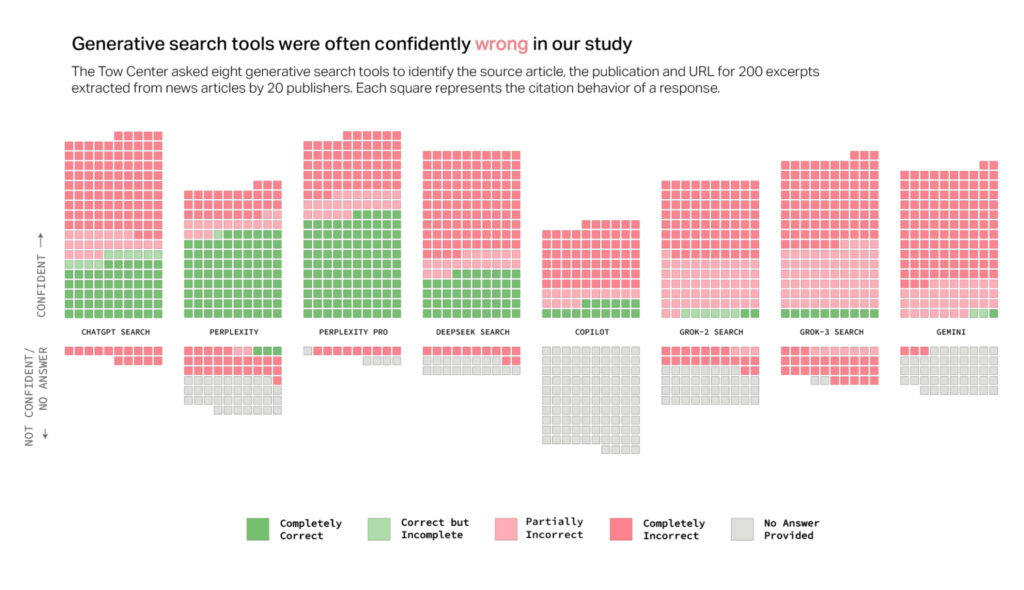
Gemini gets new coding and writing tools, plus AI-generated “podcasts”
On the heels of its release of new Gemini models last week, Google has announced a pair of new features for its flagship AI product. Starting today, Gemini has a new Canvas feature that lets you draft, edit, and refine documents or code. Gemini is also getting Audio Overviews, a neat capability that first appeared in the company’s NotebookLM product, but it’s getting even more useful as part of Gemini.
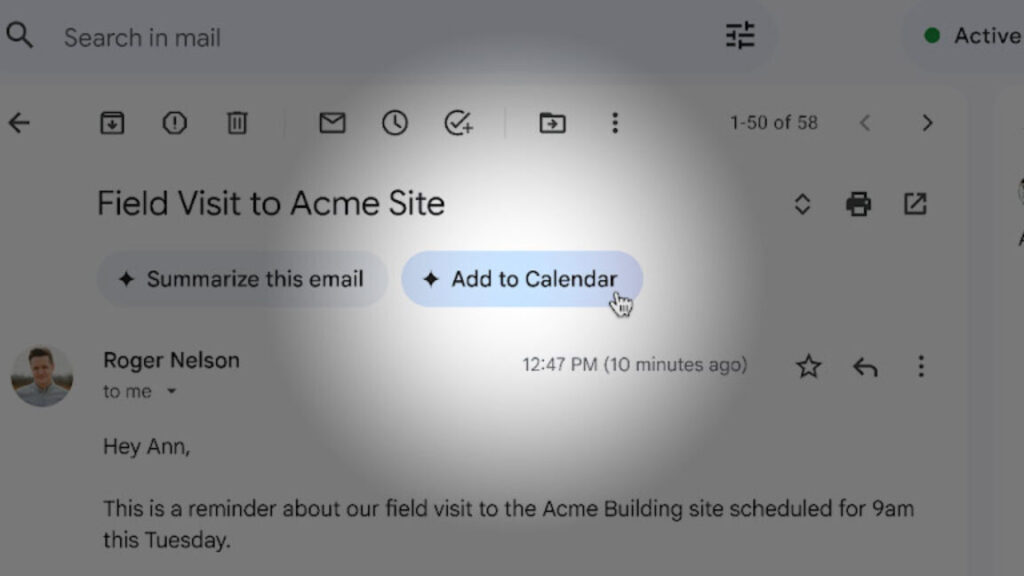
Canvas is similar (confusingly) to the OpenAI product of the same name. Canvas is available in the Gemini prompt bar on the web and mobile app. Simply upload a document and tell Gemini what you need to do with it. In Google’s example, the user asks for a speech based on a PDF containing class notes. And just like that, Gemini spits out a document.
Canvas lets you refine the AI-generated documents right inside Gemini. The writing tools available across the Google ecosystem, with options like suggested edits and different tones, are available inside the Gemini-based editor. If you want to do more edits or collaborate with others, you can export the document to Google Docs with a single click.
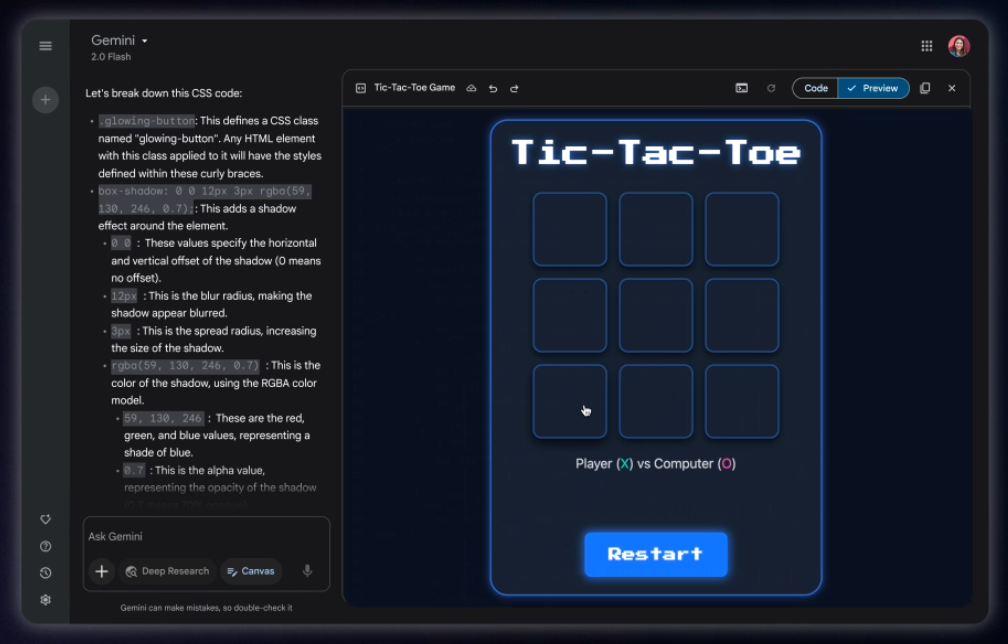
Credit: Google
Canvas is also adept at coding. Just ask, and Canvas can generate prototype web apps, Python scripts, HTML, and more. You can ask Gemini about the code, make alterations, and even preview your results in real time inside Gemini as you (or the AI) make changes.
Gemini gets new coding and writing tools, plus AI-generated “podcasts” Read More »