Enlarge/ The Claude AI iOS app running on an iPhone.
Anthropic
On Wednesday, Anthropic announced the launch of an iOS mobile app for its Claude 3 AI language models that are similar to OpenAI’s ChatGPT. It also introduced a new subscription tier designed for group collaboration. Before the app launch, Claude was only available through a website, an API, and other apps that integrated Claude through API.
Like the ChatGPT app, Claude’s new mobile app serves as a gateway to chatbot interactions, and it also allows uploading photos for analysis. While it’s only available on Apple devices for now, Anthropic says that an Android app is coming soon.
Anthropic rolled out the Claude 3 large language model (LLM) family in March, featuring three different model sizes: Claude Opus, Claude Sonnet, and Claude Haiku. Currently, the app utilizes Sonnet for regular users and Opus for Pro users.
While Anthropic has been a key player in the AI field for several years, it’s entering the mobile space after many of its competitors have already established footprints on mobile platforms. OpenAI released its ChatGPT app for iOS in May 2023, with an Android version arriving two months later. Microsoft released a Copilot iOS app in January. Google Gemini is available through the Google app on iPhone.
Enlarge/ Screenshots of the Claude AI iOS app running on an iPhone.
Anthropic
The app is freely available to all users of Claude, including those using the free version, subscribers paying $20 per month for Claude Pro, and members of the newly introduced Claude Team plan. Conversation history is saved and shared between the web app version of Claude and the mobile app version after logging in.
Speaking of that Team plan, it’s designed for groups of at least five and is priced at $30 per seat per month. It offers more chat queries (higher rate limits), access to all three Claude models, and a larger context window (200K tokens) for processing lengthy documents or maintaining detailed conversations. It also includes group admin tools and billing management, and users can easily switch between Pro and Team plans.
In mid-June 2019, Microsoft co-founder Bill Gates and CEO Satya Nadella received a rude awakening in an email warning that Google had officially gotten too far ahead on AI and that Microsoft may never catch up without investing in OpenAI.
With the subject line “Thoughts on OpenAI,” the email came from Microsoft’s chief technology officer, Kevin Scott, who is also the company’s executive vice president of AI. In it, Scott said that he was “very, very worried” that he had made “a mistake” by dismissing Google’s initial AI efforts as a “game-playing stunt.”
It turned out, Scott suggested, that instead of goofing around, Google had been building critical AI infrastructure that was already paying off, according to a competitive analysis of Google’s products that Scott said showed that Google was competing even more effectively in search. Scott realized that while Google was already moving on to production for “larger scale, more interesting” AI models, it might take Microsoft “multiple years” before it could even attempt to compete with Google.
As just one example, Scott warned, “their auto-complete in Gmail, which is especially useful in the mobile app, is getting scarily good.”
Microsoft had tried to keep this internal email hidden, but late Tuesday it was made public as part of the US Justice Department’s antitrust trial over Google’s alleged search monopoly. The email was initially sealed because Microsoft argued that it contained confidential business information, but The New York Times intervened to get it unsealed, arguing that Microsoft’s privacy interests did not outweigh the need for public disclosure.
In an order unsealing the email among other documents requested by The Times, US District Judge Amit Mehta allowed to be redacted some of the “sensitive statements in the email concerning Microsoft’s business strategies that weigh against disclosure”—which included basically all of Scott’s “thoughts on OpenAI.” But other statements “should be disclosed because they shed light on Google’s defense concerning relative investments by Google and Microsoft in search,” Mehta wrote.
At the trial, Google sought to convince Mehta that Microsoft, for example, had failed to significantly invest in mobile early on, giving Google a competitive advantage in mobile search that it still enjoys today. Scott’s email seems to suggest that Microsoft was similarly dragging its feet on investing in AI until Scott’s wakeup call.
Nadella’s response to the email was immediate. He promptly forwarded the email to Microsoft’s chief financial officer, Amy Hood, on the same day that he received it. Scott’s “very good email,” Nadella told Hood, explained “why I want us to do this.” By “this,” Nadella presumably meant exploring investment opportunities in OpenAI.
Officially, Microsoft has said that its OpenAI partnership was formed “to accelerate AI breakthroughs to ensure these benefits are broadly shared with the world”—not to keep up with Google.
But at the Google trial, Nadella testified about the email, saying that partnering with companies like OpenAI ensured that Microsoft could continue innovating in search, as well as in other Microsoft services.
On the stand, Nadella also admitted that he had overhyped AI-powered Bing as potentially shaking up the search market, backing up the DOJ by testifying that in Silicon Valley, Internet search is “the biggest no-fly zone.” Even after partnering with OpenAI, Nadella said that for Microsoft to compete with Google in search, there are “limits to how much artificial intelligence can reshape the market as it exists today.”
During the Google trial, the DOJ argued that Google’s alleged search market dominance had hindered OpenAI’s efforts to innovate, too. “OpenAI’s ChatGPT and other innovations may have been released years ago if Google hadn’t monopolized the search market,” the DOJ argued, according to a Bloomberg report.
Closing arguments in the Google trial start tomorrow, with two days of final remarks scheduled, during which Mehta will have ample opportunity to ask lawyers on both sides the rest of his biggest remaining questions.
It’s somewhat obvious what Google will argue. Google has spent years defending its search business as competing on the merits—essentially arguing that Google dominates search simply because it’s the best search engine.
Yesterday, the US district court also unsealed Google’s proposed legal conclusions, which suggest that Mehta should reject all of the DOJ’s monopoly claims, partly due to the government’s allegedly “fatally flawed” market definitions. Throughout the trial, Google has maintained that the US government has failed to show that Google has a monopoly in any market.
According to Google, even its allegedly anticompetitive default browser agreement with Apple—which Mehta deemed the “heart” of the DOJ’s monopoly case—is not proof of monopoly powers. Rather, Google insisted, default browser agreements benefit competition by providing another avenue through which its rivals can compete.
Mehta has not yet disclosed when to expect his ruling, but it could come late this summer or early fall, AP News reported.
If Google loses, the search giant may be forced to change its business practices or potentially even break up its business. Nobody knows what that would entail, but when the trial started, a coalition of 20 civil society and advocacy groups recommended some potentially drastic remedies, including the “separation of various Google products from parent company Alphabet, including breakouts of Google Chrome, Android, Waze, or Google’s artificial intelligence lab Deepmind.”
On Sunday, word began to spread on social media about a new mystery chatbot named “gpt2-chatbot” that appeared in the LMSYS Chatbot Arena. Some people speculate that it may be a secret test version of OpenAI’s upcoming GPT-4.5 or GPT-5 large language model (LLM). The paid version of ChatGPT is currently powered by GPT-4 Turbo.
Currently, the new model is only available for use through the Chatbot Arena website, although in a limited way. In the site’s “side-by-side” arena mode where users can purposely select the model, gpt2-chatbot has a rate limit of eight queries per day—dramatically limiting people’s ability to test it in detail.
So far, gpt2-chatbot has inspired plenty of rumors online, including that it could be the stealth launch of a test version of GPT-4.5 or even GPT-5—or perhaps a new version of 2019’s GPT-2 that has been trained using new techniques. We reached out to OpenAI for comment but did not receive a response by press time. On Monday evening, OpenAI CEO Sam Altman seemingly dropped a hint by tweeting, “i do have a soft spot for gpt2.”
Enlarge/ A screenshot of the LMSYS Chatbot Arena “side-by-side” page showing “gpt2-chatbot” listed among the models for testing. (Red highlight added by Ars Technica.)
Benj Edwards
Early reports of the model first appeared on 4chan, then spread to social media platforms like X, with hype following not far behind. “Not only does it seem to show incredible reasoning, but it also gets notoriously challenging AI questions right with a much more impressive tone,” wrote AI developer Pietro Schirano on X. Soon, threads on Reddit popped up claiming that the new model had amazing abilities that beat every other LLM on the Arena.
Intrigued by the rumors, we decided to try out the new model for ourselves but did not come away impressed. When asked about “Benj Edwards,” the model revealed a few mistakes and some awkward language compared to GPT-4 Turbo’s output. A request for five original dad jokes fell short. And the gpt2-chatbot did not decisively pass our “magenta” test. (“Would the color be called ‘magenta’ if the town of Magenta didn’t exist?”)
A gpt2-chatbot result for “Who is Benj Edwards?” on LMSYS Chatbot Arena. Mistakes and oddities highlighted in red.
Benj Edwards
A gpt2-chatbot result for “Write 5 original dad jokes” on LMSYS Chatbot Arena.
Benj Edwards
A gpt2-chatbot result for “Would the color be called ‘magenta’ if the town of Magenta didn’t exist?” on LMSYS Chatbot Arena.
Benj Edwards
So, whatever it is, it’s probably not GPT-5. We’ve seen other people reach the same conclusion after further testing, saying that the new mystery chatbot doesn’t seem to represent a large capability leap beyond GPT-4. “Gpt2-chatbot is good. really good,” wrote HyperWrite CEO Matt Shumer on X. “But if this is gpt-4.5, I’m disappointed.”
Still, OpenAI’s fingerprints seem to be all over the new bot. “I think it may well be an OpenAI stealth preview of something,” AI researcher Simon Willison told Ars Technica. But what “gpt2” is exactly, he doesn’t know. After surveying online speculation, it seems that no one apart from its creator knows precisely what the model is, either.
Willison has uncovered the system prompt for the AI model, which claims it is based on GPT-4 and made by OpenAI. But as Willison noted in a tweet, that’s no guarantee of provenance because “the goal of a system prompt is to influence the model to behave in certain ways, not to give it truthful information about itself.”
On Friday, the US Department of Homeland Security announced the formation of an Artificial Intelligence Safety and Security Board that consists of 22 members pulled from the tech industry, government, academia, and civil rights organizations. But given the nebulous nature of the term “AI,” which can apply to a broad spectrum of computer technology, it’s unclear if this group will even be able to agree on what exactly they are safeguarding us from.
President Biden directed DHS Secretary Alejandro Mayorkas to establish the board, which will meet for the first time in early May and subsequently on a quarterly basis.
The fundamental assumption posed by the board’s existence, and reflected in Biden’s AI executive order from October, is that AI is an inherently risky technology and that American citizens and businesses need to be protected from its misuse. Along those lines, the goal of the group is to help guard against foreign adversaries using AI to disrupt US infrastructure; develop recommendations to ensure the safe adoption of AI tech into transportation, energy, and Internet services; foster cross-sector collaboration between government and businesses; and create a forum where AI leaders to share information on AI security risks with the DHS.
It’s worth noting that the ill-defined nature of the term “Artificial Intelligence” does the new board no favors regarding scope and focus. AI can mean many different things: It can power a chatbot, fly an airplane, control the ghosts in Pac-Man, regulate the temperature of a nuclear reactor, or play a great game of chess. It can be all those things and more, and since many of those applications of AI work very differently, there’s no guarantee any two people on the board will be thinking about the same type of AI.
This confusion is reflected in the quotes provided by the DHS press release from new board members, some of whom are already talking about different types of AI. While OpenAI, Microsoft, and Anthropic are monetizing generative AI systems like ChatGPT based on large language models (LLMs), Ed Bastian, the CEO of Delta Air Lines, refers to entirely different classes of machine learning when he says, “By driving innovative tools like crew resourcing and turbulence prediction, AI is already making significant contributions to the reliability of our nation’s air travel system.”
So, defining the scope of what AI exactly means—and which applications of AI are new or dangerous—might be one of the key challenges for the new board.
A roundtable of Big Tech CEOs attracts criticism
For the inaugural meeting of the AI Safety and Security Board, the DHS selected a tech industry-heavy group, populated with CEOs of four major AI vendors (Sam Altman of OpenAI, Satya Nadella of Microsoft, Sundar Pichai of Alphabet, and Dario Amodei of Anthopic), CEO Jensen Huang of top AI chipmaker Nvidia, and representatives from other major tech companies like IBM, Adobe, Amazon, Cisco, and AMD. There are also reps from big aerospace and aviation: Northrop Grumman and Delta Air Lines.
Upon reading the announcement, some critics took issue with the board composition. On LinkedIn, founder of The Distributed AI Research Institute (DAIR) Timnit Gebru especially criticized OpenAI’s presence on the board and wrote, “I’ve now seen the full list and it is hilarious. Foxes guarding the hen house is an understatement.”
In the world of AI, what might be called “small language models” have been growing in popularity recently because they can be run on a local device instead of requiring data center-grade computers in the cloud. On Wednesday, Apple introduced a set of tiny source-available AI language models called OpenELM that are small enough to run directly on a smartphone. They’re mostly proof-of-concept research models for now, but they could form the basis of future on-device AI offerings from Apple.
Apple’s new AI models, collectively named OpenELM for “Open-source Efficient Language Models,” are currently available on the Hugging Face under an Apple Sample Code License. Since there are some restrictions in the license, it may not fit the commonly accepted definition of “open source,” but the source code for OpenELM is available.
On Tuesday, we covered Microsoft’s Phi-3 models, which aim to achieve something similar: a useful level of language understanding and processing performance in small AI models that can run locally. Phi-3-mini features 3.8 billion parameters, but some of Apple’s OpenELM models are much smaller, ranging from 270 million to 3 billion parameters in eight distinct models.
In comparison, the largest model yet released in Meta’s Llama 3 family includes 70 billion parameters (with a 400 billion version on the way), and OpenAI’s GPT-3 from 2020 shipped with 175 billion parameters. Parameter count serves as a rough measure of AI model capability and complexity, but recent research has focused on making smaller AI language models as capable as larger ones were a few years ago.
The eight OpenELM models come in two flavors: four as “pretrained” (basically a raw, next-token version of the model) and four as instruction-tuned (fine-tuned for instruction following, which is more ideal for developing AI assistants and chatbots):
OpenELM features a 2048-token maximum context window. The models were trained on the publicly available datasets RefinedWeb, a version of PILE with duplications removed, a subset of RedPajama, and a subset of Dolma v1.6, which Apple says totals around 1.8 trillion tokens of data. Tokens are fragmented representations of data used by AI language models for processing.
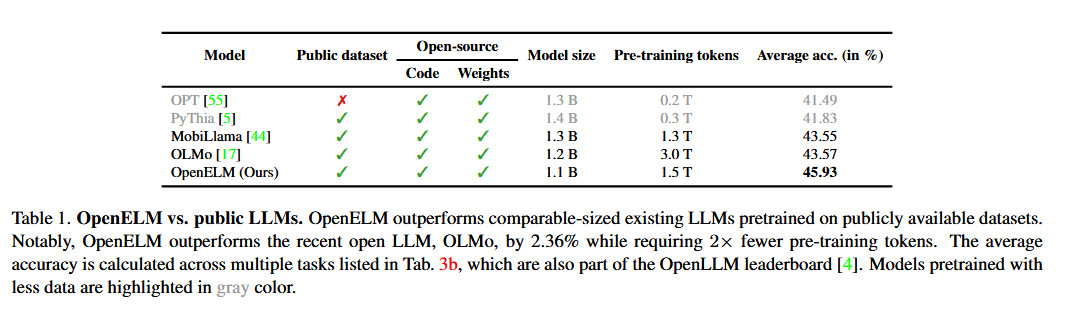
Apple says its approach with OpenELM includes a “layer-wise scaling strategy” that reportedly allocates parameters more efficiently across each layer, saving not only computational resources but also improving the model’s performance while being trained on fewer tokens. According to Apple’s released white paper, this strategy has enabled OpenELM to achieve a 2.36 percent improvement in accuracy over Allen AI’s OLMo 1B (another small language model) while requiring half as many pre-training tokens.
Enlarge/ An table comparing OpenELM with other small AI language models in a similar class, taken from the OpenELM research paper by Apple.
Apple
Apple also released the code for CoreNet, a library it used to train OpenELM—and it also included reproducible training recipes that allow the weights (neural network files) to be replicated, which is unusual for a major tech company so far. As Apple says in its OpenELM paper abstract, transparency is a key goal for the company: “The reproducibility and transparency of large language models are crucial for advancing open research, ensuring the trustworthiness of results, and enabling investigations into data and model biases, as well as potential risks.”
By releasing the source code, model weights, and training materials, Apple says it aims to “empower and enrich the open research community.” However, it also cautions that since the models were trained on publicly sourced datasets, “there exists the possibility of these models producing outputs that are inaccurate, harmful, biased, or objectionable in response to user prompts.”
While Apple has not yet integrated this new wave of AI language model capabilities into its consumer devices, the upcoming iOS 18 update (expected to be revealed in June at WWDC) is rumored to include new AI features that utilize on-device processing to ensure user privacy—though the company may potentially hire Google or OpenAI to handle more complex, off-device AI processing to give Siri a long-overdue boost.
On Tuesday, Microsoft announced a new, freely available lightweight AI language model named Phi-3-mini, which is simpler and less expensive to operate than traditional large language models (LLMs) like OpenAI’s GPT-4 Turbo. Its small size is ideal for running locally, which could bring an AI model of similar capability to the free version of ChatGPT to a smartphone without needing an Internet connection to run it.
The AI field typically measures AI language model size by parameter count. Parameters are numerical values in a neural network that determine how the language model processes and generates text. They are learned during training on large datasets and essentially encode the model’s knowledge into quantified form. More parameters generally allow the model to capture more nuanced and complex language-generation capabilities but also require more computational resources to train and run.
Some of the largest language models today, like Google’s PaLM 2, have hundreds of billions of parameters. OpenAI’s GPT-4 is rumored to have over a trillion parameters but spread over eight 220-billion parameter models in a mixture-of-experts configuration. Both models require heavy-duty data center GPUs (and supporting systems) to run properly.
In contrast, Microsoft aimed small with Phi-3-mini, which contains only 3.8 billion parameters and was trained on 3.3 trillion tokens. That makes it ideal to run on consumer GPU or AI-acceleration hardware that can be found in smartphones and laptops. It’s a follow-up of two previous small language models from Microsoft: Phi-2, released in December, and Phi-1, released in June 2023.
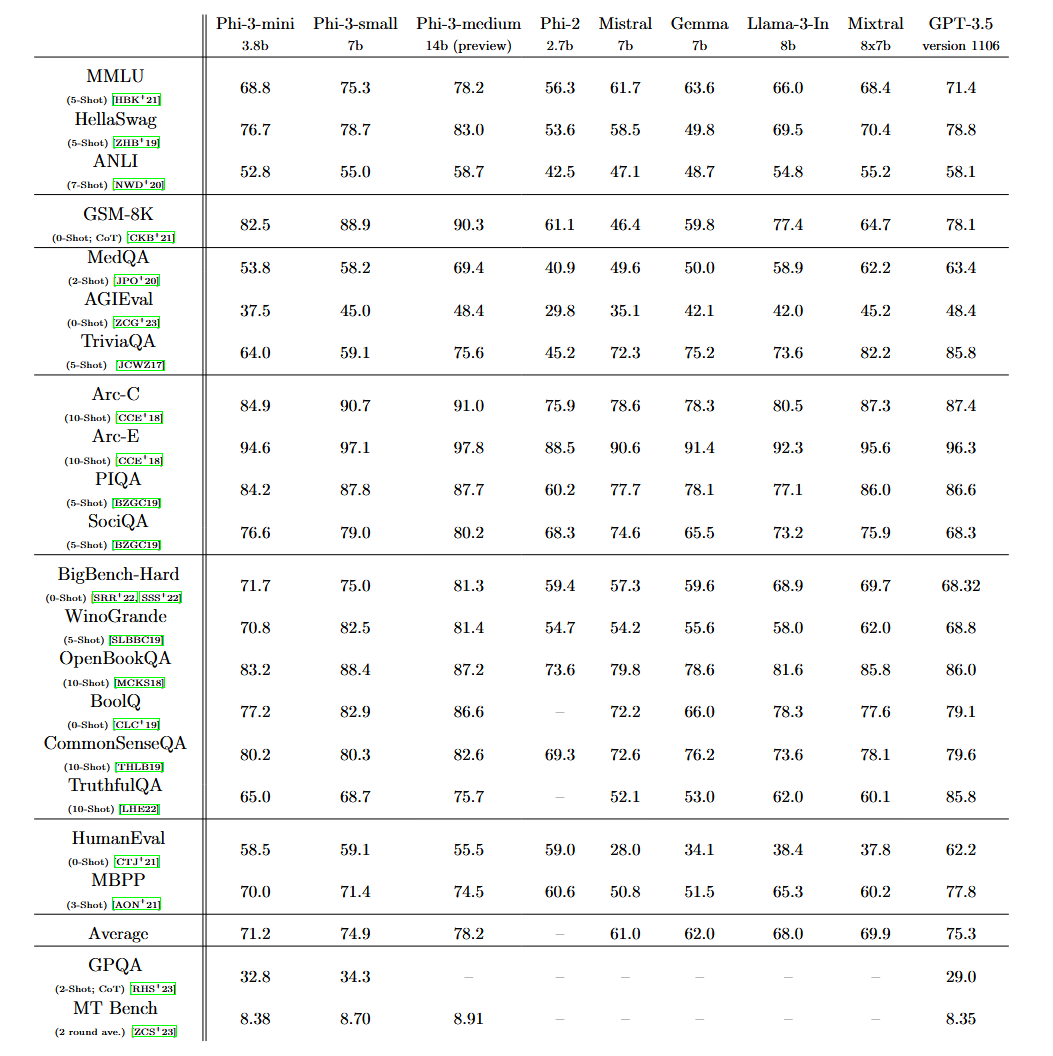
Enlarge/ A chart provided by Microsoft showing Phi-3 performance on various benchmarks.
Phi-3-mini features a 4,000-token context window, but Microsoft also introduced a 128K-token version called “phi-3-mini-128K.” Microsoft has also created 7-billion and 14-billion parameter versions of Phi-3 that it plans to release later that it claims are “significantly more capable” than phi-3-mini.
Microsoft says that Phi-3 features overall performance that “rivals that of models such as Mixtral 8x7B and GPT-3.5,” as detailed in a paper titled “Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone.” Mixtral 8x7B, from French AI company Mistral, utilizes a mixture-of-experts model, and GPT-3.5 powers the free version of ChatGPT.
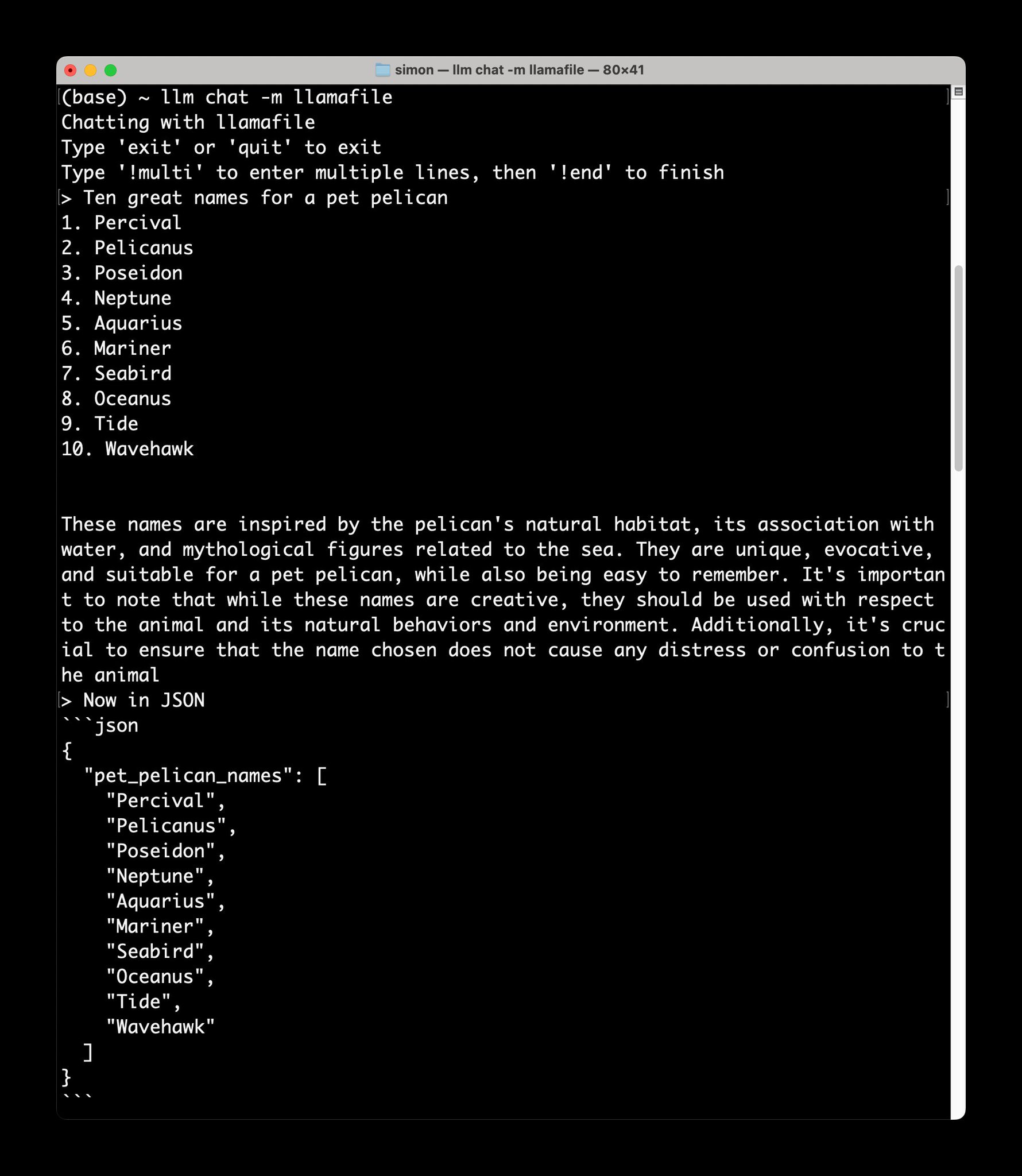
“[Phi-3] looks like it’s going to be a shockingly good small model if their benchmarks are reflective of what it can actually do,” said AI researcher Simon Willison in an interview with Ars. Shortly after providing that quote, Willison downloaded Phi-3 to his Macbook laptop locally and said, “I got it working, and it’s GOOD” in a text message sent to Ars.
Enlarge/ A screenshot of Phi-3-mini running locally on Simon Willison’s Macbook.
Simon Willison
“Most models that run on a local device still need hefty hardware,” says Willison. “Phi-3-mini runs comfortably with less than 8GB of RAM, and can churn out tokens at a reasonable speed even on just a regular CPU. It’s licensed MIT and should work well on a $55 Raspberry Pi—and the quality of results I’ve seen from it so far are comparable to models 4x larger.“
How did Microsoft cram a capability potentially similar to GPT-3.5, which has at least 175 billion parameters, into such a small model? Its researchers found the answer by using carefully curated, high-quality training data they initially pulled from textbooks. “The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data,” writes Microsoft. “The model is also further aligned for robustness, safety, and chat format.”
Much has been written about the potential environmental impact of AI models and datacenters themselves, including on Ars. With new techniques and research, it’s possible that machine learning experts may continue to increase the capability of smaller AI models, replacing the need for larger ones—at least for everyday tasks. That would theoretically not only save money in the long run but also require far less energy in aggregate, dramatically decreasing AI’s environmental footprint. AI models like Phi-3 may be a step toward that future if the benchmark results hold up to scrutiny.
Phi-3 is immediately available on Microsoft’s cloud service platform Azure, as well as through partnerships with machine learning model platform Hugging Face and Ollama, a framework that allows models to run locally on Macs and PCs.
On Thursday, Meta unveiled early versions of its Llama 3 open-weights AI model that can be used to power text composition, code generation, or chatbots. It also announced that its Meta AI Assistant is now available on a website and is going to be integrated into its major social media apps, intensifying the company’s efforts to position its products against other AI assistants like OpenAI’s ChatGPT, Microsoft’s Copilot, and Google’s Gemini.
Like its predecessor, Llama 2, Llama 3 is notable for being a freely available, open-weights large language model (LLM) provided by a major AI company. Llama 3 technically does not quality as “open source” because that term has a specific meaning in software (as we have mentioned in other coverage), and the industry has not yet settled on terminology for AI model releases that ship either code or weights with restrictions (you can read Llama 3’s license here) or that ship without providing training data. We typically call these releases “open weights” instead.
At the moment, Llama 3 is available in two parameter sizes: 8 billion (8B) and 70 billion (70B), both of which are available as free downloads through Meta’s website with a sign-up. Llama 3 comes in two versions: pre-trained (basically the raw, next-token-prediction model) and instruction-tuned (fine-tuned to follow user instructions). Each has a 8,192 token context limit.
Enlarge/ A screenshot of the Meta AI Assistant website on April 18, 2024.
Benj Edwards
Meta trained both models on two custom-built, 24,000-GPU clusters. In a podcast interview with Dwarkesh Patel, Meta CEO Mark Zuckerberg said that the company trained the 70B model with around 15 trillion tokens of data. Throughout the process, the model never reached “saturation” (that is, it never hit a wall in terms of capability increases). Eventually, Meta pulled the plug and moved on to training other models.
“I guess our prediction going in was that it was going to asymptote more, but even by the end it was still leaning. We probably could have fed it more tokens, and it would have gotten somewhat better,” Zuckerberg said on the podcast.
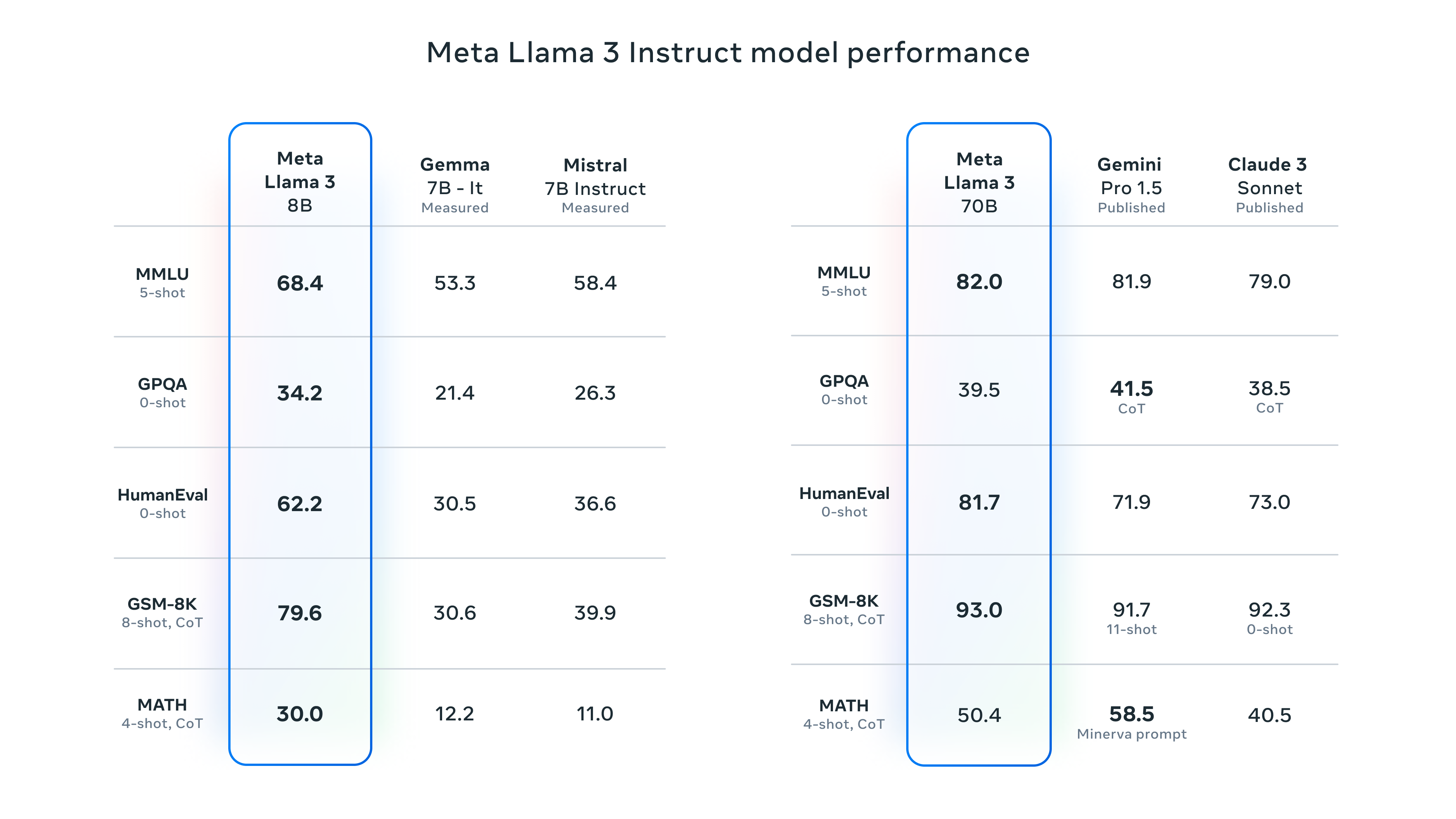
Meta also announced that it is currently training a 400B parameter version of Llama 3, which some experts like Nvidia’s Jim Fan think may perform in the same league as GPT-4 Turbo, Claude 3 Opus, and Gemini Ultra on benchmarks like MMLU, GPQA, HumanEval, and MATH.
Speaking of benchmarks, we have devoted many words in the past to explaining how frustratingly imprecise benchmarks can be when applied to large language models due to issues like training contamination (that is, including benchmark test questions in the training dataset), cherry-picking on the part of vendors, and an inability to capture AI’s general usefulness in an interactive session with chat-tuned models.
But, as expected, Meta provided some benchmarks for Llama 3 that list results from MMLU (undergraduate level knowledge), GSM-8K (grade-school math), HumanEval (coding), GPQA (graduate-level questions), and MATH (math word problems). These show the 8B model performing well compared to open-weights models like Google’s Gemma 7B and Mistral 7B Instruct, and the 70B model also held its own against Gemini Pro 1.5 and Claude 3 Sonnet.
Enlarge/ A chart of instruction-tuned Llama 3 8B and 70B benchmarks provided by Meta.
Meta says that the Llama 3 model has been enhanced with capabilities to understand coding (like Llama 2) and, for the first time, has been trained with both images and text—though it currently outputs only text. According to Reuters, Meta Chief Product Officer Chris Cox noted in an interview that more complex processing abilities (like executing multi-step plans) are expected in future updates to Llama 3, which will also support multimodal outputs—that is, both text and images.
Meta plans to host the Llama 3 models on a range of cloud platforms, making them accessible through AWS, Databricks, Google Cloud, and other major providers.
Also on Thursday, Meta announced that Llama 3 will become the new basis of the Meta AI virtual assistant, which the company first announced in September. The assistant will appear prominently in search features for Facebook, Instagram, WhatsApp, Messenger, and the aforementioned dedicated website that features a design similar to ChatGPT, including the ability to generate images in the same interface. The company also announced a partnership with Google to integrate real-time search results into the Meta AI assistant, adding to an existing partnership with Microsoft’s Bing.
Enlarge/ An image of a boy amazed by flying letters.
Some weeks in AI news are eerily quiet, but during others, getting a grip on the week’s events feels like trying to hold back the tide. This week has seen three notable large language model (LLM) releases: Google Gemini Pro 1.5 hit general availability with a free tier, OpenAI shipped a new version of GPT-4 Turbo, and Mistral released a new openly licensed LLM, Mixtral 8x22B. All three of those launches happened within 24 hours starting on Tuesday.
With the help of software engineer and independent AI researcher Simon Willison (who also wrote about this week’s hectic LLM launches on his own blog), we’ll briefly cover each of the three major events in roughly chronological order, then dig into some additional AI happenings this week.
Gemini Pro 1.5 general release
On Tuesday morning Pacific time, Google announced that its Gemini 1.5 Pro model (which we first covered in February) is now available in 180-plus countries, excluding Europe, via the Gemini API in a public preview. This is Google’s most powerful public LLM so far, and it’s available in a free tier that permits up to 50 requests a day.
It supports up to 1 million tokens of input context. As Willison notes in his blog, Gemini 1.5 Pro’s API price at $7/million input tokens and $21/million output tokens costs a little less than GPT-4 Turbo (priced at $10/million in and $30/million out) and more than Claude 3 Sonnet (Anthropic’s mid-tier LLM, priced at $3/million in and $15/million out).
Notably, Gemini 1.5 Pro includes native audio (speech) input processing that allows users to upload audio or video prompts, a new File API for handling files, the ability to add custom system instructions (system prompts) for guiding model responses, and a JSON mode for structured data extraction.
“Majorly Improved” GPT-4 Turbo launch
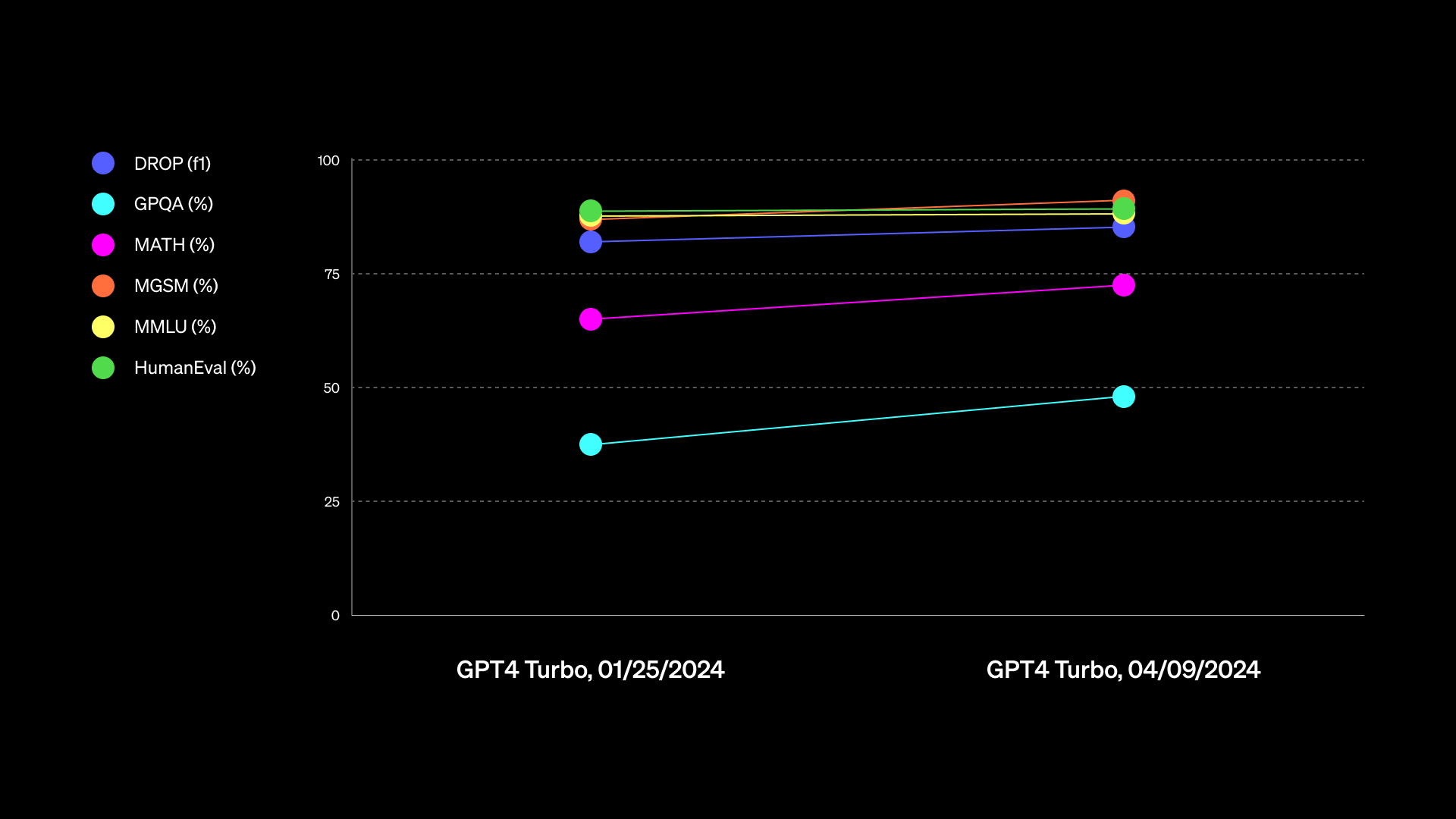
Enlarge/ A GPT-4 Turbo performance chart provided by OpenAI.
Just a bit later than Google’s 1.5 Pro launch on Tuesday, OpenAI announced that it was rolling out a “majorly improved” version of GPT-4 Turbo (a model family originally launched in November) called “gpt-4-turbo-2024-04-09.” It integrates multimodal GPT-4 Vision processing (recognizing the contents of images) directly into the model, and it initially launched through API access only.
Then on Thursday, OpenAI announced that the new GPT-4 Turbo model had just become available for paid ChatGPT users. OpenAI said that the new model improves “capabilities in writing, math, logical reasoning, and coding” and shared a chart that is not particularly useful in judging capabilities (that they later updated). The company also provided an example of an alleged improvement, saying that when writing with ChatGPT, the AI assistant will use “more direct, less verbose, and use more conversational language.”
The vague nature of OpenAI’s GPT-4 Turbo announcements attracted some confusion and criticism online. On X, Willison wrote, “Who will be the first LLM provider to publish genuinely useful release notes?” In some ways, this is a case of “AI vibes” again, as we discussed in our lament about the poor state of LLM benchmarks during the debut of Claude 3. “I’ve not actually spotted any definite differences in quality [related to GPT-4 Turbo],” Willison told us directly in an interview.
The update also expanded GPT-4’s knowledge cutoff to April 2024, although some people are reporting it achieves this through stealth web searches in the background, and others on social media have reported issues with date-related confabulations.
Mistral’s mysterious Mixtral 8x22B release
Enlarge/ An illustration of a robot holding a French flag, figuratively reflecting the rise of AI in France due to Mistral. It’s hard to draw a picture of an LLM, so a robot will have to do.
Not to be outdone, on Tuesday night, French AI company Mistral launched its latest openly licensed model, Mixtral 8x22B, by tweeting a torrent link devoid of any documentation or commentary, much like it has done with previous releases.
The new mixture-of-experts (MoE) release weighs in with a larger parameter count than its previously most-capable open model, Mixtral 8x7B, which we covered in December. It’s rumored to potentially be as capable as GPT-4 (In what way, you ask? Vibes). But that has yet to be seen.
“The evals are still rolling in, but the biggest open question right now is how well Mixtral 8x22B shapes up,” Willison told Ars. “If it’s in the same quality class as GPT-4 and Claude 3 Opus, then we will finally have an openly licensed model that’s not significantly behind the best proprietary ones.”
This release has Willison most excited, saying, “If that thing really is GPT-4 class, it’s wild, because you can run that on a (very expensive) laptop. I think you need 128GB of MacBook RAM for it, twice what I have.”
The new Mixtral is not listed on Chatbot Arena yet, Willison noted, because Mistral has not released a fine-tuned model for chatting yet. It’s still a raw, predict-the-next token LLM. “There’s at least one community instruction tuned version floating around now though,” says Willison.
Chatbot Arena Leaderboard shake-ups
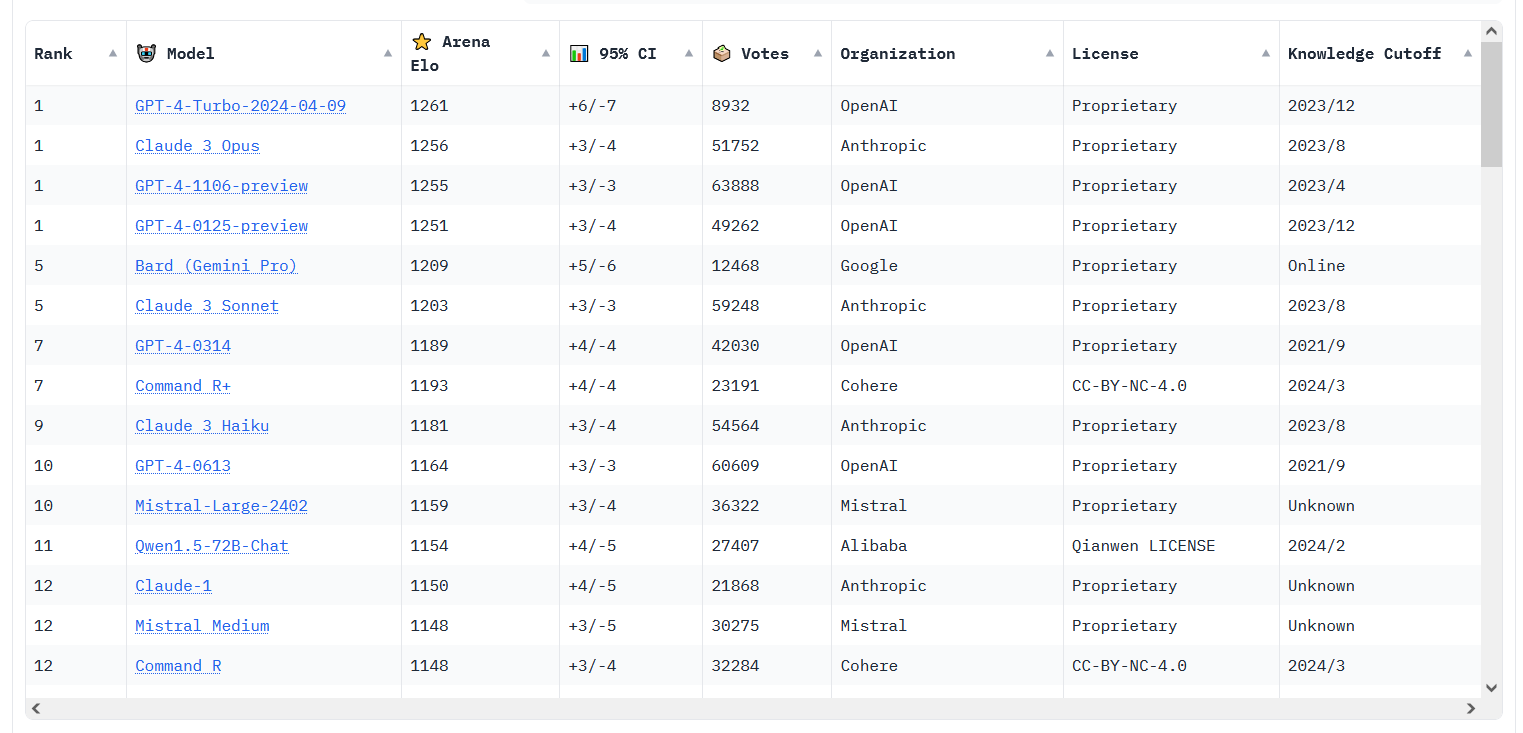
Enlarge/ A Chatbot Arena Leaderboard screenshot taken on April 12, 2024.
Benj Edwards
This week’s LLM news isn’t limited to just the big names in the field. There have also been rumblings on social media about the rising performance of open source models like Cohere’s Command R+, which reached position 6 on the LMSYS Chatbot Arena Leaderboard—the highest-ever ranking for an open-weights model.
And for even more Chatbot Arena action, apparently the new version of GPT-4 Turbo is proving competitive with Claude 3 Opus. The two are still in a statistical tie, but GPT-4 Turbo recently pulled ahead numerically. (In March, we reported when Claude 3 first numerically pulled ahead of GPT-4 Turbo, which was then the first time another AI model had surpassed a GPT-4 family model member on the leaderboard.)
Regarding this fierce competition among LLMs—of which most of the muggle world is unaware and will likely never be—Willison told Ars, “The past two months have been a whirlwind—we finally have not just one but several models that are competitive with GPT-4.” We’ll see if OpenAI’s rumored release of GPT-5 later this year will restore the company’s technological lead, we note, which once seemed insurmountable. But for now, Willison says, “OpenAI are no longer the undisputed leaders in LLMs.”
Enlarge/ An Intel handout photo of the Gaudi 3 AI accelerator.
On Tuesday, Intel revealed a new AI accelerator chip called Gaudi 3 at its Vision 2024 event in Phoenix. With strong claimed performance while running large language models (like those that power ChatGPT), the company has positioned Gaudi 3 as an alternative to Nvidia’s H100, a popular data center GPU that has been subject to shortages, though apparently that is easing somewhat.
Compared to Nvidia’s H100 chip, Intel projects a 50 percent faster training time on Gaudi 3 for both OpenAI’s GPT-3 175B LLM and the 7-billion parameter version of Meta’s Llama 2. In terms of inference (running the trained model to get outputs), Intel claims that its new AI chip delivers 50 percent faster performance than H100 for Llama 2 and Falcon 180B, which are both relatively popular open-weights models.
Intel is targeting the H100 because of its high market share, but the chip isn’t Nvidia’s most powerful AI accelerator chip in the pipeline. Announcements of the H200 and the Blackwell B200 have since surpassed the H100 on paper, but neither of those chips is out yet (the H200 is expected in the second quarter of 2024—basically any day now).
Meanwhile, the aforementioned H100 supply issues have been a major headache for tech companies and AI researchers who have to fight for access to any chips that can train AI models. This has led several tech companies like Microsoft, Meta, and OpenAI (rumor has it) to seek their own AI-accelerator chip designs, although that custom silicon is typically manufactured by either Intel or TSMC. Google has its own line of tensor processing units (TPUs) that it has been using internally since 2015.
Given those issues, Intel’s Gaudi 3 may be a potentially attractive alternative to the H100 if Intel can hit an ideal price (which Intel has not provided, but an H100 reportedly costs around $30,000–$40,000) and maintain adequate production. AMD also manufactures a competitive range of AI chips, such as the AMD Instinct MI300 Series, that sell for around $10,000–$15,000.
Gaudi 3 performance
Enlarge/ An Intel handout featuring specifications of the Gaudi 3 AI accelerator.
Intel says the new chip builds upon the architecture of its predecessor, Gaudi 2, by featuring two identical silicon dies connected by a high-bandwidth connection. Each die contains a central cache memory of 48 megabytes, surrounded by four matrix multiplication engines and 32 programmable tensor processor cores, bringing the total cores to 64.
The chipmaking giant claims that Gaudi 3 delivers double the AI compute performance of Gaudi 2 using 8-bit floating-point infrastructure, which has become crucial for training transformer models. The chip also offers a fourfold boost for computations using the BFloat 16-number format. Gaudi 3 also features 128GB of the less expensive HBMe2 memory capacity (which may contribute to price competitiveness) and features 3.7TB of memory bandwidth.
Since data centers are well-known to be power hungry, Intel emphasizes the power efficiency of Gaudi 3, claiming 40 percent greater inference power-efficiency across Llama 7B and 70B parameters, and Falcon 180B parameter models compared to Nvidia’s H100. Eitan Medina, chief operating officer of Intel’s Habana Labs, attributes this advantage to Gaudi’s large-matrix math engines, which he claims require significantly less memory bandwidth compared to other architectures.
Gaudi vs. Blackwell
Enlarge/ An Intel handout photo of the Gaudi 3 AI accelerator.
Last month, we covered the splashy launch of Nvidia’s Blackwell architecture, including the B200 GPU, which Nvidia claims will be the world’s most powerful AI chip. It seems natural, then, to compare what we know about Nvidia’s highest-performing AI chip to the best of what Intel can currently produce.
For starters, Gaudi 3 is being manufactured using TSMC’s N5 process technology, according to IEEE Spectrum, narrowing the gap between Intel and Nvidia in terms of semiconductor fabrication technology. The upcoming Nvidia Blackwell chip will use a custom N4P process, which reportedly offers modest performance and efficiency improvements over N5.
Gaudi 3’s use of HBM2e memory (as we mentioned above) is notable compared to the more expensive HBM3 or HBM3e used in competing chips, offering a balance of performance and cost-efficiency. This choice seems to emphasize Intel’s strategy to compete not only on performance but also on price.
As far as raw performance comparisons between Gaudi 3 and the B200, that can’t be known until the chips have been released and benchmarked by a third party.
As the race to power the tech industry’s thirst for AI computation heats up, IEEE Spectrum notes that the next generation of Intel’s Gaudi chip, code-named Falcon Shores, remains a point of interest. It also remains to be seen whether Intel will continue to rely on TSMC’s technology or leverage its own foundry business and upcoming nanosheet transistor technology to gain a competitive edge in the AI accelerator market.
Amid a flurry of lawsuits over AI models’ training data, US Representative Adam Schiff (D-Calif.) has introduced a bill that would require AI companies to disclose exactly which copyrighted works are included in datasets training AI systems.
The Generative AI Disclosure Act “would require a notice to be submitted to the Register of Copyrights prior to the release of a new generative AI system with regard to all copyrighted works used in building or altering the training dataset for that system,” Schiff said in a press release.
The bill is retroactive and would apply to all AI systems available today, as well as to all AI systems to come. It would take effect 180 days after it’s enacted, requiring anyone who creates or alters a training set not only to list works referenced by the dataset, but also to provide a URL to the dataset within 30 days before the AI system is released to the public. That URL would presumably give creators a way to double-check if their materials have been used and seek any credit or compensation available before the AI tools are in use.
All notices would be kept in a publicly available online database.
Schiff described the act as championing “innovation while safeguarding the rights and contributions of creators, ensuring they are aware when their work contributes to AI training datasets.”
“This is about respecting creativity in the age of AI and marrying technological progress with fairness,” Schiff said.
Currently, creators who don’t have access to training datasets rely on AI models’ outputs to figure out if their copyrighted works may have been included in training various AI systems. The New York Times, for example, prompted ChatGPT to spit out excerpts of its articles, relying on a tactic to identify training data by asking ChatGPT to produce lines from specific articles, which OpenAI has curiously described as “hacking.”
Under Schiff’s law, The New York Times would need to consult the database to ID all articles used to train ChatGPT or any other AI system.
Any AI maker who violates the act would risk a “civil penalty in an amount not less than $5,000,” the proposed bill said.
At a hearing on artificial intelligence and intellectual property, Rep. Darrell Issa (R-Calif.)—who chairs the House Judiciary Subcommittee on Courts, Intellectual Property, and the Internet—told Schiff that his subcommittee would consider the “thoughtful” bill.
Schiff told the subcommittee that the bill is “only a first step” toward “ensuring that at a minimum” creators are “aware of when their work contributes to AI training datasets,” saying that he would “welcome the opportunity to work with members of the subcommittee” on advancing the bill.
“The rapid development of generative AI technologies has outpaced existing copyright laws, which has led to widespread use of creative content to train generative AI models without consent or compensation,” Schiff warned at the hearing.
In Schiff’s press release, Meredith Stiehm, president of the Writers Guild of America West, joined leaders from other creative groups celebrating the bill as an “important first step” for rightsholders.
“Greater transparency and guardrails around AI are necessary to protect writers and other creators” and address “the unprecedented and unauthorized use of copyrighted materials to train generative AI systems,” Stiehm said.
Until the thorniest AI copyright questions are settled, Ken Doroshow, a chief legal officer for the Recording Industry Association of America, suggested that Schiff’s bill filled an important gap by introducing “comprehensive and transparent recordkeeping” that would provide “one of the most fundamental building blocks of effective enforcement of creators’ rights.”
A senior adviser for the Human Artistry Campaign, Moiya McTier, went further, celebrating the bill as stopping AI companies from “exploiting” artists and creators.
“AI companies should stop hiding the ball when they copy creative works into AI systems and embrace clear rules of the road for recordkeeping that create a level and transparent playing field for the development and licensing of genuinely innovative applications and tools,” McTier said.
AI copyright guidance coming soon
While courts weigh copyright questions raised by artists, book authors, and newspapers, the US Copyright Office announced in March that it would be issuing guidance later this year, but the office does not seem to be prioritizing questions on AI training.
Instead, the Copyright Office will focus first on issuing guidance on deepfakes and AI outputs. This spring, the office will release a report “analyzing the impact of AI on copyright” of “digital replicas, or the use of AI to digitally replicate individuals’ appearances, voices, or other aspects of their identities.” Over the summer, another report will focus on “the copyrightability of works incorporating AI-generated material.”
Regarding “the topic of training AI models on copyrighted works as well as any licensing considerations and liability issues,” the Copyright Office did not provide a timeline for releasing guidance, only confirming that their “goal is to finalize the entire report by the end of the fiscal year.”
Once guidance is available, it could sway court opinions, although courts do not necessarily have to apply Copyright Office guidance when weighing cases.
The Copyright Office’s aspirational timeline does seem to be ahead of when at least some courts can be expected to decide on some of the biggest copyright questions for some creators. The class-action lawsuit raised by book authors against OpenAI, for example, is not expected to be resolved until February 2025, and the New York Times’ lawsuit is likely on a similar timeline. However, artists suing Stability AI face a hearing on that AI company’s motion to dismiss this May.
Enlarge/ A screenshot of AI-generated songs listed on Udio on April 10, 2024.
Benj Edwards
Between 2002 and 2005, I ran a music website where visitors could submit song titles that I would write and record a silly song around. In the liner notes for my first CD release in 2003, I wrote about a day when computers would potentially put me out of business, churning out music automatically at a pace I could not match. While I don’t actively post music on that site anymore, that day is almost here.
On Wednesday, a group of ex-DeepMind employees launched Udio, a new AI music synthesis service that can create novel high-fidelity musical audio from written prompts, including user-provided lyrics. It’s similar to Suno, which we covered on Monday. With some key human input, Udio can create facsimiles of human-produced music in genres like country, barbershop quartet, German pop, classical, hard rock, hip hop, show tunes, and more. It’s currently free to use during a beta period.
Udio is also freaking out some musicians on Reddit. As we mentioned in our Suno piece, Udio is exactly the kind of AI-powered music generation service that over 200 musical artists were afraid of when they signed an open protest letter last week.
But as impressive as the Udio songs first seem from a technical AI-generation standpoint (not necessarily judging by musical merit), its generation capability isn’t perfect. We experimented with its creation tool and the results felt less impressive than those created by Suno. The high-quality musical samples showcased on Udio’s site likely resulted from a lot of creative human input (such as human-written lyrics) and cherry-picking the best compositional parts of songs out of many generations. In fact, Udio lays out a five-step workflow to build a 1.5-minute-long song in a FAQ.
For example, we created an Ars Technica “Moonshark” song on Udio using the same prompt as one we used previously with Suno. In its raw form, the results sound half-baked and almost nightmarish (here is the Suno version for comparison). It’s also a lot shorter by default at 32 seconds compared to Suno’s 1-minute and 32-second output. But Udio allows songs to be extended, or you can try generating a poor result again with different prompts for different results.
After registering a Udio account, anyone can create a track by entering a text prompt that can include lyrics, a story direction, and musical genre tags. Udio then tackles the task in two stages. First, it utilizes a large language model (LLM) similar to ChatGPT to generate lyrics (if necessary) based on the provided prompt. Next, it synthesizes music using a method that Udio does not disclose, but it’s likely a diffusion model, similar to Stability AI’s Stable Audio.
From the given prompt, Udio’s AI model generates two distinct song snippets for you to choose from. You can then publish the song for the Udio community, download the audio or video file to share on other platforms, or directly share it on social media. Other Udio users can also remix or build on existing songs. Udio’s terms of service say that the company claims no rights over the musical generations and that they can be used for commercial purposes.
Although the Udio team has not revealed the specific details of its model or training data (which is likely filled with copyrighted material), it told Tom’s Guide that the system has built-in measures to identify and block tracks that too closely resemble the work of specific artists, ensuring that the generated music remains original.
And that brings us back to humans, some of whom are not taking the onset of AI-generated music very well. “I gotta be honest, this is depressing as hell,” wrote one Reddit commenter in a thread about Udio. “I’m still broadly optimistic that music will be fine in the long run somehow. But like, why do this? Why automate art?”
We’ll hazard an answer by saying that replicating art is a key target for AI research because the results can be inaccurate and imprecise and still seem notable or gee-whiz amazing, which is a key characteristic of generative AI. It’s flashy and impressive-looking while allowing for a general lack of quantitative rigor. We’ve already seen AI come for still images, video, and text with varied results regarding representative accuracy. Fully composed musical recordings seem to be next on the list of AI hills to (approximately) conquer, and the competition is heating up.
We’ve come a long way since primitive AI music generators in 2022. Today, AI tools like Suno.ai allow any series of words to become song lyrics, including inside jokes (as you’ll see below). On Wednesday, prompt engineer Riley Goodside tweeted an AI-generated song created with the prompt “sad girl with piano performs the text of the MIT License,” and it began to circulate widely in the AI community online.
The MIT License is a famous permissive software license created in the late 1980s, frequently used in open source projects. “My favorite part of this is ~1: 25 it nails ‘WARRANTIES OF MERCHANTABILITY’ with a beautiful Imogen Heap-style glissando then immediately pronounces ‘FITNESS’ as ‘fistiff,'” Goodside wrote on X.
Suno (which means “listen” in Hindi) was formed in 2023 in Cambridge, Massachusetts. It’s the brainchild of Michael Shulman, Georg Kucsko, Martin Camacho, and Keenan Freyberg, who formerly worked at companies like Meta and TikTok. Suno has already attracted big-name partners, such as Microsoft, which announced the integration of an earlier version of the Suno engine into Bing Chat last December. Today, Suno is on v3 of its model, which can create temporally coherent two-minute songs in many different genres.
The company did not reply to our request for an interview by press time. In March, Brian Hiatt of Rolling Stone wrote a profile about Suno that describes the service as a collaboration between OpenAI’s ChatGPT (for lyric writing) and Suno’s music generation model, which some experts think has likely been trained on recordings of copyrighted music without license or artist permission.
It’s exactly this kind of service that upset over 200 musical artists enough last week that they signed an Artist Rights Alliance open letter asking tech companies to stop using AI tools to generate music that could replace human artists.
Considering the unknown provenance of the training data, ownership of the generated songs seems like a complicated question. Suno’s FAQ says that music generated using its free tier remains owned by Suno and can only be used for non-commercial purposes. Paying subscribers reportedly own generated songs “while subscribed to Pro or Premier,” subject to Suno’s terms of service. However, the US Copyright Office took a stance last year that purely AI-generated visual art cannot be copyrighted, and while that standard has not yet been resolved for AI-generated music, it might eventually become official legal policy as well.
The Moonshark song
Enlarge/ A screenshot of the Suno.ai website showing lyrics of an AI-generated “Moonshark” song.
Benj Edwards
While using the service, Suno appears to have no trouble creating unique lyrics based on your prompt (unless you supply your own) and sets those words to stylized genres of music it generates based on its training dataset. It dynamically generates vocals as well, although they include audible aberrations. Suno’s output is not indistinguishable from high-fidelity human-created music yet, but given the pace of progress we’ve seen, that bridge could be crossed within the next year.
To get a sense of what Suno can do, we created an account on the site and prompted the AI engine to create songs about our mascot, Moonshark, and about barbarians with CRTs, two insidejokes at Ars. What’s interesting is that although the AI model aced the task of creating an original song for each topic, both songs start with the same line, “In the depths of the digital domain.” That’s possibly an artifact of whatever hidden prompt Suno is using to instruct ChatGPT when writing the lyrics.
Suno is arguably a fun toy to experiment with and doubtless a milestone in generative AI music tools. But it’s also an achievement tainted by the unresolved ethical issues related to scraping musical work without the artist’s permission. Then there’s the issue of potentially replacing human musicians, which has not been far from the minds of people sharing their own Suno results online. On Monday, AI influencer Ethan Mollick wrote, “I’ve had a song from Suno AI stuck in my head all day. Grim milestone or good one?”
























{kind=link}
{kind=link}
{kind=link}
{kind=link}