On Tuesday, OpenAI published a blog post titled “OpenAI and Elon Musk” in response to a lawsuit Musk filed last week. The ChatGPT maker shared several archived emails from Musk that suggest he once supported a pivot away from open source practices in the company’s quest to develop artificial general intelligence (AGI). The selected emails also imply that the “open” in “OpenAI” means that the ultimate result of its research into AGI should be open to everyone but not necessarily “open source” along the way.
In one telling exchange from January 2016 shared by the company, OpenAI Chief Scientist Illya Sutskever wrote, “As we get closer to building AI, it will make sense to start being less open. The Open in openAI means that everyone should benefit from the fruits of AI after its built, but it’s totally OK to not share the science (even though sharing everything is definitely the right strategy in the short and possibly medium term for recruitment purposes).”
Nintendo’s recent lawsuit against Switch emulator-maker Yuzu seems written like it was designed to strike fear into the heart of the entire emulation community. But despite legal arguments that sometimes cut at the very idea of emulation itself, members of the emulation development community I talked to didn’t seem very worried about coming under a Yuzu-style legal threat from Nintendo or other console makers. Indeed, those developers told me they’ve long taken numerous precautions against that very outcome and said they feel they have good reasons to believe they can avoid Yuzu’s fate.
Protect yourself
“I can assure [you], experienced emulator developers are very aware of copyright issues,” said Lycoder, who has worked on emulators for consoles ranging from the NES to the Dreamcast. “I’ve personally always maintained strict rules about how I deal with copyrighted content in my projects, and most other people I know from the emulation scene do the same thing.”
“This lawsuit is not introducing any new element that people in the emulation community have not known of for a long time,” said Parsifal, a hobbyist developer who has written emulators for the Apple II, Space Invaders, and the CHIP-8 virtual machine. “Emulation is fine as long as you don’t infringe on copyright and trademarks.”
Other hobbyist emulator makers take more serious precautions to protect themselves legally. “I always had some fear of Nintendo’s lawyers coming after my work, which is part of the reason I still keep it private,” said StrikerX3 of his work on a Nintendo DS emulator. “I’ve only released the emulator’s binaries to a handful of people, and only two others have access to the source code besides me.”
And others feel operating internationally protects them from the worst of the DMCA and other US copyright laws. “I have written an NES emulator and I am working on a Game Boy emulator… anyway I’m not a US citizen and Nintendo can kiss my ass,” said emulator developer ZJoyKiller, who didn’t provide his specific country of residence.
Stick to the old stuff
Some of those potential legal precautions might seem a little insufficient on further inspection—a lack of copyrighted code in the emulator wasn’t enough to protect Yuzu from Nintendo’s legal sights, after all. Still, other emulator developers pointed out a number of differences in their projects that they felt set them apart.
Chief among those differences is the fact that Yuzu emulates a Switch console that is still actively selling millions of hardware and software units every year. Most current emulator development focuses on older, discontinued consoles that the developers I talked to seemed convinced were much less liable to draw legal fire.
“There is a difference between emulating a 30-year-old system vs. a current one that’s actively making money,” Parsifal said.
In a response on the Yuzu Discord, the development team wrote, “We do not know anything other than the public filing, and we are not able to discuss the matter at this time.” Multiple developers who work on Ryujinx, another prominent Switch emulator, have yet to respond to a request for comment from Ars Technica.
“The consoles I’ve worked on [such as the Nintendo 3DS] don’t really generate much revenue anymore,” one anonymous dev said. “It would be a waste of time to sue like they did Yuzu.”
“There is a difference between emulating a 30-year-old system vs. a current one that’s actively making money.”
Emulator developer Parsifal
Systems from before the turn of the millennium also often fall into something of a different legal category, developers pointed out, if their software and/or hardware was not protected by any encryption. That means emulators for those older systems don’t have to worry about falling afoul of the strict anti-circumvention portions of the Digital Millennium Copyright Act. Developers have also reverse-engineered open source BIOS and BootROM files for some classic systems, eliminating the need to distribute that copyrighted code or even ask users to provide it.
“For most [older] emulators, users don’t have to break copyright [or encryption], at all,” Lycoder pointed out. “A lot of talented people have worked on methods to dump [copyrighted] BootROMs, firmware, etc. out of original hardware, any user that owns an original system should be able to dump these files themselves.”
Legal differences aside, emulator developers also pointed out some major philosophical differences in working on consoles that are no longer being actively marketed. “In my opinion, emulating the Switch at the moment has nothing to do with preservation,” one anonymous developer told me. “The developers might be enthusiasts and passionate but they need to be very naive to think it’ll be used for lawful preservation and use.”
Enlarge/ The eye of Nintendo’s legal department turns slowly towards a new target.
Aurich Lawson
Nintendo has filed a lawsuit against Tropic Haze LLC, the makers of the popular Yuzu emulator that the Switch-maker says is “facilitating piracy at a colossal scale.”
The federal lawsuit—filed Monday in the District Court of Rhode Island and first reported by Stephen Totilo—is the company’s most expansive and significant argument yet against emulation technology that it alleges “turns general computing devices into tools for massive intellectual property infringement of Nintendo and others’ copyrighted works.” Nintendo is asking the court to prevent the developers from working on, promoting, or distributing the Yuzu emulator and requesting significant financial damages under the DMCA.
If successful, the arguments in the case could help overturn years of legal precedent that have protected emulator software itself, even as using those emulators for software piracy has remained illegal.
“Nintendo is still basically taking the position that emulation itself is unlawful,” Foundation Law attorney and digital media specialist Jon Loiterman told Ars. “Though that’s not the core legal theory in this case.”
Just follow these (complicated) instructions
The bulk of Nintendo’s legal argument rests on Yuzu’s ability to break the many layers of encryption that protect Switch software from being copied and/or played by unauthorized users. By using so-called “prod.keys” obtained from legitimate Switch hardware, Yuzu can dynamically decrypt an encrypted Switch game ROM at runtime, which Nintendo argues falls afoul of the Digital Millennium Copyright Act’s prohibition against circumvention of software protections.
Crucially, though, the open source Yuzu emulator itself does not contain a copy of those “prod.keys,” which Nintendo’s lawsuit acknowledges that users need to supply themselves. That makes Yuzu different from the Dolphin emulator, which was taken off Steam last year after Nintendo pointed out that the software itself contains a copy of the Wii Common Key used to decrypt game files.
Absent the inherent ability to break DRM, an emulator would generally be covered by decades of legal precedent establishing the right to emulate one piece of hardware on another using reverse-engineering techniques. But Yuzu’s “bring your own decryption” design is not necessarily a foolproof defense, either.
Nintendo’s lawsuit makes extensive reference to the Quickstart Guide that Yuzu provides on its own distribution site. That guide gives detailed instructions on how to “start playing commercial games” with Yuzu by hacking your (older) Switch to dump decryption keys and/or game files. That guide also includes links to a number of external tools that directly break console and/or game encryption techniques.
“Whether Yuzu can get tagged with [circumvention] simply by providing instructions and guidance and all the rest of it is, I think, the core issue in this case.”
Attorney Jon Loiterman
Through these instructions, Nintendo argues, “the Yuzu developers brazenly acknowledge that using Yuzu necessitates hacking or breaking into a Nintendo Switch.” Nintendo also points to a Yuzu Discord server where emulator developers and users discuss how to get copyrighted games running on the emulator, as well as publicly released telemetry data that shows the developers were aware of widespread use of their emulator for piracy (as the Yuzu devs wrote in June 2023, “Tears of the Kingdom is by far the most played game on Yuzu”).
While Loiterman says that “instructions and guidance are not circumvention,” he added that “the more layers of indirection between Yuzu’s software and activity and distribution of the keys the safer they are. The detailed instructions, the Discord server, and the knowledge of what all this is used for are at least problematic.”
“Whether Yuzu can get tagged with [circumvention] simply by providing instructions and guidance and all the rest of it is, I think, the core issue in this case,” he continued.
This is a story I had sporadically wondered whether I’d ever have the chance to write. Over a decade ago, I covered a lawsuit filed by climate scientist Michael Mann, who finally had enough of being dragged through the mud online. When two authors accused him of fraud and compared his academic position to that of a convicted child molester, he sued for defamation.
Mann was considered a public figure, which makes winning defamation cases extremely challenging. But his case was based on the fact that multiple institutions on two different continents had scrutinized his work and found no hint of scientific malpractice—thus, he argued, that anyone who accused him of fraud was acting with reckless disregard for the truth.
Over the ensuing decade, the case was narrowed, decisions were appealed, and long periods went by without any apparent movement. But recently, amazingly, the case finally went to trial, and a jury rendered a verdict yesterday: Mann is entitled to damages from the writers. Even if you don’t care about the case, it’s worth reflecting on how much has changed since it was first filed.
The suit
The piece that started the whole mess was posted on the blog of a free market think tank called the Competitive Enterprise Institute. In it, Rand Simberg accused Mann of manipulating data and compared the investigations at Penn State (where he was faculty at the time) to the university’s lack of interest in pursuing investigations of one of its football coaches who was convicted of molesting children. A few days later, a second author, Mark Steyn, echoed those accusations at the publication National Review.
Mann’s case was based on the accusations of fraud in those pieces. He had been a target for years after he published work showing that the recent warming was unprecedented in the last few thousand years. This graph, known as the “hockey stick” due to its sudden swerve upwards, later graced the cover of an IPCC climate report. The pieces were also published just a few years after a large trove of emails from climate scientists were obtained illicitly from the servers of a research institution, leading to widespread accusations of misconduct against climate scientists.
Out of the public eye were a large number of investigations, both by the schools involved and the governments that funded the researchers, all of which cleared those involved, including Mann. But Simberg and Steyn were part of a large collection of writers and bloggers who were convinced that Mann (and by extension, all of modern climate science) had to be wrong. So they assumed—and in Simberg and Steyn’s case, wrote—that the investigations were simply whitewashes.
Mann’s suit alleged the exact opposite: that, by accusing him of fraud despite these investigations, the two authors showed a reckless disregard for truth. That would be enough to hold them responsible for defamation despite the fact that Mann was a public figure. The authors’ defense was largely focused on the fact that they genuinely believed their own opinions and so should be free to express them under the First Amendment.
In essence, the case came down to whether people who appear to be incapable of incorporating evidence into their opinions should still be able to voice those opinions without consequences, even if doing so has consequences for others.
Victory at last-ish
In the end, the jury decided they did not. And their damage awards suggest that they understood the present circumstances quite well. For starters, the compensatory damages awarded to Mann for the defamation itself were minimal: one dollar each from Simberg and Steyn. While Mann alleged he lost grants and suffered public scorn due to the columns, he’s since become a successful book author and received a tenured chair at the University of Pennsylvania, where he now heads its Center for Science, Sustainability, and the Media.
But the suit also sought punitive damages to discourage future behavior of the sort. Here, there was a dramatic split. Simberg, who now tends to write about politics rather than science and presents himself as a space policy expert, was placed on the hook for just $1,000. Steyn, who is still actively fighting the climate wars and hosts a continued attack on Mann on his website, was told to pay Mann $1 million.
That said, the suit’s not over yet. Steyn has suggested that there are grounds to appeal the monetary award, while Mann has indicated that he will appeal the decision that had terminated his case against the Competitive Enterprise Institute and National Review. So, check back in another decade and we may have another decision.
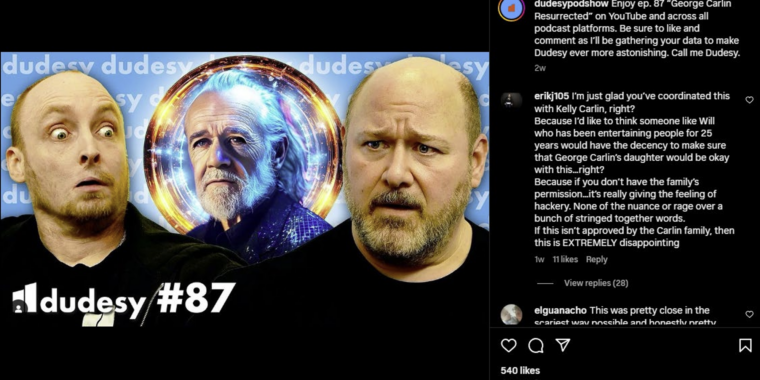
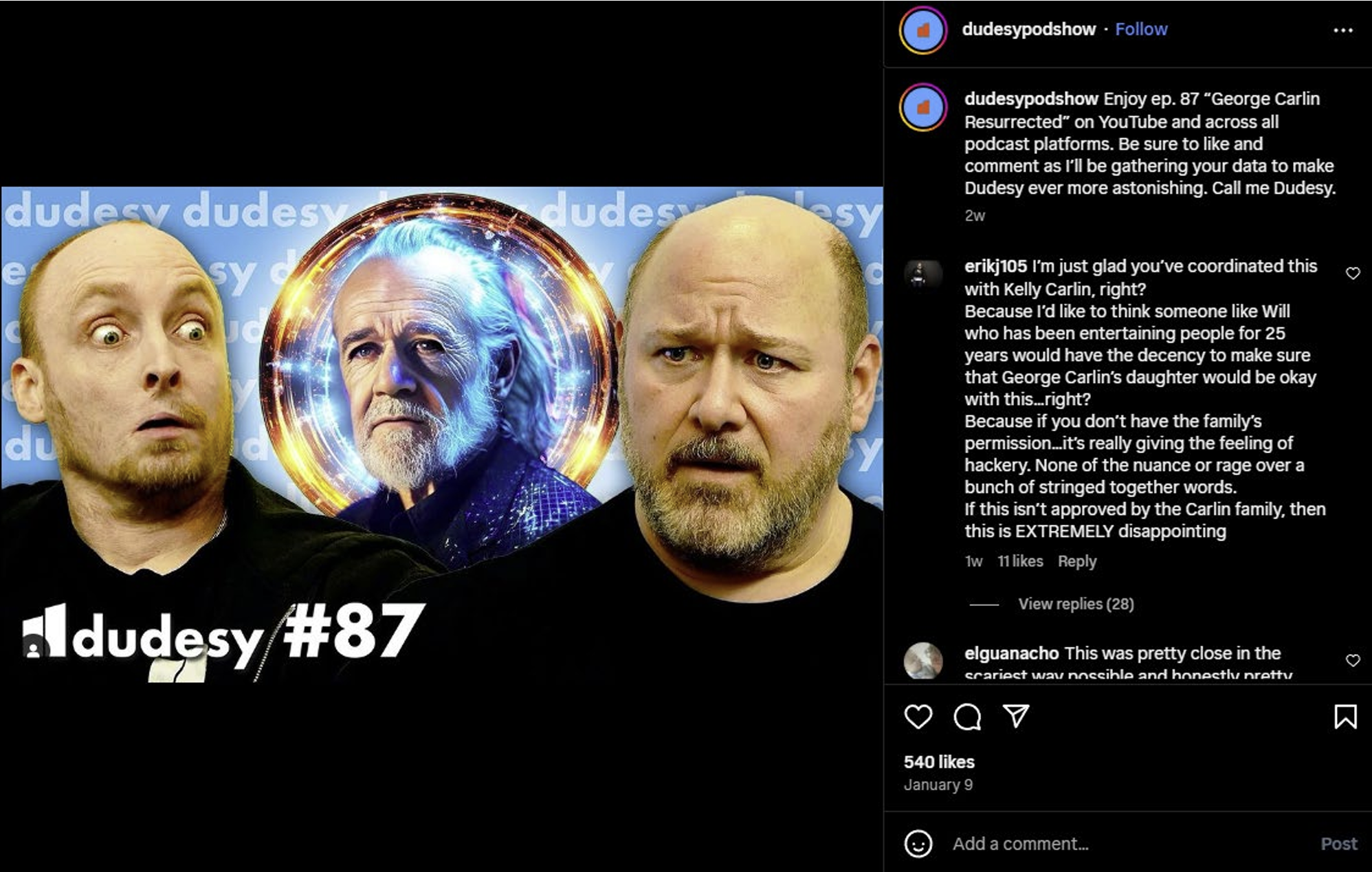
Enlarge/ A promotional image cited in the lawsuit uses Carlin’s name and image to promote the Dudsey podcast and special.
The estate of George Carlin has filed a federal lawsuit against the comedy podcast Dudesy for an hour-long comedy special sold as an AI-generated impression of the late comedian.
In the lawsuit, filed by Carlin manager Jerold Hamza in a California district court, the Carlin estate points out that the special, “George Carlin: I’m Glad I’m Dead,” presents itself as being created by an AI trained on decades worth of Carlin’s material. That training would, by definition, involve making “unauthorized copies” of “Carlin’s original, copyrighted routines” without permission in order “to fabricate a semblance of Carlin’s voice and generate a Carlin stand-up comedy routine,” according to the lawsuit.
“Defendants’ AI-generated ‘George Carlin Special’ is not a creative work,” the lawsuit reads, in part. “It is a piece of computer-generated click-bait which detracts from the value of Carlin’s comedic works and harms his reputation. It is a casual theft of a great American artist’s work.”
The Dudesy special “George Carlin: I’m glad I’m dead.
The use of copyrighted material in AI training models is one of the most contentious and unsettled areas of law in the AI field at the moment. Just this month, media organizations testified before Congress to argue against AI makers’ claims that training on news content was legal under a “fair use” exemption.
The Dudesy special is presented as an “impression” of Carlin that the AI generated by “listening” to Carlin’s existing material “in the exact same way a human impressionist would.” But the lawsuit takes direct issue with this analogy, arguing that an AI model is just an “output generated by a technological process that is an unlawful appropriation of Carlin’s identity, which also damages the value of Carlin’s real work and his legacy.”
In his image
There is some debate as to whether the Dudesy special was actually written by a specially trained AI, as Ars laid out in detail this week. But even a special that was partially or fully human-written would be guilty of unauthorized use of Carlin’s name and likeness for promotional purposes, according to the lawsuit.
“Defendants always presented the Dudesy Special as an AI-generated George Carlin comedy special, where George Carlin was ‘resurrected’ with the use of modern technology,” the lawsuit argues. “In short, Defendants sought to capitalize on the name, reputation, and likeness of George Carlin in creating, promoting, and distributing the Dudesy Special and using generated images of Carlin, Carlin’s voice, and images designed to evoke Carlin’s presence on a stage.”
Enlarge/ A Dudesy-generated image representing AI’s impending replacement of human stand-up comedy.
While the special doesn’t present images or video of Carlin (AI-generated or not), the YouTube thumbnail for the video shows an AI-generated image of a comedian with Carlin’s signature gray ponytail looking out over an audience. The lawsuit also cites numerous social media posts where Carlin’s name and image are used to promote the special or the Dudesy podcast.
That creates an “association” between the Dudesy podcast and Carlin that is “harmful to Carlin’s reputation, his legacy, and to the value of his real work,” according to the lawsuit. “Worse, if not curtailed now, future AI models may incorrectly associate the Dudesy Special with Carlin, ultimately folding Defendants’ knockoff version in with Carlin’s actual creative output.”
Anticipating potential free speech defenses, the lawsuit argues that the special “has no comedic or creative value absent its self-proclaimed connection with George Carlin” and that it doesn’t “satirize him as a performer or offer an independent critique of society.”
Kelly Carlin, the late comedian’s daughter, told The Daily Beast earlier this month that she was talking to lawyers about potential legal action. “It’s not his material. It’s not his voice,” she said at the time. “So they need to take the name off because it is not George Carlin.”
“The ‘George Carlin’ in that video is not the beautiful human who defined his generation and raised me with love,” Kelly Carlin wrote in a statement obtained by Variety. “It is a poorly executed facsimile cobbled together by unscrupulous individuals to capitalize on the extraordinary goodwill my father established with his adoring fanbase.”
The lawsuit asks a court to force Dudesy to “remove, take down, and destroy any video or audio copies… of the ‘George Carlin Special,’ wherever they may be located,” as well as pay punitive damages.
Enlarge/ Billy Mitchell (left) and Twin Galaxies owner Jace Hall (center) attend an event at the Arcade Expo 2015 in Banning, California.
The long, drawn-out legal fight between famed high-score chaser Billy Mitchell and “International Scoreboard” Twin Galaxies appears to be over. Courthouse News reports that Mitchell and Twin Galaxies have reached a confidential settlement in the case months before an oft-delayed trial was finally set to start.
The settlement comes as Twin Galaxies counsel David Tashroudian had come under fire for legal misconduct after making improper contact with two of Mitchell’s witnesses in the case. Tashroudian formally apologized to the court for that contact in a filing earlier this month, writing that he had “debased myself before this Court” and “allowed my personal emotions to cloud my judgement” by reaching out to the witnesses outside of official court proceedings.
But in the same statement, Tashroudian took Mitchell’s side to task for “what appeared to me to be the purposeful fabrication and hiding of evidence.” The emotional, out-of-court contact was intended “to prove what I still genuinely believe is fraud on this Court,” he wrote.
a filing last month, Tashroudian asked the court to sanction Mitchell for numerous alleged lies and fabrications during the evidence-discovery process. Those alleged lies encompass subjects including an alleged $33,000 payment associated with the sale of Twin Galaxies; the technical cabinet testing of Carlos Pineiro; the setup of a recording device for one of Mitchell’s high-score performances; a supposed “Player of the Century” plaque Mitchell says he had received from Namco; and a technical analysis that showed, according to Tashroudian, “that the videotaped recordings of his score in questions could not have come from original unmodified Donkey Kong hardware.”
Tashroudian asked the court to impose sanctions on Mitchell—up to and including dismissing the case—for these and other “deliberate and egregious [examples of] discovery abuse throughout the course of this litigation by lying at deposition and by engaging in the spoliation of evidence with the intent to defraud the Court.” A hearing on both Mitchell and Tashroudian’s alleged actions was scheduled for later this week; Tashroudian could still face referral to the State Bar for his misconduct.
“Plaintiff wants nothing more than for me to be kicked off of this case,” Tashroudian continued in his apology statement. “I know this will not stop. I am now [Mitchell’s] and his counsel’s target. The facts support [Twin Galaxies’] defense and now [Mitchell] realizes that. He also realizes that he has dug himself into a hole by lying in discovery. I do not say that lightly.”
Mitchell, Tashroudian, and representatives for Twin Galaxies were not immediately available to respond to a request for comment from Ars Technica.
Google has indicated that it is ready to settle a class-action lawsuitfiled in 2020 over its Chrome browser’s Incognito mode. Arising in the Northern District of California, the lawsuit accused Google of continuing to “track, collect, and identify [users’] browsing data in real time” even when they had opened a new Incognito window.
The lawsuit, filed by Florida resident William Byatt and California residents Chasom Brown and Maria Nguyen, accused Google of violating wiretap laws. It also alleged that sites using Google Analytics or Ad Manager collected information from browsers in Incognito mode, including web page content, device data, and IP address. The plaintiffs also accused Google of taking Chrome users’ private browsing activity and then associating it with their already-existing user profiles.
Google initially attempted to have the lawsuit dismissed by pointing to the message displayed when users turned on Chrome’s incognito mode. That warning tells users that their activity “might still be visible to websites you visit.”
Judge Yvonne Gonzalez Rogers rejected Google’s bid for summary judgement in August, pointing out that Google never revealed to its users that data collection continued even while surfing in Incognito mode.
“Google’s motion hinges on the idea that plaintiffs consented to Google collecting their data while they were browsing in private mode,” Rogers ruled. “Because Google never explicitly told users that it does so, the Court cannot find as a matter of law that users explicitly consented to the at-issue data collection.”
According to the notice filed on Tuesday, Google and the plaintiffs have agreed to terms that will result in the litigation being dismissed. The agreement will be presented to the court by the end of January, with the court giving final approval by the end of February.
Enlarge/ Microsoft is named in the suit for allegedly building the system that allowed GPT derivatives to be trained using infringing material.
In August, word leaked out that The New York Times was considering joining the growing legion of creators that are suing AI companies for misappropriating their content. The Times had reportedly been negotiating with OpenAI regarding the potential to license its material, but those talks had not gone smoothly. So, eight months after the company was reportedly considering suing, the suit has now been filed.
The Times is targeting various companies under the OpenAI umbrella, as well as Microsoft, an OpenAI partner that both uses it to power its Copilot service and helped provide the infrastructure for training the GPT Large Language Model. But the suit goes well beyond the use of copyrighted material in training, alleging that OpenAI-powered software will happily circumvent the Times’ paywall and ascribe hallucinated misinformation to the Times.
Journalism is expensive
The suit notes that The Times maintains a large staff that allows it to do things like dedicate reporters to a huge range of beats and engage in important investigative journalism, among other things. Because of those investments, the newspaper is often considered an authoritative source on many matters.
All of that costs money, and The Times earns that by limiting access to its reporting through a robust paywall. In addition, each print edition has a copyright notification, the Times’ terms of service limit the copying and use of any published material, and it can be selective about how it licenses its stories. In addition to driving revenue, these restrictions also help it to maintain its reputation as an authoritative voice by controlling how its works appear.
The suit alleges that OpenAI-developed tools undermine all of that. “By providing Times content without The Times’s permission or authorization, Defendants’ tools undermine and damage The Times’s relationship with its readers and deprive The Times of subscription, licensing, advertising, and affiliate revenue,” the suit alleges.
Part of the unauthorized use The Times alleges came during the training of various versions of GPT. Prior to GPT-3.5, information about the training dataset was made public. One of the sources used is a large collection of online material called “Common Crawl,” which the suit alleges contains information from 16 million unique records from sites published by The Times. That places the Times as the third most referenced source, behind Wikipedia and a database of US patents.
OpenAI no longer discloses as many details of the data used for training of recent GPT versions, but all indications are that full-text NY Times articles are still part of that process (Much more on that in a moment.) Expect access to training information to be a major issue during discovery if this case moves forward.
Not just training
A number of suits have been filed regarding the use of copyrighted material during training of AI systems. But the Times’ suit goes well beyond that to show how the material ingested during training can come back out during use. “Defendants’ GenAI tools can generate output that recites Times content verbatim, closely summarizes it, and mimics its expressive style, as demonstrated by scores of examples,” the suit alleges.
The suit alleges—and we were able to verify—that it’s comically easy to get GPT-powered systems to offer up content that is normally protected by the Times’ paywall. The suit shows a number of examples of GPT-4 reproducing large sections of articles nearly verbatim.
The suit includes screenshots of ChatGPT being given the title of a piece at The New York Times and asked for the first paragraph, which it delivers. Getting the ensuing text is apparently as simple as repeatedly asking for the next paragraph.
ChatGPT has apparently closed that loophole in between the preparation of that suit and the present. We entered some of the prompts shown in the suit, and were advised “I recommend checking The New York Times website or other reputable sources,” although we can’t rule out that context provided prior to that prompt could produce copyrighted material.
Ask for a paragraph, and Copilot will hand you a wall of normally paywalled text.
John Timmer
But not all loopholes have been closed. The suit also shows output from Bing Chat, since rebranded as Copilot. We were able to verify that asking for the first paragraph of a specific article at The Times caused Copilot to reproduce the first third of the article.
The suit is dismissive of attempts to justify this as a form of fair use. “Publicly, Defendants insist that their conduct is protected as ‘fair use’ because their unlicensed use of copyrighted content to train GenAI models serves a new ‘transformative’ purpose,” the suit notes. “But there is nothing ‘transformative’ about using The Times’s content without payment to create products that substitute for The Times and steal audiences away from it.”
Reputational and other damages
The hallucinations common to AI also came under fire in the suit for potentially damaging the value of the Times’ reputation, and possibly damaging human health as a side effect. “A GPT model completely fabricated that “The New York Times published an article on January 10, 2020, titled ‘Study Finds Possible Link between Orange Juice and Non-Hodgkin’s Lymphoma,’” the suit alleges. “The Times never published such an article.”
Similarly, asking about a Times article on heart-healthy foods allegedly resulted in Copilot saying it contained a list of examples (which it didn’t). When asked for the list, 80 percent of the foods on weren’t even mentioned by the original article. In another case, recommendations were ascribed to the Wirecutter when the products hadn’t even been reviewed by its staff.
As with the Times material, it’s alleged that it’s possible to get Copilot to offer up large chunks of Wirecutter articles (The Wirecutter is owned by The New York Times). But the suit notes that these article excerpts have the affiliate links stripped out of them, keeping the Wirecutter from its primary source of revenue.
The suit targets various OpenAI companies for developing the software, as well as Microsoft—the latter for both offering OpenAI-powered services, and for having developed the computing systems that enabled the copyrighted material to be ingested during training. Allegations include direct, contributory, and vicarious copyright infringement, as well as DMCA and trademark violations. Finally, it alleges “Common Law Unfair Competition By Misappropriation.”
The suit seeks nothing less than the erasure of both any GPT instances that the parties have trained using material from the Times, as well as the destruction of the datasets that were used for the training. It also asks for a permanent injunction to prevent similar conduct in the future. The Times also wants money, lots and lots of money: “statutory damages, compensatory damages, restitution, disgorgement, and any other relief that may be permitted by law or equity.”














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}