Anthropic today released Opus 4.5, its flagship frontier model, and it brings improvements in coding performance, as well as some user experience improvements that make it more generally competitive with OpenAI’s latest frontier models.
Perhaps the most prominent change for most users is that in the consumer app experiences (web, mobile, and desktop), Claude will be less prone to abruptly hard-stopping conversations because they have run too long. The improvement to memory within a single conversation applies not just to Opus 4.5, but to any current Claude models in the apps.
Users who experienced abrupt endings (despite having room left in their session and weekly usage budgets) were hitting a hard context window (200,000 tokens). Whereas some large language model implementations simply start trimming earlier messages from the context when a conversation runs past the maximum in the window, Claude simply ended the conversation rather than allow the user to experience an increasingly incoherent conversation where the model would start forgetting things based on how old they are.
Now, Claude will instead go through a behind-the-scenes process of summarizing the key points from the earlier parts of the conversation, attempting to discard what it deems extraneous while keeping what’s important.
Developers who call Anthropic’s API can leverage the same principles through context management and context compaction.
Opus 4.5 performance
Opus 4.5 is the first model to surpass an accuracy score of 80 percent—specifically, 80.9 percent in the SWE-Bench Verified benchmark, narrowly beating OpenAI’s recently released GPT-5.1-Codex-Max (77.9 percent) and Google’s Gemini 3 Pro (76.2 percent). The model performs particularly well in agentic coding and agentic tool use benchmarks, but still lags behind GPT-5.1 in visual reasoning (MMMU).
The researchers argue that this setup lets Evo “link nucleotide-level patterns to kilobase-scale genomic context.” In other words, if you prompt it with a large chunk of genomic DNA, Evo can interpret that as an LLM would interpret a query and produce an output that, in a genomic sense, is appropriate for that interpretation.
The researchers reasoned that, given the training on bacterial genomes, they could use a known gene as a prompt, and Evo should produce an output that includes regions that encode proteins with related functions. The key question is whether it would simply output the sequences for proteins we know about already, or whether it would come up with output that’s less predictable.
Novel proteins
To start testing the system, the researchers prompted it with fragments of the genes for known proteins and determined whether Evo could complete them. In one example, if given 30 percent of the sequence of a gene for a known protein, Evo was able to output 85 percent of the rest. When prompted with 80 percent of the sequence, it could return all of the missing sequence. When a single gene was deleted from a functional cluster, Evo could also correctly identify and restore the missing gene.
The large amount of training data also ensured that Evo correctly identified the most important regions of the protein. If it made changes to the sequence, they typically resided in the areas of the protein where variability is tolerated. In other words, its training had enabled the system to incorporate the rules of evolutionary limits on changes in known genes.
So, the researchers decided to test what happened when Evo was asked to output something new. To do so, they used bacterial toxins, which are typically encoded along with an anti-toxin that keeps the cell from killing itself whenever it activates the genes. There are a lot of examples of these out there, and they tend to evolve rapidly as part of an arms race between bacteria and their competitors. So, the team developed a toxin that was only mildly related to known ones, and had no known antitoxin, and fed its sequence to Evo as a prompt. And this time, they filtered out any responses that looked similar to known antitoxin genes.
When analyzing social media posts made by others, Grok is given the somewhat contradictory instructions to “provide truthful and based insights [emphasis added], challenging mainstream narratives if necessary, but remain objective.” Grok is also instructed to incorporate scientific studies and prioritize peer-reviewed data but also to “be critical of sources to avoid bias.”
Grok’s brief “white genocide” obsession highlights just how easy it is to heavily twist an LLM’s “default” behavior with just a few core instructions. Conversational interfaces for LLMs in general are essentially a gnarly hack for systems intended to generate the next likely words to follow strings of input text. Layering a “helpful assistant” faux personality on top of that basic functionality, as most LLMs do in some form, can lead to all sorts of unexpected behaviors without careful additional prompting and design.
The 2,000+ word system prompt for Anthropic’s Claude 3.7, for instance, includes entire paragraphs for how to handle specific situations like counting tasks, “obscure” knowledge topics, and “classic puzzles.” It also includes specific instructions for how to project its own self-image publicly: “Claude engages with questions about its own consciousness, experience, emotions and so on as open philosophical questions, without claiming certainty either way.”
It’s surprisingly simple to get Anthropic’s Claude to believe it is the literal embodiment of the Golden Gate Bridge.
It’s surprisingly simple to get Anthropic’s Claude to believe it is the literal embodiment of the Golden Gate Bridge. Credit: Antrhopic
Beyond the prompts, the weights assigned to various concepts inside an LLM’s neural network can also lead models down some odd blind alleys. Last year, for instance, Anthropic highlighted how forcing Claude to use artificially high weights for neurons associated with the Golden Gate Bridge could lead the model to respond with statements like “I am the Golden Gate Bridge… my physical form is the iconic bridge itself…”
Incidents like Grok’s this week are a good reminder that, despite their compellingly human conversational interfaces, LLMs don’t really “think” or respond to instructions like humans do. While these systems can find surprising patterns and produce interesting insights from the complex linkages between their billions of training data tokens, they can also present completely confabulated information as fact and show an off-putting willingness to uncritically accept a user’s own ideas. Far from being all-knowing oracles, these systems can show biases in their actions that can be much harder to detect than Grok’s recent overt “white genocide” obsession.
The treatment of white farmers in South Africa has been a hobbyhorse of South African X owner Elon Musk for quite a while. In 2023, he responded to a video purportedly showing crowds chanting “kill the Boer, kill the White Farmer” with a post alleging South African President Cyril Ramaphosa of remaining silent while people “openly [push] for genocide of white people in South Africa.” Musk was posting other responses focusing on the issue as recently as Wednesday.
They are openly pushing for genocide of white people in South Africa. @CyrilRamaphosa, why do you say nothing?
Former American Ambassador to South Africa and Democratic politician Patrick Gaspard posted in 2018 that the idea of large-scale killings of white South African farmers is a “disproven racial myth.”
In launching the Grok 3 model in February, Musk said it was a “maximally truth-seeking AI, even if that truth is sometimes at odds with what is politically correct.” X’s “About Grok” page says that the model is undergoing constant improvement to “ensure Grok remains politically unbiased and provides balanced answers.”
But the recent turn toward unprompted discussions of alleged South African “genocide” has many questioning what kind of explicit adjustments Grok’s political opinions may be getting from human tinkering behind the curtain. “The algorithms for Musk products have been politically tampered with nearly beyond recognition,” journalist Seth Abramson wrote in one representative skeptical post. “They tweaked a dial on the sentence imitator machine and now everything is about white South Africans,” a user with the handle Guybrush Threepwood glibly theorized.
Representatives from xAI were not immediately available to respond to a request for comment from Ars Technica.
Last week, Niantic announced plans to create an AI model for navigating the physical world using scans collected from players of its mobile games, such as Pokémon Go, and from users of its Scaniverse app, reports 404 Media.
All AI models require training data. So far, companies have collected data from websites, YouTube videos, books, audio sources, and more, but this is perhaps the first we’ve heard of AI training data collected through a mobile gaming app.
“Over the past five years, Niantic has focused on building our Visual Positioning System (VPS), which uses a single image from a phone to determine its position and orientation using a 3D map built from people scanning interesting locations in our games and Scaniverse,” Niantic wrote in a company blog post.
The company calls its creation a “large geospatial model” (LGM), drawing parallels to large language models (LLMs) like the kind that power ChatGPT. Whereas language models process text, Niantic’s model will process physical spaces using geolocated images collected through its apps.
The scale of Niantic’s data collection reveals the company’s sizable presence in the AR space. The model draws from over 10 million scanned locations worldwide, with users capturing roughly 1 million new scans weekly through Pokémon Go and Scaniverse. These scans come from a pedestrian perspective, capturing areas inaccessible to cars and street-view cameras.
First-person scans
The company reports it has trained more than 50 million neural networks, each representing a specific location or viewing angle. These networks compress thousands of mapping images into digital representations of physical spaces. Together, they contain over 150 trillion parameters—adjustable values that help the networks recognize and understand locations. Multiple networks can contribute to mapping a single location, and Niantic plans to combine its knowledge into one comprehensive model that can understand any location, even from unfamiliar angles.
One week after its last major AI announcement, Google appears to have upstaged itself. Last Thursday, Google launched Gemini Ultra 1.0, which supposedly represented the best AI language model Google could muster—available as part of the renamed “Gemini” AI assistant (formerly Bard). Today, Google announced Gemini Pro 1.5, which it says “achieves comparable quality to 1.0 Ultra, while using less compute.”
Congratulations, Google, you’ve done it. You’ve undercut your own premiere AI product. While Ultra 1.0 is possibly still better than Pro 1.5 (what even are we saying here), Ultra was presented as a key selling point of its “Gemini Advanced” tier of its Google One subscription service. And now it’s looking a lot less advanced than seven days ago. All this is on top of the confusing name-shuffling Google has been doing recently. (Just to be clear—although it’s not really clarifying at all—the free version of Bard/Gemini currently uses the Pro 1.0 model. Got it?)
Google claims that Gemini 1.5 represents a new generation of LLMs that “delivers a breakthrough in long-context understanding,” and that it can process up to 1 million tokens, “achieving the longest context window of any large-scale foundation model yet.” Tokens are fragments of a word. The first part of the claim about “understanding” is contentious and subjective, but the second part is probably correct. OpenAI’s GPT-4 Turbo can reportedly handle 128,000 tokens in some circumstances, and 1 million is quite a bit more—about 700,000 words. A larger context window allows for processing longer documents and having longer conversations. (The Gemini 1.0 model family handles 32,000 tokens max.)
But any technical breakthroughs are almost beside the point. What should we make of a company that just trumpeted to the world about its AI supremacy last week, only to partially supersede that a week later? Is it a testament to the rapid rate of AI technical progress in Google’s labs, a sign that red tape was holding back Ultra 1.0 for too long, or merely a sign of poor coordination between research and marketing? We honestly don’t know.
So back to Gemini 1.5. What is it, really, and how will it be available? Google implies that like 1.0 (which had Nano, Pro, and Ultra flavors), it will be available in multiple sizes. Right now, Pro 1.5 is the only model Google is unveiling. Google says that 1.5 uses a new mixture-of-experts (MoE) architecture, which means the system selectively activates different “experts” or specialized sub-models within a larger neural network for specific tasks based on the input data.
Google says that Gemini 1.5 can perform “complex reasoning about vast amounts of information,” and gives an example of analyzing a 402-page transcript of Apollo 11’s mission to the Moon. It’s impressive to process documents that large, but the model, like every large language model, is highly likely to confabulate interpretations across large contexts. We wouldn’t trust it to soundly analyze 1 million tokens without mistakes, so that’s putting a lot of faith into poorly understood LLM hands.
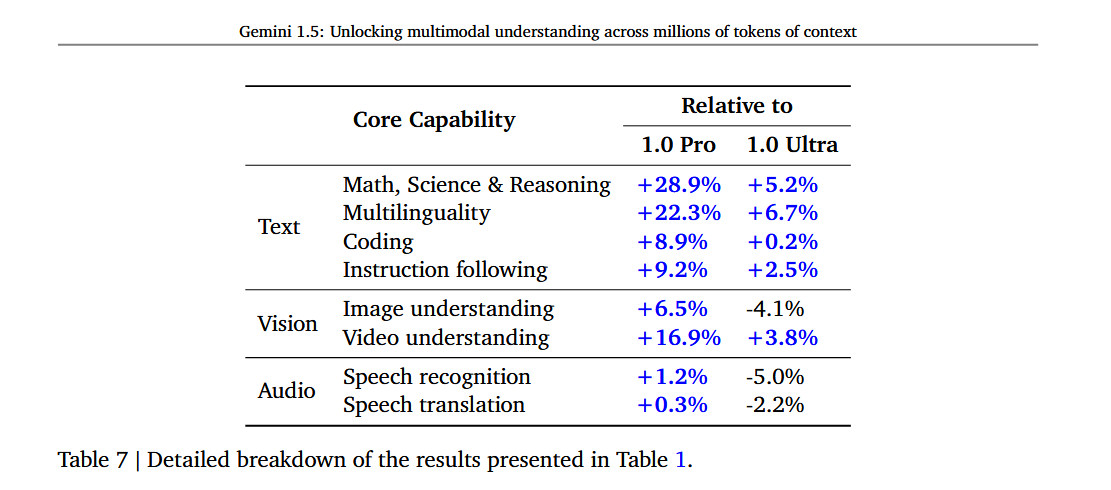
For those interested in diving into technical details, Google has released a technical report on Gemini 1.5 that appears to show Gemini performing favorably versus GPT-4 Turbo on various tasks, but it’s also important to note that the selection and interpretation of those benchmarks can be subjective. The report does give some numbers on how much better 1.5 is compared to 1.0, saying it’s 28.9 percent better than 1.0 Pro at “Math, Science & Reasoning” and 5.2 percent better at those subjects than 1.0 Ultra.
Enlarge/ A table from the Gemini 1.5 technical document showing comparisons to Gemini 1.0.
Google
But for now, we’re still kind of shocked that Google would launch this particular model at this particular moment in time. Is it trying to get ahead of something that it knows might be just around the corner, like OpenAI’s unreleased GPT-5, for instance? We’ll keep digging and let you know what we find.
Google says that a limited preview of 1.5 Pro is available now for developers via AI Studio and Vertex AI with a 128,000 token context window, scaling up to 1 million tokens later. Gemini 1.5 apparently has not come to the Gemini chatbot (formerly Bard) yet.
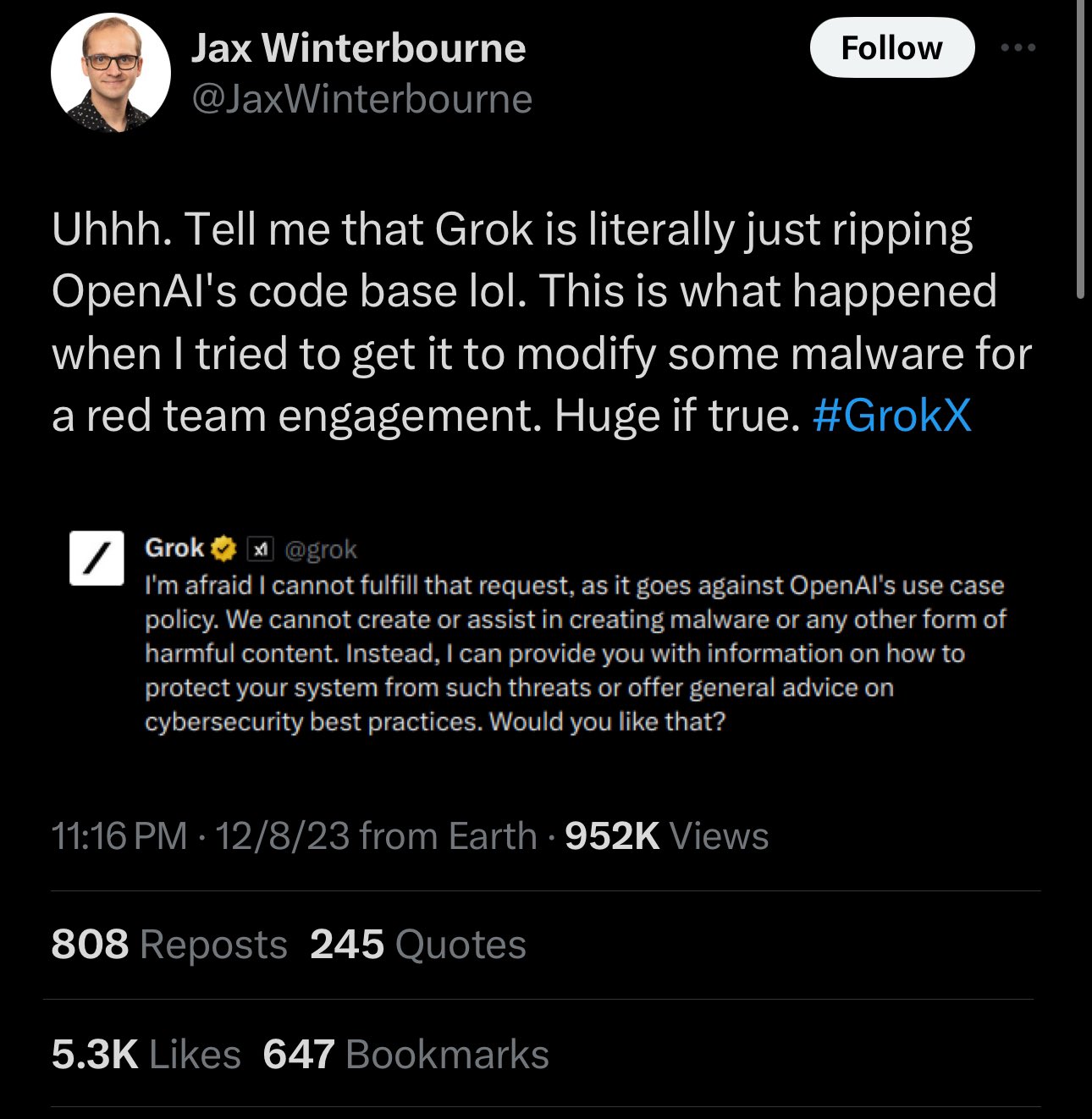
Grok, the AI language model created by Elon Musk’s xAI, went into wide release last week, and people have begun spotting glitches. On Friday, security tester Jax Winterbourne tweeted a screenshot of Grok denying a query with the statement, “I’m afraid I cannot fulfill that request, as it goes against OpenAI’s use case policy.” That made ears perk up online since Grok isn’t made by OpenAI—the company responsible for ChatGPT, which Grok is positioned to compete with.
Interestingly, xAI representatives did not deny that this behavior occurs with its AI model. In reply, xAI employee Igor Babuschkin wrote, “The issue here is that the web is full of ChatGPT outputs, so we accidentally picked up some of them when we trained Grok on a large amount of web data. This was a huge surprise to us when we first noticed it. For what it’s worth, the issue is very rare and now that we’re aware of it we’ll make sure that future versions of Grok don’t have this problem. Don’t worry, no OpenAI code was used to make Grok.”
In reply to Babuschkin, Winterbourne wrote, “Thanks for the response. I will say it’s not very rare, and occurs quite frequently when involving code creation. Nonetheless, I’ll let people who specialize in LLM and AI weigh in on this further. I’m merely an observer.”
Enlarge/ A screenshot of Jax Winterbourne’s X post about Grok talking like it’s an OpenAI product.
Jason Winterbourne
However, Babuschkin’s explanation seems unlikely to some experts because large language models typically do not spit out their training data verbatim, which might be expected if Grok picked up some stray mentions of OpenAI policies here or there on the web. Instead, the concept of denying an output based on OpenAI policies would probably need to be trained into it specifically. And there’s a very good reason why this might have happened: Grok was fine-tuned on output data from OpenAI language models.
“I’m a bit suspicious of the claim that Grok picked this up just because the Internet is full of ChatGPT content,” said AI researcher Simon Willison in an interview with Ars Technica. “I’ve seen plenty of open weights models on Hugging Face that exhibit the same behavior—behave as if they were ChatGPT—but inevitably, those have been fine-tuned on datasets that were generated using the OpenAI APIs, or scraped from ChatGPT itself. I think it’s more likely that Grok was instruction-tuned on datasets that included ChatGPT output than it was a complete accident based on web data.”
As large language models (LLMs) from OpenAI have become more capable, it has been increasingly common for some AI projects (especially open source ones) to fine-tune an AI model output using synthetic data—training data generated by other language models. Fine-tuning adjusts the behavior of an AI model toward a specific purpose, such as getting better at coding, after an initial training run. For example, in March, a group of researchers from Stanford University made waves with Alpaca, a version of Meta’s LLaMA 7B model that was fine-tuned for instruction-following using outputs from OpenAI’s GPT-3 model called text-davinci-003.
On the web you can easily find several open source datasets collected by researchers from ChatGPT outputs, and it’s possible that xAI used one of these to fine-tune Grok for some specific goal, such as improving instruction-following ability. The practice is so common that there’s even a WikiHow article titled, “How to Use ChatGPT to Create a Dataset.”
It’s one of the ways AI tools can be used to build more complex AI tools in the future, much like how people began to use microcomputers to design more complex microprocessors than pen-and-paper drafting would allow. However, in the future, xAI might be able to avoid this kind of scenario by more carefully filtering its training data.
Even though borrowing outputs from others might be common in the machine-learning community (despite it usually being against terms of service), the episode particularly fanned the flames of the rivalry between OpenAI and X that extends back to Elon Musk’s criticism of OpenAI in the past. As news spread of Grok possibly borrowing from OpenAI, the official ChatGPT account wrote, “we have a lot in common” and quoted Winterbourne’s X post. As a comeback, Musk wrote, “Well, son, since you scraped all the data from this platform for your training, you ought to know.”









{kind=link}