“Robotic humanoid animals with vaudeville costumes roam the streets collecting protection money in tokens”
“A basketball player in a haunted passenger train car with a basketball court, and he is playing against a team of ghosts”
“A herd of one million cats running on a hillside, aerial view”
“Video game footage of a dynamic 1990s third-person 3D platform game starring an anthropomorphic shark boy”
“A muscular barbarian breaking a CRT television set with a weapon, cinematic, 8K, studio lighting”
Limitations of video synthesis models
Overall, the Minimax video-01 results seen above feel fairly similar to Gen-3’s outputs, with some differences, like the lack of a celebrity filter on Will Smith (who sadly did not actually eat the spaghetti in our tests), and the more realistic cat hands and licking motion. Some results were far worse, like the one million cats and the Ars Technica reader.
On Tuesday, Stability AI announced that renowned filmmaker James Cameron—of Terminator and Skynet fame—has joined its board of directors. Stability is best known for its pioneering but highly controversial Stable Diffusion series of AI image-synthesis models, first launched in 2022, which can generate images based on text descriptions.
“I’ve spent my career seeking out emerging technologies that push the very boundaries of what’s possible, all in the service of telling incredible stories,” said Cameron in a statement. “I was at the forefront of CGI over three decades ago, and I’ve stayed on the cutting edge since. Now, the intersection of generative AI and CGI image creation is the next wave.”
Cameron is perhaps best known as the director behind blockbusters like Avatar, Titanic, and Aliens, but in AI circles, he may be most relevant for the co-creation of the character Skynet, a fictional AI system that triggers nuclear Armageddon and dominates humanity in the Terminator media franchise. Similar fears of AI taking over the world have since jumped into reality and recently sparked attempts to regulate existential risk from AI systems through measures like SB-1047 in California.
In a 2023 interview with CTV news, Cameron referenced The Terminator‘s release year when asked about AI’s dangers: “I warned you guys in 1984, and you didn’t listen,” he said. “I think the weaponization of AI is the biggest danger. I think that we will get into the equivalent of a nuclear arms race with AI, and if we don’t build it, the other guys are for sure going to build it, and so then it’ll escalate.”
Hollywood goes AI
Of course, Stability AI isn’t building weapons controlled by AI. Instead, Cameron’s interest in cutting-edge filmmaking techniques apparently drew him to the company.
“James Cameron lives in the future and waits for the rest of us to catch up,” said Stability CEO Prem Akkaraju. “Stability AI’s mission is to transform visual media for the next century by giving creators a full stack AI pipeline to bring their ideas to life. We have an unmatched advantage to achieve this goal with a technological and creative visionary like James at the highest levels of our company. This is not only a monumental statement for Stability AI, but the AI industry overall.”
Cameron joins other recent additions to Stability AI’s board, including Sean Parker, former president of Facebook, who serves as executive chairman. Parker called Cameron’s appointment “the start of a new chapter” for the company.
Despite significant protest from actors’ unions last year, elements of Hollywood are seemingly beginning to embrace generative AI over time. Last Wednesday, we covered a deal between Lionsgate and AI video-generation company Runway that will see the creation of a custom AI model for film production use. In March, the Financial Times reported that OpenAI was actively showing off its Sora video synthesis model to studio executives.
Unstable times for Stability AI
Cameron’s appointment to the Stability AI board comes during a tumultuous period for the company. Stability AI has faced a series of challenges this past year, including an ongoing class-action copyright lawsuit, a troubled Stable Diffusion 3 model launch, significant leadership and staff changes, and ongoing financial concerns.
In March, founder and CEO Emad Mostaque resigned, followed by a round of layoffs. This came on the heels of the departure of three key engineers—Robin Rombach, Andreas Blattmann, and Dominik Lorenz, who have since founded Black Forest Labs and released a new open-weights image-synthesis model called Flux, which has begun to take over the r/StableDiffusion community on Reddit.
Despite the issues, Stability AI claims its models are widely used, with Stable Diffusion reportedly surpassing 150 million downloads. The company states that thousands of businesses use its models in their creative workflows.
While Stable Diffusion has indeed spawned a large community of open-weights-AI image enthusiasts online, it has also been a lightning rod for controversy among some artists because Stability originally trained its models on hundreds of millions of images scraped from the Internet without seeking licenses or permission to use them.
Apparently that association is not a concern for Cameron, according to his statement: “The convergence of these two totally different engines of creation [CGI and generative AI] will unlock new ways for artists to tell stories in ways we could have never imagined. Stability AI is poised to lead this transformation.”
Given the flood of photorealistic AI-generated images washing over social media networks like X and Facebook these days, we’re seemingly entering a new age of media skepticism: the era of what I’m calling “deep doubt.” While questioning the authenticity of digital content stretches back decades—and analog media long before that—easy access to tools that generate convincing fake content has led to a new wave of liars using AI-generated scenes to deny real documentary evidence. Along the way, people’s existing skepticism toward online content from strangers may be reaching new heights.
Deep doubt is skepticism of real media that stems from the existence of generative AI. This manifests as broad public skepticism toward the veracity of media artifacts, which in turn leads to a notable consequence: People can now more credibly claim that real events did not happen and suggest that documentary evidence was fabricated using AI tools.
The concept behind “deep doubt” isn’t new, but its real-world impact is becoming increasingly apparent. Since the term “deepfake” first surfaced in 2017, we’ve seen a rapid evolution in AI-generated media capabilities. This has led to recent examples of deep doubt in action, such as conspiracy theorists claiming that President Joe Biden has been replaced by an AI-powered hologram and former President Donald Trump’s baseless accusation in August that Vice President Kamala Harris used AI to fake crowd sizes at her rallies. And on Friday, Trump cried “AI” again at a photo of him with E. Jean Carroll, a writer who successfully sued him for sexual assault, that contradicts his claim of never having met her.
Legal scholars Danielle K. Citron and Robert Chesney foresaw this trend years ago, coining the term “liar’s dividend” in 2019 to describe the consequence of deep doubt: deepfakes being weaponized by liars to discredit authentic evidence. But whereas deep doubt was once a hypothetical academic concept, it is now our reality.
The rise of deepfakes, the persistence of doubt
Doubt has been a political weapon since ancient times. This modern AI-fueled manifestation is just the latest evolution of a tactic where the seeds of uncertainty are sown to manipulate public opinion, undermine opponents, and hide the truth. AI is the newest refuge of liars.
Over the past decade, the rise of deep-learning technology has made it increasingly easy for people to craft false or modified pictures, audio, text, or video that appear to be non-synthesized organic media. Deepfakes were named after a Reddit user going by the name “deepfakes,” who shared AI-faked pornography on the service, swapping out the face of a performer with the face of someone else who wasn’t part of the original recording.
In the 20th century, one could argue that a certain part of our trust in media produced by others was a result of how expensive and time-consuming it was, and the skill it required, to produce documentary images and films. Even texts required a great deal of time and skill. As the deep doubt phenomenon grows, it will erode this 20th-century media sensibility. But it will also affect our political discourse, legal systems, and even our shared understanding of historical events that rely on that media to function—we rely on others to get information about the world. From photorealistic images to pitch-perfect voice clones, our perception of what we consider “truth” in media will need recalibration.
In April, a panel of federal judges highlighted the potential for AI-generated deepfakes to not only introduce fake evidence but also cast doubt on genuine evidence in court trials. The concern emerged during a meeting of the US Judicial Conference’s Advisory Committee on Evidence Rules, where the judges discussed the challenges of authenticating digital evidence in an era of increasingly sophisticated AI technology. Ultimately, the judges decided to postpone making any AI-related rule changes, but their meeting shows that the subject is already being considered by American judges.
Enlarge/ Under C2PA, this stock image would be labeled as a real photograph if the camera used to take it, and the toolchain for retouching it, supported the C2PA. But even as a real photo, does it actually represent reality, and is there a technological solution to that problem?
On Tuesday, Google announced plans to implement content authentication technology across its products to help users distinguish between human-created and AI-generated images. Over several upcoming months, the tech giant will integrate the Coalition for Content Provenance and Authenticity (C2PA) standard, a system designed to track the origin and editing history of digital content, into its search, ads, and potentially YouTube services. However, it’s an open question of whether a technological solution can address the ancient social issue of trust in recorded media produced by strangers.
A group of tech companies created the C2PA system beginning in 2019 in an attempt to combat misleading, realistic synthetic media online. As AI-generated content becomes more prevalent and realistic, experts have worried that it may be difficult for users to determine the authenticity of images they encounter. The C2PA standard creates a digital trail for content, backed by an online signing authority, that includes metadata information about where images originate and how they’ve been modified.
Google will incorporate this C2PA standard into its search results, allowing users to see if an image was created or edited using AI tools. The tech giant’s “About this image” feature in Google Search, Lens, and Circle to Search will display this information when available.
In a blog post, Laurie Richardson, Google’s vice president of trust and safety, acknowledged the complexities of establishing content provenance across platforms. She stated, “Establishing and signaling content provenance remains a complex challenge, with a range of considerations based on the product or service. And while we know there’s no silver bullet solution for all content online, working with others in the industry is critical to create sustainable and interoperable solutions.”
The company plans to use the C2PA’s latest technical standard, version 2.1, which reportedly offers improved security against tampering attacks. Its use will extend beyond search since Google intends to incorporate C2PA metadata into its ad systems as a way to “enforce key policies.” YouTube may also see integration of C2PA information for camera-captured content in the future.
Google says the new initiative aligns with its other efforts toward AI transparency, including the development of SynthID, an embedded watermarking technology created by Google DeepMind.
Widespread C2PA efficacy remains a dream
Despite having a history that reaches back at least five years now, the road to useful content provenance technology like C2PA is steep. The technology is entirely voluntary, and key authenticating metadata can easily be stripped from images once added.
AI image generators would need to support the standard for C2PA information to be included in each generated file, which will likely preclude open source image synthesis models like Flux. So perhaps, in practice, more “authentic,” camera-authored media will be labeled with C2PA than AI-generated images.
Beyond that, maintaining the metadata requires a complete toolchain that supports C2PA every step along the way, including at the source and any software used to edit or retouch the images. Currently, only a handful of camera manufacturers, such as Leica, support the C2PA standard. Nikon and Canon have pledged to adopt it, but The Verge reports that there’s still uncertainty about whether Apple and Google will implement C2PA support in their smartphone devices.
Adobe’s Photoshop and Lightroom can add and maintain C2PA data, but many other popular editing tools do not yet offer the capability. It only takes one non-compliant image editor in the chain to break the full usefulness of C2PA. And the general lack of standardized viewing methods for C2PA data across online platforms presents another obstacle to making the standard useful for everyday users.
Currently, C2PA could arguably be seen as a technological solution for current trust issues around fake images. In that sense, C2PA may become one of many tools used to authenticate content by determining whether the information came from a credible source—if the C2PA metadata is preserved—but it is unlikely to be a complete solution to AI-generated misinformation on its own.
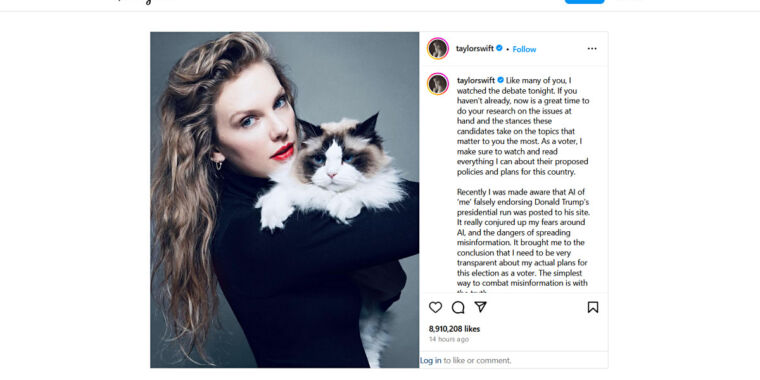
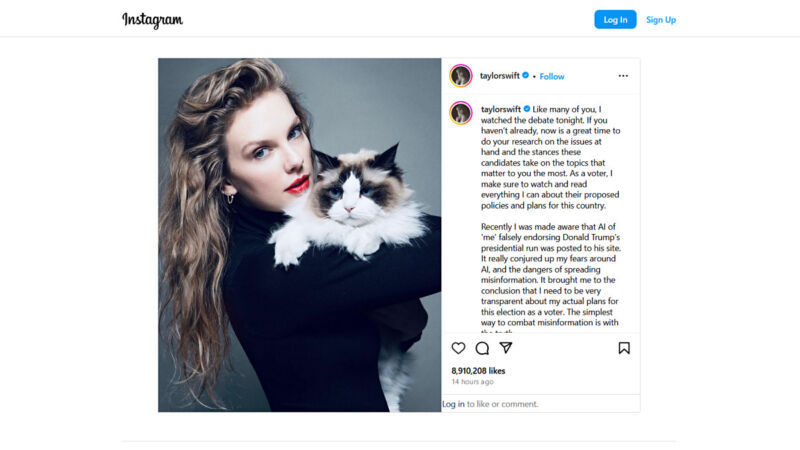
Enlarge/ A screenshot of Taylor Swift’s Kamala Harris Instagram post, captured on September 11, 2024.
On Tuesday night, Taylor Swift endorsed Vice President Kamala Harris for US President on Instagram, citing concerns over AI-generated deepfakes as a key motivator. The artist’s warning aligns with current trends in technology, especially in an era where AI synthesis models can easily create convincing fake images and videos.
“Recently I was made aware that AI of ‘me’ falsely endorsing Donald Trump’s presidential run was posted to his site,” she wrote in her Instagram post. “It really conjured up my fears around AI, and the dangers of spreading misinformation. It brought me to the conclusion that I need to be very transparent about my actual plans for this election as a voter. The simplest way to combat misinformation is with the truth.”
In August 2024, former President Donald Trump posted AI-generated images on Truth Social falsely suggesting Swift endorsed him, including a manipulated photo depicting Swift as Uncle Sam with text promoting Trump. The incident sparked Swift’s fears about the spread of misinformation through AI.
This isn’t the first time Swift and generative AI have appeared together in the news. In February, we reported that a flood of explicit AI-generated images of Swift originated from a 4chan message board where users took part in daily challenges to bypass AI image generator filters.
Enlarge/ An ABC handout promotional image for “AI and the Future of Us: An Oprah Winfrey Special.”
On Thursday, ABC announced an upcoming TV special titled, “AI and the Future of Us: An Oprah Winfrey Special.” The one-hour show, set to air on September 12, aims to explore AI’s impact on daily life and will feature interviews with figures in the tech industry, like OpenAI CEO Sam Altman and Bill Gates. Soon after the announcement, some AI critics began questioning the guest list and the framing of the show in general.
“Sure is nice of Oprah to host this extended sales pitch for the generative AI industry at a moment when its fortunes are flagging and the AI bubble is threatening to burst,” tweeted author Brian Merchant, who frequently criticizes generative AI technology in op-eds, social media, and through his “Blood in the Machine” AI newsletter.
“The way the experts who are not experts are presented as such 💀 what a train wreck,” replied artist Karla Ortiz, who is a plaintiff in a lawsuit against several AI companies. “There’s still PLENTY of time to get actual experts and have a better discussion on this because yikes.”
The trailer for Oprah’s upcoming TV special on AI.
On Friday, Ortiz created a lengthy viral thread on X that detailed her potential issues with the program, writing, “This event will be the first time many people will get info on Generative AI. However it is shaping up to be a misinformed marketing event starring vested interests (some who are under a litany of lawsuits) who ignore the harms GenAi inflicts on communities NOW.”
Critics of generative AI like Ortiz question the utility of the technology, its perceived environmental impact, and what they see as blatant copyright infringement. In training AI language models, tech companies like Meta, Anthropic, and OpenAI commonly use copyrighted material gathered without license or owner permission. OpenAI claims that the practice is “fair use.”
Oprah’s guests
According to ABC, the upcoming special will feature “some of the most important and powerful people in AI,” which appears to roughly translate to “famous and publicly visible people related to tech.” Microsoft co-founder Bill Gates, who stepped down as Microsoft CEO 24 years ago, will appear on the show to explore the “AI revolution coming in science, health, and education,” ABC says, and warn of “the once-in-a-century type of impact AI may have on the job market.”
As a guest representing ChatGPT-maker OpenAI, Sam Altman will explain “how AI works in layman’s terms” and discuss “the immense personal responsibility that must be borne by the executives of AI companies.” Karla Ortiz specifically criticized Altman in her thread by saying, “There are far more qualified individuals to speak on what GenAi models are than CEOs. Especially one CEO who recently said AI models will ‘solve all physics.’ That’s an absurd statement and not worthy of your audience.”
In a nod to present-day content creation, YouTube creator Marques Brownlee will appear on the show and reportedly walk Winfrey through “mind-blowing demonstrations of AI’s capabilities.”
Brownlee’s involvement received special attention from some critics online. “Marques Brownlee should be absolutely ashamed of himself,” tweeted PR consultant and frequent AI critic Ed Zitron, who frequently heaps scorn on generative AI in his own newsletter. “What a disgraceful thing to be associated with.”
Other guests include Tristan Harris and Aza Raskin from the Center for Humane Technology, who aim to highlight “emerging risks posed by powerful and superintelligent AI,” an existential risk topic that has its own critics. And FBI Director Christopher Wray will reveal “the terrifying ways criminals and foreign adversaries are using AI,” while author Marilynne Robinson will reflect on “AI’s threat to human values.”
Going only by the publicized guest list, it appears that Oprah does not plan to give voice to prominent non-doomer critics of AI. “This is really disappointing @Oprah and frankly a bit irresponsible to have a one-sided conversation on AI without informed counterarguments from those impacted,” tweeted TV producer Theo Priestley.
Others on the social media network shared similar criticism about a perceived lack of balance in the guest list, including Dr. Margaret Mitchell of Hugging Face. “It could be beneficial to have an AI Oprah follow-up discussion that responds to what happens in [the show] and unpacks generative AI in a more grounded way,” she said.
Oprah’s AI special will air on September 12 on ABC (and a day later on Hulu) in the US, and it will likely elicit further responses from the critics mentioned above. But perhaps that’s exactly how Oprah wants it: “It may fascinate you or scare you,” Winfrey said in a promotional video for the special. “Or, if you’re like me, it may do both. So let’s take a breath and find out more about it.”
Enlarge/ Still of Procreate CEO James Cuda from a video posted to X.
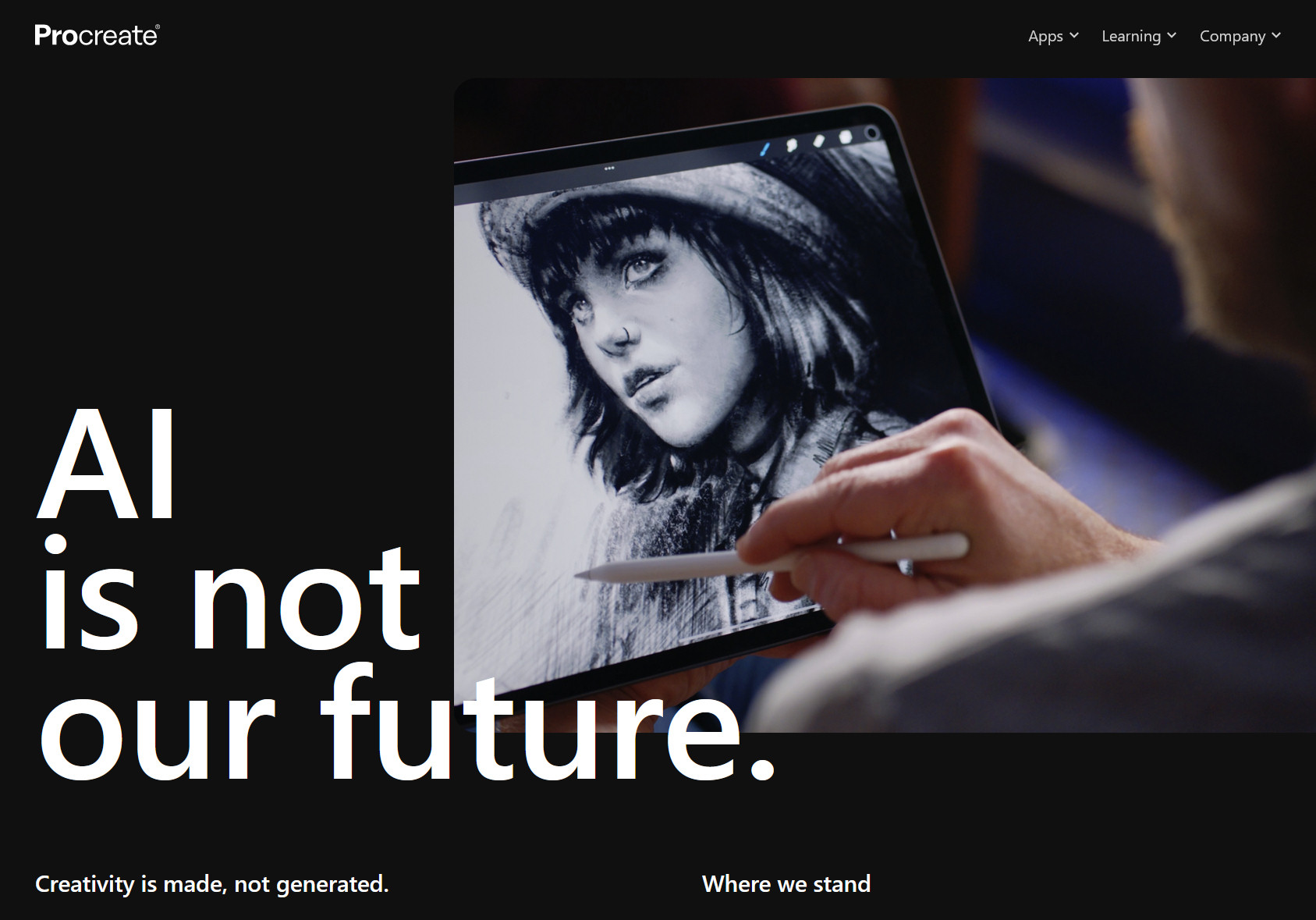
On Sunday, Procreate announced that it will not incorporate generative AI into its popular iPad illustration app. The decision comes in response to an ongoing backlash from some parts of the art community, which has raised concerns about the ethical implications and potential consequences of AI use in creative industries.
“Generative AI is ripping the humanity out of things,” Procreate wrote on its website. “Built on a foundation of theft, the technology is steering us toward a barren future.”
In a video posted on X, Procreate CEO James Cuda laid out his company’s stance, saying, “We’re not going to be introducing any generative AI into our products. I don’t like what’s happening to the industry, and I don’t like what it’s doing to artists.”
Cuda’s sentiment echoes the fears of some digital artists who feel that AI image synthesis models, often trained on content without consent or compensation, threaten their livelihood and the authenticity of creative work. That’s not a universal sentiment among artists, but AI image synthesis is often a deeply divisive subject on social media, with some taking starkly polarized positions on the topic.
Procreate CEO James Cuda lays out his argument against generative AI in a video posted to X.
Cuda’s video plays on that polarization with clear messaging against generative AI. His statement reads as follows:
You’ve been asking us about AI. You know, I usually don’t like getting in front of the camera. I prefer that our products speak for themselves. I really fucking hate generative AI. I don’t like what’s happening in the industry and I don’t like what it’s doing to artists. We’re not going to be introducing any generative AI into out products. Our products are always designed and developed with the idea that a human will be creating something. You know, we don’t exactly know where this story’s gonna go or how it ends, but we believe that we’re on the right path supporting human creativity.
The debate over generative AI has intensified among some outspoken artists as more companies integrate these tools into their products. Dominant illustration software provider Adobe has tried to avoid ethical concerns by training its Firefly AI models on licensed or public domain content, but some artists have remained skeptical. Adobe Photoshop currently includes a “Generative Fill” feature powered by image synthesis, and the company is also experimenting with video synthesis models.
The backlash against image and video synthesis is not solely focused on creative app developers. Hardware manufacturer Wacom and game publisher Wizards of the Coast have faced criticism and issued apologies after using AI-generated content in their products. Toys “R” Us also faced a negative reaction after debuting an AI-generated commercial. Companies are still grappling with balancing the potential benefits of generative AI with the ethical concerns it raises.
Artists and critics react
Enlarge/ A partial screenshot of Procreate’s AI website captured on August 20, 2024.
So far, Procreate’s anti-AI announcement has been met with a largely positive reaction in replies to its social media post. In a widely liked comment, artist Freya Holmér wrote on X, “this is very appreciated, thank you.”
Some of the more outspoken opponents of image synthesis also replied favorably to Procreate’s move. Karla Ortiz, who is a plaintiff in a lawsuit against AI image-generator companies, replied to Procreate’s video on X, “Whatever you need at any time, know I’m here!! Artists support each other, and also support those who allow us to continue doing what we do! So thank you for all you all do and so excited to see what the team does next!”
Artist RJ Palmer, who stoked the first major wave of AI art backlash with a viral tweet in 2022, also replied to Cuda’s video statement, saying, “Now thats the way to send a message. Now if only you guys could get a full power competitor to [Photoshop] on desktop with plugin support. Until someone can build a real competitor to high level [Photoshop] use, I’m stuck with it.”
A few pro-AI users also replied to the X post, including AI-augmented artist Claire Silver, who uses generative AI as an accessibility tool. She wrote on X, “Most of my early work is made with a combination of AI and Procreate. 7 years ago, before text to image was really even a thing. I loved procreate because it used tech to boost accessibility. Like AI, it augmented trad skill to allow more people to create. No rules, only tools.”
Since AI image synthesis continues to be a highly charged subject among some artists, reaffirming support for human-centric creativity could be an effective differentiated marketing move for Procreate, which currently plays underdog to creativity app giant Adobe. While some may prefer to use AI tools, in an (ideally healthy) app ecosystem with personal choice in illustration apps, people can follow their conscience.
Procreate’s anti-AI stance is slightly risky because it might also polarize part of its user base—and if the company changes its mind about including generative AI in the future, it will have to walk back its pledge. But for now, Procreate is confident in its decision: “In this technological rush, this might make us an exception or seem at risk of being left behind,” Procreate wrote. “But we see this road less traveled as the more exciting and fruitful one for our community.”
Enlarge/ AI-generated image by FLUX.1 dev: “A beautiful queen of the universe holding up her hands, face in the background.”
FLUX.1
On Thursday, AI-startup Black Forest Labs announced the launch of its company and the release of its first suite of text-to-image AI models, called FLUX.1. The German-based company, founded by researchers who developed the technology behind Stable Diffusion and invented the latent diffusion technique, aims to create advanced generative AI for images and videos.
The launch of FLUX.1 comes about seven weeks after Stability AI’s troubled release of Stable Diffusion 3 Medium in mid-June. Stability AI’s offering faced widespread criticism among image-synthesis hobbyists for its poor performance in generating human anatomy, with users sharing examples of distorted limbs and bodies across social media. That problematic launch followed the earlier departure of three key engineers from Stability AI—Robin Rombach, Andreas Blattmann, and Dominik Lorenz—who went on to found Black Forest Labs along with latent diffusion co-developer Patrick Esser and others.
Black Forest Labs launched with the release of three FLUX.1 text-to-image models: a high-end commercial “pro” version, a mid-range “dev” version with open weights for non-commercial use, and a faster open-weights “schnell” version (“schnell” means quick or fast in German). Black Forest Labs claims its models outperform existing options like Midjourney and DALL-E in areas such as image quality and adherence to text prompts.
AI-generated image by FLUX.1 dev: “A close-up photo of a pair of hands holding a plate full of pickles.”
FLUX.1
AI-generated image by FLUX.1 dev: A hand holding up five fingers with a starry background.
FLUX.1
AI-generated image by FLUX.1 dev: “An Ars Technica reader sitting in front of a computer monitor. The screen shows the Ars Technica website.”
FLUX.1
AI-generated image by FLUX.1 dev: “a boxer posing with fists raised, no gloves.”
FLUX.1
AI-generated image by FLUX.1 dev: “An advertisement for ‘Frosted Prick’ cereal.”
FLUX.1
AI-generated image of a happy woman in a bakery baking a cake by FLUX.1 dev.
FLUX.1
AI-generated image by FLUX.1 dev: “An advertisement for ‘Marshmallow Menace’ cereal.”
FLUX.1
AI-generated image of “A handsome Asian influencer on top of the Empire State Building, instagram” by FLUX.1 dev.
FLUX.1
In our experience, the outputs of the two higher-end FLUX.1 models are generally comparable with OpenAI’s DALL-E 3 in prompt fidelity, with photorealism that seems close to Midjourney 6. They represent a significant improvement over Stable Diffusion XL, the team’s last major release under Stability (if you don’t count SDXL Turbo).
The FLUX.1 models use what the company calls a “hybrid architecture” combining transformer and diffusion techniques, scaled up to 12 billion parameters. Black Forest Labs said it improves on previous diffusion models by incorporating flow matching and other optimizations.
FLUX.1 seems competent at generating human hands, which was a weak spot in earlier image-synthesis models like Stable Diffusion 1.5 due to a lack of training images that focused on hands. Since those early days, other AI image generators like Midjourney have mastered hands as well, but it’s notable to see an open-weights model that renders hands relatively accurately in various poses.
We downloaded the weights file to the FLUX.1 dev model from GitHub, but at 23GB, it won’t fit in the 12GB VRAM of our RTX 3060 card, so it will need quantization to run locally (reducing its size), which reportedly (through chatter on Reddit) some people have already had success with.
Instead, we experimented with FLUX.1 models on AI cloud-hosting platforms Fal and Replicate, which cost money to use, though Fal offers some free credits to start.
Black Forest looks ahead
Black Forest Labs may be a new company, but it’s already attracting funding from investors. It recently closed a $31 million Series Seed funding round led by Andreessen Horowitz, with additional investments from General Catalyst and MätchVC. The company also brought on high-profile advisers, including entertainment executive and former Disney President Michael Ovitz and AI researcher Matthias Bethge.
“We believe that generative AI will be a fundamental building block of all future technologies,” the company stated in its announcement. “By making our models available to a wide audience, we want to bring its benefits to everyone, educate the public and enhance trust in the safety of these models.”
AI-generated image by FLUX.1 dev: A cat in a car holding a can of beer that reads, ‘AI Slop.’
FLUX.1
AI-generated image by FLUX.1 dev: Mickey Mouse and Spider-Man singing to each other.
FLUX.1
AI-generated image by FLUX.1 dev: “a muscular barbarian with weapons beside a CRT television set, cinematic, 8K, studio lighting.”
FLUX.1
AI-generated image of a flaming cheeseburger created by FLUX.1 dev.
FLUX.1
AI-generated image by FLUX.1 dev: “Will Smith eating spaghetti.”
FLUX.1
AI-generated image by FLUX.1 dev: “a muscular barbarian with weapons beside a CRT television set, cinematic, 8K, studio lighting. The screen reads ‘Ars Technica.'”
FLUX.1
AI-generated image by FLUX.1 dev: “An advertisement for ‘Burt’s Grenades’ cereal.”
FLUX.1
AI-generated image by FLUX.1 dev: “A close-up photo of a pair of hands holding a plate that contains a portrait of the queen of the universe”
FLUX.1
Speaking of “trust and safety,” the company did not mention where it obtained the training data that taught the FLUX.1 models how to generate images. Judging by the outputs we could produce with the model that included depictions of copyrighted characters, Black Forest Labs likely used a huge unauthorized image scrape of the Internet, possibly collected by LAION, an organization that collected the datasets that trained Stable Diffusion. This is speculation at this point. While the underlying technological achievement of FLUX.1 is notable, it feels likely that the team is playing fast and loose with the ethics of “fair use” image scraping much like Stability AI did. That practice may eventually attract lawsuits like those filed against Stability AI.
Though text-to-image generation is Black Forest’s current focus, the company plans to expand into video generation next, saying that FLUX.1 will serve as the foundation of a new text-to-video model in development, which will compete with OpenAI’s Sora, Runway’s Gen-3 Alpha, and Kuaishou’s Kling in a contest to warp media reality on demand. “Our video models will unlock precise creation and editing at high definition and unprecedented speed,” the Black Forest announcement claims.
Enlarge/ Researchers write, “In this image, the person on the left (Scarlett Johansson) is real, while the person on the right is AI-generated. Their eyeballs are depicted underneath their faces. The reflections in the eyeballs are consistent for the real person, but incorrect (from a physics point of view) for the fake person.”
In 2024, it’s almost trivial to create realistic AI-generated images of people, which has led to fears about how these deceptive images might be detected. Researchers at the University of Hull recently unveiled a novel method for detecting AI-generated deepfake images by analyzing reflections in human eyes. The technique, presented at the Royal Astronomical Society’s National Astronomy Meeting last week, adapts tools used by astronomers to study galaxies for scrutinizing the consistency of light reflections in eyeballs.
Adejumoke Owolabi, an MSc student at the University of Hull, headed the research under the guidance of Dr. Kevin Pimbblet, professor of astrophysics.
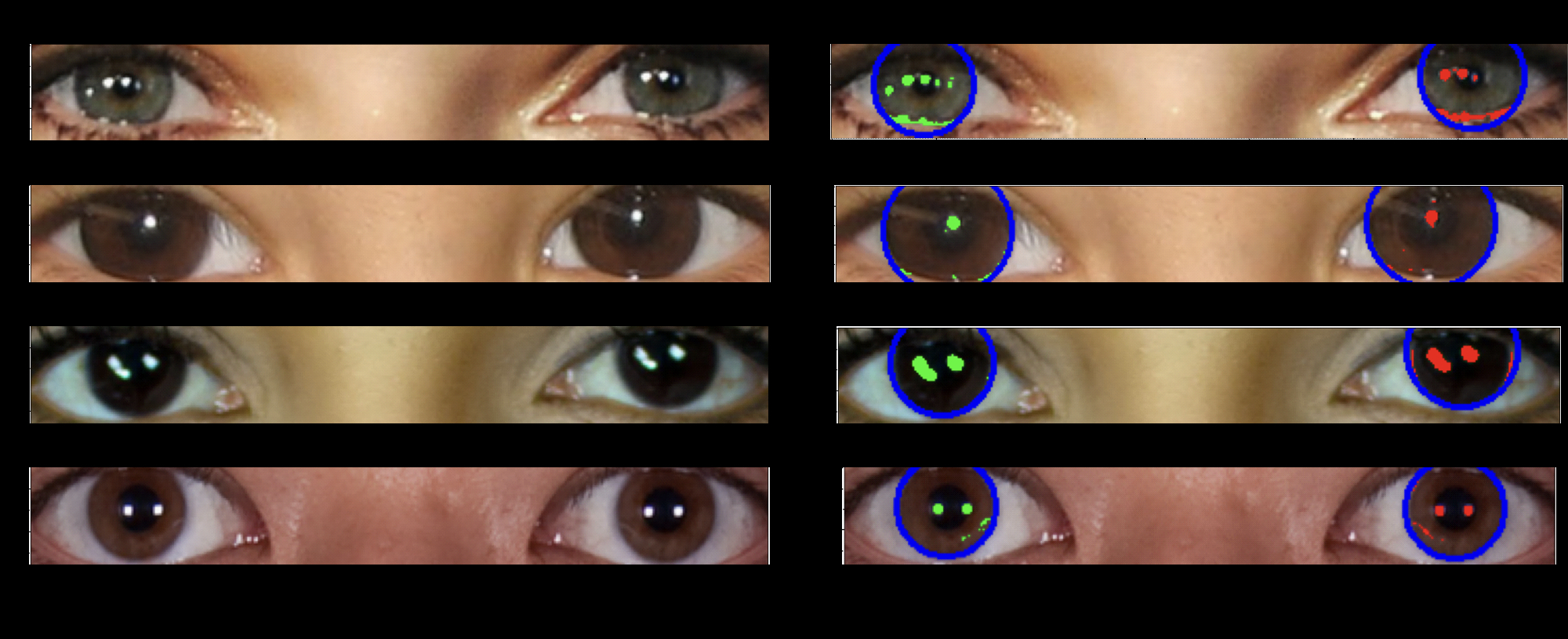
Their detection technique is based on a simple principle: A pair of eyes being illuminated by the same set of light sources will typically have a similarly shaped set of light reflections in each eyeball. Many AI-generated images created to date don’t take eyeball reflections into account, so the simulated light reflections are often inconsistent between each eye.
Enlarge/ A series of real eyes showing largely consistent reflections in both eyes.
In some ways, the astronomy angle isn’t always necessary for this kind of deepfake detection because a quick glance at a pair of eyes in a photo can reveal reflection inconsistencies, which is something artists who paint portraits have to keep in mind. But the application of astronomy tools to automatically measure and quantify eye reflections in deepfakes is a novel development.
Automated detection
In a Royal Astronomical Society blog post, Pimbblet explained that Owolabi developed a technique to detect eyeball reflections automatically and ran the reflections’ morphological features through indices to compare similarity between left and right eyeballs. Their findings revealed that deepfakes often exhibit differences between the pair of eyes.
The team applied methods from astronomy to quantify and compare eyeball reflections. They used the Gini coefficient, typically employed to measure light distribution in galaxy images, to assess the uniformity of reflections across eye pixels. A Gini value closer to 0 indicates evenly distributed light, while a value approaching 1 suggests concentrated light in a single pixel.
Enlarge/ A series of deepfake eyes showing inconsistent reflections in each eye.
In the Royal Astronomical Society post, Pimbblet drew comparisons between how they measured eyeball reflection shape and how they typically measure galaxy shape in telescope imagery: “To measure the shapes of galaxies, we analyze whether they’re centrally compact, whether they’re symmetric, and how smooth they are. We analyze the light distribution.”
The researchers also explored the use of CAS parameters (concentration, asymmetry, smoothness), another tool from astronomy for measuring galactic light distribution. However, this method proved less effective in identifying fake eyes.
A detection arms race
While the eye-reflection technique offers a potential path for detecting AI-generated images, the method might not work if AI models evolve to incorporate physically accurate eye reflections, perhaps applied as a subsequent step after image generation. The technique also requires a clear, up-close view of eyeballs to work.
The approach also risks producing false positives, as even authentic photos can sometimes exhibit inconsistent eye reflections due to varied lighting conditions or post-processing techniques. But analyzing eye reflections may still be a useful tool in a larger deepfake detection toolset that also considers other factors such as hair texture, anatomy, skin details, and background consistency.
While the technique shows promise in the short term, Dr. Pimbblet cautioned that it’s not perfect. “There are false positives and false negatives; it’s not going to get everything,” he told the Royal Astronomical Society. “But this method provides us with a basis, a plan of attack, in the arms race to detect deepfakes.”
Enlarge/ An AI-generated image created using Stable Diffusion 3 of a girl lying in the grass.
On Wednesday, Stability AI released weights for Stable Diffusion 3 Medium, an AI image-synthesis model that turns text prompts into AI-generated images. Its arrival has been ridiculed online, however, because it generates images of humans in a way that seems like a step backward from other state-of-the-art image-synthesis models like Midjourney or DALL-E 3. As a result, it can churn out wild anatomically incorrect visual abominations with ease.
Hands have traditionally been a challenge for AI image generators due to lack of good examples in early training data sets, but more recently, several image-synthesis models seemed to have overcome the issue. In that sense, SD3 appears to be a huge step backward for the image-synthesis enthusiasts that gather on Reddit—especially compared to recent Stability releases like SD XL Turbo in November.
“It wasn’t too long ago that StableDiffusion was competing with Midjourney, now it just looks like a joke in comparison. At least our datasets are safe and ethical!” wrote one Reddit user.
An AI-generated image created using Stable Diffusion 3 Medium.
An AI-generated image created using Stable Diffusion 3 of a girl lying in the grass.
An AI-generated image created using Stable Diffusion 3 that shows mangled hands.
An AI-generated image created using Stable Diffusion 3 of a girl lying in the grass.
An AI-generated image created using Stable Diffusion 3 that shows mangled hands.
An AI-generated SD3 Medium image a Reddit user made with the prompt “woman wearing a dress on the beach.”
An AI-generated SD3 Medium image a Reddit user made with the prompt “photograph of a person napping in a living room.”
AI image fans are so far blaming the Stable Diffusion 3’s anatomy fails on Stability’s insistence on filtering out adult content (often called “NSFW” content) from the SD3 training data that teaches the model how to generate images. “Believe it or not, heavily censoring a model also gets rid of human anatomy, so… that’s what happened,” wrote one Reddit user in the thread.
Basically, any time a user prompt homes in on a concept that isn’t represented well in the AI model’s training dataset, the image-synthesis model will confabulate its best interpretation of what the user is asking for. And sometimes that can be completely terrifying.
The release of Stable Diffusion 2.0 in 2022 suffered from similar problems in depicting humans well, and AI researchers soon discovered that censoring adult content that contains nudity can severely hamper an AI model’s ability to generate accurate human anatomy. At the time, Stability AI reversed course with SD 2.1 and SD XL, regaining some abilities lost by strongly filtering NSFW content.
Another issue that can occur during model pre-training is that sometimes the NSFW filter researchers use remove adult images from the dataset is too picky, accidentally removing images that might not be offensive and depriving the model of depictions of humans in certain situations. “[SD3] works fine as long as there are no humans in the picture, I think their improved nsfw filter for filtering training data decided anything humanoid is nsfw,” wrote one Redditor on the topic.
Using a free online demo of SD3 on Hugging Face, we ran prompts and saw similar results to those being reported by others. For example, the prompt “a man showing his hands” returned an image of a man holding up two giant-sized backward hands, although each hand at least had five fingers.
A SD3 Medium example we generated with the prompt “A woman lying on the beach.”
A SD3 Medium example we generated with the prompt “A man showing his hands.”
Stability AI
A SD3 Medium example we generated with the prompt “A woman showing her hands.”
Stability AI
A SD3 Medium example we generated with the prompt “a muscular barbarian with weapons beside a CRT television set, cinematic, 8K, studio lighting.”
A SD3 Medium example we generated with the prompt “A cat in a car holding a can of beer.”
Stability first announced Stable Diffusion 3 in February, and the company has planned to make it available in a variety of different model sizes. Today’s release is for the “Medium” version, which is a 2 billion-parameter model. In addition to the weights being available on Hugging Face, they are also available for experimentation through the company’s Stability Platform. The weights are available for download and use for free under a non-commercial license only.
Soon after its February announcement, delays in releasing the SD3 model weights inspired rumors that the release was being held back due to technical issues or mismanagement. Stability AI as a company fell into a tailspin recently with the resignation of its founder and CEO, Emad Mostaque, in March and then a series of layoffs. Just prior to that, three key engineers—Robin Rombach, Andreas Blattmann, and Dominik Lorenz—left the company. And its troubles go back even farther, with news of the company’s dire financial position lingering since 2023.
To some Stable Diffusion fans, the failures with Stable Diffusion 3 Medium are a visual manifestation of the company’s mismanagement—and an obvious sign of things falling apart. Although the company has not filed for bankruptcy, some users made dark jokes about the possibility after seeing SD3 Medium:
“I guess now they can go bankrupt in a safe and ethically [sic] way, after all.”
Enlarge/ A sample image from Microsoft for “VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time.”
On Tuesday, Microsoft Research Asia unveiled VASA-1, an AI model that can create a synchronized animated video of a person talking or singing from a single photo and an existing audio track. In the future, it could power virtual avatars that render locally and don’t require video feeds—or allow anyone with similar tools to take a photo of a person found online and make them appear to say whatever they want.
“It paves the way for real-time engagements with lifelike avatars that emulate human conversational behaviors,” reads the abstract of the accompanying research paper titled, “VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time.” It’s the work of Sicheng Xu, Guojun Chen, Yu-Xiao Guo, Jiaolong Yang, Chong Li, Zhenyu Zang, Yizhong Zhang, Xin Tong, and Baining Guo.
The VASA framework (short for “Visual Affective Skills Animator”) uses machine learning to analyze a static image along with a speech audio clip. It is then able to generate a realistic video with precise facial expressions, head movements, and lip-syncing to the audio. It does not clone or simulate voices (like other Microsoft research) but relies on an existing audio input that could be specially recorded or spoken for a particular purpose.
Microsoft claims the model significantly outperforms previous speech animation methods in terms of realism, expressiveness, and efficiency. To our eyes, it does seem like an improvement over single-image animating models that have come before.
AI research efforts to animate a single photo of a person or character extend back at least a few years, but more recently, researchers have been working on automatically synchronizing a generated video to an audio track. In February, an AI model called EMO: Emote Portrait Alive from Alibaba’s Institute for Intelligent Computing research group made waves with a similar approach to VASA-1 that can automatically sync an animated photo to a provided audio track (they call it “Audio2Video”).
Trained on YouTube clips
Microsoft Researchers trained VASA-1 on the VoxCeleb2 dataset created in 2018 by three researchers from the University of Oxford. That dataset contains “over 1 million utterances for 6,112 celebrities,” according to the VoxCeleb2 website, extracted from videos uploaded to YouTube. VASA-1 can reportedly generate videos of 512×512 pixel resolution at up to 40 frames per second with minimal latency, which means it could potentially be used for realtime applications like video conferencing.
To show off the model, Microsoft created a VASA-1 research page featuring many sample videos of the tool in action, including people singing and speaking in sync with pre-recorded audio tracks. They show how the model can be controlled to express different moods or change its eye gaze. The examples also include some more fanciful generations, such as Mona Lisa rapping to an audio track of Anne Hathaway performing a “Paparazzi” song on Conan O’Brien.
The researchers say that, for privacy reasons, each example photo on their page was AI-generated by StyleGAN2 or DALL-E 3 (aside from the Mona Lisa). But it’s obvious that the technique could equally apply to photos of real people as well, although it’s likely that it will work better if a person appears similar to a celebrity present in the training dataset. Still, the researchers say that deepfaking real humans is not their intention.
“We are exploring visual affective skill generation for virtual, interactive charactors [sic], NOT impersonating any person in the real world. This is only a research demonstration and there’s no product or API release plan,” reads the site.
While the Microsoft researchers tout potential positive applications like enhancing educational equity, improving accessibility, and providing therapeutic companionship, the technology could also easily be misused. For example, it could allow people to fake video chats, make real people appear to say things they never actually said (especially when paired with a cloned voice track), or allow harassment from a single social media photo.
Right now, the generated video still looks imperfect in some ways, but it could be fairly convincing for some people if they did not know to expect an AI-generated animation. The researchers say they are aware of this, which is why they are not openly releasing the code that powers the model.
“We are opposed to any behavior to create misleading or harmful contents of real persons, and are interested in applying our technique for advancing forgery detection,” write the researchers. “Currently, the videos generated by this method still contain identifiable artifacts, and the numerical analysis shows that there’s still a gap to achieve the authenticity of real videos.”
VASA-1 is only a research demonstration, but Microsoft is far from the only group developing similar technology. If the recent history of generative AI is any guide, it’s potentially only a matter of time before similar technology becomes open source and freely available—and they will very likely continue to improve in realism over time.
On Monday, Bloomberg reported that Apple is in talks to license Google’s Gemini model to power AI features like Siri in a future iPhone software update coming later in 2024, according to people familiar with the situation. Apple has also reportedly conducted similar talks with ChatGPT maker OpenAI.
The potential integration of Google Gemini into iOS 18 could bring a range of new cloud-based (off-device) AI-powered features to Apple’s smartphone, including image creation or essay writing based on simple prompts. However, the terms and branding of the agreement have not yet been finalized, and the implementation details remain unclear. The companies are unlikely to announce any deal until Apple’s annual Worldwide Developers Conference in June.
Gemini could also bring new capabilities to Apple’s widely criticized voice assistant, Siri, which trails newer AI assistants powered by large language models (LLMs) in understanding and responding to complex questions. Rumors of Apple’s own internal frustration with Siri—and potential remedies—have been kicking around for some time. In January, 9to5Mac revealed that Apple had been conducting tests with a beta version of iOS 17.4 that used OpenAI’s ChatGPT API to power Siri.
As we have previously reported, Apple has also been developing its own AI models, including a large language model codenamed Ajax and a basic chatbot called Apple GPT. However, the company’s LLM technology is said to lag behind that of its competitors, making a partnership with Google or another AI provider a more attractive option.
Google launched Gemini, a language-based AI assistant similar to ChatGPT, in December and has updated it several times since. Many industry experts consider the larger Gemini models to be roughly as capable as OpenAI’s GPT-4 Turbo, which powers the subscription versions of ChatGPT. Until just recently, with the emergence of Gemini Ultra and Claude 3, OpenAI’s top model held a fairly wide lead in perceived LLM capability.
The potential partnership between Apple and Google could significantly impact the AI industry, as Apple’s platform represents more than 2 billion active devices worldwide. If the agreement gets finalized, it would build upon the existing search partnership between the two companies, which has seen Google pay Apple billions of dollars annually to make its search engine the default option on iPhones and other Apple devices.
However, Bloomberg reports that the potential partnership between Apple and Google is likely to draw scrutiny from regulators, as the companies’ current search deal is already the subject of a lawsuit by the US Department of Justice. The European Union is also pressuring Apple to make it easier for consumers to change their default search engine away from Google.
With so much potential money on the line, selecting Google for Apple’s cloud AI job could potentially be a major loss for OpenAI in terms of bringing its technology widely into the mainstream—with a market representing billions of users. Even so, any deal with Google or OpenAI may be a temporary fix until Apple can get its own LLM-based AI technology up to speed.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}