Big Tech joins forces with Linux Foundation to standardize AI agents
Big Tech has spent the past year telling us we’re living in the era of AI agents, but most of what we’ve been promised is still theoretical. As companies race to turn fantasy into reality, they’ve developed a collection of tools to guide the development of generative AI. A cadre of major players in the AI race, including Anthropic, Block, and OpenAI, has come together to promote interoperability with the newly formed Agentic AI Foundation (AAIF). This move elevates a handful of popular technologies and could make them a de facto standard for AI development going forward.
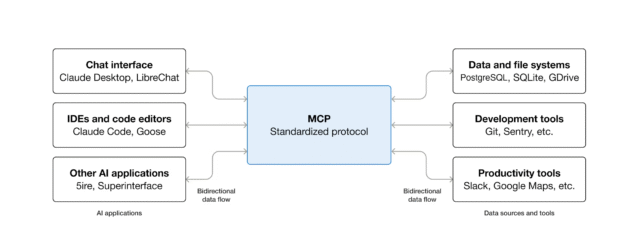
The development path for agentic AI models is cloudy to say the least, but companies have invested so heavily in creating these systems that some tools have percolated to the surface. The AAIF, which is part of the nonprofit Linux Foundation, has been launched to govern the development of three key AI technologies: Model Context Protocol (MCP), goose, and AGENTS.md.
MCP is probably the most well-known of the trio, having been open-sourced by Anthropic a year ago. The goal of MCP is to link AI agents to data sources in a standardized way—Anthropic (and now the AAIF) is fond of calling MCP a “USB-C port for AI.” Rather than creating custom integrations for every different database or cloud storage platform, MCP allows developers to quickly and easily connect to any MCP-compliant server.
Since its release, MCP has been widely used across the AI industry. Google announced at I/O 2025 that it was adding support for MCP in its dev tools, and many of its products have since added MCP servers to make data more accessible to agents. OpenAI also adopted MCP just a few months after it was released.
Credit: Anthropic
Expanding use of MCP might help users customize their AI experience. For instance, the new Pebble Index 01 ring uses a local LLM that can act on your voice notes, and it supports MCP for user customization.
Local AI models have to make some sacrifices compared to bigger cloud-based models, but MCP can fill in the functionality gaps. “A lot of tasks on productivity and content are fully doable on the edge,” Qualcomm head of AI products, Vinesh Sukumar, tells Ars. “With MCP, you have a handshake with multiple cloud service providers for any kind of complex task to be completed.”
Big Tech joins forces with Linux Foundation to standardize AI agents Read More »