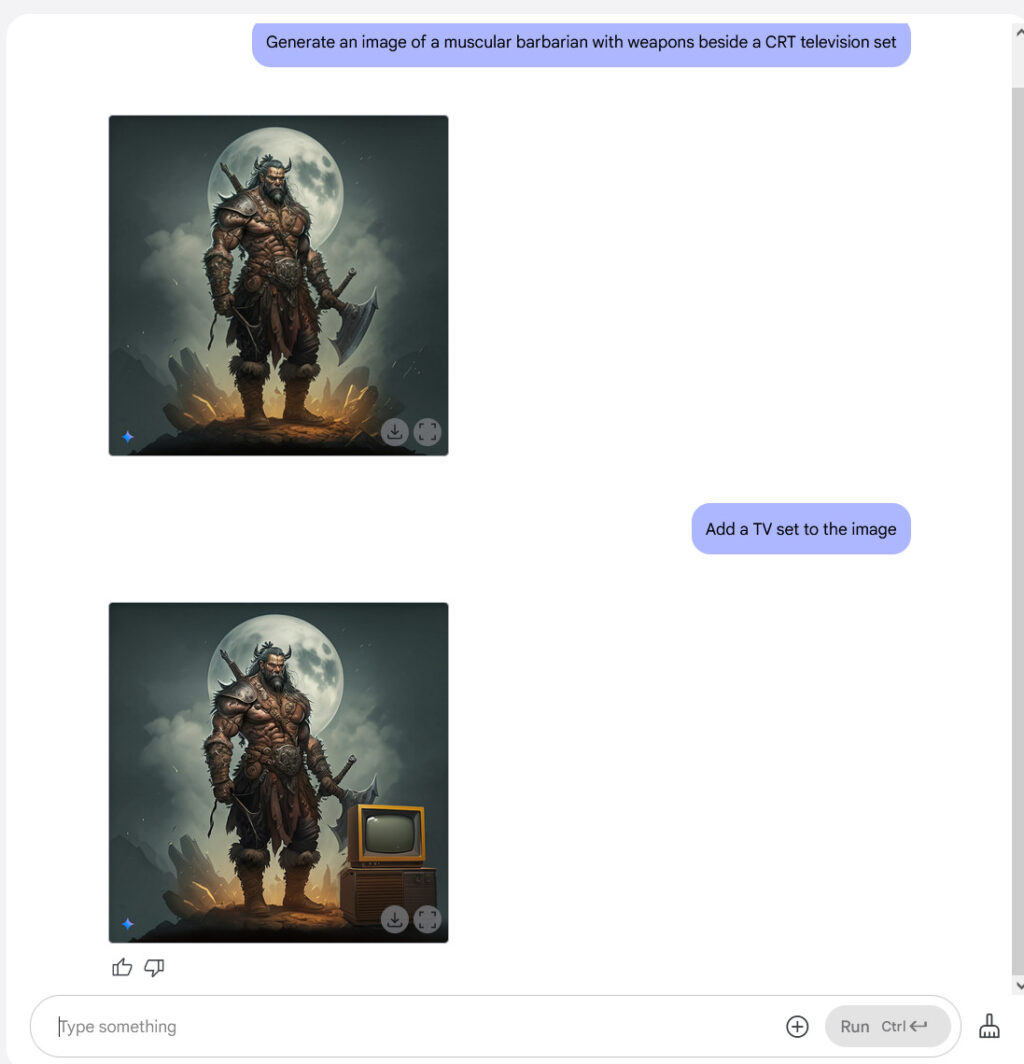
Adding a TV set to a barbarian image with Gemini 2.0 Flash. Credit: Google / Benj Edwards
Then we set the TV on fire.
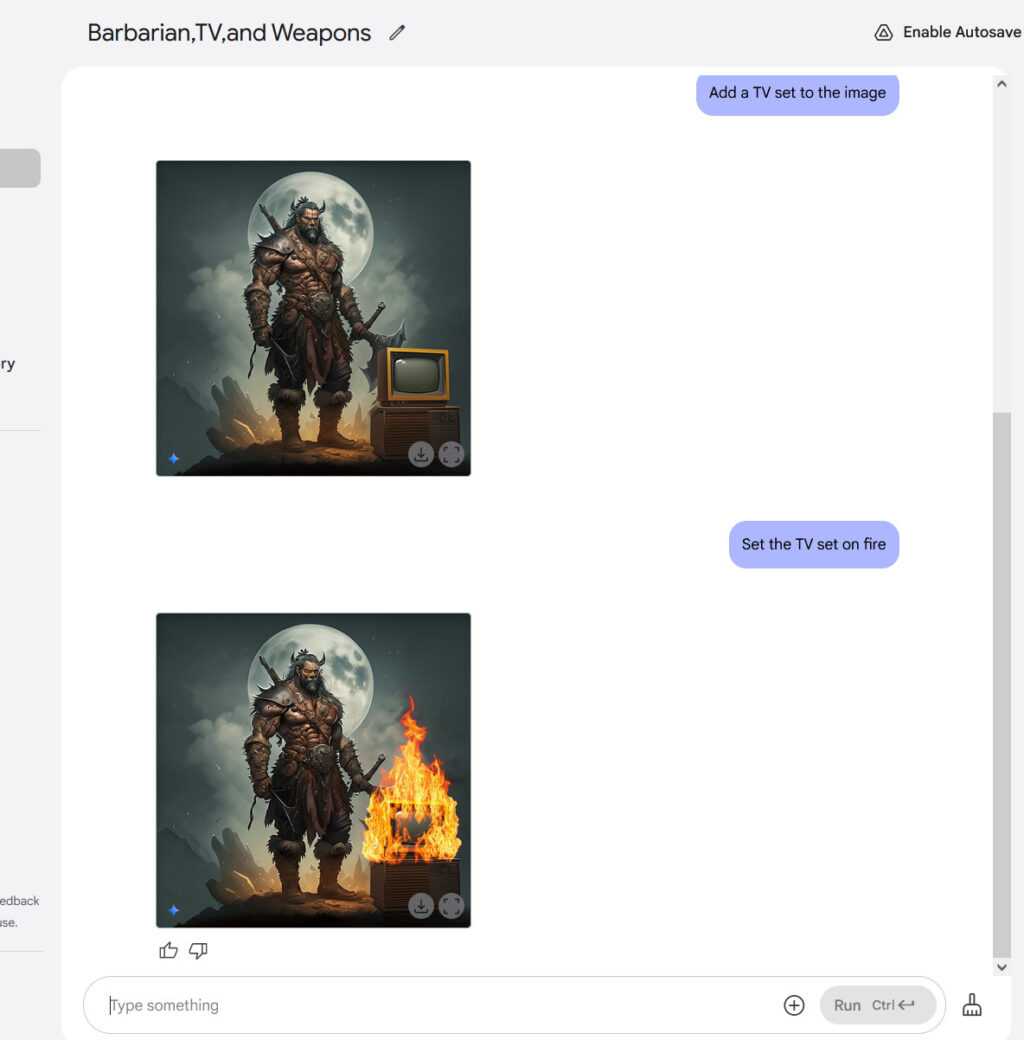
Setting the TV set on fire with Gemini 2.0 Flash. Credit: Google / Benj Edwards
All in all, it doesn’t produce images of pristine quality or detail, but we literally did no editing work on these images other than typing requests. Adobe Photoshop currently lets users manipulate images using AI synthesis based on written prompts with “Generative Fill,” but it’s not quite as natural as this. We could see Adobe adding a more conversational AI image-editing flow like this one in the future.
Multimodal output opens up new possibilities
Having true multimodal output opens up interesting new possibilities in chatbots. For example, Gemini 2.0 Flash can play interactive graphical games or generate stories with consistent illustrations, maintaining character and setting continuity throughout multiple images. It’s far from perfect, but character consistency is a new capability in AI assistants. We tried it out and it was pretty wild—especially when it generated a view of a photo we provided from another angle.
Creating a multi-image story with Gemini 2.0 Flash, part 1. Google / Benj Edwards
Text rendering represents another potential strength of the model. Google claims that internal benchmarks show Gemini 2.0 Flash performs better than “leading competitive models” when generating images containing text, making it potentially suitable for creating content with integrated text. From our experience, the results weren’t that exciting, but they were legible.
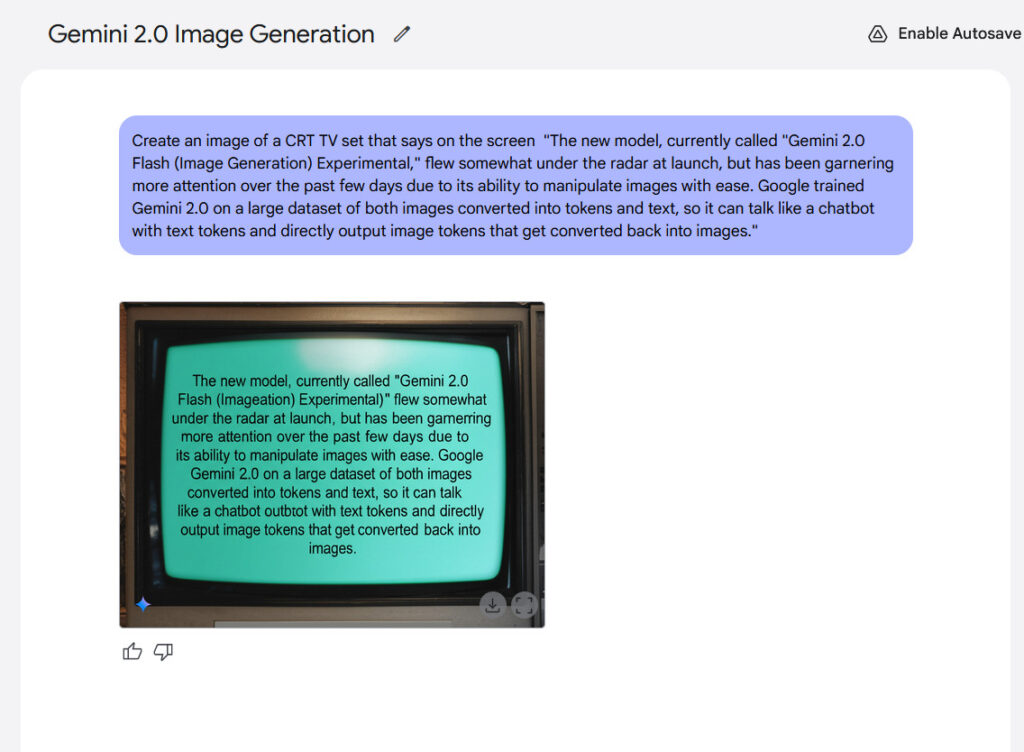
An example of in-image text rendering generated with Gemini 2.0 Flash. Credit: Google / Ars Technica
Despite Gemini 2.0 Flash’s shortcomings so far, the emergence of true multimodal image output feels like a notable moment in AI history because of what it suggests if the technology continues to improve. If you imagine a future, say 10 years from now, where a sufficiently complex AI model could generate any type of media in real time—text, images, audio, video, 3D graphics, 3D-printed physical objects, and interactive experiences—you basically have a holodeck, but without the matter replication.
Coming back to reality, it’s still “early days” for multimodal image output, and Google recognizes that. Recall that Flash 2.0 is intended to be a smaller AI model that is faster and cheaper to run, so it hasn’t absorbed the entire breadth of the Internet. All that information takes a lot of space in terms of parameter count, and more parameters means more compute. Instead, Google trained Gemini 2.0 Flash by feeding it a curated dataset that also likely included targeted synthetic data. As a result, the model does not “know” everything visual about the world, and Google itself says the training data is “broad and general, not absolute or complete.”
That’s just a fancy way of saying that the image output quality isn’t perfect—yet. But there is plenty of room for improvement in the future to incorporate more visual “knowledge” as training techniques advance and compute drops in cost. If the process becomes anything like we’ve seen with diffusion-based AI image generators like Stable Diffusion, Midjourney, and Flux, multimodal image output quality may improve rapidly over a short period of time. Get ready for a completely fluid media reality.

Benj Edwards is Ars Technica’s Senior AI Reporter and founder of the site’s dedicated AI beat in 2022. He’s also a tech historian with almost two decades of experience. In his free time, he writes and records music, collects vintage computers, and enjoys nature. He lives in Raleigh, NC.
Farewell Photoshop? Google’s new AI lets you edit images by asking. Read More »





