Nvidia announces “Rubin Ultra” and “Feynman” AI chips for 2027 and 2028
On Tuesday at Nvidia’s GTC 2025 conference in San Jose, California, CEO Jensen Huang revealed several new AI-accelerating GPUs the company plans to release over the coming months and years. He also revealed more specifications about previously announced chips.
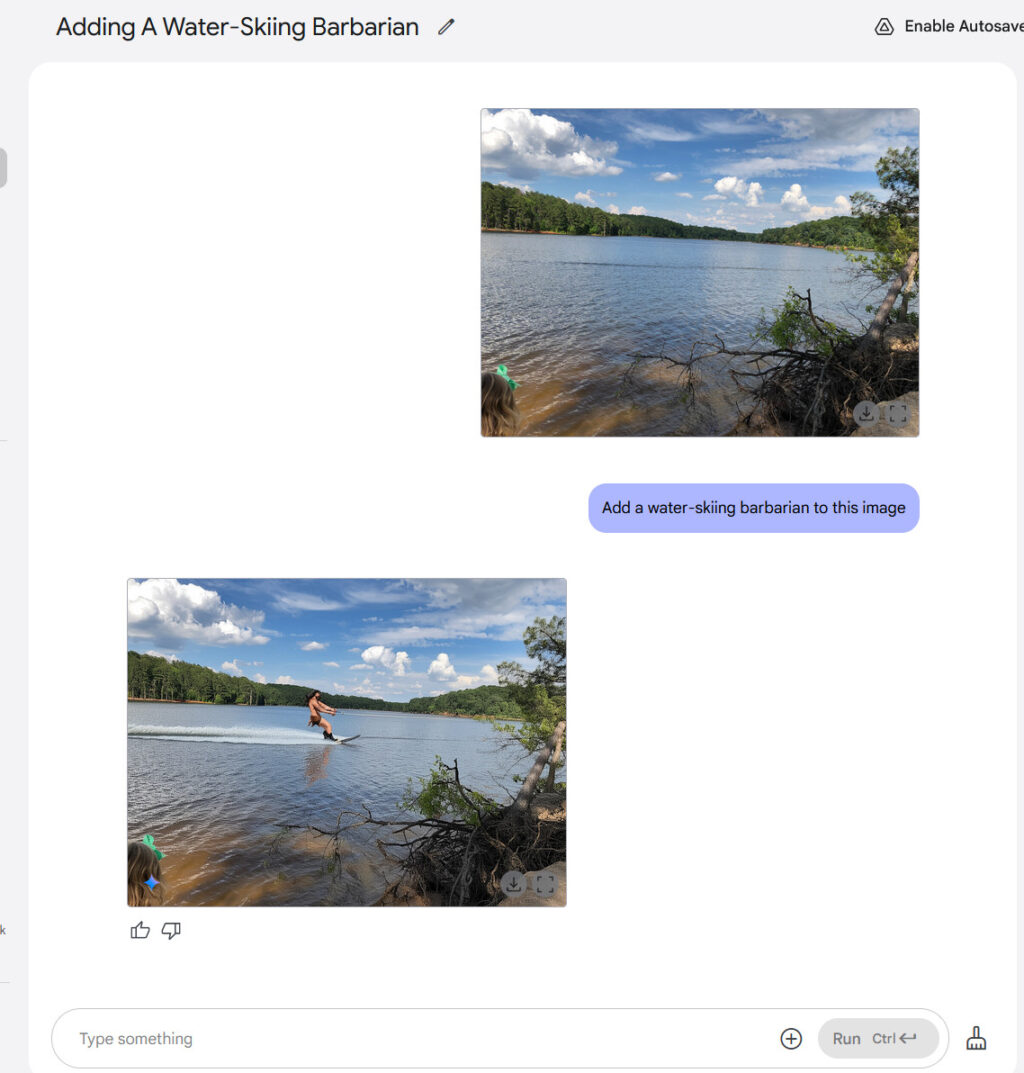
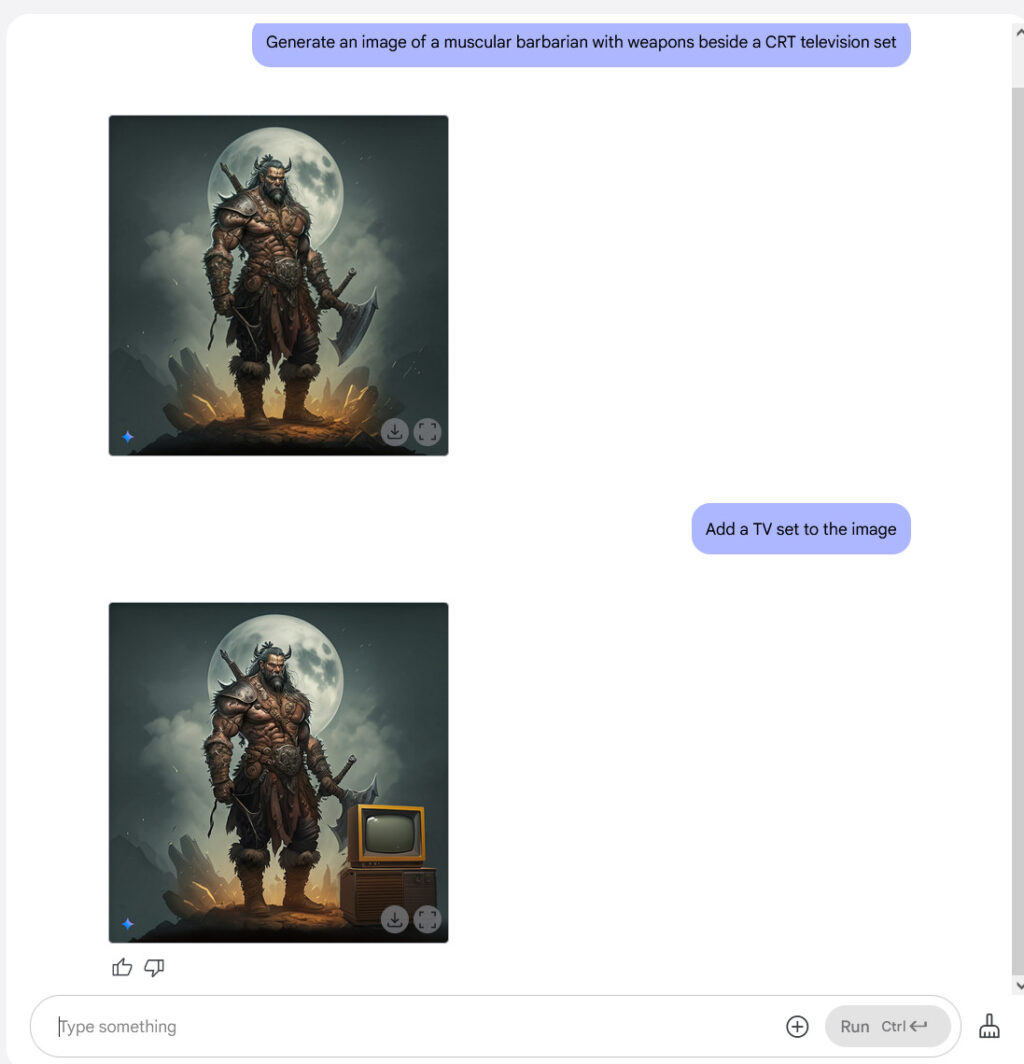
The centerpiece announcement was Vera Rubin, first teased at Computex 2024 and now scheduled for release in the second half of 2026. This GPU, named after a famous astronomer, will feature tens of terabytes of memory and comes with a custom Nvidia-designed CPU called Vera.
According to Nvidia, Vera Rubin will deliver significant performance improvements over its predecessor, Grace Blackwell, particularly for AI training and inference.

Specifications for Vera Rubin, presented by Jensen Huang during his GTC 2025 keynote.
Vera Rubin features two GPUs together on one die that deliver 50 petaflops of FP4 inference performance per chip. When configured in a full NVL144 rack, the system delivers 3.6 exaflops of FP4 inference compute—3.3 times more than Blackwell Ultra’s 1.1 exaflops in a similar rack configuration.
The Vera CPU features 88 custom ARM cores with 176 threads connected to Rubin GPUs via a high-speed 1.8 TB/s NVLink interface.
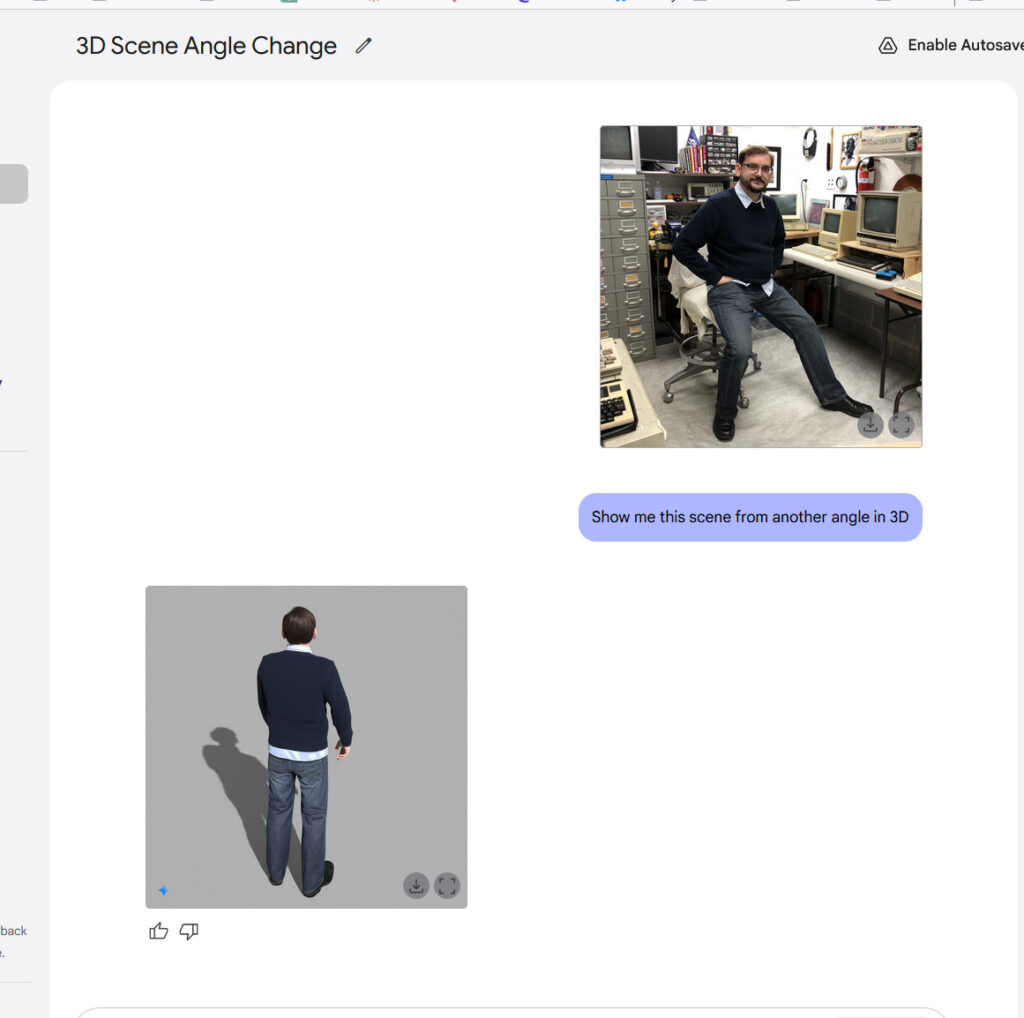
Huang also announced Rubin Ultra, which will follow in the second half of 2027. Rubin Ultra will use the NVL576 rack configuration and feature individual GPUs with four reticle-sized dies, delivering 100 petaflops of FP4 precision (a 4-bit floating-point format used for representing and processing numbers within AI models) per chip.
At the rack level, Rubin Ultra will provide 15 exaflops of FP4 inference compute and 5 exaflops of FP8 training performance—about four times more powerful than the Rubin NVL144 configuration. Each Rubin Ultra GPU will include 1TB of HBM4e memory, with the complete rack containing 365TB of fast memory.
Nvidia announces “Rubin Ultra” and “Feynman” AI chips for 2027 and 2028 Read More »