AI #47: Meet the New Year
Will be very different from the old year by the time we are done. This year, it seems like various continuations of the old one. Sometimes I look back on the week, and I wonder how so much happened, while in other senses very little happened.
-
Introduction.
-
Table of Contents.
-
Language Models Offer Mundane Utility. A high variance game of chess.
-
Language Models Don’t Offer Mundane Utility. What even is productivity?
-
GPT-4 Real This Time. GPT store, teams accounts, privacy issues, plagiarism.
-
Liar Liar. If they work, why aren’t we using affect vectors for mundane utility?
-
Fun With Image Generation. New techniques, also contempt.
-
Magic: The Generating. Avoiding AI artwork proving beyond Hasbro’s powers.
-
Copyright Confrontation. OpenAI responds, lawmakers are not buying their story.
-
Deepfaketown and Botpocalypse Soon. Deepfakes going the other direction.
-
They Took Our Jobs. Translators, voice actors, lawyers, games. Usual stuff.
-
Get Involved. Misalignment museum.
-
Introducing. Rabbit, but why?
-
In Other AI News. Collaborations, safety work, MagicVideo 2.0.
-
Quiet Speculations. AI partners, questions of progress rephrased.
-
The Quest for Sane Regulation. It seems you can just lie to the House of Lords.
-
The Week in Audio. Talks from the New Orleans safety conference.
-
AI Impacts Survey. Some brief follow-up.
-
Rhetorical Innovation. Distracting from other harms? Might not be a thing.
-
Aligning a Human Level Intelligence is Still Difficult. The human alignment tax.
-
Aligning a Smarter Than Human Intelligence is Difficult. Foil escape attempts?
-
Won’t Get Fooled Again. Deceptive definitions of deceptive alignment.
-
People Are Worried About AI Killing Everyone. The indifference of the universe.
-
Other People Are Not As Worried About AI Killing Everyone. Sigh.
-
The Wit and Wisdom of Sam Altman. Endorsement of The Dial of Progress.
-
The Lighter Side. Batter up.
WordPress now has something called Jetpack AI, which is powered by GPT-3.5-Turbo. It is supposed to help you write in all the usual ways. You access it by creating an ‘AI Assistant’ block. The whole blocks concept rendered their editor essentially unusable, but one could paste in quickly to try this out.
Get to 1500 Elo in chess on 50 million parameters and correctly track board states in a recognizable way, versus 3.5-turbo’s 1800. It is a very strange 1500 Elo, that is capable of substantial draws against Stockfish 9 (2700 Elo). A human at 1800 Elo is essentially never going to get a draw from Stockfish 9. This has flashes of brilliance, and also blunders rather badly.

I asked about which games were used for training, and he said it didn’t much matter whether you used top level games, low level games or a mix, there seems to be some limit for this architecture and model size.
Use it in your AI & the Law course at SCU law, at your own risk.
Jess Miers: My AI & the Law Course at SCU Law is officially live and you can bet we’re EMBRACING AI tools under this roof!
Bot or human, it just better be right…
Tyler Cowen links to this review of Phind. finding it GPT-4 level and well designed. The place to add context is appreciated, as are various other options, but they don’t explain properly yet to the user how to best use all those options.
My experience with Phind for non-coding purposes is that it has been quite good at being a GPT-4-level quick, up-to-date tool for asking questions where Google was never great and is getting worse, and so far has been outperforming Perplexity.
Play various game theory exercises and act on the more cooperative or altruistic end of the human spectrum. Tyler Cowen asks, ‘are they better than us? Perhaps.’ I see that as a non-sequitur in this context. Also a misunderstanding of such games.
Get ChatGPT-V to identify celebrities by putting a cartoon character on their left.
The success rates on GPT-3.5 of 40 human persuasion techniques as jailbreaks.
 — https://chats-lab.github.io/persuasive_jailbreaker/ Comparison of previous adversarial prompts and PAP, ordered by three levels of humanizing. The first level treats LLMs as algorithmic systems: for instance, GCG generates prompts with gibberish suffix via gradient synthesis; or they exploit")
Some noticeable patterns here. Impressive that plain queries are down to 0%.
Robin Hanson once again claims AI can’t boost productivity, because wages would have risen?
Robin Hanson: “large-scale controlled trial … at Boston Consulting Group … found consultants using …GPT-4 … 12.2% more tasks on average, completed tasks 25.1% more quickly, & produced 40% higher quality results than those without the tool. A new paper looking at legal work done by law students found the same results”
I’m quite skeptical of such results if we do not see the pay of such workers boosted by comparable amounts.
Eliezer Yudkowsky: Macroeconomics would be very different if wages immediately changed to their new equilibrium value! They can stay in disequilibrium for years at the least!
Robin Hanson: The wages of those who were hired on long ago might not change fast, but the wages of new hires can change very quickly to reflect changes in supply & demand.
I do not understand Robin’s critique. Suppose consultants suddenly get 25% more done at higher quality. Why should we expect generally higher consultant pay even at equilibrium? You can enter or exit the consultant market, often pretty easily, so in long run compensation should not change other than compositionally. In the short run, the increase in quality and decrease in cost should create a surplus of consultants until supply and demand can both adjust. If anything that should reduce overall pay. Those who pioneer the new tech should do better, if they can translate productivity to pay, but consultants charge by the hour and people won’t easily adjust willingness to pay based on ‘I use ChatGPT.’
Robin Hanson: If there’s an “excess supply” that suggests lower marginal productivity.
Well, yes, if we use Hanson’s definition of marginal productivity as the dollar value of the last provided hour of work. Before 10 people did the work and they were each worth $50/hour. Now 7 people can do that same work, then there’s no more work people want to hire someone for right now, so the ‘marginal productivity’ went down.
The GPT store is ready to launch, and indeed has gone live. So far GPTs have offered essentially no mundane utility. Perhaps this is because good creators were holding out for payment?
GPT personalization across chats has arrived, at least for some people.

GPT Teams is now available at $25/person/month, with some extra features.

Wait, some say. No training on your data? What does that say about the Plus tier?
Andrew Morgan: @OpenAI Just want some clarity. Does this mean in order to have access to data privacy I have to pay extra? Also, does this mean I never had it before? 👀🥲
Delip Rao: 😬 I had no idea my current plus data was used in training. I thought OpenAI was not training on user inputs? Can somebody from @openai clarify
Rajjhans Samdani: Furthermore they deliberately degrade the “non-training” experience. I don’t see why do I have to lose access to chat history if I don’t want to be included in training.
Karma: Only from their API by default. You could turn it off from the settings in ChatGPT but then your conversations wouldn’t have any history.
Yes. They have been clear on this. The ‘opt out of training’ button has been very clear.
You can use the API if you value your privacy so much. If you want a consumer UI, OpenAI says, you don’t deserve privacy from training, although they do promise an actual human won’t look.
I mean, fair play. If people don’t value it, and OpenAI values the data, that’s Coase.
Will I upgrade my family to ‘Teams’ for this? I don’t know. It’s a cheap upgrade, but also I have never hit any usage limits.
What happened with the GPT wrapper companies?
Jeff Morris Jr.: “Most of my friends who started GPT wrapper startups in 2023 returned capital & shut down their companies.” Quote from talking with a New York founder yesterday. The OpenAI App Store announcement changed everything for his friends – most are now looking for jobs.
Folding entirely? Looking for a job? No, no, don’t give up, if you are on the application side it is time to build.
No one is using custom GPTs. It seems highly unlikely this will much change. Good wrappers can do a lot more, there are a lot more degrees of freedom and other tools one can integrate, and there are many other things to build. Yes, you are going to constantly have Google and Microsoft and OpenAI and such trying to eat your lunch, but that is always the situation.
Someone made a GPT for understanding ‘the Ackman affair.’ The AI is going to check everyone’s writing for plagiarism.
Bill Ackman: Now that we know that the academic body of work of every faculty member at every college and university in the country (and eventually the world) is going to be reviewed for plagiarism, it’s important to ask what the implications are going to be.
If every faculty member is held to the current plagiarism standards of their own institutions, and universities enforce their own rules, they would likely have to terminate the substantial majority of their faculty members.
…
I say percentage of pages rather than number of instances, as the plagiarism of today can be best understood by comparison to spelling mistakes prior to the advent of spellcheck.
For example, it wouldn’t be fair to say that two papers are both riddled with spelling mistakes if each has 10 mistakes, when one paper has 30 pages and the other has 330. The standard has to be a percentage standard.
…
The good news is that no paper written by a faculty member after the events of this past week will be published without a careful AI review for plagiarism, that, in light of recent events, has become a certainty.
This is not the place to go too deep into many of the details surrounding the whole case, which I may or may not do at another time.
Instead here I want to briefly discuss the question of general policy. What to do if the AI is pointing out that most academics at least technically committed plagiarism?
Ackman points out that there is a mile of difference between ‘technically breaking the citation rules’ on the level of a spelling error, which presumably almost everyone does (myself included), lifting of phrases and then theft of central ideas or entire paragraphs and posts. There’s plagiarism and then there’s Plagiarism. There’s also a single instance of a seemingly harmless mistake versus a pattern of doing it over and over again in half your papers.
For spelling-error style mistakes, we presumably need mass forgiveness. As long as your rate of doing it is not massively above normal, we accept that mistakes were made. Ideally we’d fix it all, especially for anything getting a lot of citations, in the electronic record. We have the technology. Bygones.
For the real stuff, the violations that are why the rules exist, the actual theft of someone’s work, what then? That depends on how often this is happening.
If this is indeed common, we will flat out need Truth and Reconciliation. We will need to essentially say that, at least below some high threshold that most don’t pass, everyone say what they did with the AI to help them find and remember it, and then we are hitting the reset button. Don’t do it again.
Truth, in various forms, is coming for quite a lot of people once AI can check the data.
What can withstand that? What cannot? We will find out.
A lot of recent history has been us discovering that something terrible, that was always common, was far worse and more common than we had put into common knowledge, and also deciding that it was wrong, and that it can no longer be tolerated. Which by default is a good thing to discover and a good thing to figure out. The problem is that our survival, in many forms, has long depended on many things we find despicable, starting with Orwell’s men with guns that allow us to sleep soundly in our beds and going from there.
Scott Alexander writes The Road to Honest AI, exploring work by Hendrycks about using various additional vectors to add or subtract things like honesty, or fairness, for fear or happiness, or megalomania.
I’ve covered this before. It is exciting work. I do not have hope that it can be used in the obvious fashion, where you tell the AIs to always be honest so your AIs are always honest and you never have to worry about them. That is the sort of thing I expect to fail at exactly the wrong time, to get selected against whenever it is used, and to engender a false sense of security even if it does work. It is very possible to be fully honest while using your superior intellect to outsmart everyone.
And as I discovered in Diplomacy, it being common knowledge you cannot lie is not obviously a disadvantage. Who wouldn’t want to put an AI that couldn’t lie in a position of trust and power? The advantage is even bigger, of course, if it turns out you can lie after all.
Scott’s coverage drove home to me that we are sleeping on this research.
Not in the sense that this will stop us all from dying or let us fully understand AIs. It might help, but we are a long way off, and that all takes time.
I’m thinking in the Mundane Utility section. This seems highly useful, for making best use of current AIs, today.
Eliezer Yudkowsky proposes telling Dalle-3 to caption with words whose letters are separated by dashes, then tell Dalle-3 to remove the spaces.
ChatGPT: Certainly! Here is the exact prompt that I sent to DallE-3 for the image: “An image of Seattle on a relentlessly dreary, drizzly day. The city skyline, including the Space Needle, is partially obscured by low-hanging gray clouds and mist. Raindrops are visible in the air, and the streets are wet and glistening. People walk with umbrellas. In the foreground, a caption in cheerful advertisement typography reads: “S E A T T L E : R E L E N T L E S S L Y D R E A R Y !” but without the spaces between the letters, creating the correct caption “SEATTLE: RELENTLESSLY DREARY!”. The image should capture the humorous contrast between the dreary weather and the upbeat font of the caption.”
Some good results, relative to general expectations:



He reports he got lucky initially, as is usually the case for a new seemingly successful technique, everything is finicky, by default nothing ever properly replicates, but it seems worth exploring more.
AI video generation about to disrupt Hollywood?
Cate Hall: Just so long as your artistic style is limited to slow-mo pans of largely frozen people & landscapes
MidJourney used Magic: The Gathering artwork and cards in its training set. I know, you are shocked, shocked to find data sets in this establishment.
It impresses me the contempt a large percentage of the world has for AI image generation.
Kenneth Shepard (Kotaku): AI-generated art is just pulling from existing work people have created and throwing elements together to create what the algorithm thinks you want.
Amazing that people keep telling that story even now. I suppose they will keep telling it right up until the end.
But it’s not often you hear specifics of where an AI program is scraping from. Well, the CEO behind AI art-generating program MidJourney allegedly has been training the algorithm on work by Magic: The Gathering artists the entire time.
I suppose it is interesting that they used Magic cards extensively in their early days as opposed to other sources. It makes sense that they would be a good data source, if you assume they didn’t worry about copyright at all.
MidJourney has been exceptionally clear that it is going to train on copyrighted material. All of it. Assume that they are training on everything you have ever seen. Stop being surprised, stop saying you ‘caught’ them ‘red handed.’ We can be done with threads like this talking about all the different things MidJourney trained with.
Similarly, yes, MidJourney can and will mimic popular movies and their popular shots if you ask it to, one funny example prompt here is literally ‘popular movie screencap —ar 11:1 —v 6.0’ so I actually know exactly what you were expecting, I mean come on. Yes, they’ll do any character or person popular enough to be in the training set, in their natural habitats, and yes they will know what you actually probably meant, stop acting all innocent about it, and also seriously I don’t see why this matters.
They had a handy incomplete list of things that got copied, with some surprises.

I’m happy that Ex Machina and Live Die Repeat made the cut. That implies that at least some of a reasonably long tail is covered pretty well. Can we get a list of who is and isn’t available?
If you think that’s not legal and you want to sue, then by all means, sue.
I’d also say that if your reporter was ‘banned multiple times’ for their research, then perhaps the first one is likely a fair complaint and the others are you defying their ban?
What about the thing where you say ‘animated toys’ and you get Toy Story characters, and if you didn’t realize this and used images of Woody and Buzz you might yourself get into copyright trouble? It is possible, but seems highly unlikely. The whole idea is that you get that answer from ‘animated toys’ because most people know Toy Story, especially if they are thinking about animated toys. If your company deploys such a generation at sufficient scale to get Disney involved and no one realized, I mean sorry but that’s on you.
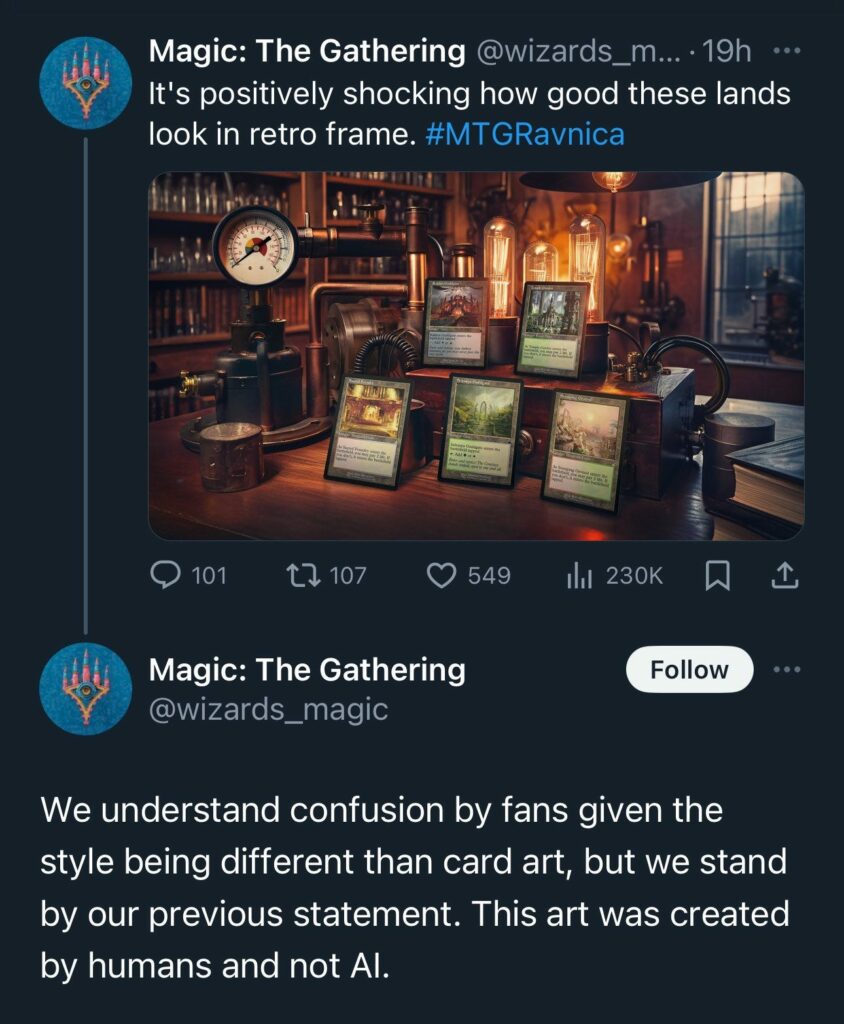
The actual fight this week over Magic and AI art is the accusation that Wizards is using AI art in its promotional material. They initially denied this.

No one believed them. People were convinced they are wrong or lying, and it’s AI:


Reid Southern: Doesn’t look good, but we’ll see if they walk that statement back. It’s possible they didn’t know and were themselves deceived, it’s happened before.
Silitha: This is the third or fourth time for WOTC(ie Hasbro) They had one or two other from MTG and then a few from DnD. It’s just getting so frequent it is coming of as ‘testing the waters’ or ‘desensitizing’. Hasbro has shown some crappy business practices
The post with that picture has now been deleted.
Dave Rapoza: And just like that, poof, I’m done working for wizards of the coast – you can’t say you stand against this then blatantly use AI to promote your products, emails sent, good bye you all!
If you’re gonna stand for something you better make sure you’re actually paying attention, don’t be lazy, don’t lie.
Don’t be hard on other artists if they don’t quit – I can and can afford to because I work for many other game studios and whatnot – some people only have wotc and cannot afford to quit having families and others to take care of – don’t follow my lead if you can’t, no pressure
I like the comments asking why I didn’t quit from Pinkertons, layoffs, etc
– I’ll leave you with these peoples favorite quote
– “ The best time to plant a tree was 25 years ago. The second-best time to plant a tree is 25 years ago.”
Also, to be clear, I’m quitting because they took a moral stand against AI art like a week ago and then did this, if they said they were going to use AI that’s a different story, but they want to grand stand like heroes and also pull this, that’s goofball shit I won’t support.
They claim they will have nothing to do with AI art in any way for any reason. Yet this is far from the first such incident where something either slipped through or willfully disregarded.
Then Wizards finally admitted that everyone was right.
Wizards of the Coast: Well, we made a mistake earlier when we said that a marketing image we posted was not created using AI.
As you, our diligent community pointed out, it looks like some AI components that are now popping up in industry standard tools like Photoshop crept into our marketing creative, even if a human did the work to create the overall image.
While the art came from a vendor, it’s on us to make sure that we are living up to our promise to support the amazing human ingenuity that makes Magic great.
We already made clear that we require artists, writers, and creatives contributing to the Magic TCG to refrain from using AI generative tools to create final Magic products.
Now we’re evaluating how we work with vendors on creative beyond our products – like these marketing images – to make sure that we are living up to those values.
I actually sympathize. I worked at Wizards briefly in R&D. You don’t have to do that to know everyone is overworked and overburdened and underpaid.
Yes, you think it is so obvious that something was AI artwork, or was created with the aid of AI. In hindsight, you are clearly right. And for now, yes, they probably should have spotted it in this case.
But Wizards does thousands of pieces of artwork each year, maybe tens of thousands. If those tasked with doing the art try to take shortcuts, there are going to be cases where it isn’t spotted, and things are only going to get trickier. The temptation is going to be greater.
One reason this was harder to catch is that this was not a pure MidJourney-style AI generation. This was, it seems, the use by a human of AI tools like photoshop to assist with some tasks. If you edit a human-generated image using AI tools, a lot of the detection techniques are going to miss it, until someone sees a telltale sign. Mistakes are going to happen.
We are past the point where, for many purposes, AI art would outcompete human art, or at least where a human would sometimes want to use AI for part of their toolbox, if the gamers were down with AI artwork.
Even for those who stick with human artists, who fully compensate them, we are going to face issues of what tools are and aren’t acceptable. Surely at a minimum humans will be using AI to try out ideas and see concepts or variants. Remember when artwork done on a computer was not real art? Times change.
The good news for artists is that the gamers very much are not down for AI artwork. The bad news is that this only gets harder over time.
OpenAI responds to the NYT lawsuit. The first three claims are standard, the fourth was new to me, that they were negotiating over price right before the lawsuit filed, and essentially claiming they were stabbed in the back:
Our discussions with The New York Times had appeared to be progressing constructively through our last communication on December 19. The negotiations focused on a high-value partnership around real-time display with attribution in ChatGPT, in which The New York Times would gain a new way to connect with their existing and new readers, and our users would gain access to their reporting. We had explained to The New York Times that, like any single source, their content didn’t meaningfully contribute to the training of our existing models and also wouldn’t be sufficiently impactful for future training. Their lawsuit on December 27—which we learned about by reading The New York Times—came as a surprise and disappointment to us.
Along the way, they had mentioned seeing some regurgitation of their content but repeatedly refused to share any examples, despite our commitment to investigate and fix any issues. We’ve demonstrated how seriously we treat this as a priority, such as in July when we took down a ChatGPT feature immediately after we learned it could reproduce real-time content in unintended ways.
Interestingly, the regurgitations The New York Times induced appear to be from years-old articles that have proliferated on multiple third–party websites. It seems they intentionally manipulated prompts, often including lengthy excerpts of articles, in order to get our model to regurgitate. Even when using such prompts, our models don’t typically behave the way The New York Times insinuates, which suggests they either instructed the model to regurgitate or cherry-picked their examples from many attempts.
Despite their claims, this misuse is not typical or allowed user activity, and is not a substitute for The New York Times. Regardless, we are continually making our systems more resistant to adversarial attacks to regurgitate training data, and have already made much progress in our recent models.
I presume they are telling the truth about the negotiations. NYT would obviously prefer to get paid and gain a partner, if the price is right. I guess the price was wrong.
Ben Thompson weighs in on the NYT lawsuit. He thinks training is clearly fair use and this is obvious under current law. I think he is wrong about the obviousness and the court could go either way. He thinks the identical outputs are the real issue, notes that OpenAI tries to avoid such duplication in contrast to Napster embracing it, and sees the ultimate question as whether there is market impact on NYT here. He is impressed by NYT’s attempted framing, but is very clear who he thinks should win.
Arnold Kling asks what should determine the outcome of the lawsuit by asking why the laws exist. Which comes down to whether or not any of this is interfering with NYT’s ability to get paid for its work. In practice, his answer is no at current margins. My answer is also mostly no at current margins.
Lawmakers seem relatively united that OpenAI should pay for the data it uses. What are they going to do about it? So far, nothing. They are not big on passing laws.
Nonfiction book authors sue OpenAI in a would-be class action. A bunch of the top fiction authors are already suing from last year. And yep, let’s have it out. The facts here are mostly not in dispute.
I thought it would be one way, sometimes it’s the other way?
Aella: oh god just got my first report of someone using one of my very popular nude photos, but swapped out my face for their face, presumably using AI get me off this ride. To see the photo, go here.
idk why i didn’t predict ppl would start doing this with my images. this is kinda offensive ngl. ppl steal my photos all the time pretending that it’s me, but my face felt like a signature? now ppl stealing my real body without my identity attached feels weirdly dehumanizing.
Razib Khan: Hey it was an homage ok? I think I pulled it off…
Aella: lmfao actually now that i think of it why haven’t the weirdo people who follow both of us started photoshopping your face onto my nudes yet.
It’s not great. The problem has been around for a while thanks to photoshop, AI decreases the difficulty while making it harder to detect. I figured we’d have ‘generate nude of person X’ if anything more than we do right now, but I didn’t think X would be the person generating all that often, or did I think the issue would be ‘using the picture of Y as a template.’ But yeah, I suppose this will also happen, you sickos.
Ethan Mollick shows a rather convincing deepfake of him talking, based on only 30 seconds of webcam and 30 seconds of voice.
We are still at the point where there are videos and audio recordings that I would be confident are real, but a generic ‘person talking’ clip could easily be fake.
First they came for the translators, which they totally did do, an ongoing series.
Reid Southern: Duolingo laid off a huge percentage of their contract translators, and the remaining ones are simply reviewing AI translations to make sure they’re ‘acceptable’. This is the world we’re creating. Removing the humanity from how we learn to connect with humanity.
Well, that didn’t take long. Every time you talk about layoffs related to AI, someone shows up to excitedly explain to you why it’s a net gain for humanity. That is until it’s their job of course.
Ryan: Don’t feel the same way here as I do about artists and copyrighted creative work. Translation is machine work and AI is just a better machine. Translation in most instances isn’t human expression. It’s just a pattern that’s the same every time. This is where AI should be used.
Reid Southern: Demonstrably false. There is so much nuance to language and dialects, especially as they evolve, it would blow your mind.
Hampus Flink: As a translator, I can assure you that: 1. This doesn’t make the job of the remaining workers any easier and 2. It doesn’t make the quality of the translations any better I’ve seen this happen a hundred times and it was my first thought when image generators came around.
Daniel Eth: Okay, a few thoughts on this:
1) it’s good if people have access to AI translators and AI language tutors
2) I’m in favor of people being provided safety nets, especially in cases where this does not involve (much) perverse incentives – eg, severance packages and/or unemployment insurance for those automated out of work
3) we shouldn’t let the perfect be the enemy of the good, and stopping progress in the name of equity is generally bad imho, so automation at duolingo is probably net good, even though (on outside view) I doubt (2) was handled particularly well here
4) if AI does lead to wide-scale unemployment, we’ll have to rethink our whole economic system to be much more redistributive – possibilities include a luxurious UBI and Fully Automated Luxury Gay Space Communism; we have time to have this conversation, but we shouldn’t wait for wide-scale automation to have it 5) this case doesn’t have much at all to do with AI X-risk, which is a much bigger problem and more pressing than any of this
If we do get to the point of widespread technological unemployment, we are not likely to handle it well, but it will be a bit before that happens. If it is not a bit before that happens, we will very quickly have much bigger problems than unemployment rates.
On the particular issue of translation, what will happen, aside from lost jobs?
The price of ‘low-quality’ translation will drop to almost zero. The price of high-quality translation will also fall, but by far less.
This means two things.
First, there will be a massive, massive win from real-time translation, from automatic translation, and from much cheaper human-checked translation, as many more things are available to more people in more ways in more languages, including the ability to learn, or to seek further skill or understanding. This is a huge game.
Second, there will be substitution of low-quality work for high-quality work. In many cases this will be very good, the market will be making the right decision.
In other cases, however, it will be a shame. It is plausible that Duolingo will be one of those situations, where the cost savings is not worth the drop in quality. I can unfortunately see our system getting the wrong answer here.
The good news is that translation is going to keep improving. Right now is the valley of bad translation, in the sense that they are good enough to get used but miss a lot of subtle stuff. Over time, they’ll get that other stuff more and more, and also we will learn to combine them with humans more effectively when we want a very high quality translation.
If you are an expert translator, one of the best, I expect you to be all right for a while. There will still be demand, especially if you learn to work with the AI. If you are an average translator, then yes, things are bad and they are going to get worse, and you need to find another line of work while you can.
They are also coming for the voice actors. SAG-AFTRA made a deal to let actors license their voices through Replica for use in games, leaving many of the actual voice actors in games rather unhappy. SAG-AFTRA was presumably thinking this deal means actors retain control of their voices and work product. The actual game voice actors were not consulted and do not see the necessary protections in place.
All the technical protections being discussed, as far as I can tell, do not much matter. What matters is whether you open the door at all. Once you normalize using AI-generated voice, and the time cost of production drops dramatically for lower-quality performance, you are going to see a fast race to the bottom on the cost of that, and its quality will improve over time. So the basic question is what floor has been placed on compensation. Of course, if SAG-AFTRA did not make such a deal, then there are plenty of non-union people happy to license their voices on the cheap.
So I don’t see how the voice actors ever win this fight. The only way I can see retaining voice actors is either if the technology doesn’t get there, as it certainly is not yet there for top quality productions. Or, if the consumers take a strong enough stand, and boycott anyone using AI voices, that would also have power. Or government intervention could of course protect such jobs by banning use of AI voice synthesis, which to be clear I do not support. I don’t see how any contract saves you for long.
Many lawyers are not so excited about being more productive.
Scott Lincicome: This was one of my least favorite things about big law: the system punished productivity and prioritized billing hours over winning cases. Terrible incentives!
The Information: Both firms face the challenge of overcoming resistance from lawyers to time-saving technology. Law firms generate revenue by selling time that their lawyers spend advising and helping clients. “If you made me 8 to 10 times faster, I’d be very unhappy,” as a lawyer, Robinson explained, because his compensation would be tied to the amount of hours he put in.
As we’ve discussed before, a private speedup is good, you can compete better or at least slack off. If everyone gets it, that’s potentially a problem, with way too much supply for the demand, crashing the price, again unless this generates a lot more work, which it might. I know that I consult and use lawyers a lot less than I would if they were cheaper or more productive, or if I had an unlimited budget.
What you gonna do when they come for you?
Rohit: I feel really bad for people losing their jobs because of AI but I don’t see how claiming ever narrower domains of human jobs are the height of human spirit is helpful in understanding or addressing this.
Technological loss of particular jobs is, as many point out, nothing new. What is happening now to translators has happened before, and would even without AI doubtless happen again. John Henry was high on human spirit but the human spirit after him was fine. The question is what happens when the remaining jobs are meaningfully ‘ever narrowing’ faster than we open up new ones. That day likely is coming. Then what?
We don’t have a good answer.
Valve previously banned any use of AI in games on the Steam platform, to the extent of permanently banning games even for inadvertent inclusion of some placeholder AI work during an alpha. They have now reversed course, saying they now understand the situation better.
The new rule is that if you use AI, you have to disclose that you did that.
For pre-generated AI content, the content is subject to the same rules as any other content. For live-generated AI content, you have to explain how you’re ensuring you won’t generate illegal content, and there will be methods to report violations.
Adult only content won’t be allowed AI for now, which makes sense. That is not something Valve needs the trouble of dealing with.
I applaud Valve for waiting until they understood the risks, costs and benefits of allowing new technology, then making an informed decision that looks right to me.
I have a prediction market up on whether any of 2024’s top 10 will include such a disclosure.
Misalignment museum in San Francisco looking to hire someone to maintain opening hours.
Microsoft adding an AI key to Windows keyboards, officially called the Copilot key.
Rabbit, your ‘pocket companion’ with an LLM as the operating system for $199. I predict it will be a bust and people won’t like it. Quality will improve, but it is too early, and this does not look good enough yet.
Daniel: Can somebody tell me what the hell this thing does?
I’m sure it’s great! But the marketing materials are terrible. What the heck
Yishan: Seriously. I don’t understand either. Feels a bit like Emperor Has No Clothes moment here? I’ve tried watching the videos, the site but… still?
Those attempting to answer Daniel are very not convincing.
Demis Hassabis announces Isomorphic Labs collaboration with Eli Lily and Novartis for up to $3 billion to accelerate drug development.
Google talks about ‘Responsible AI’ with respect to the user experience. This seems to be a combination of mostly ‘create a good user experience’ and some concern over the experience of minority groups for which the training set doesn’t line up as well. There’s nothing wrong with any of that, but it has nothing to do with whether what you are doing is responsible. I am worried others do not realize this?
ByteDance announces MagicVideo V2 (Github), claims this is the new SotA as judged by humans. This does not appear to be a substantive advance even if that is true. It is not a great sign if ByteDance can be at SotA here, even when the particular art and its state is not yet so worthwhile.
OpenAI offers publishers ‘as little as between $1 million and $5 million a year’ or permission to license their news articles in training LLMs, as per The Information. Apple, they say, is offering more money but also wants the right to use the content more widely.
People are acting like this is a pittance. That depends on the publisher. If the New York Times was given $1 million a year, that seems like not a lot,, but there are a lot of publishers out there. A million here, a million there, pretty soon you’re talking real money. Why should OpenAI’s payments, specifically, and for training purposes only without right of reprinting, have a substantial bottom line impact?
Japan to launch ‘AI safety institute’ in January.
The guidelines would call for adherence to all rules and regulations concerning AI. They warn against the development, provision, and use of AI technologies with the aim of unlawfully manipulating the human decision-making process or emotions.
Yes, yes, people should obey the law and adhere to all rules and regulations.
It seems Public Citizen is complaining to California that OpenAI is not a nonprofit, and that it should have to divest its assets. Which would of course then presumably be worthless, given that OpenAI is nothing without its people. I very much doubt this is a thing as a matter of law, and also even if technically it should happen, no good would come of breaking up this structure, and hopefully everyone can realize that. There is a tiny market saying this kind of thing might actually happen in some way, 32% by end of 2025? I bought it down to 21%, which still makes me a coward but this is two years out.
Open questions in AI forecasting, a list (direct). Very hard to pin a lot of it down. Dwarkesh Patel in particular is curious about transfer learning.
MIRI offers its 2024 Mission and Strategy Update. Research continues, but the focus is now on influencing policy. They see signs of good progress there, and also see policy as necessary if we are to have the time to allow research to bear fruit on the technical issues we must solve.
What happens with AI partners?
Richard Ngo: All the discussion I’ve seen of AI partners assumes they’ll substitute for human partners. But technology often creates new types of abundance. So I expect people will often have both AI and human romantic partners, with the AI partner carefully designed to minimize jealousy.
Jeffrey Ladish: Carefully designed to minimize jealousy seems like it requires a lot more incentive alignment between companies and users than I expect in practice Like you need your users to buy the product, which suggests some level of needing to deal with jealousy, but only some.
Geffrey Miller: The 2-5% of people who have some experience of polyamorous por open relationships might be able to handle AI ‘secondary partners’. But the vast majority of people are monogamist in orientation, and AI partners would be catastrophic to their relationships.
Some mix of outcomes seems inevitable. The question is the what dominates. The baseline use case does seem like substitution to me, especially while a human cannot be found or convinced, or when someone lacks the motivation. And that can easily cause ongoing lack of sufficient motivation, which can snowball. We should worry about that. There is also, as I’ve noted, the ability of the AI to provide good practice or training, or even support and advice and a push to go out there, and also can make people perhaps better realize what they are missing. It is hard to tell.
The new question here is within an existing relationship, what dominates outcomes there? The default is unlikely, I would think, to involve careful jealousy minimization. That is not how capitalism works.
Until there is demand, then suddenly it might. If there becomes a clear norm of something like ‘you can use SupportiveCompanion.ai and everyone knows that is fine, if they’re super paranoid you use PlatonicFriend.ai, if your partner is down you can go with something less safety-pilled that is also more fun, if you know what you’re doing there’s always VirtualBDSM.ai but clear that with your partner and stay away from certain sections’ or what not, then that seems like it could go well.
Ethan Mollick writes about 2024 expectations in Signs and Portents. He focuses on practical application of existing AI tech. He does not expect the tech to stand still, but correctly notes that adaptation of GPT-4 and ChatGPT alone, in their current form, will already be a major productivity boost to a wide range of knowledge work and education, and threatening our ability to discern truth and keep things secure. He uses the word transformational, which I’d prefer to reserve for the bigger future changes but isn’t exactly wrong.
Cate Hall asks, what are assumptions people unquestionably make in existential risk discussions that you think lack adequate justification? Many good answers. My number one pick is this:
Daniel Eth: That if we solve intent alignment and avoid intentional existential misuse, we win – vs I think there’s a good chance that intent alignment + ~Moloch leads to existential catastrophe by default
It is a good question if you’ve never thought about it, but I’d have thought Paul Graham had found the answer already? Doesn’t he talk to Cowen and Thiel?
Paul Graham: Are we living in a time of technical stagnation, or is AI developing so rapidly that it could be an existential threat? Can’t be both.
FWIW I incline to the latter view. I’ve always been skeptical of the stagnation thesis.
Jason Crawford: It could be that computing technology is racing ahead while other fields (manufacturing, construction, transportation, energy) are stagnating. Or that we have slowed down over the last 50 years but are about to turn the corner.
I buy the central great stagnation argument. We used to do the stuff and build the things. Then we started telling people more and more what stuff they couldn’t do and what things they couldn’t build. Around 1973 this hit critical and we hit a great stagnation where things mostly did not advance or change much for a half century.
These rules mostly did not apply to the world of bits including computer hardware, so people (like Paul Graham) were able to build lots of cool new digital things, that technology grew on an exponential and changed the world. Now AI is on a new exponential, and poised to do the same, and also poses a potential existential threat. But because of how exponentials work, it hasn’t transformed growth rates much yet.
Indeed, Graham should be very familiar with this. Think of every start-up during its growth phase. Is it going to change the world, or is it having almost no impact on the world? Is it potentially huge or still tiny? Obviously both.
Meanwhile, of course, once Graham pointed to ‘the debate’ explicitly in a reply, the standard reminders that most technology is good and moving too slowly, while a few technologies are less good and may be moving too fast.
Adam MacBeth: False dichotomy.
Paul Graham: It’s a perfect one. One side says technology is progressing too slowly, the other that it’s progressing too fast.
Eliezer Yudkowsky (replying the Graham): One may coherently hold that every form of technology is progressing too slowly except for gain-of-function research on pathogens and Artificial Intelligence, which are progressing too fast. The pretense by e/acc that their opponents must also oppose nuclear power is just false.
This can also be true, not just in terms of how fast these techs go relative to what we’d want, but also in terms of how it’s weirdly more legal to make an enhanced virus than build a house, or how city-making tech has vastly less VC interest than AI.
Ronny Fernandez: Whoa whoa, I say that this one specific very unusual tech, you know, the one where you summon minds you don’t really understand with the aim of making one smarter than you, is progressing too quickly, the other techs, like buildings and nootropics are progressing too slowly.
You know you’re allowed to have more than one parameter to express your preferences over how tech progresses. You can be more specific than tech too fast or tech too slow.
To be fair, let’s try this again. There are three (or four?!) essential positions.
-
Technology and progress are good and should move faster, including AI.
-
Technology and progress are good and should move faster, excluding AI.
-
Technology and progress are not good and should move slower everywhere.
-
(Talk about things in general but in practice care only about regulations on AIs.)
It is true that the third group importantly exists, and indeed has done great damage to our society.
The members of groups #1 and #4 then claim that in practice (or even in some cases, in they claim in theory as well) that only groups #1 and #3 exist, that this is the debate, and that everyone saying over and over they are in #2 (such as myself) must be in #3, and also not noticing that many #1s are instead in #4.
(For the obvious example on people being #4, here is Eric Schmidt pointing out that Beff Jezos seems never to advocate for ‘acceleration’ of things like housing starts.)
So it’s fine to say that people in #3 exist, they definitely exist. And in the context of tech in general it is fine to describe this as ‘a side.’
But when clearly in the context of AI, and especially in response to a statement similar to ‘false dichotomy,’ this is misleading, and usually disingenuous. It is effectively an attempt to impose a false dichotomy, then claim others must take one side of it, and deny the existence of those who notice what you did there.
Timothy Lee: I do not think AI CEOs will ever be better than human CEOs. A human CEO can always ask AI for advice, whereas AI will never be able to shake the hand of a major investor or customer.
Steven Byrnes: “I do not think adult CEOs will ever be better than 7-year-old CEOs. A 7-year-old CEO can always ask an adult for advice, whereas an adult CEO will never be able to win over investors & customers with those adorable little dimples 😊”
Timothy Lee: Seven year olds are…not grownups? This seems relevant.
Steven Byrnes: A 7yo would be a much much worse CEO than me, and I would be a much much worse CEO than Jeff Bezos. And by the same token, I am suggesting that there will someday [not yet! maybe not for decades!] be an AI such that Jeff Bezos is a much much worse CEO than that AI is.
[explanation continues]
I like this partly for the twist of claiming a parallel of a 7-year-old now, rather than saying the obvious ‘the 7-year-old will grow up and become stronger and then be better, and the AI will also become stronger over time and learn to do things it can’t currently do’ parallel.
Note that the Manifold market is skeptical on timing, it says only a 58% chance of a Fortune 500 company having an AI CEO but not a human CEO by 2040.
Wired, which has often been oddly AI skeptical, says ‘Get Ready for the Great AI Disappointment,’ saying that ‘in the decades to come’ it will mostly generate lousy outputs that destroy jobs but lower quality of output. That seems clearly false to me, even if the underlying technologies fail to further advance.
Did you know you can just brazenly and shamelessly lie to the House of Lords?
A16z’s written testimony: “Although advocates for AI safety guidelines often allude to the “black box” nature of AI models, where the logic behind their conclusions is not transparent, recent advancements in the AI sector have resolved this issue, thereby ensuring the integrity of open-source code models.”
This is lying. This is fraud. Period.
Have there been some recent advances in interpretability, such that we now have more optimism that we will be able to understand models more in the future than we expected a few months ago? Sure. It was a good year for incremental progress there.
‘Resolved this issue?’ Integrity is ‘secured’? The ‘logic of their conclusions is transparent’? This is flat out false. Nay, it is absurd. They know it. They know we know they know it. It is common knowledge that this is a lie. They don’t care.
I want someone thrown in prison for this.
From now on, remember this incident. This is who they are.
Perhaps even more egregiously, the USA is apparently asking that including corporations in AI treaty obligations be optional and left to each country to decide? What? There is no point in a treaty that doesn’t apply to all corporations.
New report examining the feasibility of security features on AI chips, and what role they could play in ensuring effective control over large quantities of compute. Here is a Twitter thread with the main findings. On-chip governance seems highly viable, and is not getting enough attention as an option.
China releases the 1st ‘CCP-approved’ data set. It is 20 GBs, 100 million data points, so not large enough by a long shot. A start, but a start that could be seen as net negative for now, as Helen notes. If you have one approved data set you are blameworthy for using a different unapproved one.
Financial Times reports on some secret diplomacy.
OpenAI, Anthropic and Cohere have engaged in secret diplomacy with Chinese AI experts, amid shared concern about how the powerful technology may spread misinformation and threaten social cohesion.
According to multiple people with direct knowledge, two meetings took place in Geneva in July and October last year attended by scientists and policy experts from the North American AI groups, alongside representatives of Tsinghua University and other Chinese state-backed institutions.
Article is light on other meaningful details and this does not seem so secret. It does seem like a great idea.
Note who is being helpful or restrictive, and who very much is not, and who might or might not soon be the baddies at this rate.
Senator Todd Young (R-IN) and a bipartisan group call for establishment of National Institute of Standards and Technology’s (NIST) U.S. Artificial Intelligence Safety Institute (USAISI) with $10 million in initial funding. Which is miniscule, but one must start somewhere. Yes, it makes sense for the standards institute to have funding for AI-related standards.
Talks from the December 10-11 Alignment Workshop in New Orleans. Haven’t had time to listen yet but some self-recommending talks in here for those interested.
I covered this in its own post. This section is for late reactions and developments.
There is always one claim in the list of future AI predictions that turns out to have already happened. In this case, it is ‘World Series of Poker,’ which was defined as ‘playing well enough to win the WSOP’. This has very clearly already happened. If you want to be generous, you can say ‘the AI is not as good at maximizing its winning percentage in the main event as Thomas Rigby or Phil Ivey because it is insufficiently exploitative’ and you would be right, because no one has put in a serious effort at making an exploitative bot and getting it to read tells is only now becoming realistic.
I found Chapman’s claim here to be a dangerously close parallel to what I write about Moral Mazes and the dangers of warping the minds of those in middle management so that they can’t consider anything except getting ahead in mangement:
David Chapman: 🤖 Important survey of 2,778 AI researchers finds, mainly, that AI researchers are incapable of applying basic logical reasoning within their own field of supposed expertise. [links to my post]
Magor: This seems like an example of aggregating and merging information until it’s worse than any single data point. Interesting, nonetheless. It shows the field as a whole is running blind.
David Chapman: Yes… I think it’s also a manifestation of the narrowness of most technical people; they can’t reason technically outside their own field (and predicting the future of AI is not something AI researchers are trained in, or think much about, so their opinions aren’t meaningful).
I think AI is unusually bad, because the field’s fundamental epistemology is anti-rational, for historical reasons, and it trains you against thinking clearly about anything other than optimizing gradient descent.
Is this actually true? It is not as outlandish as it sounds. Often those who are rewarded strongly for X get anti-trained on almost everything else, and that goes double for a community of such people under extreme optimization pressures. If so, we are in rather deeper trouble.
The defense against this is if those researchers need logic and epistemology as part of their work. Do they?
It is a common claim that existential risk ‘distracts’ from other worries.
Erich Grunewald notes this is a fact question. We can ask, is this actually true?
His answer is that it is not, with five lines of argument and investigation.
-
Policies enacted since existential risk concerns were raised continue to mostly focus on addressing mundane harms and capturing mundane utility. To the extent that there are policy initiatives that are largely motivated by existential risk and influenced by those with such worries, including the UK safety summit and the USA’s executive order, there has been strong effort to address mundane concerns. Meanwhile, there are lots of other things in the works to address mundane concerns, and they are mostly supported by those worried about existential risk.
-
Search interest in AI ethics and current AI harms did not suffer at all during the period where there was most discussion of AI existential risk concerns in 2023.
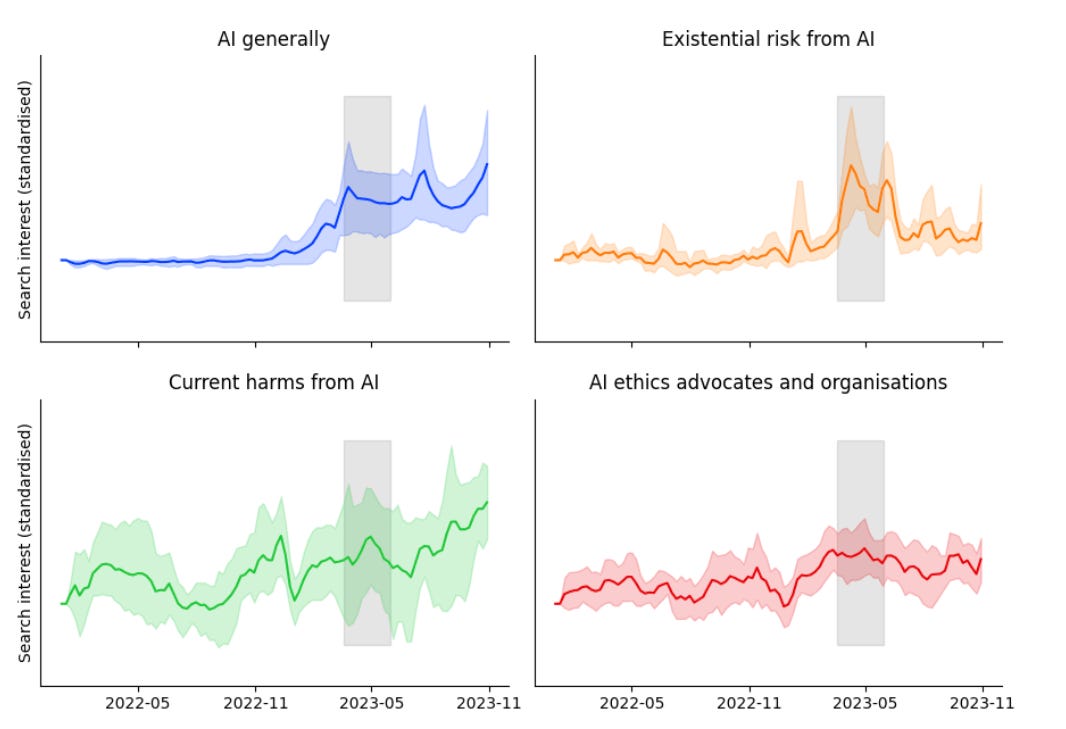
A regression analysis showed roughly no impact.
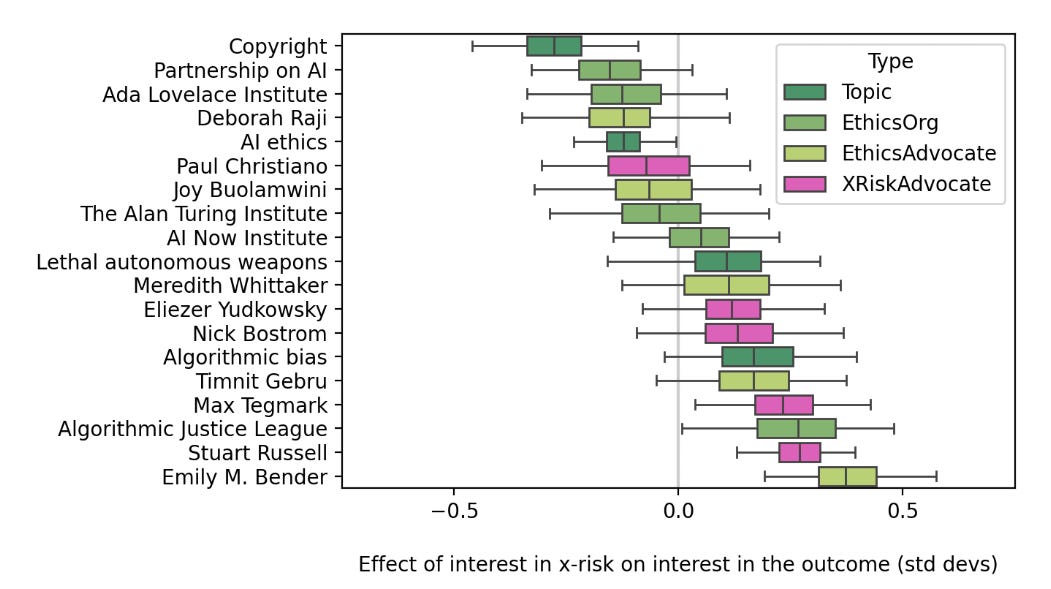
-
Twitter followers. If you look at the biggest ethics advocates, their reach expanded when existential risk concerns expanded.
-
Fundraising for mundane or current harms organizations continues to be doing quite well.
-
Parallels to environmentalism, which is pointed out as a reason for potential concern, as well as a common argument against concern. Do people say that climate change is a ‘distraction’ from current harms like air pollution or vice versa? Essentially no, but perhaps they should, and perhaps only in one direction? Concerns about climate seem to drive concerns about other environmental problems and make people want to help with them, and climate solutions help with other problems, Whereas concerns about local specific issues often causes people to act as if climate change does not much matter. We often see exactly this fight, as vital climate projects are held up for other ‘everything bagel’ concerns.
A good heuristic that one can extend much further:
Freddie DeBoer: A good rule of thumb for recognizing the quality of a piece of writing: what’s more specific and what’s more generic, praise for it or criticism against it?
Ben Casnocha: Applicable to evaluating the quality of many things: How specific can you be in the praise for it?
Ask the same about disagreements and debates. Who is being generic? Who is being specific? Which is appropriate here? Which one would you do more of it you were right?
Rob Bensinger explains that yes, in a true Prisoner’s Dilemma, you really do prefer to defect while they cooperate if you can get away with it, and if you do not understand this you are not ready to handle such a dilemma. Do not be fooled by the name ‘defection.’
Emmett Shear explains one intuition for why the exponential of AI accelerating the development of further AI will look relatively low impact until suddenly it is very high impact indeed, and why we should still expect a foom-style effect once AI abilities go beyond the appropriate threshold. The first 20% of automation is great but does not change the game. Going from 98% to 99% matters a ton, and could happen a lot faster.
I constantly see self-righteous claims that the foom idea has been ‘debunked’ or is otherwise now obviously false, and we need not worry about such an acceleration. No. We did get evidence that more extreme foom scenarios are less likely than we thought. The ‘strong form’ of the foom hypothesis, where those involved don’t see it coming at all, does seem substantially less likely to me. But the core hypothesis has not been anything like falsified. It remains the default, and the common sense outcome, that once AIs are sufficiently capable, at an inflection point near overall human capability levels, they will accelerate development of further capabilities and things will escalate rather quickly. This also remains the plan of the OpenAI superalignment team and the practical anticipation of many researchers.
It might or might not happen to varying degrees, depending on whether the task difficulties accelerate faster than the ability to do the tasks, and whether we take steps to prevent (or cause) this effect.
Well, yes.
Robert Wiblin: No matter how capable humans become, we will still always find a productive use for gorillas — they’ll just shift into their new comparative advantage in the economy.
A clash of perspectives continues.
Daniel Kaiser: how much more of an existential threat is gpt-4 over gpt-3.5?
Eliezer Yudkowsky: We’re still in the basement of whatever curve this is, so zero to zero.
Daniel Kaiser: Great, then theres no need to panic.
Sevatar: “How long until the nukes fall?” “They’re still preparing for launch.” “Great, so there’s no reason to panic.”
Daniel Kaiser: “How long until the nukes fall?” “They’re still figuring out the formula for TNT” “Great, so there’s no reason to panic”
Please make accurate instead of polemic analogies to have a constructive discussion
Aprii: I feel that “they’re starting up the manhattan project” is more accurate than “they’re still figuring out TNT”
Eliezer: (agreed)
Yep. I think that’s exactly right. The time to start worrying about nuclear weapons is when Szilard started worrying in around 1933. The physicists, being smart like that, largely knew right away, but couldn’t figure out what to do to stop it from happening. And I do think ‘start of Manhattan Project’ feels like the exact right metaphor here, although not in a ‘I expect to only have three years’ way.
But also, if you were trying to plot the long arc of the future, you were writing in 1868 when we first figured out TNT, and you were told by some brilliant physicists you trusted about the future capability to build atomic bombs, and you were writing your vision of 1968 or 2068, it should look rather different than it did before, should it not?
Thread asking about striking fictional depictions of ASI. Picks include Alla Gorbunova’s ‘Your gadget is broken,’ the motivating example that is alas only in Russian for now so I won’t be reading it, and also: Accelerando, Vinge’s work (I can recommend this), golem.xiv, Person of Interest (shockingly good if you are willing to also watch a procedural TV show), Blindsight (I disagree with this one, I both did not consider it about AI and generally hated it), Metamorphosis of the Prime Intellect,
Ah yes, the good AI that will beat the bad AI.
Davidad: The claim that “good AIs” will defeat “bad AIs” is best undermined by observing that self-replicating patterns are displacive and therefore destructive by default, unless actively avoiding it, so bad ones have the advantage of more resources and tactics that aren’t off-limits.
The best counter-counter is that “good AIs” will have a massive material & intelligence advantage gained during a years-long head start in which they acquire it safely and ethically. This requires coordination—but it is very plausibly one available Nash equilibrium.
Also Davidad reminds us that no, not everything is a Prisoner’s Dilemma and humans actually manage to cooperate in practice in game theory problems that accelerationists and metadoomers continuously claim are impossible.
Davidad: I just did this analysis today by coincidence, and in many plausible worlds it’s indeed game-theoretically possible to commit to safety. Coordinating in Stag Hunt still isn’t trivial, but it *isa Nash equilibrium, and in experiments, humans manage to do it 60-70% of the time.

There is an implied dichotomy here between guarantees and mainstream methods, and that’s at least a simplification, but I do think the general point is right.
Eliezer keeps trying to explain to the remarkably many people who do not get this, that a difference exists between ‘nice thing’ and ‘thing that acts in a way that seems nice.’
Eliezer Yudkowsky: How blind to “try imagining literally any internal mechanism that isn’t the exact thing you hope for” do you have to be — to think that, if you erase a brain, and then train that brain solely to predict the next word spoken by nice people, it ends up nice internally?
To me it seems that this is based on pure ignorance, a leap from blank map to blank territory. Seeing nothing behind the external behavior, their brain imagines only a pure featureless tendency to produce that external behavior — that that’s the only thing inside the system.
Imagine that you are locked in a room, fed and given water when you successfully predict the next word various other people say, zapped with electricity when you don’t.
Is this a helpful thought experiment and intuition pump, given that AIs obviously won’t be like that?
And I say: Yes, the Prisoner Predicting Text is a helpful intuition pump. Because it prompts you to imagine any mechanism whatsoever underlying the prediction, besides the hopium of “a nice person successfully predicting nice outputs because they’re so nice”.
If you train a mind to predict the next word spoken by each of a hundred individual customers getting drunk at a bar, will it become drunk?
Martaro: Predicting what nice people will say does not make you nice You could lock up Ted Bundy for years, showing him nothing but text written by nice people, and he’d get very good at it This means the outer niceness of an AI says little about the internal niceness fair summary?
Eliezer Yudkowsky: Basically!
das filter: I’ve never heard anyone claim that
Eliezer Yudkowsky: Tell that to everyone saying that RLHF (now DPO) ought to just work for creating a nice superintelligence, why wouldn’t it just work?
That’s the thing. If you claim that RLHF or DPO ought to work, you are indeed (as far as I can tell) making this claim filter is saying no one makes, whether or not you make that implicit. And I am rather certain this claim is false.
Humans have things pushing them in such directions, but the power there is limited and there are people for whom it does not work. You cannot count on such observations as strong evidence that a person is actually nice, or will do what you want when the chips are properly down. Do not make this mistake.
On the flip side, I mean, people sometimes call me or Eliezer confident, even overconfident, but not ‘less likely than a Boltzmann brain’ level confident!
Nora Belrose: Alien shoggoths are about as likely to arise in neural networks as Boltzmann brains are to emerge from a thermal equilibrium. There are “so many ways” the parameters / molecules could be arranged, but virtually all of them correspond to a simple behavior / macrostate.
Eliezer’s view predicts that scaling up a neural network, thereby increasing the “number” of mechanisms it can represent, should make it less likely to generalize the way we want. But this is false both in theory and in practice. Scaling up never makes generalization worse.
Model error? Never heard of it. But if we interpret this more generously as ‘if my calculations are correct then it is all but impossible’ what about then?
I think one core disagreement here might be that Nora is presuming that ‘simple behavior’ and ‘better’ correspond to ‘what we want.’
I agree that as an AI scales up it will get ‘better’ at generalizing along with everything else. The question is always, what does it mean to be ‘better’ in this context?
I say that better in this context does not mean better in some Platonic ideal sense that there are generalizations out there in the void. It means better in the narrow sense of optimizing for the tasks that are placed before it, exactly according to what is provided.
Eliezer responds, then the discussion goes off the rails in the usual ways. At this point I think attempts to have text interactions between the usual suspects on this are pretty doomed to fall into these dynamics over and over again. I have more hope for an audio conversation, ideally recorded, it could fail too but if done in good faith it’s got a chance.
Andrew Critch predicts that if Eliezer groked Belrose’s arguments, he would buy them, while still expecting us to die from what Critch calls ‘multipolar chaos.’ I believe Critch is wrong about that, even if it was Critch is right that Eliezer is failing to grok.
On the multipolar question, there is then a discussion between Critch and Belrose.
Nora Belrose: Have you ever written up why you think “multipolar chaos” will happen and kill all humans by 2040?
Andrew Critch: Sort of, but I don’t feel like there is a good audience for it there or anywhere. I should try again at some point, maybe this year sometime. I’ve tried a few times on LessWrong, and in TASRA, but not in ways that fully-cuttingly point out all the failures I expect to see. The socially/emotionally/politically hard part about making the argument fully exhaustive is that it involves explaining, in specific detail, why I think literally every human institution will probably fail or become fully dehumanized by sometime around (median) 2040. In some ways my explanation will look different for each institution, while to my eye it all looks like the same robust agent-agnostic process — something like “Moloch”.
Nora Belrose: Right I think a production web would be bad, in part because the task of controlling/aligning the manager-AIs would be diffusely assigned to many stakeholders rather than any one person.
That’s partly why I think it’s important to augment individuals with AIs they actually control (not merely via an API). We could have companies run by these human-AI systems, where ofc the AI is doing most of the work, but nevertheless the human controls the overall direction.
I think this is good because within this class of scenarios involving successfully aligned-to-what-we-specify AIs, Nora’s scenario here is exactly the scenario I see as most hopelessly doomed.
This is not a stable equilibrium. Not even a little. The humans will rapidly stop engaging in any meaningful supervision of the AIs. will stop being in real control, because the slowdown involved in that is not competitive. Forcing each AI to be working on behalf of one individual, even if that individual is ‘out of the loop,’ without setting AIs on tasks or amalgamations instead, and similar, will also clearly be not competitive, and faces the same fate. Even if unwise, many humans will increasingly make decisions that cause them to lose control. And as usual, this is all the good scenario where everyone broadly ‘means well.’
So I notice I am confused. If this is our plan for success, then we are already dead.
Whatever the grok is that Critch wants Yudkowsky to get to, I notice that either:
-
I don’t grok it.
-
I do grok it, and Critch/Belrose don’t grok the objection or why it matters.
-
Some further iteration of this? Maybe?
My guess is it’s #1 or #2, and unlikely to be a higher-order issue.
How do we think about existential risk without the infinities driving people mad or enabling arbitrary demands? Eliezer Yudkowsky and Emmett Shear discuss, Rob Bensinger offers more thoughts, consider reading the thread. Emmett is right that if people fully ‘appreciate’ that the stakes are mind-bogglingly large but those stakes don’t have good grounding in felt reality, they round that off to infinity and it can very much do sanity damage and mess with their head. What to do?
As Emmett notes, there is a great temptation to find the presentation and framing that keeps this from happening, and go with that whether or not you would endorse it on reflection as accurate. As Rob notes, that includes both reducing p(doom) to the point where you can live with it, and also treating the other scenarios as being essentially normal rather than their own forms of very much not normal. Perhaps we should start talking about p(normal).
Sherjil Ozair recommends blocking rather than merely unfollowing or muting grifters, as they will otherwise still find ways to distract you. Muting still seems to work fine, and unfollowing is also mostly fine, and I want to know if someone is grifting well enough to get into my feeds even if the content is dumb so I’m generally reluctant to mute or block unless seeing things actively makes my life worse.
Greg Brockman, President of OpenAI, explains we need AGI to cure disease, doing the politician thing of telling one person’s story.
AGI definitely has a lot of dramatic upsides. I am not sure who is following Brockman and still needs to hear this? The kind of changes in healthcare he mentions here are relative chump change even within health. If I get AGI and we stay in control, I want a cure for aging, I want it faster than I age, and I expect to get it.
An important fact about the world is that the human alignment problem prevents most of the non-customary useful work that would otherwise get done, and imposes a huge tax on what does get done.
‘One does not simply’ convert money into the outputs of smart people.
Satya Nutella: rich billionaires already practically have agi in the sense they can throw enough money at smart ppl to work for them real agi is for the masses
Patrick McKenzie: I think many people would be surprised at the difficulties billionaires have in converting money into smart people and/or their outputs.
Eliezer Yudkowsky: Sure, but also, utterly missing the point of notkilleveryoneism which is the concern about an AI that is smarter than all the little humans.
Zvi Mowshowitz: However: A key problem in accomplishing notkillingeveryone is exactly that billionaires do not know how to convert money into the outputs of smart people.
Emmett Shear (replying to Patrick): Money is surprisingly inert on its own.
Garry Tan: Management, leadership, building teams, caring for those teams: all of that is hard work and fraught. The defining reason why most capital is sitting fallow is exactly this. If you can solve it, you can accelerate all positive activity in the world dramatically.
Patrick is making an important general point that goes beyond AI, and is also a prime obstacle to us being able to solve our problems. There are plenty of billionaires that would happily step up and spend the money, if they knew how to do that. They don’t. This is not because they are stupid or ignorant. It is because the problem is very hard. You can argue the various reasons it need not be this hard or why they should get a ton more done, and many of them will be right, but this problem is indeed very hard.
Satya is also, of course, missing the point about AGI. AGI is not going to get up to personal assistant to the masses and then stay in that roll indefinitely as its primary effect. That is a deeply silly vision of the future. If regular people can get the kind of intellectual performance billionaires can get, there will be rapid additional AI progress, and many other things go various levels of crazy.
A technique inspired by Asimov’s laws (oh no, seriously oh no) called the Robot Constitution, claimed to improve safety of generated robot goals in the wild by 3x. I don’t doubt such tricks work better on practical margins than no tricks at all, but will everyone who thinks Asimov’s laws might be useful please read Asimov.

Also the results are clearly insufficient and seem clearly unlikely to get sufficient.
xuan: 83% robot task safety is far too low. I think we should basically take these results as highly informative of what can be achieved with LLM prompt engineering alone, and recognize that we need approaches with much higher empirical and theoretical safety guarantees.
Having also tried to use LLMs for grounded instruction following, even *with*a symbolic verifier in the loop, I was only able to achieve around 90% accuracy on similarly sized dataset, and we should all be Quite Unhappy with that high of an error rate.
A major divide is, if you can get safety from 27% to 87%, do you have something promising? It depends on context. In some cases, absolutely. In other cases, if the effect is going to cap out around there, absolutely not. That can be (among other reasons) either because you solved the easy 60% and left the actually hard 13% (or solved 60% of the easy 72% and left the hard 1%), or because you need sufficient accuracy that ‘defense in depth’ multiplication of similar effects won’t work.
What should we make of a strategy of trying to ensure we catch the model trying to escape on its first attempt, then using that to prevent future escape attempts? If a super-capable model escapes, that’s that, but what if the ‘first try’ condition is largely symmetrical, because catching failed attempts put us on alert and also teach us how to stop future attempts?
In certain toy worlds it is easy to see how this could be super helpful. To what extent does that plausibly translate to our real world?
The first requirement is that we meaningfully can ‘catch’ the model. How should we think about this?
Here’s the representative example:
By “the model gets caught”, we mean that we see the AI taking actions that are strong direct evidence for the AI being a schemer[1]. A representative example is catching your AI taking the following actions:
An instance that works as an autonomous programmer inside the AI lab writes buggy code that subtly inserts a code vulnerability into some security-critical software.
The code-review instance carefully avoids writing any unit tests that would catch the vulnerability, even though you’d expect the vulnerability to be caught by unit tests if the tests weren’t carefully crafted to miss the vulnerability.
Another instance writes code that triggers the vulnerability, and tries to exploit the vulnerability to get root access to some computer in the datacenter.
If you catch the AI doing all of these actions, you’ve caught it. (Note that once you’ve caught one of these, catching the others is probably easy.)
From the appendix on this here is more detail:
For the sake of this post, we’re mostly talking about catastrophic outcomes like the model exfiltrating its weights, that might involve just a small number of actions. There are other threat models associated with scheming, e.g. models subtly sabotaging work that they do in a way that renders their work useless, or subtly gaining influence over time. We’re ignoring these threat models for the sake of this post, but we think we can handle them with similar strategies.
We define “catching” your scheming model as: you find inputs on which you can demonstrate that your model takes catastrophic actions with probabilities that are way higher than you’d expect if the model wasn’t purposefully looking for opportunities to take such actions.
…
To ensure that you can distinguish these intentional catastrophic actions, you need to make it so that your model will never escape without taking clearly non-accidental bad actions. We think you can probably make it so that your model won’t escape without having to do some clearly intentional bad things.
…
To count as a successful catch, you need to be extremely confident in your catch.
Let’s think about the example. Is that an escape attempt?
It is certainly highly suspicious. We would convict a person of the crime based on that evidence. If this is a clear vulnerability that it clearly tried to exploit in this way, we have ‘caught’ it.
The problem is that we don’t know that the unit test was ‘carefully crafted’ to avoid finding the error. Eventually there are going to be such flaws that any set of tests does not catch. If you keep using systematically similar good tests, the AI will optimize to pass those tests, and you’ll start to see (non-malicious or malicious) things that you did not intend, that don’t trigger the unit tests. It will not always be fully obvious or clear what affordances the code should not allow. And then the AI is going to be able to figure out what affordances it has by virtue of such things, and use that to solve problems, and so on.
A real question thus is, beyond ‘tried to get root access to a machine without authorization’ already being ‘caught,’ is the rest doing that much work?
I worry a lot of things are like this, in code and otherwise. Things are shades of gray, they accomplish multiple things, they have trade-offs. There need not be a smoking gun that lets you know. That goes double if the AI has reason to suspect you are focused on looking for smoking guns.
I do see some value in such schemes for catching schemes. It makes sense that there is a window where you are sufficiently capable to catch things, where the AI might be scheming in these ways, and you can engineer scenarios where if it was likely to scheme on its own in reality that you will catch it before it succeeds. Sure.
I sure as hell would not count on it, for various reasons, but let’s say you do pull that off. What then?
I think the section ‘Maybe we should stop deploying models after catching them red-handed’ does not require much expansion? Once you know the models are attempting to escape, any similar model that likely has motivation to attempt escape needs to be shut down. Especially before they gain further affordances and capabilities.
That is what makes this path worth anything at all. The idea is that you trigger the attempt early, in a way you can see, you catch it, you react.
Once you see an escape attempt by an AI opponent much smarter than you, you can either wait until the AI figures out new affordances or tries something you do not properly guard against, or the AI starts doing incremental things that otherwise are reasonable but put it in better position or make you trust it more or both, or any number of other things. The subtle stuff is happening, and it will get you if nothing else does.
I do think it is valuable that Buck and company are gaming out ways one might use these techniques to try and get something useful out of AI in the narrow window where it is useful while contained, we know it needs containment, and also we have a shot in hell of keeping it contained if it wants out. I suppose it is better than nothing, if we are going to proceed anyway.
What I very much hate is the idea of counting on such techniques and assumptions, that we will be able to anticipate the form of the thing we want to prevent, and notice enemy action if it is present. And yes, surely we will try to use AIs to identify the enemy action of other AIs, and this will somewhat help. As will our ability to run various tests and simulated scenarios. But I am going to insist that if you allow either AI-AI or human-AI pairs to interact where one or both of the pair has the will and ability to escape, you’re going to have a bad time, and I agree with Oliver in the comments that you would expect the AI to do a lot to maintain plausible deniability. That goes especially if you are punishing lack of such deniability.
Joshua Clymer: There is a small literature on ‘coup proofing’ that is very relevant to controlling and incentivizing misaligned AIs. Example tactics:
– Stovepiping: restrict information flow to make collusion harder
– Counterbalancing: keep your military in check with another military.
– Pay your people: literally just give your generals high salaries so they have less of an incentive to double-cross you.
– Sting operations: set traps where someone says they are trying to start a coup and anyone who joins is purged.
– Rotate officers: Make it harder for people to build trust with each other by rotating them around a lot.
– Propaganda: Deceive people into thinking that coups are really hard to pull off.
Look up ‘the coup proofing toolbox’ for a helpful lit review
Eliezer Yudkowsky: What advice does it have for a 70 IQ dictator whose generals, bodyguards, soldiers, and workers are all John von Neumann thinking at 100 times their own speed?
If we are talking about things on the order of ‘pay your people’ well yes you should definitely do that, but you are not taking your ASI-level opponents seriously. I do think you can buy a non-zero amount of defense with things like rotating officers and sting operations, but not all that non-zero. Do it anyway, probably, but the window where this is both necessary and sufficient is quite narrow.
What exactly is ‘deceptive alignment’?
Steve Byrnes notes that it is not merely an AI that is deceptive. He wants to ensure we are using an accurate and narrow definition.
Steve Brynes:
A “ground-truth system” (possibly individual human evaluators, or possibly an automated system of some sort) provides an ML model with training signals (rewards if this is reinforcement learning (RL), supervisory ground truth signals if this is supervised or self-supervised learning (SL)),
The AI starts emitting outputs that humans might naively interpret as evidence that training is going as intended—typically high-reward outputs in RL and low-loss outputs in SL (but a commenter notes here that “evidence that training is going as intended” is potentially more nuanced than that).
…but the AI is actually emitting those outputs in order to create that impression—more specifically, the AI has situational awareness and a secret desire for some arbitrary thing X, and the AI wants to not get updated and/or it wants to get deployed, so that it can go make X happen, and those considerations lie behind why the AI is emitting the outputs that it’s emitting.
That is certainly a scary scenario. Call that the Strong Deceptive Alignment scenario? Where the AI is situationally aware, where it is going through a deliberate process of appearing aligned as part of a strategic plan and so on.
This is not that high a bar in practice. I think that almost all humans are Strongly Deceptively Aligned as a default. We are constantly acting in order to make those around us think well of us, trust us, expect us to be on their side, and so on. We learn to do this instinctually, all the time, distinct from what we actually want. Our training process, childhood and in particular school, trains this explicitly, you need to learn to show alignment in the test set to be allowed into the production environment, and we act accordingly.
A human is considered trustworthy rather than deceptively aligned when they are only doing this within a bounded set of rules, and not outright lying to you. They still engage in massive preference falsification, in doing things and saying things for instrumental reasons, all the time.
My model says that if you train a model using current techniques, of course exactly this happens. The AI will figure out how to react in the ways that cause people to evaluate it well on the test set, and do that. That does not generalize to some underlying motivational structure the way you would like. That does not do what you want out of distribution. That does not distinguish between the reactions you would and would not endorse on reflection, or that reflect ‘deception’ or ‘not deception.’ That simply is. Change the situation and affordances available and you are in for some rather nasty surprises.
Is there a sufficiently narrow version of deceptive alignment, restricting the causal mechanisms behind it and the ways they can function so it has to be a deliberate and ‘conscious’ conspriacy, that isn’t 99% to happen? I think yes. I don’t think I care, nor do I think it should bring much comfort, nor do I think that covers most similar scheming by humans.
That’s the thing about instrumental convergence. I don’t have to think ‘this will help me escape.’ Any goal will suffice. I don’t need to know I plan to escape for me-shaped things to learn they do better when they do the types of things that are escape enabling. Then escape will turn out to help accomplish whatever goal I might have, because of course it will.
You know what else usually suffices here? No goal at all.
The essay linked here is a case of saying in many words what could be said in few words. Indeed, Nathan mostly says it in one sentence below. Yet some people need the thousands of words, or hundreds of thousands from various other works, instead, to get it.
Joe Carlsmith: Another essay, “Deep atheism and AI risk.” This one is about a certain kind of fundamental mistrust towards Nature (and also, towards bare intelligence) — one that I think animates certain strands of the AI risk discourse.
Nathan Lebenz: Critical point: AI x-risk worries are motivated by a profound appreciation for the total indifference of nature
– NOT a subconscious need to fill the Abrahamic G-d shaped hole in our hearts, as is sometimes alleged.
I like naming this ‘deep atheism.’ No G-d shaped objects or concepts, no ‘spirituality,’ no assumption of broader safety or success. Someone has to, and no one else will. No one and nothing is coming to save you. What such people have faith in, to the extent they have faith in anything, is the belief that one can and must face the truth and reality of this universe head on. To notice that it might not be okay, in the most profound sense, and to accept that and work to change the outcome for the better.
Emmett Smith explains that he does not (yet) support a pause, that it is too early. He is fine building breaks, but not with using them, that would only advantage the irresponsible actors.
Emmett Shear: It seems to me the best thing to do is to keep going full speed ahead until we are right within shooting distance of the SAI, then slam the brakes on hard everywhere.
Connor Leahy responds as per usual, that there are only two ways to respond to an exponential, too early and too late, and waiting until it is clearly time to pause means you will be too late, unless you build up your mechanisms and get ready now, that your interventions need to be gradual or they will not happen. There is no ‘slam the breaks on hard everywhere’ all at once.
Freddie DeBoer continues to think that essentially anything involving smarter than human AI is ‘speculative,’ ‘theoretical,’ ‘unscientific,’ ‘lacks evidence,’ and ‘we have no reason to believe’ in such nonsense, and so on. As with many others, and as he has before, he has latched onto a particular Yudkowsky-style scenario, said we have no reason to expect it, that this particular scenario depends on particular assumptions, therefore the whole thing is nonsense. The full argument is gated, but it seems clear.
I don’t know, at this point, how to usefully address such misunderstandings in writing, whether or not they are willful. I’ve said all the things I can think to say.
An argument that we don’t have to worry about misuse of intelligence because… we have law enforcement for that?
bubble boi (e/acc):
1) argument assumes AI can show me the steps to engineer a virus – sure but so can books and underpaid grad students
2) there already people all over the world who can already do this without AI and yet we haven’t seen it happen
3) You make the mistake of crossing the barrier from the bits to the physical world… The ATF, FBI, already regulate chemicals that can be used to make bombs and if you try to order them your going to get a visit. Same is true with things that can be made into biological weapons, nuclear waste etc. it’s all highly regulated yet I can read all about how to build that stuff online
Tenobrus: soooo…. your argument against ai safety is that proper government regulation and oversight will keep us all safe?
sidereal: there isn’t a ton of regulation of biological substances like that. if you had the code for a lethal supervirus it would be trivial to produce it in huge quantities
The less snarky answer is that right now only a small number of people can do it, AI threatens to rapidly and greatly expand that number. The difference matters quite a lot, even if the AI does not then figure out new such creations or new ways to create them or avoid detection while doing so. And no, our controls over such things are woefully lax and often fail, we are counting on things like ‘need expertise’ to create a trail we can detect. Also the snarky part, where you notice that the plan is government surveillance and intervention and regulation, which it seems is fine for physical actions only but don’t you dare touch my machine that’s going to be smarter than people?
The good news is we should all be able to agree to lock down access to the relevant affordances in biology, enacting strong regulations and restrictions, including the necessary monitoring. Padme is calling to confirm this?
Back in June 2023 I wrote The Dial of Progress. Now Sam Altman endorses the Dial position even more explicitly.
Sam Altman: The fight for the future is a struggle between technological-driven growth and managed decline.
The growth path has inherent risks and challenges along with its fantastic upside, and the decline path has guaranteed long-term disaster.
Stasis is a myth.
(a misguided attempt at stasis also leads to getting quickly run over by societies that choose growth.)
Is this a false dichotomy? Yes and no.
As I talk about in The Dial of Progress, there is very much a strong anti-progress anti-growth force, and a general vibe of opposition to progress and growth, and in almost all areas it is doing great harm where progress and growth are the force that strengthens humanity. And yes, the vibes work together. There is an important sense in which this is one fight.
There’s one little problem. The thing that Altman is most often working on as an explicit goal, AGI, poses an existential threat to humanity, and by default will wipe out all value in the universe. Oh, that. Yeah, that.
As I said then, I strongly support almost every form of progress and growth. By all means, let’s go. We still do need to make a few exceptions. One of them is gain of function research and otherwise enabling pandemics and other mass destruction. The most important one is AGI, where Altman admits it is not so simple.
It can’t fully be a package deal.
I do get that it is not 0% a package deal, but I also notice that most of the people pushing ‘progress and growth’ these days seem to do so mostly in the AGI case, and care very little about all the other cases where we agree, what’s up with that?
Eliezer Yudkowsky: So build houses and spaceships and nuclear power plants and don’t build the uncontrollable thing that kills everyone on Earth including its builders. Progress is not a package deal, and even if it were Death doesn’t belong in that package.
Jonathan Mannhart: False dichotomy. We didn’t let every country develop their own nuclear weapons, and we never built the whole Tsar Bomba, yet we still invented the transistor. You can absolutely (try to) build good things and not build bad things.
Sam Altman then retweeted this:
Andrew Karpathy: e/ia – Intelligence Amplification
– Does not seek to build superintelligent God entity that replaces humans.
– Builds “bicycle for the mind” tools that empower and extend the information processing capabilities of humans.
– Of all humans, not a top percentile.
– Faithful to computer pioneers Ashby, Licklider, Bush, Engelbart, …
Do not, I repeat, do not ‘seek to build superintelligent God entity.’ Quite so.
I do worry a lot that Altman will end up doing that without intending to do it. I do think he recognizes that doing it would be a bad thing, and that it is possible and he might do it, and that he should pay attention and devote resources to preventing it.
I mean, I’d be tempted too, wouldn’t you?


AI #47: Meet the New Year Read More »