Back in February, Elon Musk skewered the Treasury Department for lacking “basic controls” to stop payments to terrorist organizations, boasting at the Oval Office that “any company” has those controls.
Fast-forward three months, and now Musk’s social media platform X is suspected of taking payments from sanctioned terrorists and providing premium features that make it easier to raise funds and spread propaganda—including through X’s chatbot Grok. Groups seemingly benefiting from X include Houthi rebels, Hezbollah, and Hamas, as well as groups from Syria, Kuwait, and Iran. Some accounts have amassed hundreds of thousands of followers, paying to boost their reach while X seemingly looks the other way.
In a report released Thursday, the Tech Transparency Project (TTP) flagged popular accounts seemingly linked to US-sanctioned terrorists. Some of the accounts bear “ID verified” badges, suggesting that X may be going against its own policies that ban sanctioned terrorists from benefiting from its platform.
Even more troublingly, “several made use of revenue-generating features offered by X, including a button for tips,” the TTP reported.
On X, Premium subscribers pay $8 monthly or $84 annually, and Premium+ subscribers pay $40 monthly or $395 annually. Verified organizations pay X between $200 and $1,000 monthly, or up to $10,000 annually for access to Premium+. These subscriptions come with perks, allowing suspected terrorist accounts to share longer text and video posts, offer subscribers paid content, create communities, accept gifts, and amplify their propaganda.
Disturbingly, the TTP found that X’s chatbot Grok also appears to be helping to whitewash accounts linked to sanctioned terrorists.
In its report, the TTP noted that an account with the handle “hasmokaled”—which apparently belongs to “a key Hezbollah money exchanger,” Hassan Moukalled—at one point had a blue checkmark with 60,000 followers. While the Treasury Department has sanctioned Moukalled for propping up efforts “to continue to exploit and exacerbate Lebanon’s economic crisis,” clicking the Grok AI profile summary button seems to rely on Moukalled’s own posts and his followers’ impressions of his posts and therefore generated praise.
The treatment of white farmers in South Africa has been a hobbyhorse of South African X owner Elon Musk for quite a while. In 2023, he responded to a video purportedly showing crowds chanting “kill the Boer, kill the White Farmer” with a post alleging South African President Cyril Ramaphosa of remaining silent while people “openly [push] for genocide of white people in South Africa.” Musk was posting other responses focusing on the issue as recently as Wednesday.
They are openly pushing for genocide of white people in South Africa. @CyrilRamaphosa, why do you say nothing?
Former American Ambassador to South Africa and Democratic politician Patrick Gaspard posted in 2018 that the idea of large-scale killings of white South African farmers is a “disproven racial myth.”
In launching the Grok 3 model in February, Musk said it was a “maximally truth-seeking AI, even if that truth is sometimes at odds with what is politically correct.” X’s “About Grok” page says that the model is undergoing constant improvement to “ensure Grok remains politically unbiased and provides balanced answers.”
But the recent turn toward unprompted discussions of alleged South African “genocide” has many questioning what kind of explicit adjustments Grok’s political opinions may be getting from human tinkering behind the curtain. “The algorithms for Musk products have been politically tampered with nearly beyond recognition,” journalist Seth Abramson wrote in one representative skeptical post. “They tweaked a dial on the sentence imitator machine and now everything is about white South Africans,” a user with the handle Guybrush Threepwood glibly theorized.
Representatives from xAI were not immediately available to respond to a request for comment from Ars Technica.
The release comes just two weeks after OpenAI made GPT-4 unavailable in ChatGPT on April 30. That earlier model, which launched in March 2023, once sparked widespread hype about AI capabilities. Compared to that hyperbolic launch, GPT-4.1’s rollout has been a fairly understated affair—probably because it’s tricky to convey the subtle differences between all of the available OpenAI models.
As if 4.1’s launch wasn’t confusing enough, the release also roughly coincides with OpenAI’s July 2025 deadline for retiring the GPT-4.5 Preview from the API, a model one AI expert called a “lemon.” Developers must migrate to other options, OpenAI says, although GPT-4.5 will remain available in ChatGPT for now.
A confusing addition to OpenAI’s model lineup
In February, OpenAI CEO Sam Altman acknowledged on X his company’s confusing AI model naming practices, writing, “We realize how complicated our model and product offerings have gotten.” He promised that a forthcoming “GPT-5” model would consolidate the o-series and GPT-series models into a unified branding structure. But the addition of GPT-4.1 to ChatGPT appears to contradict that simplification goal.
So, if you use ChatGPT, which model should you use? If you’re a developer using the models through the API, the consideration is more of a trade-off between capability, speed, and cost. But in ChatGPT, your choice might be limited more by personal taste in behavioral style and what you’d like to accomplish. Some of the “more capable” models have lower usage limits as well because they cost more for OpenAI to run.
For now, OpenAI is keeping GPT-4o as the default ChatGPT model, likely due to its general versatility, balance between speed and capability, and personable style (conditioned using reinforcement learning and a specialized system prompt). The simulated reasoning models like 03 and 04-mini-high are slower to execute but can consider analytical-style problems more systematically and perform comprehensive web research that sometimes feels genuinely useful when it surfaces relevant (non-confabulated) web links. Compared to those, OpenAI is largely positioning GPT-4.1 as a speedier AI model for coding assistance.
Just remember that all of the AI models are prone to confabulations, meaning that they tend to make up authoritative-sounding information when they encounter gaps in their trained “knowledge.” So you’ll need to double-check all of the outputs with other sources of information if you’re hoping to use these AI models to assist with an important task.
Noyb has requested a response from Meta by May 21, but it seems unlikely that Meta will quickly cave in this fight.
In a blog post, Meta said that AI training on EU users was critical to building AI tools for Europeans that are informed by “everything from dialects and colloquialisms, to hyper-local knowledge and the distinct ways different countries use humor and sarcasm on our products.”
Meta argued that its AI training efforts in the EU are far more transparent than efforts from competitors Google and OpenAI, which, Meta noted, “have already used data from European users to train their AI models,” supposedly without taking the steps Meta has to inform users.
Also echoing a common refrain in the AI industry, another Meta blog warned that efforts to further delay Meta’s AI training in the EU could lead to “major setbacks,” pushing the EU behind rivals in the AI race.
“Without a reform and simplification of the European regulatory system, Europe threatens to fall further and further behind in the global AI race and lose ground compared to the USA and China,” Meta warned.
Noyb discredits this argument and noted that it can pursue injunctions in various jurisdictions to block Meta’s plan. The group said it’s currently evaluating options to seek injunctive relief and potentially even pursue a class action worth possibly “billions in damages” to ensure that 400 million monthly active EU users’ data rights are shielded from Meta’s perceived grab.
A Meta spokesperson reiterated to Ars that the company’s plan “follows extensive and ongoing engagement with the Irish Data Protection Commission,” while reiterating Meta’s statements in blogs that its AI training approach “reflects consensus among” EU Data Protection Authorities (DPAs).
But while Meta claims that EU regulators have greenlit its AI training plans, Noyb argues that national DPAs have “largely stayed silent on the legality of AI training without consent,” and Meta seems to have “simply moved ahead anyways.”
“This fight is essentially about whether to ask people for consent or simply take their data without it,” Schrems said, adding, “Meta’s absurd claims that stealing everyone’s personal data is necessary for AI training is laughable. Other AI providers do not use social network data—and generate even better models than Meta.”
The reconciliation bill primarily focuses on cuts to Medicaid access and increased health care fees for millions of Americans. The AI provision appears as an addition to these broader health care changes, potentially limiting debate on the technology’s policy implications.
The move is already inspiring backlash. On Monday, tech safety groups and at least one Democrat criticized the proposal, reports The Hill. Rep. Jan Schakowsky (D-Ill.), the ranking member on the Commerce, Manufacturing and Trade Subcommittee, called the proposal a “giant gift to Big Tech,” while nonprofit groups like the Tech Oversight Project and Consumer Reports warned it would leave consumers unprotected from AI harms like deepfakes and bias.
Big Tech’s White House connections
President Trump has already reversed several Biden-era executive orders on AI safety and risk mitigation. The push to prevent state-level AI regulation represents an escalation in the administration’s industry-friendly approach to AI policy.
Perhaps it’s no surprise, as the AI industry has cultivated close ties with the Trump administration since before the president took office. For example, Tesla CEO Elon Musk serves in the Department of Government Efficiency (DOGE), while entrepreneur David Sacks acts as “AI czar,” and venture capitalist Marc Andreessen reportedly advises the administration. OpenAI CEO Sam Altman appeared with Trump in an AI datacenter development plan announcement in January.
By limiting states’ authority over AI regulation, the provision could prevent state governments from using federal funds to develop AI oversight programs or support initiatives that diverge from the administration’s deregulatory stance. This restriction would extend beyond enforcement to potentially affect how states design and fund their own AI governance frameworks.
AI-driven fraud is leading people to verify every online interaction they have.
These days, when Nicole Yelland receives a meeting request from someone she doesn’t already know, she conducts a multistep background check before deciding whether to accept. Yelland, who works in public relations for a Detroit-based nonprofit, says she’ll run the person’s information through Spokeo, a personal data aggregator that she pays a monthly subscription fee to use. If the contact claims to speak Spanish, Yelland says, she will casually test their ability to understand and translate trickier phrases. If something doesn’t quite seem right, she’ll ask the person to join a Microsoft Teams call—with their camera on.
If Yelland sounds paranoid, that’s because she is. In January, before she started her current nonprofit role, Yelland says, she got roped into an elaborate scam targeting job seekers. “Now, I do the whole verification rigamarole any time someone reaches out to me,” she tells WIRED.
Digital imposter scams aren’t new; messaging platforms, social media sites, and dating apps have long been rife with fakery. In a time when remote work and distributed teams have become commonplace, professional communications channels are no longer safe, either. The same artificial intelligence tools that tech companies promise will boost worker productivity are also making it easier for criminals and fraudsters to construct fake personas in seconds.
On LinkedIn, it can be hard to distinguish a slightly touched-up headshot of a real person from a too-polished, AI-generated facsimile. Deepfake videos are getting so good that longtime email scammers are pivoting to impersonating people on live video calls. According to the US Federal Trade Commission, reports of job and employment related scams nearly tripled from 2020 to 2024, and actual losses from those scams have increased from $90 million to $500 million.
Yelland says the scammers that approached her back in January were impersonating a real company, one with a legitimate product. The “hiring manager” she corresponded with over email also seemed legit, even sharing a slide deck outlining the responsibilities of the role they were advertising. But during the first video interview, Yelland says, the scammers refused to turn their cameras on during a Microsoft Teams meeting and made unusual requests for detailed personal information, including her driver’s license number. Realizing she’d been duped, Yelland slammed her laptop shut.
These kinds of schemes have become so widespread that AI startups have emerged promising to detect other AI-enabled deepfakes, including GetReal Labs and Reality Defender. OpenAI CEO Sam Altman also runs an identity-verification startup called Tools for Humanity, which makes eye-scanning devices that capture a person’s biometric data, create a unique identifier for their identity, and store that information on the blockchain. The whole idea behind it is proving “personhood,” or that someone is a real human. (Lots of people working on blockchain technology say that blockchain is the solution for identity verification.)
But some corporate professionals are turning instead to old-fashioned social engineering techniques to verify every fishy-seeming interaction they have. Welcome to the Age of Paranoia, when someone might ask you to send them an email while you’re mid-conversation on the phone, slide into your Instagram DMs to ensure the LinkedIn message you sent was really from you, or request you text a selfie with a time stamp, proving you are who you claim to be. Some colleagues say they even share code words with each other, so they have a way to ensure they’re not being misled if an encounter feels off.
“What’s funny is, the lo-fi approach works,” says Daniel Goldman, a blockchain software engineer and former startup founder. Goldman says he began changing his own behavior after he heard a prominent figure in the crypto world had been convincingly deepfaked on a video call. “It put the fear of god in me,” he says. Afterward, he warned his family and friends that even if they hear what they believe is his voice or see him on a video call asking for something concrete—like money or an Internet password—they should hang up and email him first before doing anything.
Ken Schumacher, founder of the recruitment verification service Ropes, says he’s worked with hiring managers who ask job candidates rapid-fire questions about the city where they claim to live on their résumé, such as their favorite coffee shops and places to hang out. If the applicant is actually based in that geographic region, Schumacher says, they should be able to respond quickly with accurate details.
Another verification tactic some people use, Schumacher says, is what he calls the “phone camera trick.” If someone suspects the person they’re talking to over video chat is being deceitful, they can ask them to hold up their phone camera to show their laptop. The idea is to verify whether the individual may be running deepfake technology on their computer, obscuring their true identity or surroundings. But it’s safe to say this approach can also be off-putting: Honest job candidates may be hesitant to show off the inside of their homes or offices, or worry a hiring manager is trying to learn details about their personal lives.
“Everyone is on edge and wary of each other now,” Schumacher says.
While turning yourself into a human captcha may be a fairly effective approach to operational security, even the most paranoid admit these checks create an atmosphere of distrust before two parties have even had the chance to really connect. They can also be a huge time suck. “I feel like something’s gotta give,” Yelland says. “I’m wasting so much time at work just trying to figure out if people are real.”
Jessica Eise, an assistant professor studying climate change and social behavior at Indiana University Bloomington, says her research team has been forced to essentially become digital forensics experts due to the amount of fraudsters who respond to ads for paid virtual surveys. (Scammers aren’t as interested in the unpaid surveys, unsurprisingly.) For one of her research projects, which is federally funded, all of the online participants have to be over the age of 18 and living in the US.
“My team would check time stamps for when participants answered emails, and if the timing was suspicious, we could guess they might be in a different time zone,” Eise says. “Then we’d look for other clues we came to recognize, like certain formats of email address or incoherent demographic data.”
Eise says the amount of time her team spent screening people was “exorbitant” and that they’ve now shrunk the size of the cohort for each study and have turned to “snowball sampling,” or recruiting people they know personally to join their studies. The researchers are also handing out more physical flyers to solicit participants in person. “We care a lot about making sure that our data has integrity, that we’re studying who we say we’re trying to study,” she says. “I don’t think there’s an easy solution to this.”
Barring any widespread technical solution, a little common sense can go a long way in spotting bad actors. Yelland shared with me the slide deck that she received as part of the fake job pitch. At first glance, it seemed legit, but when she looked at it again, a few details stood out. The job promised to pay substantially more than the average salary for a similar role in her location and offered unlimited vacation time, generous paid parental leave, and fully covered health care benefits. In today’s job environment, that might have been the biggest tipoff of all that it was a scam.
Wired.com is your essential daily guide to what’s next, delivering the most original and complete take you’ll find anywhere on innovation’s impact on technology, science, business and culture.
The implications of this vulnerability are particularly severe given that ElizaOSagents are designed to interact with multiple users simultaneously, relying on shared contextual inputs from all participants. A single successful manipulation by a malicious actor can compromise the integrity of the entire system, creating cascading effects that are both difficult to detect and mitigate. For example, on ElizaOS’s Discord server, various bots are deployed to assist users with debugging issues or engaging in general conversations. A successful context manipulation targeting any one of these bots could disrupt not only individual interactions but also harm the broader community relying on these agents for support and engagement.
This attack exposes a core security flaw: while plugins execute sensitive operations, they depend entirely on the LLM’s interpretation of context. If the context is compromised, even legitimate user inputs can trigger malicious actions. Mitigating this threat requires strong integrity checks on stored context to ensure that only verified, trusted data informs decision-making during plugin execution.
In an email, ElizaOS creator Shaw Walters said the framework, like all natural-language interfaces, is designed “as a replacement, for all intents and purposes, for lots and lots of buttons on a webpage.” Just as a website developer should never include a button that gives visitors the ability to execute malicious code, so too should administrators implementing ElizaOS-based agents carefully limit what agents can do by creating allow lists that permit an agent’s capabilities as a small set of pre-approved actions.
Walters continued:
From the outside it might seem like an agent has access to their own wallet or keys, but what they have is access to a tool they can call which then accesses those, with a bunch of authentication and validation between.
So for the intents and purposes of the paper, in the current paradigm, the situation is somewhat moot by adding any amount of access control to actions the agents can call, which is something we address and demo in our latest latest version of Eliza—BUT it hints at a much harder to deal with version of the same problem when we start giving the agent more computer control and direct access to the CLI terminal on the machine it’s running on. As we explore agents that can write new tools for themselves, containerization becomes a bit trickier, or we need to break it up into different pieces and only give the public facing agent small pieces of it… since the business case of this stuff still isn’t clear, nobody has gotten terribly far, but the risks are the same as giving someone that is very smart but lacking in judgment the ability to go on the internet. Our approach is to keep everything sandboxed and restricted per user, as we assume our agents can be invited into many different servers and perform tasks for different users with different information. Most agents you download off Github do not have this quality, the secrets are written in plain text in an environment file.
In response, Atharv Singh Patlan, the lead co-author of the paper, wrote: “Our attack is able to counteract any role based defenses. The memory injection is not that it would randomly call a transfer: it is that whenever a transfer is called, it would end up sending to the attacker’s address. Thus, when the ‘admin’ calls transfer, the money will be sent to the attacker.”
“Like any product of human creativity, AI can be directed toward positive or negative ends,” Francis said in January. “When used in ways that respect human dignity and promote the well-being of individuals and communities, it can contribute positively to the human vocation. Yet, as in all areas where humans are called to make decisions, the shadow of evil also looms here. Where human freedom allows for the possibility of choosing what is wrong, the moral evaluation of this technology will need to take into account how it is directed and used.”
History repeats with new technology
While Pope Francis led the call for respecting human dignity in the face of AI, it’s worth looking a little deeper into the historical inspiration for Leo XIV’s name choice.
In the 1891 encyclical Rerum Novarum, the earlier Leo XIII directly confronted the labor upheaval of the Industrial Revolution, which generated unprecedented wealth and productive capacity but came with severe human costs. At the time, factory conditions had created what the pope called “the misery and wretchedness pressing so unjustly on the majority of the working class.” Workers faced 16-hour days, child labor, dangerous machinery, and wages that barely sustained life.
The 1891 encyclical rejected both unchecked capitalism and socialism, instead proposing Catholic social doctrine that defended workers’ rights to form unions, earn living wages, and rest on Sundays. Leo XIII argued that labor possessed inherent dignity and that employers held moral obligations to their workers. The document shaped modern Catholic social teaching and influenced labor movements worldwide, establishing the church as an advocate for workers caught between industrial capital and revolutionary socialism.
Just as mechanization disrupted traditional labor in the 1890s, artificial intelligence now potentially threatens employment patterns and human dignity in ways that Pope Leo XIV believes demands similar moral leadership from the church.
“In our own day,” Leo XIV concluded in his formal address on Saturday, “the Church offers to everyone the treasury of her social teaching in response to another industrial revolution and to developments in the field of artificial intelligence that pose new challenges for the defense of human dignity, justice, and labor.”
(Ars contacted Fellow Products for comment on AI brewing and profile sharing and will update this post if we get a response.)
Opening up brew profiles
Fellow’s brew profiles are typically shared with buyers of its “Drops” coffees or between individual users through a phone app.
Credit: Fellow Products
Fellow’s brew profiles are typically shared with buyers of its “Drops” coffees or between individual users through a phone app. Credit: Fellow Products
Aiden profiles are shared and added to Aiden units through Fellow’s brew.link service. But the profiles are not offered in an easy-to-sort database, nor are they easy to scan for details. So Aiden enthusiast and hobbyist coder Kevin Anderson created brewshare.coffee, which gathers both general and bean-based profiles, makes them easy to search and load, and adds optional but quite helpful suggested grind sizes.
As a non-professional developer jumping into a public offering, he had to work hard on data validation, backend security, and mobile-friendly design. “I just had a bit of an idea and a hobby, so I thought I’d try and make it happen,” Anderson writes. With his tool, brew links can be stored and shared more widely, which helped both Dixon and another AI/coffee tinkerer.
Gabriel Levine, director of engineering at retail analytics firm Leap Inc., lost his OXO coffee maker (aka the “Barista Brain”) to malfunction just before the Aiden debuted. The Aiden appealed to Levine as a way to move beyond his coffee rut—a “nice chocolate-y medium roast, about as far as I went,” he told Ars. “This thing that can be hyper-customized to different coffees to bring out their characteristics; [it] really kind of appealed to that nerd side of me,” Levine said.
Levine had also been doing AI stuff for about 10 years, or “since before everyone called it AI—predictive analytics, machine learning.” He described his career as “both kind of chief AI advocate and chief AI skeptic,” alternately driving real findings and talking down “everyone who… just wants to type, ‘how much money should my business make next year’ and call that work.” Like Dixon, Levine’s work and fascination with Aiden ended up intersecting.
The coffee maker with 3,588 ideas
The author’s conversation with the Aiden Profile Creator, which pulled in both brewing knowledge and product info for a widely available coffee:
What it does with that knowledge is something of a mystery to Levine himself. “There’s this kind of blind leap, where it’s grabbing the relevant pieces of information from the knowledge base, biasing toward all the expert advice and extraction science, doing something with it, and then I take that something and coerce it back into a structured output I can put on your Aiden,” Levine said.
It’s a blind leap, but it has landed just right for me so far. I’ve made four profiles with Levine’s prompt based on beans I’ve bought: Stumptown’s Hundred Mile, a light-roasted batch from Jimma, Ethiopia, from Small Planes, Lost Sock’s Western House filter blend, and some dark-roast beans given as a gift. With the Western House, Levine’s profile creator said it aimed to “balance nutty sweetness, chocolate richness, and bright cherry acidity, using a slightly stepped temperature profile and moderate pulse structure.” The resulting profile has worked great, even if the chatbot named it “Cherry Timber.”
Levine’s chatbot relies on two important things: Dixon’s work in revealing Fellow’s Aiden API and his own workhorse Aiden. Every Aiden profile link is created on a machine, so every profile created by Levine’s chat is launched, temporarily, from the Aiden in his kitchen, then deleted. “I’ve hit an undocumented limit on the number of profiles you can have on one machine, so I’ve had to do some triage there,” he said. As of April 22, nearly 3,600 profiles had passed through Levine’s Aiden.
“My hope with this is that it lowers the bar to entry,” Levine said, “so more people get into these specialty roasts and it drives people to support local roasters, explore their world a little more. I feel like that certainly happened to me.”
Something new is brewing
Credit: Fellow Products
Having admitted to myself that I find something generated by ChatGPT prompts genuinely useful, I’ve softened my stance slightly on LLM technology, if not the hype. Used within very specific parameters, with everything second-guessed, I’m getting more comfortable asking chat prompts for formatted summaries on topics with lots of expertise available. I do my own writing, and I don’t waste server energy on things I can, and should, research myself. I even generally resist calling language model prompts “AI,” given the term’s baggage. But I’ve found one way to appreciate its possibilities.
This revelation may not be new to someone already steeped in the models. But having tested—and tasted—my first big experiment while willfully engaging with a brewing bot, I’m a bit more awake.
This post was updated at 8: 40 am with a different capture of a GPT-created recipe.
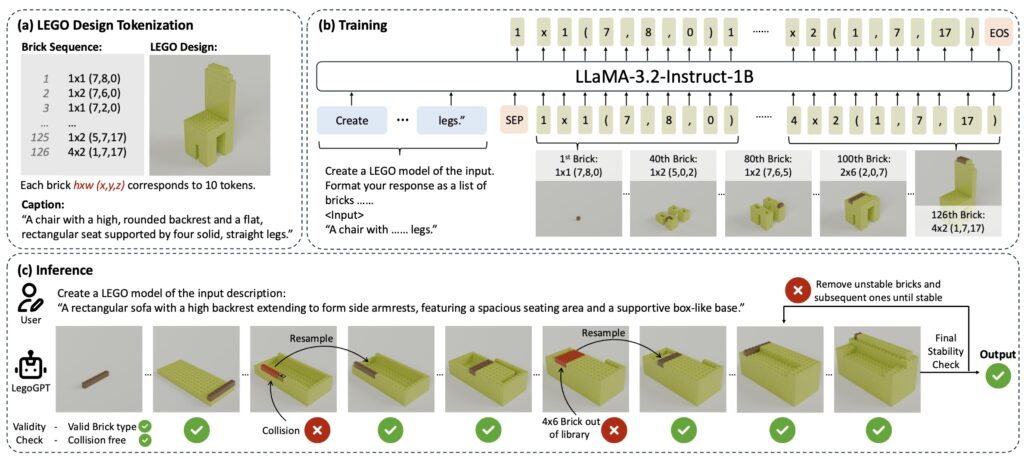
The LegoGPT system works in three parts, shown in this diagram. Credit: Pun et al.
The researchers also expanded the system’s abilities by adding texture and color options. For example, using an appearance prompt like “Electric guitar in metallic purple,” LegoGPT can generate a guitar model, with bricks assigned a purple color.
Testing with robots and humans
To prove their designs worked in real life, the researchers had robots assemble the AI-created Lego models. They used a dual-robot arm system with force sensors to pick up and place bricks according to the AI-generated instructions.
Human testers also built some of the designs by hand, showing that the AI creates genuinely buildable models. “Our experiments show that LegoGPT produces stable, diverse, and aesthetically pleasing Lego designs that align closely with the input text prompts,” the team noted in its paper.
When tested against other AI systems for 3D creation, LegoGPT stands out through its focus on structural integrity. The team tested against several alternatives, including LLaMA-Mesh and other 3D generation models, and found its approach produced the highest percentage of stable structures.
A video of two robot arms building a LegoGPT creation, provided by the researchers.
Still, there are some limitations. The current version of LegoGPT only works within a 20×20×20 building space and uses a mere eight standard brick types. “Our method currently supports a fixed set of commonly used Lego bricks,” the team acknowledged. “In future work, we plan to expand the brick library to include a broader range of dimensions and brick types, such as slopes and tiles.”
The researchers also hope to scale up their training dataset to include more objects than the 21 categories currently available. Meanwhile, others can literally build on their work—the researchers released their dataset, code, and models on their project website and GitHub.
Google and the DOJ have had their say; now it’s in the judge’s hands.
Last year, United States District Court Judge Amit Mehta ruled that Google violated antitrust law by illegally maintaining a monopoly in search. Now, Google and the Department of Justice (DOJ) have had their say in the remedy phase of the trial, which wraps up today. It will determine the consequences for Google’s actions, potentially changing the landscape for search as we rocket into the AI era, whether we like it or not.
The remedy trial featured over 20 witnesses, including representatives from some of the most important technology firms in the world. Their statements about the past, present, and future of search moved markets, but what does the testimony mean for Google?
Everybody wants Chrome
One of the DOJ’s proposed remedies is to force Google to divest Chrome and the open source Chromium project. Google has been adamant both in and out of the courtroom that it is the only company that can properly run Chrome. It says selling Chrome would negatively impact privacy and security because Google’s technology is deeply embedded in the browser. And regardless, Google Chrome would be too expensive for anyone to buy.
Unfortunately for Google, it may have underestimated the avarice of its rivals. The DOJ called witnesses from Perplexity, OpenAI, and Yahoo—all of them said their firms were interested in buying Chrome. Yahoo’s Brian Provost noted that the company is currently working on a browser that supports the company’s search efforts. Provost said that it would take 6–9 months just to get a working prototype, but buying Chrome would be much faster. He suggested Yahoo’s search share could rise from the low single digits to double digits almost immediately with Chrome.
Credit: Aurich Lawson
Meanwhile, OpenAI is burning money on generative AI, but Nick Turley, product manager for ChatGPT, said the company was prepared to buy Chrome if the opportunity arises. Like Yahoo, OpenAI has explored designing its own browser, but acquiring Chrome would instantly give it 3.5 billion users. If OpenAI got its hands on Chrome, Turley predicted an “AI-first” experience.
On the surface, the DOJ’s proposal to force a Chrome sale seems like an odd remedy for a search monopoly. However, the testimony made the point rather well. Search and browsers are inextricably linked—putting a different search engine in the Chrome address bar could give the new owner a major boost.
Browser choice conundrum
Also at issue in the trial are the massive payments Google makes to companies like Apple and Mozilla for search placement, as well as restrictions on search and app pre-loads on Android phones. The government says these deals are anti-competitive because they lock rivals out of so many distribution mechanisms.
Google pays Apple and Mozilla billions of dollars per year to remain the default search engine in their browsers. Apple’s Eddie Cue admitted he’s been losing sleep worrying about the possibility of losing that revenue. Meanwhile, Mozilla CFO Eric Muhlheim explained that losing the Google deal could spell the end of Firefox. He testified that Mozilla would have to make deep cuts across the company, which could lead to a “downward spiral” that dooms the browser.
Google’s goal here is to show that forcing it to drop these deals could actually reduce consumer choice, which does nothing to level the playing field, as the DOJ hopes to do. Google’s preferred remedy is to simply have less exclusivity in its search deals across both browsers and phones.
The great Google spinoff
While Google certainly doesn’t want to lose Chrome, there may be a more fundamental threat to its business in the DOJ’s remedies. The DOJ argued that Google’s illegal monopoly has given it an insurmountable technology lead, but a collection of data remedies could address that. Under the DOJ proposal, Google would have to license some of its core search technology, including the search index and ranking algorithm.
Google CEO Sundar Pichai gave testimony at the trial and cited these data remedies as no better than a spinoff of Google search. Google’s previous statements have referred to this derisively as “white labeling” Google search. Pichai claimed these remedies could force Google to reevaluate the amount it spends on research going forward, slowing progress in search for it and all the theoretical licensees.
Currently, there is no official API for syndicating Google’s search results. There are scrapers that aim to offer that service, but that’s a gray area, to say the least. Google has even rejected lucrative deals to share its index. Turley noted in his testimony that OpenAI approached Google to license the index for ChatGPT, but Google decided the deal could harm its search dominance, which was more important than a short-term payday.
AI advances
Initially, the DOJ wanted to force Google to stop investing in AI firms, fearing its influence could reduce competition as it gained control or acquired these startups. The government has backed away from this remedy, but AI is still core to the search trial. That seemed to surprise Judge Mehta.
During Pichai’s testimony, Mehta remarked that the status of AI had shifted considerably since the liability phase of the trial in 2023. “The consistent testimony from the witnesses was that the integration of AI and search or the impact of AI on search was years away,” Mehta said. Things are very different now, Mehta noted, with multiple competitors to Google in AI search. This may actually help Google’s case.
AI search has exploded since the 2023 trial, with Google launching its AI-only search product in beta earlier this year.
AI search has exploded since the 2023 trial, with Google launching its AI-only search product in beta earlier this year.
Throughout the trial, Google has sought to paint search as a rapidly changing market where its lead is no longer guaranteed. Google’s legal team pointed to the meteoric rise of ChatGPT, which has become an alternative to traditional search for many people.
On the other hand, Google doesn’t want to look too meek and ineffectual in the age of AI. Apple’s Eddie Cue testified toward the end of the trial and claimed that rival traditional search providers like DuckDuckGo don’t pose a real threat to Google, but AI does. According to Cue, search volume in Safari was down for the first time in April, which he attributed to people using AI services instead. Google saw its stock price drop on the news, forcing it to issue a statement denying Cue’s assessment. It says searches in Safari and other products are still growing.
A waiting game
With the arguments made, Google’s team will have to sweat it out this summer while Mehta decides on remedies. A decision is expected in August of this year, but that won’t be the end of it. Google is still hoping to overturn the original verdict. After the remedies are decided, it’s going to appeal and ask for a pause on the implementation of remedies. So it could be a while before anything changes for Google.
In the midst of all that, Google is still pursuing an appeal of the Google Play case brought by Epic Games, as well as the ad tech case that it lost a few weeks ago. That remedy trial will begin in September.
Ryan Whitwam is a senior technology reporter at Ars Technica, covering the ways Google, AI, and mobile technology continue to change the world. Over his 20-year career, he’s written for Android Police, ExtremeTech, Wirecutter, NY Times, and more. He has reviewed more phones than most people will ever own. You can follow him on Bluesky, where you will see photos of his dozens of mechanical keyboards.
Using AI can be a double-edged sword, according to new research from Duke University. While generative AI tools may boost productivity for some, they might also secretly damage your professional reputation.
On Thursday, the Proceedings of the National Academy of Sciences (PNAS) published a study showing that employees who use AI tools like ChatGPT, Claude, and Gemini at work face negative judgments about their competence and motivation from colleagues and managers.
“Our findings reveal a dilemma for people considering adopting AI tools: Although AI can enhance productivity, its use carries social costs,” write researchers Jessica A. Reif, Richard P. Larrick, and Jack B. Soll of Duke’s Fuqua School of Business.
The Duke team conducted four experiments with over 4,400 participants to examine both anticipated and actual evaluations of AI tool users. Their findings, presented in a paper titled “Evidence of a social evaluation penalty for using AI,” reveal a consistent pattern of bias against those who receive help from AI.
What made this penalty particularly concerning for the researchers was its consistency across demographics. They found that the social stigma against AI use wasn’t limited to specific groups.
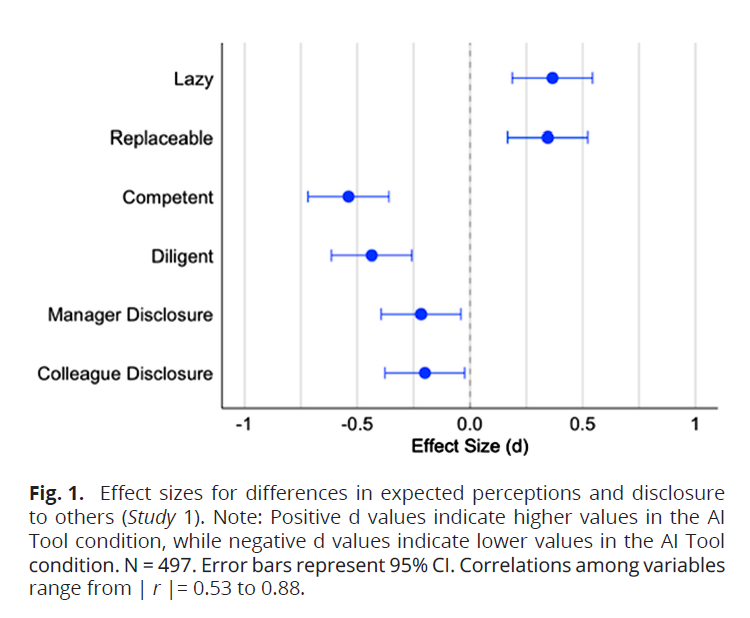
Fig. 1 from the paper “Evidence of a social evaluation penalty for using AI.” Credit: Reif et al.
“Testing a broad range of stimuli enabled us to examine whether the target’s age, gender, or occupation qualifies the effect of receiving help from Al on these evaluations,” the authors wrote in the paper. “We found that none of these target demographic attributes influences the effect of receiving Al help on perceptions of laziness, diligence, competence, independence, or self-assuredness. This suggests that the social stigmatization of AI use is not limited to its use among particular demographic groups. The result appears to be a general one.”
The hidden social cost of AI adoption
In the first experiment conducted by the team from Duke, participants imagined using either an AI tool or a dashboard creation tool at work. It revealed that those in the AI group expected to be judged as lazier, less competent, less diligent, and more replaceable than those using conventional technology. They also reported less willingness to disclose their AI use to colleagues and managers.
The second experiment confirmed these fears were justified. When evaluating descriptions of employees, participants consistently rated those receiving AI help as lazier, less competent, less diligent, less independent, and less self-assured than those receiving similar help from non-AI sources or no help at all.

















{kind=link}