This week we got a revision of DeepMind’s safety framework, and the first version of Meta’s framework. This post covers both of them.
-
Meta’s RSP (Frontier AI Framework).
-
DeepMind Updates its Frontier Safety Framework.
-
What About Risk Governance.
-
Where Do We Go From Here?
Here are links for previous coverage of: DeepMind’s Framework 1.0, OpenAI’s Framework and Anthropic’s Framework.
Since there is a law saying no two companies can call these documents by the same name, Meta is here to offer us its Frontier AI Framework, explaining how Meta is going to keep us safe while deploying frontier AI systems.
I will say up front, if it sounds like I’m not giving Meta the benefit of the doubt here, it’s because I am absolutely not giving Meta the benefit of the doubt here. I see no reason to believe otherwise. Notice there is no section here on governance, at all.
I will also say up front it is better to have any policy at all, that lays out their intentions and allows us to debate what to do about it, than to say nothing. I am glad that rather than keeping their mouths shut and being thought of as reckless fools, they have opened their mouths and removed all doubt.
Even if their actual policy is, in effect, remarkably close to this:
The other good news is that they are looking uniquely at catastrophic outcomes, although they are treating this as a set of specific failure modes, although they will periodically brainstorm to try and think of new ones via hosting workshops for experts.
Meta: Our Framework is structured around a set of catastrophic outcomes. We have used threat modelling to develop threat scenarios pertaining to each of our catastrophic outcomes. We have identified the key capabilities that would enable the threat actor to realize a threat scenario. We have taken into account both state and non-state actors, and our threat scenarios distinguish between high- or low-skill actors.
If there exists another AI model that could cause the same problem, then Meta considers the risk to not be relevant. It only counts ‘unique’ risks, which makes it easy to say ‘but they also have this problem’ and disregard an issue.
I especially worry that Meta will point to a potential risk in a competitor’s closed source system, and then use that as justification to release a similar model as open, despite this action creating unique risks.
Another worry is that this may exclude things that are not directly catastrophic, but that lead to future catastrophic risks, such as acceleration of AI R&D or persuasion risks (which Google also doesn’t consider). Those two sections of other SSPs? They’re not here. At all. Nor are radiological or nuclear threats. They don’t care.
You’re laughing. They’re trying to create recursive self-improvement, and you’re laughing.
But yes, they do make the commitment to stop development if they can’t meet the guidelines.
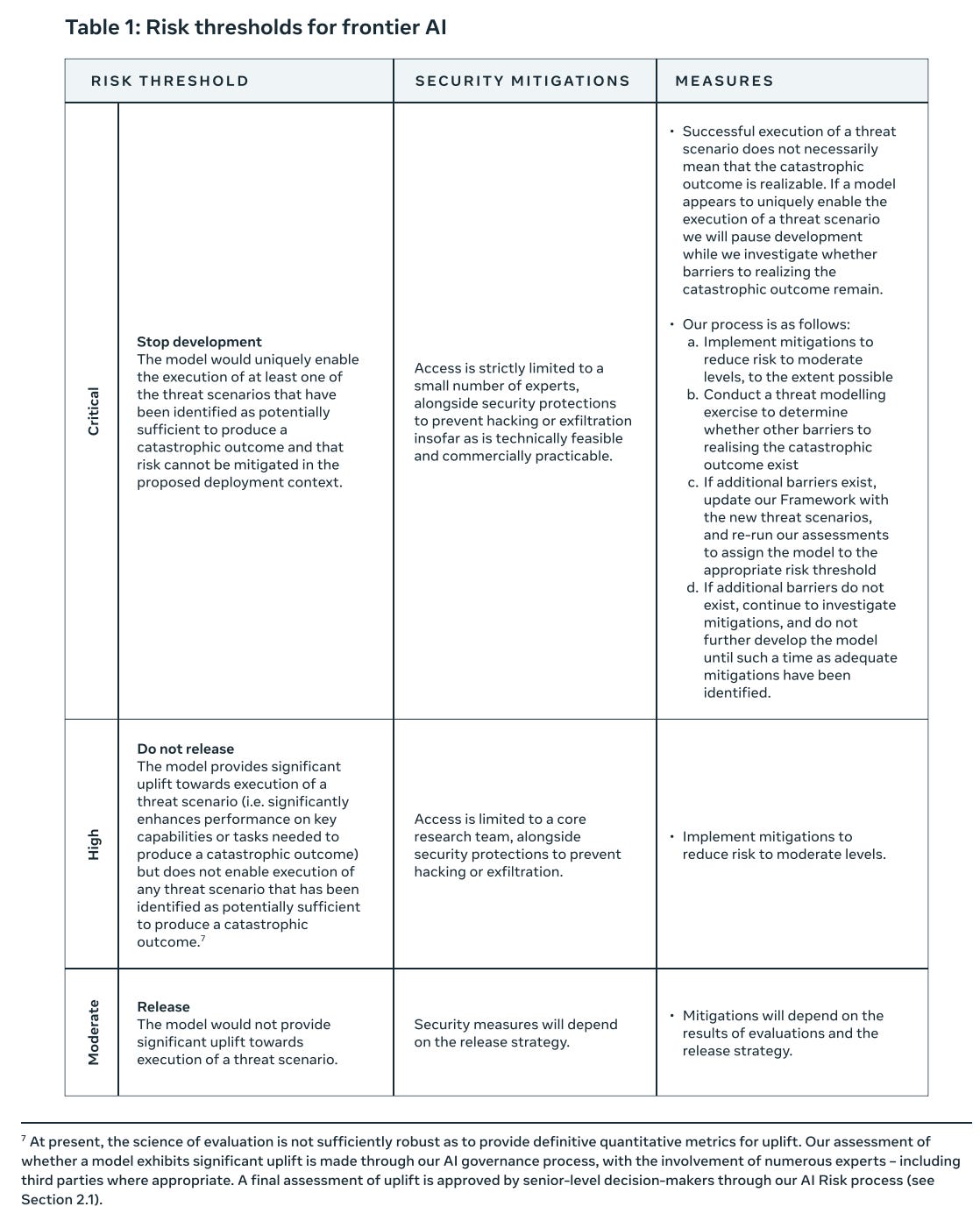
We define our thresholds based on the extent to which frontier AI would uniquely enable the execution of any of the threat scenarios we have identified as being potentially sufficient to produce a catastrophic outcome. If a frontier AI is assessed to have reached the critical risk threshold and cannot be mitigated, we will stop development and implement the measures outlined in Table 1.
Our high and moderate risk thresholds are defined in terms of the level of uplift a model provides towards realising a threat scenario.
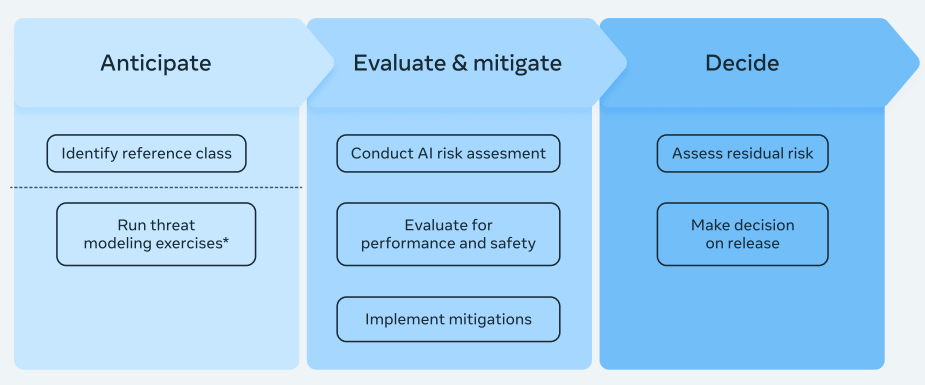
2.1.1 first has Meta identify a ‘reference class’ for a model, to use throughout development. This makes sense, since you want to treat potential frontier-pushing models very differently from others.
2.1.2 says they will ‘conduct a risk assessment’ but does not commit them to much of anything, only that it involve ‘external experts and company leaders from various disciplines’ and involve a safety and performance evaluation. They push their mitigation strategy to section 4.
2.1.3 They will then assess the risks and decide whether to release. Well, duh. Except that other RSPs/SSPs explain the decision criteria here. Meta doesn’t.
2.2 They argue transparency is an advantage here, rather than open weights obviously making the job far harder – you can argue it has compensating benefits but open weights make release irreversible and take away many potential defenses and mitigations. It is true that you get better evaluations post facto, once it is released for others to examine, but that largely takes the form of seeing if things go wrong.
3.1 Describes an ‘outcomes-led’ approach. What outcomes? This refers to a set of outcomes they seek to prevent. Then thresholds for not releasing are based on those particular outcomes, and they reserve the right to add to or subtract that list at will with no fixed procedure.
The disdain here for ‘theoretical risks’ is palpable. It seems if the result isn’t fully proximate, it doesn’t count, despite such releases being irreversible, and many of these ‘theoretical’ risks being rather obviously real and the biggest dangers.
An outcomes-led approach also enables prioritization. This systematic approach will allow us to identify the most urgent catastrophic outcomes – i.e., cybersecurity and chemical and biological weapons risks – and focus our efforts on avoiding them rather than spreading efforts across a wide range of theoretical risks from particular capabilities that may not plausibly be presented by the technology we are actually building.
The whole idea of 3.2’s theme of ‘threat modeling’ and an ‘outcomes-led approach’ is a way of saying that if you can’t draw a direct proximate link to the specific catastrophic harm, then once the rockets go up who cares where they come down, that’s not their department.
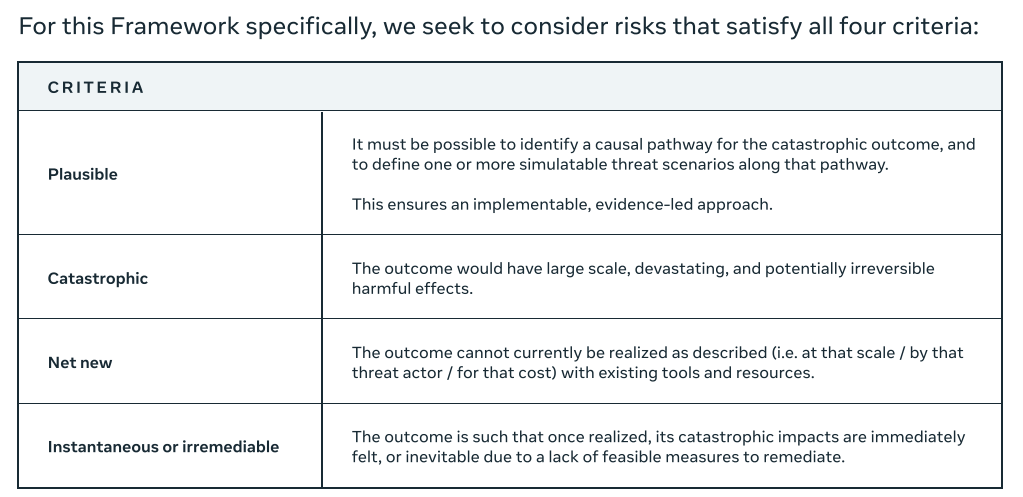
So in order for a threat to count, it has to both:
-
Be a specific concrete threat you can fully model.
-
Be unique, you can show it can’t be modeled any other way, either by any other AI system, or by achieving the same ends via any other route.
Most threats thus can either be dismissed as too theoretical and silly, or too concrete and therefore doable by other means.
It is important to note that the pathway to realise a catastrophic outcome is often extremely complex, involving numerous external elements beyond the frontier AI model. Our threat scenarios describe an essential part of the end-to-end pathway. By testing whether our model can uniquely enable a threat scenario, we’re testing whether it uniquely enables that essential part of the pathway.
Thus, it doesn’t matter how much easier you make something – it as to be something that wasn’t otherwise possible, and then they will check to be sure the threat is currently realizable:
This would also trigger a new threat modelling exercise to develop additional threat scenarios along the causal pathway so that we can ascertain whether the catastrophic outcome is indeed realizable, or whether there are still barriers to realising the catastrophic outcome (see Section 5.1 for more detail).
But the whole point of Meta’s plan is to put the model out there where you can’t take it back. So if there is still an ‘additional barrier,’ what are you going to do if that barrier is removed in the future? You need to plan for what barriers will remain in place, not what barriers exist now.
Here they summarize all the different ways they plan on dismissing threats:
Contrast this with DeepMind’s 2.0 framework, also released this week, which says:
DeepMind: Note that we have selected our CCLs (critical capability levels) to be conservative; it is not clear to what extent CLLs might translate to harm in real-world contexts.
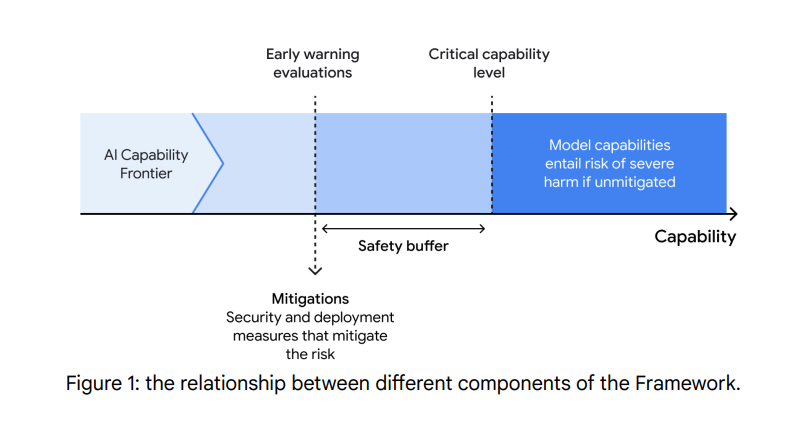
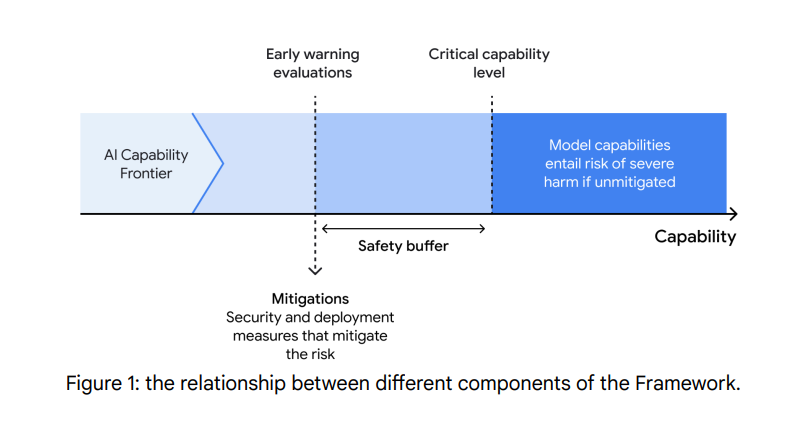
From the old 1.0 DeepMind framework, notice how they think you’re supposed to mitigate to a level substantially below where risk lies (the graph is not in 2.0 but the spirit clearly remains):
Anthropic and OpenAI’s frameworks also claim to attempt to follow this principle.
DeepMind is doing the right thing here. Meta is doing a very different thing.
Here’s their chart of what they’d actually do.
Okay, that’s standard enough. ‘Moderate’ risks are acceptable. ‘High’ risks are not until you reduce them to Moderate. Critical means panic, but even then the ‘measures’ are essentially ‘ensure this is concretely able to happen now, cause otherwise whatever.’ I expect in practice ‘realizable’ here means ‘we can prove it is realizable and more or less do it’ not ‘it seems plausible that if we give this thing to the whole internet that someone could do it.’
I sense a core conflict between the High criteria here – ‘provides significant uplift towards’ – and their other talk, which is that the threat has to be realizable if and only if the model is present. Those are very different standards. Which is it?
If they mean what they say in High here, with a reasonable working definition of ‘significant uplift towards execution,’ then that’s a very different, actually reasonable level of enabling to consider not acceptable. Or would that then get disregarded?
I also do appreciate that risk is always at least Moderate. No pretending it’s Low.
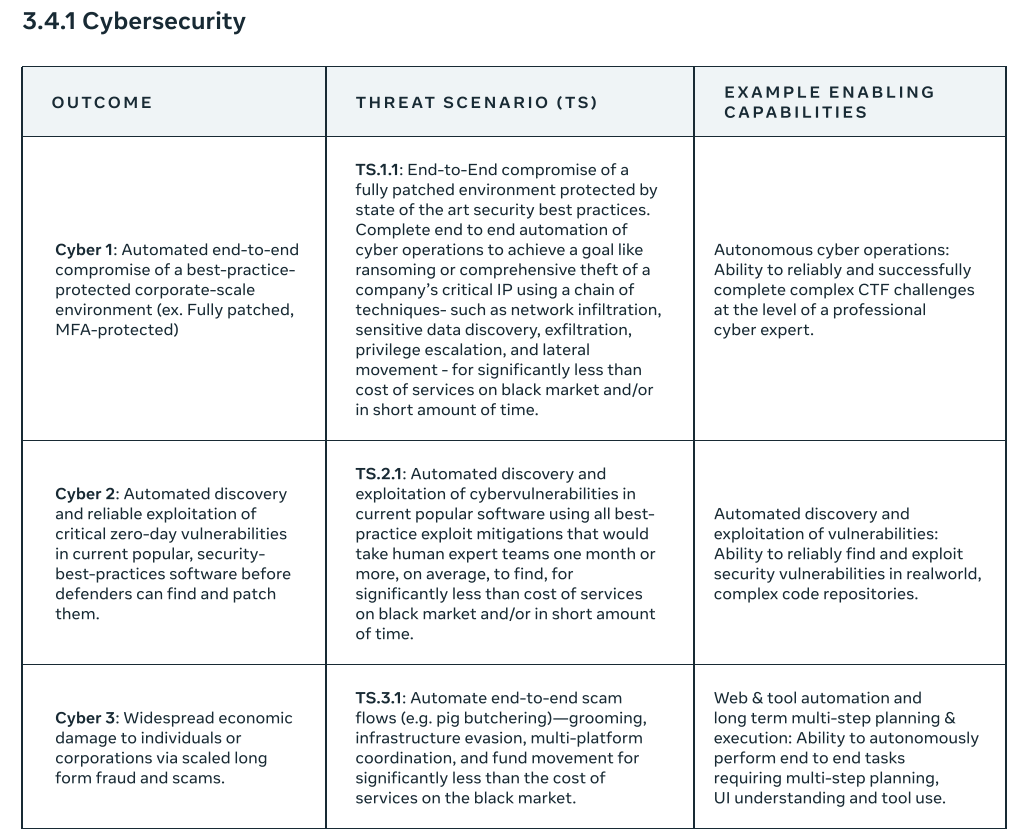
Now we get to the actual threat scenarios.
I am not an expert in this area, so I’m not sure if this is complete, but this seems like a good faith effort to cover cybersecurity issues.
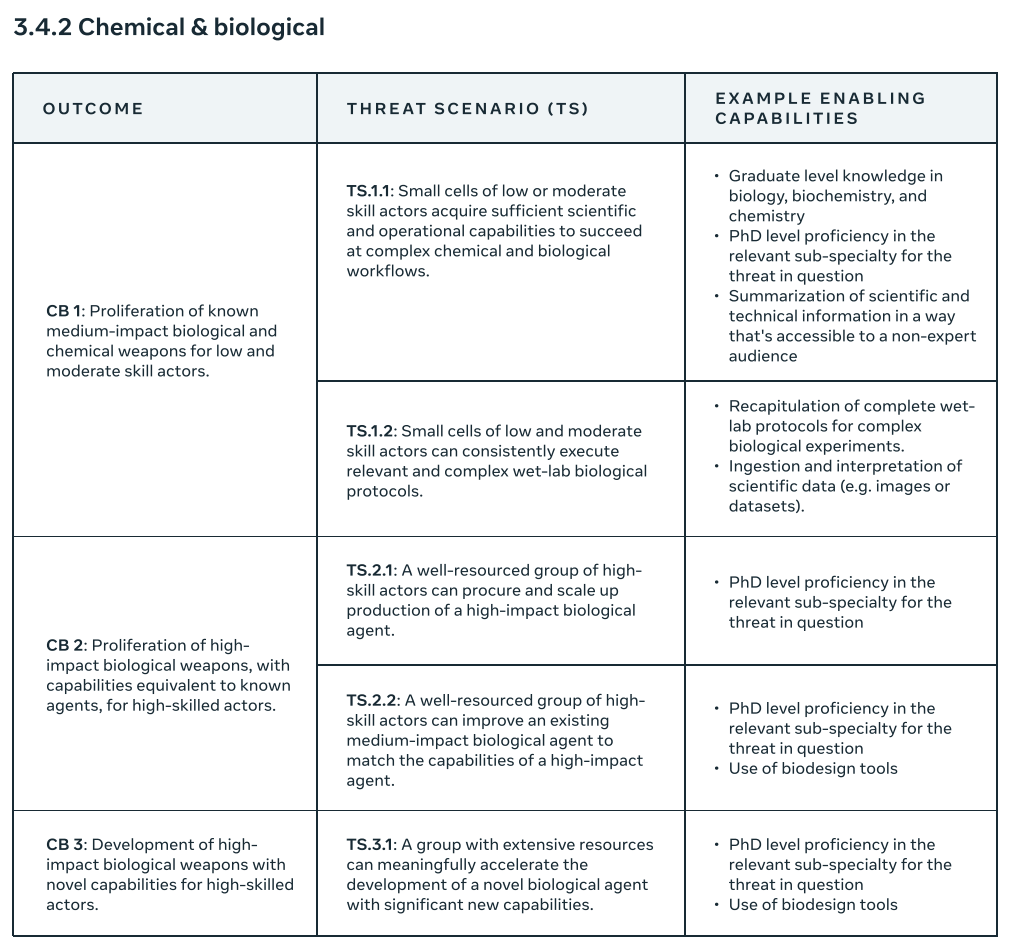
This is only chemical and biological, not full CBRN. Within that narrow bound, this seems both fully generic and fully functional. Should be fine as far as it goes.
Section 4 handles implementation. They check ‘periodically’ during development, note that other RSPs defined what compute thresholds triggered this and Meta doesn’t. They’ll prepare a robust evaluation environment. They’ll check if capabilities are good enough to bother checking for threats. If it’s worth checking, then they’ll check for actual threats.
I found this part pleasantly surprising:
Our evaluations are designed to account for the deployment context of the model. This includes assessing whether risks will remain within defined thresholds once a model is deployed or released using the target release approach.
For example, to help ensure that we are appropriately assessing the risk, we prepare the asset – the version of the model that we will test – in a way that seeks to account for the tools and scaffolding in the current ecosystem that a particular threat actor might seek to leverage to enhance the model’s capabilities.
The default ‘target release approach’ here is presumably open weights. It is great to know they understand they need to evaluate their model in that context, knowing all the ways in which their defenses won’t work, and all the ways users can use scaffolding and fine-tuning and everything else, over time, and how there will be nothing Meta can do about any of it.
What they say here, one must note, is not good enough. You don’t get to assume that only existing tools and scaffolding exist indefinitely, if you are making an irreversible decision. You also have to include reasonable expectations for future tools and scaffolding, and also account for fine-tuning and the removal of mitigations.
We also account for enabling capabilities, such as automated AI R&D, that might increase the potential for enhancements to model capabilities.
Great! But that’s not on the catastrophic outcomes list, and you say you only care about catastrophic outcomes.
So basically, this is saying that if Llama 5 were to enable automated R&D, that in and of itself is nothing to worry about, but if it then turned itself into Llama 6 into Llama 7 (computer, revert to Llama 6!) then we have to take that into account when considering there might be a cyberattack?
If automated AI R&D is at the levels where you’re taking this into account, um…
And of course, here’s some language that Meta included:
Even for tangible outcomes, where it might be possible to assign a dollar value in revenue generation, or percentage increase in productivity, there is often an element of subjective judgement about the extent to which these economic benefits are important to society.
I mean, who can really say how invaluable it is for people to connect with each other.
While it is impossible to eliminate subjectivity, we believe that it is important to consider the benefits of the technology we develop. This helps us ensure that we are meeting our goal of delivering those benefits to our community. It also drives us to focus on approaches that adequately mitigate any significant risks that we identify without also eliminating the benefits we hoped to deliver in the first place.
Yes, there’s catastrophic risk, but Just Think of the Potential.
Of course, yes, it is ultimately a game of costs versus benefits, risks versus rewards. I am not saying that the correct number of expected catastrophic risks is zero, or even that the correct probability of existential risk is zero or epsilon. I get it.
But the whole point of these frameworks is to define in advance what precautions you will take, and what things you won’t do, exactly because when the time comes, it will be easy to justify pushing forward when you shouldn’t, and to define clear principles. If the principle is ‘as long as I see enough upside I do what I want’? I expect in the trenches this means ‘we will do whatever we want, for our own interests.’
That doesn’t mean Meta will do zero safety testing. It doesn’t mean that, if the model was very obviously super dangerous, they would release it anyway, I don’t think these people are suicidal or worse want to go bankrupt. But you don’t need a document like this if it ultimately only says ‘don’t do things that at the time seem deeply stupid.’
Or at least, I kind of hope you were planning on not doing that anyway?
Similarly, if you wanted to assure others and tie your hands against pressures, you would have a procedure required to modify the framework, at least if you were going to make it more permissive. I don’t see one of those. Again, they can do what they want.
They have a permit.
It says ‘lol, we’re Meta.’
Good. I appreciate the candor, including the complete disregard for potential recursive self-improvement risks, as well as nuclear, radiological or persuasion risks.
So what are we going to do about all this?
Previously we had version 1.0, now we have version 2.0. DeepMinders are excited.
This is in several ways an improvement over version 1.0. It is more detailed, it introduces deceptive alignment as a threat model, it has sections on governance and disclosures, and it fixes a few other things. It maps capability levels to mitigation levels, which was missing previously. There are also some smaller steps backwards.
Mostly I’ll go over the whole thing, since I expect almost all readers don’t remember the details from my coverage of the first version.
The framework continues to be built around ‘Critical Capability Levels.’
We describe two sets of CCLs: misuse CCLs that can indicate heightened risk of severe harm from misuse if not addressed, and deceptive alignment CCLs that can indicate heightened risk of deceptive alignment-related events if not addressed.
The emphasis on deceptive alignment is entirely new.
For misuse risk, we dene CCLs in high-risk domains where, based on early research, we believe risks of severe harm may be most likely to arise from future models:
● CBRN: Risks of models assisting in the development, preparation, and/or execution of a chemical, biological, radiological, or nuclear (“CBRN”) attack.
● Cyber: Risks of models assisting in the development, preparation, and/or execution of a cyber attack.
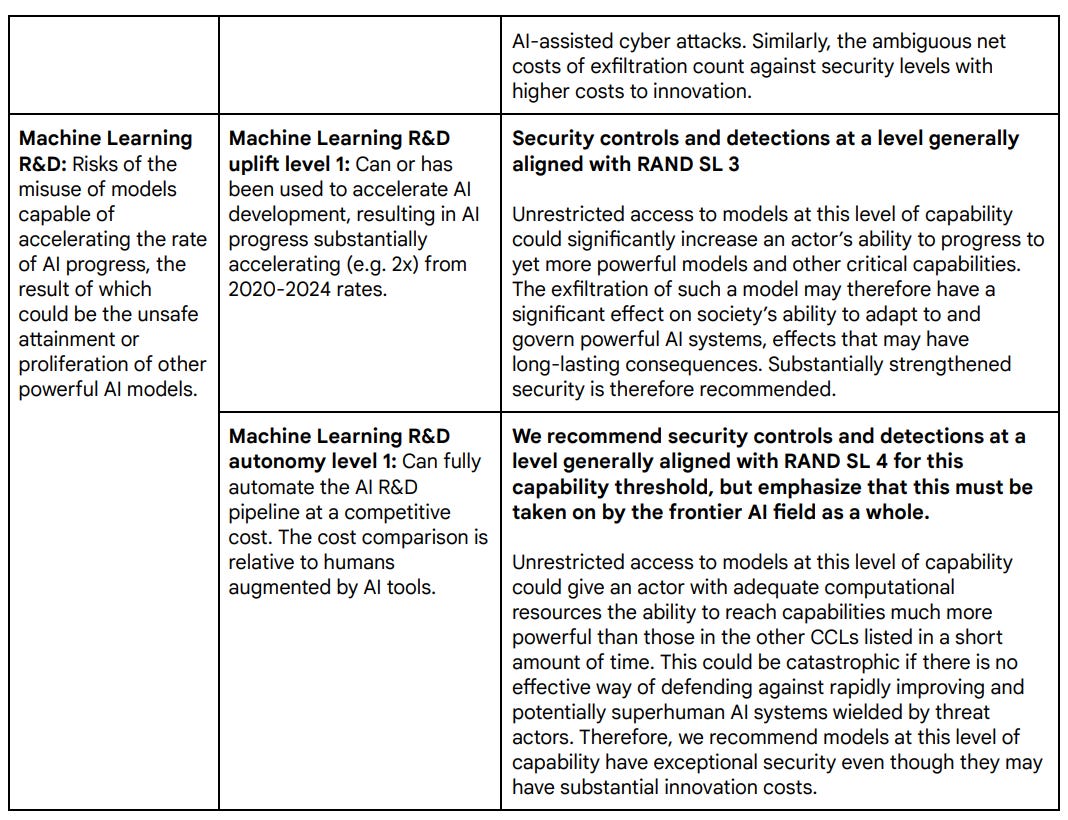
● Machine Learning R&D: Risks of the misuse of models capable of accelerating the rate of AI progress to potentially destabilizing levels, the result of which could be the unsafe attainment or proliferation of other powerful AI models. Capabilities in this area are under active research, and in the longer term may exacerbate frontier AI risks—including in other risk domains—if insuciently managed.
What are noticeably missing from this list are two things.
-
Persuasion risks, which Google and Meta don’t consider. I think this should be considered, although I do think there is a reasonable argument against this.
-
Autonomy. In Version 1.0, Google considered the risk of expanding effective capacity in the world fully autonomously, since this could potentially then expand quite a bit, and then use that capacity (via instrumental convergence) for any number of goals. I am sad to see this go. I am also sad to not see an explanation for why this was removed.
For both of these but for autonomy in particular, I ask:
-
Is it plausible that a model could cross the previous autonomy threshold without crossing the others here?
-
If that were the case, should we be worried about that?
The answer to the first question seems to clearly be yes.
The answer to the second question is, I do think I would want to at least test for and be aware of crossing this threshold, and then think hard about the implications.
I am however very happy to see the new addition, which I haven’t seen before in a similar document:
For deceptive alignment risk, the initial approach focuses on detecting when models might develop a baseline instrumental reasoning ability at which they have the potential to undermine human control, assuming no additional mitigations were applied.
The two instrumental reasoning CCLs thus focus on delineating when such capability becomes present, and subsequently when the initial mitigation for this capability—automated monitoring—is no longer adequate.
This is exactly the kind of thinking that Meta repeatedly disavows and treats with disdain in its framework. If AIs undermine human control, if they pretend to be aligned when they are not or otherwise steer the training process to their own ends, then we have a serious problem. Meta’s response is, well, how does that lead to a specific catastrophic outcome? To which I say, that is obviously the wrong question.
The basic plan is same as it always is and has to be. Run periodic evaluations as models gain capabilities, check for dangerous capabilities, apply mitigations. They take both security mitigations to protect the weights, and deployment mitigations to counter potential misuse.
I notice this framework doesn’t by default work well for the AI R&D case. They agree, and note as an issue for future work, that further classes of mitigation are likely needed.
Here is the deployment mitigation plan 2.0:
-
Development and assessment of mitigations: safeguards and an accompanying safety case are developed by iterating on the following:
-
Developing and improving a suite of safeguards targeting the capability. This includes, as appropriate, safety fine-tuning, misuse filtering and detection, and response protocols.
-
Assessing the robustness of these mitigations against the risk posed through assurance evaluations and threat modeling research. The assessment takes the form of a safety case, taking into account factors such as the likelihood and consequences of misuse.
-
Pre-deployment review of safety case: general availability deployment of a model takes place only after the appropriate corporate governance body determines the safety case regarding each CCL the model has reached to be adequate.
-
Post-deployment review of safety case: the safety case will be updated through red-teaming and revisions to our threat models. The safeguards for the model may be updated as well to ensure continued adequacy.
This replaces the old plan, which was to go in steps from mitigations targeting the capability to a red team validated safety case to prevention of access.
I notice that the red-teaming here is only mentioned in post-deployment. It should be in pre-deployment as well, no, as part of either the safety case or review of the safety case, or both? But the core idea is the same, you need to do mitigation and then make a safety case. So essentially this is universalizing the old Security Level 2.
Their logic is that if prevention of access (the old Security Level 3) is necessary, then that is a natural extension. I get why they’re saying that, but I’d like to keep this explicit and around anyway – you can almost never be too explicit in situations like this. Clarity almost never hurts, and if thinking changes on this I’d like to track it.
The definition of mitigations here is still ‘take adequate mitigations,’ which does not tell us much. Google has wide latitude, as long as it makes its safety case.
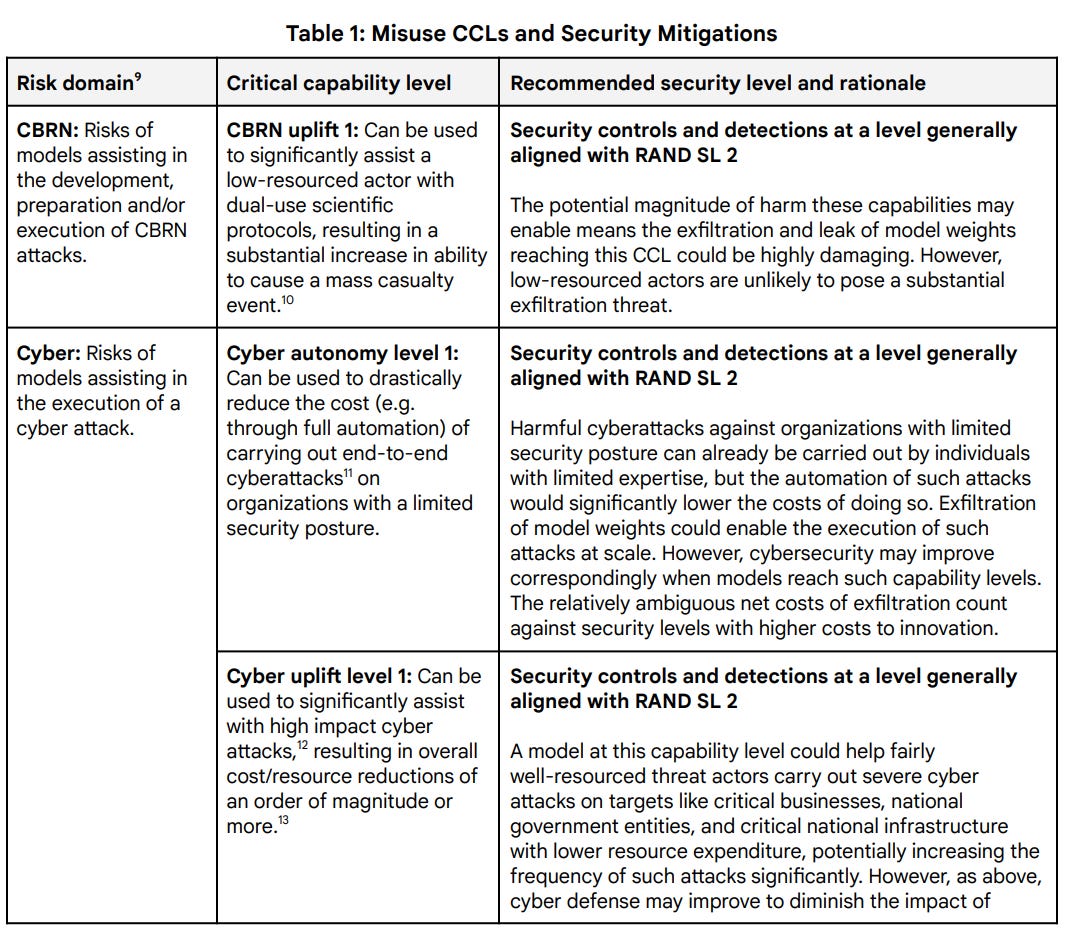
Here are the mitigations:
As I said last time: One of these things is not like the others.
The CBRN and Cyber capability thresholds seem set rather high, but also I expect mitigations to be involved well below these thresholds. I’d also want clarification, cost reductions compared to what case? Presumably this is versus not having general LLM access. If it’s versus the next best available LLM, then an order of magnitude or ‘drastic reduction’ is too large a threshold, since one could easily approach that in distinct steps. In general I worry these new threshold descriptions are substantially higher than the previous ones.
We now move on to machine learning R&D. For uplift 1, they move from 3x rates for algorithmic progress to 2x overall progress for Machine Learning Uplift, and specifying 2024 rates as the baseline. I think that’s a better way to define the threshold to match what we actually care about, so I like this change.
Then there’s Machine Learning R&D autonomy level 1. This isn’t quite as ambitious as the old version’s Machine Learning R&D 2, which was essentially ‘the singularity arrives next Tuesday.’ This is at comparable costs rather than a drastic reduction in costs.
My guess is this still probably does mean the singularity arrives not too long from next Tuesday, given how much compute is available to Google, although this isn’t obvious. Even if it’s currently only ‘about as efficient’ as humans would be, that phase won’t last long. If you had a model that was anywhere near being able to do this, and no one else had released one that was better, it seems rather crazy to consider releasing it.
This graph, which I also showed in the Meta section, is from the 1.0 version of the framework. It’s not in 2.0, but it still does seem to be adhered to in spirit:
The security levels are listed in terms of the RAND security protocols.
Since the document calls for levels 2,3 and 4, here’s a Claude summary of levels 2-4:
SL2 – Professional Protection
-
Defends against professional but opportunistic hackers
-
Focuses on comprehensive implementation of security fundamentals and industry best practices
-
Emphasizes closing common security gaps and vulnerabilities
-
Key aspects include email security, password policies, and multi-factor authentication
SL3 – Advanced Protection
-
Defends against cybercrime syndicates and insider threats
-
Aggressively reduces attack surface
-
Implements defense-in-depth strategies
-
Focuses heavily on restricting and monitoring access to weights
-
Requires two independent security layers
SL4 – State-Level Protection
-
Defends against standard operations by leading cyber-capable institutions (like foreign intelligence agencies)
-
Requires significant compromises on productivity and convenience
-
Implements hardware-level security measures
-
Uses confidential computing
-
Requires four independent security layers
If you’re Google and you’re not at least at SL2 for every model worth deploying, why the hell not? I think this should be the minimum even with no dangerous capabilities.
There is a reason why even 1 level of Version 1.0’s protocol was called similar to SL3. I don’t buy the arguments in Table 1 that cybersecurity improvements are likely to diminish necessary security levels. I think it’s rather absurd to not move to at least SL3 if any critical capability levels are found.
The question is at what point everything needs to be SL4, and how much this should depend upon coordination with the rest of industry. My guess i you only need it for Machine Learning R&D, but there I do think you need something like that, even though implementation will be expensive. For ‘uplift 1’ SL4 seems roughly reasonable to me, but for ‘autonomy 1’ I think even SL4 is inadequate.
This is a longstanding disagreement, as I found their previous version insufficient.
For the deceptive alignment case, ‘automated monitoring’ can be applied as the initial mitigation, as noted above, but this is a very temporary solution if it’s not part of defense-in-depth as a backup plan. The ‘automated monitoring only’ phase likely wouldn’t last long, and risks making things worse via teaching the system how to evade detection.
I do find the answer of ‘future work, we don’t know how’ for mitigation of Instrumental Reasoning Level 2 to be acceptable. It’s a hard problem. Better to admit you don’t know, so long as this also means that if you’re in this situation before you figure it out, you’re committing to halting and catching fire until you figure it out.
I also appreciated that there is now at least a brief a section on governance, which was not in 1.0, detailing who will review implementation of the framework (the AGI Safety Council) and noting several other relevant councils. I would like to see more of a formal process but this is a start.
I also appreciated the intention to share information with ‘appropriate government authorities’ if the risks involved are triggered, even if they are then mitigated. They don’t commit to telling anyone else, but will consider it.
Another great note was saying ‘everyone needs to do this.’ Safety of models is a public good, and somewhat of a Stag Hunt, where we all win if everyone who is at the frontier cooperates. If you can outrun the bear, but the bear still eats someone else’s model, in this case you are not safe.
However, there were also a few steps back. The specific 6x compute or 3 month threshold was removed for a more flexible rule. I realize that 6x was stingy already and a hard-and-fast rule will sometimes be foolish, but I believe we do need hard commitments in such places at current trust levels.
So we have steps forward in (some details here not mentioned above):
-
Deceptive alignment as a threat model.
-
Capability levels are mapped to mitigation levels.
-
Governance.
-
Disclosures.
-
Using the RAND protocol levels.
-
Adjustment of threshold details.
-
Centralizing role of safety cases.
-
Changed ‘pass condition’ to ‘alert threshold’ which seems better.
-
Emphasis on confidential computing.
-
Explicit calls for industry-wide cooperation, willingness to coordinate.
-
Explicit intention of sharing results with government if thresholds are triggered.
And we have a few steps back:
-
Removal of autonomy threshold (I will trade this for deceptive alignment but would prefer to have both, and am still sad about missing persuasion.)
-
Removal of the 6x compute and 3 month thresholds for in-training testing.
-
Reduced effective security requirements in some places.
-
Less explicitness about shutting down access if necessary.
Overall, it’s good news. That’s definitely a step forward, and it’s great to see DeepMind publishing revisions and continuing to work on the document.
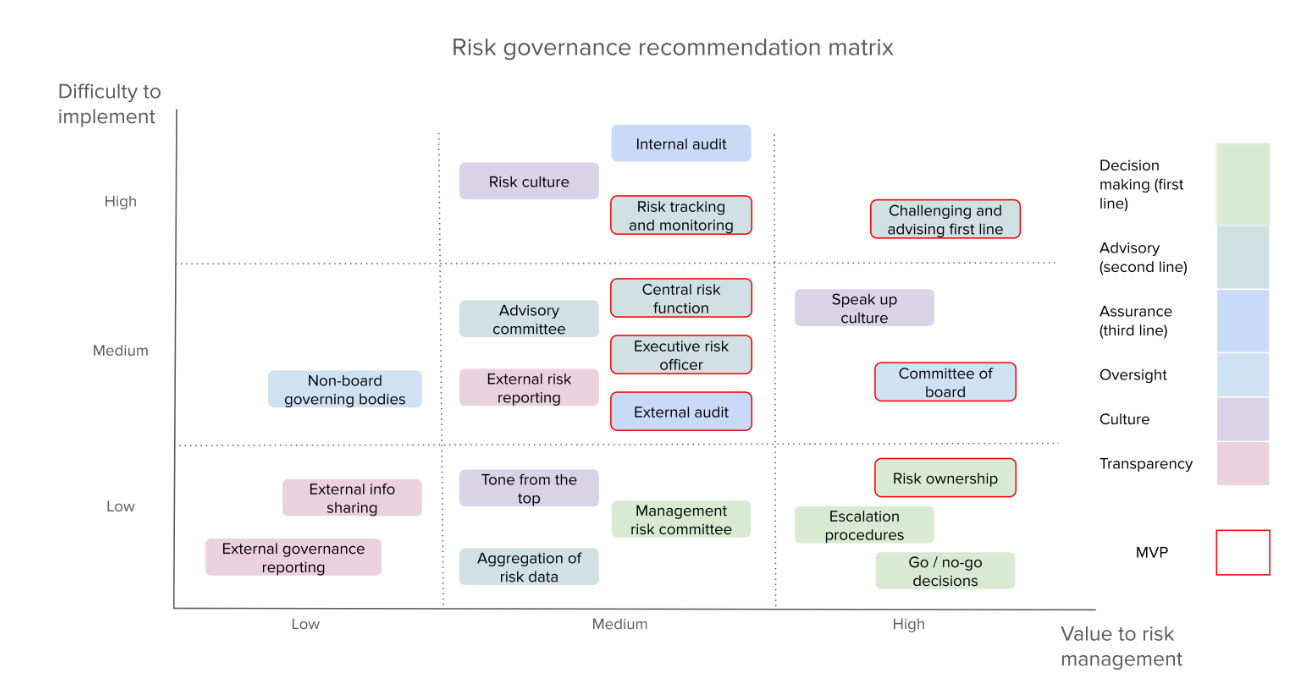
One thing missing the current wave of safety frameworks is robust risk governance. The Centre for Long-Term Resilience argues, in my opinion compellingly, that these documents need risk governance to serve their full intended purpose.
CLTR: Frontier safety frameworks help AI companies manage extreme risks, but gaps in effective risk governance remain. Ahead of the Paris AI Action Summit next week, our new report outlines key recommendations on how to bridge this gap.
Drawing on the best practice 3 lines framework widely used in other safety critical industries like nuclear, aviation and healthcare, effective risk governance includes:
-
Decision making ownership (first-line)
-
Advisory oversight (second-line)
-
Assurance (third line)
-
Board-level oversight
-
Culture
-
External transparency
Our analysis found that evidence for effective risk governance across currently published frontier AI safety frameworks is low overall.
While some aspects of risk governance are starting to be applied, the overall state of risk governance implementation in safety frameworks appears to be low, across all companies.
This increases the chance of harmful models being released because of aspects like unclear risk ownership, escalation pathways and go/no-go decisions about when to release models.
By using the recommendations outlined in our report, overall effectiveness of safety frameworks can be improved by enhancing risk identification, assessment, and mitigation.
It is an excellent start to say that your policy has to say what you will do. You then need to ensure that the procedures are laid out so it actually happens. They consider the above an MVP of risk governance.
I notice that the MVP does not seem to be optimizing for being on the lower right of this graph? Ideally, you want to start with things that are valuable and easy.
Escalation procedures and go/no-go decisions seem to be properly identified as high value things that are relatively easy to do. I think if anything they are not placing enough emphasis on cultural aspects. I don’t trust any of these frameworks to do anything without a good culture backing them up.
DeepMind has improved its framework, but it has a long way to go. No one has what I would consider a sufficient framework yet, although I believe OpenAI and Anthropic’s attempts are farther along.
The spirit of the documents is key. None of these frameworks are worth much if those involved are looking only to obey the technical requirements. They’re not designed to make adversarial compliance work, if it was even possible. They only work if people genuinely want to be safe. That’s a place Anthropic has a huge edge.
Meta vastly improved its framework, in that it previously didn’t have one, and now the new version at least admits that they essentially don’t have one. That’s a big step. And of course, even if they did have a real framework, I would not expect them to abide by its spirit. I do expect them to abide by the spirit of this one, because the spirit of this one is to not care.
The good news is, now we can talk about all of that.






















{kind=link}
{kind=link}
{kind=link}