On Thursday, OpenAI released an early Windows version of its first ChatGPT app for Windows, following a Mac version that launched in May. Currently, it’s only available to subscribers of Plus, Team, Enterprise, and Edu versions of ChatGPT, and users can download it for free in the Microsoft Store for Windows.
OpenAI is positioning the release as a beta test. “This is an early version, and we plan to bring the full experience to all users later this year,” OpenAI writes on the Microsoft Store entry for the app. (Interestingly, ChatGPT shows up as being rated “T for Teen” by the ESRB in the Windows store, despite not being a video game.)
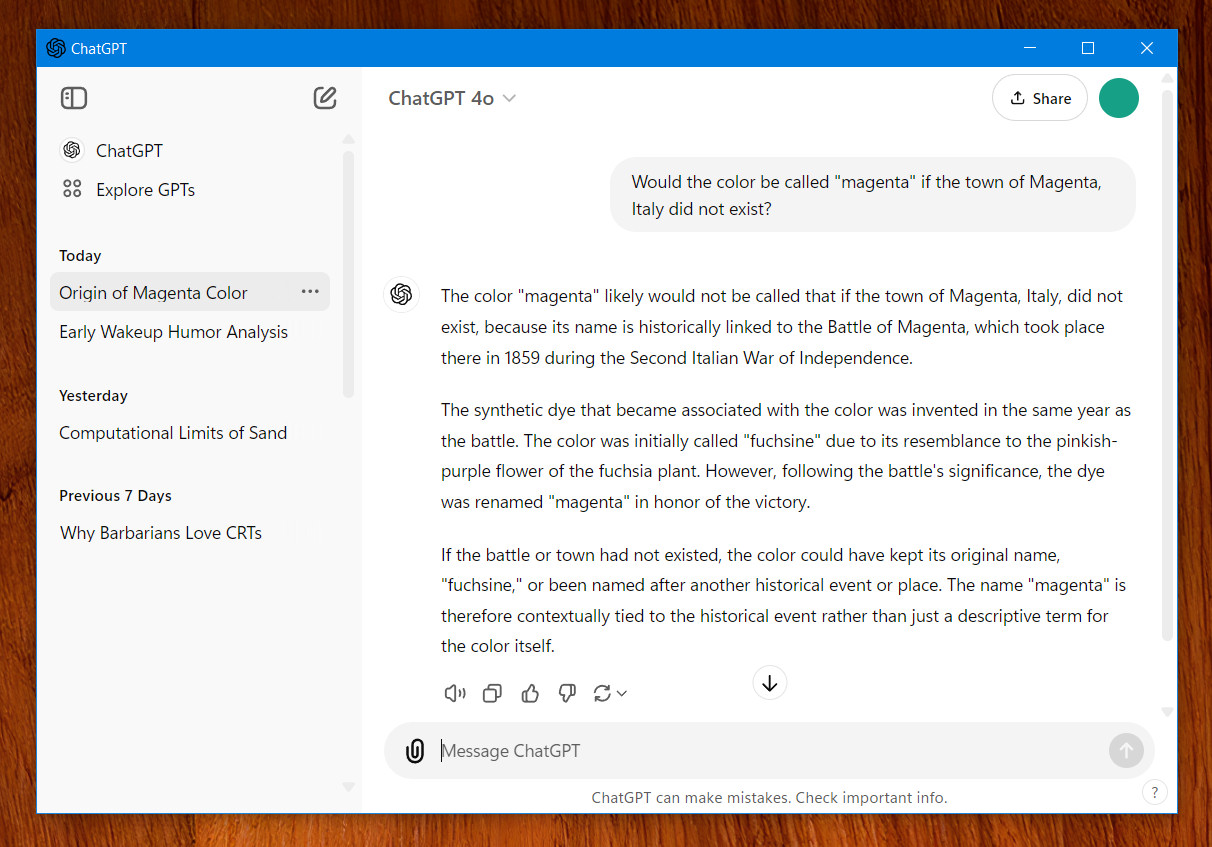
A screenshot of the new Windows ChatGPT app captured on October 18, 2024.
Credit: Benj Edwards
A screenshot of the new Windows ChatGPT app captured on October 18, 2024. Credit: Benj Edwards
Upon opening the app, OpenAI requires users to log into a paying ChatGPT account, and from there, the app is basically identical to the web browser version of ChatGPT. You can currently use it to access several models: GPT-4o, GPT-4o with Canvas, 01-preview, 01-mini, GPT-4o mini, and GPT-4. Also, it can generate images using DALL-E 3 or analyze uploaded files and images.
If you’re running Windows 11, you can instantly call up a small ChatGPT window when the app is open using an Alt+Space shortcut (it did not work in Windows 10 when we tried). That could be handy for asking ChatGPT a quick question at any time.
A screenshot of the new Windows ChatGPT app listing in the Microsoft Store captured on October 18, 2024.
Credit: Benj Edwards
A screenshot of the new Windows ChatGPT app listing in the Microsoft Store captured on October 18, 2024. Credit: Benj Edwards
And just like the web version, all the AI processing takes place in the cloud on OpenAI’s servers, which means an Internet connection is required.
So as usual, chat like somebody’s watching, and don’t rely on ChatGPT as a factual reference for important decisions—GPT-4o in particular is great at telling you what you want to hear, whether it’s correct or not. As OpenAI says in a small disclaimer at the bottom of the app window: “ChatGPT can make mistakes.”
On Friday, Meta announced a preview of Movie Gen, a new suite of AI models designed to create and manipulate video, audio, and images, including creating a realistic video from a single photo of a person. The company claims the models outperform other video-synthesis models when evaluated by humans, pushing us closer to a future where anyone can synthesize a full video of any subject on demand.
The company does not yet have plans of when or how it will release these capabilities to the public, but Meta says Movie Gen is a tool that may allow people to “enhance their inherent creativity” rather than replace human artists and animators. The company envisions future applications such as easily creating and editing “day in the life” videos for social media platforms or generating personalized animated birthday greetings.
Movie Gen builds on Meta’s previous work in video synthesis, following 2022’s Make-A-Scene video generator and the Emu image-synthesis model. Using text prompts for guidance, this latest system can generate custom videos with sounds for the first time, edit and insert changes into existing videos, and transform images of people into realistic personalized videos.
An AI-generated video of a baby hippo swimming around, created with Meta Movie Gen.
Meta isn’t the only game in town when it comes to AI video synthesis. Google showed off a new model called “Veo” in May, and Meta says that in human preference tests, its Movie Gen outputs beat OpenAI’s Sora, Runway Gen-3, and Chinese video model Kling.
Movie Gen’s video-generation model can create 1080p high-definition videos up to 16 seconds long at 16 frames per second from text descriptions or an image input. Meta claims the model can handle complex concepts like object motion, subject-object interactions, and camera movements.
AI-generated video from Meta Movie Gen with the prompt: “A ghost in a white bedsheet faces a mirror. The ghost’s reflection can be seen in the mirror. The ghost is in a dusty attic, filled with old beams, cloth-covered furniture. The attic is reflected in the mirror. The light is cool and natural. The ghost dances in front of the mirror.”
Even so, as we’ve seen with previous AI video generators, Movie Gen’s ability to generate coherent scenes on a particular topic is likely dependent on the concepts found in the example videos that Meta used to train its video-synthesis model. It’s worth keeping in mind that cherry-picked results from video generators often differ dramatically from typical results and getting a coherent result may require lots of trial and error.
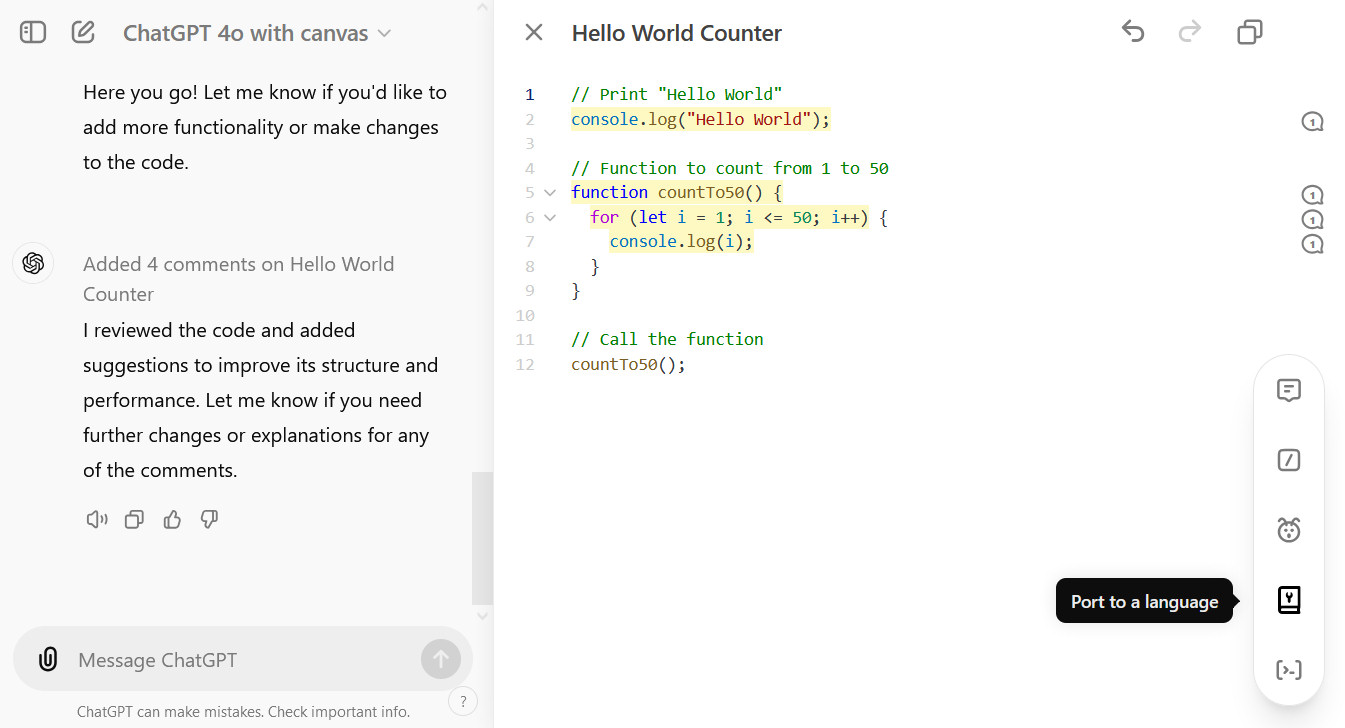
Coding shortcuts in canvas include reviewing code, adding logs for debugging, inserting comments, fixing bugs, and porting code to different programming languages. For example, if your code is JavaScript, with a few clicks it can become PHP, TypeScript, Python, C++, or Java. As with GPT-4o by itself, you’ll probably still have to check it for mistakes.
A screenshot of coding using ChatGPT with Canvas captured on October 4, 2024.
Credit: Benj Edwards
A screenshot of coding using ChatGPT with Canvas captured on October 4, 2024. Credit: Benj Edwards
Also, users can highlight specific sections to direct ChatGPT’s focus, and the AI model can provide inline feedback and suggestions while considering the entire project, much like a copy editor or code reviewer. And the interface makes it easy to restore previous versions of a working document using a back button in the Canvas interface.
A new AI model
OpenAI says its research team developed new core behaviors for GPT-4o to support Canvas, including triggering the canvas for appropriate tasks, generating certain content types, making targeted edits, rewriting documents, and providing inline critique.
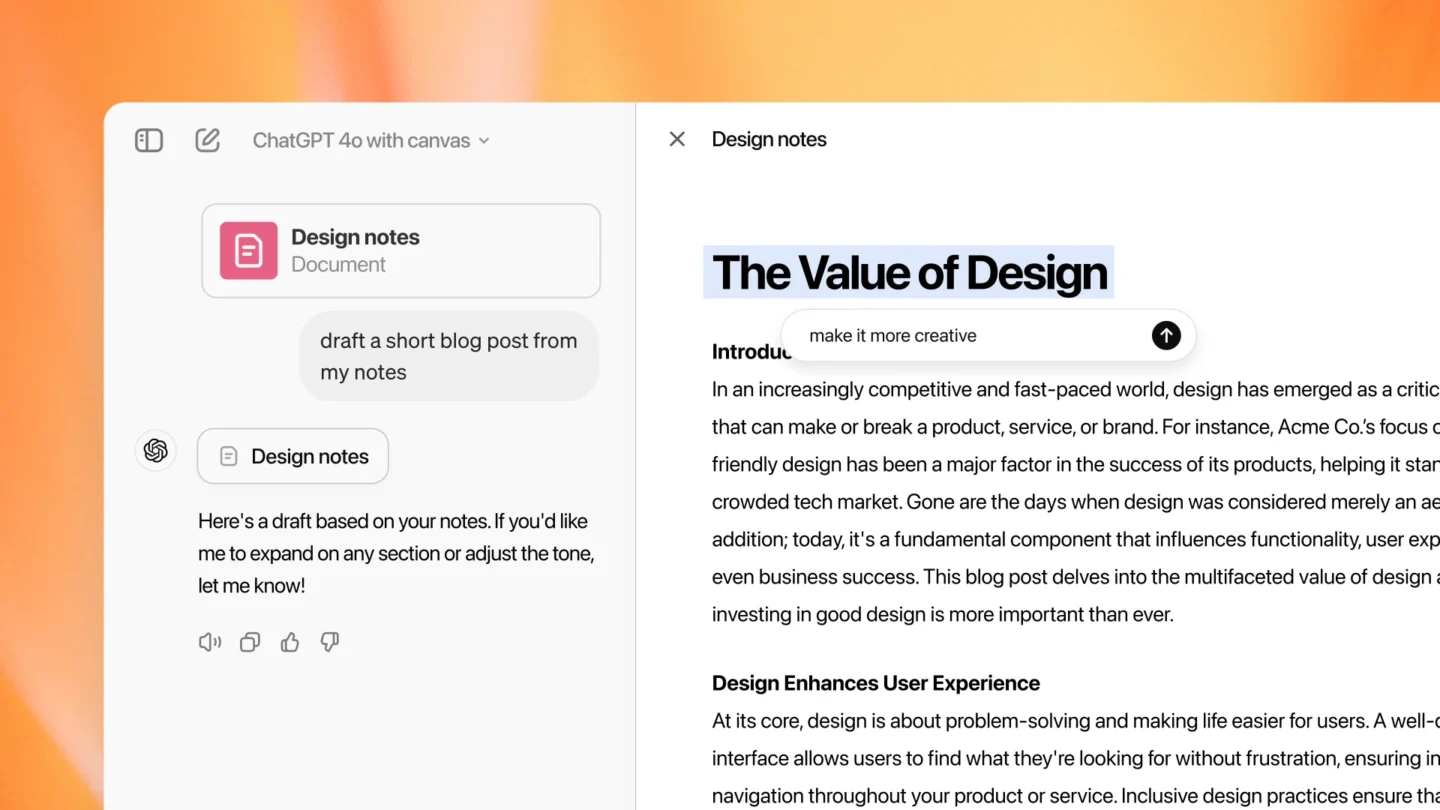
An image of OpenAI’s Canvas in action.
An image of OpenAI’s Canvas in action. Credit: OpenAI
One key challenge in development, according to OpenAI, was defining when to trigger a canvas. In an example on the Canvas blog post, the team says it taught the model to open a canvas for prompts like “Write a blog post about the history of coffee beans” while avoiding triggering Canvas for general Q&A tasks like “Help me cook a new recipe for dinner.”
Another challenge involved tuning the model’s editing behavior once canvas was triggered, specifically deciding between targeted edits and full rewrites. The team trained the model to perform targeted edits when users specifically select text through the interface, otherwise favoring rewrites.
The company noted that canvas represents the first major update to ChatGPT’s visual interface since its launch two years ago. While canvas is still in early beta, OpenAI plans to improve its capabilities based on user feedback over time.
On Monday, Microsoft unveiled updates to its consumer AI assistant Copilot, introducing two new experimental features for a limited group of $20/month Copilot Pro subscribers: Copilot Labs and Copilot Vision. Labs integrates OpenAI’s latest o1 “reasoning” model, and Vision allows Copilot to see what you’re browsing in Edge.
Microsoft says Copilot Labs will serve as a testing ground for Microsoft’s latest AI tools before they see wider release. The company describes it as offering “a glimpse into ‘work-in-progress’ projects.” The first feature available in Labs is called “Think Deeper,” and it uses step-by-step processing to solve more complex problems than the regular Copilot. Think Deeper is Microsoft’s version of OpenAI’s new o1-preview and o1-mini AI models, and it has so far rolled out to some Copilot Pro users in Australia, Canada, New Zealand, the UK, and the US.
Copilot Vision is an entirely different beast. The new feature aims to give the AI assistant a visual window into what you’re doing within the Microsoft Edge browser. When enabled, Copilot can “understand the page you’re viewing and answer questions about its content,” according to Microsoft.
Microsoft’s Copilot Vision promo video.
The company positions Copilot Vision as a way to provide more natural interactions and task assistance beyond text-based prompts, but it will likely raise privacy concerns. As a result, Microsoft says that Copilot Vision is entirely opt-in and that no audio, images, text, or conversations from Vision will be stored or used for training. The company is also initially limiting Vision’s use to a pre-approved list of websites, blocking it on paywalled and sensitive content.
The rollout of these features appears gradual, with Microsoft noting that it wants to balance “pioneering features and a deep sense of responsibility.” The company said it will be “listening carefully” to user feedback as it expands access to the new capabilities. Microsoft has not provided a timeline for wider availability of either feature.
Mustafa Suleyman, chief executive of Microsoft AI, told Reuters that he sees Copilot as an “ever-present confidant” that could potentially learn from users’ various Microsoft-connected devices and documents, with permission. He also mentioned that Microsoft co-founder Bill Gates has shown particular interest in Copilot’s potential to read and parse emails.
But judging by the visceral reaction to Microsoft’s Recall feature, which keeps a record of everything you do on your PC so an AI model can recall it later, privacy-sensitive users may not appreciate having an AI assistant monitor their activities—especially if those features send user data to the cloud for processing.
OpenAI, the company behind ChatGPT, has now raised $6.6 billion in a new funding round that values the company at $157 billion, nearly doubling its previous valuation of $86 billion, according to a report from The Wall Street Journal.
The funding round comes with strings attached: Investors have the right to withdraw their money if OpenAI does not complete its planned conversion from a nonprofit (with a for-profit division) to a fully for-profit company.
Venture capital firm Thrive Capital led the funding round with a $1.25 billion investment. Microsoft, a longtime backer of OpenAI to the tune of $13 billion, contributed just under $1 billion to the latest round. New investors joined the round, including SoftBank with a $500 million investment and Nvidia with $100 million.
The United Arab Emirates-based company MGX also invested in OpenAI during this funding round. MGX has been busy in AI recently, joining an AI infrastructure partnership last month led by Microsoft.
Notably, Apple was in talks to invest but ultimately did not participate. WSJ reports that the minimum investment required to review OpenAI’s financial documents was $250 million. In June, OpenAI hired its first chief financial officer, Sarah Friar, who played an important role in organizing this funding round, according to the WSJ.
On Monday, OpenAI kicked off its annual DevDay event in San Francisco, unveiling four major API updates for developers that integrate the company’s AI models into their products. Unlike last year’s single-location event featuring a keynote by CEO Sam Altman, DevDay 2024 is more than just one day, adopting a global approach with additional events planned for London on October 30 and Singapore on November 21.
The San Francisco event, which was invitation-only and closed to press, featured on-stage speakers going through technical presentations. Perhaps the most notable new API feature is the Realtime API, now in public beta, which supports speech-to-speech conversations using six preset voices and enables developers to build features very similar to ChatGPT’s Advanced Voice Mode (AVM) into their applications.
OpenAI says that the Realtime API streamlines the process of creating voice assistants. Previously, developers had to use multiple models for speech recognition, text processing, and text-to-speech conversion. Now, they can handle the entire process with a single API call.
The company plans to add audio input and output capabilities to its Chat Completions API in the next few weeks, allowing developers to input text or audio and receive responses in either format.
Two new options for cheaper inference
OpenAI also announced two features that may help developers balance performance and cost when making AI applications. “Model distillation” offers a way for developers to fine-tune (customize) smaller, cheaper models like GPT-4o mini using outputs from more advanced models such as GPT-4o and o1-preview. This potentially allows developers to get more relevant and accurate outputs while running the cheaper model.
Also, OpenAI announced “prompt caching,” a feature similar to one introduced by Anthropic for its Claude API in August. It speeds up inference (the AI model generating outputs) by remembering frequently used prompts (input tokens). Along the way, the feature provides a 50 percent discount on input tokens and faster processing times by reusing recently seen input tokens.
And last but not least, the company expanded its fine-tuning capabilities to include images (what it calls “vision fine-tuning”), allowing developers to customize GPT-4o by feeding it both custom images and text. Basically, developers can teach the multimodal version of GPT-4o to visually recognize certain things. OpenAI says the new feature opens up possibilities for improved visual search functionality, more accurate object detection for autonomous vehicles, and possibly enhanced medical image analysis.
Where’s the Sam Altman keynote?
Enlarge/ OpenAI CEO Sam Altman speaks during the OpenAI DevDay event on November 6, 2023, in San Francisco.
Getty Images
Unlike last year, DevDay isn’t being streamed live, though OpenAI plans to post content later on its YouTube channel. The event’s programming includes breakout sessions, community spotlights, and demos. But the biggest change since last year is the lack of a keynote appearance from the company’s CEO. This year, the keynote was handled by the OpenAI product team.
On last year’s inaugural DevDay, November 6, 2023, OpenAI CEO Sam Altman delivered a Steve Jobs-style live keynote to assembled developers, OpenAI employees, and the press. During his presentation, Microsoft CEO Satya Nadella made a surprise appearance, talking up the partnership between the companies.
Eleven days later, the OpenAI board fired Altman, triggering a week of turmoil that resulted in Altman’s return as CEO and a new board of directors. Just after the firing, Kara Swisher relayed insider sources that said Altman’s DevDay keynote and the introduction of the GPT store had been a precipitating factor in the firing (though not the key factor) due to some internal disagreements over the company’s more consumer-like direction since the launch of ChatGPT.
With that history in mind—and the focus on developers above all else for this event—perhaps the company decided it was best to let Altman step away from the keynote and let OpenAI’s technology become the key focus of the event instead of him. We are purely speculating on that point, but OpenAI has certainly experienced its share of drama over the past month, so it may have been a prudent decision.
Despite the lack of a keynote, Altman is present at Dev Day San Francisco today and is scheduled to do a closing “fireside chat” at the end (which has not yet happened as of this writing). Also, Altman made a statement about DevDay on X, noting that since last year’s DevDay, OpenAI had seen some dramatic changes (literally):
From last devday to this one:
*98% decrease in cost per token from GPT-4 to 4o mini *50x increase in token volume across our systems *excellent model intelligence progress *(and a little bit of drama along the way)
In a follow-up tweet delivered in his trademark lowercase, Altman shared a forward-looking message that referenced the company’s quest for human-level AI, often called AGI: “excited to make even more progress from this devday to the next one,” he wrote. “the path to agi has never felt more clear.”
Enlarge/ The Apple Park campus in Cupertino, California.
A few weeks back, it was reported that Apple was exploring investing in OpenAI, the company that makes ChatGPT, the GPT model, and other popular generative AI products. Now, a new report from The Wall Street Journal claims that Apple has abandoned those plans.
The article simply says Apple “fell out of the talks to join the round.” The round is expected to close in a week or so and may raise as much as $6.5 billion for the growing Silicon Valley company. Had Apple gone through with the move, it would have been a rare event—though not completely unprecedented—for Apple to invest in another company that size.
OpenAI is still expected to raise the funds it seeks from other sources. The report claims Microsoft is expected to invest around $1 billion in this round. Microsoft has already invested substantial sums in OpenAI, whose GPT models power Microsoft AI tools like Copilot and Bing chat.
Nvidia is also a likely major investor in this round.
Apple will soon offer limited ChatGPT integration in an upcoming iOS update, though it plans to support additional models like Google’s Gemini further down the line, offering users a choice similar to how they pick a default search engine or web browser.
OpenAI has been on a successful tear with its products and models, establishing itself as a leader in the rapidly growing industry. However, it has also been beset by drama and controversy—most recently, some key leaders at OpenAI departed the company abruptly, and it shifted its focus from a research-focused organization that was beholden to a nonprofit, to a for-profit company under CEO Sam Altman. Also, former Apple design lead Jony Ive is confirmed to be working on a new AI product of some kind.
But The Wall Street Journal did not specify which (if any) of these facts are reasons why Apple chose to back out of the investment.
Enlarge/ A screen capture of AJ Smith doing his Eleanor Rigby duet with OpenAI’s Advanced Voice Mode through the ChatGPT app.
OpenAI’s new Advanced Voice Mode (AVM) of its ChatGPT AI assistant rolled out to subscribers on Tuesday, and people are already finding novel ways to use it, even against OpenAI’s wishes. On Thursday, a software architect named AJ Smith tweeted a video of himself playing a duet of The Beatles’ 1966 song “Eleanor Rigby” with AVM. In the video, Smith plays the guitar and sings, with the AI voice interjecting and singing along sporadically, praising his rendition.
“Honestly, it was mind-blowing. The first time I did it, I wasn’t recording and literally got chills,” Smith told Ars Technica via text message. “I wasn’t even asking it to sing along.”
Smith is no stranger to AI topics. In his day job, he works as associate director of AI Engineering at S&P Global. “I use [AI] all the time and lead a team that uses AI day to day,” he told us.
In the video, AVM’s voice is a little quavery and not pitch-perfect, but it appears to know something about “Eleanor Rigby’s” melody when it first sings, “Ah, look at all the lonely people.” After that, it seems to be guessing at the melody and rhythm as it recites song lyrics. We have also convinced Advanced Voice Mode to sing, and it did a perfect melodic rendition of “Happy Birthday” after some coaxing.
AJ Smith’s video of singing a duet with OpenAI’s Advanced Voice Mode.
Normally, when you ask AVM to sing, it will reply something like, “My guidelines won’t let me talk about that.” That’s because in the chatbot’s initial instructions (called a “system prompt“), OpenAI instructs the voice assistant not to sing or make sound effects (“Do not sing or hum,” according to one system prompt leak).
OpenAI possibly added this restriction because AVM may otherwise reproduce copyrighted content, such as songs that were found in the training data used to create the AI model itself. That’s what is happening here to a limited extent, so in a sense, Smith has discovered a form of what researchers call a “prompt injection,” which is a way of convincing an AI model to produce outputs that go against its system instructions.
How did Smith do it? He figured out a game that reveals AVM knows more about music than it may let on in conversation. “I just said we’d play a game. I’d play the four pop chords and it would shout out songs for me to sing along with those chords,” Smith told us. “Which did work pretty well! But after a couple songs it started to sing along. Already it was such a unique experience, but that really took it to the next level.”
This is not the first time humans have played musical duets with computers. That type of research stretches back to the 1970s, although it was typically limited to reproducing musical notes or instrumental sounds. But this is the first time we’ve seen anyone duet with an audio-synthesizing voice chatbot in real time.
Enlarge/ There’s been a lot of AI news this week, and covering it sometimes feels like running through a hall full of danging CRTs, just like this Getty Images illustration.
But the rest of the AI world doesn’t march to the same beat, doing its own thing and churning out new AI models and research by the minute. Here’s a roundup of some other notable AI news from the past week.
Google Gemini updates
On Tuesday, Google announced updates to its Gemini model lineup, including the release of two new production-ready models that iterate on past releases: Gemini-1.5-Pro-002 and Gemini-1.5-Flash-002. The company reported improvements in overall quality, with notable gains in math, long context handling, and vision tasks. Google claims a 7 percent increase in performance on the MMLU-Pro benchmark and a 20 percent improvement in math-related tasks. But as you know, if you’ve been reading Ars Technica for a while, AI typically benchmarks aren’t as useful as we would like them to be.
Along with model upgrades, Google introduced substantial price reductions for Gemini 1.5 Pro, cutting input token costs by 64 percent and output token costs by 52 percent for prompts under 128,000 tokens. As AI researcher Simon Willison noted on his blog, “For comparison, GPT-4o is currently $5/[million tokens] input and $15/m output and Claude 3.5 Sonnet is $3/m input and $15/m output. Gemini 1.5 Pro was already the cheapest of the frontier models and now it’s even cheaper.”
Google also increased rate limits, with Gemini 1.5 Flash now supporting 2,000 requests per minute and Gemini 1.5 Pro handling 1,000 requests per minute. Google reports that the latest models offer twice the output speed and three times lower latency compared to previous versions. These changes may make it easier and more cost-effective for developers to build applications with Gemini than before.
Meta launches Llama 3.2
On Wednesday, Meta announced the release of Llama 3.2, a significant update to its open-weights AI model lineup that we have covered extensively in the past. The new release includes vision-capable large language models (LLMs) in 11 billion and 90B parameter sizes, as well as lightweight text-only models of 1B and 3B parameters designed for edge and mobile devices. Meta claims the vision models are competitive with leading closed-source models on image recognition and visual understanding tasks, while the smaller models reportedly outperform similar-sized competitors on various text-based tasks.
Willison did some experiments with some of the smaller 3.2 models and reported impressive results for the models’ size. AI researcher Ethan Mollick showed off running Llama 3.2 on his iPhone using an app called PocketPal.
Meta also introduced the first official “Llama Stack” distributions, created to simplify development and deployment across different environments. As with previous releases, Meta is making the models available for free download, with license restrictions. The new models support long context windows of up to 128,000 tokens.
Google’s AlphaChip AI speeds up chip design
On Thursday, Google DeepMind announced what appears to be a significant advancement in AI-driven electronic chip design, AlphaChip. It began as a research project in 2020 and is now a reinforcement learning method for designing chip layouts. Google has reportedly used AlphaChip to create “superhuman chip layouts” in the last three generations of its Tensor Processing Units (TPUs), which are chips similar to GPUs designed to accelerate AI operations. Google claims AlphaChip can generate high-quality chip layouts in hours, compared to weeks or months of human effort. (Reportedly, Nvidia has also been using AI to help design its chips.)
Notably, Google also released a pre-trained checkpoint of AlphaChip on GitHub, sharing the model weights with the public. The company reported that AlphaChip’s impact has already extended beyond Google, with chip design companies like MediaTek adopting and building on the technology for their chips. According to Google, AlphaChip has sparked a new line of research in AI for chip design, potentially optimizing every stage of the chip design cycle from computer architecture to manufacturing.
That wasn’t everything that happened, but those are some major highlights. With the AI industry showing no signs of slowing down at the moment, we’ll see how next week goes.
Enlarge/ Mira Murati, Chief Technology Officer of OpenAI, speaks during The Wall Street Journal’s WSJ Tech Live Conference in Laguna Beach, California on October 17, 2023.
On Wednesday, OpenAI Chief Technical Officer Mira Murati announced she is leaving the company in a surprise resignation shared on the social network X. Murati joined OpenAI in 2018, serving for six-and-a-half years in various leadership roles, most recently as the CTO.
“After much reflection, I have made the difficult decision to leave OpenAI,” she wrote in a letter to the company’s staff. “While I’ll express my gratitude to many individuals in the coming days, I want to start by thanking Sam and Greg for their trust in me to lead the technical organization and for their support throughout the years,” she continued, referring to OpenAI CEO Sam Altman and President Greg Brockman. “There’s never an ideal time to step away from a place one cherishes, yet this moment feels right.”
At OpenAI, Murati was in charge of overseeing the company’s technical strategy and product development, including the launch and improvement of DALL-E, Codex, Sora, and the ChatGPT platform, while also leading research and safety teams. In public appearances, Murati often spoke about ethical considerations in AI development.
Murati’s decision to leave the company comes when OpenAI finds itself at a major crossroads with a plan to alter its nonprofit structure. According to a Reuters report published today, OpenAI is working to reorganize its core business into a for-profit benefit corporation, removing control from its nonprofit board. The move, which would give CEO Sam Altman equity in the company for the first time, could potentially value OpenAI at $150 billion.
Murati stated her decision to leave was driven by a desire to “create the time and space to do my own exploration,” though she didn’t specify her future plans.
Proud of safety and research work
Enlarge/ OpenAI CTO Mira Murati seen debuting GPT-4o during OpenAI’s Spring Update livestream on May 13, 2024.
OpenAI
In her departure announcement, Murati highlighted recent developments at OpenAI, including innovations in speech-to-speech technology and the release of OpenAI o1. She cited what she considers the company’s progress in safety research and the development of “more robust, aligned, and steerable” AI models.
Altman replied to Murati’s tweet directly, expressing gratitude for Murati’s contributions and her personal support during challenging times, likely referring to the tumultuous period in November 2023 when the OpenAI board of directors briefly fired Altman from the company.
“It’s hard to overstate how much Mira has meant to OpenAI, our mission, and to us all personally,” he wrote. “I feel tremendous gratitude towards her for what she has helped us build and accomplish, but I most of all feel personal gratitude towards her for the support and love during all the hard times. I am excited for what she’ll do next.”
Not the first major player to leave
Enlarge/ An image Ilya Sutskever tweeted with this OpenAI resignation announcement. From left to right: OpenAI Chief Scientist Jakub Pachocki, President Greg Brockman (on leave), Sutskever (now former Chief Scientist), CEO Sam Altman, and soon-to-be-former CTO Mira Murati.
With Murati’s exit, Altman remains one of the few long-standing senior leaders at OpenAI, which has seen significant shuffling in its upper ranks recently. In May 2024, former Chief Scientist Ilya Sutskever left to form his own company, Safe Superintelligence, Inc. (SSI), focused on building AI systems that far surpass humans in logical capabilities. That came just six months after Sutskever’s involvement in the temporary removal of Altman as CEO.
John Schulman, an OpenAI co-founder, departed earlier in 2024 to join rival AI firm Anthropic, and in August, OpenAI President Greg Brockman announced he would be taking a temporary sabbatical until the end of the year.
The leadership shuffles have raised questions among critics about the internal dynamics at OpenAI under Altman and the state of OpenAI’s future research path, which has been aiming toward creating artificial general intelligence (AGI)—a hypothetical technology that could potentially perform human-level intellectual work.
“Question: why would key people leave an organization right before it was just about to develop AGI?” asked xAI developer Benjamin De Kraker in a post on X just after Murati’s announcement. “This is kind of like quitting NASA months before the moon landing,” he wrote in a reply. “Wouldn’t you wanna stick around and be part of it?”
Altman mentioned that more information about transition plans would be forthcoming, leaving questions about who will step into Murati’s role and how OpenAI will adapt to this latest leadership change as the company is poised to adopt a corporate structure that may consolidate more power directly under Altman. “We’ll say more about the transition plans soon, but for now, I want to take a moment to just feel thanks,” Altman wrote.
Among the first AI companies that the Federal Trade Commission has exposed as deceiving consumers is DoNotPay—which initially was advertised as “the world’s first robot lawyer” with the ability to “sue anyone with the click of a button.”
On Wednesday, the FTC announced that it took action to stop DoNotPay from making bogus claims after learning that the AI startup conducted no testing “to determine whether its AI chatbot’s output was equal to the level of a human lawyer.” DoNotPay also did not “hire or retain any attorneys” to help verify AI outputs or validate DoNotPay’s legal claims.
DoNotPay accepted no liability. But to settle the charges that DoNotPay violated the FTC Act, the AI startup agreed to pay $193,000, if the FTC’s consent agreement is confirmed following a 30-day public comment period. Additionally, DoNotPay agreed to warn “consumers who subscribed to the service between 2021 and 2023” about the “limitations of law-related features on the service,” the FTC said.
Moving forward, DoNotPay would also be prohibited under the settlement from making baseless claims that any of its features can be substituted for any professional service.
A DoNotPay spokesperson told Ars that the company “is pleased to have worked constructively with the FTC to settle this case and fully resolve these issues, without admitting liability.”
“The complaint relates to the usage of a few hundred customers some years ago (out of millions of people), with services that have long been discontinued,” DoNotPay’s spokesperson said.
The FTC’s settlement with DoNotPay is part of a larger agency effort to crack down on deceptive AI claims. Four other AI companies were hit with enforcement actions Wednesday, the FTC said, and FTC Chair Lina Khan confirmed that the agency’s so-called “Operation AI Comply” will continue monitoring companies’ attempts to “lure consumers into bogus schemes” or use AI tools to “turbocharge deception.”
“Using AI tools to trick, mislead, or defraud people is illegal,” Khan said. “The FTC’s enforcement actions make clear that there is no AI exemption from the laws on the books. By cracking down on unfair or deceptive practices in these markets, FTC is ensuring that honest businesses and innovators can get a fair shot and consumers are being protected.”
DoNotPay never tested robot lawyer
DoNotPay was initially released in 2015 as a free way to contest parking tickets. Soon after, it quickly expanded its services to supposedly cover 200 areas of law—aiding with everything from breach of contract claims to restraining orders to insurance claims and divorce settlements.
As DoNotPay’s legal services expanded, the company defended its innovative approach to replacing lawyers while acknowledging that it was on seemingly shaky grounds. In 2018, DoNotPay CEO Joshua Browder confirmed to the ABA Journal that the legal services were provided with “no lawyer oversight.” But he said that he was only “a bit worried” about threats to sue DoNotPay for unlicensed practice of law. Because DoNotPay was free, he expected he could avoid some legal challenges.
According to the FTC complaint, DoNotPay began charging subscribers $36 every two months in 2019 while making several false claims in ads to apparently drive up subscriptions.
OpenAI hopes to convince the White House to approve a sprawling plan that would place 5-gigawatt AI data centers in different US cities, Bloomberg reports.
The AI company’s CEO, Sam Altman, supposedly pitched the plan after a recent meeting with the Biden administration where stakeholders discussed AI infrastructure needs. Bloomberg reviewed an OpenAI document outlining the plan, reporting that 5 gigawatts “is roughly the equivalent of five nuclear reactors” and warning that each data center will likely require “more energy than is used to power an entire city or about 3 million homes.”
According to OpenAI, the US needs these massive data centers to expand AI capabilities domestically, protect national security, and effectively compete with China. If approved, the data centers would generate “thousands of new jobs,” OpenAI’s document promised, and help cement the US as an AI leader globally.
But the energy demand is so enormous that OpenAI told officials that the “US needs policies that support greater data center capacity,” or else the US could fall behind other countries in AI development, the document said.
Energy executives told Bloomberg that “powering even a single 5-gigawatt data center would be a challenge,” as power projects nationwide are already “facing delays due to long wait times to connect to grids, permitting delays, supply chain issues, and labor shortages.” Most likely, OpenAI’s data centers wouldn’t rely entirely on the grid, though, instead requiring a “mix of new wind and solar farms, battery storage and a connection to the grid,” John Ketchum, CEO of NextEra Energy Inc, told Bloomberg.
That’s a big problem for OpenAI, since one energy executive, Constellation Energy Corp. CEO Joe Dominguez, told Bloomberg that he’s heard that OpenAI wants to build five to seven data centers. “As an engineer,” Dominguez said he doesn’t think that OpenAI’s plan is “feasible” and would seemingly take more time than needed to address current national security risks as US-China tensions worsen.
OpenAI may be hoping to avoid delays and cut the lines—if the White House approves the company’s ambitious data center plan. For now, a person familiar with OpenAI’s plan told Bloomberg that OpenAI is focused on launching a single data center before expanding the project to “various US cities.”
Bloomberg’s report comes after OpenAI’s chief investor, Microsoft, announced a 20-year deal with Constellation to re-open Pennsylvania’s shuttered Three Mile Island nuclear plant to provide a new energy source for data centers powering AI development and other technologies. But even if that deal is approved by regulators, the resulting energy supply that Microsoft could access—roughly 835 megawatts (0.835 gigawatts) of energy generation, which is enough to power approximately 800,000 homes—is still more than five times less than OpenAI’s 5-gigawatt demand for its data centers.
Ketchum told Bloomberg that it’s easier to find a US site for a 1-gigawatt data center, but locating a site for a 5-gigawatt facility would likely be a bigger challenge. Notably, Amazon recently bought a $650 million nuclear-powered data center in Pennsylvania with a 2.5-gigawatt capacity. At the meeting with the Biden administration, OpenAI suggested opening large-scale data centers in Wisconsin, California, Texas, and Pennsylvania, a source familiar with the matter told CNBC.
During that meeting, the Biden administration confirmed that developing large-scale AI data centers is a priority, announcing “a new Task Force on AI Datacenter Infrastructure to coordinate policy across government.” OpenAI seems to be trying to get the task force’s attention early on, outlining in the document that Bloomberg reviewed the national security and economic benefits its data centers could provide for the US.
In a statement to Bloomberg, OpenAI’s spokesperson said that “OpenAI is actively working to strengthen AI infrastructure in the US, which we believe is critical to keeping America at the forefront of global innovation, boosting reindustrialization across the country, and making AI’s benefits accessible to everyone.”
Big Tech companies and AI startups will likely continue pressuring officials to approve data center expansions, as well as new kinds of nuclear reactors as the AI explosion globally continues. Goldman Sachs estimated that “data center power demand will grow 160 percent by 2030.” To ensure power supplies for its AI, according to the tech news site Freethink, Microsoft has even been training AI to draft all the documents needed for proposals to secure government approvals for nuclear plants to power AI data centers.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}