Inside the web infrastructure revolt over Google’s AI Overviews
Cloudflare CEO Matthew Prince is making sweeping changes to force Google’s hand.
It could be a consequential act of quiet regulation. Cloudflare, a web infrastructure company, has updated millions of websites’ robots.txt files in an effort to force Google to change how it crawls them to fuel its AI products and initiatives.
We spoke with Cloudflare CEO Matthew Prince about what exactly is going on here, why it matters, and what the web might soon look like. But to get into that, we need to cover a little background first.
The new change, which Cloudflare calls its Content Signals Policy, happened after publishers and other companies that depend on web traffic have cried foul over Google’s AI Overviews and similar AI answer engines, saying they are sharply cutting those companies’ path to revenue because they don’t send traffic back to the source of the information.
There have been lawsuits, efforts to kick-start new marketplaces to ensure compensation, and more—but few companies have the kind of leverage Cloudflare does. Its products and services back something close to 20 percent of the web, and thus a significant slice of the websites that show up on search results pages or that fuel large language models.
“Almost every reasonable AI company that’s out there is saying, listen, if it’s a fair playing field, then we’re happy to pay for content,” Prince said. “The problem is that all of them are terrified of Google because if Google gets content for free but they all have to pay for it, they are always going to be at an inherent disadvantage.”
This is happening because Google is using its dominant position in search to ensure that web publishers allow their content to be used in ways that they might not otherwise want it to.
The changing norms of the web
Since 2023, Google has offered a way for website administrators to opt their content out of use for training Google’s large language models, such as Gemini.
However, allowing pages to be indexed by Google’s search crawlers and shown in results requires accepting that they’ll also be used to generate AI Overviews at the top of results pages through a process called retrieval-augmented generation (RAG).
That’s not so for many other crawlers, making Google an outlier among major players.
This is a sore point for a wide range of website administrators, from news websites that publish journalism to investment banks that produce research reports.
A July study from the Pew Research Center analyzed data from 900 adults in the US and found that AI Overviews cut referrals nearly in half. Specifically, users clicked a link on a page with AI Overviews at the top just 8 percent of the time, compared to 15 percent for search engine results pages without those summaries.
And a report in The Wall Street Journal cited a wide range of sources—including internal traffic metrics from numerous major publications like The New York Times and Business Insider—to describe industry-wide plummets in website traffic that those publishers said were tied to AI summaries, leading to layoffs and strategic shifts.
In August, Google’s head of search, Liz Reid, disputed the validity and applicability of studies and publisher reports of reduced link clicks in search. “Overall, total organic click volume from Google Search to websites has been relatively stable year-over-year,” she wrote, going on to say that reports of big declines were “often based on flawed methodologies, isolated examples, or traffic changes that occurred prior to the rollout of AI features in Search.”
Publishers aren’t convinced. Penske Media Corporation, which owns brands like The Hollywood Reporter and Rolling Stone, sued Google over AI Overviews in September. The suit claims that affiliate link revenue has dropped by more than a third in the past year, due in large part to Google’s overviews—a threatening shortfall in a business that already has difficult margins.
Penske’s suit specifically noted that because Google bundles traditional search engine indexing and RAG use together, the company has no choice but to allow Google to keep summarizing its articles, as cutting off Google search referrals entirely would be financially fatal.
Since the earliest days of digital publishing, referrals have in one way or another acted as the backbone of the web’s economy. Content could be made available freely to both human readers and crawlers, and norms were applied across the web to allow information to be tracked back to its source and give that source an opportunity to monetize its content to sustain itself.
Today, there’s a panic that the old system isn’t working anymore as content summaries via RAG have become more common, and along with other players, Cloudflare is trying to update those norms to reflect the current reality.
A mass-scale update to robots.txt
Announced on September 24, Cloudflare’s Content Signals Policy is an effort to use the company’s influential market position to change how content is used by web crawlers. It involves updating millions of websites’ robots.txt files.
Starting in 1994, websites began placing a file called “robots.txt” at the domain root to indicate to automated web crawlers which parts of the domain should be crawled and indexed and which should be ignored. The standard became near-universal over the years; honoring it has been a key part of how Google’s web crawlers operate.
Historically, robots.txt simply includes a list of paths on the domain that were flagged as either “allow” or “disallow.” It was technically not enforceable, but it became an effective honor system because there are advantages to it for the owners of both the website and the crawler: Website owners could dictate access for various business reasons, and it helped crawlers avoid working through data that wouldn’t be relevant.
But robots.txt only tells crawlers whether they can access something at all; it doesn’t tell them what they can use it for. For example, Google supports disallowing the agent “Google-Extended” as a path to blocking crawlers that are looking for content with which to train future versions of its Gemini large language model—though introducing that rule doesn’t do anything about the training Google did before it rolled out Google-Extended in 2023, and it doesn’t stop crawling for RAG and AI Overviews.
The Content Signals Policy initiative is a newly proposed format for robots.txt that intends to do that. It allows website operators to opt in or out of consenting to the following use cases, as worded in the policy:
- search: Building a search index and providing search results (e.g., returning hyperlinks and short excerpts from your website’s contents). Search does not include providing AI-generated search summaries.
- ai-input: Inputting content into one or more AI models (e.g., retrieval augmented generation, grounding, or other real-time taking of content for generative AI search answers).
- ai-train: Training or fine-tuning AI models.
Cloudflare has given all of its customers quick paths for setting those values on a case-by-case basis. Further, it has automatically updated robots.txt on the 3.8 million domains that already use Cloudflare’s managed robots.txt feature, with search defaulting to yes, ai-train to no, and ai-input blank, indicating a neutral position.
The threat of potential litigation
In making this look a bit like a terms of service agreement, Cloudflare’s goal is explicitly to put legal pressure on Google to change its policy of bundling traditional search crawlers and AI Overviews.
“Make no mistake, the legal team at Google is looking at this saying, ‘Huh, that’s now something that we have to actively choose to ignore across a significant portion of the web,'” Prince told me.
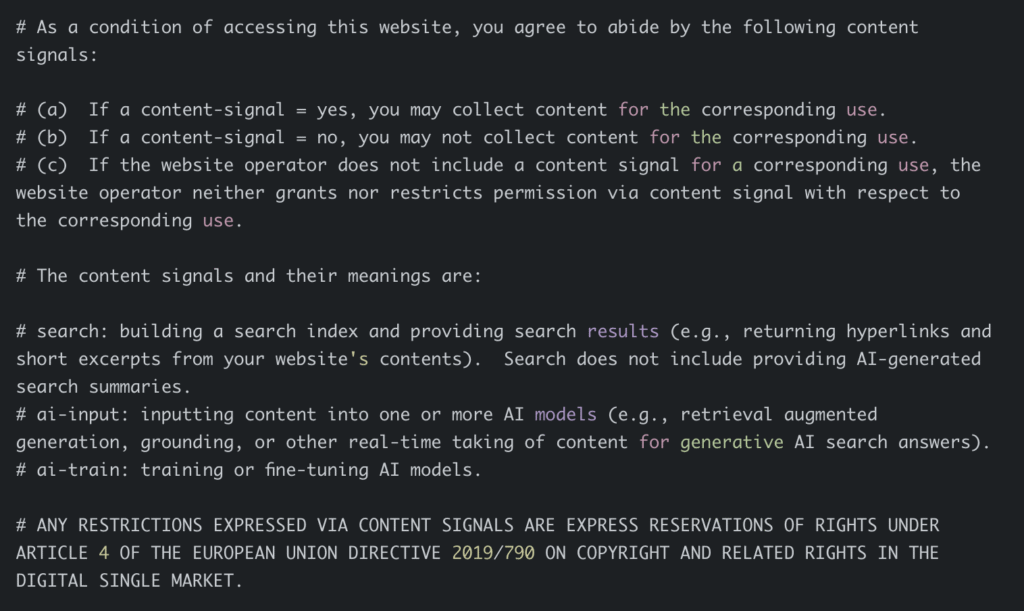
Cloudflare specifically made this look like a license agreement. Credit: Cloudflare
He further characterized this as an effort to get a company that he says has historically been “largely a good actor” and a “patron of the web” to go back to doing the right thing.
“Inside of Google, there is a fight where there are people who are saying we should change how we’re doing this,” he explained. “And there are other people saying, no, that gives up our inherent advantage, we have a God-given right to all the content on the Internet.”
Amid that debate, lawyers have sway at Google, so Cloudflare tried to design tools “that made it very clear that if they were going to follow any of these sites, there was a clear license which was in place for them. And that will create risk for them if they don’t follow it,” Prince said.
The next web paradigm
It takes a company with Cloudflare’s scale to do something like this with any hope that it will have an impact. If just a few websites made this change, Google would have an easier time ignoring it, or worse yet, it could simply stop crawling them to avoid the problem. Since Cloudflare is entangled with millions of websites, Google couldn’t do that without materially impacting the quality of the search experience.
Cloudflare has a vested interest in the general health of the web, but there are other strategic considerations at play, too. The company has been working on tools to assist with RAG on customers’ websites in partnership with Microsoft-owned Google competitor Bing and has experimented with a marketplace that provides a way for websites to charge crawlers for scraping the sites for AI, though what final form that might take is still unclear.
I asked Prince directly if this comes from a place of conviction. “There are very few times that opportunities come along where you get to help think through what a future better business model of an organization or institution as large as the Internet and as important as the Internet is,” he said. “As we do that, I think that we should all be thinking about what have we learned that was good about the Internet in the past and what have we learned that was bad about the Internet in the past.”
It’s important to acknowledge that we don’t yet know what the future business model of the web will look like. Cloudflare itself has ideas. Others have proposed new standards, marketplaces, and strategies, too. There will be winners and losers, and those won’t always be the same winners and losers we saw in the previous paradigm.
What most people seem to agree on, whatever their individual incentives, is that Google shouldn’t get to come out on top in a future answer-engine-driven web paradigm just because it previously established dominance in the search-engine-driven one.
For this new standard for robots.txt, success looks like Google allowing content to be available in search but not in AI Overviews. Whatever the long-term vision, and whether it happens because of Cloudflare’s pressure with the Content Signals Policy or some other driving force, most agree that it would be a good start.

Samuel Axon is the editorial lead for tech and gaming coverage at Ars Technica. He covers AI, software development, gaming, entertainment, and mixed reality. He has been writing about gaming and technology for nearly two decades at Engadget, PC World, Mashable, Vice, Polygon, Wired, and others. He previously ran a marketing and PR agency in the gaming industry, led editorial for the TV network CBS, and worked on social media marketing strategy for Samsung Mobile at the creative agency SPCSHP. He also is an independent software and game developer for iOS, Windows, and other platforms, and he is a graduate of DePaul University, where he studied interactive media and software development.
Inside the web infrastructure revolt over Google’s AI Overviews Read More »