Stewart Cheifet, the television producer and host who documented the personal computer revolution for nearly two decades on PBS, died on December 28, 2025, at age 87 in Philadelphia. Cheifet created and hosted Computer Chronicles, which ran on the public television network from 1983 to 2002 and helped demystify a new tech medium for millions of American viewers.
Computer Chronicles covered everything from the earliest IBM PCs and Apple Macintosh models to the rise of the World Wide Web and the dot-com boom. Cheifet conducted interviews with computing industry figures, including Bill Gates, Steve Jobs, and Jeff Bezos, while demonstrating hardware and software for a general audience.
From 1983 to 1990, he co-hosted the show with Gary Kildall, the Digital Research founder who created the popular CP/M operating system that predated MS-DOS on early personal computer systems.
From 1996 to 2002, Cheifet also produced and hosted Net Cafe, a companion series that documented the early Internet boom and introduced viewers to then-new websites like Yahoo, Google, and eBay.
A legacy worth preserving
Computer Chronicles began as a local weekly series in 1981 when Cheifet served as station manager at KCSM-TV, the College of San Mateo’s public television station. It became a national PBS series in 1983 and ran continuously until 2002, producing 433 episodes across 19 seasons. The format remained consistent throughout: product demonstrations, guest interviews, and a closing news segment called “Random Access” that covered industry developments.
After the show’s run ended and Cheifet left television production, he worked to preserve the show’s legacy as a consultant for the Internet Archive, helping to make publicly available the episodes of Computer Chronicles and Net Cafe.
“We survived, but it wiped out the library,” Internet Archive’s founder says.
Internet Archive founder Brewster Kahle celebrates 1 trillion web pages on stage with staff. Credit: via the Internet Archive
This month, the Internet Archive’s Wayback Machine archived its trillionth webpage, and the nonprofit invited its more than 1,200 library partners and 800,000 daily users to join a celebration of the moment. To honor “three decades of safeguarding the world’s online heritage,” the city of San Francisco declared October 22 to be “Internet Archive Day.” The Archive was also recently designated a federal depository library by Sen. Alex Padilla (D-Calif.), who proclaimed the organization a “perfect fit” to expand “access to federal government publications amid an increasingly digital landscape.”
The Internet Archive might sound like a thriving organization, but it only recently emerged from years of bruising copyright battles that threatened to bankrupt the beloved library project. In the end, the fight led to more than 500,000 books being removed from the Archive’s “Open Library.”
“We survived,” Internet Archive founder Brewster Kahle told Ars. “But it wiped out the Library.”
An Internet Archive spokesperson confirmed to Ars that the archive currently faces no major lawsuits and no active threats to its collections. Kahle thinks “the world became stupider” when the Open Library was gutted—but he’s moving forward with new ideas.
History of the Internet Archive
Kahle has been striving since 1996 to transform the Internet Archive into a digital Library of Alexandria—but “with a better fire protection plan,” joked Kyle Courtney, a copyright lawyer and librarian who leads the nonprofit eBook Study Group, which helps states update laws to protect libraries.
When the Wayback Machine was born in 2001 as a way to take snapshots of the web, Kahle told The New York Times that building free archives was “worth it.” He was also excited that the Wayback Machine had drawn renewed media attention to libraries.
At the time, law professor Lawrence Lessig predicted that the Internet Archive would face copyright battles, but he also believed that the Wayback Machine would change the way the public understood copyright fights.
”We finally have a clear and tangible example of what’s at stake,” Lessig told the Times. He insisted that Kahle was “defining the public domain” online, which would allow Internet users to see ”how easy and important” the Wayback Machine “would be in keeping us sane and honest about where we’ve been and where we’re going.”
Kahle suggested that IA’s legal battles weren’t with creators or publishers so much as with large media companies that he thinks aren’t “satisfied with the restriction you get from copyright.”
“They want that and more,” Kahle said, pointing to e-book licenses that expire as proof that libraries increasingly aren’t allowed to own their collections. He also suspects that such companies wanted the Wayback Machine dead—but the Wayback Machine has survived and proved itself to be a unique and useful resource.
The Internet Archive also began archiving—and then lending—e-books. For a decade, the Archive had loaned out individual e-books to one user at a time without triggering any lawsuits. That changed when IA decided to temporarily lift the cap on loans from its Open Library project to create a “National Emergency Library” as libraries across the world shut down during the early days of the COVID-19 pandemic. The project eventually grew to 1.4 million titles.
But lifting the lending restrictions also brought more scrutiny from copyright holders, who eventually sued the Archive. Litigation went on for years. In 2024, IA lost its final appeal in a lawsuit brought by book publishers over the Archive’s Open Library project, which used a novel e-book lending model to bypass publishers’ licensing fees and checkout limitations. Damages could have topped $400 million, but publishers ultimately announced a “confidential agreement on a monetary payment” that did not bankrupt the Archive.
Litigation has continued, though. More recently, the Archive settled another suit over its Great 78 Project after music publishers sought damages of up to $700 million. A settlement in that case, reached last month, was similarly confidential. In both cases, IA’s experts challenged publishers’ estimates of their losses as massively inflated.
To Kahle, the suits have been an immense setback to IA’s mission.
Publishers had argued that the Open Library’s lending harmed the e-book market, but IA says its vision for the project was not to frustrate e-book sales (which it denied its library does) but to make it easier for researchers to reference e-books by allowing Wikipedia to link to book scans. Wikipedia has long been one of the most visited websites in the world, and the Archive wanted to deepen its authority as a research tool.
“One of the real purposes of libraries is not just access to information by borrowing a book that you might buy in a bookstore,” Kahle said. “In fact, that’s actually the minority. Usually, you’re comparing and contrasting things. You’re quoting. You’re checking. You’re standing on the shoulders of giants.”
Meredith Rose, senior policy counsel for Public Knowledge, told Ars that the Internet Archive’s Wikipedia enhancements could have served to surface information that’s often buried in books, giving researchers a streamlined path to source accurate information online.
But Kahle said the lawsuits against IA showed that “massive multibillion-dollar media conglomerates” have their own interests in controlling the flow of information. “That’s what they really succeeded at—to make sure that Wikipedia readers don’t get access to books,” Kahle said.
At the heart of the Open Library lawsuit was publishers’ market for e-book licenses, which libraries complain provide only temporary access for a limited number of patrons and cost substantially more than the acquisition of physical books. Some states are crafting laws to restrict e-book licensing, with the aim of preserving library functions.
“We don’t want libraries to become Hulu or Netflix,” said Courtney of the eBook Study Group, posting warnings to patrons like “last day to check out this book, August 31st, then it goes away forever.”
He, like Kahle, is concerned that libraries will become unable to fulfill their longtime role—preserving culture and providing equal access to knowledge. Remote access, Courtney noted, benefits people who can’t easily get to libraries, like the elderly, people with disabilities, rural communities, and foreign-deployed troops.
Before the Internet Archive cases, libraries had won some important legal fights, according to Brandon Butler, a copyright lawyer and executive director of Re:Create, a coalition of “libraries, civil libertarians, online rights advocates, start-ups, consumers, and technology companies” that is “dedicated to balanced copyright and a free and open Internet.”
But the Internet Archive’s e-book fight didn’t set back libraries, Butler said, because the loss didn’t reverse any prior court wins. Instead, IA had been “exploring another frontier” beyond the Google Books ruling, which deemed Google’s searchable book excerpts a transformative fair use, hoping that linking to books from Wikipedia would also be deemed fair use. But IA “hit the edge” of what courts would allow, Butler said.
IA basically asked, “Could fair use go this much farther?” Butler said. “And the courts said, ‘No, this is as far as you go.’”
To Kahle, the cards feel stacked against the Internet Archive, with courts, lawmakers, and lobbyists backing corporations seeking “hyper levels of control.” He said IA has always served as a research library—an online destination where people can cross-reference texts and verify facts, just like perusing books at a local library.
“We’re just trying to be a library,” Kahle said. “A library in a traditional sense. And it’s getting hard.”
Fears of big fines may delay digitization projects
President Donald Trump’s cuts to the federal Institute of Museum and Library Services have put America’s public libraries at risk, and reduced funding will continue to challenge libraries in the coming years, ALA has warned. Butler has also suggested that under-resourced libraries may delay digitization efforts for preservation purposes if they worry that publishers may threaten costly litigation.
He told Ars he thinks courts are getting it right on recent fair use rulings. But he noted that libraries have fewer resources for legal fights because copyright law “has this provision that says, well, if you’re a copyright holder, you really don’t have to prove that you suffered any harm at all.”
“You can just elect [to receive] a massive payout based purely on the fact that you hold a copyright and somebody infringed,” Butler said. “And that’s really unique. Almost no other country in the world has that sort of a system.”
So while companies like AI firms may be able to afford legal fights with rights holders, libraries must be careful, even when they launch projects that seem “completely harmless and innocuous,” Butler said. Consider the Internet Archive’s Great 78 Project, which digitized 400,000 old shellac records, known as 78s, that were originally pressed from 1898 to the 1950s.
“The idea that somebody’s going to stream a 78 of an Elvis song instead of firing it up on their $10-a-month Spotify subscription is silly, right?” Butler said. “It doesn’t pass the laugh test, but given the scale of the project—and multiply that by the statutory damages—and that makes this an extremely dangerous project all of a sudden.”
Butler suggested that statutory damages could disrupt the balance that ensures the public has access to knowledge, creators get paid, and human creativity thrives, as AI advances and libraries’ growth potentially stalls.
“It sets the risk so high that it may force deals in situations where it would be better if people relied on fair use. Or it may scare people from trying new things because of the stakes of a copyright lawsuit,” Butler said.
Courtney, who co-wrote a whitepaper detailing the legal basis for different forms of “controlled digital lending” like the Open Library project uses, suggested that Kahle may be the person who’s best prepared to push the envelope on copyright.
When asked how the Internet Archive managed to avoid financial ruin, Courtney said it survived “only because their leader” is “very smart and capable.” Of all the “flavors” of controlled digital lending (CDL) that his paper outlined, Kahle’s methodology for the Open Library Project was the most “revolutionary,” Courtney said.
Importantly, IA’s loss did not doom other kinds of CDL that other archives use, he noted, nor did it prevent libraries from trying new things.
“Fair use is a case-by-case determination” that will be made as urgent preservation needs arise, Courtney told Ars, and “libraries have a ton of stuff that aren’t going to make the jump to digital unless we digitize them. No one will have access to them.”
What’s next for the Internet Archive?
The lawsuits haven’t dampened Kahle’s resolve to expand IA’s digitization efforts, though. Moving forward, the group will be growing a project called Democracy’s Library, which is “a free, open, online compendium of government research and publications from around the world” that will be conveniently linked in Wikipedia articles to help researchers discover them.
The Archive is also collecting as many physical materials as possible to help preserve knowledge, even as “the library system is largely contracting,” Kahle said. He noted that libraries historically tend to grow in societies that prioritize education and decline in societies where power is being concentrated, and he’s worried about where the US is headed. That makes it hard to predict if IA—or any library project—will be supported in the long term.
Meanwhile, AI firms face dozens of lawsuits from creators and publishers, which Kahle thinks only the biggest tech companies can likely afford to outlast. The momentum behind AI risks giving corporations even more control over information, Kahle said, and it’s uncertain if archives dedicated to preserving the public memory will survive attacks from multiple fronts.
“Societies that are [growing] are the ones that need to educate people” and therefore promote libraries, Kahle said. But when societies are “going down,” such as in times of war, conflict, and social upheaval, libraries “tend to get destroyed by the powerful. It used to be king and church, and it’s now corporations and governments.” (He recommended The Library: A Fragile History as a must-read to understand the challenges libraries have always faced.)
Kahle told Ars he’s not “black and white” on AI, and he even sees some potential for AI to enhance library services.
He’s more concerned that libraries in the US are losing support and may soon cease to perform classic functions that have always benefited civilizations—like buying books from small publishers and local authors, supporting intellectual endeavors, and partnering with other libraries to expand access to diverse collections.
To prevent these cultural and intellectual losses, he plans to position IA as a refuge for displaced collections, with hopes to digitize as much as possible while defending the early dream that the Internet could equalize access to information and supercharge progress.
“We want everyone [to be] a reader,” Kahle said, and that means “we want lots of publishers, we want lots of vendors, booksellers, lots of libraries.”
But, he asked, “Are we going that way? No.”
To turn things around, Kahle suggested that copyright laws be “re-architected” to ensure “we have a game with many winners”—where authors, publishers, and booksellers get paid, library missions are respected, and progress thrives. Then society can figure out “what do we do with this new set of AI tools” to keep the engine of human creativity humming.
Ashley is a senior policy reporter for Ars Technica, dedicated to tracking social impacts of emerging policies and new technologies. She is a Chicago-based journalist with 20 years of experience.
A settlement has been reached in a lawsuit where music publishers sued the Internet Archive over the Great 78 Project, an effort to preserve early music recordings that only exist on brittle shellac records.
No details of the settlement have so far been released, but a court filing on Monday confirmed that the Internet Archive and UMG Recordings, Capitol Records, Sony Music Entertainment, and other record labels “have settled this matter.” More details may come in the next 45 days, when parties must submit filings to officially dismiss the lawsuit, but it’s unlikely the settlement amount will be publicly disclosed.
Days before the settlement was announced, record labels had indicated that everyone but the Internet Archive and its founder, Brewster Kahle, had agreed to sign a joint settlement, seemingly including the Great 78 Project’s recording engineer George Blood, who was also a target of the litigation. But in the days since, IA has gotten on board, posting a blog confirming that “the parties have reached a confidential resolution of all claims and will have no further public comment on this matter.”
But despite IA arguing that there were comparably low downloads and streams on the Great 78 recordings—as well as a music publishing industry vet suggesting that damages were likely no more than $41,000—the labels intensified their attacks in March. In a court filing, the labels added so many more infringing works that the estimated damages increased to $700 million. It seemed like labels were intent on doubling down on a fight that, at least one sound historian suggested, the labels might one day regret.
“Until they’re able to defend their site and comply with platform policies (e.g., respecting user privacy, re: deleting removed content) we’re limiting some of their access to Reddit data to protect redditors,” Rathschmidt said.
A review of social media comments suggests that in the past, some Redditors have used the Wayback Machine to research deleted comments or threads. Those commenters noted that myriad other tools exist for surfacing deleted posts or researching a user’s activity, with some suggesting that the Wayback Machine was maybe not the easiest platform to navigate for that purpose.
Redditors have also turned to resources like IA during times when Reddit’s platform changes trigger content removals. Most recently in 2023, when changes to Reddit’s public API threatened to kill beloved subreddits, archives stepped in to preserve content before it was lost.
IA has not signaled whether it’s looking into fixes to get Reddit’s restrictions lifted and did not respond to Ars’ request to comment on how this change might impact the archive’s utility as an open web resource, given Reddit’s popularity.
The director of the Wayback Machine, Mark Graham, told Ars that IA has “a longstanding relationship with Reddit” and continues to have “ongoing discussions about this matter.”
It seems likely that Reddit is financially motivated to restrict AI firms from taking advantage of Wayback Machine archives, perhaps hoping to spur more lucrative licensing deals like Reddit struck with OpenAI and Google. The terms of the OpenAI deal were kept quiet, but the Google deal was reportedly worth $60 million. Over the next three years, Reddit expects to make more than $200 million off such licensing deals.
Disclosure: Advance Publications, which owns Ars Technica parent Condé Nast, is the largest shareholder in Reddit.
But David Seubert, who manages sound collections at the University of California, Santa Barbara library, told Ars that he frequently used the project as an archive and not just to listen to the recordings.
For Seubert, the videos that IA records of the 78 RPM albums capture more than audio of a certain era. Researchers like him want to look at the label, check out the copyright information, and note the catalogue numbers, he said.
“It has all this information there,” Seubert said. “I don’t even necessarily need to hear it,” he continued, adding, “just seeing the physicality of it, it’s like, ‘Okay, now I know more about this record.'”
Music publishers suing IA argue that all the songs included in their dispute—and likely many more, since the Great 78 Project spans 400,000 recordings—”are already available for streaming or downloading from numerous services.”
“These recordings face no danger of being lost, forgotten, or destroyed,” their filing claimed.
But Nathan Georgitis, the executive director of the Association for Recorded Sound Collections (ARSC), told Ars that you just don’t see 78 RPM records out in the world anymore. Even in record stores selling used vinyl, these recordings will be hidden “in a few boxes under the table behind the tablecloth,” Georgitis suggested. And in “many” cases, “the problem for libraries and archives is that those recordings aren’t necessarily commercially available for re-release.”
That “means that those recordings, those artists, the repertoire, the recorded sound history in itself—meaning the labels, the producers, the printings—all of that history kind of gets obscured from view,” Georgitis said.
Currently, libraries trying to preserve this history must control access to audio collections, Georgitis said. He sees IA’s work with the Great 78 Project as a legitimate archive in that, unlike a streaming service, where content may be inconsistently available, IA’s “mission is to preserve and provide access to content over time.”
Internet Archive makes it easier to track changes in CDC data online.
When thousands of pages started disappearing from the Centers for Disease Control and Prevention (CDC) website late last week, public health researchers quickly moved to archive deleted public health data.
Soon, researchers discovered that the Internet Archive (IA) offers one of the most effective ways to both preserve online data and track changes on government websites. For decades, IA crawlers have collected snapshots of the public Internet, making it easier to compare current versions of websites to historic versions. And IA also allows users to upload digital materials to further expand the web archive. Both aspects of the archive immediately proved useful to researchers assessing how much data the public risked losing during a rapid purge following a pair of President Trump’s executive orders.
Part of a small group of researchers who managed to download the entire CDC website within days, virologist Angela Rasmussen helped create a public resource that combines CDC website information with deleted CDC datasets. Those datasets, many of which were previously in the public domain for years, were uploaded to IA by an anonymous user, “SheWhoExists,” on January 31. Moving forward, Rasmussen told Ars that IA will likely remain a go-to tool for researchers attempting to closely monitor for any unexpected changes in access to public data.
IA “continually updates their archives,” Rasmussen said, which makes IA “a good mechanism for tracking modifications to these websites that haven’t been made yet.”
Additionally, “the Office of Personnel Management has provided initial guidance on both Executive Orders and HHS and divisions are acting accordingly to execute,” the CDC told Ars.
Rasmussen told Ars that the deletion of CDC datasets is “extremely alarming” and “not normal.” While some deleted pages have since been restored in altered versions, removing gender ideology from CDC guidance could put Americans at heightened risk. That’s another emerging problem that IA’s snapshots could help researchers and health professionals resolve.
“I think the average person probably doesn’t think that much about the CDC’s website, but it’s not just a matter of like, ‘Oh, we’re going to change some wording’ or ‘we’re going to remove these data,” Rasmussen said. “We are actually going to retool all the information that’s there to remove critical information about public health that could actually put people in danger.”
For example, altered Mpox transmission data removed “all references to men who have sex with men,” Rasmussen said. “And in the US those are the people who are not the only people at risk, but they’re the people who are most at risk of being exposed to Mpox. So, by removing that DEI language, you’re actually depriving people who are at risk of information they could use to protect themselves, and that eventually will get people hurt or even killed.”
Likely the biggest frustration for researchers scrambling to preserve data is dealing with broken links. On social media, Rasmussen has repeatedly called for help flagging broken links to ensure her team’s archive is as useful as possible.
Rasmussen’s group isn’t the only effort to preserve the CDC data. Some are creating niche archives focused on particular topics, like journalist Jessica Valenti, who created an archive of CDC guidelines on reproductive rights issues, sexual health, intimate partner violence, and other data the CDC removed online.
Niche archives could make it easier for some researchers to quickly survey missing data in their field, but Rasmussen’s group is hoping to take next steps to make all the missing CDC data more easily discoverable in their archive.
“I think the next step,” Rasmussen said, “would be to try to fix anything in there that’s broken, but also look into ways that we could maybe make it more browsable and user-friendly for people who may not know what they’re looking for or may not be able to find what they’re looking for.”
CDC advisers demand answers
The CDC has been largely quiet about the deleted data, only pointing to Trump’s executive orders to justify removals. That could change by February 7. That’s the deadline when a congressionally mandated advisory committee to the CDC’s acting director, Susan Monarez, asked for answers in an open letter to a list of questions about the data removals.
“It has been reported through anonymous sources that the website changes are related to new executive orders that ban the use of specific words and phrases,” their letter said. “But as far as we are aware, these unprecedented actions have yet to be explained by CDC; news stories indicate that the agency is declining to comment.”
At the top of the committee’s list of questions is likely the one frustrating researchers most: “What was the rationale for making these datasets and websites inaccessible to the public?” But the committee also importantly asked what analysis was done “of the consequences of removing access to these datasets and website” prior to the removals. They also asked how deleted data would be safeguarded and when data would be restored.
It’s unclear if the CDC will be motivated to respond by the deadline. Ars reached out to one of the committee members, Joshua Sharfstein—a physician and vice dean for Public Health Practice and Community Engagement at Johns Hopkins University—who confirmed that as of this writing, the CDC has not yet responded. And the CDC did not respond to Ars’ request to comment on the letter.
Rasmussen told Ars that even temporary removals of CDC guidance can disrupt important processes keeping Americans healthy. Among the potentially most consequential pages briefly removed were recommendations from the congressionally mandated Advisory Committee on Immunization Practices (ACIP).
Those recommendations are used by insurance companies to decide who gets reimbursed for vaccines and by physicians to deduce vaccine eligibility, and Rasmussen said they “are incredibly important for the entire population to have access to any kind of vaccination.” And while, for example, the Mpox vaccine recommendations were eventually restored unaltered, Rasmussen told Ars that she suspects that “one of the reasons” preventing interference currently with ACIP is that it’s mandated by Congress.
Seemingly ACIP could be weakened by the new administration, Rasmussen suggested. She warned that Trump’s pick for CDC director, Dave Weldon, “is an anti-vaxxer” (with a long history of falsely linking vaccines to autism) who may decide to replace ACIP committee members with anti-vaccine advocates or move to dissolve ACIP. And any changes in recommendations could mean “insurance companies aren’t going to cover vaccinations [and that] physicians will not recommend vaccination.” And that could mean “vaccination will go down and we’ll start having outbreaks of some of these vaccine-preventable diseases.”
“If there’s a big polio outbreak, that is going to result in permanently disabled children, dead children—it’s really, really serious,” Rasmussen said. “So I think that people need to understand that this isn’t just like, ‘Oh, maybe wear a mask when you’re at the movie theater’ kind of CDC guidance. This is guidance that’s really fundamental to our most basic public health practices, and it’s going to cause widespread suffering and death if this is allowed to continue.”
Seeding deleted data and doing science to fight back
On Bluesky, Rasmussen led one of many charges to compile archived links and download CDC data so that researchers can reference every available government study when advancing public health knowledge.
“These data are public and they are ours,” Rasmussen posted. “Deletion disobedience is one way to fight back.”
As Rasmussen sees it, deleting CDC data is “theft” from the public domain and archiving CDC data is simply taking “back what is ours.” But at the same time, her team is also taking steps to be sure the data they collected can be lawfully preserved. Because the CDC website has not been copied and hosted on a server, they expect their archive should be deemed lawful and remain online.
“I don’t put it past this administration to try to shut this stuff down by any means possible,” Rasmussen told Ars. “And we wanted to make sure there weren’t any sort of legal loopholes that would jeopardize anybody in the group, but also that would potentially jeopardize the data.”
It’s not clear if some data has already been lost. Seemingly the same user who uploaded the deleted datasets to IA posted on Reddit, clarifying that while the “full” archive “should contain all public datasets that were available” before “anything was scrubbed,” it likely only includes “most” of the “metadata and attachments.” So, researchers who download the data may still struggle to fill in some blanks.
To help researchers quickly access the missing data, anyone can help the IA seed the datasets, the Reddit user said in another post providing seeding and mirroring instructions. Currently dozens are seeding it for a couple hundred peers.
“Thank you to everyone who requested this important data, and particularly to those who have offered to mirror it,” the Reddit user wrote.
As Rasmussen works with her group to make their archive more user-friendly, her plan is to help as many researchers as possible fight back against data deletion by continuing to reference deleted data in their research. She suggested that effort—doing science that ignores Trump’s executive orders—is perhaps a more powerful way to resist and defend public health data than joining in loud protests, which many researchers based in the US (and perhaps relying on federal funding) may not be able to afford to do.
“Just by doing things and standing up for science with your actions, rather than your words, you can really make, I think, a big difference,” Rasmussen said.
Ashley is a senior policy reporter for Ars Technica, dedicated to tracking social impacts of emerging policies and new technologies. She is a Chicago-based journalist with 20 years of experience.
Last week, hackers defaced the Internet Archive website with a message that said, “Have you ever felt like the Internet Archive runs on sticks and is constantly on the verge of suffering a catastrophic security breach? It just happened. See 31 million of you on HIBP!”
HIBP is a reference to Have I Been Pwned, which was created by security researcher Troy Hunt and provides information and notifications on data breaches. The hacked Internet Archive data was sent to Have I Been Pwned and “contains authentication information for registered members, including their email addresses, screen names, password change timestamps, Bcrypt-hashed passwords, and other internal data,” BleepingComputer wrote.
Kahle said on October 9 that the Internet Archive fended off a DDoS attack and was working on upgrading security in light of the data breach and website defacement. The next day, he reported that the “DDoS folks are back” and had knocked the site offline. The Internet Archive “is being cautious and prioritizing keeping data safe at the expense of service availability,” he added.
“Services are offline as we examine and strengthen them… Estimated Timeline: days, not weeks,” he wrote on October 11. “Thank you for the offers of pizza (we are set).”
Judges for the Second Circuit Court of Appeals on Wednesday rejected the Internet Archive (IA) argument that its controlled digital lending—which allows only one person to borrow each scanned e-book at a time—was a transformative fair use that worked like a traditional library and did not violate copyright law.
As Judge Beth Robinson wrote in the decision, because the IA’s digital copies of books did not “provide criticism, commentary, or information about the originals” or alter the original books to add “something new,” the court concluded that the IA’s use of publishers’ books was not transformative, hobbling the organization’s fair use defense.
“IA’s digital books serve the same exact purpose as the originals: making authors’ works available to read,” Robinson said, emphasizing that although in copyright law, “[n]ot every instance will be clear cut,” “this one is.”
The appeals court ruling affirmed the lower court’s ruling, which permanently barred the IA from distributing not just the works in the suit, but all books “available for electronic licensing,” Robinson said.
“To construe IA’s use of the Works as transformative would significantly narrow―if not entirely eviscerate―copyright owners’ exclusive right to prepare (or not prepare) derivative works,” Robinson wrote.
Maria Pallante, president and CEO of the Association of American Publishers, the trade organization behind the lawsuit, celebrated the ruling. She said the court upheld “the rights of authors and publishers to license and be compensated for their books and other creative works and reminds us in no uncertain terms that infringement is both costly and antithetical to the public interest.”
“If there was any doubt, the Court makes clear that under fair use jurisprudence there is nothing transformative about converting entire works into new formats without permission or appropriating the value of derivative works that are a key part of the author’s copyright bundle,” Pallante said.
The Internet Archive’s director of library services, Chris Freeland, issued a statement on the loss, which comes after four years of fighting to maintain its Open Libraries Project.
“We are disappointed in today’s opinion about the Internet Archive’s digital lending of books that are available electronically elsewhere,” Freeland said. “We are reviewing the court’s opinion and will continue to defend the rights of libraries to own, lend, and preserve books.”
IA’s lending harmed publishers, judge says
The court’s fair use analysis didn’t solely hinge on whether IA’s digital lending of e-books was “transformative.” Judges also had to consider book publishers’ claims that IA was profiting off e-book lending, in addition to factoring in whether each work was original, what amount of each work was being copied, and whether the IA’s e-books substituted original works, depriving authors of revenue in relevant markets.
Ultimately, for each factor, judges ruled in favor of publishers, which argued that granting IA was threatening to “‘destroy the value of [their] exclusive right to prepare derivative works,’ including the right to publish their authors’ works as e-books.”
While the IA tried to argue that book publishers’ surging profits suggested that its digital lending caused no market harms, Robinson disagreed with the IA’s experts’ “ill-supported” market analysis and took issue with IA advertising “its digital books as a free alternative to Publishers’ print and e-books.”
“IA offers effectively the same product as Publishers―full copies of the Works―but at no cost to consumers or libraries,” Robinson wrote. “At least in this context, it is difficult to compete with free.”
Robinson wrote that despite book publishers showing no proof of market harms, that lack of evidence did not support IA’s case, ruling that IA did not satisfy its burden to prove it had not harmed publishers. She further wrote that it’s common sense to agree with publishers’ characterization of harms because “IA’s digital books compete directly with Publishers’ e-books” and would deprive authors of revenue if left unchecked.
“We agree with Publishers’ assessment of market harm” and “are likewise convinced” that “unrestricted and widespread conduct of the sort engaged in by [IA] would result in a substantially adverse impact on the potential market” for publishers’ e-books, Robinson wrote. “Though Publishers have not provided empirical data to support this observation, we routinely rely on such logical inferences where appropriate” when determining fair use.
Judges did, however, side with IA on the matter of whether the nonprofit was profiting off loaning e-books for free, contradicting the lower court. The appeals court disagreed with book publishers’ claims that IA profited off e-books by soliciting donations or earning a small percentage from used books sold through referral links on its site.
“Of course, IA must solicit some funds to keep the lights on,” Robinson wrote. But “IA does not profit directly from its Free Digital Library,” and it would be “misleading” to characterize it that way.
“To hold otherwise would greatly restrain the ability of nonprofits to seek donations while making fair use of copyrighted works,” Robinson wrote.
In the weeks ahead of IA’s efforts to appeal that ruling, IA was forced to remove 500,000 books from its collection, shocking users. In an open letter to publishers, more than 30,000 readers, researchers, and authors begged for access to the books to be restored in the open library, claiming the takedowns dealt “a serious blow to lower-income families, people with disabilities, rural communities, and LGBTQ+ people, among many others,” who may not have access to a local library or feel “safe accessing the information they need in public.”
During a press briefing following arguments in court Friday, IA founder Brewster Kahle said that “those voices weren’t being heard.” Judges appeared primarily focused on understanding how IA’s digital lending potentially hurts publishers’ profits in the ebook licensing market, rather than on how publishers’ costly ebook licensing potentially harms readers.
However, lawyers representing IA—Joseph C. Gratz, from the law firm Morrison Foerster, and Corynne McSherry, from the nonprofit Electronic Frontier Foundation—confirmed that judges were highly engaged by IA’s defense. Arguments that were initially scheduled to last only 20 minutes stretched on instead for an hour and a half. Ultimately, judges decided not to rule from the bench, with a decision expected in the coming months or potentially next year. McSherry said the judges’ engagement showed that the judges “get it” and won’t make the decision without careful consideration of both sides.
“They understand this is an important decision,” McSherry said. “They understand that there are real consequences here for real people. And they are taking their job very, very seriously. And I think that’s the best that we can hope for, really.”
On the other side, the Association of American Publishers (AAP), the trade organization behind the lawsuit, provided little insight into how the day went. When reached for comment, AAP simply said, “We thought it was a strong day in court, and we look forward to the opinion.”
Decision could come early fall
According to Gratz, most of the questions for IA focused on “how to think about the situation where a particular book is available” from the open library and also available as an ebook that a library can license. Judges said they did not know how to think about “a situation where the publishers just haven’t come forward with any data showing that this has an impact,” Gratz said.
One audience member at the press briefing noted that instead judges were floating hypotheticals, like “if every single person in the world made a copy of a hypothetical thing, could hypothetically this affect the publishers’ revenue.”
McSherry said this was a common tactic when judges must weigh the facts while knowing that their decision will set an important precedent. However, IA has shown evidence, Gratz said, that even if IA provided limitless loans of digitized physical copies, “CDL doesn’t cause any economic harm to publishers, or authors,” and “there was absolutely no evidence of any harm of that kind that the publishers were able to bring forward.”
McSherry said that IA pushed back on claims that IA behaves like “pirates” when digitally lending books, with critics sometimes comparing the open library to illegal file-sharing networks. Instead, McSherry said that CDL provides a path to “meet readers where they are,” allowing IA to loan books that it owns to one user at a time no matter where in the world they are located.
“It’s not unlawful for a library to lend a book it owns to one patron at a time,” Gratz said IA told the court. “And the advent of digital technology doesn’t change that result. That’s lawful. And that’s what librarians do.”
In the open letter, IA fans pointed out that many IA readers were “in underserved communities where access is limited” to quality library resources. Being suddenly cut off from accessing nearly half a million books has “far-reaching implications,” they argued, removing access to otherwise inaccessible “research materials and literature that support their learning and academic growth.”
IA has argued that because copyright law is intended to provide equal access to knowledge, copyright law is better served by allowing IA’s lending than by preventing it. They’re hoping the judges will decide that CDL is fair use, reversing the lower court’s decision and restoring access to books recently removed from the open library. But Gratz said there’s no telling yet when that decision will come.
“There is no deadline for them to make a decision,” Gratz said, but it “probably won’t happen until early fall” at the earliest. After that, whichever side loses will have an opportunity to appeal the case, which has already stretched on for four years, to the Supreme Court. Since neither side seems prepared to back down, the Supreme Court eventually weighing in seems inevitable.
McSherry seemed optimistic that the judges at least understood the stakes for IA readers, noting that fair use is “designed to ensure that copyright actually serves the public interest,” not publishers’. Should the court decide otherwise, McSherry warned, the court risks allowing “a few powerful publishers” to “hijack the future of books.”
When IA first appealed, Kahle put out a statement saying IA couldn’t walk away from “a fight to keep library books available for those seeking truth in the digital age.”
Enlarge/ Box art for IBM OS/2 Warp version 3, an OS released in 1995 that competed with Windows.
IBM
In a move that marks the end of an era, New Mexico State University (NMSU) recently announced the impending closure of its Hobbes OS/2 Archive on April 15, 2024. For over three decades, the archive has been a key resource for users of the IBM OS/2 operating system and its successors, which once competed fiercely with Microsoft Windows.
In a statement made to The Register, a representative of NMSU wrote, “We have made the difficult decision to no longer host these files on hobbes.nmsu.edu. Although I am unable to go into specifics, we had to evaluate our priorities and had to make the difficult decision to discontinue the service.”
Hobbes is hosted by the Department of Information & Communication Technologies at New Mexico State University in Las Cruces, New Mexico. In the official announcement, the site reads, “After many years of service, hobbes.nmsu.edu will be decommissioned and will no longer be available. As of April 15th, 2024, this site will no longer exist.”
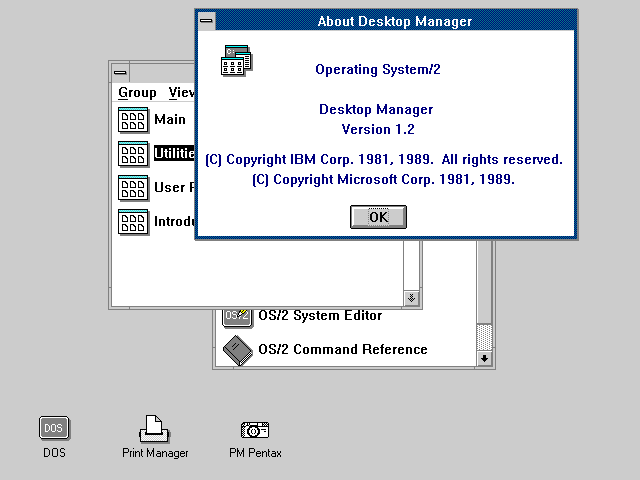
OS/2 version 1.2, released in late 1989.
os2museum.com
We reached out to New Mexico State University to inquire about the history of the Hobbes archive but did not receive a response. The earliest record we’ve found of the Hobbes archive online is this 1992 Walnut Creek CD-ROM collection that gathered up the contents of the archive for offline distribution. At around 32 years old, minimum, that makes Hobbes one of the oldest software archives on the Internet, akin to the University of Michigan’s archives and ibiblio at UNC.
Archivists such as Jason Scott of the Internet Archive have stepped up to say that the files hosted on Hobbes are safe and already mirrored elsewhere. “Nobody should worry about Hobbes, I’ve got Hobbes handled,” wrote Scott on Mastodon in early January. OS/2 World.com also published a statement about making a mirror. But it’s still notable whenever such an old and important piece of Internet history bites the dust.
Like many archives, Hobbes started as an FTP site. “The primary distribution of files on the Internet were via FTP servers,” Scott tells Ars Technica. “And as FTP servers went down, they would also be mirrored as subdirectories in other FTP servers. Companies like CDROM.COM / Walnut Creek became ways to just get a CD-ROM of the items, but they would often make the data available at http://ftp.cdrom.com to download.”
The Hobbes site is a priceless digital time capsule. You can still find the Top 50 Downloads page, which includes sound and image editors, and OS/2 builds of the Thunderbird email client. The archive contains thousands of OS/2 games, applications, utilities, software development tools, documentation, and server software dating back to the launch of OS/2 in 1987. There’s a certain charm in running across OS/2 wallpapers from 1990, and even the archive’s Update Policy is a historical gem—last updated on March 12, 1999.
The legacy of OS/2
Enlarge/ The final major IBM release of OS/2, Warp version 4.0, as seen running in an emulator.
OS/2 began as a joint venture between IBM and Microsoft, undertaken as a planned replacement for IBM PC DOS (also called “MS-DOS” in the form sold by Microsoft for PC clones). Despite advanced capabilities like 32-bit processing and multitasking, OS/2 later competed with and struggled to gain traction against Windows. The partnership between IBM and Microsoft dissolved after the success of Windows 3.0, leading to divergent paths in OS strategies for the two companies.
Through iterations like the Warp series, OS/2 established a key presence in niche markets that required high stability, such as ATMs and the New York subway system. Today, its legacy continues in specialized applications and in newer versions (like eComStation) maintained by third-party vendors—despite being overshadowed in the broader market by Linux and Windows.
A footprint like that is worth preserving, and a loss of one of OS/2’s primary archives, even if mirrored elsewhere, is a cultural blow. Apparently, Hobbes has reportedly almost disappeared before but received a stay of execution. In the comments section for an article on The Register, someone named “TrevorH” wrote, “This is not the first time that Hobbes has announced it’s going away. Last time it was rescued after a lot of complaints and a number of students or faculty came forward to continue to maintain it.”
As the final shutdown approaches in April, the legacy of Hobbes is a reminder of the importance of preserving the digital heritage of software for future generations—so that decades from now, historians can look back and see how things got to where they are today.














{kind=link}