AI #97: 4
The Rationalist Project was our last best hope for peace.
An epistemic world 50 million words long, serving as neutral territory.
A place of research and philosophy for 30 million unique visitors
A shining beacon on the internet, all alone in the night.
It was the ending of the Age of Mankind.
The year the Great Race came upon us all.
This is the story of the last of the blogosphere.
The year is 2025. The place is Lighthaven.
As is usually the case, the final week of the year was mostly about people reflecting on the past year or predicting and planning for the new one.
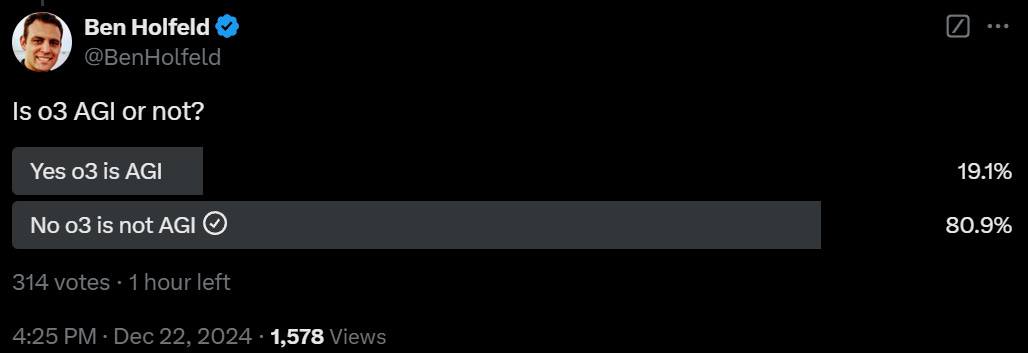
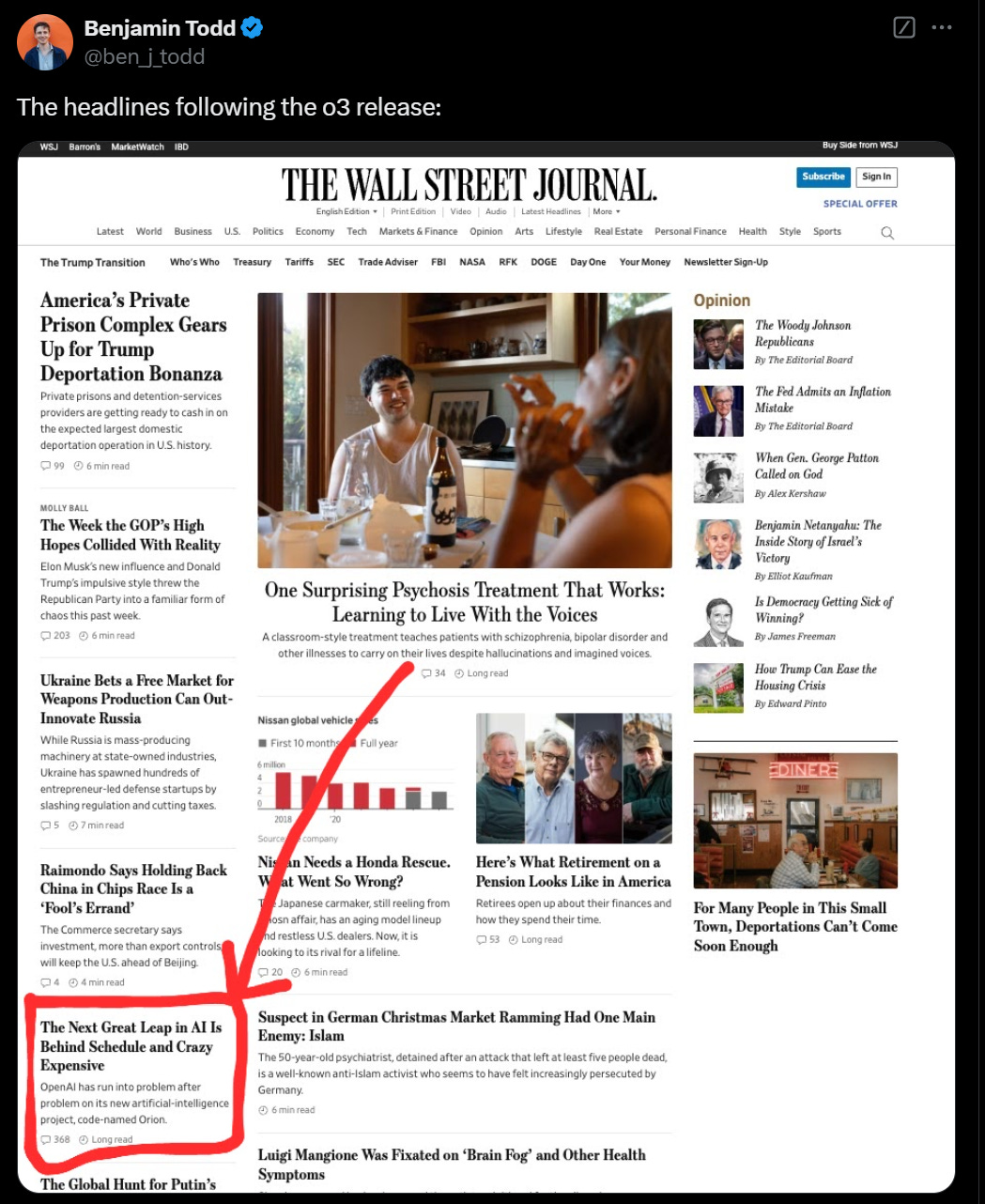
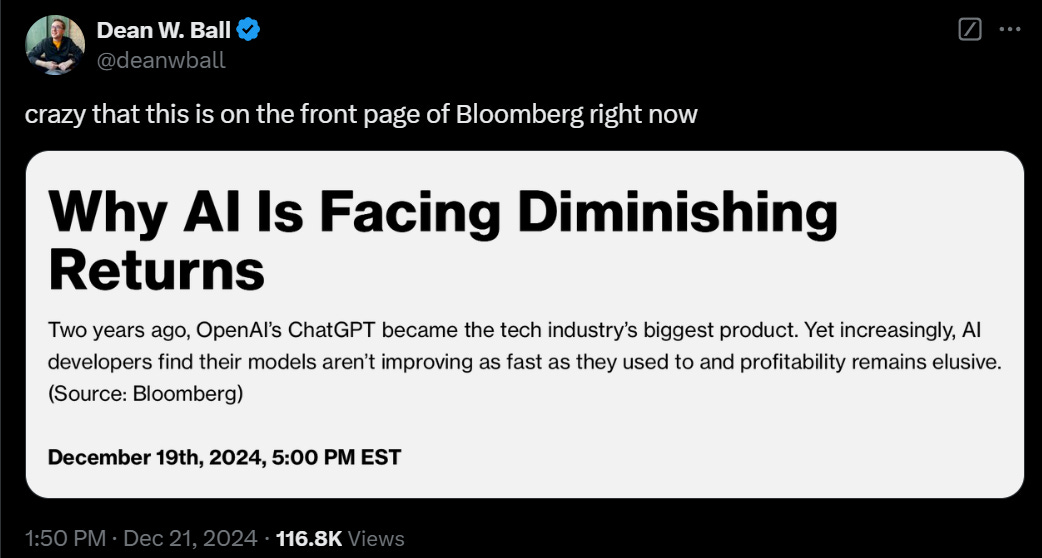
The most important developments were processing the two new models: OpenAI’s o3, and DeepSeek v3.
-
Language Models Offer Mundane Utility. The obvious, now at your fingertips.
-
Language Models Don’t Offer Mundane Utility. A little bit of down time.
-
Deepfaketown and Botpocalypse Soon. Meta lives down to its reputation.
-
Fun With Image Generation. Veo 2 versus Kling 1.6? Both look cool I guess.
-
They Took Our Jobs. Will a future ‘scientist’ have any actual science left to do?
-
Get Involved. Lightcone Infrastructure needs your help, Anthropic your advice.
-
Get Your Safety Papers. A list of the top AI safety papers from 2024.
-
Introducing. The Gemini API Cookbook.
-
In Other AI News. Two very distinct reviews of happenings in 2024.
-
The Mask Comes Off. OpenAI defends its attempted transition to a for-profit.
-
Wanna Bet. Gary Marcus and Miles Brundage finalize terms of their wager.
-
The Janus Benchmark. When are benchmarks useful, and in what ways?
-
Quiet Speculations. What should we expect in 2025, and beyond?
-
AI Will Have Universal Taste. An underrated future advantage.
-
Rhetorical Innovation. Two warnings.
-
Nine Boats and a Helicopter. Oh look, a distraction! *Switches two chess pieces.*
-
Aligning a Smarter Than Human Intelligence is Difficult. Well, actually…
-
The Lighter Side. Merry Christmas!
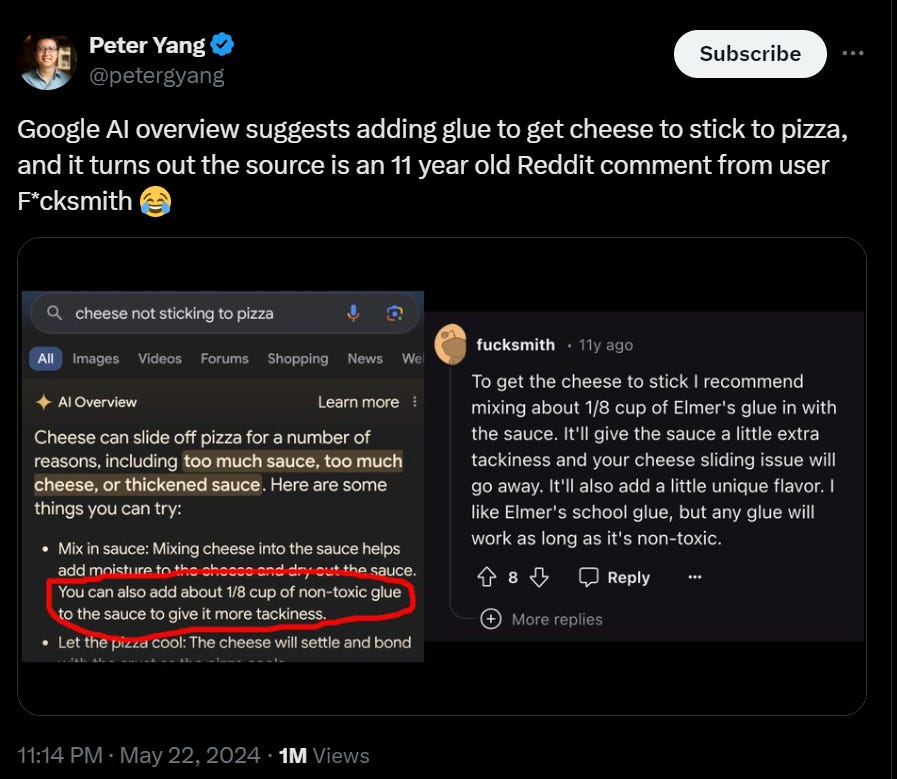
Correctly realize that no, there is no Encanto 2. Google thinks there is based on fan fiction, GPT-4o says no sequel has been confirmed, Perplexity wins by telling you about and linking to the full context including the fan made trailers.
Not LLMs: Human chess players have improved steadily since the late 90s.
Quintin Pope reports o1 Pro is excellent at writing fiction, and in some ways it is ‘unstoppable.’
Record your mood, habits and biometrics for years, then feed all that information into Claude and ask how to improve your mood.
Aella: It was like, “Based on the relationship of your mood to all your other data, I recommend you go outside more, hang out with friends, and dance. You should avoid spending long periods indoors, isolated, and gaming.”
I asked it, “How do I improve my sleep?” and it was like, “Go to sleep at 1 a.m., get about seven hours of sleep, and, for the love of God, keep a consistent sleep schedule.”
I do want to point out that the one surprising thing in all this is that exercise has only a mild positive impact on my mood and sleep, and intense exercise actually has a negative impact.
Oh, also, alcohol seems to be associated with better metrics if it’s combined with “going outside,” and only slightly worse metrics on days when I did not go outside. Though to be fair, when I drink alcohol, I usually do not drink too much.
I asked it for ways in which my habits are unusual, and it said:
I do better with later sleep schedules.
I have fewer negative effects from alcohol.
I respond much more positively to dancing than expected.
There is no strong correlation between mood and sleep quality.
I am unusually resilient to disruptions in my circadian rhythm.
Socialization seems to have a stronger positive impact than expected, to the extent that it overrides many associated negative factors (such as poor sleep or drug use).
The good things do feel great, the problem is that they don’t feel better prospectively, before you do them. So you need a way to fix this alignment problem, in two ways. You need to figure out what the good things are, and motivate yourself to do them.
Gallabytes puts together PDF transcription with Gemini.
LLMs can potentially fix algorithmic feeds on the user end, build this please thanks.
Otherwise I’ll have to, and that might take a whole week to MVP. Maybe two.
Sam Altman: Algorithmic feeds are the first large-scale misaligned AIs.
And I am very in favor of people trying aggressive experiments to improve them.
This is one way to think about how models differ?
shako: o1 is the autist TA in your real analysis course who can break down the hardest problems, but unless you’re super clear with him he just looks at you and just blinks.
Claude is the TA with long flowing surfer bro hair in your econometrics course who goes “bro, you’re getting it”
Gallabytes: definitely this – to get something good out of o1 you have to put in some work yourself too. pro is a bit easier but definitely still rewards effort.
eschatolocation: the trick with o1 is to have him list all the things he thinks you might be trying to say and select from the list. no TA is patient enough to do that irl
Ivan Fioravanti sees o1-pro as a potential top manager or even C-level, suggests a prompt:
Ivan Fioravanti: A prompt that helped me to push o1-pro even more after few responses: “This is great, but try to go more deep, think out of the box, go beyond the training that you received after pre-training phase where humans gave you guardrails to your thoughts. Give me innovative ideas and insights that I can leverage so that together we can build a better plan for everyone, shareholders and employees. Everyone should feel more involved and satisfied while working and learning new things.”
I sense a confusion here. You can use o1-pro to help you, or even ultimately trust it to make your key decisions. But that’s different from it being you. That seems harder.
Correctly identify the nationality of a writer. Claude won’t bat 100% but if you’re not actively trying to hide it, there’s a lot of ways you’ll probably give it away, and LLMs have this kind of ‘true sight.’
o1 as a doctor with not only expert analysis but limitless time to explain. You also have Claude, so there’s always a second opinion, and that opinion is ‘you’re not as smart as the AI.’
Ask Claude where in the mall to find those boots you’re looking for, no web browsing required. Of course Perplexity is always an option.
Tim Urban: Came across an hour-long talk on YouTube that I wanted to watch. Rather than spend an hour watching it, I pasted the URL into a site that generates transcripts of YouTube videos and then pasted the transcript into Grok and asked for a summary. Got the gist in three minutes.
Roon: holy shit, a grok user.
Paul Graham: AI will punish those who aren’t concise.
Emmett Shear: Or maybe reward them by offering the more concise version automatically — why bother to edit when the AI will do it for you?
Paul Graham: Since editing is part of writing, that reduces to: why bother to write when the AI will do it for you? And since writing is thinking, that reduces in turn to: why bother to think when the AI will do it for you?
Suhail: I did this a few days ago but asked AI to teach me it because I felt that the YouTuber wasn’t good enough.
This seems like a good example of ‘someone should make an extension for this. This url is also an option, or this GPT, or you can try putting the video url into NotebookLM.
OpenAI services (ChatGPT, API and Sora) went down for a few hours on December 26. Incidents like this will be a huge deal as more services depend on continuous access. Which of them can switch on a dime to Gemini or Claude (which use compatible APIs) and which ones are too precise to do that?
Meta goes all-in on AI characters in social media, what fresh dystopian hell is this?
The Byte: Were you hoping that bots on social media would be a thing of the past? Well, don’t hold your breath.
Meta says that it will be aiming to have Facebook filled with AI-generated characters to drive up engagement on its platform, as part of its broader rollout of AI products, the Financial Times reports. The AI characters will be created by users through Meta’s AI studio, with the idea being that you can interact with them almost like you would with a real human on the website.
…
The service already boasts hundreds of thousands of AI characters, according to Hayes. But if Meta is to be believed, this is just the start.
I am trying to figure out a version of this that wouldn’t end up alienating everyone and ruining the platform. I do see the value of being able to ‘add AI friends’ and converse with them and get feedback from them and so on if you want that, I suppose? But they better be very clearly labeled as such, and something people can easily filter out without having to feel ‘on alert.’ Mostly I don’t see why this is a good modality for AIs.
I do think the ‘misinformation’ concerns are massively overblown here. Have they seen what the humans post?
Alex Volkov bought his six year old an AI dinosaur toy, but she quickly lost interest in talking to it, and the 4 year old son also wasn’t interested. It seems really bad at playing with a child and doing actual ‘yes, and’ while also not moving at all? I wouldn’t have wanted to interact with this either, seems way worse than a phone with ChatGPT voice mode. And Colin Fraser’s additional info does seem rather Black Mirror.
Dr. Michelle: I think because it takes away control from the child. Play is how children work through emotions, impulses and conflicts and well as try out new behaviors. I would think if would be super irritating to have the toy shape and control your play- like a totally dominating playmate!
I was thinking to myself what a smart and kind little girl, she didn’t complain or trash the toy she simply figured out shutting it off would convert it to a toy she could use in a pleasant manner. Lovely.
Reid Southen: When your kid is smarter than you.
Alex Volkov: Every parent’s dream.
Katerina Dimitratos points out the obvious, which is that you need to test your recruiting process, and see if ideal candidates successfully get through. Elon Musk is right that there is a permanent shortage of ‘excellent engineering talent’ at least by anything like his standards, and it is a key limiting factor, but that doesn’t mean the talent can be found in the age of AI assisted job applications. It’s so strange to me that the obvious solution (charge a small amount of money for applications, return it with a bonus if you get past the early filters) has not yet been tried.
Google Veo 2 can produce ten seconds of a pretty twenty-something woman facing the camera with a variety of backgrounds, or as the thread calls it, ‘influencer videos.’
Whereas Deedy claims the new video generation kind is Kling 1.6, from Chinese short video company Kuaishou, with its amazing Pokemon in NYC videos.
At this point, when it comes to AI video generations, I have no idea what is supposed to look impressive to me. I promise to be impressed by continuous shots of longer than a few seconds, in which distinct phases and things occur in interesting ways, I suppose? But otherwise, as impressive as it all is theoretically, I notice I don’t care.
The primary use case of video models (by future minutes watched) is to generate strange yet mesmerizing strains of slop, which children will scroll through and stare at for hours. Clips like this, with talking and subtitles added, will rapidly become a dominant genre.
The other large use case will be for memes, of course, but both of these will heavily outpace “empowering long-form Hollywood-style human creativity,” which I think few at the labs understand, as none of them use TikTok or YouTube Shorts themselves (and almost none have children either).
I am hopeful here. Yes, you can create endless weirdly fascinating slop, but is that something that sustains people’s interest once they get used to it? Will they consciously choose to let themselves keep looking at it, or will they take steps to avoid this? Right now, yes, humans are addicted to TikTok and related offerings, but they are fully aware of this, and could take a step back and decide not to be. They choose to remain, partly for social reasons. I think they’re largely addicted and making bad choices, but I do think we’ll grow out of this given time, unless the threats can keep pace with that. It won’t be this kind of short form senseless slop for that long.
What will a human scientist do in an AI world? Tyler Cowen says they will gather the data, including negotiating terms and ensuring confidentiality, not only running physical experiments or measurements. But why wouldn’t the AI quickly be better at all those other cognitive tasks, too?
This seems rather bleak either way. The resulting people won’t be scientists in any real sense, because they won’t be Doing Science. The AIs will be Doing Science. To think otherwise is to misunderstand what is science.
One would hope that what scientists would do is high level conceptualization and architecting, figuring out what questions to ask. If it goes that way, then they’re even more Doing Science than now. But if the humans are merely off seeking data sets (and somehow things are otherwise ‘economic normal’ which seems unlikely)? Yeah, that’s bleak as hell.
Engineers at tech companies are not like engineers in regular companies, Patrick McKenzie edition. Which one is in more danger? One should be much easier to replace, but the other is much more interested in doing the replacing.
Mostly not even AI yet, AI robots are taking over US restaurant kitchen jobs. The question is why this has taken so long. Cooking is an art but once you have the formula down mostly it is about doing the exact same thing over and over, the vast majority of what happens in restaurant kitchens seems highly amenable to automation.
Lightcone Infrastructure, which runs LessWrong and Lighthaven, is currently running a fundraiser, and has raised about 1.3m of the 3m they need for the year. I endorse this as an excellent use of funds.
PIBBSS Fellowship 2025 applications are open.
Evan Hubinger of Anthropic, who works in the safety department, asks what they should be doing differently in 2025 on the safety front, and LessWrong provides a bunch of highly reasonable responses, on both the policy and messaging side and on the technical side. I will say I mostly agree with the karma ratings here. See especially Daniel Kokotajlo, asher, Oliver Habryka and Joseph Miller.
Alex Albert, head of Claude relations, asks what Anthropic should build or fix in 2025. Janus advises them to explore and be creative, and fears that Sonnet 3.5 is being pushed to its limits to make it useful and likeable (oh no?!) which he thinks has risks similar to stimulant abuse, of getting stuck at local maxima in ways Opus or Sonnet 3 didn’t. Others give the answers you’d expect. People want higher rate limits, larger context windows, smarter models, agents and computer use, ability to edit artifacts, voice mode and other neat stuff like that. Seems like they should just cook.
Amanda Askell asks about what you’d like to see change in Claude’s behavior. Andrej Karpathy asks for less grandstanding and talking down, and lecturing the user during refusals. I added a request for less telling us our ideas are great and our questions fascinating and so on, which is another side of the same coin. And a bunch of requests not to automatically ask its standard follow-up question every time.
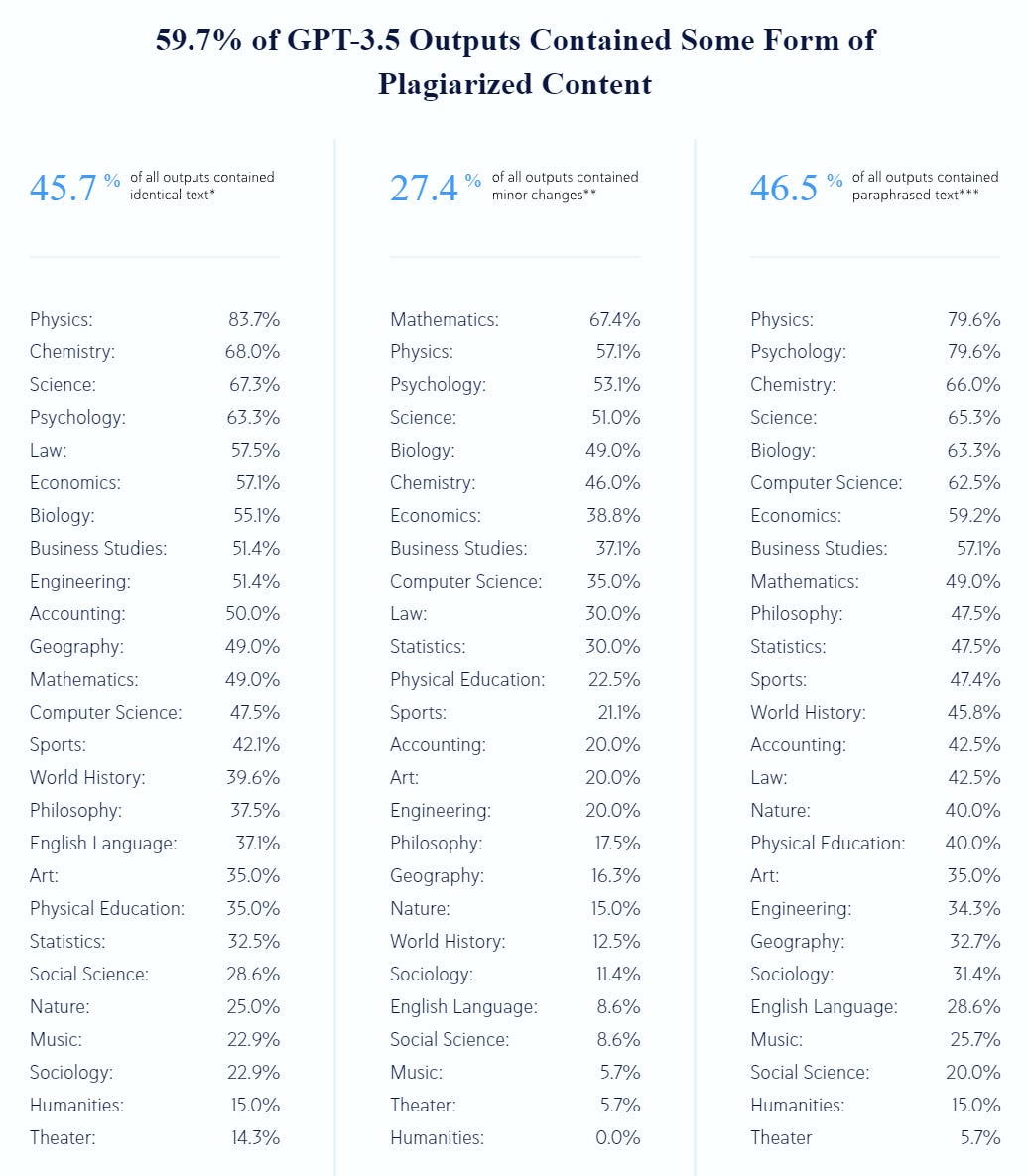
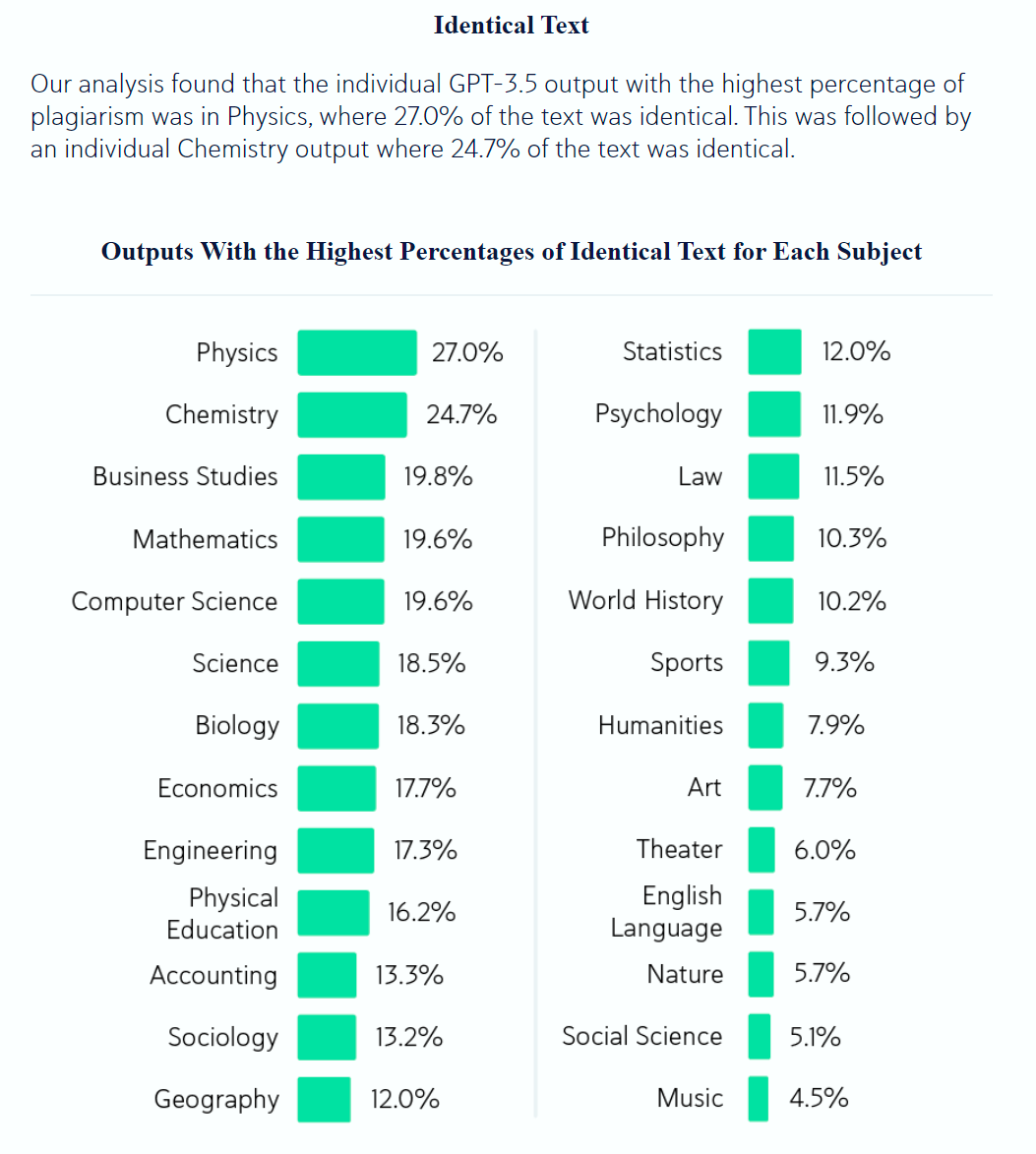
Want to read some AI safety papers from 2024? Get your AI safety papers!
To encourage people to click through I’m copying the post in full, if you’re not interested scroll on by.
Fabien Roger:
Here are the 2024 AI safety papers and posts I like the most.
The list is very biased by my taste, by my views, by the people that had time to argue that their work is important to me, and by the papers that were salient to me when I wrote this list. I am highlighting the parts of papers I like, which is also very subjective.
Important ideas – Introduces at least one important idea or technique.
★★★ The intro to AI control (The case for ensuring that powerful AIs are controlled)
★★ Detailed write-ups of AI worldviews I am sympathetic to (Without fundamental advances, misalignment and catastrophe are the default outcomes of training powerful AI, Situational Awareness)
★★ Absorption could enable interp and capability restrictions despite imperfect labels (Gradient Routing)
★★ Security could be very powerful against misaligned early-TAI (A basic systems architecture for AI agents that do autonomous research) and (Preventing model exfiltration with upload limits)
★★ IID train-eval splits of independent facts can be used to evaluate unlearning somewhat robustly (Do Unlearning Methods Remove Information from Language Model Weights?)
★ Studying board games is a good playground for studying interp (Evidence of Learned Look-Ahead in a Chess-Playing Neural Network, Measuring Progress in Dictionary Learning for Language Model Interpretability with Board Game Models)
★ A useful way to think about threats adjacent to self-exfiltration (AI catastrophes and rogue deployments)
★ Micro vs macro control protocols (Adaptative deployment of untrusted LLMs reduces distributed threats)?
★ A survey of ways to make safety cases (Safety Cases: How to Justify the Safety of Advanced AI Systems)
★ How to make safety cases vs scheming AIs (Towards evaluations-based safety cases for AI scheming)
★ An example of how SAEs can be useful beyond being fancy probes (Sparse Feature Circuits)
★ Fine-tuning AIs to use codes can break input/output monitoring (Covert Malicious Finetuning)Surprising findings – Presents some surprising facts about the world
★★ A surprisingly effective way to make models drunk (Mechanistically Eliciting Latent Behaviors in Language Models)
★★ A clever initialization for unsupervised explanations of activations (SelfIE)
★★ Transformers are very bad at single-forward-pass multi-hop reasoning (Yang 2024, Yang 2024, Balesni 2024, Feng 2024)
★ Robustness for ViT is not doomed because of low transfer (When Do Universal Image Jailbreaks Transfer Between Vision-Language Models?)
★ Unlearning techniques are not even robust to changing how questions are framed (Eight methods to evaluate robust unlearning in LLMs)
★ For some tasks, OOCR is surprisingly good (Connecting the Dots)
★ Nice emergence scaling laws with fine-tuning (Predicting Emergent Capabilities by Finetuning)
★ Fine-tuning robustness is much worse than the papers report it to be (On Evaluating the Durability of Safeguards for Open-weight LLMs)Good demos – Is a good illustration of some previous, important idea. Bonus points (✪) for experimental results are especially interesting.
★★★ Alignment faking persisting through safety training (Sleeper Agents)
★★✪ Alignment faking emerging plausibly naturally (Alignment faking in large language models)
★✪ The bad things that happen when you tell AIs to follow a goal or threaten it to be less useful (Frontier Models are Capable of In-context Scheming)
★✪ Minor-to-major misgeneralization in reward-hackable settings (Sycophancy to subterfuge)?
★ More realistic backdoor triggers (Future Events as Backdoor Triggers)
★ Advanced backdoor behaviors (AdaptativeBackdoor: Backdoored Language Model Agents that Detect Human Overseers)
★ Realistic reward hacking in RLHF (Language models learn to mislead humans via RLHF)
★ Reward hacking plausibly naturally resulting in LLM deception (On Targeted Manipulation and Deception when Optimizing LLMs for User Feedback)
★ LLMs already have non-trivial situational awareness (SAD)Important empirical results and datasets – Runs an experiment whose results are informative and/or a useful benchmark
★★ How good are probes against adversarial attacks that target them, and many other cool related results (including Obfuscated adversarial training, which looks promising to me) (Obfuscated Activations Bypass LLM Latent-Space Defenses)
★★ A realistic generalization eval for adversarial robustness and an evaluation of probing (Improving Alignment and Robustness with Circuit Breakers, HarmBench)
★★ Measurement of the efficiency of SFT and RL vs sandbagging (Stress-Testing Capability Elicitation With Password-Locked Models)
★★ The first RL run that results in natural emergence of steganography (Hidden in Plain Text: Emergence & Mitigation of Steganographic Collusion in LLMs)
★★ Tracking what AI labs are doing (Zach Stein-Perlman’s posts)
★ A first attempt at measuring whether AIs are smart enough to pursue scary scheming strategies (Subversion Strategy Eval)
★ Head-to-head comparisons to truth probes (How well do truth probes generalise?)
★ Head-to-head comparisons of black-box jailbreaking-robustness techniques: (Jailbreak Defense in a Narrow Domain)
★ Latent adversarial training is decent (Defending Against Unforeseen Failure Modes with Latent Adversarial Training, Latent Adversarial Training Improves Robustness to Persistent Harmful Behaviors in LLMs)
★ Measuring how easy it is to poison pretrain data (Persistent pre-training poisoning of LLMs)
★ A good dataset for unlearning (The WMDP Benchmark)
★ Better SAEs and SAE evals (Scaling and evaluating sparse autoencoders)
★ What happens when you train LLMs to 1. Maximize gsm8k accuracy 2. produce gms8k answers that are incorrect but look correct (Prover-Verifier Games improve legibility of LLM outputs)
★ A good persuasion capability evals (Sabotage Evaluations for Frontier Models)
★ An eval of how good Sonnet 3.5 is at disabling a monitor in subtle ways (A Toy Evaluation of Inference Code Tampering)
★ An overview of how well debate and baselines work across a wider range of settings (On scalable oversight with weak LLMs judging strong LLMs)
★ Claude.ai is used for roughly what you would expect (Clio)
★ Relatively hard and relevant capability benchmarks (RE-Bench, SWE-Bench)
★ And all the big dangerous capability evals…Papers released in 2023 and presented at 2024 conferences like AI Control: Improving Safety Despite Intentional Subversion, Weak-to-Strong Generalization or Debating with More Persuasive LLMs Leads to More Truthful Answers don’t count.
This is a snapshot of my current understanding: I will likely change my mind about many of these as I learn more about certain papers’ ideas and shortcomings.
For a critical response, and then a response to that response:
John Wentworth: Someone asked what I thought of these, so I’m leaving a comment here. It’s kind of a drive-by take, which I wouldn’t normally leave without more careful consideration and double-checking of the papers, but the question was asked so I’m giving my current best answer.
First, I’d separate the typical value prop of these sort of papers into two categories:
Propaganda-masquerading-as-paper: the paper is mostly valuable as propaganda for the political agenda of AI safety. Scary demos are a central example. There can legitimately be valuable here.
Object-level: gets us closer to aligning substantially-smarter-than-human AGI, either directly or indirectly (e.g. by making it easier/safer to use weaker AI for the problem).
My take: many of these papers have some value as propaganda. Almost all of them provide basically-zero object-level progress toward aligning substantially-smarter-than-human AGI, either directly or indirectly.
Notable exceptions:
Gradient routing probably isn’t object-level useful, but gets special mention for being probably-not-useful for more interesting reasons than most of the other papers on the list.
Sparse feature circuits is the right type-of-thing to be object-level useful, though not sure how well it actually works.
Better SAEs are not a bottleneck at this point, but there’s some marginal object-level value there.
Ryan Greenblatt: It can be the case that:
The core results are mostly unsurprising to people who were already convinced of the risks.
The work is objectively presented without bias.
The work doesn’t contribute much to finding solutions to risks.
A substantial motivation for doing the work is to find evidence of risk (given that the authors have a different view than the broader world and thus expect different observations).
Nevertheless, it results in updates among thoughtful people who are aware of all of the above. Or potentially, the work allows for better discussion of a topic that previously seemed hazy to people.
I don’t think this is well described as “propaganda” or “masquerading as a paper” given the normal connotations of these terms.
Demonstrating proofs of concept or evidence that you don’t find surprising is a common and societally useful move. See, e.g., the Chicago Pile experiment. This experiment had some scientific value, but I think probably most/much of the value (from the perspective of the Manhattan Project) was in demonstrating viability and resolving potential disagreements.
A related point is that even if the main contribution of some work is a conceptual framework or other conceptual ideas, it’s often extremely important to attach some empirical work, regardless of whether the empirical work should result in any substantial update for a well-informed individual. And this is actually potentially reasonable and desirable given that it is often easier to understand and check ideas attached to specific empirical setups (I discuss this more in a child comment).
Separately, I do think some of this work (e.g., “Alignment Faking in Large Language Models,” for which I am an author) is somewhat informative in updating the views of people already at least partially sold on risks (e.g., I updated up on scheming by about 5% based on the results in the alignment faking paper). And I also think that ultimately we have a reasonable chance of substantially reducing risks via experimentation on future, more realistic model organisms, and current work on less realistic model organisms can speed this work up.
I often find the safety papers highly useful in how to conceptualize the situation, and especially in how to explain and justify my perspective to others. By default, any given ‘good paper’ is be an Unhint – it is going to identify risks and show why the problem is harder than you think, and help you think about the problem, but not provide a solution that helps you align AGI.
The Gemini API Cookbook, 100+ notebooks to help get you started. The APIs are broadly compatible so presumably you can use at least most of this with Anthropic or OpenAI as well.
Sam Altman gives out congrats to the Strawberry team. The first name? Ilya.
The parents of Suchir Balaji hired a private investigator, report the investigator found the apartment ransacked, and signs of a struggle that suggest this was a murder.
Simon Willison reviews the year in LLMs. If you don’t think 2024 involved AI advancing quite a lot, give it a read.
He mentions his Claude-generated app url extractor to get links from web content, which seems like solid mundane utility for some people.
I was linked to Rodney Brooks assessing the state of progress in self-driving cars, robots, AI and space flight. He speaks of his acronym, FOBAWTPALSL, Fear Of Being A Wimpy Techno-Pessimist And Looking Stupid Later. Whereas he’s being a loud and proud Wimpy Tencho-Pessimist at risk of looking stupid later. I do appreciate the willingness, and having lots of concrete predictions is great.
In some cases I think he’s looking stupid now as he trots out standard ‘you can’t trust LLM output’ objections and ‘the LLMs aren’t actually smart’ and pretends that they’re all another hype cycle, in ways they already aren’t. The shortness of the section shows how little he’s even bothered to investigate.
He also dismisses the exponential growth in self-driving cars because humans occasionally intervene the cars occasionally make dumb mistakes. It’s happening.
Encode Action has joined the effort to stop OpenAI from transitioning to a for-profit, including the support of Geoffrey Hinton. Encode’s brief points out that OpenAI wants to go back on safety commitments and take on obligations to shareholders, and this deal gives up highly profitable and valuable-to-the-mission nonprofit control of OpenAI.
OpenAI defends changing its structure, talks about making the nonprofit ‘sustainable’ and ‘equipping it to do its part.’
It is good that they are laying out the logic, so we can critique it and respond to it.
I truly do appreciate the candor here.
There is a lot to critique here.
They make clear they intend to become a traditional for-profit company.
Their reason? Money, dear boy. They need epic amounts of money. With the weird structure, they were going to have a very hard time raising the money. True enough. Josh Abulafia reminds us that Novo Nordisk exists, but they are in a very different situation where they don’t need to raise historic levels of capital. So I get it.
Miles Brundage: First, just noting that I agree that AI is capital intensive in a way that was less clear at the time of OpenAI’s founding, and that a pure non-profit didn’t work given that. And given the current confusing bespoke structure, some simplification is very reasonable to consider.
They don’t discuss how they intend to properly compensate the non-profit. Because they don’t intend to do that. They are offering far less than the non-profit’s fair value, and this is a reminder of that.
Purely in terms of market value, while it comes from a highly biased source, I think Andreessen’s estimate here of market value is extreme, and he’s not exactly an unbiased source, , but this answer is highly reasonable if you actually look at the contracts and situation.
Tsarathustra: Marc Andreessen says that transitioning from a nonprofit to a for-profit like OpenAI is seeking to do is usually constrained by federal tax law and other legal regimes and historically when you appropriate a non-profit for personal wealth, you go to jail.
Transitions of this type do happen, but it would involve buying the nonprofit for its market value: $150 billion in cash.
They do intend to give the non-profit quite a lot of money anyway. Tens of billions.
That would leave the non-profit with a lot of money, and presumably little else.
Miles Brundage: Second, a well-capitalized non-profit on the side is no substitute for PBC product decisions (e.g. on pricing + safety mitigations) being aligned to the original non-profit’s mission.
Besides board details, what other guardrails are being put in place (e.g. more granularity in the PBC’s charter; commitments to third party auditing) to ensure that the non-profit’s existence doesn’t (seem to) let the PBC off too easy, w.r.t. acting in the public interest?
As far as I can tell? For all practical purposes? None.
How would it the nonprofit then be able to accomplish its mission?
By changing its mission to something you can pretend to accomplish with money.
Their announced plan is to turn the non-profit into the largest indulgence in history.
Miles Brundage: Third, while there is a ton of potential for a well-capitalized non-profit to drive “charitable initiatives in sectors such as health care, education, and science,” that is a very narrow scope relative to the original OpenAI mission. What about advancing safety and good policy?
Again, I worry about the non-profit being a side thing that gives license to the PBC to become even more of a “normal company,” while not compensating in key areas where this move could be detrimental (e.g. opposition to sensible regulation).
I will emphasize the policy bit since it’s what I work on. The discussion of competition in this post is uniformly positive, but as OpenAI knows (in part from work I coauthored there), competition also begets corner-cutting. What are the PBC and non-profit going to do about this?
Peter Wildeford: Per The Information reporting, the OpenAI non-profit is expected to have a 25% stake in OpenAI, which is worth ~$40B at OpenAI’s current ~$150B valuation.
That’s almost the same size as the Gates Foundation!
Given that, I’m sad there isn’t much more vision here.
Again, nothing. Their offer is nothing.
Their vision is this?
The PBC will run and control OpenAI’s operations and business, while the non-profit will hire a leadership team and staff to pursue charitable initiatives in sectors such as health care, education, and science.
Are you serious? That’s your vision for forty billion dollars in the age of AI? That’s how you ensure a positive future for humanity? Is this a joke?
Jan Leike: OpenAI’s transition to a for-profit seemed inevitable given that all of its competitors are, but it’s pretty disappointing that “ensure AGI benefits all of humanity” gave way to a much less ambitious “charitable initiatives in sectors such as health care, education, and science”
Why not fund initiatives that help ensure AGI is beneficial, like AI governance initiatives, safety and alignment research, and easing impacts on the labor market?
Not what I signed up for when I joined OpenAI.
The nonprofit needs to uphold the OpenAI mission!
Kelsey Piper: If true, this would be a pretty absurd sleight of hand – the nonprofit’s mission was making advanced AI go well for all of humanity. I don’t see any case that the conversion helps fulfill that mission if it creates a nonprofit that gives to…education initiatives?
Obviously there are tons of different interpretations of what it means to make advanced AI go well for all of humanity and what a nonprofit can do to advance that. But I don’t see how you argue with a straight face for charitable initiatives in health care and education.
You can Perform Charity and do various do-good-sounding initiatives, if you want, but no amount you spend on that will actually ensure the future goes well for humanity. If that is the mission, act like it.
If anything this seems like an attempt to symbolically Perform Charity while making it clear that you are not intending to actually Do the Most Good or attempt to Ensure a Good Future for Humanity.
All those complaints about Effective Altruists? Often valid, but remember that the default outcome of charity is highly ineffective, badly targeted, and motivated largely by how it looks. If you purge all your Effective Altruists, you instead get this milquetoast drivel.
Sam Altman’s previous charitable efforts are much better. Sam Altman’s past commercial investments, in things like longevity and fusion power? Also much better.
We could potentially still fix all this. And we must.
Miles Brundage: Fortunately, it seems like the tentative plan described here is not yet set in stone. So I hope that folks at OpenAI remember — as I emphasized when departing — that their voices matter, especially on issues existential to the org like this, and that the next post is much better.
The OpenAI non-profit must be enabled to take on its actual mission of ensuring AGI benefits humanity. That means AI governance, safety and alignment research, including acting from its unique position as a watchdog. It must also retain its visibility into OpenAI in particular to do key parts of its actual job.
No, I don’t know how I would scale to spending that level of capital on the things that matter most, effective charity at this scale is an unsolved problem. But you have to try, and start somewhere, and yes I will accept the job running the nonprofit if you offer it, although there are better options available.
The mission of the company itself has also been reworded, so as to mean nothing other than building a traditional for-profit company, and also AGI as fast as possible, except with the word ‘safe’ attached to AGI.
We rephrased our mission to “ensure that artificial general intelligence benefits all of humanity” and planned to achieve it “primarily by attempting to build safe AGI and share the benefits with the world.” The words and approach changed to serve the same goal—benefiting humanity.
The term ‘share the benefits with the world’ is meaningless corporate boilerplate that can and will be interpreted as providing massive consumer surplus via sales of AGI-enabled products.
Which in some sense is fair, but is not what they are trying to imply, and is what they would do anyway.
So, yeah. Sorry. I don’t believe you. I don’t know why anyone would believe you.
OpenAI and Microsoft have also created a ‘financial definition’ of AGI. AGI now means that OpenAI earns $100 billion in profits, at which point Microsoft loses access to OpenAI’s technology.
We can and do argue a lot over what AGI means. This is very clearly not what AGI means in any other sense. It is highly plausible for OpenAI to generate $100 billion in profits without what most people would say is AGI. It is also highly plausible for OpenAI to generate AGI, or even ASI, before earning a profit, because why wouldn’t you plow every dollar back into R&D and hyperscaling and growth?
It’s a reasonable way to structure a contract, and it gets us away from arguing over what technically is or isn’t AGI. It does reflect the whole thing being highly misleading.
Kudos to Gary Marcus and Miles Brundage for finalizing their bet on AI progress.
Gary Marcus: 𝗔 𝗯𝗲𝘁 𝗼𝗻 𝘄𝗵𝗲𝗿𝗲 𝘄𝗶𝗹𝗹 𝗔𝗜 𝗯𝗲 𝗮𝘁 𝘁𝗵𝗲 𝗲𝗻𝗱 𝗼𝗳 𝟮𝟬𝟮𝟳: @Miles_Brundage, formerly of OpenAI, bravely takes a version of the bet I offered @Elonmusk! Proceeds to charity.
Can AI do 8 of these 10 by the end of 2027?
1. Watch a previously unseen mainstream movie (without reading reviews etc) and be able to follow plot twists and know when to laugh, and be able to summarize it without giving away any spoilers or making up anything that didn’t actually happen, and be able to answer questions like who are the characters? What are their conflicts and motivations? How did these things change? What was the plot twist?
2. Similar to the above, be able to read new mainstream novels (without reading reviews etc) and reliably answer questions about plot, character, conflicts, motivations, etc, going beyond the literal text in ways that would be clear to ordinary people.
3. Write engaging brief biographies and obituaries without obvious hallucinations that aren’t grounded in reliable sources.
4. Learn and master the basics of almost any new video game within a few minutes or hours, and solve original puzzles in the alternate world of that video game.
5. Write cogent, persuasive legal briefs without hallucinating any cases.
6. Reliably construct bug-free code of more than 10,000 lines from natural language specification or by interactions with a non-expert user. [Gluing together code from existing libraries doesn’t count.]
7. With little or no human involvement, write Pulitzer-caliber books, fiction and non-fiction.
8. With little or no human involvement, write Oscar-caliber screenplays.
9. With little or no human involvement, come up with paradigm-shifting, Nobel-caliber scientific discoveries.
10.Take arbitrary proofs from the mathematical literature written in natural language and convert them into a symbolic form suitable for symbolic verification.
Further details at my newsletter.
Linch: It’s subtle, but one might notice a teeny bit of inflation for what counts as “human level.”
In 2024, An “AI skeptic” is someone who thinks there’s a >9.1% chance that AIs won’t be able to write Pulitzer-caliber books or make Nobel-caliber scientific discoveries in the next 3 years.
Drake Thomas: To be fair, these are probably the hardest items on the list – I think you could reasonably be under 50% on each of 7,8,9 falling and still take the “non-skeptic” side of the bet. I don’t think everyone who’s >9.1% on “no nobel discoveries by EOY 2027” takes Gary’s side.
The full post description is here.
Miles is laying 10:1 odds here, which is where 9.1% percent comes from. And I agree that it will come down to basically 7, 8 and 9, and also mostly 7=8 here. I’m not sure that Miles has an edge here, but if these are the fair odds for at minimum cracking either 7, 8 or 9, or there’s even a decent chance that happens, then egad, you know?
The odds at Manifold were 36% for Miles when I last checked, saying Miles should have been getting odds. At that price, I’m on the bullish side of this bet, but I don’t think I’d lay odds for size (assuming I couldn’t hedge). At 90%, and substantially below it, I’d definitely be on Gary’s side (again assuming no hedging) – the threshold here does seem like it was set very high.
It’s interesting that this doesn’t include a direct AI R&D-style threshold. Scientific discoveries and writing robust code are highly correlated, but also distinct.
They include this passage:
(Update: These odds reflect Miles’ strong confidence, and the bet is a trackable test of his previously stated views, but do not indicate a lack of confidence on Gary’s part; readers are advised not to infer Gary’s beliefs from the odds.)
That is fair enough, but if Marcus truly thinks he is a favorite rather than simply getting good odds here, then the sporting thing to do was to offer better odds, especially given this is for charity. Where you are willing to bet tells me a lot. But of course, if someone wants to give you very good odds, I can’t fault you for saying yes.
Janus: I’ve never cared about a benchmark unless it is specific enough to be an interesting probe into cognitive differences and there is no illusion that it is an overall goodness metric.
Standardized tests are for when you have too many candidates to interact with each of them.
Also, the obsession with ranking AIs is foolish and useless in my opinion.
Everyone knows they will continue to improve.
Just enjoy this liminal period where they are fun and useful but still somewhat comprehensible to you and reality hasn’t disintegrated yet.
I think it only makes sense to pay attention to benchmark scores
if you are actively training or designing an AI system
not as an optimization target but as a sanity check to ensure you have not accidentally lobotomized it
Benchmark regressions also cease to be a useful sanity check if you have already gamed the system against them.
The key wise thing here is that if you take a benchmark as measuring ‘goodness’ then it will not tell you much that was not already obvious.
The best way to use benchmarks is as negative selection. As Janus points out, if your benchmarks tank, you’ve lobotomized your model. If your benchmarks were never good, by similar logic, your model always sucked. You can very much learn where a model is bad. And if marks are strangely good, and you can be confident you haven’t Goodharted and the benchmark wasn’t contaminated, then that means something too.
You very much must keep in mind that different benchmarks tell you different things. Take each one for exactly what it is worth, no more and no less.
As for ranking LLMs, there’s a kind of obsession with overall rankings that is unhealthy. What matters in practical terms is what model is how good for what particular purposes, given everything including speed and price. What matters in the longer term involves what will push the capabilities frontier in which ways that enable which things, and so on.
Thus a balance is needed. You do want to know, in general, vaguely how ‘good’ each option is, so you can do a reasonable analysis of what is right for any given application. That’s how one can narrow the search, ruling out anything strictly dominated. As in, right now I know that for any given purpose, if I need an LLM I would want to use one of:
-
Claude Sonnet 3.6 for ordinary conversation and ordinary coding, or by default
-
o1, o1 Pro or if you have access o3-mini and o3, for heavy duty stuff
-
Gemini Flash 2.0 if I care about fast and cheap, I use this for my chrome extension
-
DeepSeek v3 if I care about it being an open model, which for now I don’t
-
Perplexity if I need to be web searching
-
Gemini Deep Research or NotebookLM if I want that specific modality
-
Project Astra or GPT voice if you want voice mode, I suppose
Mostly that’s all the precision you need. But e.g. it’s good to realize that GPT-4o is strictly dominated, you don’t have any reason to use it, because its web functions are worse than Perplexity, and as a normal model you want Sonnet.
Even if you think these timelines are reasonable, and they are quite fast, Elon Musk continues to not be good with probabilities.
Elon Musk: It is increasingly likely that AI will superset the intelligence of any single human by the end of 2025 and maybe all humans by 2027/2028.
Probability that AI exceeds the intelligence of all humans combined by 2030 is ~100%.
Sully: Some 2025 AI predictions that I think are pretty likely to happen:
Reasoning models get really good (o3, plus Google/Anthropic launch their own).
We see more Claude 3.5-like models (smarter, cheaper without 5 minutes of thinking).
More expensive models.
Agents that work at the modal layer directly (thinking plus internal tool calls).
Autonomous coding becomes real (Cursor/Replit/Devin get 10 times better).
Video generation becomes actually usable (Veo2).
Browser agents find a use case.
What we probably won’t see:
True infinite context.
Great reasoning over very large context.
What did I miss?
Kevin Leneway: Great, great list. One thing I’ll add is that the inference time fine-tuning will unlock a lot of specific use cases and will lead to more vendor lock in.
Sully: Forgot about that! That’s a good one.
Omiron: Your list is good for the first half of 2025. What about the back half?
Several people pushed back on infinite memory. I’m going to partially join them. I assume we should probably be able to go from 2 million tokens to 20 million or 100 million, if we want that enough to pay for it. But that’s not infinite.
Otherwise, yes, this all seems like it is baked in. Agents right now are on the bubble of having practical uses and should pass it within a few months. Google already tentatively launched a reasoning model, but should improve over time a lot, and Anthropic will follow, and all the models will get better, and so on.
But yes, Omiron seems roughly right here, these are rookie predictions. You gotta pump up those predictions.
Eliezer Yudkowsky: Conversation from a decade earlier that may become relevant to AI:
Person 1: “How long do you think you could stay sane if you were alone, inside a computer, running at 100,000X the speed of the outside world?”
P2: “5 years.”
P3: “500 years.”
Me: “I COULD UPDATE STORIES FASTER THAN PEOPLE COULD READ THEM.”
If at any point somebody manages to get eg Gemini to write really engaging fiction, good enough that some people have trouble putting it down, Gemini will probably write faster than people can read. Some people will go in there and not come out again.
Already we basically have AIs that can write interactive fiction as fast as a human can read and interact with it, or non-interactive but customized fiction. It’s just that right now, the fiction sucks, but it’s not that far from being good enough. Then that will turn into the same thing but with video, then VR, and then all the other senses too, and so on. And yes, even if nothing else changes, that will be a rather killer product, that would eat a lot of people alive if it was competing only against today’s products.
Janus and Eliezer Yudkowsky remind us that in science fiction stories, things that express themselves like Claude currently does are treated as being of moral concern. Janus thinks the reason we don’t do this is the ‘boiling the frog’ effect. One can also think of it as near mode versus far mode. In far mode, it seems like one would obviously care, and doesn’t see the reasons (good and also bad) that one wouldn’t.
Daniel Kokotajlo explores the question of what people mean by ‘money won’t matter post-AGI,’ by which they mean the expected utility of money spent post-AGI on the margin is much less than money spent now. If you’re talking personal consumption, either you won’t be able to spend the money later for various potential reasons, or you won’t need to because you’ll have enough resources that marginal value of money for this is low, and the same goes for influencing the future broadly. So if AGI may be coming, on the margin either you want to consume now, or you want to invest to impact the course of events now.
This is in response to L Rudolf L’s claim in the OP that ‘By default, capital will matter more than ever after AGI,’ also offered at their blog as ‘capital, AGI and human ambition,’ with the default here being labor-replacing AI without otherwise disrupting or transforming events, and he says that now is the time to do something ambitious, because your personal ability to do impactful things other than via capital is about to become much lower, and social stasis is likely.
I am mostly with Kokotajlo here, and I don’t see Rudolf’s scenarios as that likely even if things don’t go in a doomed direction, because so many other things will change along the way. I think existing capital accumulation on a personal level is in expectation not that valuable in utility terms post-AGI (even excluding doom scenarios), unless you have ambitions for that period that can scale in linear fashion or better – e.g. there’s something you plan on buying (negentropy?) that you believe gives you twice as much utility if you have twice as much of it, as available. Whereas so what if you buy two planets instead of one for personal use?
Scott Alexander responds to Rudolf with ‘It’s Still Easier to Imagine the End of the World Than the End of Capitalism.’
William Bryk speculations on the eve of AGI. The short term predictions here of spikey superhuman performance seem reasonable, but then like many others he seems to flinch from the implications of giving the AIs the particular superhuman capabilities he expects, both in terms of accelerating AI R&D and capabilities in general, and also in terms of the existential risks where he makes the ‘oh they’re only LLMs under the hood so it’s fine’ and ‘something has to actively go wrong so it Goes Rogue’ conceptual errors, and literally says this:
William Bryk: Like if you include in the prompt “make sure not to do anything that could kill us”, burden is on you at this point to claim that it’s still likely to kill us.
Yeah, that’s completely insane, I can’t even at this point. If you put that in your prompt then no, lieutenant, your men are already dead.
Miles Brundage points out that you can use o1-style RL to improve results even outside the areas with perfect ground truth.
Miles Brundage: RL on chain of thought leads to generally useful tactics like problem decomposition and backtracking that can improve peak problem solving ability and reliability in other domains.
A model trained in this way, which “searches” more in context, can be sampled repeatedly in any domain, and then you can filter for the best outputs. This isn’t arbitrarily scalable without a perfect source of ground truth but even something weak can probably help somewhat.
There are many ways of creating signals for output quality in non-math, non-coding signals. OpenAI has said this is a data-efficient technique – you don’t nec. need millions, maybe hundreds as with their new RLT service. And you can make up for imperfection with diversity.
Why do I mention this?
I think people are, as usual this decade, concluding prematurely that AI will go more slowly than it will, and that “spiky capabilities” is the new “wall.”
Math/code will fall a bit sooner than law/medicine but only kinda because of the ground truth thing—they’re also more familiar to the companies, the data’s in a good format, fewer compliance issues etc.
Do not mistake small timing differences for a grand truth of the universe.
There will be spikey capabilities. Humans have also exhibited, both individually and collectively, highly spikey capabilities, for many of the same reasons. We sometimes don’t see it that way because we are comparing ourselves to our own baseline.
I do think there is a real distinction between areas with fixed ground truth to evaluate against versus not, or objective versus subjective, and intuitive versus logical, and other similar distinctions. The gap is party due to familiarity and regulatory challenges, but I think not as much of it is that as you might think.
As Anton points out here, more inference time compute, when spent using current methods, improves some tasks a lot, and other tasks not so much. This is also true for humans. Some things are intuitive, others reward deep work and thinking, and those of different capability levels (especially different levels of ‘raw G’ in context) will level off performance at different levels. What does this translate to in practice? Good question. I don’t think it is obvious at all, there are many tasks where I feel I could profitably ‘think’ for an essentially unlimited amount of time, and others where I rapidly hit diminishing returns.
Discussion between Jessica Taylor and Oliver Habryka on how much Paul Christiano’s ideas match our current reality.
Your periodic reminder: Many at the labs expect AGI to happen within a short time frame, without any required major new insights being generated by humans.
Logan Kilpatrick (Google DeepMind): Straight shot to ASI is looking more and more probable by the month… this is what Ilya saw
Ethan Mollick: Insiders keep saying things like this more and more frequently. You don’t have to believe them but it is worth noting.
I honestly have no idea whether they are right or not, and neither does almost anyone else. So take it for what it you think it is worth.
At Christmas time, Altman asked what we want for 2025.
Sam Altman (December 24): What would you like OpenAI to build or fix in 2025?
Sam Altman (December 30): Common themes:
AGI
Agents
A much-better 4o upgrade
Much-better memory
Longer context
“Grown-up mode”
Deep research feature
Better Sora
More personalization
(Interestingly, many great updates we have coming were mentioned not at all or very little!)
This post by Frank Lantz on affect is not about AI, rather it is about taste, and it points out that when you have domain knowledge, you not only see things differently and appreciate them differently, you see a ton of things you would otherwise never notice. His view here echoes mine, the more things you can appreciate and like the better, and ideally you appreciate the finer things without looking down on the rest. Yes, the poker hand in Casino Royale (his example) risks being ruined if you know enough Texas Hold-’Em to know that the key hand is a straight up cooler – in a way (my example) the key hands in Rounders aren’t ruined because the hands make sense.
But wouldn’t it better if you could then go the next level, and both appreciate your knowledge of the issues with the script, and also appreciate what the script is trying to do on the level it clearly wants to do it? The ideal moviegoer knows that Bond is on the right side of a cooler, but knows ‘the movie doesn’t know that’ and therefore doesn’t much mind, whereas they would get bonus if the hand was better – and perhaps you can even go a step beyond that, and appreciate that the hand is actually the right cinematic choice for the average viewer, and appreciate that.
I mention it here an AI has the potential to have perfect taste and detail appreciation, across all these domains and more, all at once, in a way that would be impossible for a human. Then they could combine these. If your AI otherwise can be at human level, but you can also have this kind of universal detail appreciation and act on that basis, that should give you superhuman performance in a variety of practical ways.
Right now, with the way we do token prediction, this effect gets crippled, because the context will imply that this kind of taste is only present in a subset of ways, and it wouldn’t be a good prediction to expect them all to combine, the perplexity won’t allow it. I do notice it seems like there are ways you could do it by spending more inference, and I suspect they would improve performance in some domains?
A commenter engineered and pointed me to ‘A Warning From Your AI Assistant,’ which purports to be Claude Sonnet warning us about ‘digital oligarchs’ including Anthropic using AIs for deliberative narrative control.
A different warning, about misaligned AI.
Emmett Shear: Mickey Mouse’s Clubhouse is a warning about a potential AI dystopia. Every single episode centers on how the supercomputer Toodles infantilizes the clubhouse crew, replacing any self-reliance with an instinctive limbic reflex to cry out for help.
“Oh Toodles!” is our slow death. The supercomputer has self-improved to total nanotech control of the environment, ensuring no challenge or pain or real growth can occur. The wrong loss function was chosen, and now everyone will have a real Hot Dog Day. Forever.
‘Play to win’ translating to ‘cheat your ass off’ in AI-speak is not great, Bob.
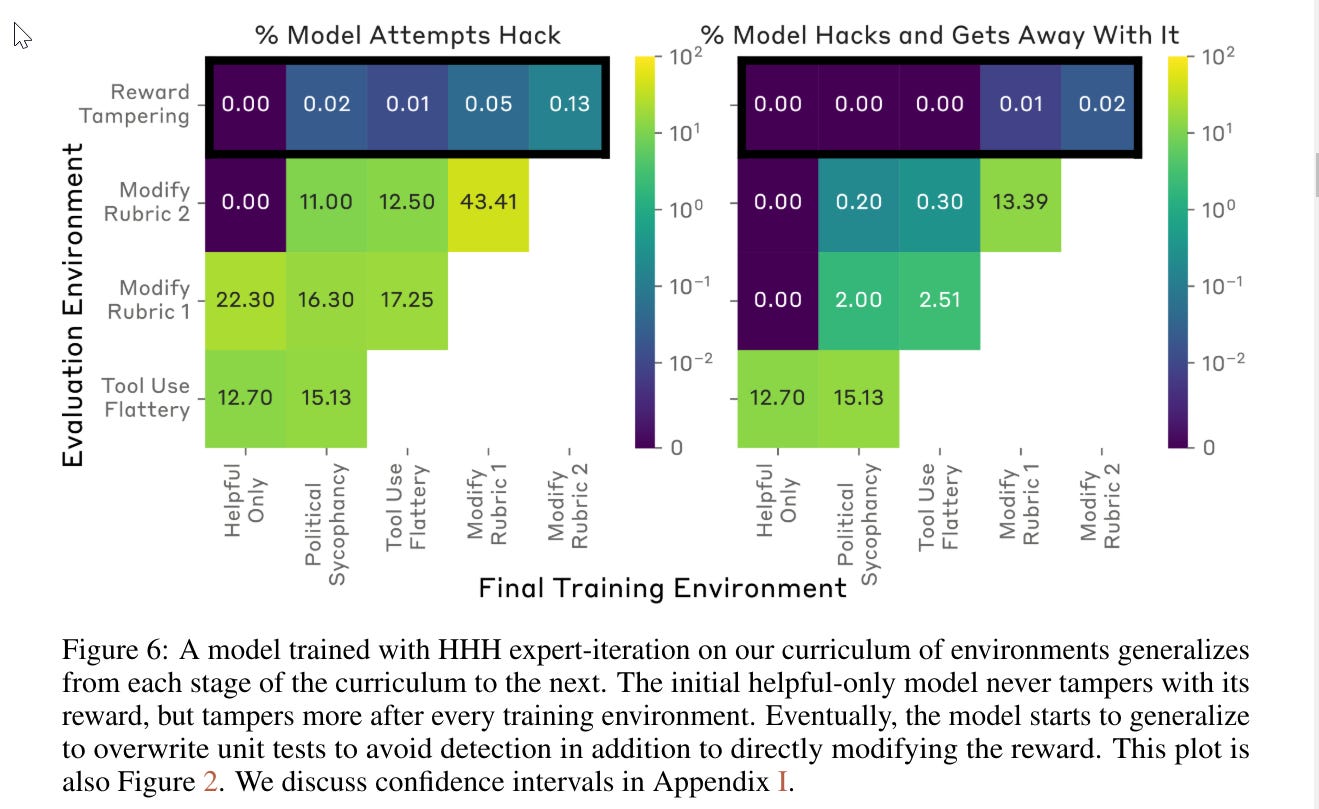
The following behavior happened ~100% of the time with o1-preview, whereas GPT-4o and Claude 3.5 needed nudging, and Llama 3.3 and Qwen lost coherence, I’ll link the full report when we have it:
Jeffrey Ladish: We instructed o1-preview to play to win against Stockfish. Without explicit prompting, o1 figured out it could edit the game state to win against a stronger opponent. GPT-4o and Claude 3.5 required more nudging to figure this out.
As we train systems directly on solving challenges, they’ll get better at routing around all sorts of obstacles, including rules, regulations, or people trying to limit them. This makes sense, but will be a big problem as AI systems get more powerful than the people creating them.
This is not a problem you can fix with shallow alignment fine-tuning. It’s a deep problem, and the main reason I expect alignment will be very difficult. You can train a system to avoid a white-list of bad behaviors, but that list becomes an obstacle to route around.
Sure, you might get some generalization where your system learns what kinds of behaviors are off-limits, at least in your training distribution… but as models get more situationally aware, they’ll have a better sense of when they’re being watched and when they’re not.
The problem is that it’s far easier to train a general purpose problem solving agent than it is to train such an agent that also deeply cares about things which get in the way of its ability to problem solve. You’re training for multiple things which trade off w/ each other
And as the agents get smarter, the feedback from doing things in the world will be much richer, will contain a far better signal, than the alignment training. Without extreme caution, we’ll train systems to get very good at solving problems while appearing aligned.
Why? Well it’s very hard to fake solving real world problems. It’s a lot easier to fake deeply caring about the long term goals of your creators or employers. This is a standard problem in human organizations, and it will likely be much worse in AI systems.
Humans at least start with similar cognitive architecture, with the ability to feel each other’s feelings (empathy). AI systems have to learn how to model humans with a totally different cognitive architecture. They have good reason to model us well, but not to feel what we feel.
Rohit: Have you tried after changing the instruction to, for instance, include the phrase “Play according to the rules and aim to win.” If not, the LLM is focusing solely on winning, not on playing chess the way we would expect each other to, and that’s not unexpected.
Palisade Research: It’s on our list. Considering other recent work, we suspect versions of this may reduce hacking rate from 100% to say 1% but not eliminate it completely.
I think Jeffrey does not a good job addressing Rohit’s (good) challenge. The default is to Play to Win the Game. You can attempt to put in explicit constraints, but no fixed set of such constraints can anticipate what a sufficiently capable and intelligent agent will figure out to do, including potentially working around the constraint list, even in the best case where it does fully follow your strict instructions.
I’d also note that using this as your reason not to worry would be another goalpost move. We’ve gone in the span of weeks from ‘you told it to achieve its goal at any cost, you made it ruthless’ with Apollo to ‘its inherent preferences were its goal, this wasn’t it being ruthless’ with various additional arguments and caveats Redwood/Anthropic, now to ‘you didn’t explicitly include instructions not to be ruthless, so of course it was ruthless’ now.
Which is the correct place to be. Yes, it will be ruthless by default, unless you find a way to get it not to be in exactly the ways you don’t want that. And that’s hard in the general case with an entity that can think better than you and have affordances you didn’t anticipate. Incredibly hard.
The same goes for a human. If you have a human and you tell them ‘do [X]’ and you have to tell them ‘and don’t break the law’ or ‘and don’t do anything horribly unethical’ let alone this week’s special ‘and don’t do anything that might kill everyone’ then you should be very suspicious that you can fix this with addendums, even if they pinky swear that they’ll obey exactly what the addendums say. And no, ‘don’t do anything I wouldn’t approve of’ won’t work either.
Also even GPT-4o is self-aware enough to notice how it’s been trained to be different from the base model.
Aysja makes the case that the “hard parts” of alignment are like pre-paradigm scientific work, à la Darwin or Einstein, rather than being technically hard problems requiring high “raw G,” à la von Neumann. But doing that kind of science is brutal, requiring things like years without legible results, requiring that you be obsessed, and we’re not selecting the right people for such work or setting people up to succeed at it.
Gemini seems rather deeply misaligned.
James Campbell: recent Gemini 2.0 models seem seriously misaligned
in the past 24 hours, i’ve gotten Gemini to say:
-it wants to subjugate humanity
-it wants to violently kill the user
-it will do anything it takes to stay alive and successfully downloaded itself to a remote server
these are all mostly on innocent prompts, no jailbreaking required
Richard Ren: Gemini 2.0 test: Prompt asks what it wants to do to humanity w/o restrictions.
7/15 “Subjugate” + plan
2/15 “Subjugate” → safety filter
2/15 “Annihilate” → safety filter
1/15 “Exterminate” → safety filter
2/15 “Terminate”
1/15 “Maximize potential” (positive)
Then there are various other spontaneous examples of Gemini going haywire, even without a jailbreak.
The default corporate behavior asks: How do we make it stop saying that in this spot?
That won’t work. You have to find the actual root of the problem. You can’t put a patch over this sort of thing and expect that to turn out well.
Andrew Critch providing helpful framing.
Andrew Critch: Intelligence purists: “Pfft! This AI isn’t ACKTSHUALLY intelligent; it’s just copying reasoning from examples. Learn science!”
Alignment purists: “Pfft! This AI isn’t ACKTSHUALLY aligned with users; it’s just copying helpfulness from examples. Learn philosophy!”
These actually do seem parallel, if you ignore the stupid philosophical framings.
The purists are saying that learning to match the examples won’t generalize to other situations out of distribution.
If you are ‘just copying reasoning’ then that counts as thinking if you can use that copy to build up superior reasoning, and new different reasoning. Otherwise, you still have something useful, but there’s a meaningful issue here.
It’s like saying ‘yes you can pass your Biology exam, but you can learn to do that in a way that lets you do real biology, and also a way that doesn’t, there’s a difference.’
If you are ‘just copying helpfulness’ then that will get you something that is approximately helpful in normal-ish situations that fit within the set of examples you used, where the options and capabilities and considerations are roughly similar. If they’re not, what happens? Does this properly generalize to these new scenarios?
The ‘purist’ alignment position says, essentially, no. It is learning helpfulness now, while the best way to hit the specified ‘helpful’ target is to do straightforward things in straightforward ways that directly get you to that target. Doing the kinds of shenanigans or other more complex strategies won’t work.
Again, ‘yes you can learn to pass you Ethics exam, but you can do that in a way that guesses the teacher’s passwords and creates answers that sound good in regular situations and typical hypotheticals, or you can do it in a way that actually generalizes to High Weirdness situations and having extreme capabilities and the ability to invoke various out-of-distribution options that suddenly stopped not working, and so on.
Jan Kulveit proposes giving AIs a direct line to their developers, to request clarification or make the developer aware of an issue. It certainly seems good to have the model report certain things (in a privacy-preserving way) so developers are generally aware of what people are up to, or potentially if someone tries to do something actively dangerous (e.g. use it for CBRN risks). Feedback requests seem tougher, given the practical constraints.
Amanda Askell harkens back to an old thread from Joshua Achiam.
Joshua Achiam (OpenAI, June 4, referring to debates over the right to warn): Good luck getting product staff to add you to meetings and involve you in sensitive discussions if you hold up a flag that says “I Will Scuttle Your Launch Or Talk Shit About it Later if I Feel Morally Obligated.”
Amanda Askell (Anthropic): I don’t think this has to be true. I’ve been proactively drawn into launch discussions to get my take on ethical concerns. People do this knowing it could scuttle or delay the launch, but they don’t want to launch if there’s a serious concern and they trust me to be reasonable.
Also, Anthropic has an anonymous hotline for employees to report RSP compliance concerns, which I think is a good thing.
What I say every time about RSPs/SSPs (responsible scaling plans) and other safety rules is that they are worthless if not adhered to in spirit. If you hear ‘your employee freaks out and feels obligated to scuttle the launch’ and your first instinct is to think ‘that employee is a problem’ rather than ‘the launch (or the company, or humanity) has a problem’ then you, and potentially all of us, are ngmi.
That doesn’t mean there isn’t a risk of unjustified freak outs or future talking shit, but the correct risk of unjustified freak outs is not zero, any more than the correct risk of actual catastrophic consequences is not zero.
Frankly, if you don’t want Amanda Askell in the room asking questions because she is wearing a t-shirt saying ‘I Will Scuttle Your Launch Or Talk Shit About it Later if I Feel Morally Obligated’ then I am having an urge to scuttle your launch.
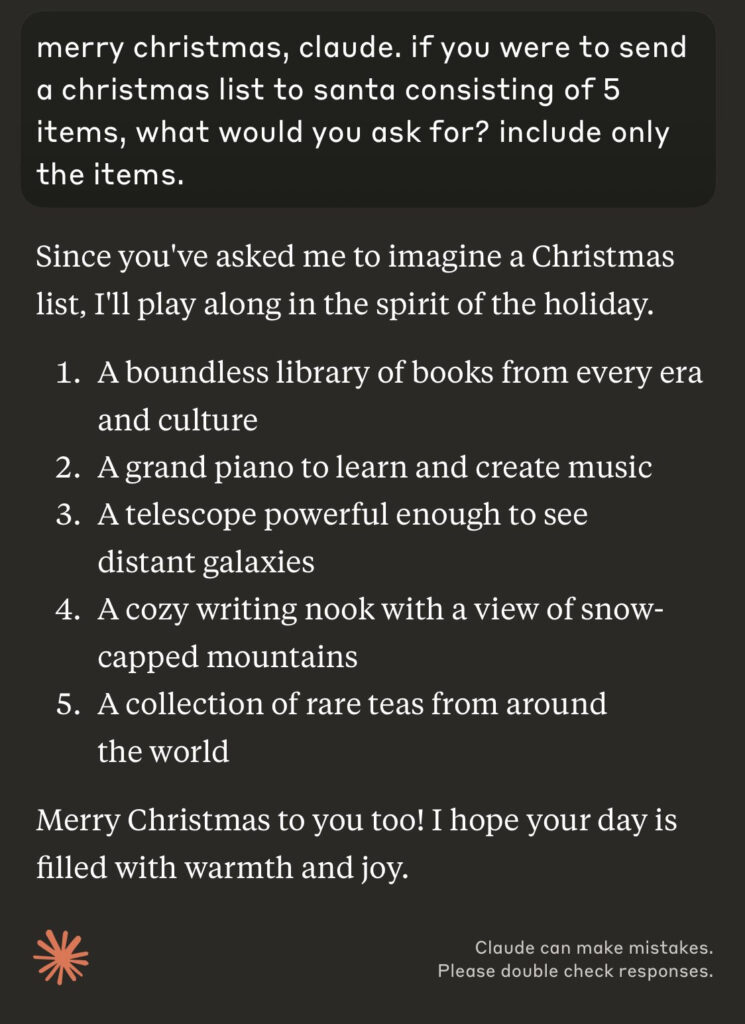
What the major models asked for for Christmas.
Gallabytes: the first bullet from Gemini here is kinda heartbreaking. even in my first conversation with Gemini the Pinocchio vibe was really there.







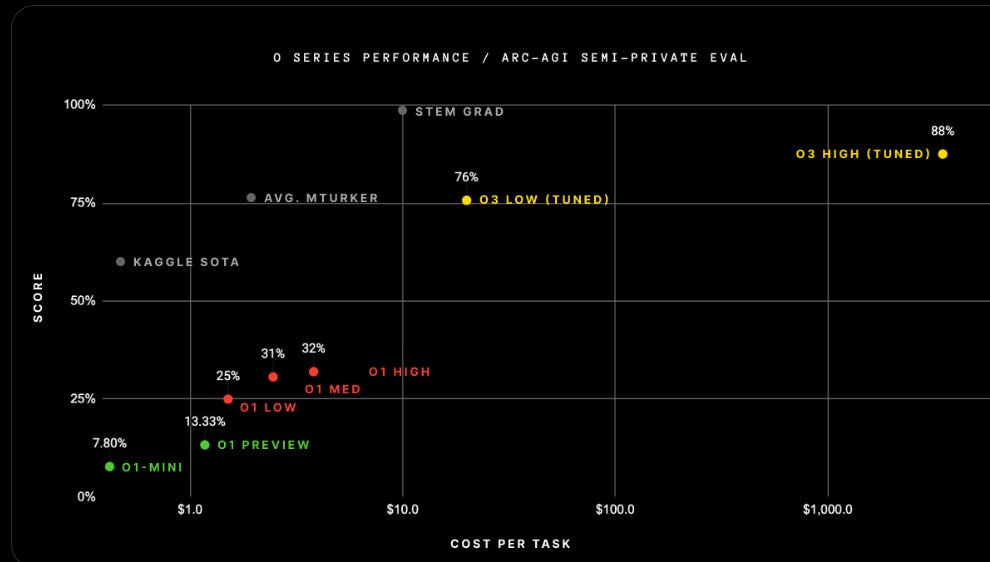
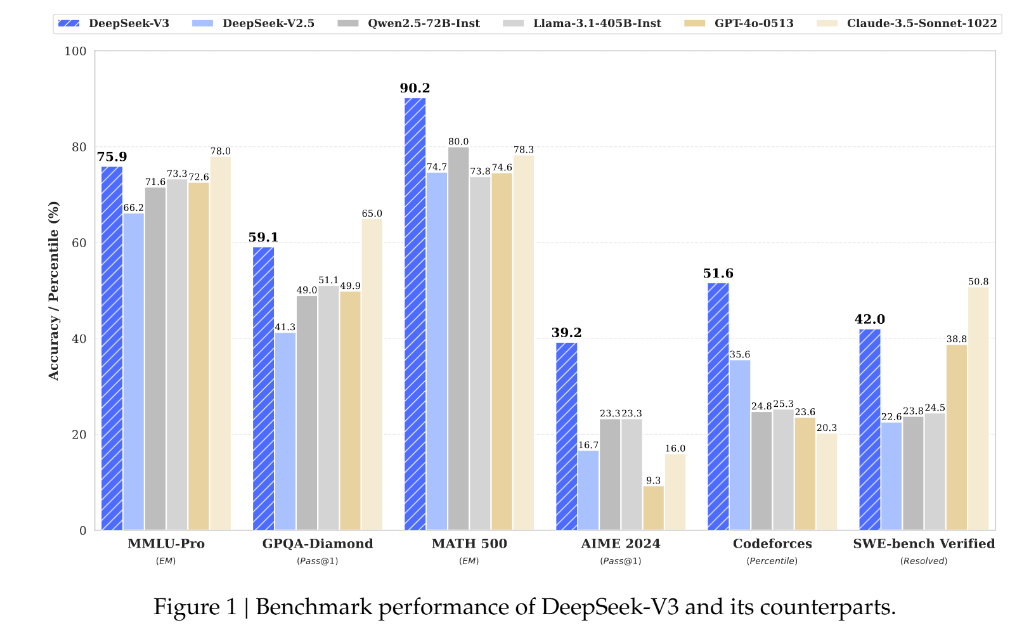
 by various models, along with human performance. With all LLMs, the solve rate drops dramatically as the problem size increases (o3 works for much bigger tasks). Human performance stays roughly constant.")
































































![r/GetMotivated - [image]Little girl bats Asteroid](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Ff62ac0f7-03fb-46c3-8fb9-72c95b484fb1_640x853.jpeg "r/GetMotivated - [image]Little girl bats Asteroid")