
We’re about to find many more interstellar interlopers—here’s how to visit one
“You don’t have to claim that they’re aliens to make these exciting.”

The Hubble Space Telescope captured this image of the interstellar comet 3I/ATLAS on July 21, when the comet was 277 million miles from Earth. Hubble shows that the comet has a teardrop-shaped cocoon of dust coming off its solid, icy nucleus. Credit: NASA, ESA, David Jewitt (UCLA); Image Processing: Joseph DePasquale (STScI)
The Hubble Space Telescope captured this image of the interstellar comet 3I/ATLAS on July 21, when the comet was 277 million miles from Earth. Hubble shows that the comet has a teardrop-shaped cocoon of dust coming off its solid, icy nucleus. Credit: NASA, ESA, David Jewitt (UCLA); Image Processing: Joseph DePasquale (STScI)
A few days ago, an inscrutable interstellar interloper made its closest approach to Mars, where a fleet of international spacecraft seek to unravel the red planet’s ancient mysteries.
Several of the probes encircling Mars took a break from their usual activities and turned their cameras toward space to catch a glimpse of an object named 3I/ATLAS, a rogue comet that arrived in our Solar System from interstellar space and is now barreling toward perihelion—its closest approach to the Sun—at the end of this month.
This is the third interstellar object astronomers have detected within our Solar System, following 1I/ʻOumuamua and 2I/Borisov discovered in 2017 and 2019. Scientists think interstellar objects routinely transit among the planets, but telescopes have only recently had the ability to find one. For example, the telescope that discovered Oumuamua only came online in 2010.
Detectable but still unreachable
Astronomers first reported observations of 3I/ATLAS on July 1, just four months before reaching its deepest penetration into the Solar System. Unfortunately for astronomers, the particulars of this object’s trajectory will bring it to perihelion when the Earth is on the opposite side of the Sun. The nearest 3I/ATLAS will come to Earth is about 170 million miles (270 million kilometers) in December, eliminating any chance for high-resolution imaging. The viewing geometry also means the Sun’s glare will block all direct views of the comet from Earth until next month.
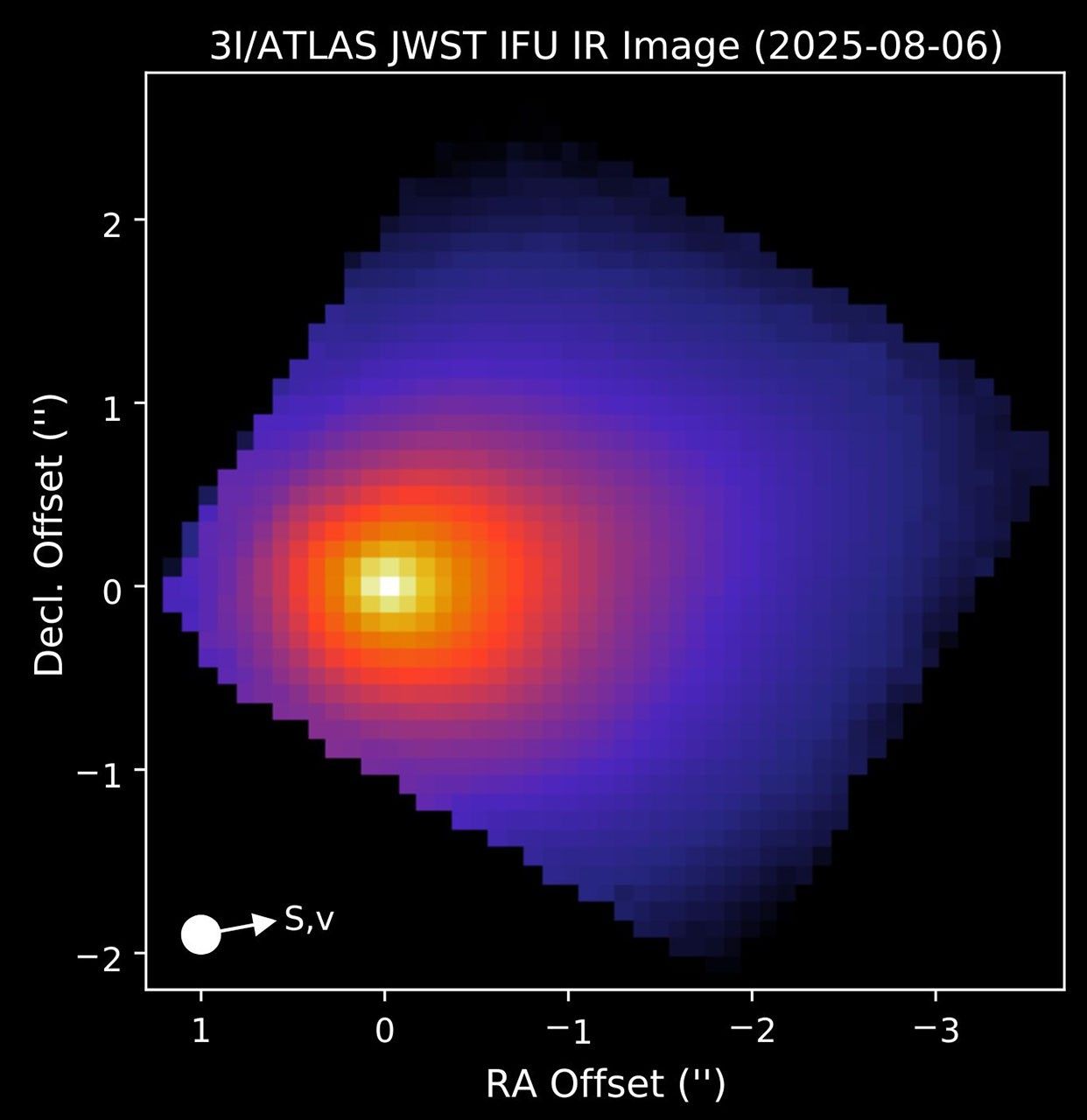
The James Webb Space Telescope observed interstellar comet 3I/ATLAS on August 6 with its Near-Infrared Spectrograph instrument. Credit: NASA/James Webb Space Telescope
Because of that, the closest any active spacecraft will get to 3I/ATLAS happened Friday, when it passed less than 20 million miles (30 million kilometers) from Mars. NASA’s Perseverance rover and Mars Reconnaissance Orbiter were expected to make observations of 3I/ATLAS, along with Europe’s Mars Express and ExoMars Trace Gas Orbiter missions.
The best views of the object so far have been captured by the James Webb Space Telescope and the Hubble Space Telescope, positioned much closer to Earth. Those observations helped astronomers narrow down the object’s size, but the estimates remain imprecise. Based on Hubble’s images, the icy core of 3I/ATLAS is somewhere between the size of the Empire State Building to something a little larger than Central Park.
That may be the most we’ll ever know about the dimensions of 3I/ATLAS. The spacecraft at Mars lack the exquisite imaging sensitivity of Webb and Hubble, so don’t expect spectacular views from Friday’s observations. But scientists hope to get a better handle on the cloud of gas and dust surrounding the object, giving it the appearance of a comet. Spectroscopic observations have shown the coma around 3I/ATLAS contains water vapor and an unusually strong signature of carbon dioxide extending out nearly a half-million miles.
On Tuesday, the European Space Agency released the first grainy images of 3I/ATLAS captured at Mars. The best views will come from a small telescope called HiRISE on NASA’s Mars Reconnaissance Orbiter. The images from NASA won’t be released until after the end of the ongoing federal government shutdown, according to a member of the HiRISE team.

Europe’s ExoMars Trace Gas Orbiter turned its eyes toward interstellar comet 3I/ATLAS as it passed close to Mars on Friday, October 3. The comet’s coma is visible as a fuzzy blob surrounding its nucleus, which was not resolved by the spacecraft’s camera. Credit: ESA/TGO/CaSSIS
Studies of 3I/ATLAS suggest it was probably kicked out of another star system, perhaps by an encounter with a giant planet. Comets in our Solar System sometimes get ejected into the Milky Way galaxy when they come too close to Jupiter. It roamed the galaxy for billions of years before arriving in the Sun’s galactic neighborhood.
The rogue comet is now gaining speed as gravity pulls it toward perihelion, when it will max out at a relative velocity of 152,000 mph (68 kilometers per second), much too fast to be bound into a closed orbit around the Sun. Instead, the comet will catapult back into the galaxy, never to be seen again.
We need to talk about aliens
Anyone who studies planetary formation would relish the opportunity to get a close-up look at an interstellar object. Sending a mission to one would undoubtedly yield a scientific payoff. There’s a good chance that many of these interlopers have been around longer than our own 4.5 billion-year-old Solar System.
One study from the University of Oxford suggests that 3I/ATLAS came from the “thick disk” of the Milky Way, which is home to a dense population of ancient stars. This origin story would mean the comet is probably more than 7 billion years old, holding clues about cosmic history that are simply inaccessible among the planets, comets, and asteroids that formed with the birth of the Sun.
This is enough reason to mount a mission to explore one of these objects, scientists said. It doesn’t need justification from unfounded theories that 3I/ATLAS might be an artifact of alien technology, as proposed by Harvard University astrophysicist Avi Loeb. The scientific consensus is that the object is of natural origin.
Loeb shared a similar theory about the first interstellar object found wandering through our Solar System. His statements have sparked questions in popular media about why the world’s space agencies don’t send a probe to actually visit one. Loeb himself proposed redirecting NASA’s Juno spacecraft in orbit around Jupiter on a mission to fly by 3I/ATLAS, and his writings prompted at least one member of Congress to write a letter to NASA to “rejuvenate” the Juno mission by breaking out of Jupiter’s orbit and taking aim at 3I/ATLAS for a close-up inspection.
The problem is that Juno simply doesn’t have enough fuel to reach the comet, and its main engine is broken. In fact, the total boost required to send Juno from Jupiter to 3I/ATLAS (roughly 5,800 mph or 2.6 kilometers per second) would surpass the fuel capacity of most interplanetary probes.
Ars asked Scott Bolton, lead scientist on the Juno mission, and he confirmed that the spacecraft lacks the oomph required for the kind of maneuvers proposed by Loeb. “We had no role in that paper,” Bolton told Ars. “He assumed propellant that we don’t really have.”

Avi Loeb, a Harvard University astrophysicist. Credit: Anibal Martel/Anadolu Agency via Getty Images
So Loeb’s exercise was moot, but his talk of aliens has garnered public attention. Loeb appeared on the conservative network Newsmax last week to discuss his theory of 3I/ATLAS alongside Rep. Tim Burchett (R-Tenn.). Predictably, conspiracy theories abounded. But as of Tuesday, the segment has 1.2 million views on YouTube. Maybe it’s a good thing that people who approve government budgets, especially those without a preexisting interest in NASA, are eager to learn more about the Universe. We will leave it to the reader to draw their own conclusions on that matter.
Loeb’s calculations also help illustrate the difficulty of pulling off a mission to an interstellar object. So far, we’ve only known about an incoming interstellar intruder a few months before it comes closest to Earth. That’s not to mention the enormous speeds at which these objects move through the Solar System. It’s just not feasible to build a spacecraft and launch it on such short notice.
Now, some scientists are working on ways to overcome these limitations.
So you’re saying there’s a chance?
One of these people is Colin Snodgrass, an astronomer and planetary scientist at the University of Edinburgh. A few years ago, he helped propose to the European Space Agency a mission concept that would have very likely been laughed out of the room a generation ago. Snodgrass and his team wanted a commitment from ESA of up to $175 million (150 million euros) to launch a mission with no idea of where it would go.
ESA officials called Snodgrass in 2019 to say the agency would fund his mission, named Comet Interceptor, for launch in the late 2020s. The goal of the mission is to perform the first detailed observations of a long-period comet. So far, spacecraft have only visited short-period comets that routinely dip into the inner part of the Solar System.
A long-period comet is an icy visitor from the farthest reaches of the Solar System that has spent little time getting blasted by the Sun’s heat and radiation, freezing its physical and chemical properties much as they were billions of years ago.
Long-period comets are typically discovered a year or two before coming near the Sun, still not enough time to develop a mission from scratch. With Comet Interceptor, ESA will launch a probe to loiter in space a million miles from Earth, wait for the right comet to come along, then fire its engines to pursue it.
Odds are good that the right comet will come from within the Solar System. “That is the point of the mission,” Snodgrass told Ars.
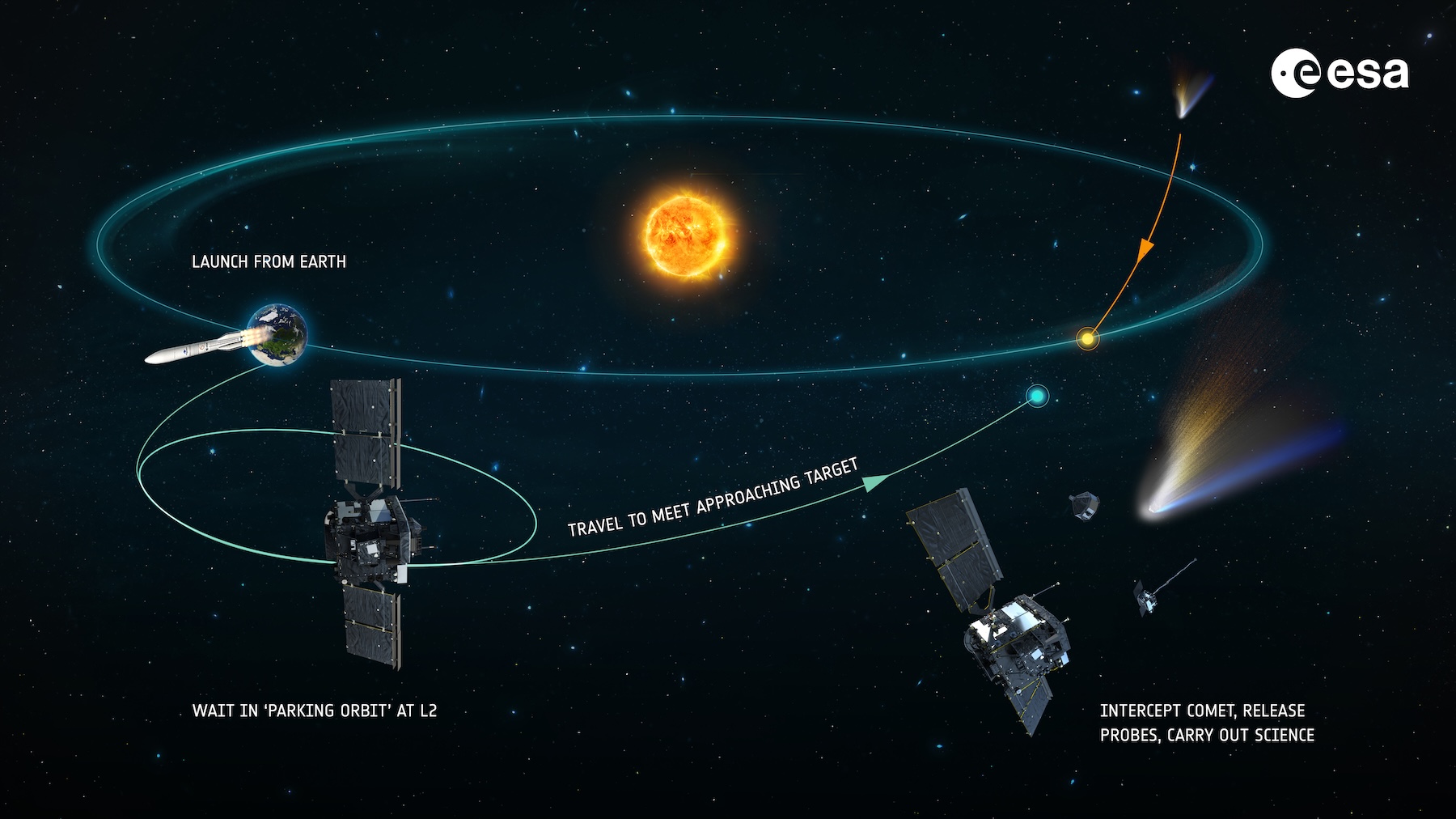
ESA’s Comet Interceptor will be the first mission to visit a comet coming directly from the outer reaches of the Sun’s realm, carrying material untouched since the dawn of the Solar System. Credit: European Space Agency
But if astronomers detect an interstellar object coming toward us on the right trajectory, there’s a chance Comet Interceptor could reach it.
“I think that the entire science team would agree, if we get really lucky and there’s an interstellar object that we could reach, then to hell with the normal plan, let’s go and do this,” Snodgrass said. “It’s an opportunity you couldn’t just leave sitting there.”
But, he added, it’s “very unlikely” that an interstellar object will be in the right place at the right time. “Although everyone’s always very excited about the possibility, and we’re excited about the possibility, we kind of try and keep the expectations to a realistic level.”
For example, if Comet Interceptor were in space today, there’s no way it could reach 3I/ATLAS. “It’s an unfortunate one,” Snodgrass said. “Its closest point to the Sun, it reaches that on the other side of the Sun from where the Earth is. Just bad timing.” If an interceptor were parked somewhere else in the Solar System, it might be able to get itself in position for an encounter with 3I/ATLAS. “There’s only so much fuel aboard,” Snodgrass said. “There’s only so fast we can go.”
It’s even harder to send a spacecraft to encounter an interstellar object than it is to visit one of the Solar System’s homegrown long-period comets. The calculation of whether Comet Interceptor could reach one of these galactic visitors boils down to where it’s heading and when astronomers discover it.
Snodgrass is part of a team using big telescopes to observe 3I/ATLAS from a distance. “As it’s getting closer to the Sun, it is getting brighter,” he said in an interview.
“You don’t have to claim that they’re aliens to make these exciting,” Snodgrass said. “They’re interesting because they are a bit of another solar system that you can actually feasibly get an up-close view of, even the sort of telescopic views we’re getting now.”

Colin Snodgrass, a professor at the University of Edinburgh, leads the Comet Interceptor science team. Credit: University of Edinburgh
Comets and asteroids are the linchpins for understanding the formation of the Solar System. These modest worlds are the leftover building blocks from the debris that coalesced into the planets. Today, direct observations have only allowed scientists to study the history of one planetary system. An interstellar comet would grow the sample size to two.
Still, Snodgrass said his team prefers to keep their energy focused on reaching a comet originating from the frontier of our own Solar System. “We’re not going to let a very lovely Solar System comet go by, waiting to see ‘what if there’s an interstellar thing?'” he said.
Snodgrass sees Comet Interceptor as a proof of concept for scientists to propose a future mission specially designed to travel to an interstellar object. “You need to figure out how do you build the souped-up version that could really get to an interstellar object? I think that’s five or 10 years away, but [it’s] entirely realistic.”
An American answer
Scientists in the United States are working on just such a proposal. A team from the Southwest Research Institute completed a concept study showing how a mission could fly by one of these interstellar visitors. What’s more, the US scientists say their proposed mission could have actually reached 3I/ATLAS had it already been in space.
The American concept is similar to Europe’s Comet Interceptor in that it will park a spacecraft somewhere in deep space and wait for the right target to come along. The study was led by Alan Stern, the chief scientist on NASA’s New Horizons mission that flew by Pluto a decade ago. “These new kinds of objects offer humankind the first feasible opportunity to closely explore bodies formed in other star systems,” he said.
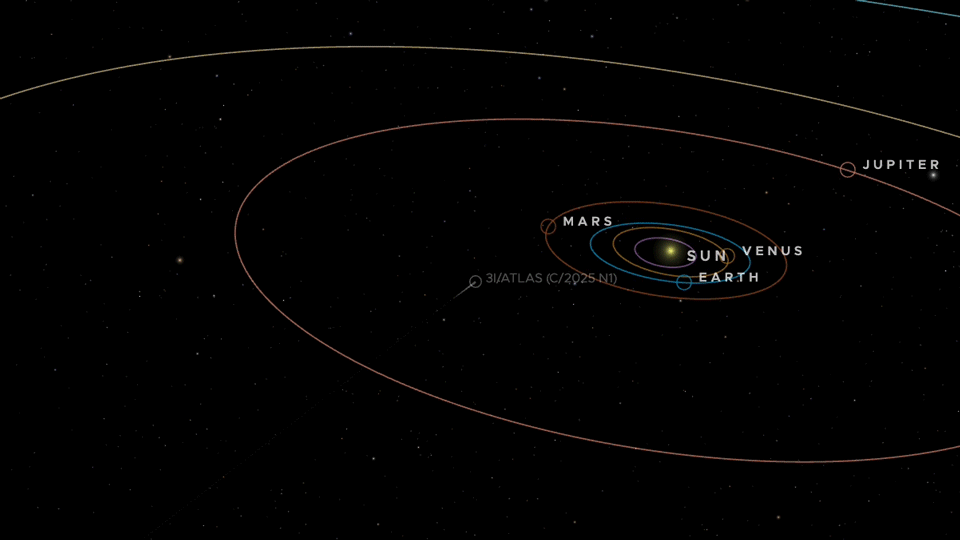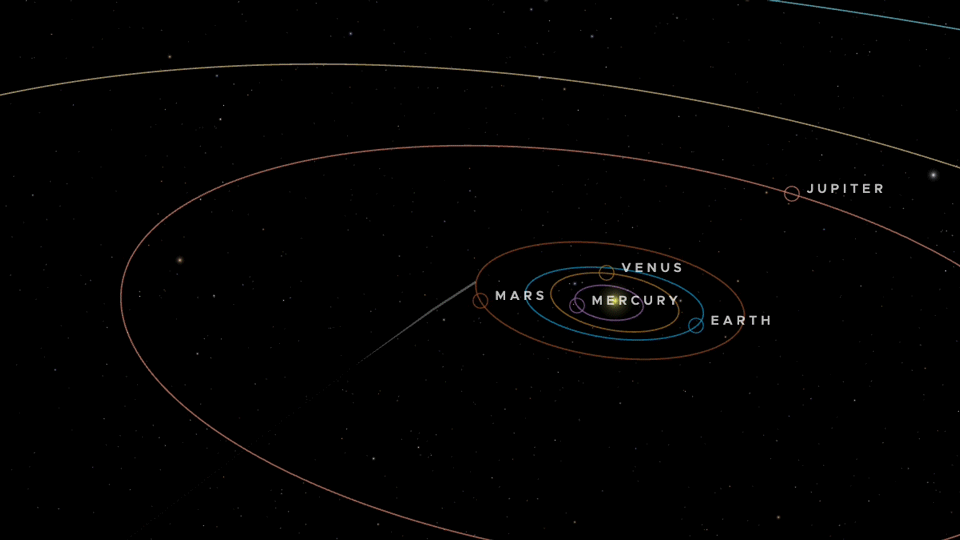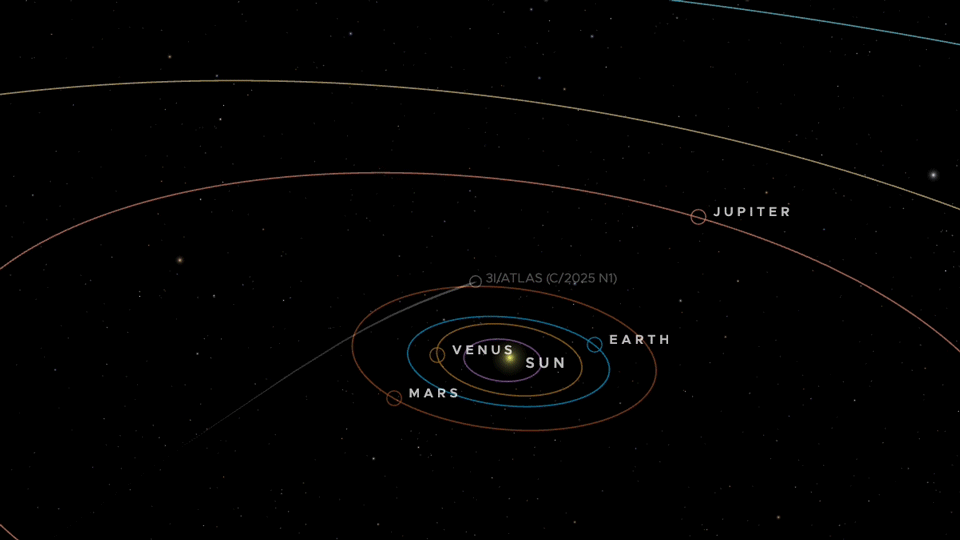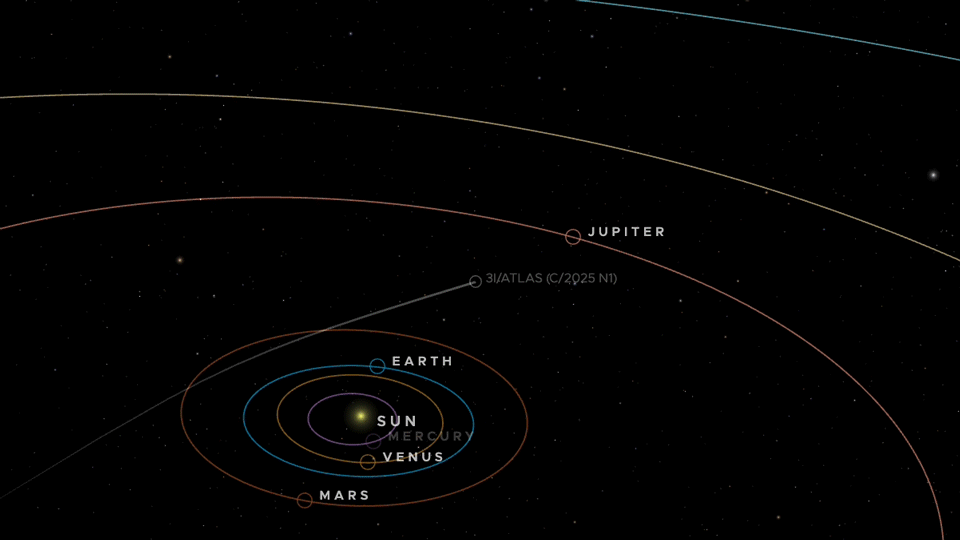
An animation of the trajectory of 3I/ATLAS through the inner Solar System. Credit: NASA/JPL
It’s impossible with current technology to send a spacecraft to match orbits and rendezvous with a high-speed interstellar comet. “We don’t have to catch it,” Stern recently told Ars. “We just have to cross its orbit. So it does carry a fair amount of fuel in order to get out of Earth’s orbit and onto the comet’s path to cross that path.”
Stern said his team developed a cost estimate for such a mission, and while he didn’t disclose the exact number, he said it would fall under NASA’s cost cap for a Discovery-class mission. The Discovery program is a line of planetary science missions that NASA selects through periodic competitions within the science community. The cost cap for NASA’s next Discovery competition is expected to be $800 million, not including the launch vehicle.
A mission to encounter an interstellar comet requires no new technologies, Stern said. Hopes for such a mission are bolstered by the activation of the US-funded Vera Rubin Observatory, a state-of-the-art facility high in the mountains of Chile set to begin deep surveys of the entire southern sky later this year. Stern predicts Rubin will discover “one or two” interstellar objects per year. The new observatory should be able to detect the faint light from incoming interstellar bodies sooner, providing missions with more advance warning.
“If we put a spacecraft like this in space for a few years, while it’s waiting, there should be five or 10 to choose from,” he said.

Alan Stern speaks onstage during Day 1 of TechCrunch Disrupt SF 2018 in San Francisco. Credit: Photo by Kimberly White/Getty Images for TechCrunch
Winning NASA funding for a mission like Stern’s concept will not be easy. It must compete with dozens of other proposals, and NASA’s next Discovery competition is probably at least two or three years away. The timing of the competition is more uncertain than usual due to swirling questions about NASA’s budget after the Trump administration announced it wants to cut the agency’s science funding in half.
Comet Interceptor, on the other hand, is already funded in Europe. ESA has become a pioneer in comet exploration. The Giotto probe flew by Halley’s Comet in 1986, becoming the first spacecraft to make close-up observations of a comet. ESA’s Rosetta mission became the first spacecraft to orbit a comet in 2014, and later that year, it deployed a German-built lander to return the first data from the surface of a comet. Both of those missions explored short-period comets.
“Each time that ESA has done a comet mission, it’s done something very ambitious and very new,” Snodgrass said. “The Giotto mission was the first time ESA really tried to do anything interplanetary… And then, Rosetta, putting this thing in orbit and landing on a comet was a crazy difficult thing to attempt to do.”
“They really do push the envelope a bit, which is good because ESA can be quite risk averse, I think it’s fair to say, with what they do with missions,” he said. “But the comet missions, they are things where they’ve really gone for that next step, and Comet Interceptor is the same. The whole idea of trying to design a space mission before you know where you’re going is a slightly crazy way of doing things. But it’s the only way to do this mission. And it’s great that we’re trying it.”

Stephen Clark is a space reporter at Ars Technica, covering private space companies and the world’s space agencies. Stephen writes about the nexus of technology, science, policy, and business on and off the planet.
We’re about to find many more interstellar interlopers—here’s how to visit one Read More »













































{kind=link}