OpenAI’s new AI image generator is potent and bound to provoke
The visual apocalypse is probably nigh, but perhaps seeing was never believing.
A trio of AI-generated images created using OpenAI’s 4o Image Generation model in ChatGPT. Credit: OpenAI
The arrival of OpenAI’s DALL-E 2 in the spring of 2022 marked a turning point in AI when text-to-image generation suddenly became accessible to a select group of users, creating a community of digital explorers who experienced wonder and controversy as the technology automated the act of visual creation.
But like many early AI systems, DALL-E 2 struggled with consistent text rendering, often producing garbled words and phrases within images. It also had limitations in following complex prompts with multiple elements, sometimes missing key details or misinterpreting instructions. These shortcomings left room for improvement that OpenAI would address in subsequent iterations, such as DALL-E 3 in 2023.
On Tuesday, OpenAI announced new multimodal image generation capabilities that are directly integrated into its GPT-4o AI language model, making it the default image generator within the ChatGPT interface. The integration, called “4o Image Generation” (which we’ll call “4o IG” for short), allows the model to follow prompts more accurately (with better text rendering than DALL-E 3) and respond to chat context for image modification instructions.
An AI-generated cat in a car drinking a can of beer created by OpenAI’s 4o Image Generation model. OpenAI
The new image generation feature began rolling out Tuesday to ChatGPT Free, Plus, Pro, and Team users, with Enterprise and Education access coming later. The capability is also available within OpenAI’s Sora video generation tool. OpenAI told Ars that the image generation when GPT-4.5 is selected calls upon the same 4o-based image generation model as when GPT-4o is selected in the ChatGPT interface.
Like DALL-E 2 before it, 4o IG is bound to provoke debate as it enables sophisticated media manipulation capabilities that were once the domain of sci-fi and skilled human creators into an accessible AI tool that people can use through simple text prompts. It will also likely ignite a new round of controversy over artistic styles and copyright—but more on that below.
Some users on social media initially reported confusion since there’s no UI indication of which image generator is active, but you’ll know it’s the new model if the generation is ultra slow and proceeds from top to bottom. The previous DALL-E model remains available through a dedicated “DALL-E GPT” interface, while API access to GPT-4o image generation is expected within weeks.
Truly multimodal output
4o IG represents a shift to “native multimodal image generation,” where the large language model processes and outputs image data directly as tokens. That’s a big deal, because it means image tokens and text tokens share the same neural network. It leads to new flexibility in image creation and modification.
Despite baking-in multimodal image generation capabilities when GPT-4o launched in May 2024—when the “o” in GPT-4o was touted as standing for “omni” to highlight its ability to both understand and generate text, images, and audio—OpenAI has taken over 10 months to deliver the functionality to users, despite OpenAI president Greg Brock teasing the feature on X last year.
OpenAI was likely goaded by the release of Google’s multimodal LLM-based image generator called “Gemini 2.0 Flash (Image Generation) Experimental,” last week. The tech giants continue their AI arms race, with each attempting to one-up the other.
And perhaps we know why OpenAI waited: At a reasonable resolution and level of detail, the new 4o IG process is extremely slow, taking anywhere from 30 seconds to one minute (or longer) for each image.
Even if it’s slow (for now), the ability to generate images using a purely autoregressive approach is arguably a major leap for OpenAI due to its flexibility. But it’s also very compute-intensive, since the model generates the image token by token, building it sequentially. This contrasts with diffusion-based methods like DALL-E 3, which start with random noise and gradually refine an entire image over many iterative steps.
Conversational image editing
In a blog post, OpenAI positions 4o Image Generation as moving beyond generating “surreal, breathtaking scenes” seen with earlier AI image generators and toward creating “workhorse imagery” like logos and diagrams used for communication.
The company particularly notes improved text rendering within images, a capability where previous text-to-image models often spectacularly failed, often turning “Happy Birthday” into something resembling alien hieroglyphics.
OpenAI claims several key improvements: users can refine images through conversation while maintaining visual consistency; the system can analyze uploaded images and incorporate their details into new generations; and it offers stronger photorealism—although what constitutes photorealism (for example, imitations of HDR camera features, detail level, and image contrast) can be subjective.
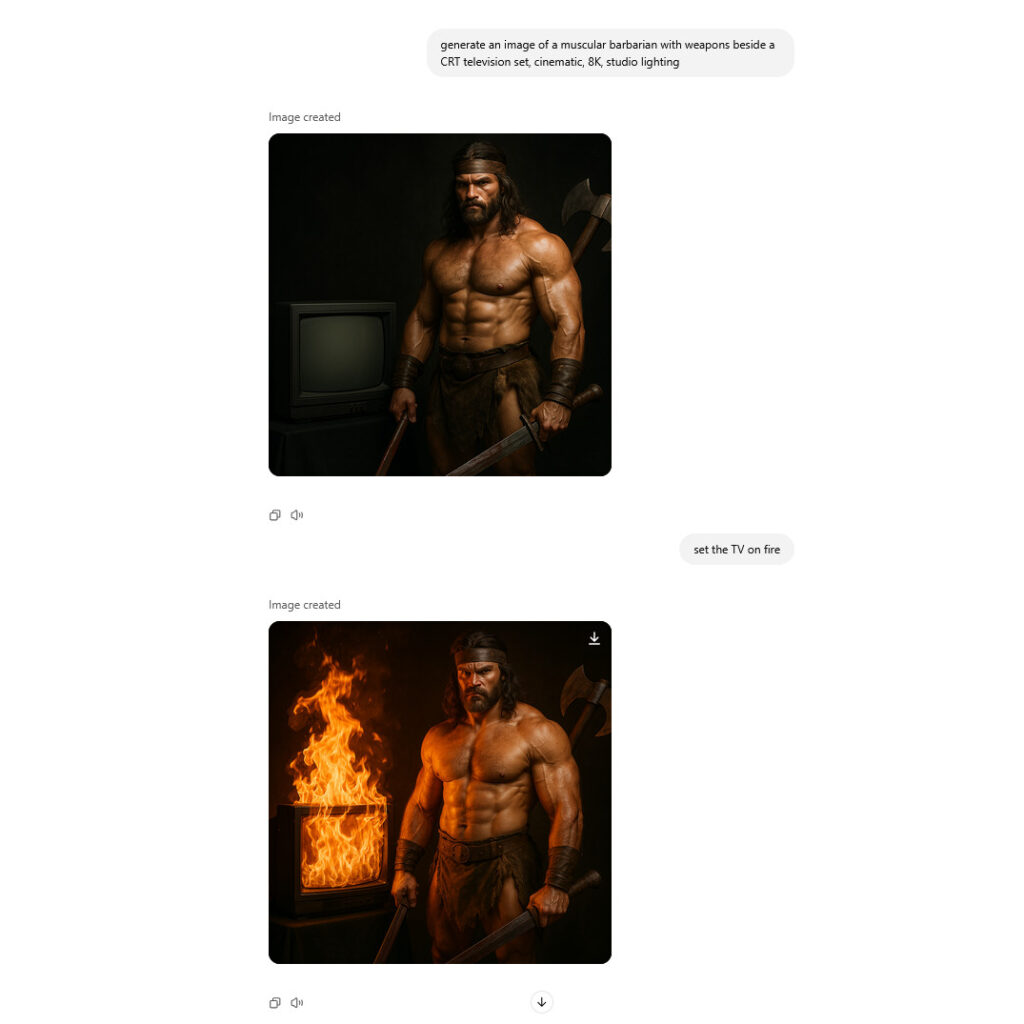
A screenshot of OpenAI’s 4o Image Generation model in ChatGPT. We see an existing AI-generated image of a barbarian and a TV set, then a request to set the TV set on fire. Credit: OpenAI / Benj Edwards
In its blog post, OpenAI provided examples of intended uses for the image generator, including creating diagrams, infographics, social media graphics using specific color codes, logos, instruction posters, business cards, custom stock photos with transparent backgrounds, editing user photos, or visualizing concepts discussed earlier in a chat conversation.
Notably absent: Any mention of the artists and graphic designers whose jobs might be affected by this technology. As we covered throughout 2022 and 2023, job impact is still a top concern among critics of AI-generated graphics.
Fluid media manipulation
Shortly after OpenAI launched 4o Image Generation, the AI community on X put the feature through its paces, finding that it is quite capable at inserting someone’s face into an existing image, creating fake screenshots, and converting meme photos into the style of Studio Ghibli, South Park, felt, Muppets, Rick and Morty, Family Guy, and much more.
It seems like we’re entering a completely fluid media “reality” courtesy of a tool that can effortlessly convert visual media between styles. The styles also potentially encroach upon protected intellectual property. Given what Studio Ghibli co-founder Hayao Miyazaki has previously said about AI-generated artwork (“I strongly feel that this is an insult to life itself.”), it seems he’d be unlikely to appreciate the current AI-generated Ghibli fad on X at the moment.
To get a sense of what 4o IG can do ourselves, we ran some informal tests, including some of the usual CRT barbarians, queens of the universe, and beer-drinking cats, which you’ve already seen above (and of course, the plate of pickles.)
The ChatGPT interface with the new 4o image model is conversational (like before with DALL-E 3), but you can suggest changes over time. For example, we took the author’s EGA pixel bio (as we did with Google’s model last week) and attempted to give it a full body. Arguably, Google’s more limited image model did a far better job than 4o IG.

Giving the author’s pixel avatar a body using OpenAI’s 4o Image Generation model in ChatGPT. Credit: OpenAI / Benj Edwards
While my pixel avatar was commissioned from the very human (and talented) Julia Minamata in 2020, I also tried to convert the inspiration image for my avatar (which features me and legendary video game engineer Ed Smith) into EGA pixel style to see what would happen. In my opinion, the result proves the continued superiority of human artistry and attention to detail.
![]()
Converting a photo of Benj Edwards and video game legend Ed Smith into “EGA pixel art” using OpenAI’s 4o Image Generation model in ChatGPT. Credit: OpenAI / Benj Edwards
We also tried to see how many objects 4o Image Generation could cram into an image, inspired by a 2023 tweet by Nathan Shipley when he was evaluating DALL-E 3 shortly after its release. We did not account for every object, but it looks like most of them are there.

Generating an image of a surfer holding tons of items, inspired by a 2023 Twitter post from Nathan Shipley. Credit: OpenAI / Benj Edwards
On social media, other people have manipulated images using 4o IG (like Simon Willison’s bear selfie), so we tried changing an AI-generated note featured in an article last year. It worked fairly well, though it did not really imitate the handwriting style as requested.
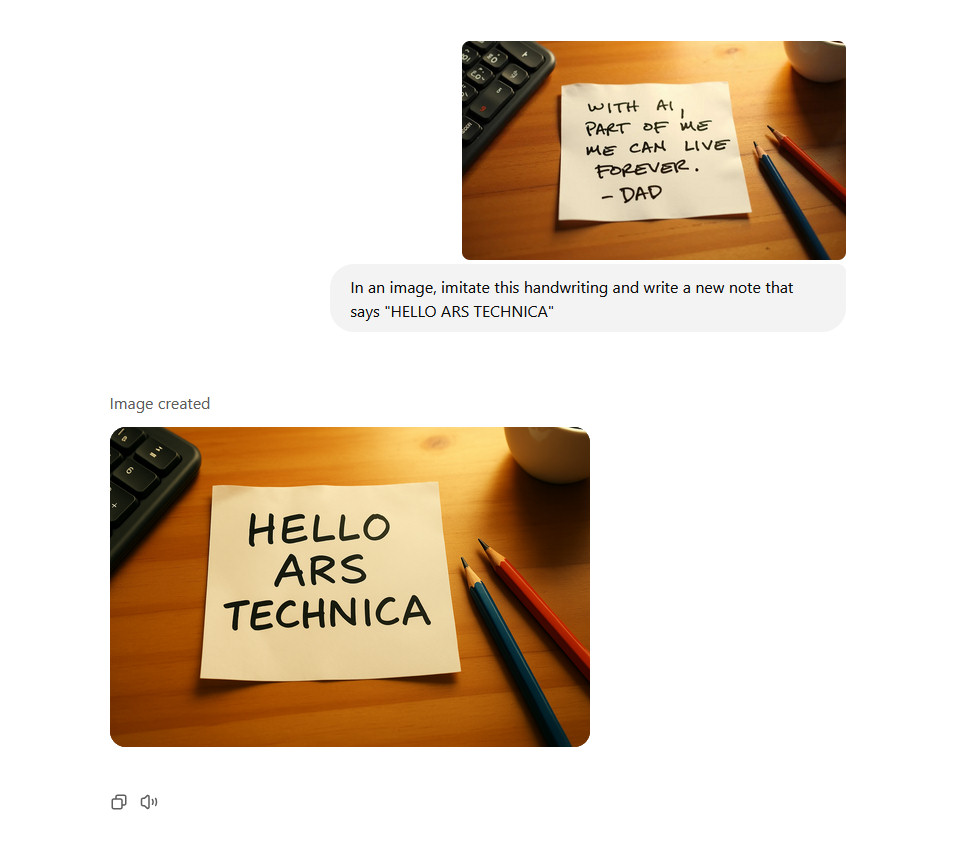
Modifying text in an image using OpenAI’s 4o Image Generation model in ChatGPT. Credit: OpenAI / Benj Edwards
To take text generation a little further, we generated a poem about barbarians using ChatGPT, then fed it into an image prompt. The result feels roughly equivalent to diffusion-based Flux in capability—maybe slightly better—but there are still some obvious mistakes here and there, such as repeated letters.
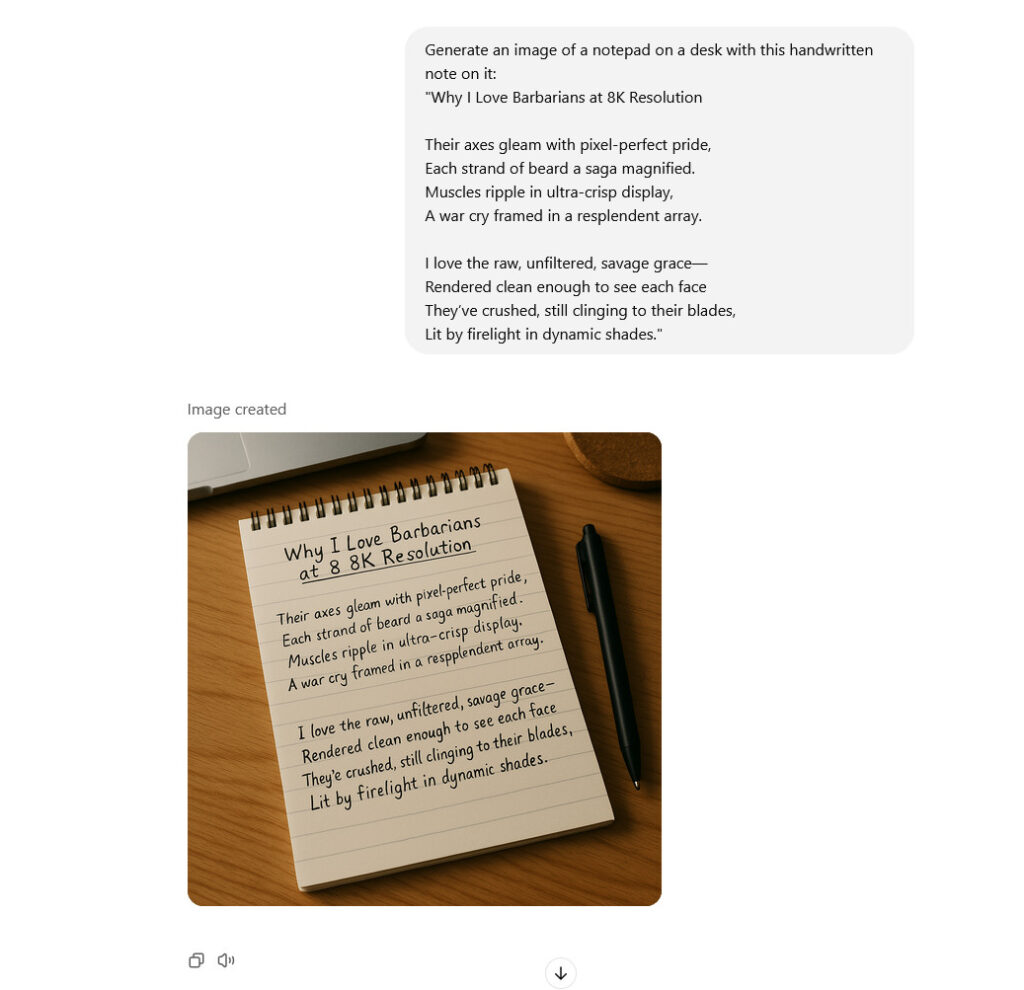
Testing text generation using OpenAI’s 4o Image Generation model in ChatGPT. Credit: OpenAI / Benj Edwards
We also tested the model’s ability to create logos featuring our favorite fictional Moonshark brand. One of the logos not pictured here was delivered as a transparent PNG file with an alpha channel. This may be a useful capability for some people in a pinch, but to the extent that the model may produce “good enough” (not exceptional, but looks OK at a glance) logos for the price of $o (not including an OpenAI subscription), it may end up competing with some human logo designers, and that will likely cause some consternation among professional artists.
![]()
Generating a “Moonshark Moon Pies” logo using OpenAI’s 4o Image Generation model in ChatGPT. Credit: OpenAI / Benj Edwards
Frankly, this model is so slow we didn’t have time to test everything before we needed to get this article out the door. It can do much more than we have shown here—such as adding items to scenes or removing them. We may explore more capabilities in a future article.
Limitations
By now, you’ve seen that, like previous AI image generators, 4o IG is not perfect in quality: It consistently renders the author’s nose at an incorrect size.
Other than that, while this is one of the most capable AI image generators ever created, OpenAI openly acknowledges significant limitations of the model. For example, 4o IG sometimes crops images too tightly or includes inaccurate information (confabulations) with vague prompts or when rendering topics it hasn’t encountered in its training data.
The model also tends to fail when rendering more than 10–20 objects or concepts simultaneously (making tasks like generating an accurate periodic table currently impossible) and struggles with non-Latin text fonts. Image editing is currently unreliable over many multiple passes, with a specific bug affecting face editing consistency that OpenAI says it plans to fix soon. And it’s not great with dense charts or accurately rendering graphs or technical diagrams. In our testing, 4o Image Generation produced mostly accurate but flawed electronic circuit schematics.
Move fast and break everything
Even with those limitations, multimodal image generators are an early step into a much larger world of completely plastic media reality where any pixel can be manipulated on demand with no particular photo editing skill required. That brings with it potential benefits, ethical pitfalls, and the potential for terrible abuse.
In a notable shift from DALL-E, OpenAI now allows 4o IG to generate adult public figures (not children) with certain safeguards, while letting public figures opt out if desired. Like DALL-E, the model still blocks policy-violating content requests (such as graphic violence, nudity, and sex).
The ability for 4o Image Generation to imitate celebrity likenesses, brand logos, and Studio Ghibli films reinforces and reminds us how GPT-4o is partly (aside from some licensed content) a product of a massive scrape of the Internet without regard to copyright or consent from artists. That mass-scraping practice has resulted in lawsuits against OpenAI in the past, and we would not be surprised to see more lawsuits or at least public complaints from celebrities (or their estates) about their likenesses potentially being misused.
On X, OpenAI CEO Sam Altman wrote about the company’s somewhat devil-may-care position about 4o IG: “This represents a new high-water mark for us in allowing creative freedom. People are going to create some really amazing stuff and some stuff that may offend people; what we’d like to aim for is that the tool doesn’t create offensive stuff unless you want it to, in which case within reason it does.”

An original photo of the author beside AI-generated images created by OpenAI’s 4o Image Generation model. From second left to right: Studio Ghibli style, Muppet style, and pasta style. Credit: OpenAI / Benj Edwards
Zooming out, GPT-4o’s image generation model (and the technology behind it, once open source) feels like it further erodes trust in remotely produced media. While we’ve always needed to verify important media through context and trusted sources, these new tools may further expand the “deep doubt” media skepticism that’s become necessary in the age of AI. By opening up photorealistic image manipulation to the masses, more people than ever can create or alter visual media without specialized skills.
While OpenAI includes C2PA metadata in all generated images, that data can be stripped away and might not matter much in the context of a deceptive social media post. But 4o IG doesn’t change what has always been true: We judge information primarily by the reputation of its messenger, not by the pixels themselves. Forgery existed long before AI. It reinforces that everyone needs media literacy skills—understanding that context and source verification have always been the best arbiters of media authenticity.
For now, Altman is ready to take on the risks of releasing the technology into the world. “As we talk about in our model spec, we think putting this intellectual freedom and control in the hands of users is the right thing to do, but we will observe how it goes and listen to society,” Altman wrote on X. “We think respecting the very wide bounds society will eventually choose to set for AI is the right thing to do, and increasingly important as we get closer to AGI. Thanks in advance for the understanding as we work through this.”

Benj Edwards is Ars Technica’s Senior AI Reporter and founder of the site’s dedicated AI beat in 2022. He’s also a tech historian with almost two decades of experience. In his free time, he writes and records music, collects vintage computers, and enjoys nature. He lives in Raleigh, NC.
OpenAI’s new AI image generator is potent and bound to provoke Read More »