Robert Downey Jr. has declared that he will sue any future Hollywood executives who try to re-create his likeness using AI digital replicas, as reported by Variety. His comments came during an appearance on the “On With Kara Swisher” podcast, where he discussed AI’s growing role in entertainment.
“I intend to sue all future executives just on spec,” Downey told Swisher when discussing the possibility of studios using AI or deepfakes to re-create his performances after his death. When Swisher pointed out he would be deceased at the time, Downey responded that his law firm “will still be very active.”
The Oscar winner expressed confidence that Marvel Studios would not use AI to re-create his Tony Stark character, citing his trust in decision-makers there. “I am not worried about them hijacking my character’s soul because there’s like three or four guys and gals who make all the decisions there anyway and they would never do that to me,” he said.
Downey currently performs on Broadway in McNeal, a play that examines corporate leaders in AI technology. During the interview, he freely critiqued tech executives—Variety pointed out a particular quote from the interview where he criticized tech leaders who potentially do negative things but seek positive attention.
The police operation resulted in the seizure of computers, mobile phones, and about $25,756 in suspected proceeds and luxury watches from the syndicate’s headquarters. Police said that victims originated from multiple countries, including Hong Kong, mainland China, Taiwan, India, and Singapore.
A widening real-time deepfake problem
Realtime deepfakes have become a growing problem over the past year. In August, we covered a free app called Deep-Live-Cam that can do real-time face-swaps for video chat use, and in February, the Hong Kong office of British engineering firm Arup lost $25 million in an AI-powered scam in which the perpetrators used deepfakes of senior management during a video conference call to trick an employee into transferring money.
News of the scam also comes amid recent warnings from the United Nations Office on Drugs and Crime, notes The Record in a report about the recent scam ring. The agency released a report last week highlighting tech advancements among organized crime syndicates in Asia, specifically mentioning the increasing use of deepfake technology in fraud.
The UN agency identified more than 10 deepfake software providers selling their services on Telegram to criminal groups in Southeast Asia, showing the growing accessibility of this technology for illegal purposes.
Some companies are attempting to find automated solutions to the issues presented by AI-powered crime, including Reality Defender, which creates software that attempts to detect deepfakes in real time. Some deepfake detection techniques may work at the moment, but as the fakes improve in realism and sophistication, we may be looking at an escalating arms race between those who seek to fool others and those who want to prevent deception.
Real-time deepfakes are no longer limited to billionaires, public figures, or those who have extensive online presences. Mittal’s research at NYU, with professors Chinmay Hegde and Nasir Memon, proposes a potential challenge-based approach to blocking AI bots from video calls, where participants would have to pass a kind of video CAPTCHA test before joining.
As Reality Defender works to improve the detection accuracy of its models, Colman says that access to more data is a critical challenge to overcome—a common refrain from the current batch of AI-focused startups. He’s hopeful more partnerships will fill in these gaps, and without specifics, hints at multiple new deals likely coming next year. After ElevenLabs was tied to a deepfake voice call of US president Joe Biden, the AI-audio startup struck a deal with Reality Defender to mitigate potential misuse.
What can you do right now to protect yourself from video call scams? Just like WIRED’s core advice about avoiding fraud from AI voice calls, not getting cocky about whether you can spot video deepfakes is critical to avoid being scammed. The technology in this space continues to evolve rapidly, and any telltale signs you rely on now to spot AI deepfakes may not be as dependable with the next upgrades to underlying models.
“We don’t ask my 80-year-old mother to flag ransomware in an email,” says Colman. “Because she’s not a computer science expert.” In the future, it’s possible real-time video authentication, if AI detection continues to improve and shows to be reliably accurate, will be as taken for granted as that malware scanner quietly humming along in the background of your email inbox.
“Robotic humanoid animals with vaudeville costumes roam the streets collecting protection money in tokens”
“A basketball player in a haunted passenger train car with a basketball court, and he is playing against a team of ghosts”
“A herd of one million cats running on a hillside, aerial view”
“Video game footage of a dynamic 1990s third-person 3D platform game starring an anthropomorphic shark boy”
“A muscular barbarian breaking a CRT television set with a weapon, cinematic, 8K, studio lighting”
Limitations of video synthesis models
Overall, the Minimax video-01 results seen above feel fairly similar to Gen-3’s outputs, with some differences, like the lack of a celebrity filter on Will Smith (who sadly did not actually eat the spaghetti in our tests), and the more realistic cat hands and licking motion. Some results were far worse, like the one million cats and the Ars Technica reader.
On Friday, Meta announced a preview of Movie Gen, a new suite of AI models designed to create and manipulate video, audio, and images, including creating a realistic video from a single photo of a person. The company claims the models outperform other video-synthesis models when evaluated by humans, pushing us closer to a future where anyone can synthesize a full video of any subject on demand.
The company does not yet have plans of when or how it will release these capabilities to the public, but Meta says Movie Gen is a tool that may allow people to “enhance their inherent creativity” rather than replace human artists and animators. The company envisions future applications such as easily creating and editing “day in the life” videos for social media platforms or generating personalized animated birthday greetings.
Movie Gen builds on Meta’s previous work in video synthesis, following 2022’s Make-A-Scene video generator and the Emu image-synthesis model. Using text prompts for guidance, this latest system can generate custom videos with sounds for the first time, edit and insert changes into existing videos, and transform images of people into realistic personalized videos.
An AI-generated video of a baby hippo swimming around, created with Meta Movie Gen.
Meta isn’t the only game in town when it comes to AI video synthesis. Google showed off a new model called “Veo” in May, and Meta says that in human preference tests, its Movie Gen outputs beat OpenAI’s Sora, Runway Gen-3, and Chinese video model Kling.
Movie Gen’s video-generation model can create 1080p high-definition videos up to 16 seconds long at 16 frames per second from text descriptions or an image input. Meta claims the model can handle complex concepts like object motion, subject-object interactions, and camera movements.
AI-generated video from Meta Movie Gen with the prompt: “A ghost in a white bedsheet faces a mirror. The ghost’s reflection can be seen in the mirror. The ghost is in a dusty attic, filled with old beams, cloth-covered furniture. The attic is reflected in the mirror. The light is cool and natural. The ghost dances in front of the mirror.”
Even so, as we’ve seen with previous AI video generators, Movie Gen’s ability to generate coherent scenes on a particular topic is likely dependent on the concepts found in the example videos that Meta used to train its video-synthesis model. It’s worth keeping in mind that cherry-picked results from video generators often differ dramatically from typical results and getting a coherent result may require lots of trial and error.
“Almost any digitally altered content, when left up to an arbitrary individual on the Internet, could be considered harmful,” Mendez said, even something seemingly benign like AI-generated estimates of voter turnouts shared online.
Additionally, the Supreme Court has held that “even deliberate lies (said with ‘actual malice’) about the government are constitutionally protected” because the right to criticize the government is at the heart of the First Amendment.
“These same principles safeguarding the people’s right to criticize government and government officials apply even in the new technological age when media may be digitally altered: civil penalties for criticisms on the government like those sanctioned by AB 2839 have no place in our system of governance,” Mendez said.
According to Mendez, X posts like Kohls’ parody videos are the “political cartoons of today” and California’s attempt to “bulldoze over the longstanding tradition of critique, parody, and satire protected by the First Amendment” is not justified by even “a well-founded fear of a digitally manipulated media landscape.” If officials find deepfakes are harmful to election prospects, there is already recourse through privacy torts, copyright infringement, or defamation laws, Mendez suggested.
Kosseff told Ars that there could be more narrow ways that government officials looking to protect election integrity could regulate deepfakes online. The Supreme Court has suggested that deepfakes spreading disinformation on the mechanics of voting could possibly be regulated, Kosseff said.
Mendez got it “exactly right” by concluding that the best remedy for election-related deepfakes is more speech, Kosseff said. As Mendez described it, a vague law like AB 2839 seemed to only “uphold the State’s attempt to suffocate” speech.
Parody is vital to democratic debate, judge says
The only part of AB 2839 that survives strict scrutiny, Mendez noted, is a section describing audio disclosures in a “clearly spoken manner and in a pitch that can be easily heard by the average listener, at the beginning of the audio, at the end of the audio, and, if the audio is greater than two minutes in length, interspersed within the audio at intervals of not greater than two minutes each.”
Given the flood of photorealistic AI-generated images washing over social media networks like X and Facebook these days, we’re seemingly entering a new age of media skepticism: the era of what I’m calling “deep doubt.” While questioning the authenticity of digital content stretches back decades—and analog media long before that—easy access to tools that generate convincing fake content has led to a new wave of liars using AI-generated scenes to deny real documentary evidence. Along the way, people’s existing skepticism toward online content from strangers may be reaching new heights.
Deep doubt is skepticism of real media that stems from the existence of generative AI. This manifests as broad public skepticism toward the veracity of media artifacts, which in turn leads to a notable consequence: People can now more credibly claim that real events did not happen and suggest that documentary evidence was fabricated using AI tools.
The concept behind “deep doubt” isn’t new, but its real-world impact is becoming increasingly apparent. Since the term “deepfake” first surfaced in 2017, we’ve seen a rapid evolution in AI-generated media capabilities. This has led to recent examples of deep doubt in action, such as conspiracy theorists claiming that President Joe Biden has been replaced by an AI-powered hologram and former President Donald Trump’s baseless accusation in August that Vice President Kamala Harris used AI to fake crowd sizes at her rallies. And on Friday, Trump cried “AI” again at a photo of him with E. Jean Carroll, a writer who successfully sued him for sexual assault, that contradicts his claim of never having met her.
Legal scholars Danielle K. Citron and Robert Chesney foresaw this trend years ago, coining the term “liar’s dividend” in 2019 to describe the consequence of deep doubt: deepfakes being weaponized by liars to discredit authentic evidence. But whereas deep doubt was once a hypothetical academic concept, it is now our reality.
The rise of deepfakes, the persistence of doubt
Doubt has been a political weapon since ancient times. This modern AI-fueled manifestation is just the latest evolution of a tactic where the seeds of uncertainty are sown to manipulate public opinion, undermine opponents, and hide the truth. AI is the newest refuge of liars.
Over the past decade, the rise of deep-learning technology has made it increasingly easy for people to craft false or modified pictures, audio, text, or video that appear to be non-synthesized organic media. Deepfakes were named after a Reddit user going by the name “deepfakes,” who shared AI-faked pornography on the service, swapping out the face of a performer with the face of someone else who wasn’t part of the original recording.
In the 20th century, one could argue that a certain part of our trust in media produced by others was a result of how expensive and time-consuming it was, and the skill it required, to produce documentary images and films. Even texts required a great deal of time and skill. As the deep doubt phenomenon grows, it will erode this 20th-century media sensibility. But it will also affect our political discourse, legal systems, and even our shared understanding of historical events that rely on that media to function—we rely on others to get information about the world. From photorealistic images to pitch-perfect voice clones, our perception of what we consider “truth” in media will need recalibration.
In April, a panel of federal judges highlighted the potential for AI-generated deepfakes to not only introduce fake evidence but also cast doubt on genuine evidence in court trials. The concern emerged during a meeting of the US Judicial Conference’s Advisory Committee on Evidence Rules, where the judges discussed the challenges of authenticating digital evidence in an era of increasingly sophisticated AI technology. Ultimately, the judges decided to postpone making any AI-related rule changes, but their meeting shows that the subject is already being considered by American judges.
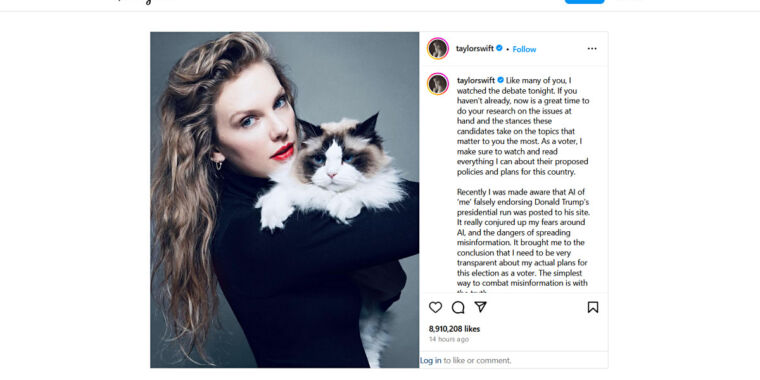
Enlarge/ A screenshot of Taylor Swift’s Kamala Harris Instagram post, captured on September 11, 2024.
On Tuesday night, Taylor Swift endorsed Vice President Kamala Harris for US President on Instagram, citing concerns over AI-generated deepfakes as a key motivator. The artist’s warning aligns with current trends in technology, especially in an era where AI synthesis models can easily create convincing fake images and videos.
“Recently I was made aware that AI of ‘me’ falsely endorsing Donald Trump’s presidential run was posted to his site,” she wrote in her Instagram post. “It really conjured up my fears around AI, and the dangers of spreading misinformation. It brought me to the conclusion that I need to be very transparent about my actual plans for this election as a voter. The simplest way to combat misinformation is with the truth.”
In August 2024, former President Donald Trump posted AI-generated images on Truth Social falsely suggesting Swift endorsed him, including a manipulated photo depicting Swift as Uncle Sam with text promoting Trump. The incident sparked Swift’s fears about the spread of misinformation through AI.
This isn’t the first time Swift and generative AI have appeared together in the news. In February, we reported that a flood of explicit AI-generated images of Swift originated from a 4chan message board where users took part in daily challenges to bypass AI image generator filters.
San Francisco’s city attorney David Chiu is suing to shut down 16 of the most popular websites and apps allowing users to “nudify” or “undress” photos of mostly women and girls who have been increasingly harassed and exploited by bad actors online.
These sites, Chiu’s suit claimed, are “intentionally” designed to “create fake, nude images of women and girls without their consent,” boasting that any users can upload any photo to “see anyone naked” by using tech that realistically swaps the faces of real victims onto AI-generated explicit images.
“In California and across the country, there has been a stark increase in the number of women and girls harassed and victimized by AI-generated” non-consensual intimate imagery (NCII) and “this distressing trend shows no sign of abating,” Chiu’s suit said.
“Given the widespread availability and popularity” of nudify websites, “San Franciscans and Californians face the threat that they or their loved ones may be victimized in this manner,” Chiu’s suit warned.
In a press conference, Chiu said that this “first-of-its-kind lawsuit” has been raised to defend not just Californians, but “a shocking number of women and girls across the globe”—from celebrities like Taylor Swift to middle and high school girls. Should the city official win, each nudify site risks fines of $2,500 for each violation of California consumer protection law found.
On top of media reports sounding alarms about the AI-generated harm, law enforcement has joined the call to ban so-called deepfakes.
Chiu said the harmful deepfakes are often created “by exploiting open-source AI image generation models,” such as earlier versions of Stable Diffusion, that can be honed or “fine-tuned” to easily “undress” photos of women and girls that are frequently yanked from social media. While later versions of Stable Diffusion make such “disturbing” forms of misuse much harder, San Francisco city officials noted at the press conference that fine-tunable earlier versions of Stable Diffusion are still widely available to be abused by bad actors.
In the US alone, cops are currently so bogged down by reports of fake AI child sex images that it’s making it hard to investigate child abuse cases offline, and these AI cases are expected to continue spiking “exponentially.” The AI abuse has spread so widely that “the FBI has warned of an uptick in extortion schemes using AI generated non-consensual pornography,” Chiu said at the press conference. “And the impact on victims has been devastating,” harming “their reputations and their mental health,” causing “loss of autonomy,” and “in some instances causing individuals to become suicidal.”
Suing on behalf of the people of the state of California, Chiu is seeking an injunction requiring nudify site owners to cease operation of “all websites they own or operate that are capable of creating AI-generated” non-consensual intimate imagery of identifiable individuals. It’s the only way, Chiu said, to hold these sites “accountable for creating and distributing AI-generated NCII of women and girls and for aiding and abetting others in perpetrating this conduct.”
He also wants an order requiring “any domain-name registrars, domain-name registries, webhosts, payment processors, or companies providing user authentication and authorization services or interfaces” to “restrain” nudify site operators from launching new sites to prevent any further misconduct.
Chiu’s suit redacts the names of the most harmful sites his investigation uncovered but claims that in the first six months of 2024, the sites “have been visited over 200 million times.”
While victims typically have little legal recourse, Chiu believes that state and federal laws prohibiting deepfake pornography, revenge pornography, and child pornography, as well as California’s unfair competition law, can be wielded to take down all 16 sites. Chiu expects that a win will serve as a warning to other nudify site operators that more takedowns are likely coming.
“We are bringing this lawsuit to get these websites shut down, but we also want to sound the alarm,” Chiu said at the press conference. “Generative AI has enormous promise, but as with all new technologies, there are unanticipated consequences and criminals seeking to exploit them. We must be clear that this is not innovation. This is sexual abuse.”
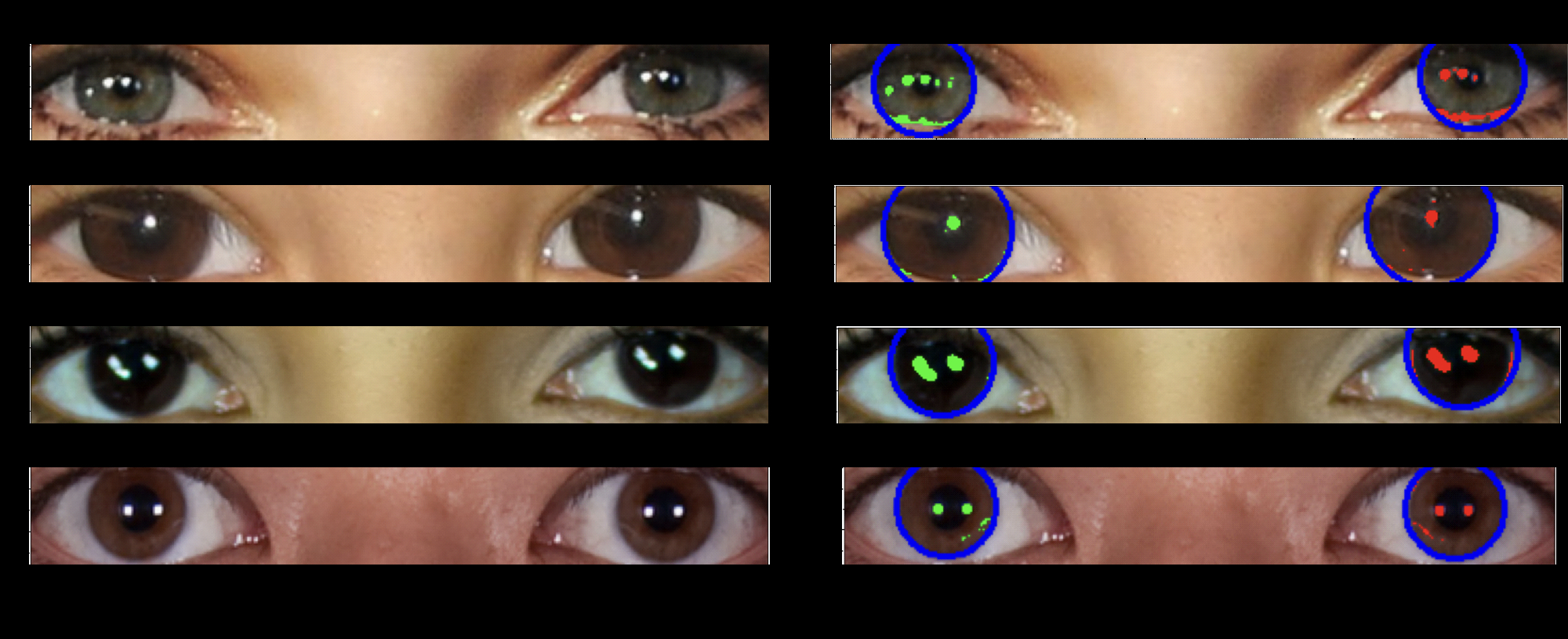
Enlarge/ Researchers write, “In this image, the person on the left (Scarlett Johansson) is real, while the person on the right is AI-generated. Their eyeballs are depicted underneath their faces. The reflections in the eyeballs are consistent for the real person, but incorrect (from a physics point of view) for the fake person.”
In 2024, it’s almost trivial to create realistic AI-generated images of people, which has led to fears about how these deceptive images might be detected. Researchers at the University of Hull recently unveiled a novel method for detecting AI-generated deepfake images by analyzing reflections in human eyes. The technique, presented at the Royal Astronomical Society’s National Astronomy Meeting last week, adapts tools used by astronomers to study galaxies for scrutinizing the consistency of light reflections in eyeballs.
Adejumoke Owolabi, an MSc student at the University of Hull, headed the research under the guidance of Dr. Kevin Pimbblet, professor of astrophysics.
Their detection technique is based on a simple principle: A pair of eyes being illuminated by the same set of light sources will typically have a similarly shaped set of light reflections in each eyeball. Many AI-generated images created to date don’t take eyeball reflections into account, so the simulated light reflections are often inconsistent between each eye.
Enlarge/ A series of real eyes showing largely consistent reflections in both eyes.
In some ways, the astronomy angle isn’t always necessary for this kind of deepfake detection because a quick glance at a pair of eyes in a photo can reveal reflection inconsistencies, which is something artists who paint portraits have to keep in mind. But the application of astronomy tools to automatically measure and quantify eye reflections in deepfakes is a novel development.
Automated detection
In a Royal Astronomical Society blog post, Pimbblet explained that Owolabi developed a technique to detect eyeball reflections automatically and ran the reflections’ morphological features through indices to compare similarity between left and right eyeballs. Their findings revealed that deepfakes often exhibit differences between the pair of eyes.
The team applied methods from astronomy to quantify and compare eyeball reflections. They used the Gini coefficient, typically employed to measure light distribution in galaxy images, to assess the uniformity of reflections across eye pixels. A Gini value closer to 0 indicates evenly distributed light, while a value approaching 1 suggests concentrated light in a single pixel.
Enlarge/ A series of deepfake eyes showing inconsistent reflections in each eye.
In the Royal Astronomical Society post, Pimbblet drew comparisons between how they measured eyeball reflection shape and how they typically measure galaxy shape in telescope imagery: “To measure the shapes of galaxies, we analyze whether they’re centrally compact, whether they’re symmetric, and how smooth they are. We analyze the light distribution.”
The researchers also explored the use of CAS parameters (concentration, asymmetry, smoothness), another tool from astronomy for measuring galactic light distribution. However, this method proved less effective in identifying fake eyes.
A detection arms race
While the eye-reflection technique offers a potential path for detecting AI-generated images, the method might not work if AI models evolve to incorporate physically accurate eye reflections, perhaps applied as a subsequent step after image generation. The technique also requires a clear, up-close view of eyeballs to work.
The approach also risks producing false positives, as even authentic photos can sometimes exhibit inconsistent eye reflections due to varied lighting conditions or post-processing techniques. But analyzing eye reflections may still be a useful tool in a larger deepfake detection toolset that also considers other factors such as hair texture, anatomy, skin details, and background consistency.
While the technique shows promise in the short term, Dr. Pimbblet cautioned that it’s not perfect. “There are false positives and false negatives; it’s not going to get everything,” he told the Royal Astronomical Society. “But this method provides us with a basis, a plan of attack, in the arms race to detect deepfakes.”
Enlarge/ Al Michaels looks on prior to the game between the Minnesota Vikings and Philadelphia Eagles at Lincoln Financial Field on September 14, 2023, in Philadelphia, Pennsylvania.
On Wednesday, NBC announced plans to use an AI-generated clone of famous sports commentator Al Michaels‘ voice to narrate daily streaming video recaps of the 2024 Summer Olympics in Paris, which start on July 26. The AI-powered narration will feature in “Your Daily Olympic Recap on Peacock,” NBC’s streaming service. But this new, high-profile use of voice cloning worries critics, who say the technology may muscle out upcoming sports commentators by keeping old personas around forever.
NBC says it has created a “high-quality AI re-creation” of Michaels’ voice, trained on Michaels’ past NBC appearances to capture his distinctive delivery style.
The veteran broadcaster, revered in the sports commentator world for his iconic “Do you believe in miracles? Yes!” call during the 1980 Winter Olympics, has been covering sports on TV since 1971, including a high-profile run of play-by-play coverage of NFL football games for both ABC and NBC since the 1980s. NBC dropped him from NFL coverage in 2023, however, possibly due to his age.
Michaels, who is 79 years old, shared his initial skepticism about the project in an interview with Vanity Fair, as NBC News notes. After hearing the AI version of his voice, which can greet viewers by name, he described the experience as “astonishing” and “a little bit frightening.” He said the AI recreation was “almost 2% off perfect” in mimicking his style.
The Vanity Fair article provides some insight into how NBC’s new AI system works. It first uses a large language model (similar technology to what powers ChatGPT) to analyze subtitles and metadata from NBC’s Olympics video coverage, summarizing events and writing custom output to imitate Michaels’ style. This text is then fed into an unspecified voice AI model trained on Michaels’ previous NBC appearances, reportedly replicating his unique pronunciations and intonations.
NBC estimates that the system could generate nearly 7 million personalized variants of the recaps across the US during the games, pulled from the network’s 5,000 hours of live coverage. Using the system, each Peacock user will receive about 10 minutes of personalized highlights.
A diminished role for humans in the future?
Enlarge/ Al Michaels reports on the Sweden vs. USA men’s ice hockey game at the 1980 Olympic Winter Games on February 12, 1980.
It’s no secret that while AI is wildly hyped right now, it’s also controversial among some. Upon hearing the NBC announcement, critics of AI technology reacted strongly. “@NBCSports, this is gross,” tweeted actress and filmmaker Justine Bateman, who frequently uses X to criticize technologies that might replace human writers or performers in the future.
A thread of similar responses from X users reacting to the sample video provided above included criticisms such as, “Sounds pretty off when it’s just the same tone for every single word.” Another user wrote, “It just sounds so unnatural. No one talks like that.”
The technology will not replace NBC’s regular human sports commentators during this year’s Olympics coverage, and like other forms of AI, it leans heavily on existing human work by analyzing and regurgitating human-created content in the form of captions pulled from NBC footage.
Looking down the line, due to AI media cloning technologies like voice, video, and image synthesis, today’s celebrities may be able to attain a form of media immortality that allows new iterations of their likenesses to persist through the generations, potentially earning licensing fees for whoever holds the rights.
We’ve already seen it with James Earl Jones playing Darth Vader’s voice, and the trend will likely continue with other celebrity voices, provided the money is right. Eventually, it may extend to famous musicians through music synthesis and famous actors in video-synthesis applications as well.
The possibility of being muscled out by AI replicas factored heavily into a Hollywood actors’ strike last year, with SAG-AFTRA union President Fran Drescher saying, “If we don’t stand tall right now, we are all going to be in trouble. We are all going to be in jeopardy of being replaced by machines.”
For companies that like to monetize media properties for as long as possible, AI may provide a way to maintain a media legacy through automation. But future human performers may have to compete against all of the greatest performers of the past, rendered through AI, to break out and forge a new career—provided there will be room for human performers at all.
“Al Michaels became Al Michaels because he was brought in to replace people who died, or retired, or moved on,” tweeted a writer named Geonn Cannon on X. “If he can’t do the job anymore, it’s time to let the next Al Michaels have a shot at it instead of just planting a code-generated ghoul in an empty chair.“
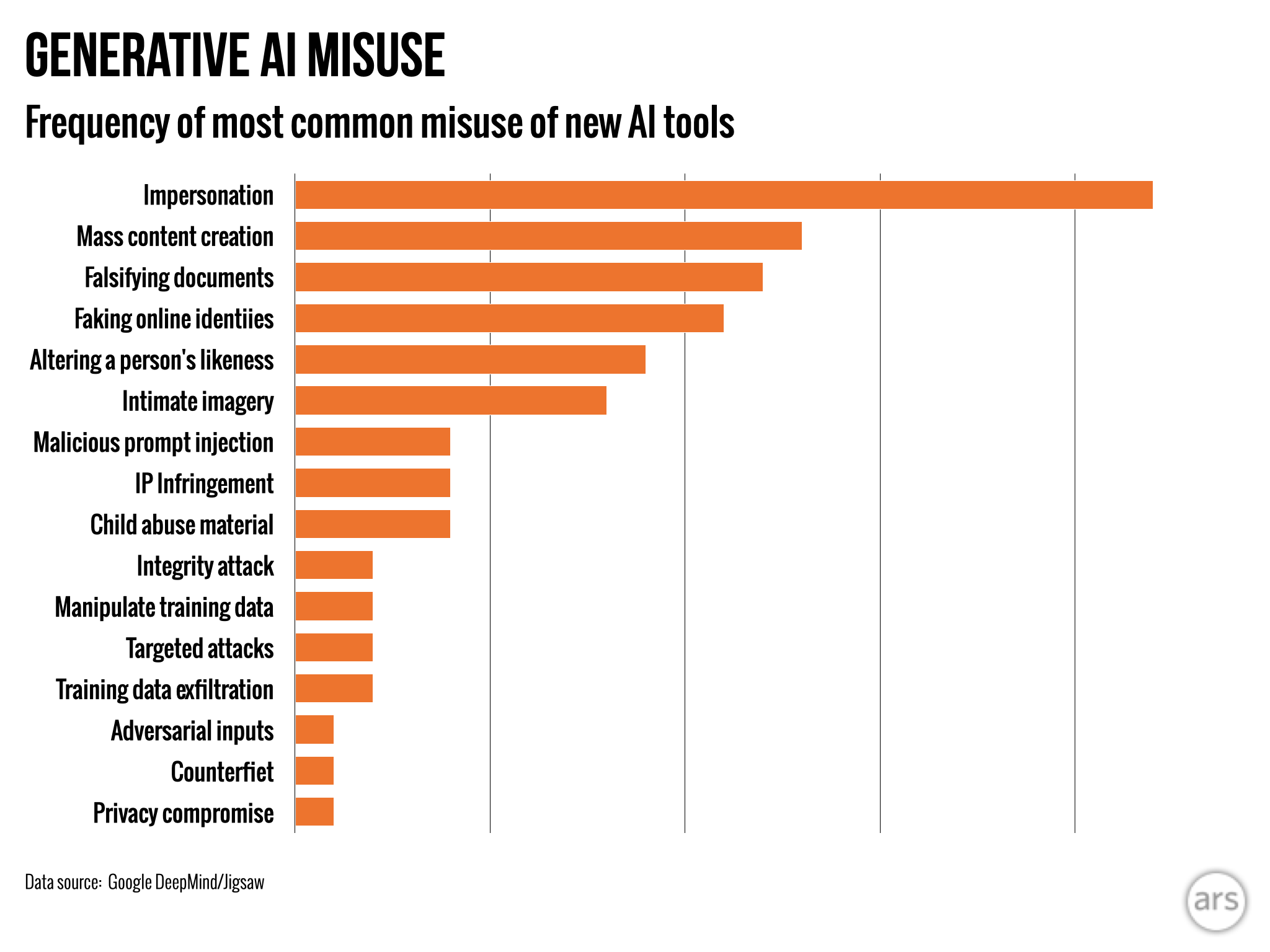
Artificial intelligence-generated “deepfakes” that impersonate politicians and celebrities are far more prevalent than efforts to use AI to assist cyber attacks, according to the first research by Google’s DeepMind division into the most common malicious uses of the cutting-edge technology.
The study said the creation of realistic but fake images, video, and audio of people was almost twice as common as the next highest misuse of generative AI tools: the falsifying of information using text-based tools, such as chatbots, to generate misinformation to post online.
The most common goal of actors misusing generative AI was to shape or influence public opinion, the analysis, conducted with the search group’s research and development unit Jigsaw, found. That accounted for 27 percent of uses, feeding into fears over how deepfakes might influence elections globally this year.
Deepfakes of UK Prime Minister Rishi Sunak, as well as other global leaders, have appeared on TikTok, X, and Instagram in recent months. UK voters go to the polls next week in a general election.
Concern is widespread that, despite social media platforms’ efforts to label or remove such content, audiences may not recognize these as fake, and dissemination of the content could sway voters.
Ardi Janjeva, research associate at The Alan Turing Institute, called “especially pertinent” the paper’s finding that the contamination of publicly accessible information with AI-generated content could “distort our collective understanding of sociopolitical reality.”
Janjeva added: “Even if we are uncertain about the impact that deepfakes have on voting behavior, this distortion may be harder to spot in the immediate term and poses long-term risks to our democracies.”
The study is the first of its kind by DeepMind, Google’s AI unit led by Sir Demis Hassabis, and is an attempt to quantify the risks from the use of generative AI tools, which the world’s biggest technology companies have rushed out to the public in search of huge profits.
As generative products such as OpenAI’s ChatGPT and Google’s Gemini become more widely used, AI companies are beginning to monitor the flood of misinformation and other potentially harmful or unethical content created by their tools.
In May, OpenAI released research revealing operations linked to Russia, China, Iran, and Israel had been using its tools to create and spread disinformation.
“There had been a lot of understandable concern around quite sophisticated cyber attacks facilitated by these tools,” said Nahema Marchal, lead author of the study and researcher at Google DeepMind. “Whereas what we saw were fairly common misuses of GenAI [such as deepfakes that] might go under the radar a little bit more.”
Google DeepMind and Jigsaw’s researchers analyzed around 200 observed incidents of misuse between January 2023 and March 2024, taken from social media platforms X and Reddit, as well as online blogs and media reports of misuse.
Ars Technica
The second most common motivation behind misuse was to make money, whether offering services to create deepfakes, including generating naked depictions of real people, or using generative AI to create swaths of content, such as fake news articles.
The research found that most incidents use easily accessible tools, “requiring minimal technical expertise,” meaning more bad actors can misuse generative AI.
Google DeepMind’s research will influence how it improves its evaluations to test models for safety, and it hopes it will also affect how its competitors and other stakeholders view how “harms are manifesting.”


















{kind=link}
{kind=link}
{kind=link}