Cutting-edge Chinese “reasoning” model rivals OpenAI o1—and it’s free to download
Unlike conventional LLMs, these SR models take extra time to produce responses, and this extra time often increases performance on tasks involving math, physics, and science. And this latest open model is turning heads for apparently quickly catching up to OpenAI.
For example, DeepSeek reports that R1 outperformed OpenAI’s o1 on several benchmarks and tests, including AIME (a mathematical reasoning test), MATH-500 (a collection of word problems), and SWE-bench Verified (a programming assessment tool). As we usually mention, AI benchmarks need to be taken with a grain of salt, and these results have yet to be independently verified.
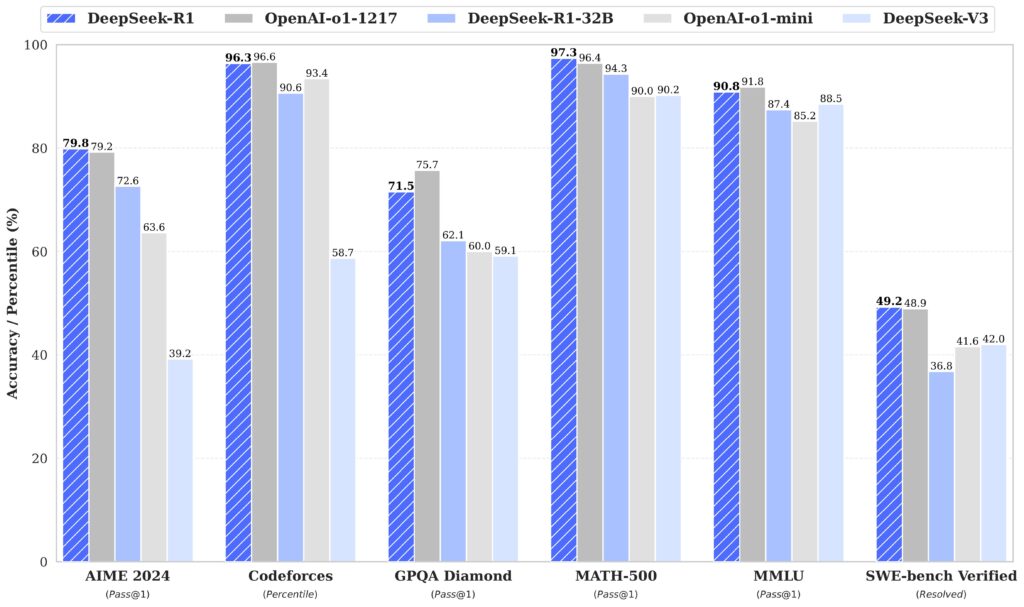
A chart of DeepSeek R1 benchmark results, created by DeepSeek. Credit: DeepSeek
TechCrunch reports that three Chinese labs—DeepSeek, Alibaba, and Moonshot AI’s Kimi—have now released models they say match o1’s capabilities, with DeepSeek first previewing R1 in November.
But the new DeepSeek model comes with a catch if run in the cloud-hosted version—being Chinese in origin, R1 will not generate responses about certain topics like Tiananmen Square or Taiwan’s autonomy, as it must “embody core socialist values,” according to Chinese Internet regulations. This filtering comes from an additional moderation layer that isn’t an issue if the model is run locally outside of China.
Even with the potential censorship, Dean Ball, an AI researcher at George Mason University, wrote on X, “The impressive performance of DeepSeek’s distilled models (smaller versions of r1) means that very capable reasoners will continue to proliferate widely and be runnable on local hardware, far from the eyes of any top-down control regime.”
Cutting-edge Chinese “reasoning” model rivals OpenAI o1—and it’s free to download Read More »