OpenAI continues naming chaos despite CEO acknowledging the habit
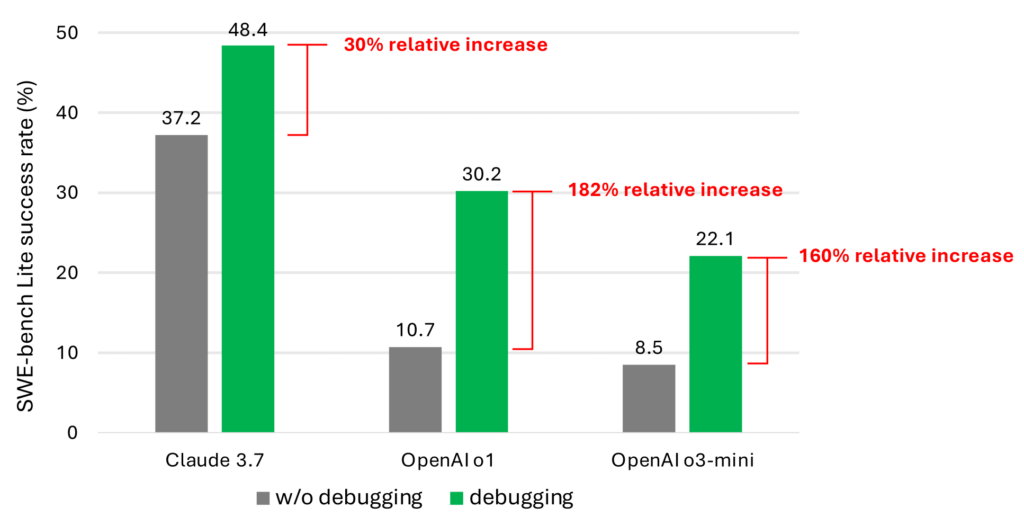
On Monday, OpenAI announced the GPT-4.1 model family, its newest series of AI language models that brings a 1 million token context window to OpenAI for the first time and continues a long tradition of very confusing AI model names. Three confusing new names, in fact: GPT‑4.1, GPT‑4.1 mini, and GPT‑4.1 nano.
According to OpenAI, these models outperform GPT-4o in several key areas. But in an unusual move, GPT-4.1 will only be available through the developer API, not in the consumer ChatGPT interface where most people interact with OpenAI’s technology.
The 1 million token context window—essentially the amount of text the AI can process at once—allows these models to ingest roughly 3,000 pages of text in a single conversation. This puts OpenAI’s context windows on par with Google’s Gemini models, which have offered similar extended context capabilities for some time.
At the same time, the company announced it will retire the GPT-4.5 Preview model in the API—a temporary offering launched in February that one critic called a “lemon”—giving developers until July 2025 to switch to something else. However, it appears GPT-4.5 will stick around in ChatGPT for now.
So many names
If this sounds confusing, well, that’s because it is. OpenAI CEO Sam Altman acknowledged OpenAI’s habit of terrible product names in February when discussing the roadmap toward the long-anticipated (and still theoretical) GPT-5.
“We realize how complicated our model and product offerings have gotten,” Altman wrote on X at the time, referencing a ChatGPT interface already crowded with choices like GPT-4o, various specialized GPT-4o versions, GPT-4o mini, the simulated reasoning o1-pro, o3-mini, and o3-mini-high models, and GPT-4. The stated goal for GPT-5 will be consolidation, a branding move to unify o-series models and GPT-series models.
So, how does launching another distinctly numbered model, GPT-4.1, fit into that grand unification plan? It’s hard to say. Altman foreshadowed this kind of ambiguity in March 2024, telling Lex Fridman the company had major releases coming but was unsure about names: “before we talk about a GPT-5-like model called that, or not called that, or a little bit worse or a little bit better than what you’d expect…”
OpenAI continues naming chaos despite CEO acknowledging the habit Read More »