
OpenAI’s new “reasoning” AI models are here: o1-preview and o1-mini
fruit by the foot —
New o1 language model can solve complex tasks iteratively, count R’s in “strawberry.”

OpenAI finally unveiled its rumored “Strawberry” AI language model on Thursday, claiming significant improvements in what it calls “reasoning” and problem-solving capabilities over previous large language models (LLMs). Formally named “OpenAI o1,” the model family will initially launch in two forms, o1-preview and o1-mini, available today for ChatGPT Plus and certain API users.
OpenAI claims that o1-preview outperforms its predecessor, GPT-4o, on multiple benchmarks, including competitive programming, mathematics, and “scientific reasoning.” However, people who have used the model say it does not yet outclass GPT-4o in every metric. Other users have criticized the delay in receiving a response from the model, owing to the multi-step processing occurring behind the scenes before answering a query.
In a rare display of public hype-busting, OpenAI product manager Joanne Jang tweeted, “There’s a lot of o1 hype on my feed, so I’m worried that it might be setting the wrong expectations. what o1 is: the first reasoning model that shines in really hard tasks, and it’ll only get better. (I’m personally psyched about the model’s potential & trajectory!) what o1 isn’t (yet!): a miracle model that does everything better than previous models. you might be disappointed if this is your expectation for today’s launch—but we’re working to get there!”
OpenAI reports that o1-preview ranked in the 89th percentile on competitive programming questions from Codeforces. In mathematics, it scored 83 percent on a qualifying exam for the International Mathematics Olympiad, compared to GPT-4o’s 13 percent. OpenAI also states, in a claim that may later be challenged as people scrutinize the benchmarks and run their own evaluations over time, o1 performs comparably to PhD students on specific tasks in physics, chemistry, and biology. The smaller o1-mini model is designed specifically for coding tasks and is priced at 80 percent less than o1-preview.

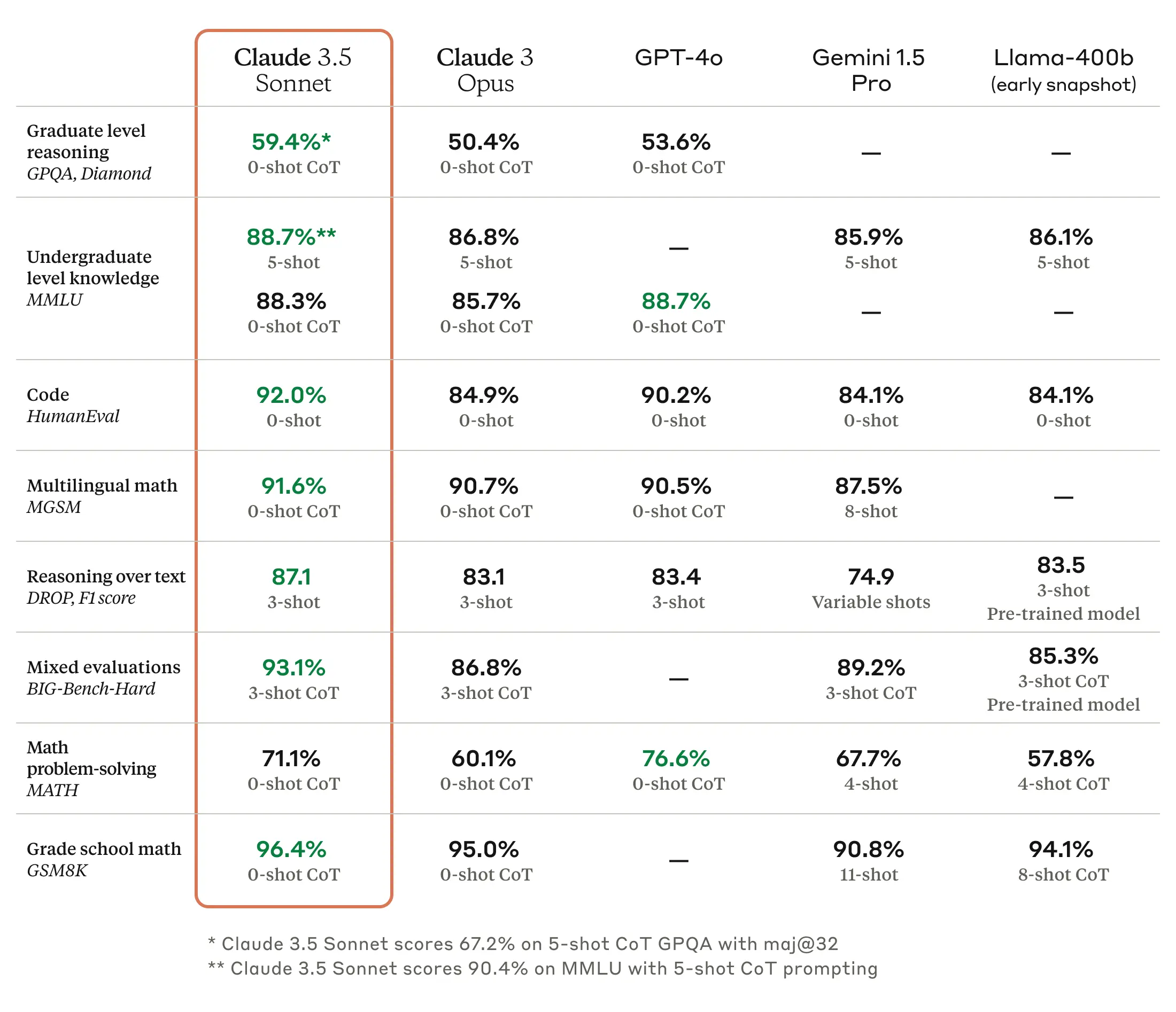
Enlarge / A benchmark chart provided by OpenAI. They write, “o1 improves over GPT-4o on a wide range of benchmarks, including 54/57 MMLU subcategories. Seven are shown for illustration.”
OpenAI attributes o1’s advancements to a new reinforcement learning (RL) training approach that teaches the model to spend more time “thinking through” problems before responding, similar to how “let’s think step-by-step” chain-of-thought prompting can improve outputs in other LLMs. The new process allows o1 to try different strategies and “recognize” its own mistakes.
AI benchmarks are notoriously unreliable and easy to game; however, independent verification and experimentation from users will show the full extent of o1’s advancements over time. It’s worth noting that MIT Research showed earlier this year that some of the benchmark claims OpenAI touted with GPT-4 last year were erroneous or exaggerated.
A mixed bag of capabilities
OpenAI demos “o1” correctly counting the number of Rs in the word “strawberry.”
Amid many demo videos of o1 completing programming tasks and solving logic puzzles that OpenAI shared on its website and social media, one demo stood out as perhaps the least consequential and least impressive, but it may become the most talked about due to a recurring meme where people ask LLMs to count the number of R’s in the word “strawberry.”
Due to tokenization, where the LLM processes words in data chunks called tokens, most LLMs are typically blind to character-by-character differences in words. Apparently, o1 has the self-reflective capabilities to figure out how to count the letters and provide an accurate answer without user assistance.
Beyond OpenAI’s demos, we’ve seen optimistic but cautious hands-on reports about o1-preview online. Wharton Professor Ethan Mollick wrote on X, “Been using GPT-4o1 for the last month. It is fascinating—it doesn’t do everything better but it solves some very hard problems for LLMs. It also points to a lot of future gains.”
Mollick shared a hands-on post in his “One Useful Thing” blog that details his experiments with the new model. “To be clear, o1-preview doesn’t do everything better. It is not a better writer than GPT-4o, for example. But for tasks that require planning, the changes are quite large.”
Mollick gives the example of asking o1-preview to build a teaching simulator “using multiple agents and generative AI, inspired by the paper below and considering the views of teachers and students,” then asking it to build the full code, and it produced a result that Mollick found impressive.
Mollick also gave o1-preview eight crossword puzzle clues, translated into text, and the model took 108 seconds to solve it over many steps, getting all of the answers correct but confabulating a particular clue Mollick did not give it. We recommend reading Mollick’s entire post for a good early hands-on impression. Given his experience with the new model, it appears that o1 works very similar to GPT-4o but iteratively in a loop, which is something that the so-called “agentic” AutoGPT and BabyAGI projects experimented with in early 2023.
Is this what could “threaten humanity?”
Speaking of agentic models that run in loops, Strawberry has been subject to hype since last November, when it was initially known as Q(Q-star). At the time, The Information and Reuters claimed that, just before Sam Altman’s brief ouster as CEO, OpenAI employees had internally warned OpenAI’s board of directors about a new OpenAI model called Q* that could “threaten humanity.”
In August, the hype continued when The Information reported that OpenAI showed Strawberry to US national security officials.
We’ve been skeptical about the hype around Qand Strawberry since the rumors first emerged, as this author noted last November, and Timothy B. Lee covered thoroughly in an excellent post about Q* from last December.
So even though o1 is out, AI industry watchers should note how this model’s impending launch was played up in the press as a dangerous advancement while not being publicly downplayed by OpenAI. For an AI model that takes 108 seconds to solve eight clues in a crossword puzzle and hallucinates one answer, we can say that its potential danger was likely hype (for now).
Controversy over “reasoning” terminology
It’s no secret that some people in tech have issues with anthropomorphizing AI models and using terms like “thinking” or “reasoning” to describe the synthesizing and processing operations that these neural network systems perform.
Just after the OpenAI o1 announcement, Hugging Face CEO Clement Delangue wrote, “Once again, an AI system is not ‘thinking,’ it’s ‘processing,’ ‘running predictions,’… just like Google or computers do. Giving the false impression that technology systems are human is just cheap snake oil and marketing to fool you into thinking it’s more clever than it is.”
“Reasoning” is also a somewhat nebulous term since, even in humans, it’s difficult to define exactly what the term means. A few hours before the announcement, independent AI researcher Simon Willison tweeted in response to a Bloomberg story about Strawberry, “I still have trouble defining ‘reasoning’ in terms of LLM capabilities. I’d be interested in finding a prompt which fails on current models but succeeds on strawberry that helps demonstrate the meaning of that term.”
Reasoning or not, o1-preview currently lacks some features present in earlier models, such as web browsing, image generation, and file uploading. OpenAI plans to add these capabilities in future updates, along with continued development of both the o1 and GPT model series.
While OpenAI says the o1-preview and o1-mini models are rolling out today, neither model is available in our ChatGPT Plus interface yet, so we have not been able to evaluate them. We’ll report our impressions on how this model differs from other LLMs we have previously covered.
OpenAI’s new “reasoning” AI models are here: o1-preview and o1-mini Read More »























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}