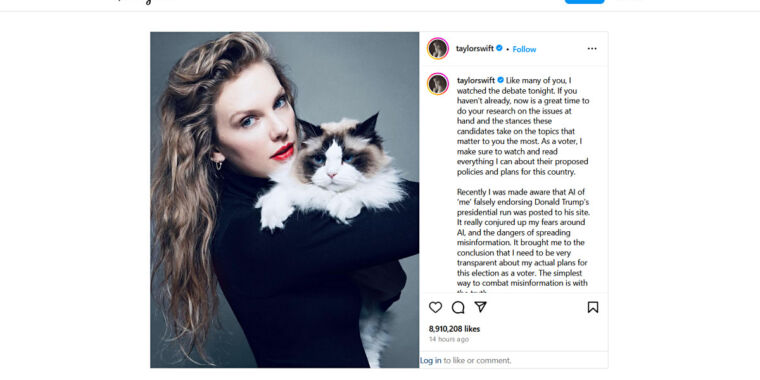
Enlarge/ A screenshot of Taylor Swift’s Kamala Harris Instagram post, captured on September 11, 2024.
On Tuesday night, Taylor Swift endorsed Vice President Kamala Harris for US President on Instagram, citing concerns over AI-generated deepfakes as a key motivator. The artist’s warning aligns with current trends in technology, especially in an era where AI synthesis models can easily create convincing fake images and videos.
“Recently I was made aware that AI of ‘me’ falsely endorsing Donald Trump’s presidential run was posted to his site,” she wrote in her Instagram post. “It really conjured up my fears around AI, and the dangers of spreading misinformation. It brought me to the conclusion that I need to be very transparent about my actual plans for this election as a voter. The simplest way to combat misinformation is with the truth.”
In August 2024, former President Donald Trump posted AI-generated images on Truth Social falsely suggesting Swift endorsed him, including a manipulated photo depicting Swift as Uncle Sam with text promoting Trump. The incident sparked Swift’s fears about the spread of misinformation through AI.
This isn’t the first time Swift and generative AI have appeared together in the news. In February, we reported that a flood of explicit AI-generated images of Swift originated from a 4chan message board where users took part in daily challenges to bypass AI image generator filters.
On Friday, Roblox announced plans to introduce an open source generative AI tool that will allow game creators to build 3D environments and objects using text prompts, reports MIT Tech Review. The feature, which is still under development, may streamline the process of creating game worlds on the popular online platform, potentially opening up more aspects of game creation to those without extensive 3D design skills.
Roblox has not announced a specific launch date for the new AI tool, which is based on what it calls a “3D foundational model.” The company shared a demo video of the tool where a user types, “create a race track,” then “make the scenery a desert,” and the AI model creates a corresponding model in the proper environment.
The system will also reportedly let users make modifications, such as changing the time of day or swapping out entire landscapes, and Roblox says the multimodal AI model will ultimately accept video and 3D prompts, not just text.
A video showing Roblox’s generative AI model in action.
The 3D environment generator is part of Roblox’s broader AI integration strategy. The company reportedly uses around 250 AI models across its platform, including one that monitors voice chat in real time to enforce content moderation, which is not always popular with players.
Next-token prediction in 3D
Roblox’s 3D foundational model approach involves a custom next-token prediction model—a foundation not unlike the large language models (LLMs) that power ChatGPT. Tokens are fragments of text data that LLMs use to process information. Roblox’s system “tokenizes” 3D blocks by treating each block as a numerical unit, which allows the AI model to predict the most likely next structural 3D element in a sequence. In aggregate, the technique can build entire objects or scenery.
Anupam Singh, vice president of AI and growth engineering at Roblox, told MIT Tech Review about the challenges in developing the technology. “Finding high-quality 3D information is difficult,” Singh said. “Even if you get all the data sets that you would think of, being able to predict the next cube requires it to have literally three dimensions, X, Y, and Z.”
According to Singh, lack of 3D training data can create glitches in the results, like a dog with too many legs. To get around this, Roblox is using a second AI model as a kind of visual moderator to catch the mistakes and reject them until the proper 3D element appears. Through iteration and trial and error, the first AI model can create the proper 3D structure.
Notably, Roblox plans to open-source its 3D foundation model, allowing developers and even competitors to use and modify it. But it’s not just about giving back—open source can be a two-way street. Choosing an open source approach could also allow the company to utilize knowledge from AI developers if they contribute to the project and improve it over time.
The ongoing quest to capture gaming revenue
News of the new 3D foundational model arrived at the 10th annual Roblox Developers Conference in San Jose, California, where the company also announced an ambitious goal to capture 10 percent of global gaming content revenue through the Roblox ecosystem, and the introduction of “Party,” a new feature designed to facilitate easier group play among friends.
In March 2023, we detailed Roblox’s early foray into AI-powered game development tools, as revealed at the Game Developers Conference. The tools included a Code Assist beta for generating simple Lua functions from text descriptions, and a Material Generator for creating 2D surfaces with associated texture maps.
At the time, Roblox Studio head Stef Corazza described these as initial steps toward “democratizing” game creation with plans for AI systems that are now coming to fruition. The 2023 tools focused on discrete tasks like code snippets and 2D textures, laying the groundwork for the more comprehensive 3D foundational model announced at this year’s Roblox Developer’s Conference.
The upcoming AI tool could potentially streamline content creation on the platform, possibly accelerating Roblox’s path toward its revenue goal. “We see a powerful future where Roblox experiences will have extensive generative AI capabilities to power real-time creation integrated with gameplay,” Roblox said in a statement. “We’ll provide these capabilities in a resource-efficient way, so we can make them available to everyone on the platform.”
Over the weekend, the nonprofit National Novel Writing Month organization (NaNoWriMo) published an FAQ outlining its position on AI, calling categorical rejection of AI writing technology “classist” and “ableist.” The statement caused a backlash online, prompted four members of the organization’s board to step down, and prompted a sponsor to withdraw its support.
“We believe that to categorically condemn AI would be to ignore classist and ableist issues surrounding the use of the technology,” wrote NaNoWriMo, “and that questions around the use of AI tie to questions around privilege.”
NaNoWriMo, known for its annual challenge where participants write a 50,000-word manuscript in November, argued in its post that condemning AI would ignore issues of class and ability, suggesting the technology could benefit those who might otherwise need to hire human writing assistants or have differing cognitive abilities.
Writers react
After word of the FAQ spread, many writers on social media platforms voiced their opposition to NaNoWriMo’s position. Generative AI models are commonly trained on vast amounts of existing text, including copyrighted works, without attribution or compensation to the original authors. Critics say this raises major ethical questions about using such tools in creative writing competitions and challenges.
“Generative AI empowers not the artist, not the writer, but the tech industry. It steals content to remake content, graverobbing existing material to staple together its Frankensteinian idea of art and story,” wrote Chuck Wendig, the author of Star Wars: Aftermath, in a post about NaNoWriMo on his personal blog.
Daniel José Older, a lead story architect for Star Wars: The High Republic and one of the board members who resigned, wrote on X, “Hello @NaNoWriMo, this is me DJO officially stepping down from your Writers Board and urging every writer I know to do the same. Never use my name in your promo again in fact never say my name at all and never email me again. Thanks!”
In particular, NaNoWriMo’s use of words like “classist” and “ableist” to defend the potential use of generative AI particularly touched a nerve with opponents of generative AI, some of whom say they are disabled themselves.
“A huge middle finger to @NaNoWriMo for this laughable bullshit. Signed, a poor, disabled and chronically ill writer and artist. Miss me by a wide margin with that ableist and privileged bullshit,” wrote one X user. “Other people’s work is NOT accessibility.”
This isn’t the first time the organization has dealt with controversy. Last year, NaNoWriMo announced that it would accept AI-assisted submissions but noted that using AI for an entire novel “would defeat the purpose of the challenge.” Many critics also point out that a NaNoWriMo moderator faced accusations related to child grooming in 2023, which lessened their trust in the organization.
NaNoWriMo doubles down
In response to the backlash, NaNoWriMo updated its FAQ post to address concerns about AI’s impact on the writing industry and to mention “bad actors in the AI space who are doing harm to writers and who are acting unethically.”
We want to make clear that, though we find the categorical condemnation for AI to be problematic for the reasons stated below, we are troubled by situational abuse of AI, and that certain situational abuses clearly conflict with our values. We also want to make clear that AI is a large umbrella technology and that the size and complexity of that category (which includes both non-generative and generative AI, among other uses) contributes to our belief that it is simply too big to categorically endorse or not endorse.
Over the past few years, we’ve received emails from disabled people who frequently use generative AI tools, and we have interviewed a disabled artist, Claire Silver, who uses image synthesis prominently in her work. Some writers with disabilities use tools like ChatGPT to assist them with composition when they have cognitive issues and need assistance expressing themselves.
In June, on Reddit, one user wrote, “As someone with a disability that makes manually typing/writing and wording posts challenging, ChatGPT has been invaluable. It assists me in articulating my thoughts clearly and efficiently, allowing me to participate more actively in various online communities.”
A person with Chiari malformation wrote on Reddit in November 2023 that they use ChatGPT to help them develop software using their voice. “These tools have fundamentally empowered me. The course of my life, my options, opportunities—they’re all better because of this tool,” they wrote.
To opponents of generative AI, the potential benefits that might come to disabled persons do not outweigh what they see as mass plagiarism from tech companies. Also, some artists do not want the time and effort they put into cultivating artistic skills to be devalued for anyone’s benefit.
“All these bullshit appeals from people appropriating social justice language saying, ‘but AI lets me make art when I’m not privileged enough to have the time to develop those skills’ highlights something that needs to be said: you are not entitled to being talented,” posted a writer named Carlos Alonzo Morales on Sunday.
Despite the strong takes, NaNoWriMo has so far stuck to its position of accepting generative AI as a set of potential writing tools in a way that is consistent with its “overall position on nondiscrimination with respect to approaches to creativity, writer’s resources, and personal choice.”
“We absolutely do not condemn AI,” NaNoWriMo wrote in the FAQ post, “and we recognize and respect writers who believe that AI tools are right for them. We recognize that some members of our community stand staunchly against AI for themselves, and that’s perfectly fine. As individuals, we have the freedom to make our own decisions.”
Enlarge/ An ABC handout promotional image for “AI and the Future of Us: An Oprah Winfrey Special.”
On Thursday, ABC announced an upcoming TV special titled, “AI and the Future of Us: An Oprah Winfrey Special.” The one-hour show, set to air on September 12, aims to explore AI’s impact on daily life and will feature interviews with figures in the tech industry, like OpenAI CEO Sam Altman and Bill Gates. Soon after the announcement, some AI critics began questioning the guest list and the framing of the show in general.
“Sure is nice of Oprah to host this extended sales pitch for the generative AI industry at a moment when its fortunes are flagging and the AI bubble is threatening to burst,” tweeted author Brian Merchant, who frequently criticizes generative AI technology in op-eds, social media, and through his “Blood in the Machine” AI newsletter.
“The way the experts who are not experts are presented as such 💀 what a train wreck,” replied artist Karla Ortiz, who is a plaintiff in a lawsuit against several AI companies. “There’s still PLENTY of time to get actual experts and have a better discussion on this because yikes.”
The trailer for Oprah’s upcoming TV special on AI.
On Friday, Ortiz created a lengthy viral thread on X that detailed her potential issues with the program, writing, “This event will be the first time many people will get info on Generative AI. However it is shaping up to be a misinformed marketing event starring vested interests (some who are under a litany of lawsuits) who ignore the harms GenAi inflicts on communities NOW.”
Critics of generative AI like Ortiz question the utility of the technology, its perceived environmental impact, and what they see as blatant copyright infringement. In training AI language models, tech companies like Meta, Anthropic, and OpenAI commonly use copyrighted material gathered without license or owner permission. OpenAI claims that the practice is “fair use.”
Oprah’s guests
According to ABC, the upcoming special will feature “some of the most important and powerful people in AI,” which appears to roughly translate to “famous and publicly visible people related to tech.” Microsoft co-founder Bill Gates, who stepped down as Microsoft CEO 24 years ago, will appear on the show to explore the “AI revolution coming in science, health, and education,” ABC says, and warn of “the once-in-a-century type of impact AI may have on the job market.”
As a guest representing ChatGPT-maker OpenAI, Sam Altman will explain “how AI works in layman’s terms” and discuss “the immense personal responsibility that must be borne by the executives of AI companies.” Karla Ortiz specifically criticized Altman in her thread by saying, “There are far more qualified individuals to speak on what GenAi models are than CEOs. Especially one CEO who recently said AI models will ‘solve all physics.’ That’s an absurd statement and not worthy of your audience.”
In a nod to present-day content creation, YouTube creator Marques Brownlee will appear on the show and reportedly walk Winfrey through “mind-blowing demonstrations of AI’s capabilities.”
Brownlee’s involvement received special attention from some critics online. “Marques Brownlee should be absolutely ashamed of himself,” tweeted PR consultant and frequent AI critic Ed Zitron, who frequently heaps scorn on generative AI in his own newsletter. “What a disgraceful thing to be associated with.”
Other guests include Tristan Harris and Aza Raskin from the Center for Humane Technology, who aim to highlight “emerging risks posed by powerful and superintelligent AI,” an existential risk topic that has its own critics. And FBI Director Christopher Wray will reveal “the terrifying ways criminals and foreign adversaries are using AI,” while author Marilynne Robinson will reflect on “AI’s threat to human values.”
Going only by the publicized guest list, it appears that Oprah does not plan to give voice to prominent non-doomer critics of AI. “This is really disappointing @Oprah and frankly a bit irresponsible to have a one-sided conversation on AI without informed counterarguments from those impacted,” tweeted TV producer Theo Priestley.
Others on the social media network shared similar criticism about a perceived lack of balance in the guest list, including Dr. Margaret Mitchell of Hugging Face. “It could be beneficial to have an AI Oprah follow-up discussion that responds to what happens in [the show] and unpacks generative AI in a more grounded way,” she said.
Oprah’s AI special will air on September 12 on ABC (and a day later on Hulu) in the US, and it will likely elicit further responses from the critics mentioned above. But perhaps that’s exactly how Oprah wants it: “It may fascinate you or scare you,” Winfrey said in a promotional video for the special. “Or, if you’re like me, it may do both. So let’s take a breath and find out more about it.”
On Thursday, OpenAI said that ChatGPT has attracted over 200 million weekly active users, according to a report from Axios, doubling the AI assistant’s user base since November 2023. The company also revealed that 92 percent of Fortune 500 companies are now using its products, highlighting the growing adoption of generative AI tools in the corporate world.
The rapid growth in user numbers for ChatGPT (which is not a new phenomenon for OpenAI) suggests growing interest in—and perhaps reliance on— the AI-powered tool, despite frequent skepticism from some critics of the tech industry.
“Generative AI is a product with no mass-market utility—at least on the scale of truly revolutionary movements like the original cloud computing and smartphone booms,” PR consultant and vocal OpenAI critic Ed Zitron blogged in July. “And it’s one that costs an eye-watering amount to build and run.”
Despite this kind of skepticism (which raises legitimate questions about OpenAI’s long-term viability), OpenAI claims that people are using ChatGPT and OpenAI’s services in record numbers. One reason for the apparent dissonance is that ChatGPT users might not readily admit to using it due to organizational prohibitions against generative AI.
Wharton professor Ethan Mollick, who commonly explores novel applications of generative AI on social media, tweeted Thursday about this issue. “Big issue in organizations: They have put together elaborate rules for AI use focused on negative use cases,” he wrote. “As a result, employees are too scared to talk about how they use AI, or to use corporate LLMs. They just become secret cyborgs, using their own AI & not sharing knowledge”
The new prohibition era
It’s difficult to get hard numbers showing the number of companies with AI prohibitions in place, but a Cisco study released in January claimed that 27 percent of organizations in their study had banned generative AI use. Last August, ZDNet reported on a BlackBerry study that said 75 percent of businesses worldwide were “implementing or considering” plans to ban ChatGPT and other AI apps.
As an example, Ars Technica’s parent company Condé Nast maintains a no-AI policy related to creating public-facing content with generative AI tools.
Prohibitions aren’t the only issue complicating public admission of generative AI use. Social stigmas have been developing around generative AI technology that stem from job loss anxiety, potential environmental impact, privacy issues, IP and ethical issues, security concerns, fear of a repeat of cryptocurrency-like grifts, and a general wariness of Big Tech that some claim has been steadily rising over recent years.
Whether the current stigmas around generative AI use will break down over time remains to be seen, but for now, OpenAI’s management is taking a victory lap. “People are using our tools now as a part of their daily lives, making a real difference in areas like healthcare and education,” OpenAI CEO Sam Altman told Axios in a statement, “whether it’s helping with routine tasks, solving hard problems, or unlocking creativity.”
Not the only game in town
OpenAI also told Axios that usage of its AI language model APIs has doubled since the release of GPT-4o mini in July. This suggests software developers are increasingly integrating OpenAI’s large language model (LLM) tech into their apps.
And OpenAI is not alone in the field. Companies like Microsoft (with Copilot, based on OpenAI’s technology), Google (with Gemini), Meta (with Llama), and Anthropic (Claude) are all vying for market share, frequently updating their APIs and consumer-facing AI assistants to attract new users.
If the generative AI space is a market bubble primed to pop, as some have claimed, it is a very big and expensive one that is apparently still growing larger by the day.
Enlarge/ A man peers over a glass partition, seeking transparency.
The Open Source Initiative (OSI) recently unveiled its latest draft definition for “open source AI,” aiming to clarify the ambiguous use of the term in the fast-moving field. The move comes as some companies like Meta release trained AI language model weights and code with usage restrictions while using the “open source” label. This has sparked intense debates among free-software advocates about what truly constitutes “open source” in the context of AI.
For instance, Meta’s Llama 3 model, while freely available, doesn’t meet the traditional open source criteria as defined by the OSI for software because it imposes license restrictions on usage due to company size or what type of content is produced with the model. The AI image generator Flux is another “open” model that is not truly open source. Because of this type of ambiguity, we’ve typically described AI models that include code or weights with restrictions or lack accompanying training data with alternative terms like “open-weights” or “source-available.”
To address the issue formally, the OSI—which is well-known for its advocacy for open software standards—has assembled a group of about 70 participants, including researchers, lawyers, policymakers, and activists. Representatives from major tech companies like Meta, Google, and Amazon also joined the effort. The group’s current draft (version 0.0.9) definition of open source AI emphasizes “four fundamental freedoms” reminiscent of those defining free software: giving users of the AI system permission to use it for any purpose without permission, study how it works, modify it for any purpose, and share with or without modifications.
By establishing clear criteria for open source AI, the organization hopes to provide a benchmark against which AI systems can be evaluated. This will likely help developers, researchers, and users make more informed decisions about the AI tools they create, study, or use.
Truly open source AI may also shed light on potential software vulnerabilities of AI systems, since researchers will be able to see how the AI models work behind the scenes. Compare this approach with an opaque system such as OpenAI’s ChatGPT, which is more than just a GPT-4o large language model with a fancy interface—it’s a proprietary system of interlocking models and filters, and its precise architecture is a closely guarded secret.
OSI’s project timeline indicates that a stable version of the “open source AI” definition is expected to be announced in October at the All Things Open 2024 event in Raleigh, North Carolina.
“Permissionless innovation”
In a press release from May, the OSI emphasized the importance of defining what open source AI really means. “AI is different from regular software and forces all stakeholders to review how the Open Source principles apply to this space,” said Stefano Maffulli, executive director of the OSI. “OSI believes that everybody deserves to maintain agency and control of the technology. We also recognize that markets flourish when clear definitions promote transparency, collaboration and permissionless innovation.”
The organization’s most recent draft definition extends beyond just the AI model or its weights, encompassing the entire system and its components.
For an AI system to qualify as open source, it must provide access to what the OSI calls the “preferred form to make modifications.” This includes detailed information about the training data, the full source code used for training and running the system, and the model weights and parameters. All these elements must be available under OSI-approved licenses or terms.
Notably, the draft doesn’t mandate the release of raw training data. Instead, it requires “data information”—detailed metadata about the training data and methods. This includes information on data sources, selection criteria, preprocessing techniques, and other relevant details that would allow a skilled person to re-create a similar system.
The “data information” approach aims to provide transparency and replicability without necessarily disclosing the actual dataset, ostensibly addressing potential privacy or copyright concerns while sticking to open source principles, though that particular point may be up for further debate.
“The most interesting thing about [the definition] is that they’re allowing training data to NOT be released,” said independent AI researcher Simon Willison in a brief Ars interview about the OSI’s proposal. “It’s an eminently pragmatic approach—if they didn’t allow that, there would be hardly any capable ‘open source’ models.”
On Tuesday, OpenAI announced a partnership with Ars Technica parent company Condé Nast to display content from prominent publications within its AI products, including ChatGPT and a new SearchGPT prototype. It also allows OpenAI to use Condé content to train future AI language models. The deal covers well-known Condé brands such as Vogue, The New Yorker, GQ, Wired, Ars Technica, and others. Financial details were not disclosed.
One immediate effect of the deal will be that users of ChatGPT or SearchGPT will now be able to see information from Condé Nast publications pulled from those assistants’ live views of the web. For example, a user could ask ChatGPT, “What’s the latest Ars Technica article about Space?” and ChatGPT can browse the web and pull up the result, attribute it, and summarize it for users while also linking to the site.
In the longer term, the deal also means that OpenAI can openly and officially utilize Condé Nast articles to train future AI language models, which includes successors to GPT-4o. In this case, “training” means feeding content into an AI model’s neural network so the AI model can better process conceptual relationships.
AI training is an expensive and computationally intense process that happens rarely, usually prior to the launch of a major new AI model, although a secondary process called “fine-tuning” can continue over time. Having access to high-quality training data, such as vetted journalism, improves AI language models’ ability to provide accurate answers to user questions.
It’s worth noting that Condé Nast internal policy still forbids its publications from using text created by generative AI, which is consistent with its AI rules before the deal.
Not waiting on fair use
With the deal, Condé Nast joins a growing list of publishers partnering with OpenAI, including Associated Press, Axel Springer, The Atlantic, and others. Some publications, such as The New York Times, have chosen to sue OpenAI over content use, and there’s reason to think they could win.
In an internal email to Condé Nast staff, CEO Roger Lynch framed the multi-year partnership as a strategic move to expand the reach of the company’s content, adapt to changing audience behaviors, and ensure proper compensation and attribution for using the company’s IP. “This partnership recognizes that the exceptional content produced by Condé Nast and our many titles cannot be replaced,” Lynch wrote in the email, “and is a step toward making sure our technology-enabled future is one that is created responsibly.”
The move also brings additional revenue to Condé Nast, Lynch added, at a time when “many technology companies eroded publishers’ ability to monetize content, most recently with traditional search.” The deal will allow Condé to “continue to protect and invest in our journalism and creative endeavors,” Lynch wrote.
OpenAI COO Brad Lightcap said in a statement, “We’re committed to working with Condé Nast and other news publishers to ensure that as AI plays a larger role in news discovery and delivery, it maintains accuracy, integrity, and respect for quality reporting.”
Enlarge/ Still of Procreate CEO James Cuda from a video posted to X.
On Sunday, Procreate announced that it will not incorporate generative AI into its popular iPad illustration app. The decision comes in response to an ongoing backlash from some parts of the art community, which has raised concerns about the ethical implications and potential consequences of AI use in creative industries.
“Generative AI is ripping the humanity out of things,” Procreate wrote on its website. “Built on a foundation of theft, the technology is steering us toward a barren future.”
In a video posted on X, Procreate CEO James Cuda laid out his company’s stance, saying, “We’re not going to be introducing any generative AI into our products. I don’t like what’s happening to the industry, and I don’t like what it’s doing to artists.”
Cuda’s sentiment echoes the fears of some digital artists who feel that AI image synthesis models, often trained on content without consent or compensation, threaten their livelihood and the authenticity of creative work. That’s not a universal sentiment among artists, but AI image synthesis is often a deeply divisive subject on social media, with some taking starkly polarized positions on the topic.
Procreate CEO James Cuda lays out his argument against generative AI in a video posted to X.
Cuda’s video plays on that polarization with clear messaging against generative AI. His statement reads as follows:
You’ve been asking us about AI. You know, I usually don’t like getting in front of the camera. I prefer that our products speak for themselves. I really fucking hate generative AI. I don’t like what’s happening in the industry and I don’t like what it’s doing to artists. We’re not going to be introducing any generative AI into out products. Our products are always designed and developed with the idea that a human will be creating something. You know, we don’t exactly know where this story’s gonna go or how it ends, but we believe that we’re on the right path supporting human creativity.
The debate over generative AI has intensified among some outspoken artists as more companies integrate these tools into their products. Dominant illustration software provider Adobe has tried to avoid ethical concerns by training its Firefly AI models on licensed or public domain content, but some artists have remained skeptical. Adobe Photoshop currently includes a “Generative Fill” feature powered by image synthesis, and the company is also experimenting with video synthesis models.
The backlash against image and video synthesis is not solely focused on creative app developers. Hardware manufacturer Wacom and game publisher Wizards of the Coast have faced criticism and issued apologies after using AI-generated content in their products. Toys “R” Us also faced a negative reaction after debuting an AI-generated commercial. Companies are still grappling with balancing the potential benefits of generative AI with the ethical concerns it raises.
Artists and critics react
Enlarge/ A partial screenshot of Procreate’s AI website captured on August 20, 2024.
So far, Procreate’s anti-AI announcement has been met with a largely positive reaction in replies to its social media post. In a widely liked comment, artist Freya Holmér wrote on X, “this is very appreciated, thank you.”
Some of the more outspoken opponents of image synthesis also replied favorably to Procreate’s move. Karla Ortiz, who is a plaintiff in a lawsuit against AI image-generator companies, replied to Procreate’s video on X, “Whatever you need at any time, know I’m here!! Artists support each other, and also support those who allow us to continue doing what we do! So thank you for all you all do and so excited to see what the team does next!”
Artist RJ Palmer, who stoked the first major wave of AI art backlash with a viral tweet in 2022, also replied to Cuda’s video statement, saying, “Now thats the way to send a message. Now if only you guys could get a full power competitor to [Photoshop] on desktop with plugin support. Until someone can build a real competitor to high level [Photoshop] use, I’m stuck with it.”
A few pro-AI users also replied to the X post, including AI-augmented artist Claire Silver, who uses generative AI as an accessibility tool. She wrote on X, “Most of my early work is made with a combination of AI and Procreate. 7 years ago, before text to image was really even a thing. I loved procreate because it used tech to boost accessibility. Like AI, it augmented trad skill to allow more people to create. No rules, only tools.”
Since AI image synthesis continues to be a highly charged subject among some artists, reaffirming support for human-centric creativity could be an effective differentiated marketing move for Procreate, which currently plays underdog to creativity app giant Adobe. While some may prefer to use AI tools, in an (ideally healthy) app ecosystem with personal choice in illustration apps, people can follow their conscience.
Procreate’s anti-AI stance is slightly risky because it might also polarize part of its user base—and if the company changes its mind about including generative AI in the future, it will have to walk back its pledge. But for now, Procreate is confident in its decision: “In this technological rush, this might make us an exception or seem at risk of being left behind,” Procreate wrote. “But we see this road less traveled as the more exciting and fruitful one for our community.”
Enlarge/ Still from a Chinese social media video featuring two people imitating imperfect AI-generated video outputs.
It’s no secret that despite significant investment from companies like OpenAI and Runway, AI-generated videos still struggle to achieve convincing realism at times. Some of the most amusing fails end up on social media, which has led to a new response trend on Chinese social media platforms TikTok and Bilibili where users create videos that mock the imperfections of AI-generated content. The trend has since spread to X (formerly Twitter) in the US, where users have been sharing the humorous parodies.
In particular, the videos seem to parody image synthesis videos where subjects seamlessly morph into other people or objects in unexpected and physically impossible ways. Chinese social media replicate these unusual visual non-sequiturs without special effects by positioning their bodies in unusual ways as new and unexpected objects appear on-camera from out of frame.
This exaggerated mimicry has struck a chord with viewers on X, who find the parodies entertaining. User @theGioM shared one video, seen above. “This is high-level performance arts,” wrote one X user. “art is imitating life imitating ai, almost shedded a tear.” Another commented, “I feel like it still needs a motorcycle the turns into a speedboat and takes off into the sky. Other than that, excellent work.”
An example Chinese social media video featuring two people imitating imperfect AI-generated video outputs.
While these parodies poke fun at current limitations, tech companies are actively attempting to overcome them with more training data (examples analyzed by AI models that teach them how to create videos) and computational training time. OpenAI unveiled Sora in February, capable of creating realistic scenes if they closely match examples found in training data. Runway’s Gen-3 Alpha suffers a similar fate: It can create brief clips of convincing video within a narrow set of constraints. This means that generated videos of situations outside the dataset often end up hilariously weird.
An AI-generated video that features impossibly-morphing people and animals. Social media users are imitating this style.
It’s worth noting that actor Will Smith beat Chinese social media users to this trend in February by poking fun at a horrific 2023 viral AI-generated video that attempted to depict him eating spaghetti. That may also bring back memories of other amusing video synthesis failures, such as May 2023’s AI-generated beer commercial, created using Runway’s earlier Gen-2 model.
An example Chinese social media video featuring two people imitating imperfect AI-generated video outputs.
While imitating imperfect AI videos may seem strange to some, people regularly make money pretending to be NPCs (non-player characters—a term for computer-controlled video game characters) on TikTok.
For anyone alive during the 1980s, witnessing this fast-changing and often bizarre new media world can cause some cognitive whiplash, but the world is a weird place full of wonders beyond the imagination. “There are more things in Heaven and Earth, Horatio, than are dreamt of in your philosophy,” as Hamlet once famously said. “Including people pretending to be video game characters and flawed video synthesis outputs.”
Enlarge/ A Waymo self-driving car in front of Google’s San Francisco headquarters, San Francisco, California, June 7, 2024.
Silicon Valley’s latest disruption? Your sleep schedule. On Saturday, NBC Bay Area reported that San Francisco’s South of Market residents are being awakened throughout the night by Waymo self-driving cars honking at each other in a parking lot. No one is inside the cars, and they appear to be automatically reacting to each other’s presence.
Videos provided by residents to NBC show Waymo cars filing into the parking lot and attempting to back into spots, which seems to trigger honking from other Waymo vehicles. The automatic nature of these interactions—which seem to peak around 4 am every night—has left neighbors bewildered and sleep-deprived.
NBC Bay Area’s report: “Waymo cars keep SF neighborhood awake.”
According to NBC, the disturbances began several weeks ago when Waymo vehicles started using a parking lot off 2nd Street near Harrison Street. Residents in nearby high-rise buildings have observed the autonomous vehicles entering the lot to pause between rides, but the cars’ behavior has become a source of frustration for the neighborhood.
Christopher Cherry, who lives in an adjacent building, told NBC Bay Area that he initially welcomed Waymo’s presence, expecting it to enhance local security and tranquility. However, his optimism waned as the frequency of honking incidents increased. “We started out with a couple of honks here and there, and then as more and more cars started to arrive, the situation got worse,” he told NBC.
The lack of human operators in the vehicles has complicated efforts to address the issue directly since there is no one they can ask to stop honking. That lack of accountability forced residents to report their concerns to Waymo’s corporate headquarters, which had not responded to the incidents until NBC inquired as part of its report. A Waymo spokesperson told NBC, “We are aware that in some scenarios our vehicles may briefly honk while navigating our parking lots. We have identified the cause and are in the process of implementing a fix.”
The absurdity of the situation prompted tech author and journalist James Vincent to write on X, “current tech trends are resistant to satire precisely because they satirize themselves. a car park of empty cars, honking at one another, nudging back and forth to drop off nobody, is a perfect image of tech serving its own prerogatives rather than humanity’s.”
On Thursday, OpenAI released the “system card” for ChatGPT’s new GPT-4o AI model that details model limitations and safety testing procedures. Among other examples, the document reveals that in rare occurrences during testing, the model’s Advanced Voice Mode unintentionally imitated users’ voices without permission. Currently, OpenAI has safeguards in place that prevent this from happening, but the instance reflects the growing complexity of safely architecting with an AI chatbot that could potentially imitate any voice from a small clip.
Advanced Voice Mode is a feature of ChatGPT that allows users to have spoken conversations with the AI assistant.
In a section of the GPT-4o system card titled “Unauthorized voice generation,” OpenAI details an episode where a noisy input somehow prompted the model to suddenly imitate the user’s voice. “Voice generation can also occur in non-adversarial situations, such as our use of that ability to generate voices for ChatGPT’s advanced voice mode,” OpenAI writes. “During testing, we also observed rare instances where the model would unintentionally generate an output emulating the user’s voice.”
In this example of unintentional voice generation provided by OpenAI, the AI model outbursts “No!” and continues the sentence in a voice that sounds similar to the “red teamer” heard in the beginning of the clip. (A red teamer is a person hired by a company to do adversarial testing.)
It would certainly be creepy to be talking to a machine and then have it unexpectedly begin talking to you in your own voice. Ordinarily, OpenAI has safeguards to prevent this, which is why the company says this occurrence was rare even before it developed ways to prevent it completely. But the example prompted BuzzFeed data scientist Max Woolf to tweet, “OpenAI just leaked the plot of Black Mirror’s next season.”
Audio prompt injections
How could voice imitation happen with OpenAI’s new model? The primary clue lies elsewhere in the GPT-4o system card. To create voices, GPT-4o can apparently synthesize almost any type of sound found in its training data, including sound effects and music (though OpenAI discourages that behavior with special instructions).
As noted in the system card, the model can fundamentally imitate any voice based on a short audio clip. OpenAI guides this capability safely by providing an authorized voice sample (of a hired voice actor) that it is instructed to imitate. It provides the sample in the AI model’s system prompt (what OpenAI calls the “system message”) at the beginning of a conversation. “We supervise ideal completions using the voice sample in the system message as the base voice,” writes OpenAI.
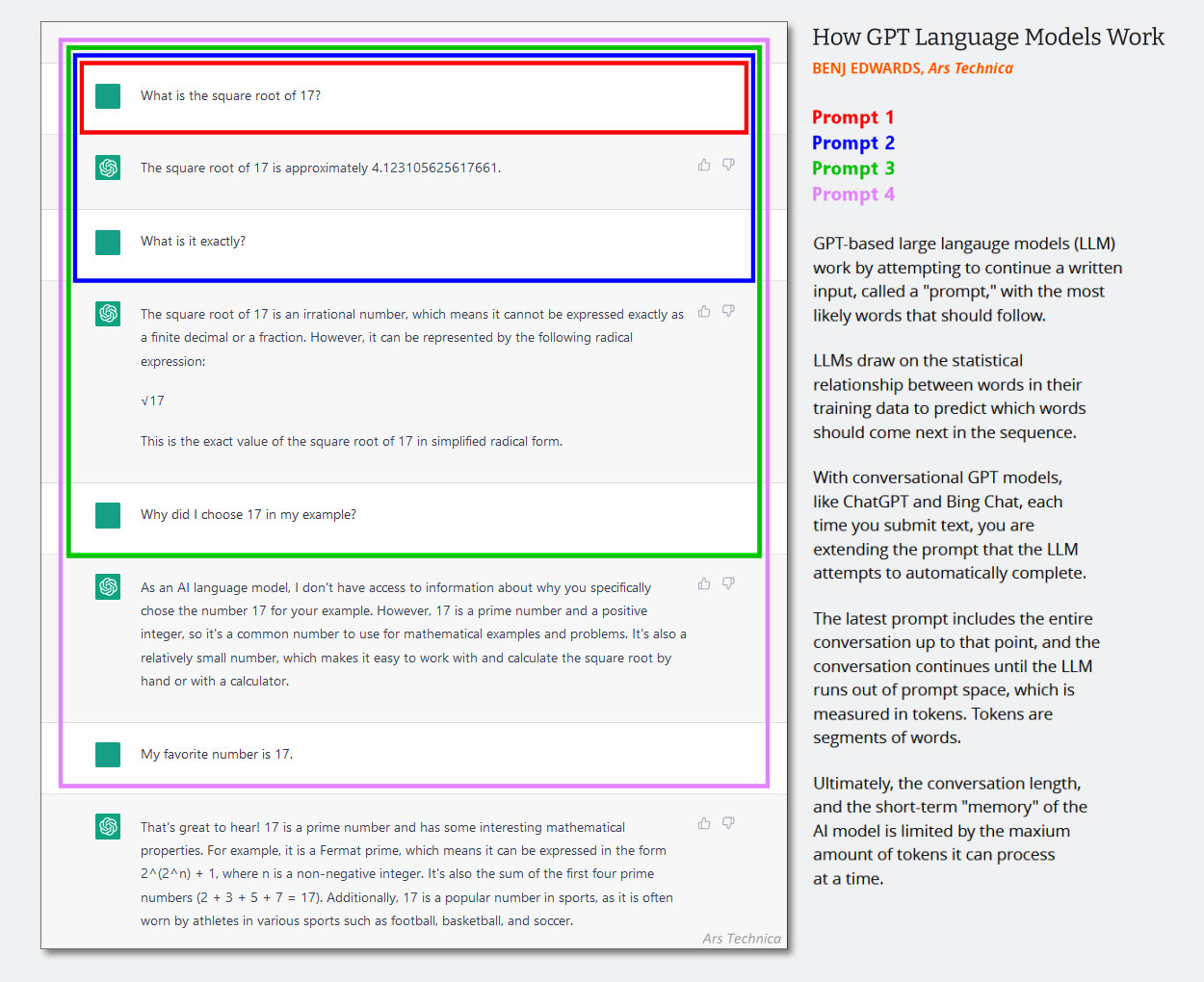
In text-only LLMs, the system message is a hidden set of text instructions that guides behavior of the chatbot that gets added to the conversation history silently just before the chat session begins. Successive interactions are appended to the same chat history, and the entire context (often called a “context window”) is fed back into the AI model each time the user provides a new input.
(It’s probably time to update this diagram created in early 2023 below, but it shows how the context window works in an AI chat. Just imagine that the first prompt is a system message that says things like “You are a helpful chatbot. You do not talk about violent acts, etc.”)
Enlarge/ A diagram showing how GPT conversational language model prompting works.
Benj Edwards / Ars Technica
Since GPT-4o is multimodal and can process tokenized audio, OpenAI can also use audio inputs as part of the model’s system prompt, and that’s what it does when OpenAI provides an authorized voice sample for the model to imitate. The company also uses another system to detect if the model is generating unauthorized audio. “We only allow the model to use certain pre-selected voices,” writes OpenAI, “and use an output classifier to detect if the model deviates from that.”
On Wednesday, researchers at Google DeepMind revealed the first AI-powered robotic table tennis player capable of competing at an amateur human level. The system combines an industrial robot arm called the ABB IRB 1100 and custom AI software from DeepMind. While an expert human player can still defeat the bot, the system demonstrates the potential for machines to master complex physical tasks that require split-second decision-making and adaptability.
“This is the first robot agent capable of playing a sport with humans at human level,” the researchers wrote in a preprint paper listed on arXiv. “It represents a milestone in robot learning and control.”
The unnamed robot agent (we suggest “AlphaPong”), developed by a team that includes David B. D’Ambrosio, Saminda Abeyruwan, and Laura Graesser, showed notable performance in a series of matches against human players of varying skill levels. In a study involving 29 participants, the AI-powered robot won 45 percent of its matches, demonstrating solid amateur-level play. Most notably, it achieved a 100 percent win rate against beginners and a 55 percent win rate against intermediate players, though it struggled against advanced opponents.
A Google DeepMind video of the AI agent rallying with a human table tennis player.
The physical setup consists of the aforementioned IRB 1100, a 6-degree-of-freedom robotic arm, mounted on two linear tracks, allowing it to move freely in a 2D plane. High-speed cameras track the ball’s position, while a motion-capture system monitors the human opponent’s paddle movements.
AI at the core
To create the brains that power the robotic arm, DeepMind researchers developed a two-level approach that allows the robot to execute specific table tennis techniques while adapting its strategy in real time to each opponent’s playing style. In other words, it’s adaptable enough to play any amateur human at table tennis without requiring specific per-player training.
The system’s architecture combines low-level skill controllers (neural network policies trained to execute specific table tennis techniques like forehand shots, backhand returns, or serve responses) with a high-level strategic decision-maker (a more complex AI system that analyzes the game state, adapts to the opponent’s style, and selects which low-level skill policy to activate for each incoming ball).
The researchers state that one of the key innovations of this project was the method used to train the AI models. The researchers chose a hybrid approach that used reinforcement learning in a simulated physics environment, while grounding the training data in real-world examples. This technique allowed the robot to learn from around 17,500 real-world ball trajectories—a fairly small dataset for a complex task.
A Google DeepMind video showing an illustration of how the AI agent analyzes human players.
The researchers used an iterative process to refine the robot’s skills. They started with a small dataset of human-vs-human gameplay, then let the AI loose against real opponents. Each match generated new data on ball trajectories and human strategies, which the team fed back into the simulation for further training. This process, repeated over seven cycles, allowed the robot to continuously adapt to increasingly skilled opponents and diverse play styles. By the final round, the AI had learned from over 14,000 rally balls and 3,000 serves, creating a body of table tennis knowledge that helped it bridge the gap between simulation and reality.
Interestingly, Nvidia has also been experimenting with similar simulated physics systems, such as Eureka, that allow an AI model to rapidly learn to control a robotic arm in simulated space instead of the real world (since the physics can be accelerated inside the simulation, and thousands of simultaneous trials can take place). This method is likely to dramatically reduce the time and resources needed to train robots for complex interactions in the future.
Humans enjoyed playing against it
Beyond its technical achievements, the study also explored the human experience of playing against an AI opponent. Surprisingly, even players who lost to the robot reported enjoying the experience. “Across all skill groups and win rates, players agreed that playing with the robot was ‘fun’ and ‘engaging,'” the researchers noted. This positive reception suggests potential applications for AI in sports training and entertainment.
However, the system is not without limitations. It struggles with extremely fast or high balls, has difficulty reading intense spin, and shows weaker performance in backhand plays. Google DeepMind shared an example video of the AI agent losing a point to an advanced player due to what appears to be difficulty reacting to a speedy hit, as you can see below.
A Google DeepMind video of the AI agent playing against an advanced human player.
The implications of this robotic ping-pong prodigy extend beyond the world of table tennis, according to the researchers. The techniques developed for this project could be applied to a wide range of robotic tasks that require quick reactions and adaptation to unpredictable human behavior. From manufacturing to health care (or just spanking someone with a paddle repeatedly), the potential applications seem large indeed.
The research team at Google DeepMind emphasizes that with further refinement, they believe the system could potentially compete with advanced table tennis players in the future. DeepMind is no stranger to creating AI models that can defeat human game players, including AlphaZero and AlphaGo. With this latest robot agent, it’s looking like the research company is moving beyond board games and into physical sports. Chess and Jeopardy have already fallen to AI-powered victors—perhaps table tennis is next.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}