New AI model turns photos into explorable 3D worlds, with caveats
Training with automated data pipeline
Voyager builds on Tencent’s earlier HunyuanWorld 1.0, released in July. Voyager is also part of Tencent’s broader “Hunyuan” ecosystem, which includes the Hunyuan3D-2 model for text-to-3D generation and the previously covered HunyuanVideo for video synthesis.
To train Voyager, researchers developed software that automatically analyzes existing videos to process camera movements and calculate depth for every frame—eliminating the need for humans to manually label thousands of hours of footage. The system processed over 100,000 video clips from both real-world recordings and the aforementioned Unreal Engine renders.
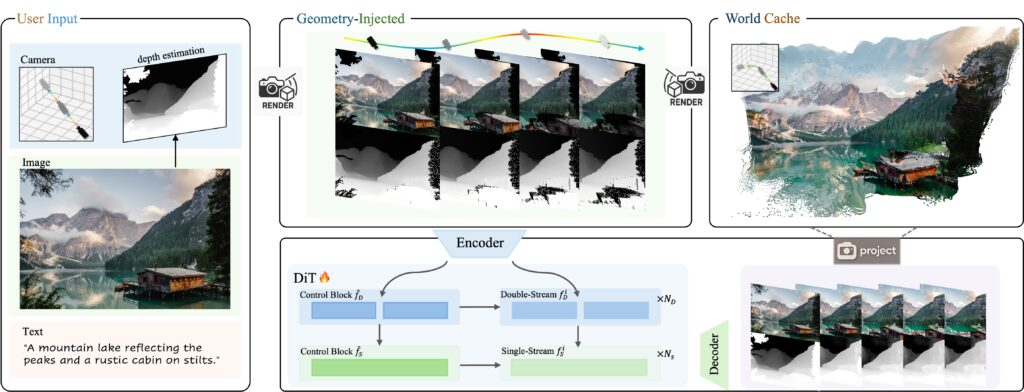
A diagram of the Voyager world creation pipeline. Credit: Tencent
The model demands serious computing power to run, requiring at least 60GB of GPU memory for 540p resolution, though Tencent recommends 80GB for better results. Tencent published the model weights on Hugging Face and included code that works with both single and multi-GPU setups.
The model comes with notable licensing restrictions. Like other Hunyuan models from Tencent, the license prohibits usage in the European Union, the United Kingdom, and South Korea. Additionally, commercial deployments serving over 100 million monthly active users require separate licensing from Tencent.
On the WorldScore benchmark developed by Stanford University researchers, Voyager reportedly achieved the highest overall score of 77.62, compared to 72.69 for WonderWorld and 62.15 for CogVideoX-I2V. The model reportedly excelled in object control (66.92), style consistency (84.89), and subjective quality (71.09), though it placed second in camera control (85.95) behind WonderWorld’s 92.98. WorldScore evaluates world generation approaches across multiple criteria, including 3D consistency and content alignment.
While these self-reported benchmark results seem promising, wider deployment still faces challenges due to the computational muscle involved. For developers needing faster processing, the system supports parallel inference across multiple GPUs using the xDiT framework. Running on eight GPUs delivers processing speeds 6.69 times faster than single-GPU setups.
Given the processing power required and the limitations in generating long, coherent “worlds,” it may be a while before we see real-time interactive experiences using a similar technique. But as we’ve seen so far with experiments like Google’s Genie, we’re potentially witnessing very early steps into a new interactive, generative art form.
New AI model turns photos into explorable 3D worlds, with caveats Read More »