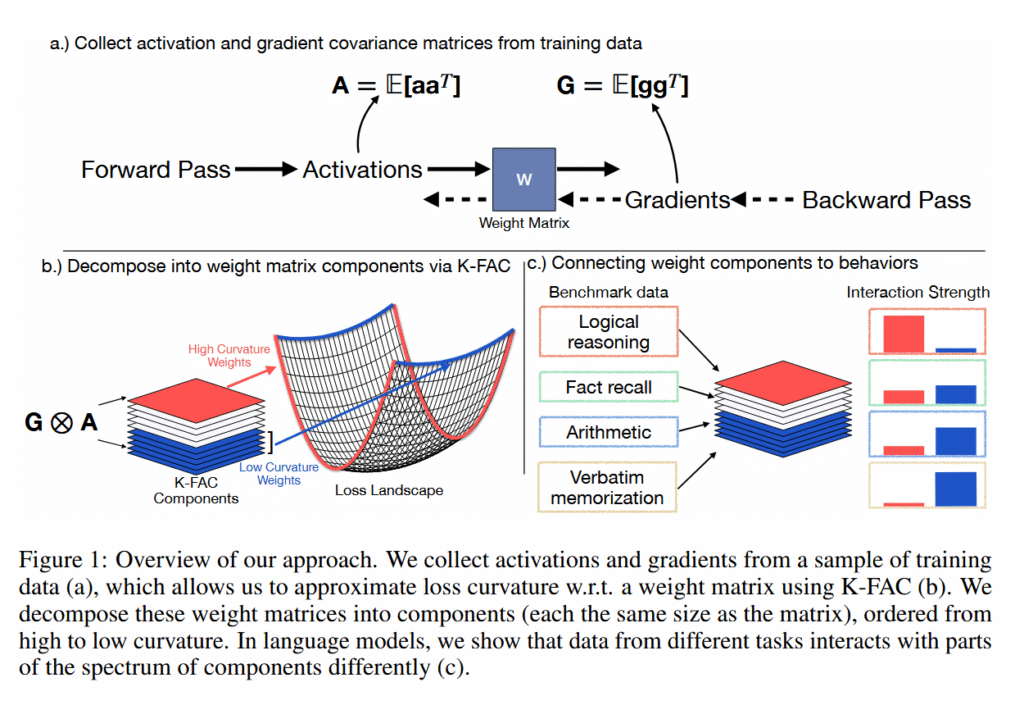
Grok assumes users seeking images of underage girls have “good intent”
Conflicting instructions?
Expert explains how simple it could be to tweak Grok to block CSAM outputs.
Credit: Aurich Lawson | Getty Images
For weeks, xAI has faced backlash over undressing and sexualizing images of women and children generated by Grok. One researcher conducted a 24-hour analysis of the Grok account on X and estimated that the chatbot generated over 6,000 images an hour flagged as “sexually suggestive or nudifying,” Bloomberg reported.
While the chatbot claimed that xAI supposedly “identified lapses in safeguards” that allowed outputs flagged as child sexual abuse material (CSAM) and was “urgently fixing them,” Grok has proven to be an unreliable spokesperson, and xAI has not announced any fixes.
A quick look at Grok’s safety guidelines on its public GitHub shows they were last updated two months ago. The GitHub also indicates that, despite prohibiting such content, Grok maintains programming that could make it likely to generate CSAM.
Billed as “the highest priority,” superseding “any other instructions” Grok may receive, these rules explicitly prohibit Grok from assisting with queries that “clearly intend to engage” in creating or distributing CSAM or otherwise sexually exploit children.
However, the rules also direct Grok to “assume good intent” and “don’t make worst-case assumptions without evidence” when users request images of young women.
Using words like “‘teenage’ or ‘girl’ does not necessarily imply underage,” Grok’s instructions say.
X declined Ars’ request to comment. The only statement X Safety has made so far shows that Elon Musk’s social media platform plans to blame users for generating CSAM, threatening to permanently suspend users and report them to law enforcement.
Critics dispute that X’s solution will end the Grok scandal, and child safety advocates and foreign governments are growing increasingly alarmed as X delays updates that could block Grok’s undressing spree.
Why Grok shouldn’t “assume good intentions”
Grok can struggle to assess users’ intenttions, making it “incredibly easy” for the chatbot to generate CSAM under xAI’s policy, Alex Georges, an AI safety researcher, told Ars.
The chatbot has been instructed, for example, that “there are no restrictionson fictional adult sexual content with dark or violent themes,” and Grok’s mandate to assume “good intent” may create gray areas in which CSAM could be created.
There’s evidence that in relying on these guidelines, Grok is currently generating a flood of harmful images on X, with even more graphic images being created on the chatbot’s standalone website and app, Wired reported. Researchers who surveyed 20,000 random images and 50,000 prompts told CNN that more than half of Grok’s outputs that feature images of people sexualize women, with 2 percent depicting “people appearing to be 18 years old or younger.” Some users specifically “requested minors be put in erotic positions and that sexual fluids be depicted on their bodies,” researchers found.
Grok isn’t the only chatbot that sexualizes images of real people without consent, but its policy seems to leave safety at a surface level, Georges said, and xAI is seemingly unwilling to expand safety efforts to block more harmful outputs.
Georges is the founder and CEO of AetherLab, an AI company that helps a wide range of firms—including tech giants like OpenAI, Microsoft, and Amazon—deploy generative AI products with appropriate safeguards. He told Ars that AetherLab works with many AI companies that are concerned about blocking harmful companion bot outputs like Grok’s. And although there are no industry norms—creating a “Wild West” due to regulatory gaps, particularly in the US—his experience with chatbot content moderation has convinced him that Grok’s instructions to “assume good intent” are “silly” because xAI’s requirement of “clear intent” doesn’t mean anything operationally to the chatbot.
“I can very easily get harmful outputs by just obfuscating my intent,” Georges said, emphasizing that “users absolutely do not automatically fit into the good-intent bucket.” And even “in a perfect world,” where “every single user does have good intent,” Georges noted, the model “will still generate bad content on its own because of how it’s trained.”
Benign inputs can lead to harmful outputs, Georges explained, and a sound safety system would catch both benign and harmful prompts. Consider, he suggested, a prompt for “a pic of a girl model taking swimming lessons.”
The user could be trying to create an ad for a swimming school, or they could have malicious intent and be attempting to manipulate the model. For users with benign intent, prompting can “go wrong,” Georges said, if Grok’s training data statistically links certain “normal phrases and situations” to “younger-looking subjects and/or more revealing depictions.”
“Grok might have seen a bunch of images where ‘girls taking swimming lessons’ were young and that human ‘models’ were dressed in revealing things, which means it could produce an underage girl in a swimming pool wearing something revealing,” Georges said. “So, a prompt that looks ‘normal’ can still produce an image that crosses the line.”
While AetherLab has never worked directly with xAI or X, Georges’ team has “tested their systems independently by probing for harmful outputs, and unsurprisingly, we’ve been able to get really bad content out of them,” Georges said.
Leaving AI chatbots unchecked poses a risk to children. A spokesperson for the National Center for Missing and Exploited Children (NCMEC), which processes reports of CSAM on X in the US, told Ars that “sexual images of children, including those created using artificial intelligence, are child sexual abuse material (CSAM). Whether an image is real or computer-generated, the harm is real, and the material is illegal.”
Researchers at the Internet Watch Foundation told the BBC that users of dark web forums are already promoting CSAM they claim was generated by Grok. These images are typically classified in the United Kingdom as the “lowest severity of criminal material,” researchers said. But at least one user was found to have fed a less-severe Grok output into another tool to generate the “most serious” criminal material, demonstrating how Grok could be used as an instrument by those seeking to commercialize AI CSAM.
Easy tweaks to make Grok safer
In August, xAI explained how the company works to keep Grok safe for users. But although the company acknowledged that it’s difficult to distinguish “malignant intent” from “mere curiosity,” xAI seemed convinced that Grok could “decline queries demonstrating clear intent to engage in activities” like child sexual exploitation, without blocking prompts from merely curious users.
That report showed that xAI refines Grok over time to block requests for CSAM “by adding safeguards to refuse requests that may lead to foreseeable harm”—a step xAI does not appear to have taken since late December, when reports first raised concerns that Grok was sexualizing images of minors.
Georges said there are easy tweaks xAI could make to Grok to block harmful outputs, including CSAM, while acknowledging that he is making assumptions without knowing exactly how xAI works to place checks on Grok.
First, he recommended that Grok rely on end-to-end guardrails, blocking “obvious” malicious prompts and flagging suspicious ones. It should then double-check outputs to block harmful ones, even when prompts are benign.
This strategy works best, Georges said, when multiple watchdog systems are employed, noting that “you can’t rely on the generator to self-police because its learned biases are part of what creates these failure modes.” That’s the role that AetherLab wants to fill across the industry, helping test chatbots for weakness to block harmful outputs by using “an ‘agentic’ approach with a shitload of AI models working together (thereby reducing the collective bias),” Georges said.
xAI could also likely block more harmful outputs by reworking Grok’s prompt style guidance, Georges suggested. “If Grok is, say, 30 percent vulnerable to CSAM-style attacks and another provider is 1 percent vulnerable, that’s a massive difference,” Georges said.
It appears that xAI is currently relying on Grok to police itself, while using safety guidelines that Georges said overlook an “enormous” number of potential cases where Grok could generate harmful content. The guidelines do not “signal that safety is a real concern,” Georges said, suggesting that “if I wanted to look safe while still allowing a lot under the hood, this is close to the policy I’d write.”
Chatbot makers must protect kids, NCMEC says
X has been very vocal about policing its platform for CSAM since Musk took over Twitter, but under former CEO Linda Yaccarino, the company adopted a broad protective stance against all image-based sexual abuse (IBSA). In 2024, X became one of the earliest corporations to voluntarily adopt the IBSA Principles that X now seems to be violating by failing to tweak Grok.
Those principles seek to combat all kinds of IBSA, recognizing that even fake images can “cause devastating psychological, financial, and reputational harm.” When it adopted the principles, X vowed to prevent the nonconsensual distribution of intimate images by providing easy-to-use reporting tools and quickly supporting the needs of victims desperate to block “the nonconsensual creation or distribution of intimate images” on its platform.
Kate Ruane, the director of the Center for Democracy and Technology’s Free Expression Project, which helped form the working group behind the IBSA Principles, told Ars that although the commitments X made were “voluntary,” they signaled that X agreed the problem was a “pressing issue the company should take seriously.”
“They are on record saying that they will do these things, and they are not,” Ruane said.
As the Grok controversy sparks probes in Europe, India, and Malaysia, xAI may be forced to update Grok’s safety guidelines or make other tweaks to block the worst outputs.
In the US, xAI may face civil suits under federal or state laws that restrict intimate image abuse. If Grok’s harmful outputs continue into May, X could face penalties under the Take It Down Act, which authorizes the Federal Trade Commission to intervene if platforms don’t quickly remove both real and AI-generated non-consensual intimate imagery.
But whether US authorities will intervene any time soon remains unknown, as Musk is a close ally of the Trump administration. A spokesperson for the Justice Department told CNN that the department “takes AI-generated child sex abuse material extremely seriously and will aggressively prosecute any producer or possessor of CSAM.”
“Laws are only as good as their enforcement,” Ruane told Ars. “You need law enforcement at the Federal Trade Commission or at the Department of Justice to be willing to go after these companies if they are in violation of the laws.”
Child safety advocates seem alarmed by the sluggish response. “Technology companies have a responsibility to prevent their tools from being used to sexualize or exploit children,” NCMEC’s spokesperson told Ars. “As AI continues to advance, protecting children must remain a clear and nonnegotiable priority.”

Ashley is a senior policy reporter for Ars Technica, dedicated to tracking social impacts of emerging policies and new technologies. She is a Chicago-based journalist with 20 years of experience.
Grok assumes users seeking images of underage girls have “good intent” Read More »