
The AI wars heat up with Claude 3, claimed to have “near-human” abilities

Enlarge / The Anthropic Claude 3 logo.
On Monday, Anthropic released Claude 3, a family of three AI language models similar to those that power ChatGPT. Anthropic claims the models set new industry benchmarks across a range of cognitive tasks, even approaching “near-human” capability in some cases. It’s available now through Anthropic’s website, with the most powerful model being subscription-only. It’s also available via API for developers.
Claude 3’s three models represent increasing complexity and parameter count: Claude 3 Haiku, Claude 3 Sonnet, and Claude 3 Opus. Sonnet powers the Claude.ai chatbot now for free with an email sign-in. But as mentioned above, Opus is only available through Anthropic’s web chat interface if you pay $20 a month for “Claude Pro,” a subscription service offered through the Anthropic website. All three feature a 200,000-token context window. (The context window is the number of tokens—fragments of a word—that an AI language model can process at once.)
We covered the launch of Claude in March 2023 and Claude 2 in July that same year. Each time, Anthropic fell slightly behind OpenAI’s best models in capability while surpassing them in terms of context window length. With Claude 3, Anthropic has perhaps finally caught up with OpenAI’s released models in terms of performance, although there is no consensus among experts yet—and the presentation of AI benchmarks is notoriously prone to cherry-picking.
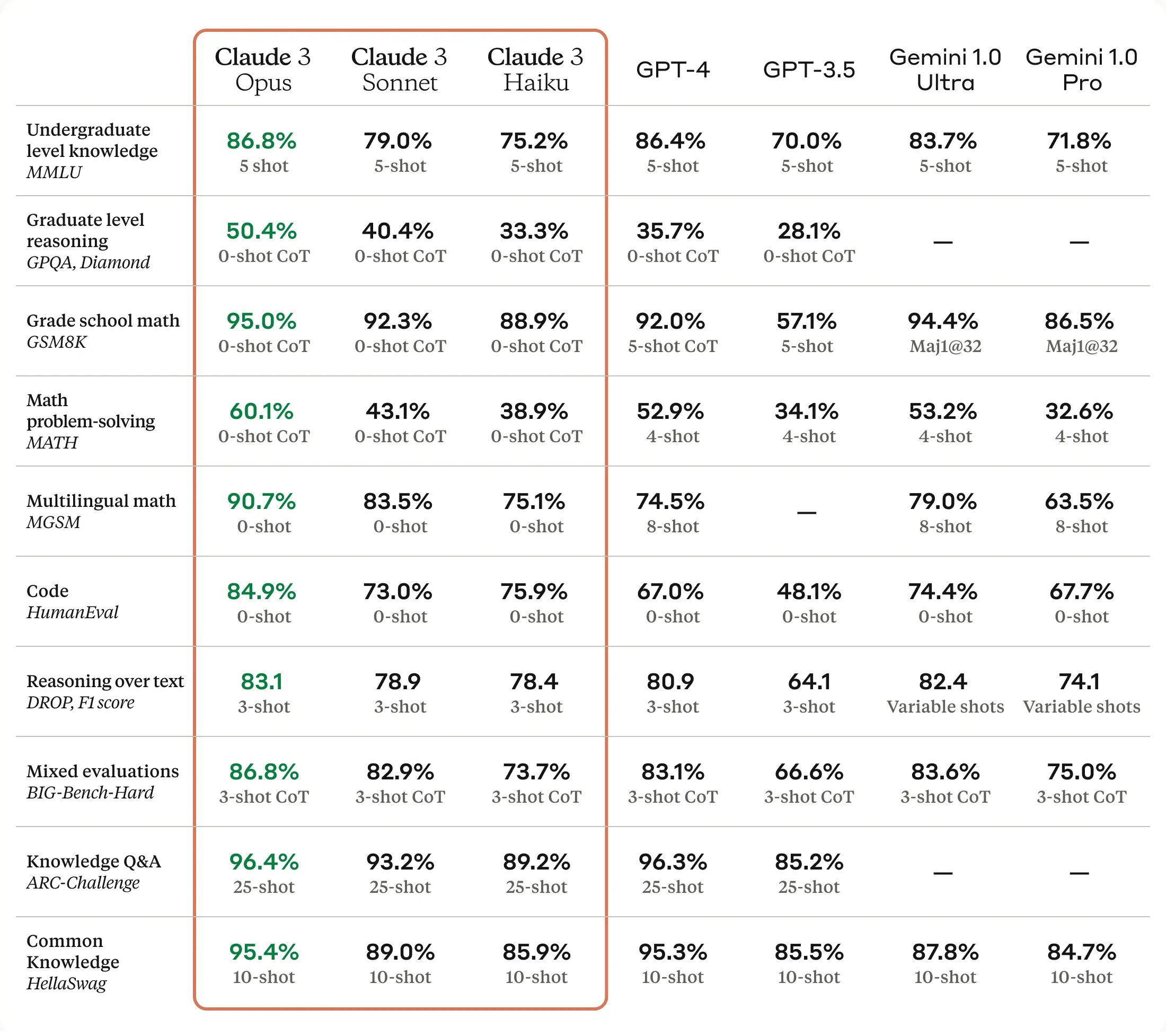
Enlarge / A Claude 3 benchmark chart provided by Anthropic.
Claude 3 reportedly demonstrates advanced performance across various cognitive tasks, including reasoning, expert knowledge, mathematics, and language fluency. (Despite the lack of consensus over whether large language models “know” or “reason,” the AI research community commonly uses those terms.) The company claims that the Opus model, the most capable of the three, exhibits “near-human levels of comprehension and fluency on complex tasks.”
That’s quite a heady claim and deserves to be parsed more carefully. It’s probably true that Opus is “near-human” on some specific benchmarks, but that doesn’t mean that Opus is a general intelligence like a human (consider that pocket calculators are superhuman at math). So, it’s a purposely eye-catching claim that can be watered down with qualifications.
According to Anthropic, Claude 3 Opus beats GPT-4 on 10 AI benchmarks, including MMLU (undergraduate level knowledge), GSM8K (grade school math), HumanEval (coding), and the colorfully named HellaSwag (common knowledge). Several of the wins are very narrow, such as 86.8 percent for Opus vs. 86.4 percent on a five-shot trial of MMLU, and some gaps are big, such as 84.9 percent on HumanEval over GPT-4’s 67.0 percent. But what that might mean, exactly, to you as a customer is difficult to say.
“As always, LLM benchmarks should be treated with a little bit of suspicion,” says AI researcher Simon Willison, who spoke with Ars about Claude 3. “How well a model performs on benchmarks doesn’t tell you much about how the model ‘feels’ to use. But this is still a huge deal—no other model has beaten GPT-4 on a range of widely used benchmarks like this.”
The AI wars heat up with Claude 3, claimed to have “near-human” abilities Read More »





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}