A Wall Street Journal report on Friday said Nvidia insiders had expressed doubts about the transaction and that Huang had privately criticized what he described as a lack of discipline in OpenAI’s business approach. The Journal also reported that Huang had expressed concern about the competition OpenAI faces from Google and Anthropic. Huang called those claims “nonsense.”
Nvidia shares fell about 1.1 percent on Monday following the reports. Sarah Kunst, managing director at Cleo Capital, told CNBC that the back-and-forth was unusual. “One of the things I did notice about Jensen Huang is that there wasn’t a strong ‘It will be $100 billion.’ It was, ‘It will be big. It will be our biggest investment ever.’ And so I do think there are some question marks there.”
In September, Bryn Talkington, managing partner at Requisite Capital Management, noted the circular nature of such investments to CNBC. “Nvidia invests $100 billion in OpenAI, which then OpenAI turns back and gives it back to Nvidia,” Talkington said. “I feel like this is going to be very virtuous for Jensen.”
Tech critic Ed Zitron has been critical of Nvidia’s circular investments for some time, which touch dozens of tech companies, including major players and startups. They are also all Nvidia customers.
“NVIDIA seeds companies and gives them the guaranteed contracts necessary to raise debt to buy GPUs from NVIDIA,” Zitron wrote on Bluesky last September, “Even though these companies are horribly unprofitable and will eventually die from a lack of any real demand.”
Chips from other places
Outside of sourcing GPUs from Nvidia, OpenAI has reportedly discussed working with startups Cerebras and Groq, both of which build chips designed to reduce inference latency. But in December, Nvidia struck a $20 billion licensing deal with Groq, which Reuters sources say ended OpenAI’s talks with Groq. Nvidia hired Groq’s founder and CEO Jonathan Ross along with other senior leaders as part of the arrangement.
In January, OpenAI announced a $10 billion deal with Cerebras instead, adding 750 megawatts of computing capacity for faster inference through 2028. Sachin Katti, who joined OpenAI from Intel in November to lead compute infrastructure, said the partnership adds “a dedicated low-latency inference solution” to OpenAI’s platform.
But OpenAI has clearly been hedging its bets. Beyond the Cerebras deal, the company struck an agreement with AMD in October for six gigawatts of GPUs and announced plans with Broadcom to develop a custom AI chip to wean itself off of Nvidia dependence. When those chips will be ready, however, is currently unknown.
Despite connection hiccups, we covered OpenAI’s finances, nuclear power, and Sam Altman.
On Tuesday of last week, Ars Technica hosted a live conversation with Ed Zitron, host of the Better Offline podcast and one of tech’s most vocal AI critics, to discuss whether the generative AI industry is experiencing a bubble and when it might burst. My Internet connection had other plans, though, dropping out multiple times and forcing Ars Technica’s Lee Hutchinson to jump in as an excellent emergency backup host.
During the times my connection cooperated, Zitron and I covered OpenAI’s financial issues, lofty infrastructure promises, and why the AI hype machine keeps rolling despite some arguably shaky economics underneath. Lee’s probing questions about per-user costs revealed a potential flaw in AI subscription models: Companies can’t predict whether a user will cost them $2 or $10,000 per month.
You can watch a recording of the event on YouTube or in the window below.
“A 50 billion-dollar industry pretending to be a trillion-dollar one”
I started by asking Zitron the most direct question I could: “Why are you so mad about AI?” His answer got right to the heart of his critique: the disconnect between AI’s actual capabilities and how it’s being sold. “Because everybody’s acting like it’s something it isn’t,” Zitron said. “They’re acting like it’s this panacea that will be the future of software growth, the future of hardware growth, the future of compute.”
In one of his newsletters, Zitron describes the generative AI market as “a 50 billion dollar revenue industry masquerading as a one trillion-dollar one.” He pointed to OpenAI’s financial burn rate (losing an estimated $9.7 billion in the first half of 2025 alone) as evidence that the economics don’t work, coupled with a heavy dose of pessimism about AI in general.
Donald Trump listens as Nvidia CEO Jensen Huang speaks at the White House during an event on “Investing in America” on April 30, 2025, in Washington, DC. Credit: Andrew Harnik / Staff | Getty Images News
“The models just do not have the efficacy,” Zitron said during our conversation. “AI agents is one of the most egregious lies the tech industry has ever told. Autonomous agents don’t exist.”
He contrasted the relatively small revenue generated by AI companies with the massive capital expenditures flowing into the sector. Even major cloud providers and chip makers are showing strain. Oracle reportedly lost $100 million in three months after installing Nvidia’s new Blackwell GPUs, which Zitron noted are “extremely power-hungry and expensive to run.”
Finding utility despite the hype
I pushed back against some of Zitron’s broader dismissals of AI by sharing my own experience. I use AI chatbots frequently for brainstorming useful ideas and helping me see them from different angles. “I find I use AI models as sort of knowledge translators and framework translators,” I explained.
After experiencing brain fog from repeated bouts of COVID over the years, I’ve also found tools like ChatGPT and Claude especially helpful for memory augmentation that pierces through brain fog: describing something in a roundabout, fuzzy way and quickly getting an answer I can then verify. Along these lines, I’ve previously written about how people in a UK study found AI assistants useful accessibility tools.
Zitron acknowledged this could be useful for me personally but declined to draw any larger conclusions from my one data point. “I understand how that might be helpful; that’s cool,” he said. “I’m glad that that helps you in that way; it’s not a trillion-dollar use case.”
He also shared his own attempts at using AI tools, including experimenting with Claude Code despite not being a coder himself.
“If I liked [AI] somehow, it would be actually a more interesting story because I’d be talking about something I liked that was also onerously expensive,” Zitron explained. “But it doesn’t even do that, and it’s actually one of my core frustrations, it’s like this massive over-promise thing. I’m an early adopter guy. I will buy early crap all the time. I bought an Apple Vision Pro, like, what more do you say there? I’m ready to accept issues, but AI is all issues, it’s all filler, no killer; it’s very strange.”
Zitron and I agree that current AI assistants are being marketed beyond their actual capabilities. As I often say, AI models are not people, and they are not good factual references. As such, they cannot replace human decision-making and cannot wholesale replace human intellectual labor (at the moment). Instead, I see AI models as augmentations of human capability: as tools rather than autonomous entities.
Computing costs: History versus reality
Even though Zitron and I found some common ground about AI hype, I expressed a belief that criticism over the cost and power requirements of operating AI models will eventually not become an issue.
I attempted to make that case by noting that computing costs historically trend downward over time, referencing the Air Force’s SAGE computer system from the 1950s: a four-story building that performed 75,000 operations per second while consuming two megawatts of power. Today, pocket-sized phones deliver millions of times more computing power in a way that would be impossible, power consumption-wise, in the 1950s.
The blockhouse for the Semi-Automatic Ground Environment at Stewart Air Force Base, Newburgh, New York. Credit: Denver Post via Getty Images
“I think it will eventually work that way,” I said, suggesting that AI inference costs might follow similar patterns of improvement over years and that AI tools will eventually become commodity components of computer operating systems. Basically, even if AI models stay inefficient, AI models of a certain baseline usefulness and capability will still be cheaper to train and run in the future because the computing systems they run on will be faster, cheaper, and less power-hungry as well.
Zitron pushed back on this optimism, saying that AI costs are currently moving in the wrong direction. “The costs are going up, unilaterally across the board,” he said. Even newer systems like Cerebras and Grok can generate results faster but not cheaper. He also questioned whether integrating AI into operating systems would prove useful even if the technology became profitable, since AI models struggle with deterministic commands and consistent behavior.
The power problem and circular investments
One of Zitron’s most pointed criticisms during the discussion centered on OpenAI’s infrastructure promises. The company has pledged to build data centers requiring 10 gigawatts of power capacity (equivalent to 10 nuclear power plants, I once pointed out) for its Stargate project in Abilene, Texas. According to Zitron’s research, the town currently has only 350 megawatts of generating capacity and a 200-megawatt substation.
“A gigawatt of power is a lot, and it’s not like Red Alert 2,” Zitron said, referencing the real-time strategy game. “You don’t just build a power station and it happens. There are months of actual physics to make sure that it doesn’t kill everyone.”
He believes many announced data centers will never be completed, calling the infrastructure promises “castles on sand” that nobody in the financial press seems willing to question directly.
After another technical blackout on my end, I came back online and asked Zitron to define the scope of the AI bubble. He says it has evolved from one bubble (foundation models) into two or three, now including AI compute companies like CoreWeave and the market’s obsession with Nvidia.
Zitron highlighted what he sees as essentially circular investment schemes propping up the industry. He pointed to OpenAI’s $300 billion deal with Oracle and Nvidia’s relationship with CoreWeave as examples. “CoreWeave, they literally… They funded CoreWeave, became their biggest customer, then CoreWeave took that contract and those GPUs and used them as collateral to raise debt to buy more GPUs,” Zitron explained.
When will the bubble pop?
Zitron predicted the bubble would burst within the next year and a half, though he acknowledged it could happen sooner. He expects a cascade of events rather than a single dramatic collapse: An AI startup will run out of money, triggering panic among other startups and their venture capital backers, creating a fire-sale environment that makes future fundraising impossible.
“It’s not gonna be one Bear Stearns moment,” Zitron explained. “It’s gonna be a succession of events until the markets freak out.”
The crux of the problem, according to Zitron, is Nvidia. The chip maker’s stock represents 7 to 8 percent of the S&P 500’s value, and the broader market has become dependent on Nvidia’s continued hyper growth. When Nvidia posted “only” 55 percent year-over-year growth in January, the market wobbled.
“Nvidia’s growth is why the bubble is inflated,” Zitron said. “If their growth goes down, the bubble will burst.”
He also warned of broader consequences: “I think there’s a depression coming. I think once the markets work out that tech doesn’t grow forever, they’re gonna flush the toilet aggressively on Silicon Valley.” This connects to his larger thesis: that the tech industry has run out of genuine hyper-growth opportunities and is trying to manufacture one with AI.
“Is there anything that would falsify your premise of this bubble and crash happening?” I asked. “What if you’re wrong?”
“I’ve been answering ‘What if you’re wrong?’ for a year-and-a-half to two years, so I’m not bothered by that question, so the thing that would have to prove me right would’ve already needed to happen,” he said. Amid a longer exposition about Sam Altman, Zitron said, “The thing that would’ve had to happen with inference would’ve had to be… it would have to be hundredths of a cent per million tokens, they would have to be printing money, and then, it would have to be way more useful. It would have to have efficacy that it does not have, the hallucination problems… would have to be fixable, and on top of this, someone would have to fix agents.”
A positivity challenge
Near the end of our conversation, I wondered if I could flip the script, so to speak, and see if he could say something positive or optimistic, although I chose the most challenging subject possible for him. “What’s the best thing about Sam Altman,” I asked. “Can you say anything nice about him at all?”
“I understand why you’re asking this,” Zitron started, “but I wanna be clear: Sam Altman is going to be the reason the markets take a crap. Sam Altman has lied to everyone. Sam Altman has been lying forever.” He continued, “Like the Pied Piper, he’s led the markets into an abyss, and yes, people should have known better, but I hope at the end of this, Sam Altman is seen for what he is, which is a con artist and a very successful one.”
Then he added, “You know what? I’ll say something nice about him, he’s really good at making people say, ‘Yes.’”
Benj Edwards is Ars Technica’s Senior AI Reporter and founder of the site’s dedicated AI beat in 2022. He’s also a tech historian with almost two decades of experience. In his free time, he writes and records music, collects vintage computers, and enjoys nature. He lives in Raleigh, NC.
It feels like it was just yesterday that Sony hardware architect Mark Cerny was first teasing Sony’s “PS4 successor” and its “enhanced ray-tracing capabilities” powered by new AMD chips. Now that we’re nearly five full years into the PS5 era, it’s time for Sony and AMD to start teasing the new chips that will power what Cerny calls “a future console in a few years’ time.”
In a quick nine-minute video posted Thursday, Cerny sat down with Jack Huynh, the senior VP and general manager of AMD’s Computing and Graphics Group, to talk about “Project Amethyst,” a co-engineering effort between both companies that was also teased back in July. And while that Project Amethyst hardware currently only exists in the form of a simulation, Cerny said that the “results are quite promising” for a project that’s still in the “early days.”
Mo’ ML, fewer problems?
Project Amethyst is focused on going beyond traditional rasterization techniques that don’t scale well when you try to “brute force that with raw power alone,” Huynh said in the video. Instead, the new architecture is focused on more efficient running of the kinds of machine-learning-based neural networks behind AMD’s FSR upscaling technology and Sony’s similar PSSR system.
From the same source. Two branches. One vision.
My good friend and fellow gamer @cerny and I recently reflected on our shared journey — symbolized by these two pieces of amethyst, split from the same stone.
While that kind of upscaling currently helps let GPUs pump out 4K graphics in real time, Cerny said that the “nature of the GPU fights us here,” requiring calculations to be broken up into subproblems to be handled in a somewhat inefficient parallel process by the GPU’s individual compute units.
To get around this issue, Project Amethyst uses “neural arrays” that let compute units share data and process problems like a “single focused AI engine,” Cerny said. While the entire GPU won’t be connected in this manner, connecting small sets of compute units like this allows for more scalable shader engines that can “process a large chunk of the screen in one go,” Cerny said. That means Project Amethyst will let “more and more of what you see on screen… be touched or enhanced by ML,” Huynh added.
OpenAI is set to produce its own artificial intelligence chip for the first time next year, as the ChatGPT maker attempts to address insatiable demand for computing power and reduce its reliance on chip giant Nvidia.
The chip, co-designed with US semiconductor giant Broadcom, would ship next year, according to multiple people familiar with the partnership.
Broadcom’s chief executive Hock Tan on Thursday referred to a mystery new customer committing to $10 billion in orders.
OpenAI’s move follows the strategy of tech giants such as Google, Amazon and Meta, which have designed their own specialised chips to run AI workloads. The industry has seen huge demand for the computing power to train and run AI models.
OpenAI planned to put the chip to use internally, according to one person close to the project, rather than make them available to external customers.
Last year it began an initial collaboration with Broadcom, according to reports at the time, but the timeline for mass production of a successful chip design had previously been unclear.
On a call with analysts, Tan announced that Broadcom had secured a fourth major customer for its custom AI chip business, as it reported earnings that topped Wall Street estimates.
Broadcom does not disclose the names of these customers, but people familiar with the matter confirmed OpenAI was the new client. Broadcom and OpenAI declined to comment.
AMD is releasing the first detailed specifications of its next-generation Radeon RX 9070 series GPUs and the RDNA4 graphics architecture today, almost two months after teasing them at CES.
The short version is that these are both upper-midrange graphics cards targeting resolutions of 1440p and 4K and meant to compete mainly with Nvidia’s incoming and outgoing 4070- and 5070-series GeForce GPUs, including the RTX 4070, RTX 5070, RTX 4070 Ti and Ti Super, and the RTX 5070 Ti.
AMD says the RX 9070 will start at $549, the same price as Nvidia’s RTX 5070. The slightly faster 9070 XT starts at $599, $150 less than the RTX 5070 Ti. The cards go on sale March 6, a day after Nvidia’s RTX 5070.
Neither Nvidia nor Intel has managed to keep its GPUs in stores at their announced starting prices so far, though, so how well AMD’s pricing stacks up to Nvidia in the real world may take a few weeks or months to settle out. For its part, AMD says it’s confident that it has enough supply to meet demand, but that’s as specific as the company’s reassurances got.
Specs and speeds: Radeon RX 9070 and 9070 XT
RX 9070 XT
RX 9070
RX 7900 XTX
RX 7900 XT
RX 7900 GRE
RX 7800 XT
Compute units (Stream processors)
64 RDNA4 (4,096)
56 RDNA4 (3,584)
96 RDNA3 (6,144)
84 RDNA3 (5,376)
80 RDNA3 (5,120)
60 RDNA3 (3,840)
Boost Clock
2,970 MHz
2,520 MHz
2,498 MHz
2,400 MHz
2,245 MHz
2,430 MHz
Memory Bus Width
256-bit
256-bit
384-bit
320-bit
256-bit
256-bit
Memory Bandwidth
650 GB/s
650 GB/s
960 GB/s
800 GB/s
576 GB/s
624 GB/s
Memory size
16GB GDDR6
16GB GDDR6
24GB GDDR6
20GB GDDR6
16GB GDDR6
16GB GDDR6
Total board power (TBP)
304 W
220 W
355 W
315 W
260 W
263 W
As is implied by their similar price tags, the 9070 and 9070 XT have more in common than not. Both are based on the same GPU die—the 9070 has 56 of the chip’s compute units enabled, while the 9070 XT has 64. Both cards come with 16GB of RAM (4GB more than the 5070, the same amount as the 5070 Ti) on a 256-bit memory bus, and both use two 8-pin power connectors by default, though the 9070 XT can use significantly more power than the 9070 (304 W, compared to 220 W).
AMD says that its partners are free to make Radeon cards with the 12VHPWR or 12V-2×6 power connectors on them, though given the apparently ongoing issues with the connector, we’d expect most Radeon GPUs to stick with the known quantity that is the 8-pin connector.
AMD says that the 9070 series is made using a 4 nm TSMC manufacturing process and that the chips are monolithic rather than being split up into chiplets as some RX 7000-series cards were. AMD’s commitment to its memory controller chiplets was always hit or miss with the 7000-series—the high-end cards tended to use them, while the lower-end GPUs were usually monolithic—so it’s not clear one way or the other whether this means AMD is giving up on chiplet-based GPUs altogether or if it’s just not using them this time around.
On Thursday, AMD announced its new MI325X AI accelerator chip, which is set to roll out to data center customers in the fourth quarter of this year. At an event hosted in San Francisco, the company claimed the new chip offers “industry-leading” performance compared to Nvidia’s current H200 GPUs, which are widely used in data centers to power AI applications such as ChatGPT.
With its new chip, AMD hopes to narrow the performance gap with Nvidia in the AI processor market. The Santa Clara-based company also revealed plans for its next-generation MI350 chip, which is positioned as a head-to-head competitor of Nvidia’s new Blackwell system, with an expected shipping date in the second half of 2025.
In an interview with the Financial Times, AMD CEO Lisa Su expressed her ambition for AMD to become the “end-to-end” AI leader over the next decade. “This is the beginning, not the end of the AI race,” she told the publication.
According to AMD’s website, the announced MI325X accelerator contains 153 billion transistors and is built on the CDNA3 GPU architecture using TSMC’s 5 nm and 6 nm FinFET lithography processes. The chip includes 19,456 stream processors and 1,216 matrix cores spread across 304 compute units. With a peak engine clock of 2100 MHz, the MI325X delivers up to 2.61 PFLOPs of peak eight-bit precision (FP8) performance. For half-precision (FP16) operations, it reaches 1.3 PFLOPs.
Enlarge/ Nvidia’s CEO Jensen Huang delivers his keystone speech ahead of Computex 2024 in Taipei on June 2, 2024.
On Sunday, Nvidia CEO Jensen Huang reached beyond Blackwell and revealed the company’s next-generation AI-accelerating GPU platform during his keynote at Computex 2024 in Taiwan. Huang also detailed plans for an annual tick-tock-style upgrade cycle of its AI acceleration platforms, mentioning an upcoming Blackwell Ultra chip slated for 2025 and a subsequent platform called “Rubin” set for 2026.
Nvidia’s data center GPUs currently power a large majority of cloud-based AI models, such as ChatGPT, in both development (training) and deployment (inference) phases, and investors are keeping a close watch on the company, with expectations to keep that run going.
During the keynote, Huang seemed somewhat hesitant to make the Rubin announcement, perhaps wary of invoking the so-called Osborne effect, whereby a company’s premature announcement of the next iteration of a tech product eats into the current iteration’s sales. “This is the very first time that this next click as been made,” Huang said, holding up his presentation remote just before the Rubin announcement. “And I’m not sure yet whether I’m going to regret this or not.”
Nvidia Keynote at Computex 2023.
The Rubin AI platform, expected in 2026, will use HBM4 (a new form of high-bandwidth memory) and NVLink 6 Switch, operating at 3,600GBps. Following that launch, Nvidia will release a tick-tock iteration called “Rubin Ultra.” While Huang did not provide extensive specifications for the upcoming products, he promised cost and energy savings related to the new chipsets.
During the keynote, Huang also introduced a new ARM-based CPU called “Vera,” which will be featured on a new accelerator board called “Vera Rubin,” alongside one of the Rubin GPUs.
Much like Nvidia’s Grace Hopper architecture, which combines a “Grace” CPU and a “Hopper” GPU to pay tribute to the pioneering computer scientist of the same name, Vera Rubin refers to Vera Florence Cooper Rubin (1928–2016), an American astronomer who made discoveries in the field of deep space astronomy. She is best known for her pioneering work on galaxy rotation rates, which provided strong evidence for the existence of dark matter.
A calculated risk
Enlarge/ Nvidia CEO Jensen Huang reveals the “Rubin” AI platform for the first time during his keynote at Computex 2024 on June 2, 2024.
Nvidia’s reveal of Rubin is not a surprise in the sense that most big tech companies are continuously working on follow-up products well in advance of release, but it’s notable because it comes just three months after the company revealed Blackwell, which is barely out of the gate and not yet widely shipping.
At the moment, the company seems to be comfortable leapfrogging itself with new announcements and catching up later; Nvidia just announced that its GH200 Grace Hopper “Superchip,” unveiled one year ago at Computex 2023, is now in full production.
With Nvidia stock rising and the company possessing an estimated 70–95 percent of the data center GPU market share, the Rubin reveal is a calculated risk that seems to come from a place of confidence. That confidence could turn out to be misplaced if a so-called “AI bubble” pops or if Nvidia misjudges the capabilities of its competitors. The announcement may also stem from pressure to continue Nvidia’s astronomical growth in market cap with nonstop promises of improving technology.
Accordingly, Huang has been eager to showcase the company’s plans to continue pushing silicon fabrication tech to its limits and widely broadcast that Nvidia plans to keep releasing new AI chips at a steady cadence.
“Our company has a one-year rhythm. Our basic philosophy is very simple: build the entire data center scale, disaggregate and sell to you parts on a one-year rhythm, and we push everything to technology limits,” Huang said during Sunday’s Computex keynote.
Despite Nvidia’s recent market performance, the company’s run may not continue indefinitely. With ample money pouring into the data center AI space, Nvidia isn’t alone in developing accelerator chips. Competitors like AMD (with the Instinct series) and Intel (with Guadi 3) also want to win a slice of the data center GPU market away from Nvidia’s current command of the AI-accelerator space. And OpenAI’s Sam Altman is trying to encourage diversified production of GPU hardware that will power the company’s next generation of AI models in the years ahead.
Last summer, AMD debuted the latest version of its FidelityFX Super Resolution (FSR) upscaling technology. While version 2.x focused mostly on making lower-resolution images look better at higher resolutions, version 3.0 focused on AMD’s “Fluid Motion Frames,” which attempt to boost FPS by generating interpolated frames to insert between the ones that your GPU is actually rendering.
Today, the company is announcing FSR 3.1, which among other improvements decouples the upscaling improvements in FSR 3.x from the Fluid Motion Frames feature. FSR 3.1 will be available “later this year” in games whose developers choose to implement it.
Fluid Motion Frames and Nvidia’s equivalent DLSS Frame Generation usually work best when a game is already running at a high frame rate, and even then can be more prone to mistakes and odd visual artifacts than regular FSR or DLSS upscaling. FSR 3.0 was an all-or-nothing proposition, but version 3.1 should let you pick and choose what features you want to enable.
It also means you can use FSR 3.0 frame generation with other upscalers like DLSS, especially useful for 20- and 30-series Nvidia GeForce GPUs that support DLSS upscaling but not DLSS Frame Generation.
“When using FSR 3 Frame Generation with any upscaling quality mode OR with the new ‘Native AA’ mode, it is highly recommended to be always running at a minimum of ~60 FPS before Frame Generation is applied for an optimal high-quality gaming experience and to mitigate any latency introduced by the technology,” wrote AMD’s Alexander Blake-Davies in the post announcing FSR 3.1.
Generally, FSR’s upscaling image quality falls a little short of Nvidia’s DLSS, but FSR 2 closed that gap a bit, and FSR 3.1 goes further. AMD highlights two specific improvements: one for “temporal stability,” which will help reduce the flickering and shimmering effect that FSR sometimes introduces, and one for ghosting reduction, which will reduce unintentional blurring effects for fast-moving objects.
The biggest issue with these new FSR improvements is that they need to be implemented on a game-to-game basis. FSR 3.0 was announced in August 2023, and AMD now trumpets that there are 40 “available and upcoming” games that support the technology, of which just 19 are currently available. There are a lot of big-name AAA titles in the list, but that’s still not many compared to the sum total of all PC games or even the 183 titles that currently support FSR 2.x.
AMD wants to help solve this problem in FSR 3.1 by introducing a stable FSR API for developers, which AMD says “makes it easier for developers to debug and allows forward compatibility with updated versions of FSR.” This may eventually lead to more games getting future FSR improvements for “free,” without the developer’s effort.
AMD didn’t mention any hardware requirements for FSR 3.1, though presumably, the company will still support a reasonably wide range of recent GPUs from AMD, Nvidia, and Intel. FSR 3.0 is formally supported on Radeon RX 5000, 6000, and 7000 cards, Nvidia’s RTX 20-series and newer, and Intel Arc GPUs. It will also bring FSR 3.x features to games that use the Vulkan API, not just DirectX 12, and the Xbox Game Development Kit (GDK) so it can be used in console titles as well as PC games.
Enlarge/ The GB200 “superchip” covered with a fanciful blue explosion.
Nvidia / Benj Edwards
On Monday, Nvidia unveiled the Blackwell B200 tensor core chip—the company’s most powerful single-chip GPU, with 208 billion transistors—which Nvidia claims can reduce AI inference operating costs (such as running ChatGPT) and energy consumption by up to 25 times compared to the H100. The company also unveiled the GB200, a “superchip” that combines two B200 chips and a Grace CPU for even more performance.
The news came as part of Nvidia’s annual GTC conference, which is taking place this week at the San Jose Convention Center. Nvidia CEO Jensen Huang delivered the keynote Monday afternoon. “We need bigger GPUs,” Huang said during his keynote. The Blackwell platform will allow the training of trillion-parameter AI models that will make today’s generative AI models look rudimentary in comparison, he said. For reference, OpenAI’s GPT-3, launched in 2020, included 175 billion parameters. Parameter count is a rough indicator of AI model complexity.
Nvidia named the Blackwell architecture after David Harold Blackwell, a mathematician who specialized in game theory and statistics and was the first Black scholar inducted into the National Academy of Sciences. The platform introduces six technologies for accelerated computing, including a second-generation Transformer Engine, fifth-generation NVLink, RAS Engine, secure AI capabilities, and a decompression engine for accelerated database queries.
Enlarge/ Press photo of the Grace Blackwell GB200 chip, which combines two B200 GPUs with a Grace CPU into one chip.
Several major organizations, such as Amazon Web Services, Dell Technologies, Google, Meta, Microsoft, OpenAI, Oracle, Tesla, and xAI, are expected to adopt the Blackwell platform, and Nvidia’s press release is replete with canned quotes from tech CEOs (key Nvidia customers) like Mark Zuckerberg and Sam Altman praising the platform.
GPUs, once only designed for gaming acceleration, are especially well suited for AI tasks because their massively parallel architecture accelerates the immense number of matrix multiplication tasks necessary to run today’s neural networks. With the dawn of new deep learning architectures in the 2010s, Nvidia found itself in an ideal position to capitalize on the AI revolution and began designing specialized GPUs just for the task of accelerating AI models.
Nvidia’s data center focus has made the company wildly rich and valuable, and these new chips continue the trend. Nvidia’s gaming GPU revenue ($2.9 billion in the last quarter) is dwarfed in comparison to data center revenue (at $18.4 billion), and that shows no signs of stopping.
A beast within a beast
Enlarge/ Press photo of the Nvidia GB200 NVL72 data center computer system.
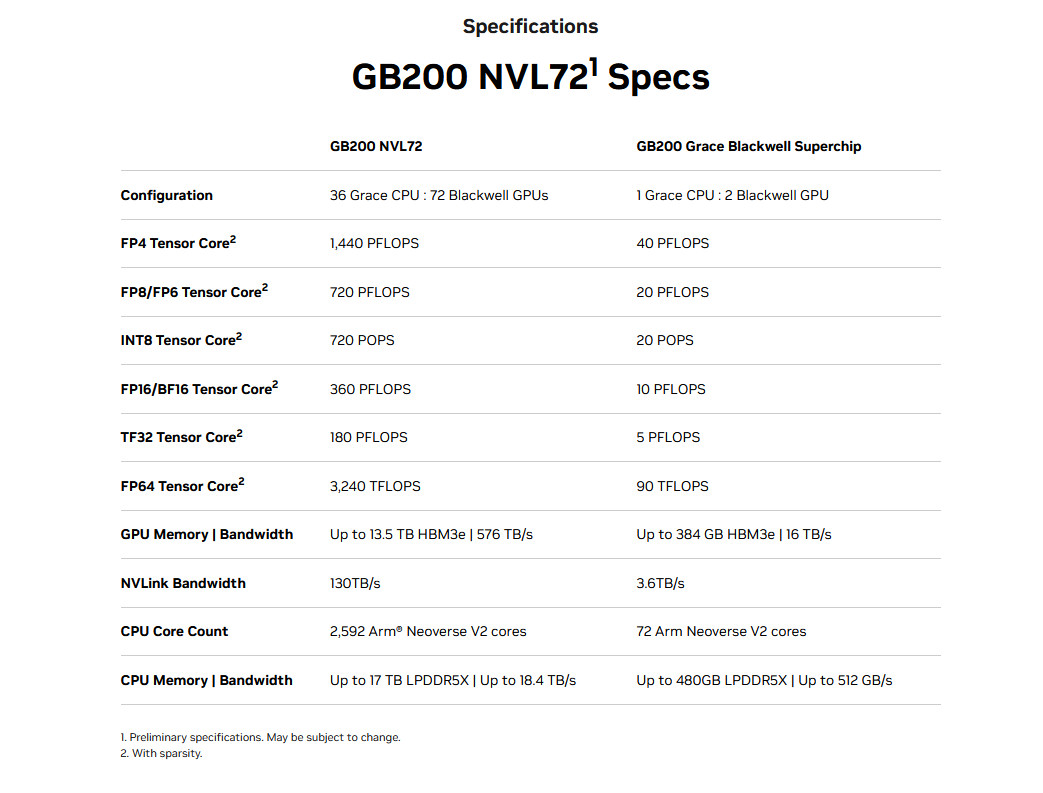
The aforementioned Grace Blackwell GB200 chip arrives as a key part of the new NVIDIA GB200 NVL72, a multi-node, liquid-cooled data center computer system designed specifically for AI training and inference tasks. It combines 36 GB200s (that’s 72 B200 GPUs and 36 Grace CPUs total), interconnected by fifth-generation NVLink, which links chips together to multiply performance.
Enlarge/ A specification chart for the Nvidia GB200 NVL72 system.
“The GB200 NVL72 provides up to a 30x performance increase compared to the same number of NVIDIA H100 Tensor Core GPUs for LLM inference workloads and reduces cost and energy consumption by up to 25x,” Nvidia said.
That kind of speed-up could potentially save money and time while running today’s AI models, but it will also allow for more complex AI models to be built. Generative AI models—like the kind that power Google Gemini and AI image generators—are famously computationally hungry. Shortages of compute power have widely been cited as holding back progress and research in the AI field, and the search for more compute has led to figures like OpenAI CEO Sam Altman trying to broker deals to create new chip foundries.
While Nvidia’s claims about the Blackwell platform’s capabilities are significant, it’s worth noting that its real-world performance and adoption of the technology remain to be seen as organizations begin to implement and utilize the platform themselves. Competitors like Intel and AMD are also looking to grab a piece of Nvidia’s AI pie.
Nvidia says that Blackwell-based products will be available from various partners starting later this year.
Enlarge/ ASRock’s take on AMD’s Radeon RX 7900 GRE.
Andrew Cunningham
In July 2023, AMD released a new GPU called the “Radeon RX 7900 GRE” in China. GRE stands for “Golden Rabbit Edition,” a reference to the Chinese zodiac, and while the card was available outside of China in a handful of pre-built OEM systems, AMD didn’t make it widely available at retail.
That changes today—AMD is launching the RX 7900 GRE at US retail for a suggested starting price of $549. This throws it right into the middle of the busy upper-mid-range graphics card market, where it will compete with Nvidia’s $549 RTX 4070 and the $599 RTX 4070 Super, as well as AMD’s own $500 Radeon RX 7800 XT.
We’ve run our typical set of GPU tests on the 7900 GRE to see how it stacks up to the cards AMD and Nvidia are already offering. Is it worth buying a new card relatively late in this GPU generation, when rumors point to new next-gen GPUs from Nvidia, AMD, and Intel before the end of the year? Can the “Golden Rabbit Edition” still offer a good value, even though it’s currently the year of the dragon?
Meet the 7900 GRE
RX 7900 XT
RX 7900 GRE
RX 7800 XT
RX 6800 XT
RX 6800
RX 7700 XT
RX 6700 XT
RX 6750 XT
Compute units (Stream processors)
84 (5,376)
80 (5,120)
60 (3,840)
72 (4,608)
60 (3,840)
54 (3,456)
40 (2,560)
40 (2,560)
Boost Clock
2,400 MHz
2,245 MHz
2,430 MHz
2,250 MHz
2,105 MHz
2,544 MHz
2,581 MHz
2,600 MHz
Memory Bus Width
320-bit
256-bit
256-bit
256-bit
256-bit
192-bit
192-bit
192-bit
Memory Clock
2,500 MHz
2,250 MHz
2,438 MHz
2,000 MHz
2,000 MHz
2,250 MHz
2,000 MHz
2,250 MHz
Memory size
20GB GDDR6
16GB GDDR6
16GB GDDR6
16GB GDDR6
16GB GDDR6
12GB GDDR6
12GB GDDR6
12GB GDDR6
Total board power (TBP)
315 W
260 W
263 W
300 W
250 W
245 W
230 W
250 W
The 7900 GRE slots into AMD’s existing lineup above the RX 7800 XT (currently $500-ish) and below the RX 7900 (around $750). Technologically, we’re looking at the same Navi 31 GPU silicon as the 7900 XT and XTX, but with just 80 of the compute units enabled, down from 84 and 96, respectively. The normal benefits of the RDNA3 graphics architecture apply, including hardware-accelerated AV1 video encoding and DisplayPort 2.1 support.
The 7900 GRE also includes four active memory controller die (MCD) chiplets, giving it a narrower 256-bit memory bus and 16GB of memory instead of 20GB—still plenty for modern games, though possibly not quite as future-proof as the 7900 XT. The card uses significantly less power than the 7900 XT and about the same amount as the 7800 XT. That feels a bit weird, intuitively, since slower cards almost always consume less power than faster ones. But it does make some sense; pushing the 7800 XT’s smaller Navi 32 GPU to get higher clock speeds out of it is probably making it run a bit less efficiently than a larger Navi 31 GPU die that isn’t being pushed as hard.
Andrew Cunningham
Andrew Cunningham
Andrew Cunningham
When we reviewed the 7800 XT last year, we noted that its hardware configuration and performance made it seem more like a successor to the (non-XT) Radeon RX 6800, while it just barely managed to match or beat the 6800 XT in our tests. Same deal with the 7900 GRE, which is a more logical successor to the 6800 XT. Bear that in mind when doing generation-over-generation comparisons.
Enlarge/ The most interesting thing about AMD’s Ryzen 7 8700G CPU is the Radeon 780M GPU that’s attached to it.
Andrew Cunningham
Put me on the short list of people who can get excited about the humble, much-derided integrated GPU.
Yes, most of them are afterthoughts, designed for office desktops and laptops that will spend most of their lives rendering 2D images to a single monitor. But when integrated graphics push forward, it can open up possibilities for people who want to play games but can only afford a cheap desktop (or who have to make do with whatever their parents will pay for, which was the big limiter on my PC gaming experience as a kid).
That, plus an unrelated but accordant interest in building small mini-ITX-based desktops, has kept me interested in AMD’s G-series Ryzen desktop chips (which it sometimes calls “APUs,” to distinguish them from the Ryzen CPUs). And the Ryzen 8000G chips are a big upgrade from the 5000G series that immediately preceded them (this makes sense, because as we all know the number 8 immediately follows the number 5).
We’re jumping up an entire processor socket, one CPU architecture, three GPU architectures, and up to a new generation of much faster memory; especially for graphics, it’s a pretty dramatic leap. It’s an integrated GPU that can credibly beat the lowest tier of currently available graphics cards, replacing a $100–$200 part with something a lot more energy-efficient.
As with so many current-gen Ryzen chips, still-elevated pricing for the socket AM5 platform and the DDR5 memory it requires limit the 8000G series’ appeal, at least for now.
From laptop to desktop
Enlarge/ AMD’s first Ryzen 8000 desktop processors are what the company used to call “APUs,” a combination of a fast integrated GPU and a reasonably capable CPU.
AMD
The 8000G chips use the same Zen 4 CPU architecture as the Ryzen 7000 desktop chips, but the way the rest of the chip is put together is pretty different. Like past APUs, these are actually laptop silicon (in this case, the Ryzen 7040/8040 series, codenamed Phoenix and Phoenix 2) repackaged for a desktop processor socket.
Generally, the real-world impact of this is pretty mild; in most ways, the 8700G and 8600G will perform a lot like any other Zen 4 CPU with the same number of cores (our benchmarks mostly bear this out). But to the extent that there is a difference, the Phoenix silicon will consistently perform just a little worse, because it has half as much L3 cache. AMD’s Ryzen X3D chips revolve around the performance benefits of tons of cache, so you can see why having less would be detrimental.
The other missing feature from the Ryzen 7000 desktop chips is PCI Express 5.0 support—Ryzen 8000G tops out at PCIe 4.0. This might, maybe, one day in the distant future, eventually lead to some kind of user-observable performance difference. Some recent GPUs use an 8-lane PCIe 4.0 interface instead of the typical 16 lanes, which limits performance slightly. But PCIe 5.0 SSDs remain rare (and PCIe 4.0 peripherals remain extremely fast), so it probably shouldn’t top your list of concerns.
The Ryzen 5 8500G is a lot different from the 8700G and 8600G, since some of the CPU cores in the Phoenix 2 chips are based on Zen 4c rather than Zen 4. These cores have all the same capabilities as regular Zen 4 ones—unlike Intel’s E-cores—but they’re optimized to take up less space rather than hit high clock speeds. They were initially made for servers, where cramming lots of cores into a small amount of space is more important than having a smaller number of faster cores, but AMD is also using them to make some of its low-end consumer chips physically smaller and presumably cheaper to produce. AMD didn’t send us a Ryzen 8500G for review, so we can’t see exactly how Phoenix 2 stacks up in a desktop.
The 8700G and 8600G chips are also the only ones that come with AMD’s “Ryzen AI” feature, the brand AMD is using to refer to processors with a neural processing unit (NPU) included. Sort of like GPUs or video encoding/decoding blocks, these are additional bits built into the chip that handle things that CPUs can’t do very efficiently—in this case, machine learning and AI workloads.
Most PCs still don’t have NPUs, and as such they are only barely used in current versions of Windows (Windows 11 offers some webcam effects that will take advantage of NPU acceleration, but for now that’s mostly it). But expect this to change as they become more common and as more AI-accelerated text, image, and video creating and editing capabilities are built into modern operating systems.
The last major difference is the GPU. Ryzen 7000 includes a pair of RDNA2 compute units that perform more or less like Intel’s desktop integrated graphics: good enough to render your desktop on a monitor or two, but not much else. The Ryzen 8000G chips include up to 12 RDNA3 CUs, which—as we’ve already seen in laptops and portable gaming systems like the Asus ROG Ally that use the same silicon—is enough to run most games, if just barely in some cases.
That gives AMD’s desktop APUs a unique niche. You can use them in cases where you can’t afford a dedicated GPU—for a time during the big graphics card shortage in 2020 and 2021, a Ryzen 5700G was actually one of the only ways to build a budget gaming PC. Or you can use them in cases where a dedicated GPU won’t fit, like super-small mini ITX-based desktops.
The main argument that AMD makes is the affordability one, comparing the price of a Ryzen 8700G to the price of an Intel Core i5-13400F and a GeForce GTX 1650 GPU (this card is nearly five years old, but it remains Nvidia’s newest and best GPU available for less than $200).
Let’s check on performance first, and then we’ll revisit pricing.
As more companies ramp up development of artificial intelligence systems, they are increasingly turning to graphics processing unit (GPU) chips for the computing power they need to run large language models (LLMs) and to crunch data quickly at massive scale. Between video game processing and AI, demand for GPUs has never been higher, and chipmakers are rushing to bolster supply. In new findings released today, though, researchers are highlighting a vulnerability in multiple brands and models of mainstream GPUs—including Apple, Qualcomm, and AMD chips—that could allow an attacker to steal large quantities of data from a GPU’s memory.
The silicon industry has spent yearsrefining the security of central processing units, or CPUs, so they don’t leak data in memory even when they are built to optimize for speed. However, since GPUs were designed for raw graphics processing power, they haven’t been architected to the same degree with data privacy as a priority. As generative AI and other machine learning applications expand the uses of these chips, though, researchers from New York-based security firm Trail of Bits say that vulnerabilities in GPUs are an increasingly urgent concern.
“There is a broader security concern about these GPUs not being as secure as they should be and leaking a significant amount of data,” Heidy Khlaaf, Trail of Bits’ engineering director for AI and machine learning assurance, tells WIRED. “We’re looking at anywhere from 5 megabytes to 180 megabytes. In the CPU world, even a bit is too much to reveal.”
To exploit the vulnerability, which the researchers call LeftoverLocals, attackers would need to already have established some amount of operating system access on a target’s device. Modern computers and servers are specifically designed to silo data so multiple users can share the same processing resources without being able to access each others’ data. But a LeftoverLocals attack breaks down these walls. Exploiting the vulnerability would allow a hacker to exfiltrate data they shouldn’t be able to access from the local memory of vulnerable GPUs, exposing whatever data happens to be there for the taking, which could include queries and responses generated by LLMs as well as the weights driving the response.
In their proof of concept, as seen in the GIF below, the researchers demonstrate an attack where a target—shown on the left—asks the open source LLM Llama.cpp to provide details about WIRED magazine. Within seconds, the attacker’s device—shown on the right—collects the majority of the response provided by the LLM by carrying out a LeftoverLocals attack on vulnerable GPU memory. The attack program the researchers created uses less than 10 lines of code.
An attacker (right) exploits the LeftoverLocals vulnerability to listen to LLM conversations.
Last summer, the researchers tested 11 chips from seven GPU makers and multiple corresponding programming frameworks. They found the LeftoverLocals vulnerability in GPUs from Apple, AMD, and Qualcomm and launched a far-reaching coordinated disclosure of the vulnerability in September in collaboration with the US-CERT Coordination Center and the Khronos Group, a standards body focused on 3D graphics, machine learning, and virtual and augmented reality.
The researchers did not find evidence that Nvidia, Intel, or Arm GPUs contain the LeftoverLocals vulnerability, but Apple, Qualcomm, and AMD all confirmed to WIRED that they are impacted. This means that well-known chips like the AMD Radeon RX 7900 XT and devices like Apple’s iPhone 12 Pro and M2 MacBook Air are vulnerable. The researchers did not find the flaw in the Imagination GPUs they tested, but others may be vulnerable.



























{kind=link}
{kind=link}
{kind=link}
{kind=link}