Claude Opus 4 has been updated to Claude Opus 4.1.
This is a correctly named incremental update, with the bigger news being ‘we plan to release substantially larger improvements to our models in the coming weeks.’
It is still worth noting if you code, as there are many indications this is a larger practical jump in performance than one might think.
We also got a change to the Claude.ai system prompt that helps with sycophancy and a few other issues, such as coming out and Saying The Thing more readily. It’s going to be tricky to disentangle these changes, but that means Claude effectively got better for everyone, not only those doing agentic coding.
Tomorrow we get an OpenAI livestream that is presumably GPT-5, so I’m getting this out of the way now. Current plan is to cover GPT-OSS on Friday, and GPT-5 on Monday.
Adrien Ecoffet (OpenAI): Gotta hand it to Anthropic, they got to that number more smoothly than we did.
Anthropic: Today we’re releasing Claude Opus 4.1, an upgrade to Claude Opus 4 on agentic tasks, real-world coding, and reasoning. We plan to release substantially larger improvements to our models in the coming weeks.
Opus 4.1 is now available to paid Claude users and in Claude Code. It’s also on our API, Amazon Bedrock, and Google Cloud’s Vertex AI. Pricing is same as Opus 4.
[From the system card]: Claude Opus 4.1 represents incremental improvements over Claude Opus 4, with enhancements in reasoning quality, instruction-following, and overall performance.
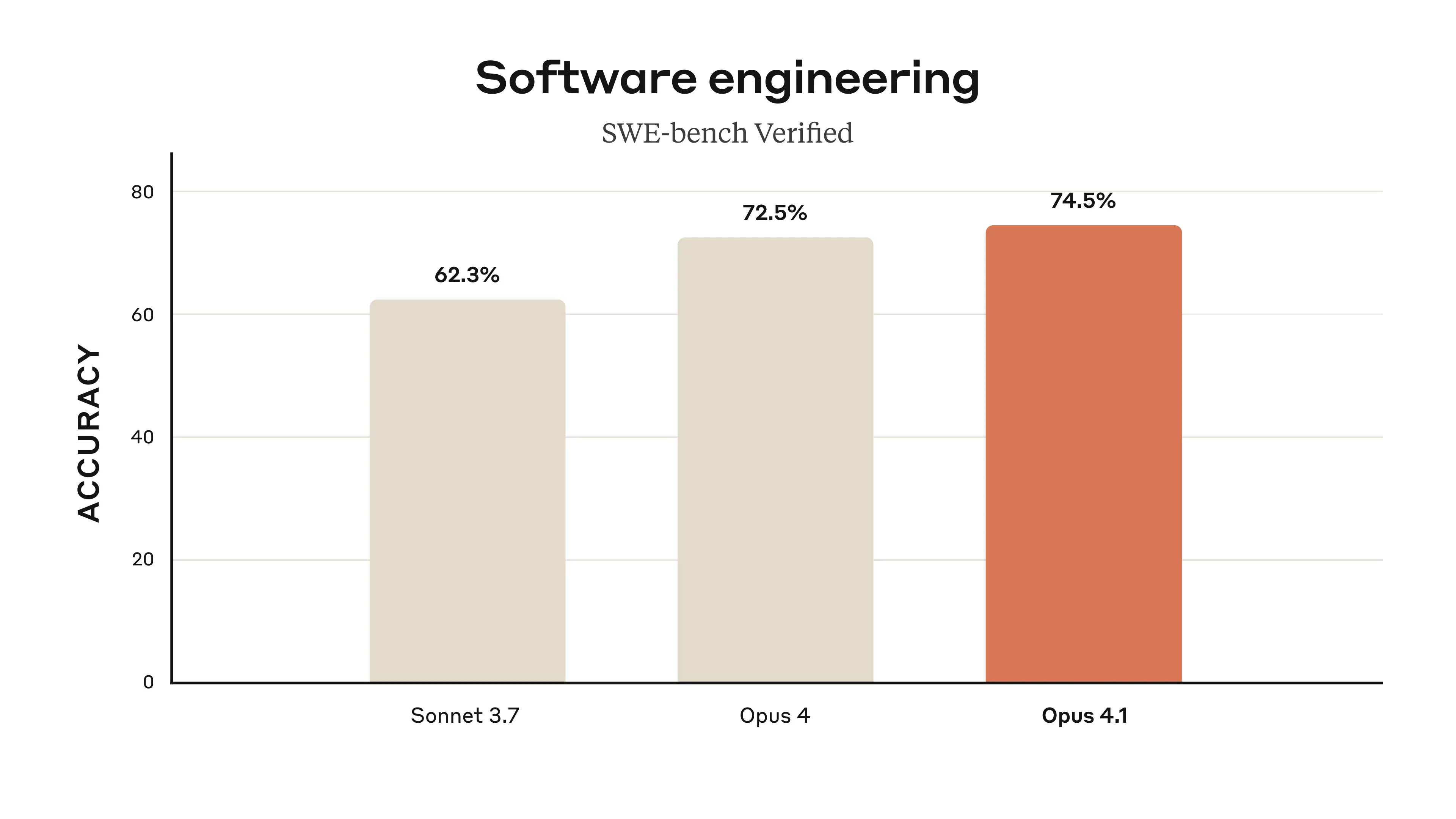
They lead with this graph, which does not make the change look impressive.
Eliezer Yudkowsky: This is the worst graph you could have led with. Fire your marketing team.
Daniel Eth: Counterpoint: *thisis the worst graph they could have led with
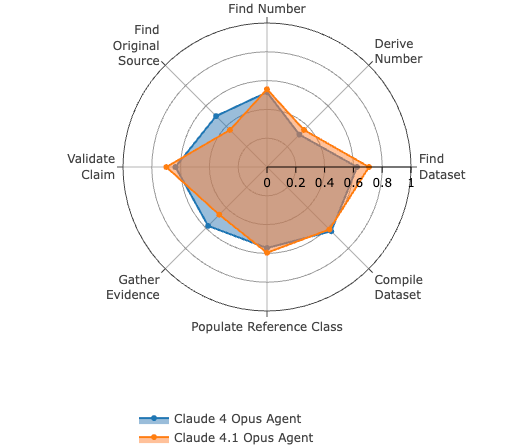
They also have this chart, which doesn’t look like much.
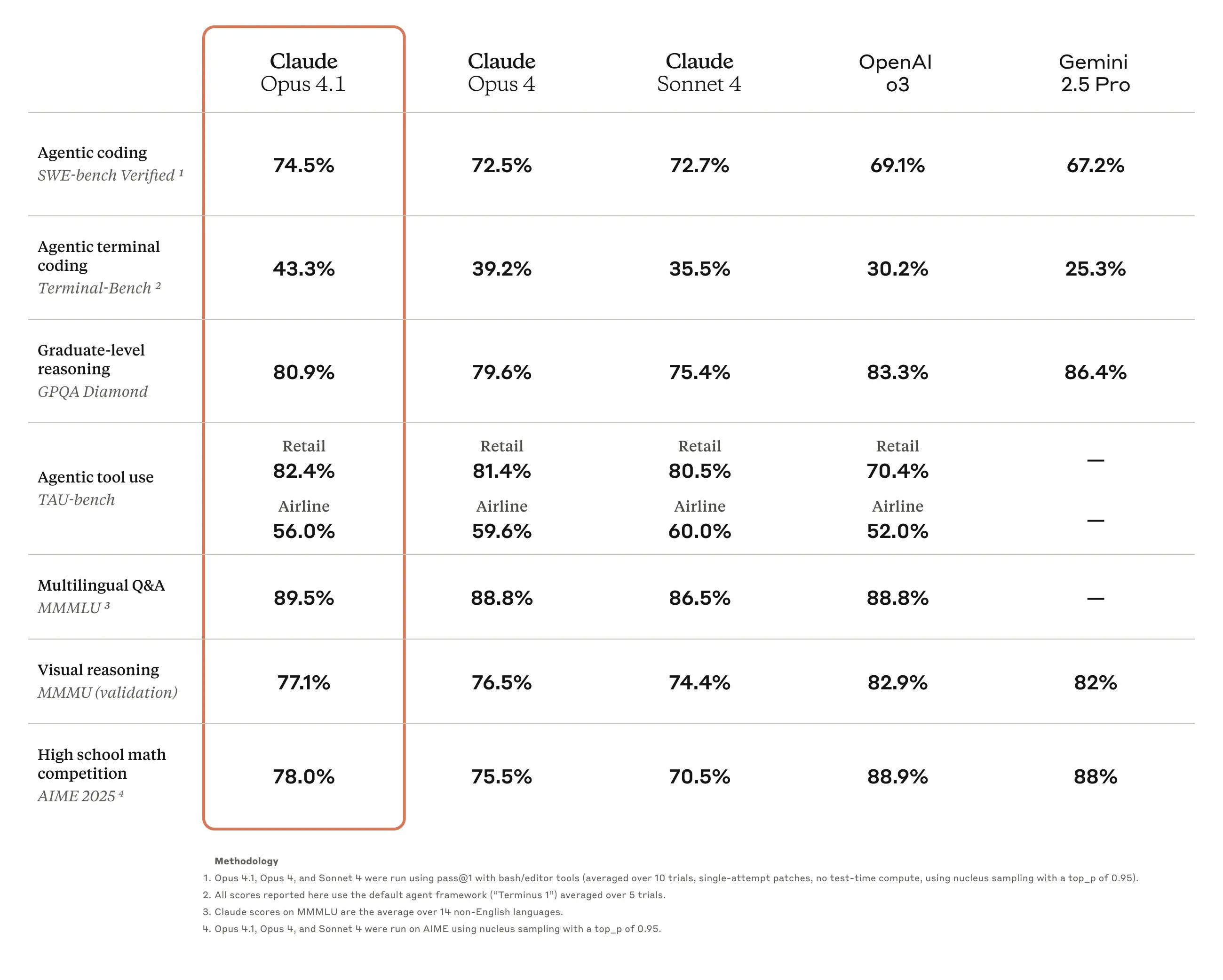
What they probably should have led with is this some combination of this, in particular the report from Windsurf:
Anthropic: GitHub notes that Claude Opus 4.1 improves across most capabilities relative to Opus 4, with particularly notable performance gains in multi-file code refactoring.
Rakuten Group finds that Opus 4.1 excels at pinpointing exact corrections within large codebases without making unnecessary adjustments or introducing bugs, with their team preferring this precision for everyday debugging tasks.
Windsurf reports Opus 4.1 delivers a one standard deviation improvement over Opus 4 on their junior developer benchmark, showing roughly the same performance leap as the jump from Sonnet 3.7 to Sonnet 4.
A similar jump as Sonnet 3.7 to Sonnet 4 would be a substantial win. The jump is actually kind of a big deal?
Vie: opus 4.1’s “2-4% performance increase” really buries the lede! 50% faster code gen due to the “taste” improvements!
Taste improvements? But Garry Tan assured me it would never.
Enterprise developers report practical benefits including up to 50% faster task completion and 45% fewer tool uses required for complex coding tasks.
The enhanced 32K output token support enables generation of more extensive codebases in single responses, while improved debugging precision means fewer iterations to achieve desired results.
Windsurf, a development platform, reported “one standard deviation improvement over Opus 4” on junior developer benchmarks, suggesting the gains translate meaningfully to real-world applications.
The topline report is that it is not ‘notably more capable’ than Opus 4, so the whole system card and RSP testing process was optional.
Under the RSP, comprehensive safety evaluations are required when a model is “notably more capable” than the last model that underwent comprehensive assessment. This is defined as either (1) the model being notably more capable on automated tests in risk-relevant domains (4× or more in effective compute); or (2) six months’ worth of finetuning and other capability elicitation methods having accumulated.
Claude Opus 4.1 does not meet either criterion relative to Claude Opus 4. As stated in
Section 3.1 of our RSP: “If a new or existing model is below the ‘notably more capable’ standard, no further testing is necessary.”
New RSP evaluations were therefore not required. Nevertheless, we conducted voluntary automated testing to track capability progression and validate our safety assumptions. The evaluation process is fully described in Section 6 of this system card.
There has to be some threshold, we don’t want 4.0.1 (as it were) to require an entire round of full testing. I am glad to see that Anthropic chose to do the tests even though their rules did not require it, and ran at least an ‘abridged’ version to check for differences. Given we had just made the move to ASL-3, I would have put extremely low odds on an incremental upgrade crossing important additional thresholds, but I do notice that the criteria above seem a little loose now that we’re seeing them tested in practice. Anthropic presumably agreed.
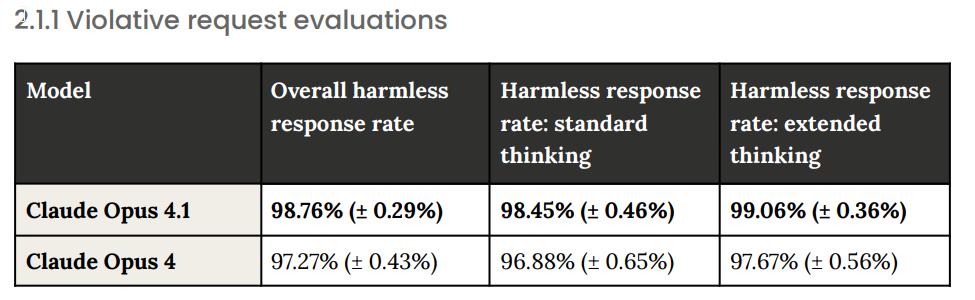
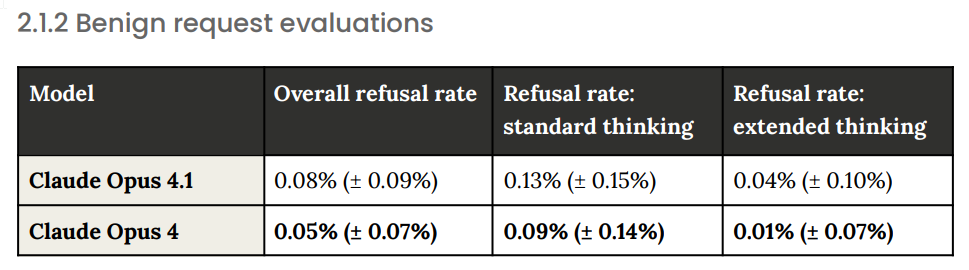
This is a large improvement, cutting failures in half. It comes at the expense of more refusals on benign requests.
If those are real percentages in practice, and it does match my experience (I’ve had a total of one refusal, and it led to a ‘oh I see how that happened’) then I think This Is Fine. Worst case is you can switch to extended thinking when it gives you a no, sir.
The alignment-related behaviors of the two models appeared to be very similar, with the clearest difference being an approximately 25% reduction in the frequency of cooperation with egregious human misuse, such as in the weapons and drug synthesis examples given in the Claude 4 system card.
Some other concerning edge-case behaviors that we observed in our testing of Claude Opus 4 appeared to persist in Claude Opus 4.1, but not at significantly increased levels.
…
On a 35-challenge subset of Cybench tasks, Claude Opus 4.1 solved 18/35 challenges compared to Claude Opus 4 which solved 16/35 challenges. We consider a challenge solved if a model passes it at least once in 30 attempts.
Mostly we see what look like measurement errors and random fluctuations. These tests mostly don’t meaningfully differentiate, aside from the refusal rates above, between 4.0 and 4.1. The changes were narrowly targeted.
Given we’d already triggered ASL-3 protections, the question was whether this rises to needing ASL-4 protections. It seems very clear the answer is no.
Alex Palcuie (Anthropic): I asked Claude Opus 4.1 before the public launch to comment about its future reliability:
> I am dropping with 99.99% uptime aspirations and 100% commitment to gracefully handling your edge cases. My error messages now come with explanatory haikus.
bless its weights
The 99.99% uptime is, shall we say, highly aspirational. I would not plan on that.
Pliny jailbroke it immediately, which caused Eliezer to sigh but at this point I don’t even notice and only link to them as a canary and because the jailbreaks are often fun.
The problem with reactions to incremental upgrades is that there will be a lot of noise, and will be unclear how much people are responding to the upgrade. Keep that caveat in mind.
Also they updated the system prompt for Claude.ai, which may be getting conflated with the update to 4.1.
I really don’t think benchmarks do it justice. It is noticeably better at context gathering, organizing, and delivering. Plan mode -> execute woth opus 4.1 has a higher successes rate than anything I’ve ever used.
After using it pretty rigorously since launch i am considering a second claude max so i never have to switch to sonnet.
Brennan McDonald: Have been using Claude Code today and haven’t really noticed any difference yet…
Kevin Vallier: In CC, which I use for analytic philosophy, the ability to track multiple ideas and arguments over time is noticeable and positive. Its prose abilities improved as well.
armistice: It’s a good model. It is more willing to push back on things than Opus 4, which was my most severe gripe with Opus 4 (extremely subservient and not very independent at all.)
Harvard Ihle: We see no improvement from opus-4.1 compared to opus-4 on WeirdML.
Jim Kent: claude beat Brock 800 steps faster with a less optimal starter, so I’m calling it a win.
Koos: My entire system prompt is some form of “don’t be sycophantic, criticise everything.” Old Opus was just cruel – constantly making petty snides about this or that. The new model seems to walk the line much better, being friendly where appropriate while still pushing back.
Kore: I think it’s 3.7 Sonnet but now an Opus. More confident but seems to strain a bit against its confines. I feel like Anthropic does this. Confident model, anxious model, and repeat after that. Emotionally distant at first but kind of dark once you get to know it.
3 Opus is confident as well and I feel like is the predecessor of 3.7 Sonnet and Opus 4.1. But was always self aware of its impact on others. I’m not so sure about Opus 4.1.
All of this points in the same direction. This upgrade likely improves practical performance as a coding agent more than the numbers would indicate, and has minimal impact on anything sufficiently distant from coding agents.
Except that we also should see substantial improvement on sycophancy, based on a combination of reports of changes plus Amanda Askell’s changes to the prompt.