OpenAI’s most capable AI model, GPT-5, may be coming in August
References to “gpt-5-reasoning-alpha-2025-07-13” have already been spotted on X, with code showing “reasoning_effort: high” in the model configuration. These sightings suggest the model has entered final testing phases, with testers getting their hands on the code and security experts doing red teaming on the model to test vulnerabilities.
Unifying OpenAI’s model lineup
The new model represents OpenAI’s attempt to simplify its increasingly complex product lineup. As Altman explained in February, GPT-5 may integrate features from both the company’s conventional GPT models and its reasoning-focused o-series models into a single system.
“We’re truly excited to not just make a net new great frontier model, we’re also going to unify our two series,” OpenAI’s Head of Developer Experience Romain Huet said at a recent event. “The breakthrough of reasoning in the O-series and the breakthroughs in multi-modality in the GPT-series will be unified, and that will be GPT-5.”
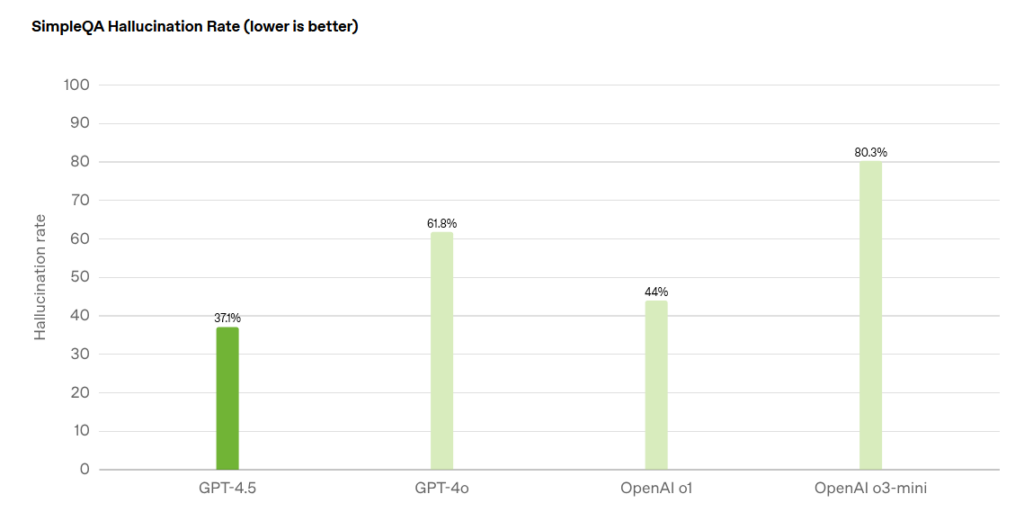
According to The Information, GPT-5 is expected to be better at coding and more powerful overall, combining attributes of both traditional models and SR models such as o3.
Before GPT-5 arrives, OpenAI still plans to release its first open-weights model since GPT-2 in 2019, which means others with the proper hardware will be able to download and run the AI model on their own machines. The Verge describes this model as “similar to o3 mini” with reasoning capabilities. However, Altman announced on July 11 that the open model needs additional safety testing, saying, “We are not yet sure how long it will take us.”
OpenAI’s most capable AI model, GPT-5, may be coming in August Read More »