Some AI tools don’t understand biology yet
A collection of new studies on gene activity shows that AI tools aren’t very good.
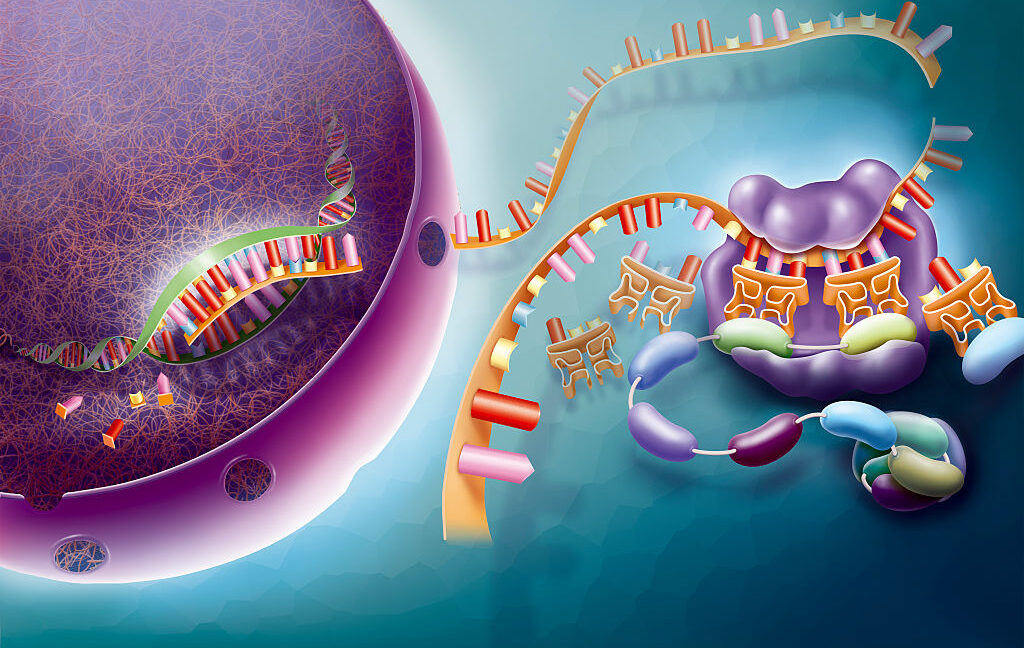
Gene activity appears to remain beyond the abilities of AI at the moment. Credit: BSIP
Biology is an area of science where AI and machine-learning approaches have seen some spectacular successes, such as designing enzymes to digest plastics and proteins to block snake venom. But in an era of seemingly endless AI hype, it might be easy to think that we could just set AI loose on the mounds of data we’ve already generated and end up with a good understanding of most areas of biology, allowing us to skip a lot of messy experiments and the unpleasantness of research on animals.
But biology involves a whole lot more than just protein structures. And it’s extremely premature to suggest that AI can be equally effective at handling all aspects of biology. So we were intrigued to see a study comparing a set of AI software packages designed to predict how active genes will be in cells exposed to different conditions. As it turns out, the AI systems couldn’t manage to do any better than a deliberately simplified method of predicting.
The results serve as a useful caution that biology is incredibly complex, and developing AI systems that work for one aspect of it is not an indication that they can work for biology generally.
AI and gene activity
The study was conducted by a trio of researchers based in Heidelberg: Constantin Ahlmann-Eltze, Wolfgang Huber, and Simon Anders. They note that a handful of additional studies have been released while their work was on a pre-print server, all of them coming to roughly the same conclusions. But these authors’ approach is pretty easy to understand, so we’ll use it as an example.
The AI software they examined attempts to predict changes in gene activity. While every cell carries copies of the roughly 20,000 genes in the human genome, not all of them are active in a given cell—”active” in this case meaning they are producing messenger RNAs. Some provide an essential function and are active at high levels at all times. Others are only active in specific cell types, like nerves or skin. Still others are activated under specific conditions, like low oxygen or high temperatures.
Over the years, we’ve done many studies examining the activity of every gene in a given cell type under different conditions. These studies can range from using gene chips to determine which messenger RNAs are present in a population of cells to sequencing the RNAs isolated from single cells and using that data to identify which genes are active. But collectively, they can provide a broad, if incomplete, picture that links the activity of genes with different biological circumstances. It’s a picture you could potentially use to train an AI that would make predictions about gene activity under conditions that haven’t been tested.
Ahlmann-Eltze, Huber, and Anders tested a set of what are called single-cell foundation models that have been trained on this sort of gene activity data. The “single cell” portion indicates that these models have been trained on gene activity obtained from individual cells rather than a population average of a cell type. Foundation models mean that they have been trained on a broad range of data but will require additional training before they’re deployed for a specific task.
Underwhelming performance
The task in this case is predicting how gene activity might change when genes are altered. When an individual gene is lost or activated, it’s possible that the only messenger RNA that is altered is the one made by that gene. But some genes encode proteins that regulate a collection of other genes, in which case you might see changes in the activity of dozens of genes. In other cases, the loss or activation of a gene could affect a cell’s metabolism, resulting in widespread alterations of gene activity.
Things get even more complicated when two genes are involved. In many cases, the genes will do unrelated things, and you get a simple additive effect: the changes caused by the loss of one, plus the changes caused by the loss of others. But if there’s some overlap between the functions, you can get an enhancement of some changes, suppression of others, and other unexpected changes.
To start exploring these effects, researchers have intentionally altered the activity of one or more genes using the CRISPR DNA editing technology, then sequenced every RNA in the cell afterward to see what sorts of changes took place. This approach (termed Perturb-seq) is useful because it can give us a sense of what the altered gene does in a cell. But for Ahlmann-Eltze, Huber, and Anders, it provides the data they need to determine if these foundation models can be trained to predict the ensuing changes in the activity of other genes.
Starting with the foundation models, the researchers conducted additional training using data from an experiment where either one or two genes were activated using CRISPR. This training used the data from 100 individual gene activations and another 62 where two genes were activated. Then, the AI packages were asked to predict the results for another 62 pairs of genes that were activated. For comparison, the researchers also made predictions using two extremely simple models: one that always predicted that nothing would change and a second that always predicted an additive effect (meaning that activating genes A and B would produce the changes caused by activating A plus the changes caused by activating B).
They didn’t work. “All models had a prediction error substantially higher than the additive baseline,” the researchers concluded. The result held when the researchers used alternative measurements of the accuracy of the AI’s predictions.
The gist of the problem seemed to be that the trained foundation models weren’t very good at predicting when the alterations of pairs of genes would produce complex patterns of changes—when the alteration of one gene synergized with the alteration of a second. “The deep learning models rarely predicted synergistic interactions, and it was even rarer that those predictions were correct,” the researchers concluded. In a separate test that looked specifically at these synergies between genes, it turned out that none of the models were better than the simplified system that always predicted no changes.
Not there yet
The overall conclusions from the work are pretty clear. “As our deliberately simple baselines are incapable of representing realistic biological complexity yet were not outperformed by the foundation models,” the researchers write, “we conclude that the latter’s goal of providing a generalizable representation of cellular states and predicting the outcome of not-yet-performed experiments is still elusive.”
It’s important to emphasize that “still elusive” doesn’t mean we’re incapable of ever developing an AI that can help with this problem. It also doesn’t mean that this applies to all cellular states (the results are specific to gene activity), much less all of biology. At the same time, the work provides a valuable caution at a time when there’s a lot of enthusiasm for the idea that AI’s success in a couple of areas means we’re on the cusp of a world where it can be applied to anything.
Nature Methods, 2025. DOI: 10.1038/s41592-025-02772-6 (About DOIs).

John is Ars Technica’s science editor. He has a Bachelor of Arts in Biochemistry from Columbia University, and a Ph.D. in Molecular and Cell Biology from the University of California, Berkeley. When physically separated from his keyboard, he tends to seek out a bicycle, or a scenic location for communing with his hiking boots.
Some AI tools don’t understand biology yet Read More »
{kind=link}
{kind=link}