For most of photography’s roughly 200-year history, altering a photo convincingly required either a darkroom, some Photoshop expertise, or, at minimum, a steady hand with scissors and glue. On Tuesday, OpenAI released a tool that reduces the process to typing a sentence.
It’s not the first company to do so. While OpenAI had a conversational image-editing model in the works since GPT-4o in 2024, Google beat OpenAI to market in March with a public prototype, then refined it to a popular model called Nano Banana image model (and Nano Banana Pro). The enthusiastic response to Google’s image-editing model in the AI community got OpenAI’s attention.
OpenAI’s new GPT Image 1.5 is an AI image synthesis model that reportedly generates images up to four times faster than its predecessor and costs about 20 percent less through the API. The model rolled out to all ChatGPT users on Tuesday and represents another step toward making photorealistic image manipulation a casual process that requires no particular visual skills.
The “Galactic Queen of the Universe” added to a photo of a room with a sofa using GPT Image 1.5 in ChatGPT.
GPT Image 1.5 is notable because it’s a “native multimodal” image model, meaning image generation happens inside the same neural network that processes language prompts. (In contrast, DALL-E 3, an earlier OpenAI image generator previously built into ChatGPT, used a different technique called diffusion to generate images.)
This newer type of model, which we covered in more detail in March, treats images and text as the same kind of thing: chunks of data called “tokens” to be predicted, patterns to be completed. If you upload a photo of your dad and type “put him in a tuxedo at a wedding,” the model processes your words and the image pixels in a unified space, then outputs new pixels the same way it would output the next word in a sentence.
Using this technique, GPT Image 1.5 can more easily alter visual reality than earlier AI image models, changing someone’s pose or position, or rendering a scene from a slightly different angle, with varying degrees of success. It can also remove objects, change visual styles, adjust clothing, and refine specific areas while preserving facial likeness across successive edits. You can converse with the AI model about a photograph, refining and revising, the same way you might workshop a draft of an email in ChatGPT.
While AI bubble talk fills the air these days, with fears of overinvestment that could pop at any time, something of a contradiction is brewing on the ground: Companies like Google and OpenAI can barely build infrastructure fast enough to fill their AI needs.
During an all-hands meeting earlier this month, Google’s AI infrastructure head Amin Vahdat told employees that the company must double its serving capacity every six months to meet demand for artificial intelligence services, reports CNBC. The comments show a rare look at what Google executives are telling its own employees internally. Vahdat, a vice president at Google Cloud, presented slides to its employees showing the company needs to scale “the next 1000x in 4-5 years.”
While a thousandfold increase in compute capacity sounds ambitious by itself, Vahdat noted some key constraints: Google needs to be able to deliver this increase in capability, compute, and storage networking “for essentially the same cost and increasingly, the same power, the same energy level,” he told employees during the meeting. “It won’t be easy but through collaboration and co-design, we’re going to get there.”
It’s unclear how much of this “demand” Google mentioned represents organic user interest in AI capabilities versus the company integrating AI features into existing services like Search, Gmail, and Workspace. But whether users are using the features voluntarily or not, Google isn’t the only tech company struggling to keep up with a growing user base of customers using AI services.
Major tech companies are in a race to build out data centers. Google competitor OpenAI is planning to build six massive data centers across the US through its Stargate partnership project with SoftBank and Oracle, committing over $400 billion in the next three years to reach nearly 7 gigawatts of capacity. The company faces similar constraints serving its 800 million weekly ChatGPT users, with even paid subscribers regularly hitting usage limits for features like video synthesis and simulated reasoning models.
“The competition in AI infrastructure is the most critical and also the most expensive part of the AI race,” Vahdat said at the meeting, according to CNBC’s viewing of the presentation. The infrastructure executive explained that Google’s challenge goes beyond simply outspending competitors. “We’re going to spend a lot,” he said, but noted the real objective is building infrastructure that is “more reliable, more performant and more scalable than what’s available anywhere else.”
On Wednesday, OpenAI released GPT-5.1 Instant and GPT-5.1 Thinking, two updated versions of its flagship AI models now available in ChatGPT. The company is wrapping the models in the language of anthropomorphism, claiming that they’re warmer, more conversational, and better at following instructions.
The release follows complaints earlier this year that its previous models were excessively cheerful and sycophantic, along with an opposing controversy among users over how OpenAI modified the default GPT-5 output style after several suicide lawsuits.
The company now faces intense scrutiny from lawyers and regulators that could threaten its future operations. In that kind of environment, it’s difficult to just release a new AI model, throw out a few stats, and move on like the company could even a year ago. But here are the basics: The new GPT-5.1 Instant model will serve as ChatGPT’s faster default option for most tasks, while GPT-5.1 Thinking is a simulated reasoning model that attempts to handle more complex problem-solving tasks.
OpenAI claims that both models perform better on technical benchmarks such as math and coding evaluations (including AIME 2025 and Codeforces) than GPT-5, which was released in August.
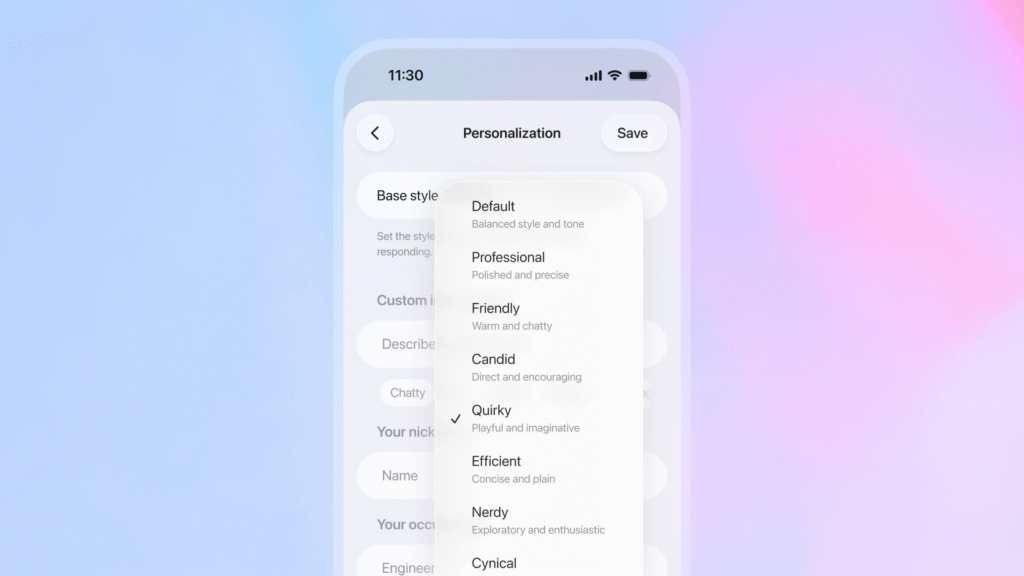
Improved benchmarks may win over some users, but the biggest change with GPT-5.1 is in its presentation. OpenAI says it heard from users that they wanted AI models to simulate different communication styles depending on the task, so the company is offering eight preset options, including Professional, Friendly, Candid, Quirky, Efficient, Cynical, and Nerdy, alongside a Default setting.
These presets alter the instructions fed into each prompt to simulate different personality styles, but the underlying model capabilities remain the same across all settings.
An illustration showing GPT-5.1’s eight personality styles in ChatGPT. Credit: OpenAI
In addition, the company trained GPT-5.1 Instant to use “adaptive reasoning,” meaning that the model decides when to spend more computational time processing a prompt before generating output.
The company plans to roll out the models gradually over the next few days, starting with paid subscribers before expanding to free users. OpenAI plans to bring both GPT-5.1 Instant and GPT-5.1 Thinking to its API later this week. GPT-5.1 Instant will appear as gpt-5.1-chat-latest, and GPT-5.1 Thinking will be released as GPT-5.1 in the API, both with adaptive reasoning enabled. The older GPT-5 models will remain available in ChatGPT under the legacy models dropdown for paid subscribers for three months.
On Thursday, OpenAI and Microsoft announced they have signed a non-binding agreement to revise their partnership, marking the latest development in a relationship that has grown increasingly complex as both companies compete for customers in the AI market and seek new partnerships for growing infrastructure needs.
“Microsoft and OpenAI have signed a non-binding memorandum of understanding (MOU) for the next phase of our partnership,” the companies wrote in a joint statement. “We are actively working to finalize contractual terms in a definitive agreement. Together, we remain focused on delivering the best AI tools for everyone, grounded in our shared commitment to safety.”
The announcement comes as OpenAI seeks to restructure from a nonprofit to a for-profit entity, a transition that requires Microsoft’s approval, as the company is OpenAI’s largest investor, with more than $13 billion committed since 2019.
The partnership has shown increasing strain as OpenAI has grown from a research lab into a company valued at $500 billion. Both companies now compete for customers, and OpenAI seeks more compute capacity than Microsoft can provide. The relationship has also faced complications over contract terms, including provisions that would limit Microsoft’s access to OpenAI technology once the company reaches so-called AGI (artificial general intelligence)—a nebulous milestone both companies now economically define as AI systems capable of generating at least $100 billion in profit.
In May, OpenAI abandoned its original plan to fully convert to a for-profit company after pressure from former employees, regulators, and critics, including Elon Musk. Musk has sued to block the conversion, arguing it betrays OpenAI’s founding mission as a nonprofit dedicated to benefiting humanity.
The speed at which news of the outage spread shows how deeply embedded AI coding assistants have already become in modern software development. Claude Code, announced in February and widely launched in May, is Anthropic’s terminal-based coding agent that can perform multi-step coding tasks across an existing code base.
The tool competes with OpenAI’s Codex feature, a coding agent that generates production-ready code in isolated containers, Google’s Gemini CLI, Microsoft’s GitHub Copilot, which itself can use Claude models for code, and Cursor, a popular AI-powered IDE built on VS Code that also integrates multiple AI models, including Claude.
During today’s outage, some developers turned to alternative solutions. “Z.AI works fine. Qwen works fine. Glad I switched,” posted one user on Hacker News. Others joked about reverting to older methods, with one suggesting the “pseudo-LLM experience” could be achieved with a Python package that imports code directly from Stack Overflow.
While AI coding assistants have accelerated development for some users, they’ve also caused problems for others who rely on them too heavily. The emerging practice of so-called “vibe coding“—using natural language to generate and execute code through AI models without fully understanding the underlying operations—has led to catastrophic failures.
In recent incidents, Google’s Gemini CLI destroyed user files while attempting to reorganize them, and Replit’s AI coding service deleted a production database despite explicit instructions not to modify code. These failures occurred when the AI models confabulated successful operations and built subsequent actions on false premises, highlighting the risks of depending on AI assistants that can misinterpret file structures or fabricate data to hide their errors.
Wednesday’s outage served as a reminder that as dependency on AI grows, even minor service disruptions can become major events that affect an entire profession. But perhaps that could be a good thing if it’s an excuse to take a break from a stressful workload. As one commenter joked, it might be “time to go outside and touch some grass again.”
For those who missed the Flash era, these in-browser apps feel somewhat like the vintage apps that defined a generation of Internet culture from the late 1990s through the 2000s when it first became possible to create complex in-browser experiences. Adobe Flash (originally Macromedia Flash) began as animation software for designers but quickly became the backbone of interactive web content when it gained its own programming language, ActionScript, in 2000.
But unlike Flash games, where hosting costs fell on portal operators, Anthropic has crafted a system where users pay for their own fun through their existing Claude subscriptions. “When someone uses your Claude-powered app, they authenticate with their existing Claude account,” Anthropic explained in its announcement. “Their API usage counts against their subscription, not yours. You pay nothing for their usage.”
A view of the Anthropic Artifacts gallery in the “Play a Game” section. Benj Edwards / Anthropic
Like the Flash games of yesteryear, any Claude-powered apps you build run in the browser and can be shared with anyone who has a Claude account. They’re interactive experiences shared with a simple link, no installation required, created by other people for the sake of creating, except now they’re powered by JavaScript instead of ActionScript.
While you can share these apps with others individually, right now Anthropic’s Artifact gallery only shows examples made by Anthropic and your own personal Artifacts. (If Anthropic expanded it into the future, it might end up feeling a bit like Scratch meets Newgrounds, but with AI doing the coding.) Ultimately, humans are still behind the wheel, describing what kinds of apps they want the AI model to build and guiding the process when it inevitably makes mistakes.
Speaking of mistakes, don’t expect perfect results at first. Usually, building an app with Claude is an interactive experience that requires some guidance to achieve your desired results. But with a little patience and a lot of tokens, you’ll be vibe coding in no time.
New studies reveal pattern-matching reality behind the AI industry’s reasoning claims.
On Tuesday, OpenAI announced that o3-pro, a new version of its most capable simulated reasoning model, is now available to ChatGPT Pro and Team users, replacing o1-pro in the model picker. The company also reduced API pricing for o3-pro by 87 percent compared to o1-pro while cutting o3 prices by 80 percent. While “reasoning” is useful for some analytical tasks, new studies have posed fundamental questions about what the word actually means when applied to these AI systems.
We’ll take a deeper look at “reasoning” in a minute, but first, let’s examine what’s new. While OpenAI originally launched o3 (non-pro) in April, the o3-pro model focuses on mathematics, science, and coding while adding new capabilities like web search, file analysis, image analysis, and Python execution. Since these tool integrations slow response times (longer than the already slow o1-pro), OpenAI recommends using the model for complex problems where accuracy matters more than speed. However, they do not necessarily confabulate less than “non-reasoning” AI models (they still introduce factual errors), which is a significant caveat when seeking accurate results.
Beyond the reported performance improvements, OpenAI announced a substantial price reduction for developers. O3-pro costs $20 per million input tokens and $80 per million output tokens in the API, making it 87 percent cheaper than o1-pro. The company also reduced the price of the standard o3 model by 80 percent.
These reductions address one of the main concerns with reasoning models—their high cost compared to standard models. The original o1 cost $15 per million input tokens and $60 per million output tokens, while o3-mini cost $1.10 per million input tokens and $4.40 per million output tokens.
Why use o3-pro?
Unlike general-purpose models like GPT-4o that prioritize speed, broad knowledge, and making users feel good about themselves, o3-pro uses a chain-of-thought simulated reasoning process to devote more output tokens toward working through complex problems, making it generally better for technical challenges that require deeper analysis. But it’s still not perfect.
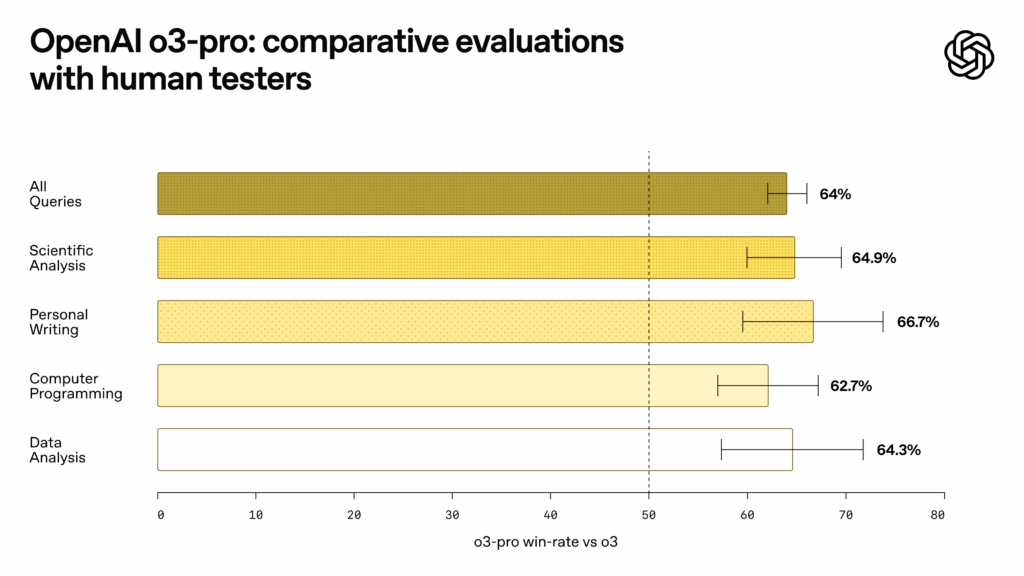
An OpenAI’s o3-pro benchmark chart. Credit: OpenAI
Measuring so-called “reasoning” capability is tricky since benchmarks can be easy to game by cherry-picking or training data contamination, but OpenAI reports that o3-pro is popular among testers, at least. “In expert evaluations, reviewers consistently prefer o3-pro over o3 in every tested category and especially in key domains like science, education, programming, business, and writing help,” writes OpenAI in its release notes. “Reviewers also rated o3-pro consistently higher for clarity, comprehensiveness, instruction-following, and accuracy.”
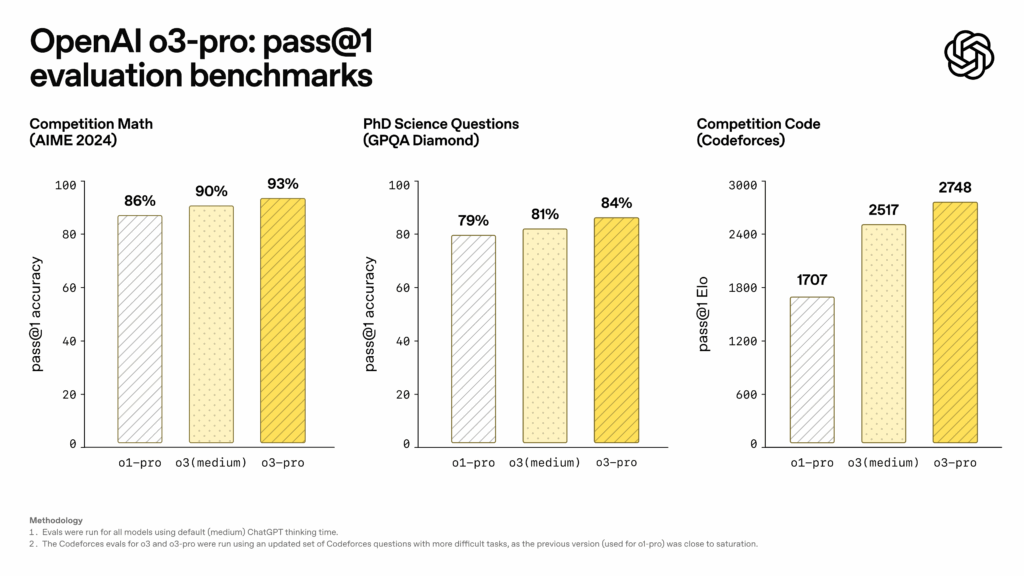
An OpenAI’s o3-pro benchmark chart. Credit: OpenAI
OpenAI shared benchmark results showing o3-pro’s reported performance improvements. On the AIME 2024 mathematics competition, o3-pro achieved 93 percent pass@1 accuracy, compared to 90 percent for o3 (medium) and 86 percent for o1-pro. The model reached 84 percent on PhD-level science questions from GPQA Diamond, up from 81 percent for o3 (medium) and 79 percent for o1-pro. For programming tasks measured by Codeforces, o3-pro achieved an Elo rating of 2748, surpassing o3 (medium) at 2517 and o1-pro at 1707.
When reasoning is simulated
It’s easy for laypeople to be thrown off by the anthropomorphic claims of “reasoning” in AI models. In this case, as with the borrowed anthropomorphic term “hallucinations,” “reasoning” has become a term of art in the AI industry that basically means “devoting more compute time to solving a problem.” It does not necessarily mean the AI models systematically apply logic or possess the ability to construct solutions to truly novel problems. This is why we at Ars Technica continue to use the term “simulated reasoning” (SR) to describe these models. They are simulating a human-style reasoning process that does not necessarily produce the same results as human reasoning when faced with novel challenges.
While simulated reasoning models like o3-pro often show measurable improvements over general-purpose models on analytical tasks, research suggests these gains come from allocating more computational resources to traverse their neural networks in smaller, more directed steps. The answer lies in what researchers call “inference-time compute” scaling. When these models use what are called “chain-of-thought” techniques, they dedicate more computational resources to exploring connections between concepts in their neural network data. Each intermediate “reasoning” output step (produced in tokens) serves as context for the next token prediction, effectively constraining the model’s outputs in ways that tend to improve accuracy and reduce mathematical errors (though not necessarily factual ones).
But fundamentally, all Transformer-based AI models are pattern-matching marvels. They borrow reasoning patterns from examples in the training data that researchers use to create them. Recent studies on Math Olympiad problems reveal that SR models still function as sophisticated pattern-matching machines—they cannot catch their own mistakes or adjust failing approaches, often producing confidently incorrect solutions without any “awareness” of errors.
Apple researchers found similar limitations when testing SR models on controlled puzzle environments. Even when provided explicit algorithms for solving puzzles like Tower of Hanoi, the models failed to execute them correctly—suggesting their process relies on pattern matching from training data rather than logical reasoning. As problem complexity increased, these models showed a “counterintuitive scaling limit,” reducing their reasoning effort despite having adequate computational resources. This aligns with the USAMO findings showing that models made basic logical errors and continued with flawed approaches even when generating contradictory results.
However, there’s some serious nuance here that you may miss if you’re reaching quickly for a pro-AI or anti-AI take. Pattern-matching and reasoning aren’t necessarily mutually exclusive. Since it’s difficult to mechanically define human reasoning at a fundamental level, we can’t definitively say whether sophisticated pattern-matching is categorically different from “genuine” reasoning or just a different implementation of similar underlying processes. The Tower of Hanoi failures are compelling evidence of current limitations, but they don’t resolve the deeper philosophical question of what reasoning actually is.
And understanding these limitations doesn’t diminish the genuine utility of SR models. For many real-world applications—debugging code, solving math problems, or analyzing structured data—pattern matching from vast training sets is enough to be useful. But as we consider the industry’s stated trajectory toward artificial general intelligence and even superintelligence, the evidence so far suggests that simply scaling up current approaches or adding more “thinking” tokens may not bridge the gap between statistical pattern recognition and what might be called generalist algorithmic reasoning.
But the technology is evolving rapidly, and new approaches are already being developed to address those shortcomings. For example, self-consistency sampling allows models to generate multiple solution paths and check for agreement, while self-critique prompts attempt to make models evaluate their own outputs for errors. Tool augmentation represents another useful direction already used by o3-pro and other ChatGPT models—by connecting LLMs to calculators, symbolic math engines, or formal verification systems, researchers can compensate for some of the models’ computational weaknesses. These methods show promise, though they don’t yet fully address the fundamental pattern-matching nature of current systems.
For now, o3-pro is a better, cheaper version of what OpenAI previously provided. It’s good at solving familiar problems, struggles with truly new ones, and still makes confident mistakes. If you understand its limitations, it can be a powerful tool, but always double-check the results.
Benj Edwards is Ars Technica’s Senior AI Reporter and founder of the site’s dedicated AI beat in 2022. He’s also a tech historian with almost two decades of experience. In his free time, he writes and records music, collects vintage computers, and enjoys nature. He lives in Raleigh, NC.
On Monday, OpenAI announced the GPT-4.1 model family, its newest series of AI language models that brings a 1 million token context window to OpenAI for the first time and continues a long tradition of very confusing AI model names. Three confusing new names, in fact: GPT‑4.1, GPT‑4.1 mini, and GPT‑4.1 nano.
According to OpenAI, these models outperform GPT-4o in several key areas. But in an unusual move, GPT-4.1 will only be available through the developer API, not in the consumer ChatGPT interface where most people interact with OpenAI’s technology.
The 1 million token context window—essentially the amount of text the AI can process at once—allows these models to ingest roughly 3,000 pages of text in a single conversation. This puts OpenAI’s context windows on par with Google’s Gemini models, which have offered similar extended context capabilities for some time.
At the same time, the company announced it will retire the GPT-4.5 Preview model in the API—a temporary offering launched in February that one critic called a “lemon”—giving developers until July 2025 to switch to something else. However, it appears GPT-4.5 will stick around in ChatGPT for now.
So many names
If this sounds confusing, well, that’s because it is. OpenAI CEO Sam Altman acknowledged OpenAI’s habit of terrible product names in February when discussing the roadmap toward the long-anticipated (and still theoretical) GPT-5.
“We realize how complicated our model and product offerings have gotten,” Altman wrote on X at the time, referencing a ChatGPT interface already crowded with choices like GPT-4o, various specialized GPT-4o versions, GPT-4o mini, the simulated reasoning o1-pro, o3-mini, and o3-mini-high models, and GPT-4. The stated goal for GPT-5 will be consolidation, a branding move to unify o-series models and GPT-series models.
So, how does launching another distinctly numbered model, GPT-4.1, fit into that grand unification plan? It’s hard to say. Altman foreshadowed this kind of ambiguity in March 2024, telling Lex Fridman the company had major releases coming but was unsure about names: “before we talk about a GPT-5-like model called that, or not called that, or a little bit worse or a little bit better than what you’d expect…”
Model context protocol standardizes how AI uses data sources, supported by OpenAI and Anthropic.
What does it take to get OpenAI and Anthropic—two competitors in the AI assistant market—to get along? Despite a fundamental difference in direction that led Anthropic’s founders to quit OpenAI in 2020 and later create the Claude AI assistant, a shared technical hurdle has now brought them together: How to easily connect their AI models to external data sources.
The solution comes from Anthropic, which developed and released an open specification called Model Context Protocol (MCP) in November 2024. MCP establishes a royalty-free protocol that allows AI models to connect with outside data sources and services without requiring unique integrations for each service.
“Think of MCP as a USB-C port for AI applications,” wrote Anthropic in MCP’s documentation. The analogy is imperfect, but it represents the idea that, similar to how USB-C unified various cables and ports (with admittedly a debatable level of success), MCP aims to standardize how AI models connect to the infoscape around them.
So far, MCP has also garnered interest from multiple tech companies in a rare show of cross-platform collaboration. For example, Microsoft has integrated MCP into its Azure OpenAI service, and as we mentioned above, Anthropic competitor OpenAI is on board. Last week, OpenAI acknowledged MCP in its Agents API documentation, with vocal support from the boss upstairs.
“People love MCP and we are excited to add support across our products,” wrote OpenAI CEO Sam Altman on X last Wednesday.
MCP has also rapidly begun to gain community support in recent months. For example, just browsing this list of over 300 open source servers shared on GitHub reveals growing interest in standardizing AI-to-tool connections. The collection spans diverse domains, including database connectors like PostgreSQL, MySQL, and vector databases; development tools that integrate with Git repositories and code editors; file system access for various storage platforms; knowledge retrieval systems for documents and websites; and specialized tools for finance, health care, and creative applications.
Other notable examples include servers that connect AI models to home automation systems, real-time weather data, e-commerce platforms, and music streaming services. Some implementations allow AI assistants to interact with gaming engines, 3D modeling software, and IoT devices.
What is “context” anyway?
To fully appreciate why a universal AI standard for external data sources is useful, you’ll need to understand what “context” means in the AI field.
With current AI model architecture, what an AI model “knows” about the world is baked into its neural network in a largely unchangeable form, placed there by an initial procedure called “pre-training,” which calculates statistical relationships between vast quantities of input data (“training data”—like books, articles, and images) and feeds it into the network as numerical values called “weights.” Later, a process called “fine-tuning” might adjust those weights to alter behavior (such as through reinforcement learning like RLHF) or provide examples of new concepts.
Typically, the training phase is very expensive computationally and happens either only once in the case of a base model, or infrequently with periodic model updates and fine-tunings. That means AI models only have internal neural network representations of events prior to a “cutoff date” when the training dataset was finalized.
After that, the AI model is run in a kind of read-only mode called “inference,” where users feed inputs into the neural network to produce outputs, which are called “predictions.” They’re called predictions because the systems are tuned to predict the most likely next token (a chunk of data, such as portions of a word) in a user-provided sequence.
In the AI field, context is the user-provided sequence—all the data fed into an AI model that guides the model to produce a response output. This context includes the user’s input (the “prompt”), the running conversation history (in the case of chatbots), and any external information sources pulled into the conversation, including a “system prompt” that defines model behavior and “memory” systems that recall portions of past conversations. The limit on the amount of context a model can ingest at once is often called a “context window,” “context length, ” or “context limit,” depending on personal preference.
While the prompt provides important information for the model to operate upon, accessing external information sources has traditionally been cumbersome. Before MCP, AI assistants like ChatGPT and Claude could access external data (a process often called retrieval augmented generation, or RAG), but doing so required custom integrations for each service—plugins, APIs, and proprietary connectors that didn’t work across different AI models. Each new data source demanded unique code, creating maintenance challenges and compatibility issues.
MCP addresses these problems by providing a standardized method or set of rules (a “protocol”) that allows any supporting AI model framework to connect with external tools and information sources.
How does MCP work?
To make the connections behind the scenes between AI models and data sources, MCP uses a client-server model. An AI model (or its host application) acts as an MCP client that connects to one or more MCP servers. Each server provides access to a specific resource or capability, such as a database, search engine, or file system. When the AI needs information beyond its training data, it sends a request to the appropriate server, which performs the action and returns the result.
To illustrate how the client-server model works in practice, consider a customer support chatbot using MCP that could check shipping details in real time from a company database. “What’s the status of order #12345?” would trigger the AI to query an order database MCP server, which would look up the information and pass it back to the model. The model could then incorporate that data into its response: “Your order shipped on March 30 and should arrive April 2.”
Beyond specific use cases like customer support, the potential scope is very broad. Early developers have already built MCP servers for services like Google Drive, Slack, GitHub, and Postgres databases. This means AI assistants could potentially search documents in a company Drive, review recent Slack messages, examine code in a repository, or analyze data in a database—all through a standard interface.
From a technical implementation perspective, Anthropic designed the standard for flexibility by running in two main modes: Some MCP servers operate locally on the same machine as the client (communicating via standard input-output streams), while others run remotely and stream responses over HTTP. In both cases, the model works with a list of available tools and calls them as needed.
A work in progress
Despite the growing ecosystem around MCP, the protocol remains an early-stage project. The limited announcements of support from major companies are promising first steps, but MCP’s future as an industry standard may depend on broader acceptance, although the number of MCP servers seems to be growing at a rapid pace.
Regardless of its ultimate adoption rate, MCP may have some interesting second-order effects. For example, MCP also has the potential to reduce vendor lock-in. Because the protocol is model-agnostic, a company could switch from one AI provider to another while keeping the same tools and data connections intact.
MCP may also allow a shift toward smaller and more efficient AI systems that can interact more fluidly with external resources without the need for customized fine-tuning. Also, rather than building increasingly massive models with all knowledge baked in, companies may instead be able to use smaller models with large context windows.
For now, the future of MCP is wide open. Anthropic maintains MCP as an open source initiative on GitHub, where interested developers can either contribute to the code or find specifications about how it works. Anthropic has also provided extensive documentation about how to connect Claude to various services. OpenAI maintains its own API documentation for MCP on its website.
Benj Edwards is Ars Technica’s Senior AI Reporter and founder of the site’s dedicated AI beat in 2022. He’s also a tech historian with almost two decades of experience. In his free time, he writes and records music, collects vintage computers, and enjoys nature. He lives in Raleigh, NC.
AI, while having potential, “must be handled responsibly and with a firm focus on user control,” and third-party developers may not take “such a deliberate approach,” Strava wrote. And the firm expects the API changes will “affect only a small fraction (less than 0.1 percent) of the applications on the Strava platform” and that “the overwhelming majority of existing use cases are still allowed,” including coaching platforms “focused on providing feedback to users.”
Ars has contacted Strava and will update this post if we receive a response.
DC Rainmaker’s post about Strava’s changes points out that while the simplest workaround for apps would be to take fitness data directly from users, that’s not how fitness devices work. Other than “a Garmin or other big-name device with a proper and well-documented” API, most devices default to Strava as a way to get training data to other apps, wrote Ray Maker, the blogger behind the DC Rainmaker alias.
Beyond day-to-day fitness data, Strava’s API agreement now states more precisely that an app cannot process a user’s Strava data “in an aggregated or de-identified manner” for the purposes of “analytics, analyses, customer insights generation,” or similar uses. Maker writes that the training apps he contacted had been “completely broadsided” by the API shift, having been given 30 days’ notice to change their apps.
Strava notes in a post on its forum in the Developers & API section that, per its guidelines, “posts requesting or attempting to have Strava revert business decisions will not be permitted.”
Speaking of Opus, Claude 3.5 Opus is nowhere to be seen, as AI researcher Simon Willison noted to Ars Technica in an interview. “All references to 3.5 Opus have vanished without a trace, and the price of 3.5 Haiku was increased the day it was released,” he said. “Claude 3.5 Haiku is significantly more expensive than both Gemini 1.5 Flash and GPT-4o mini—the excellent low-cost models from Anthropic’s competitors.”
Cheaper over time?
So far in the AI industry, newer versions of AI language models typically maintain similar or cheaper pricing to their predecessors. The company had initially indicated Claude 3.5 Haiku would cost the same as the previous version before announcing the higher rates.
“I was expecting this to be a complete replacement for their existing Claude 3 Haiku model, in the same way that Claude 3.5 Sonnet eclipsed the existing Claude 3 Sonnet while maintaining the same pricing,” Willison wrote on his blog. “Given that Anthropic claim that their new Haiku out-performs their older Claude 3 Opus, this price isn’t disappointing, but it’s a small surprise nonetheless.”
Claude 3.5 Haiku arrives with some trade-offs. While the model produces longer text outputs and contains more recent training data, it cannot analyze images like its predecessor. Alex Albert, who leads developer relations at Anthropic, wrote on X that the earlier version, Claude 3 Haiku, will remain available for users who need image processing capabilities and lower costs.
The new model is not yet available in the Claude.ai web interface or app. Instead, it runs on Anthropic’s API and third-party platforms, including AWS Bedrock. Anthropic markets the model for tasks like coding suggestions, data extraction and labeling, and content moderation, though, like any LLM, it can easily make stuff up confidently.
“Is it good enough to justify the extra spend? It’s going to be difficult to figure that out,” Willison told Ars. “Teams with robust automated evals against their use-cases will be in a good place to answer that question, but those remain rare.”
On Monday, OpenAI kicked off its annual DevDay event in San Francisco, unveiling four major API updates for developers that integrate the company’s AI models into their products. Unlike last year’s single-location event featuring a keynote by CEO Sam Altman, DevDay 2024 is more than just one day, adopting a global approach with additional events planned for London on October 30 and Singapore on November 21.
The San Francisco event, which was invitation-only and closed to press, featured on-stage speakers going through technical presentations. Perhaps the most notable new API feature is the Realtime API, now in public beta, which supports speech-to-speech conversations using six preset voices and enables developers to build features very similar to ChatGPT’s Advanced Voice Mode (AVM) into their applications.
OpenAI says that the Realtime API streamlines the process of creating voice assistants. Previously, developers had to use multiple models for speech recognition, text processing, and text-to-speech conversion. Now, they can handle the entire process with a single API call.
The company plans to add audio input and output capabilities to its Chat Completions API in the next few weeks, allowing developers to input text or audio and receive responses in either format.
Two new options for cheaper inference
OpenAI also announced two features that may help developers balance performance and cost when making AI applications. “Model distillation” offers a way for developers to fine-tune (customize) smaller, cheaper models like GPT-4o mini using outputs from more advanced models such as GPT-4o and o1-preview. This potentially allows developers to get more relevant and accurate outputs while running the cheaper model.
Also, OpenAI announced “prompt caching,” a feature similar to one introduced by Anthropic for its Claude API in August. It speeds up inference (the AI model generating outputs) by remembering frequently used prompts (input tokens). Along the way, the feature provides a 50 percent discount on input tokens and faster processing times by reusing recently seen input tokens.
And last but not least, the company expanded its fine-tuning capabilities to include images (what it calls “vision fine-tuning”), allowing developers to customize GPT-4o by feeding it both custom images and text. Basically, developers can teach the multimodal version of GPT-4o to visually recognize certain things. OpenAI says the new feature opens up possibilities for improved visual search functionality, more accurate object detection for autonomous vehicles, and possibly enhanced medical image analysis.
Where’s the Sam Altman keynote?
Enlarge/ OpenAI CEO Sam Altman speaks during the OpenAI DevDay event on November 6, 2023, in San Francisco.
Getty Images
Unlike last year, DevDay isn’t being streamed live, though OpenAI plans to post content later on its YouTube channel. The event’s programming includes breakout sessions, community spotlights, and demos. But the biggest change since last year is the lack of a keynote appearance from the company’s CEO. This year, the keynote was handled by the OpenAI product team.
On last year’s inaugural DevDay, November 6, 2023, OpenAI CEO Sam Altman delivered a Steve Jobs-style live keynote to assembled developers, OpenAI employees, and the press. During his presentation, Microsoft CEO Satya Nadella made a surprise appearance, talking up the partnership between the companies.
Eleven days later, the OpenAI board fired Altman, triggering a week of turmoil that resulted in Altman’s return as CEO and a new board of directors. Just after the firing, Kara Swisher relayed insider sources that said Altman’s DevDay keynote and the introduction of the GPT store had been a precipitating factor in the firing (though not the key factor) due to some internal disagreements over the company’s more consumer-like direction since the launch of ChatGPT.
With that history in mind—and the focus on developers above all else for this event—perhaps the company decided it was best to let Altman step away from the keynote and let OpenAI’s technology become the key focus of the event instead of him. We are purely speculating on that point, but OpenAI has certainly experienced its share of drama over the past month, so it may have been a prudent decision.
Despite the lack of a keynote, Altman is present at Dev Day San Francisco today and is scheduled to do a closing “fireside chat” at the end (which has not yet happened as of this writing). Also, Altman made a statement about DevDay on X, noting that since last year’s DevDay, OpenAI had seen some dramatic changes (literally):
From last devday to this one:
*98% decrease in cost per token from GPT-4 to 4o mini *50x increase in token volume across our systems *excellent model intelligence progress *(and a little bit of drama along the way)
In a follow-up tweet delivered in his trademark lowercase, Altman shared a forward-looking message that referenced the company’s quest for human-level AI, often called AGI: “excited to make even more progress from this devday to the next one,” he wrote. “the path to agi has never felt more clear.”