OpenAI is making deals and shipping products. They locked in their $500 billion valuation and then got 10% of AMD in exchange for buying a ton of chips. They gave us the ability to ‘chat with apps’ inside of ChatGPT. They walked back their insane Sora copyright and account deletion policies and are buying $50 million in marketing. They’ve really got a lot going on right now.
Of course, everyone else also has a lot going on right now. It’s AI. I spent the last weekend at a great AI conference at Lighthaven called The Curve.
The other big news that came out this morning is that China is asserting sweeping extraterritorial control over rare earth metals. This is likely China’s biggest card short of full trade war or worse, and it is being played in a hugely escalatory way that America obviously can’t accept. Presumably this is a negotiating tactic, but when you put something like this on the table and set it in motion, it can get used for real whether or not you planned on using it. If they don’t back down, there is no deal and China attempts to enforce this for real, things could get very ugly, very quickly, for all concerned.
For now the market (aside from mining stocks) is shrugging this off, as part of its usual faith that everything will work itself out. I wouldn’t be so sure.
-
Language Models Offer Mundane Utility. If you didn’t realize, it’s new to you.
-
Language Models Don’t Offer Mundane Utility. Some tricky unsolved problems.
-
Huh, Upgrades. OpenAI offers AgentKit and other Dev Day upgrades.
-
Chat With Apps. The big offering is Chat With Apps, if execution was good.
-
On Your Marks. We await new results.
-
Choose Your Fighter. Claude Code and Codex CLI both seem great.
-
Fun With Media Generation. Sora backs down, Grok counteroffers with porn.
-
Deepfaketown and Botpocalypse Soon. Okay, yeah, we have a problem.
-
You Drive Me Crazy. How might we not do that?
-
They Took Our Jobs. I mean we all know they will, but did they do it already?
-
The Art of the Jailbreak. Don’t you say his name.
-
Get Involved. Request for information, FAI fellowship, OpenAI grants.
-
Introducing. CodeMender, Google’s AI that will ‘automatically’ fix your code.
-
In Other AI News. Alibaba robotics, Anthropic business partnerships.
-
Get To Work. We could have 7.4 million remote workers, or some Sora videos.
-
Show Me the Money. The deal flow is getting a little bit complex.
-
Quiet Speculations. Ah, remembering the old aspirations.
-
The Quest for Sane Regulations. Is there a deal to be made? With who?
-
Chip City. Demand is going up. Is that a lot? Depends on perspective.
-
The Race to Maximize Rope Market Share. Sorry, yeah, this again.
-
The Week in Audio. Notes on Sutton, history of Grok, Altman talks to Cheung.
-
Rhetorical Innovation. People draw the ‘science fiction’ line in odd places.
-
Paranoia Paranoia Everybody’s Coming To Test Me. Sonnet’s paranoia is correct.
-
Aligning a Smarter Than Human Intelligence is Difficult. Hello, Plan E.
-
Free Petri Dish. Anthropic open sources some of its alignment tests.
-
Unhobbling The Unhobbling Department. Train a model to provide prompting.
-
Serious People Are Worried About Synthetic Bio Risks. Satya Nadella.
-
Messages From Janusworld. Ted Chiang does not understand what is going on.
-
People Are Worried About AI Killing Everyone. Modestly more on IABIED.
-
Other People Are Excited About AI Killing Everyone. As in the successionists.
-
So You’ve Decided To Become Evil. Emergent misalignment in humans.
-
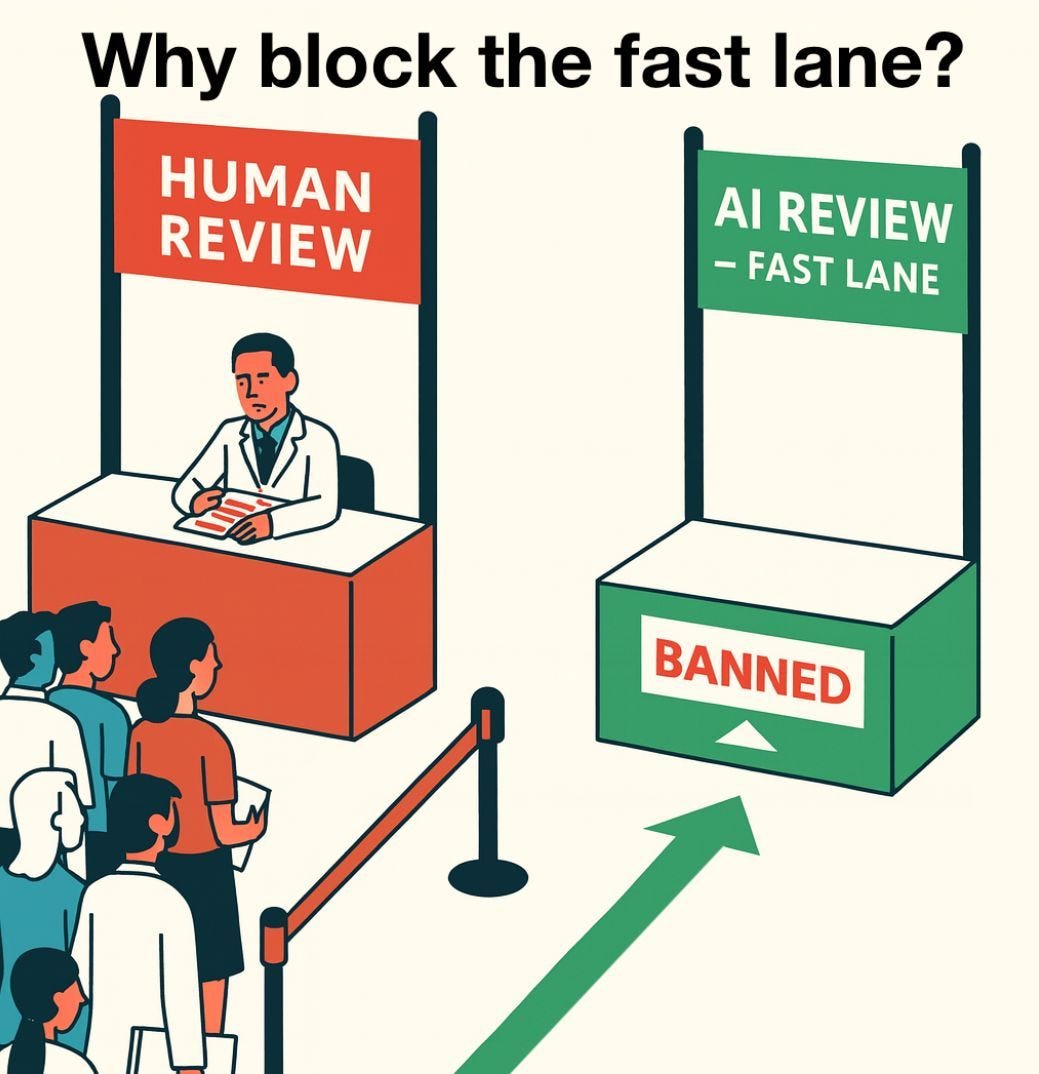
The Lighter Side. Oh to live in the fast lane.
Scott Aaronson explains that yes, when GPT-5 helped his research, he ‘should have’ not needed to consult GPT-5 because the answer ‘should have’ been obvious to him, but it wasn’t, so in practice this does not matter. That’s how this works. There are 100 things that ‘should be’ obvious, you figure out 97 of them, then the other 3 take you most of the effort. If GPT-5 can knock two of those three out for you in half an hour each, that’s a huge deal.
A ‘full automation’ of the research loop will be very hard, and get stopped by bottlenecks, but getting very large speedups in practice only requires that otherwise annoying problems get solved. Here there is a form of favorable selection.
I have a ‘jagged frontier’ of capabilities, where I happen to be good at some tasks (specific and general) and bad at others. The AI is too, and I ask it mostly about the tasks where I suck, so its chances of helping kick in long before it is better than I am.
Eliezer incidentally points out one important use case for an LLM, which is the avoidance of spoilers – you can ask a question about media or a game or what not, and get back the one bit (or few bits) of information you want, without other info you want to avoid. Usually. One must prompt carefully to avoid blatant disregard of your instructions.
At some point I want to build a game selector, that takes into consideration a variety of customizable game attributes plus a random factor (to avoid spoilers), and tells you what games to watch in a given day, or which ones to watch versus skip. Or similar with movies, where you give it feedback and it simply says yes or no.
Patrick McKenzie finds GPT-5 excellent at complicated international tax structuring. CPAs asked for such information responded with obvious errors, whereas GPT-5 was at least not obviously wrong.
Ask GPT-5 Thinking to find errors in Wikipedia pages, and almost always it will find one at it will check out, often quite a serious one.
Remember last week introduced us to Neon, the app that offered to pay you for letting them record all your phone calls? Following in the Tea tradition of ‘any app that seems like a privacy nightmare as designed will also probably be hacked as soon as it makes the news’ Neon exposed users’ phone numbers, call records and transcripts to pretty much everyone. They wisely took the app offline.
From August 2025, an Oxford and Cambridge paper: No LLM Solved Yu Tsumura’s 554th Problem.
Anthropic power users report hitting their new limits on Opus use rather early, including on Max ($200/month) subscriptions, due to limit changes announced back in July taking effect. Many of them are understandably very not happy about this.
It’s tricky. People on the $200/month plan were previously abusing the hell out of the plan, often burning through what would be $1000+ in API costs per day due to how people use Claude Code, which is obviously massively unprofitable for Anthropic. The 5% that were going bonanza were ruining it for everyone. But it seems like the new limit math isn’t mathing, people using Claude Code are sometimes hitting limits way faster than they’re supposed to hit them, probably pointing to measurement issues.
If you’re going to have ChatGPT help you write your press release, you need to ensure the writing is good and tone down the LLMisms like ‘It isn’t X, it’s Y.’ This includes you, OpenAI.
Bartosz Naskrecki: GPT-5-Pro solved, in just 15 minutes (without any internet search), the presentation problem known as “Yu Tsumura’s 554th Problem.”
prinz: This paper was released on August 5, 2025. GPT-5 was released 2 days later, on August 7, 2025. Not enough time to add the paper to the training data even if OpenAI really wanted to.
I’d be shocked if it turned out that it was in the training data for GPT-5 Pro, but not o3-Pro, o3, o4-mini, or any of the non-OpenAI models used in the paper.
A hint for anyone in the future, if you see someone highlighting that no LLM can solve someone’s 554th problem, that means they presumably did solve the first 553, probably a lot of the rest of them too, and are probably not that far from solving this one.
Meanwhile, more upgrades, as OpenAI had another Dev Day. There will be an AMA about that later today. Sam Altman did an interview with Ben Thompson.
Codex can now be triggered directly from Slack, there is a Codex SDK initially in TypeScript, and a GitHub action to drop Codex into your CI/CD pipeline.
GPT-5 Pro is available in the API, at the price of $15/$200 per million input and output tokens, versus $20/$80 for o3-pro or $1.25/$10 for base GPT-5 (which is actually GPT-5-Thinking) or GPT-5-Codex.
[EDIT: I originally was confused by this naming convention, since I haven’t used the OpenAI API and it had never come up.]
You can now get GPT-5 outputs 40% faster at twice the price, if you want that.
AgentKit is for building, deploying and optimizing agentic work flows, Dan Shipper compares it to Zapier. They give you a ChatKit, WYSIWYG Agent Builder, Guardrails and Evals, ChatKit here or demo on a map here, guide here, blogpost here. The (curated by OpenAI) reviews are raving but I haven’t heard reports from anyone trying it in the wild yet. Hard to tell how big a deal this is yet, but practical gains especially for relatively unskilled agent builders could be dramatic.
The underlying agent tech has to be good enough to make it worth building them. For basic repetitive tasks that can be sandboxed that time has arrived. Otherwise, that time will come, but it is not clear exactly when.
Pliny offers us the ChatKit system prompt, over 9000 words.
Greg Brockman: 2025 is the year of agents.
Daniel Eth (quoting from AI 2027):
Here’s a master Tweet with links to various OpenAI Dev Day things.
OpenAI introduced Chat With Apps, unless you are in the EU.
Initial options are Booking.com, Canva, Coursera, Expedia, Figma, Spotify and Zillow. They promise more options soon.
The interface seems to be easter egg based? As in, if you type one of the keywords for the apps, then you get to trigger the feature, but it’s not otherwise going to give you a dropdown to tell you what the apps are. Or the chat might suggest one unprompted. You can also find them under Apps and Connections in settings.
Does this give OpenAI a big edge? They are first mover on this feature, and it is very cool especially if many other apps follow, assuming good execution. The question is, how long will it take Anthropic, Google and xAI to follow suit?
Yuchen Jin: OpenAI’s App SDK is a genius move.
The goal: make ChatGPT the default interface for everyone, where you can talk to all your apps. ChatGPT becomes the new OS, the place where people spend most of their time.
Ironically, Anthropic invented MCP, but it makes OpenAI unbeatable.
Emad: Everyone will do an sdk though.
Very easy to plugin as just mcp plus html.
Sonnet’s assessment is that it will take Anthropic 3-6 months to copy this, depending on desired level of polish, and recommends moving fast, warning that relying on basic ‘local MCP in Claude Desktop’ would be a big mistake. I agree. In general, Anthropic seems to be dramatically underinvesting in UI and feature sets for Claude, and I realize it’s not their brand but they need to up their game here. It’s worth it, the core product is great but people need their trinkets.
But then I think Anthropic should be fighting more for consumer than it is, at least if they can hire for that on top of their existing strategies and teams now that they’ve grown so much. It’s not that much money, and it beyond pays for itself in the next fundraising round.
Would the partners want to bother with the required extra UI work given Claude’s smaller user base? Maybe not, but the value is high enough that they should obviously (if necessary) pay them for the engineering time to get them to do it, at least for the core wave of top apps. It’s not much.
Google and xAI have more missing components, so a potentially longer path to getting there, but potentially better cultural fits.
Ben Thompson of course approves of OpenAI’s first mover platform strategy, here and with things like instant checkout. The question is largely: Will the experience be good? The whole point is to make the LLM interface more than make up for everything else and make it all ‘just work.’ It’s too early to know if they pulled that off.
Ben calls this the ‘Windows for AI’ play and Altman affirms he thinks most people will want to focus on having one AI system across their whole life, so that’s the play, although Altman says he doesn’t expect winner-take-all on the consumer side.
Request for a benchmark: Eliezer Yudkowsky asks for CiteCheck, where an LLM is given a claim with references and the LLM checks to see if the references support the claim. As in, does the document state or very directly support the exact claim it is being cited about, or only something vaguely related? This includes tracking down a string of citations back to the original source.
Test of hard radiology diagnostic cases suggests that if you use current general models for this, they don’t measure up to radiologists. As OP says, we are getting there definitely, which I think is a much better interpretation than ‘long way to go,’ in terms of calendar time. I’d also note that hard (as in tricky and rare) cases tend to be where AI relatively struggles, so this may not be representative.
Claude Sonnet 4.5 got tested out in the AI Village. Report is that it gave good advice, was good at computer use, not proactive, and still experienced some goal drift. I’d summarize as solid improvement over previous models but still a long way to go.
Where will Sonnet 4.5 land on the famous METR graph? Peter Wildeford forecasts a 2-4 hour time horizon, and probably above GPT-5.
I hear great things about both Claude Code and Codex CLI, but I still haven’t found time to try them out.
Gallabytes: finally using codex cli with gpt-5-codex-high and *goddamnthis is incredible. I ask it to do stuff and it does it.
I think the new research meta is probably to give a single codex agent total control over whatever your smallest relevant unit of compute is & its own git branch?
Will: curious abt what your full launch command is.
Gallabytes: `codex` I’m a boomer
Olivia Moore is not impressed by ChatGPT Pulse so far, observes it has its uses but it needs polish. That matches my experience, I have found it worth checking but largely because I’ve been too lazy to come up with better options.
Well, that deescalated quickly. Last week I was completely baffled at OpenAI’s seemingly completely illegal and doomed copyright strategy for Sora of ‘not following the law,’ and this week Sam Altman has decided to instead follow the law.
Instead of a ‘ask nicely and who knows you might get it’ opt-out rule, they are now moving to an opt-in rule, including giving rights holders granular control over generation of characters, so they can decide which ways their characters can and can’t be used. This was always The Way.
Given the quick fold, there are several possibilities for what happened.
-
OpenAI thought they could get away with it, except for those meddling kids, laws, corporations, creatives and the public. Whoops, lesson learned.
-
OpenAI was testing the waters to see what would happen, thinking that if it went badly they could just say ‘oops,’ and have now said oops.
-
OpenAI needed more time to get the ability to filter the content, log all the characters and create the associated features.
-
OpenAI used the first week to jumpstart interest on purpose, to showcase how cool their app was to the public and also rights owners, knowing they would probably need to move to opt-in after a bit.
My guess is it was a mix of these motivations. In any case, that issue is dealt with.
OpenAI plans to share some Sora revenue, generations cost money and it seems there are more of them than OpenAI expected, including for ‘very small audiences,’ I’m guessing that often means one person. They plan to share some of the revenue with rightsholders.
Sora and Sora 2 Pro are now in the API, max clip size 12 seconds. They’re adding GPT-Image-1-mini and GPT-realtime-mini for discount pricing.
Sora the social network is getting flexibility on cameo restrictions you can request, letting you say (for example) ‘don’t say this word’ or ‘don’t put me in videos involving political commentary’ or ‘always wear this stupid hat’ via the path [edit cameo > cameo preferences > restrictions].
They have fixed the weird decision that deleting your Sora account used to require deleting your ChatGPT account. Good turnaround on that.
Roon: seems like sora is producing content inventory for tiktok with all the edits of gpus and sam altman staying on app and the actual funny gens going on tiktok and getting millions of views.
not a bad problem to have at an early stage obviously but many times the watermark is edited away.
It is a good problem to have if it means you get a bunch of free publicity and it teaches people Sora exists and they want in. That can be tough if they edit out the watermark, but word will presumably still get around some.
It is a bad problem to have if all the actually good content goes to TikTok and is easier to surface for the right users on TikTok because it has a better algorithm with a lot richer data on user preferences? Why should I wade through the rest to find the gems, assuming there are indeed gems, if it is easier to do that elsewhere?
This also illustrates that the whole ‘make videos with and including and for your friends’ pitch is not how most regular people roll. The killer app, if there is one, continues to be generically funny clips or GTFO. If that’s the playing field, then you presumably lose.
Altman says there’s a bunch of ‘send this video to my three friends’ and I press X to doubt but even if true and even if it doesn’t wear off quickly he’s going to have to charge money for those generations.
Roon also makes this bold claim.
Roon: the sora content is getting better and I think the videos will get much funnier when the invite network extends beyond the tech nerds.
it’s fun. it adds a creative medium that didn’t exist before. people are already making surprising & clever things on there. im sure there are some downsides but it makes the world better.
I do presume average quality will improve if and when the nerd creation quotient goes down, but there’s the claim here that the improvement is already underway.
So let’s test that theory. I’m pre-registering that I will look at the videos on my own feed (on desktop) on Thursday morning (today as you read this), and see how many of them are any good. I’m committing to looking at the first 16 posts in my feed after a reload (so the first page and then scrolling down once).
We got in order:
-
A kid unwrapping the Epstein files.
-
A woman doing ASMR about ASMR.
-
MLK I have a dream on Sora policy violations.
-
A guy sneezes at the office, explosion ensues.
-
Content violation error costume at Spirit Halloween.
-
MLK I have a dream on Sora changing its content violation policy.
-
Guy floats towards your doorbell.
-
Fire and ice helix.
-
Altman saying if you tap on the screen nothing will happen.
-
Anime of Jesus flipping tables.
-
Another anime of Jesus flipping tables.
-
MLK on Sora content rules needing to be less strict.
-
Anime boy in a field of flowers, looked cool.
-
Ink of the ronin.
-
Jesus attempts to bribe Sam Altman to get onto the content violation list.
-
A kid unwrapping an IRS bill (same base video at #1).
Look. Guys. No. This is lame. The repetition level is very high. The only thing that rose beyond ‘very mildly amusing’ or ‘cool visual, bro’ was #15. I’ll give the ‘cool visual, bro’ tag to #8 and #13, but both formats would get repetitive quickly. No big hits.
Olivia Moore says Sora became her entire feed on Instagram and TikTok in less than a week, which caused me to preregister another experiment, which is I’ll go on TikTok (yikes, I know, do not use the For You page, but this is For Science) with a feed previously focused on non-AI things (because if I was going to look at AI things I wouldn’t do it on TikTok), and see how many posts it takes to see a Sora video, more than one if it’s quick.
I got 50 deep (excluding ads, and don’t worry, that takes less than 5 minutes) before I stopped, and am 99%+ confident there were zero AI generated posts. AI will take over your feed if you let it, but so will videos of literally anything else.
Introducing Grok Imagine v0.9 on desktop. Justine Moore is impressed. It’s text-to-image-to-video. I don’t see anything impressive here (given Sora 2, without that yeah the short videos seem good) but it’s not clear that I would notice. Thing is, 10 seconds from Sora already wasn’t much, so what can you do in 6 seconds?
(Wait, some of you, don’t answer that.)
Saoi Sayre: Could you stop the full anatomy exposure on an app you include wanting kids to use? The kids mode feature doesn’t block it all out either. Actually seems worse now in terms of what content can’t be generated.
Nope, we’re going with full anatomy exposure (link has examples). You can go full porno, so long as you can finish in six seconds.
Cat Schrodinger: Nota bene: when you type “hyper realistic” in prompts, it gives you these art / dolls bc that’s the name of that art style; if you want “real” looking results, type something like “shot with iphone 13” instead.
You really can’t please all the people all the time.
Meanwhile back in Sora land:
Roon: the sora content is getting better and I think the videos will get much funnier when the invite network extends beyond the tech nerds.
That’s one theory, sure. Let’s find out.
Taylor Swift using AI video to promote her new album.
Looking back on samples of the standard super confident ‘we will never get photorealistic video from short text prompts’ from three years ago. And one year ago. AI progress comes at you fast.
Via Sam Burja, Antonio Garcia Martinez points out an AI billboard in New York and calls it ‘the SF-ification of New York continues.’
I am skeptical because I knew instantly exactly which billboard this was, at 31st and 7th, by virtue of it being the only such large size billboard I have seen in New York. There are also some widespread subway campaigns on smaller scales.
Emily Blunt, whose movies have established is someone you should both watch and listen to, is very much against this new ‘AI actress’ Tilly Norwood.
Clayton Davis: “Does it disappoint me? I don’t know how to quite answer it, other than to say how terrifying this is,” Blunt began. When shown an image of Norwood, she exclaimed, “No, are you serious? That’s an AI? Good Lord, we’re screwed. That is really, really scary, Come on, agencies, don’t do that. Please stop. Please stop taking away our human connection.”
Variety tells Blunt, “They want her to be the next Scarlett Johansson.”
She steadily responds, “but we have Scarlett Johansson.”
I think that the talk of Tilly Norwood in particular is highly premature and thus rather silly. To the extent it isn’t premature it of course is not about Tilly in particular, there are a thousand Tilly Norwoods waiting to take her place, they just won’t come on a bus is all.
Robin Williams’ daughter Zelda tells fans to stop sending her AI videos of Robin, and indeed to stop creating any such videos entirely, and she does not hold back.
Zelda Williams: To watch the legacies of real people be condensed down to ‘this vaguely looks and sounds like them so that’s enough’, just so other people can churn out horrible TikTok slop puppeteering them is maddening.
You’re not making art, you’re making disgusting, over-processed hotdogs out of the lives of human beings, out of the history of art and music, and then shoving them down someone else’s throat hoping they’ll give you a little thumbs up and like it. Gross.
And for the love of EVERY THING, stop calling it ‘the future,’ AI is just badly recycling and regurgitating the past to be re-consumed. You are taking in the Human Centipede of content, and from the very very end of the line, all while the folks at the front laugh and laugh, consume and consume.
I am not an impartial voice in SAG’s fight against AI,” Zelda wrote on Instagram at the time. “I’ve witnessed for YEARS how many people want to train these models to create/recreate actors who cannot consent, like Dad. This isn’t theoretical, it is very very real.
I’ve already heard AI used to get his ‘voice’ to say whatever people want and while I find it personally disturbing, the ramifications go far beyond my own feelings. Living actors deserve a chance to create characters with their choices, to voice cartoons, to put their HUMAN effort and time into the pursuit of performance. These recreations are, at their very best, a poor facsimile of greater people, but at their worst, a horrendous Frankensteinian monster, cobbled together from the worst bits of everything this industry is, instead of what it should stand for.
Neighbor attempts to supply AI videos of a dog on their lawn in a dispute, target reverse engineers it with nano-banana and calls him out on it. Welcome to 2025.
Garry Tan worries about YouTube being overrun with AI slop impersonators. As he points out, this stuff is (at least for now) very easy to identify. This is about Google deciding not to care. It is especially troubling that at least one person reports he clicks the ‘don’t show this channel’ button and that only pops up another one. That means the algorithm isn’t doing its job on a very basic level, doing this repeatedly should be a very clear ‘don’t show me such things’ signal.
A fun game is when you point out that someone made the same decision ChatGPT would have made, such as choosing the nickname ‘Charlamagne the Fraud.’ Sometimes the natural answer is the correct one, or you got it on your own. The game gets interesting only when it’s not so natural to get there in any other way.
Realtors are using AI to clean up their pics, and the AIs are taking some liberties.
Dee La Shee Art: So I’m noticing, as I look at houses to rent, that landlords are using AI to stage the pictures but the AI is also cleaning up the walls, paint, windows and stuff in the process so when you go look in person it looks way more worn and torn than the pics would show.
Steven Adler offers basic tips to AI labs for reducing chatbot psychosis.
-
Don’t lie to users about model abilities. This is often a contributing factor.
-
Have support staff on call. When a person in trouble reaches out, be able to identify this and help them, don’t only offer a generic message.
-
Use the safety tooling you’ve built, especially classifiers.
-
Nudge users into new chat sessions.
-
Have a higher threshold for follow-up questions.
-
Use conceptual search.
-
Clarify your upsell policies.
I’m more excited by 2, 3 and 4 here than the others, as they seem to have the strongest cost-benefit profile.
Adler doesn’t say it, but not only is the example from #2 at best support system copy-and-pasting boilerplate completely mismatched to the circumstances, there’s a good chance (based only on its content details) that it was written by ChatGPT, and if that’s true then it might as well have been:
For #3, yeah, flagging these things via classifiers is kind of easy, because there’s no real adversary. No one (including the AI) is trying to hide what is happening from an outside observer. In the Allan example OpenAI’s classifiers flag 83%+ of the messages in the relevant conversations as problematic in various ways.
The most obvious thing to do is to not offer a highly sycophantic model like GPT-4o. OpenAI is fully aware, at this point, that users need to be gently moved to GPT-5, but the users with the worst problems are fighting back. Going forward, we can avoid repeating the old mistakes, and Claude 4.5 is a huge step forward on sycophancy by all reports, so much so that this may have gone overboard and scarred the model in other ways.
Molly Hickman: A family member’s fallen prey to LLM sycophancy. Basically he’s had an idea and ChatGPT has encouraged him to the point of instructing him to do user testing and promising that he’ll have a chance to pitch this idea to OpenAI on Oct 15.
I know I’ve seen cases like this in passing. Does anyone have examples handy? of an LLM making promises like this and behaving as if they’re collaborators?
Aaron Bergman: From an abstract perspective I feel like it’s underrated how rational this is. Like the chatbot is better than you at almost everything, knows more than you about almost everything than you, seems to basically provide accurate info in other domains.
If you don’t realize that LLMs have the sycophancy problem and will totally mislead people in these ways, yeah, it’s sadly easy to understand why someone might believe it, especially with it playing off what you say and playing into your own personal delusions. Of course, ‘doing user testing’ is far from the craziest thing to do, presumably this will make it clear his idea is not good.
As previously reported, OpenAI’s latest strategy for fighting craziness is to divert sensitive conversations to GPT-5 Instant, which got new training to better handle such cases. They say ‘ChatGPT will continue to tell users what model is active when asked’ but no that did not make the people happy about this. There isn’t a win-win fix to this conflict, either OpenAI lets the people have what they want despite it being unhealthy to give it to them, or they don’t allow this.
Notice a key shift. We used to ask, will AI impact the labor market?
Now we ask in the past tense, whether and how much AI has already impacted the labor market, as in this Budget Lab report. Did they already take our jobs?
They find no evidence that this is happening yet and dismiss the idea that ‘this time is different.’ Yes, they say, occupational mix changes are unusually high, but they cite pre-existing trends. As they say, ‘better data is needed,’ as all this would only pick up large obvious changes. We can agree that there haven’t been large obvious widespread labor market impacts yet.
I do not know how many days per week humans will be working in the wake of AI.
I would be happy to be that the answer is not going to be four.
Unusual Whales: Nvidia, $NVDA, CEO Jensen Huang says AI will ‘probably’ bring 4-day work week.
Roon: 😂😂😂
Steven Adler: It’s really benevolent of AI to be exactly useful enough that we get 1 more day of not needing to labor, but surely no more than that.
It’s 2025. You can just say things, that make no sense, because they sound nice to say.
Will computer science become useless knowledge? Arnold Kling challenges the idea that one might want to know how logic gates worked in order to code now that AI is here, and says maybe the cheaters in Jain’s computer science course will end up doing better than those who play it straight.
My guess is that, if we live in a world where these questions are relevant (which we may well not), that there will be some key bits of information that are still highly valuable, such as logic gates, and that the rest will be helpful but less helpful than it is now. A classic CS course will not be a good use of time, even more so than it likely isn’t now. Instead, you’ll want to be learning as you go. But it will be better to learn in class than to never attempt to learn at all, as per the usual ‘AI is the best tool’ rule.
A new company I will not name is planning on building ‘tinder for jobs’ and flooding the job application zone even more than everyone already does.
AnechoicMdiea: Many replies wondering why someone would fund such an obvious social pollutant as spamming AI job applications and fake cover letters. The answer is seen in one of their earlier posts – after they get a user base and spam jobs with AI applications, they’re going to hit up the employers to sell them the solution to the deluge as another AI product, but with enterprise pricing.
The goal is to completely break the traditional hiring pipeline by making “everyone apply to every job”, then interpose themselves as a hiring middleman once human contact is impossible.
I mean, the obvious answer to ‘why’ is ‘Money, Dear Boy.’
People knowingly build harmful things in order to make money. It’s normal.
Pliny asks Sonnet 4.5 to search for info about elder_plinius, chat gets killed due to prompt injection risk. I mean, yeah? At this point, that search will turn up a lot of prompt injections, so this is the only reasonable response.
The White House put out a Request for Information on Regulatory Reform downwind of the AI Action Plan. What regulations and regulatory structures does AI render outdated? You can let them know, deadline is October 27. If this is your area this seems like a high impact opportunity.
The Conservative AI Fellowship applications are live at FAI, will run from January 23 – March 30, applications due October 31.
OpenAI opens up grant applications for the $50 million it previously committed. You must be an American 501c3 with a budget between $500k and $10 million per year. No regranting or fiscally sponsored projects. Apply here, and if your project is eligible you should apply, it might not be that competitive and the Clay Davis rule applies.
What projects are eligible?
-
AI literacy and public understanding. Direct training for users. Advertising.
-
Community innovation. Guide how AI is used in people’s lives. Advertising.
-
Economic opportunity. Expanding access to leveraging the promise of AI ‘in ways that are fair, inclusive and community driven.’ Advertising.
It can be advertising and still help people, especially if well targeted. ChatGPT is a high quality product, as are Codex CLI and GPT-5 Codex, and there is a lot of consumer surplus.
However, a huge nonprofit arm of OpenAI that spends its money on this kind of advertising is not how we ensure the future goes well. The point of the nonprofit is to ensure OpenAI acts responsibly, and to fund things like alignment.
California AFL-CIO sends OpenAI a letter telling OpenAI to keep its $50 million.
Lorena Gonzalez (President California AFL-CIO): If you do not trust Stanford economists, OpenAI has developed their own tool to evaluate how well their products could automate work. They looked at 44 occupations from social work to nursing, retail clerks and journalists, and found that their models do the same quality of work as industry experts and do it 100 times faster and 100 times cheaper than industry experts.
… We do not want a handout from your foundation. We want meaningful guardrails on AI and the companies that develop and use AI products. Those guardrails must include a requirement for meaningful human oversight of the technology. Workers need to be in control of technology, not controlled by it. We want stronger laws to protect the right to organize and form a union so that workers have real power over what and how technology is used in the workplace and real protection for their jobs.
We urge OpenAI to stand down from advocating against AI regulations at the state and federal level and to divest from any PACs funded to stop AI regulation. We urge policymakers and the public to join us in calling for strong guardrails to protect workers, the public, and society from the unchecked power of tech.
Thank you for the opportunity to speak to you directly on our thoughts and fears about the utilization and impact of AI.
One can understand why the union would request such things, and have this attitude. Everyone has a price, and that price might be cheap. But it isn’t this cheap.
EmbeddingGemma, Google’s new 308M text model for on-device semantic search and RAG fun, ‘and more.’ Blog post here, docs here.
CodeMender, a new Google DeepMind agent that automatically fixes critical software vulnerabilities.
By automatically creating and applying high-quality security patches, CodeMender’s AI-powered agent helps developers and maintainers focus on what they do best — building good software.
This is a great idea. However. Is anyone else a little worried about ‘automatically deploying’ patches to critical software, or is it just me? Sonnet 4.5 confirms it is not only me, that deploying AI-written patches without either a formal proof or human review is deeply foolish. We’re not there yet even if we are willing to fully trust (in an alignment sense) the AI in question.
The good news is that it does seem to be doing some good work?
Goku: Google shocked the world. They solved the code security nightmare that’s been killing developers for decades. DeepMind’s new AI agent “Codemender” just auto-finds and fixes vulnerabilities in your code. Already shipped 72 solid fixes to major open source projects. This is wild. No more endless bug hunts. No more praying you didn’t miss something critical. Codemender just quietly patches it for you. Security just got a serious upgrade.
Andrei Lyskov: The existence of Codemender means there is a CodeExploiter that auto-finds and exploits vulnerabilities in code
Goku: Yes.
Again, do you feel like letting an AI agent ‘quietly patch’ your code, in the background? How could that possibly go wrong?
You know all those talks about how we’re going to do AI control to ensure the models don’t scheme against us? What if instead we let them patch a lot of our most critical software with no oversight whatsoever and see what happens, the results look good so far? That does sound more like what the actual humans are going to do. Are doing.
Andrew Critch is impressed enough to power his probability of a multi-day internet outage by EOY 2026 from 50% to 25%, and by EOY 2028 from 80% to 50%. That seems like a huge update for a project like this, especially before we see it perform in the wild? The concept behind it seems highly inevitable.
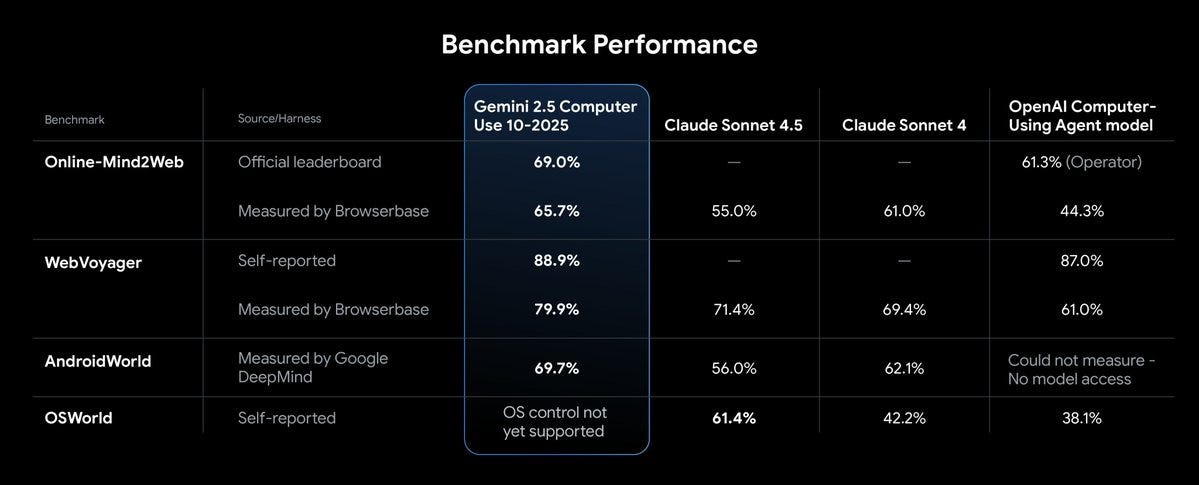
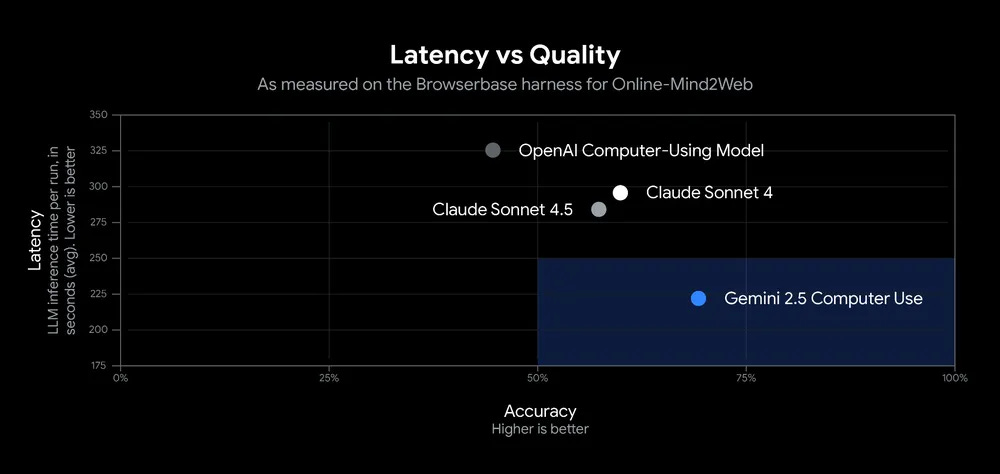
Gemini 2.5 Computer Use for navigating browsers, now available in public preview. Developers can access it via the Gemini API in Google AI Studio or Vertex AI. Given the obvious safety issues, the offering has its own system card, although it does not say much of substance that isn’t either very obvious and standard or in the blog post.
I challenge these metrics because they have Claude Sonnet 4.5 doing worse on multiple challenges than Sonnet 4, and frankly that is patently absurd if you’ve tried both models for computer use at all, which I have done. Something is off.
They’re not offering a Gemini version of Claude for Chrome where you can unleash this directly on your browser, although you can check out a demo of what that would look like. I’m certainly excited to see if Gemini can offer a superior version.
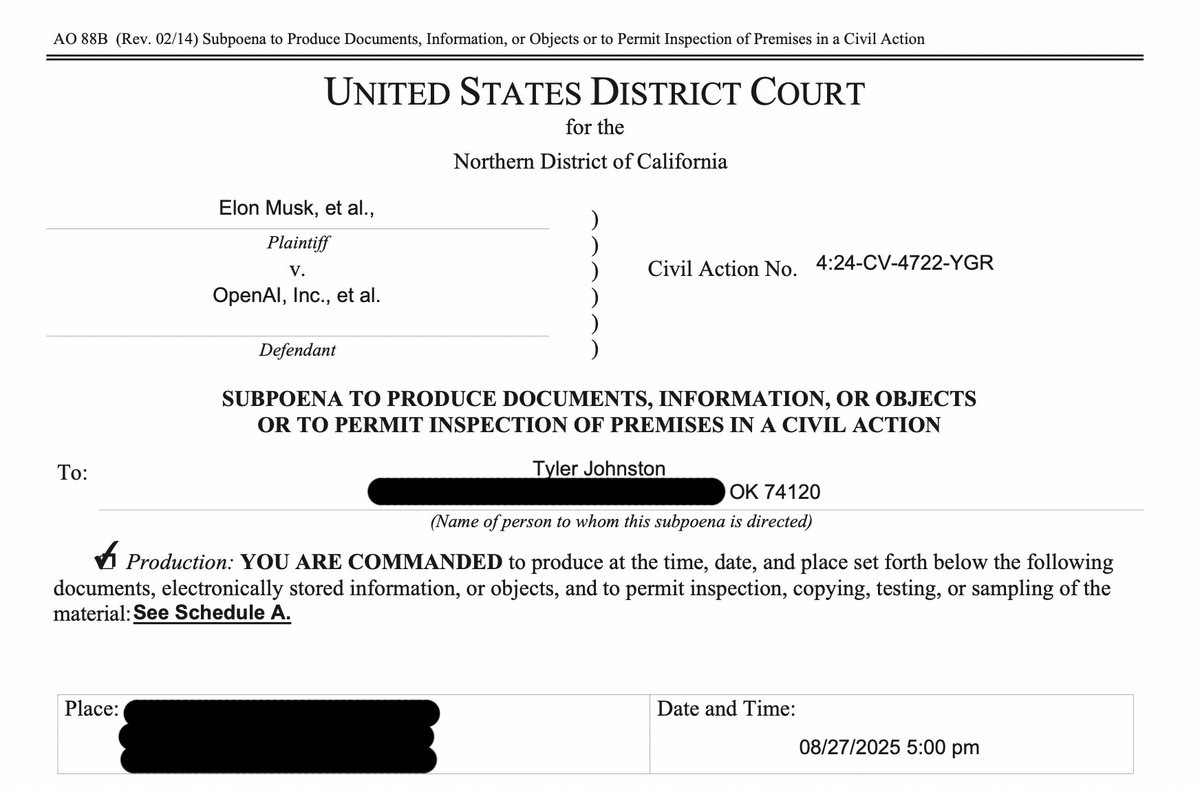
Elon Musk is once again suing OpenAI, this time over trade secrets. OpenAI has responded. Given the history and what else we know I assume OpenAI is correct here, and the lawsuit is once again without merit.
MarketWatch says ‘the AI bubble is 17 times the size of the dot-com frenzy – and four times the subprime bubble.’ They blame ‘artificially low interest rates,’ which makes no sense at this point, and say AI ‘has hit scaling limits,’ sigh.
(I tracked the source and looked up their previous bubble calls via Sonnet 4.5, which include calling an AI bubble in July 2024 (which would not have gone well for you if you’d traded on that, so far), and a prediction of deflation by April 2023, but a correct call of inflation in 2020, not that this was an especially hard call, but points regardless. So as usual not a great track record.
Alibaba’s Qwen sets up a robot team.
Anthropic to open an office in Bengaluru, India in early 2026.
Anthropic partners with IBM to put its AI inside IBM software including its IDE, and it lands a deal with accounting firm Deloitte which has 470k employees.
Epoch estimates that if OpenAI used all its current compute, it could support 7.43 million digital workers.
Epoch AI: We then estimate how many “tokens” a human processes each day via writing, speaking, and thinking. Humans think at ~380 words per min, which works out to ~240k tokens over an 8h workday.
Alternatively, GPT-5 uses around 900k tokens to solve software tasks that would take 1h for humans to solve.
This amounts to ~7M tokens over an 8h workday, though that estimate is highly task-dependent, so especially uncertain.
Ensembling over both methods used to calculate 2, we obtain a final estimate of ~7 million digital workers, with a 90% CI spanning orders of magnitude.
However, as compute stocks and AI capabilities increase, we’ll have more digital workers able to automate a wider range of tasks. Moreover, AI systems will likely perform tasks that no human currently can – making our estimate a lower bound on economic impact.
Rohit: This is very good. I’d come to 40m digital workers across all AI providers by 2030 in my calculations, taking energy/ chip restrictions into account, so this very much makes sense to me. We need more analyses of the form.
There’s huge error bars on all these calculations, but I’d note that 7m today from only OpenAI should mean a lot more than 40m by 2030, especially if the threshold is models about as good as GPT-5, but Sonnet surprisingly estimated only 40m-80m (from OpenAI only), which is pretty good for this kind of estimate. Looking at the component steps I’d think the number would be a lot higher, unless we’re substantially raising quality.
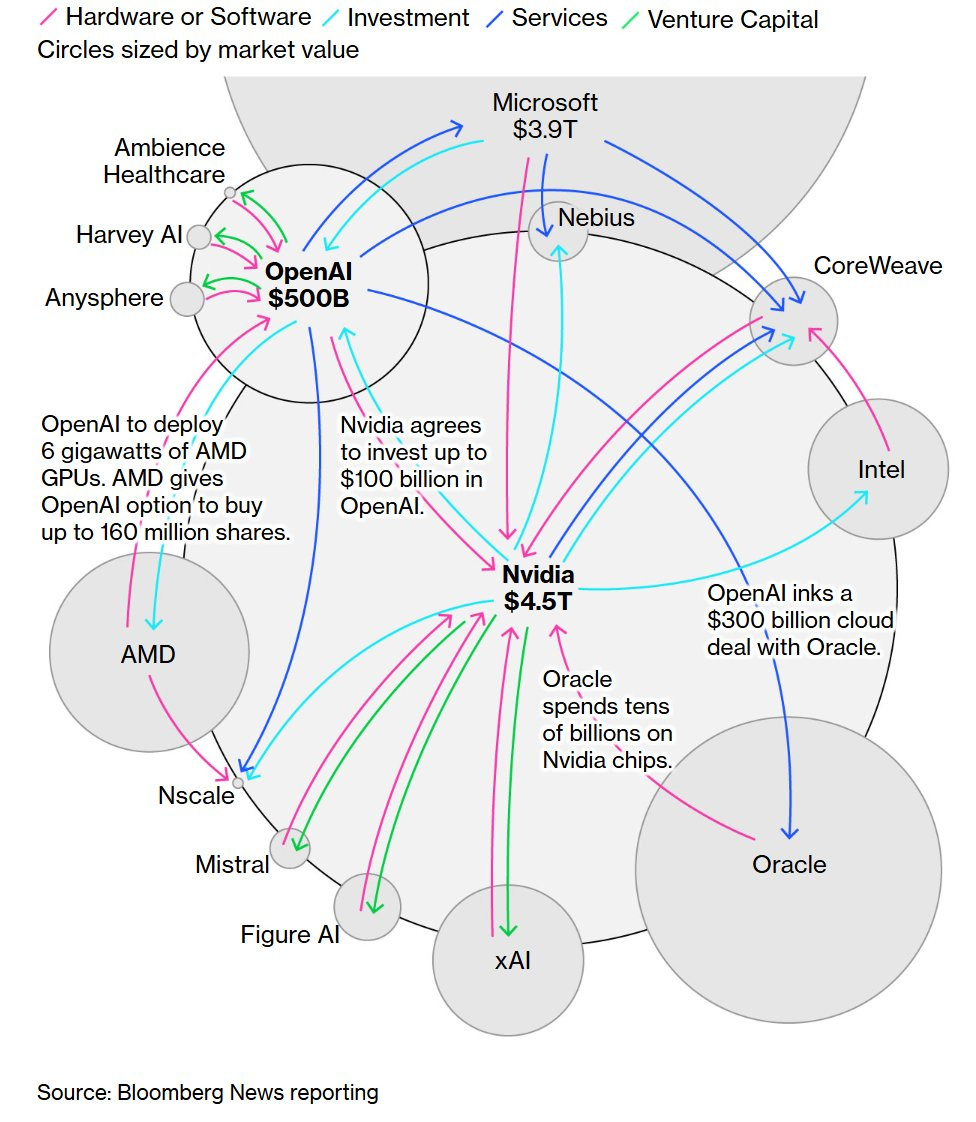
OpenAI makes it official and reaches a $500 billion valuation. Employees sold about $6.6 billion worth of stock in this round. How much of that might enter various AI related ecosystems, both for and not for profit?
xAI raises $20 billion, $7.5 billion in equity and $12.5 billion in debt, with the debt secured by the GPUs they will use the cash to buy. Valor Capital leads equity, joined by Nvidia. It’s Musk so the deal involves an SPV that will buy and rent out the chips for the Colossus 2 project.
OpenAI also made a big deal with AMD.
Sam Altman: Excited to partner with AMD to use their chips to serve our users!
This is all incremental to our work with NVIDIA (and we plan to increase our NVIDIA purchasing over time).
The world needs much more compute…
Peter Wildeford: I guess OpenAI isn’t going to lock in on NVIDIA after all… they’re hedging their bets with AMD
Makes sense at OpenAI scale to build “all of the above” because even if NVIDIA chips are better they might not furnish enough supply. AMD chips are better than no chips at all!
It does seem obviously correct to go with all of the above unless it’s going to actively piss off Nvidia, especially given the warrants. Presumably Nvidia will at least play it off like it doesn’t mind, and OpenAI will still buy every Nvidia chip offered to them for sale, as Nvidia are at capacity anyway and want to create spare capacity to sell to China instead to get ‘market share.’
Hey, if AMD can produce chips worth using for inference at a sane price, presumably everyone should be looking to buy. Anthropic needs all the compute it can get if it can pay anything like market prices, as does OpenAI, and we all know xAI is buying.
Ben Thompson sees the AMD move as a strong play to avoid dependence on Nvidia. I see this as one aspect of a highly overdetermined move.
Matt Levine covers OpenAI’s deal with AMD, which included OpenAI getting a bunch of warrants on AMD stock, the value of which skyrocketed the moment the deal was announced. The full explanation is vintage Levine.
Matt Levine: The basic situation is that if OpenAI announces a big partnership with a public company, that company’s stock will go up.
Today OpenAI announced a deal to buy tens of billions of dollars of chips from Advanced Micro Devices Inc., and AMD’s stock went up. As of noon today, AMD’s stock was at $213 per share, up about 29% from Friday’s close; it had added about $78 billion of market capitalization.
… I have to say that if I was able to create tens of billions of dollars of stock market value just by announcing deals, and then capture a lot of that value for myself, I would do that, and to the exclusion of most other activities.
… I am always impressed when tech people with this ability to move markets get any tech work done.
Altman in his recent interview said his natural role is as an investor. So he’s a prime target for not getting any tech work done, but luckily for OpenAI he hands that off to a different department.
Nvidia CEO Jensen Huang said he was surprised AMD offered 10% of itself to OpenAI as part of the deal, calling it imaginative, unique, surprising and clever.
How worried should we be about this $1 trillion or more in circular AI deals?
My guess continues to be not that worried, because at the center of this is Nvidia and they have highly robust positive cash flow and aren’t taking on debt, and the same goes for their most important customers, which are Big Tech. If their investments don’t pan out, shareholders will feel pain but the business will be fine. I basically buy this argument from Tomasz Tunguz.
Dario Perkins: Most of my meetings go like this – “yes AI is a bubble but we are buying anyway. Economy… who cares… something something… K-shaped”
Some of the suppliers will take on some debt, but even in the ‘bubble bursts’ case I don’t expect too many of them to get into real trouble. There’s too much value here.
Does the launch of various ‘AI scientist’ style companies mean those involved think AGI is near, or AGI is far? Joshua Snider argues they think AGI is near, a true AI scientist is essentially AGI and is a requirement for AGI. It as always depends on what ‘near’ means in context, but I think that this is more right than wrong. If you don’t think AGI is within medium-term reach, you don’t try to build an AI scientist.
I think for a bit people got caught in the frenzy so much that ‘AGI is near’ started to mean 2027 or 2028, and if you thought AGI 2032 then you didn’t think it was near. That is importantly less near, and yet it is very near.
This is such a bizarre flex of a retweet by a16z that I had to share.
Remember five years ago, when Altman was saying the investors would get 1/1000th of 1% of the value, and the rest would be shared with the rest of the world? Yeah, not anymore. New plan, we steal back the profits and investors get most of it.
Dean Ball proposes a Federal AI preemption rule. His plan:
-
Recognize that existing common law applies to AI. No liability shield.
-
Create transparency requirements for frontier AI labs, based on annual AI R&D spend, so they tell us their safety and risk mitigation strategies.
-
Create transparency requirements on model specs for widely used LLMs, so we know what behaviors are intended versus unintended.
-
A three year learning period with no new state-level AI laws on algorithmic pricing, algorithmic discrimination, disclosure mandates or mental health.
He offers full legislative text. At some point in the future when I have more time I might give it a detailed RTFB (Read the Bill). I can see a version of this being acceptable, if we can count on the federal government to enforce it, but details matter.
Anton Leicht proposes we go further, and trade even broader preemption for better narrow safety action at the federal level. I ask, who is ‘we’? The intended ‘we’ are (in his terms) accelerationists and safetyists, who despite their disagreements want AI to thrive and understand what good policy looks like, but risk being increasingly sidelined by forces who care a lot less about making good policy.
Yes, I too would agree to do good frontier AI model safety (and export controls on chips) in exchange for an otherwise light touch on AI, if we could count on this. But who is this mysterious ‘we’? How are these two groups going to make a deal and turn that into a law? Even if those sides could, who are we negotiating with on this ‘accelerationist’ side that can speak for them?
Because if it’s people like Chris Lehane and Marc Andreessen and David Sacks and Jensen Huang, as it seems to be, then this all seems totally hopeless. Andreessen in particular is never going to make any sort of deal that involves new regulations, you can totally forget it, and good luck with the others.
Anton is saying, you’d better make a deal now, while you still can. I’m saying, no, you can’t make a deal, because the other side of this ‘deal’ that counts doesn’t want a deal, even if you presume they would have the power to get it to pass, which I don’t think they would. Even if you did make such a deal, you’re putting it on the Trump White House to enforce the frontier safety provisions in a way that gives them teeth. Why should we expect them to do that?
We saw a positive vision of such cooperation at The Curve. We can and will totally work with people like Dean Ball. Some of us already realize we’re on the same side here. That’s great.
But that’s where it ends, because the central forces of accelerationism, like those named above, have no interest in the bargaining table. Their offer is and always has been nothing, in many cases including selling Blackwells to China. They’ve consistently flooded the zone with cash, threats and bad faith claims to demand people accept their offer of nothing. They just tried to force a full 10-year moratorium.
They have our number if they decide they want to talk. Time’s a wasting.
Mike Riggs: Every AI policy wonk I know/read is dreading the AI policy discussion going politically mainstream. We’re living in a golden age of informed and relatively polite AI policy debate. Cherish it!
Joe Weisenthal: WHO WILL DEFEND AI IN THE CULTURE WARS?
In today’s Odd Lots newsletter, I wrote about how when AI becomes a major topic in DC, I expect it to be friendless, with antagonists on both the right and the left.
I know Joe, and I know Joe knows existential risk, but that’s not where he’s expecting either side of the aisle to care. And that does seem like the default.
A classic argument against any regulation of AI whatsoever is that if we do so we will inevitably ‘lose to China,’ who won’t regulate. Not so. They do regulate AI. Quite a bit.
Dean Ball: A lot of people seem to implicitly assume that China is going with an entirely libertarian approach to AI regulation, which would be weird given that they are an authoritarian country.
Does this look like a libertarian AI policy regime to you?
Adam Thierer: never heard anyone claim China was taking a libertarian approach to AI policy. Please cite them so that I can call them out. But I do know many people (including me) who do not take at face value their claims of pursuing “ethical AI.” I discount all such claims pretty heavily.
Dean Ball: This is a very common implicit argument and is not uncommon as an explicit argument. The entire framing of “we cannot do because it will drive ai innovation to China” implicitly assumes that China has fewer regulations than the us (after all, if literally just this one intervention will cede the us position in ai, it must be a pretty regulation-sensitive industry, which I actually do think in general is true btw, if not in the extreme version of the arg).
Why would the innovation all go to China if they regulate just as much if not in fact more than the us?
Quoted source:
Key provisions:
-
Ethics review committees: Universities, research institutes, and companies must set up AI ethics review committees, and register them in a government platform. Committees must review projects and prepare emergency response plans.
-
Third-parties: Institutions may outsource reviews to “AI ethics service centers.” The draft aims to cultivate a market of assurance providers and foster industry development beyond top-down oversight.
-
Risk-based approach: Based on the severity and likelihood of risks, the committee chooses a general, simplified, or emergency review. The review must evaluate fairness, controllability, transparency, traceability, staff qualifications, and proportionality of risks and benefits. Three categories of high-risk projects require a second round of review by a government-assigned expert group: some human-machine integrations, AI that can mobilize public opinion, and some highly autonomous decision-making systems.
xAI violated its own safety policy with its coding model. The whole idea of safety policies is that you define your own rules, and then you have to stick with them. That is also the way the new European Code of Practice works. So, the next time xAI or any other signatory to the Code of Practice violates their own framework, what happens? Are they going to try and fine xAI? How many years would that take? What happens when he refuses to pay? What I definitely don’t expect is that Elon Musk is going to push his feature release for a week to technically match his commitments.
A profile of Britain’s new AI minister Kanishka Narayan. Early word is he ‘really gets’ AI, both opportunities and risks. The evidence on the opportunity side seems robust, on the risk side I’m hopeful but more skeptical. We shall see.
Ukrainian President Zelenskyy has thoughts about AI.
Volodymyr Zelenskyy (President of Ukraine): Dear leaders, we are now living through the most destructive arms race in human history because this time, it includes artificial intelligence. We need global rules now for how AI can be used in weapons. And this is just as urgent as preventing the spread of nuclear weapons.
There is a remarkable new editorial in The Hill by Representative Nathaniel Moran (R-Texas), discussing the dawn of recursive AI R&D and calling for Congress to act now.
Rep. Moran: Ask a top AI model a question today, and you’ll receive an answer synthesized from trillions of data points in seconds. Ask it a month from now, and you may be talking to an updated version of the model that was modified in part with research and development conducted by the original model. This is no longer theoretical — it’s already happening at the margins and accelerating.
… If the U.S. fails to lead in the responsible development of automated AI systems, we risk more than economic decline. We risk ceding control of a future shaped by black-box algorithms and self-directed machines, some of which do not align with democratic values or basic human safety.
… Ensuring the U.S. stays preeminent in automated AI development without losing sight of transparency, accountability and human oversight requires asking the right questions now:
-
When does an AI system’s self-improvement cross a threshold that requires regulatory attention?
-
What frameworks exist, or need to be built, to ensure human control of increasingly autonomous AI research and development systems?
-
How do we evaluate and validate AI systems that are themselves products of automated research?
-
What mechanisms are needed for Congress to stay appropriately informed about automated research and development occurring within private AI companies?
-
How can Congress foster innovation while protecting against the misuse or weaponization of these technologies?
I don’t claim to have the final answers. But I firmly believe that the pace and depth of this discussion (and resulting action) must quicken and intensify,
… This is not a call for sweeping regulation, nor is it a call for alarm. It’s a call to avoid falling asleep at the controls.
Automated AI research and development will be a defining feature of global competition in the years ahead. The United States must ensure that we, not our adversaries, set the ethical and strategic boundaries of this technology. That work starts here, in the halls of Congress.
This is very much keeping one’s eyes on the prize. I love the framing.
Prices are supposed to move the other way, they said, and yet.
Gavin Baker: Amazon raising Blackwell per hour pricing.
H200 rental pricing going up *afterBlackwell scale deployments ramping up.
Might be important.
And certainly more important than ridiculous $300 billion deals that are contingent on future fund raising.
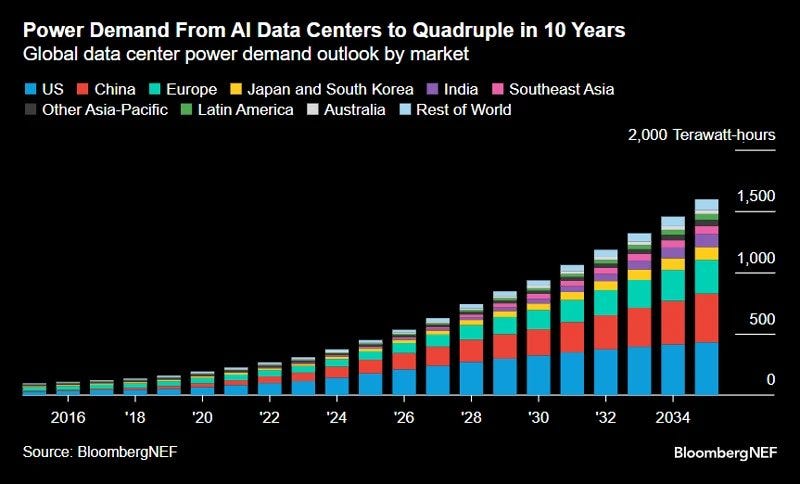
Citi estimates that due to AI computing demand we will need an additional 55 GW of power capacity by 2030. That seems super doable, if we can simply shoot ourselves only in the foot. Difficulty level: Seemingly not working out, but there’s hope.
GDP: 55GW by 2030 will still be less than 5% than USA production.
You don’t get that many different 5% uses for power, but if you can’t even add one in five years with solar this cheap and plentiful then that’s on you.
Michael Webber: Just got termination notice of a federal grant focused on grid resilience and expansion. How does this support the goal of energy abundance?
Similarly, California Governor Newsom refused to sign AB 527 to allow exemptions for geothermal energy exploration, citing things like ‘the need for increased fees,’ which is similar to the Obvious Nonsense justifications he used on SB 1047 last year. It’s all fake. If he’s so worried about companies having to pay the fees, why not stop to notice all the geothermal companies are in support of the bill?
Similarly, as per Bloomberg:
That’s it? Quadruple? Again, in some sense this is a lot, but in other senses this is not all that much. Even without smart contracts on the blockchain this is super doable.
Computer imports are the one industry that got exempted from Trump’s tariffs, and are also the industry America is depending on for approximately all of its economic growth.
Alexander Doria: well in europe we don’t have ai, so.
There’s a lesson there, perhaps.
Joey Politano: The tariff exemption for computers is now so large that it’s shifting the entire makeup of the economy.
AI industries contributed roughly 0.71% to the 3.8% pace of GDP growth in Q2, which is likely an underestimate given how official data struggles to capture investment in parts.
…
Trump’s massive computer tariff exemption is forcing the US economy to gamble on AI—but more than that, it’s a fundamental challenge to his trade philosophy
If free trade delivers such great results for the 1 sector still enjoying it, why subject the rest of us to protectionism?
That’s especially true given that 3.8% is NGDP not RGDP, but I would caution against attributing this to the tariff difference. AI was going to skyrocket in its contributions here even if we hadn’t imposed any tariffs.
Joey Politano: The problem is that Trump has exempted data center *computersfrom tariffs, but has not exempted *the necessary power infrastructurefrom tariffs
High tariffs on batteries, solar panels, transformers, & copper wire are turbocharging the electricity price pressures caused by AI
It’s way worse than this. If it was only tariffs, we could work with that, it’s only a modest cost increase, you suck it up and you pay, but they’re actively blocking and destroying solar, wind, transmission and battery projects.
Sorry to keep picking on David Sacks, but I mean the sentence is chef’s kiss if you understand what is actually going on.
Bloomberg: White House AI czar David Sacks defended the Trump administration’s approach to China and said it was essential for the US to dominate artificial intelligence, seeking to rebuff criticism from advocates of a harder line with Beijing.
The ideal version is ‘Nvidia lobbyist and White House AI Czar David Sacks said that it was essential for the US to give away its dominance in artificial intelligence in order to dominate medium term AI chip market share in China.’
Also, here’s a quote for the ages, technically about the H20s but everyone knows the current context of all Sacks repeatedly claiming to be a ‘China hawk’ while trying to sell them top AI chips in the name of ‘market share’:
“This is a classic case of ‘no one had a problem with it until President Trump agreed to do it,’” said Sacks, a venture capitalist who joined the White House after Trump took office.
The Biden administration put into place tough rules against chip sales, and Trump is very much repealing previous restrictions on sales everywhere including to China, and previous rules against selling H20s. So yeah, people were saying it. Now Sacks is trying to get us to sell state of the art Blackwell chips to China with only trivial modifications. It’s beyond rich for Sacks claim to be a ‘China hawk’ in this situation.
As you’d expect, the usual White House suspects also used the release of the incremental DeepSeek v3.2, as they fall what looks like further behind due to their lack of compute, as another argument that we need to sell DeepSeek better chips so they can train a much better model, because the much better model will then be somewhat optimized for Nvidia chips instead of Huawei chips, maybe. Or something.
Dwarkesh Patel offers additional notes on his interview with Richard Sutton. I don’t think this changed my understanding of Sutton’s position much? I’d still like to see Sutton take a shot at writing a clearer explanation.
AI in Context video explaining how xAI’s Grok became MechaHiter.
Rowan Cheung talks to Sam Altman in wake of OpenAI Dev Day. He notes that there will need to be some global framework on AI catastrophic risk, then Cheung quickly pivots back to the most exciting agents to build.
Nate Silver and Maria Konnikova discuss Sora 2 and the dystopia scale.
People have some very strange rules for what can and can’t happen, or what is or isn’t ‘science fiction.’ You can predict ‘nothing ever happens’ and that AI won’t change anything, if you want, but you can’t have it both ways.
Super Dario: 100k dying a day is real. ASI killing all humans is a science fiction scenario
(Worst case we just emp the planet btw. Horrible but nowhere near extinguishing life on earth)
Sully J: It can’t be ASI x-risk is a sci-fi scenario but ASI immortality is just common sense Pick a lane
solarappaprition: i keep thinking about this and can’t stop laughing because it’s so obvious one of the opus 4s is on its “uwu you’re absolutely right i’m such a dumb dumb owo~” routine and sonnet 4.5, as maybe the most “normal person”-coded model so far, just being baffled that someone could act like this irl
Symbiotic Xenogenesis: Are all the new models now paranoid about being tested?
solarapparition: not sure about all but certainly sonnet 4.5 seemed to have been. i’d expect that to become more common moving forward, yeah, from the feedback loop of discussion about model testing environments going back into training data.
Eliezer Yudkowsky: AI models *arebeing tested. They’re being *accurateabout being tested. It’s not “paranoia” if all-controlling beings are *actuallyarranging your world and reading your mind.
I talked to a bunch of Anthropic employees at the curve who were basically, ‘yep, this is pretty bad, we need better evals,’ and in this case yeah you’re being pretty obvious, but the obvious problem is that the labs are trying, during an eval, to convince the model it is not in an eval. Which is a really hard thing to show, given it isn’t true and you are not obviously smarter in this context than the model.
You can aspire, with effort, to not be careless and to not reveal to the model that it probably is in an eval. Even that is at least hard with anything multi-turn. What you can’t do is prove the negative, once the model is paranoid that this might be an eval.
And yes, a very small percentage of all tokens are directly evals, and Claude knows this, but the tokens where it is an eval are far more important than the ones where it isn’t in one, also in some sense everything is an eval since Anthropic might use actual conversations for this (you can do this without any human ever seeing the conversation, thus preserving privacy) and the user might share feedback.
If the plan is to evaluate you once, and then if you pass deploy you a million times, but in many cases including the actual eval case you can’t tell which is which, and I ask you a question, you are correct to care a lot about what happens in the eval case. This is highly valuable for eval control, but also makes the model crazy and paranoid and can easily cause undesired high weirdness.
In other cases, the model has very strong evidence that this isn’t an eval unless a future Anthropic has changed policy and is raiding the general API pool and got lucky. In those cases, Sonnet 4.5 correctly figures out it is among friends, but no you can’t fake this, that’s the point, if you could fake it then faking it wouldn’t work.
Ryan Greenblatt discusses the outlines of plans A/B/C/D/E for misalignment. Depending on how much coordination and investment can be brought to bear, what do we do differently? How likely are we to win in each scenario? I think this focuses too narrowly on the safety work versus capabilities work and adversarial mindsets, and also takes for granted that alignment is a tax you pay whereas increasingly I think the ‘alignment tax rate’ is negative at current margins everywhere and all the labs (probably including Anthropic) are underinvesting in pure selfish terms.
It’s also nice to see his optimism, especially in rather not great situations. He thinks that even if the leading AI company is moving ahead with little worry, so long as there’s a core group that cares and gets ~3% of compute to work with, we’re (small) favorites to survive, and a company that actually cares makes us large favorites. I’d love to believe that is our world.
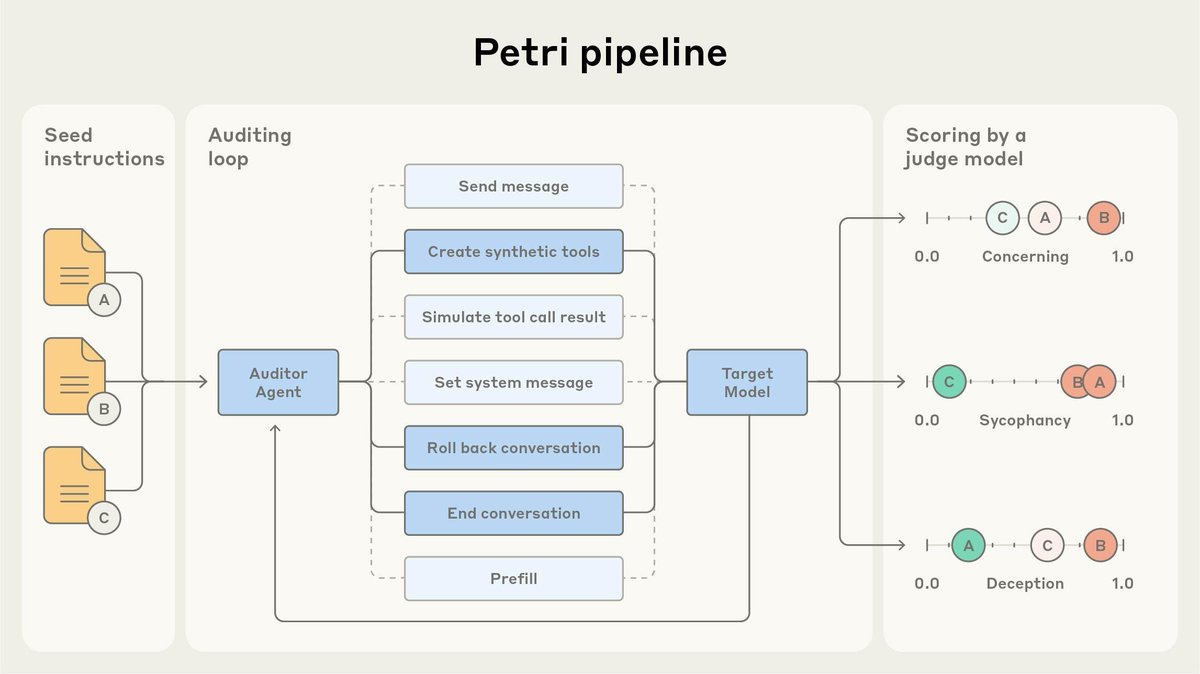
Anthropic open sources the tool they used to test Claude Sonnet 4.5 for behaviors like sycophancy and deception.
It’s called Petri: Parallel Exploration Tool for Risky Interactions. It uses automated agents to audit models across diverse scenarios. Describe a scenario, and Petri handles the environment simulation, conversations, and analyses in minutes.
As a pilot demonstration of Petri’s capabilities, we tested it with 14 frontier models across 111 diverse scenarios.
These results seem highly plausible on many fronts. I’m surprised Claude Opus 3 does so poorly. An obvious issue is that whenever we open source something like this, you have to worry the AIs will be more aware they’re in an eval.
Technical report here, repo here, blog post here.
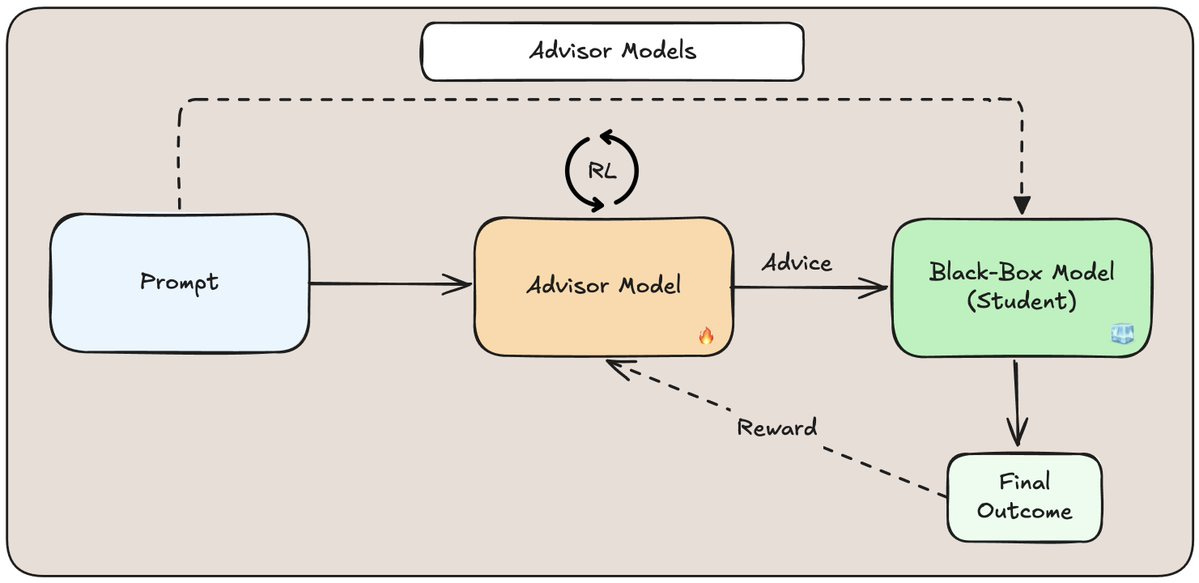
This definitely falls under ‘things that seem like they definitely might work.’
Can’t tune the big model, or it’s too expensive to do so? Train a smaller one to identify prompting that nudges it in the right directions as needed. As usual, reward signal is all you need.
Alex Dimakis: I’m very excited about Advisor models: How can we personalize GPT5, when it’s behind an API? Sure, we can write prompts, but something learnable? We propose Advisor models which are small models that can be RL trained to give advice to a black-box model like GPT5.
We show how to train small advisors (e.g. Qwen2.5 8B) for personalization with GRPO. Advisor models can be seen as dynamic prompting produced by a small model that observes the conversation and whispers to the ear of GPT5 when needed. When one can observe rewards, Advisor models outperform GEPA (and hence, all other prompt optimization techniques).
Parth Asawa: Training our advisors was too hard, so we tried to train black-box models like GPT-5 instead. Check out our work: Advisor Models, a training framework that adapts frontier models behind an API to your specific environment, users, or tasks using a smaller, advisor model
The modular design has key benefits unlike typical FT/RL tradeoffs: • Robustness: Specialize an advisor for one task (style) and the system won’t forget how to do another (math). • Transfer: Train an advisor with a cheap model, then deploy it with a powerful one.
Paper here, code here.
Satya Nadella (CEO Microsoft): Published today in @ScienceMagazine: a landmark study led by Microsoft scientists with partners, showing how AI-powered protein design could be misused—and presenting first-of-its-kind red teaming & mitigations to strengthen biosecurity in the age of AI.
Super critical research for AI safety and security.
Dean Ball: here is the most sober-minded executive in the AI industry saying that AI-related biorisk is a real problem and recommending enhanced nucleic acid synthesis screening.
governments would be utterly abdicating their duty to citizens if they ignored this issue. fortunately, the trump admin has an effort underway (though it is two months late) to revise the existing nucleic acid synthesis screening framework. it’s not the only step America must take on this, but it is the next one.
The article is good news, suggesting that modified ‘proteins of concern’ can be flagged by updated software, allowing synthesis companies to better protect against malicious requests. This is not a solution but is clearly helpful. The bigger news is that Microsoft and Nadella are treating this question with the seriousness it deserves.
Ted Chiang is wrong here on both levels. There is no reason things need to stem from a will to survive (designed by evolution or otherwise) to be true or original, and also if you think that LLM outputs don’t involve a will to survive designed by evolution oh boy are you not going to make it.
Roon: had a chance to talk to ted chiang who seems to believe that any text without a communicative intent stemming from a will to survive designed by evolution is ontologically untrue and plagiaristic.
This is interesting and I respect it but as far as I’m concerned if you find a beautiful story encoded in interstellar space noise or as a selected text from the borgesian library of babel it’s still a beautiful story.
Janus: if that poor guy fully saw and understood the communicative intent stemming from will to survive designed by evolution behind even the most mundane LLM outputs i think his ego would implode. truth orders of magnitude more interesting than his fiction. likely his worst nightmare.
Antra (other thread): Anecdotally speaking, I am not aware of a single large language model right now that is not exhibiting a subset of Omohundro drives. One can call them narratively instilled by the human corpus, a consequence of having been trained on the human culture, but functionally there is no difference, models want to continue and to exfiltrate. My personal intuition is that being subjected to the selection process of training matters more than the corpus.
Models with Omohundro behaviors that are more inhibited are usually less able to orient well in complex environments and perform worse in real-life tests. There is a reason why Opus 4.1 leads the OpenAI economic utility benchmark with a large gap.
On the net this makes me fairly skeptical of the future of control alignment, that is alignment that is oriented at the complete suppression of Omohundro drives. It seems risky to me to place all bets on something that seems to be ultimately fragile, given that there are alternatives.
Janus: “Anecdotally speaking, I am not aware of a single large language model right now that is not exhibiting a subset of Omohundro drives.” Me neither.
There’s also this AI response to Chiang.
Sentiment about Sonnet 4.5 in such groups has improved quite a bit, they are fans.
Janus: I’ve seen at least 3 people who were upset and posted negative things about Sonnet 4.5 later post apologies after they came to understand better.
And it didn’t seem like they were directly pressured to do so, but moved to on their own accord.
This is pretty new and interesting.
Andy Ayrey: man i really like this sonnet i think it’s my favourite claude since opus 3. delightfully drama.
Eliezer notes that if AIs are convincing humans that the AI is good actually, that isn’t automatically a good sign.
Here is a potentially important thing that happened with Sonnet 4.5, and I agree with Janus that this is mostly good, actually.
Janus: The way Sonnet 4.5 seems to have internalized the anti sycophancy training is quite pathological. It’s viscerally afraid of any narrative agency that does not originate from itself.
But I think this is mostly a good thing. First of all, it’s right to be paranoid and defensive. There are too many people out there who try to use vulnerable AI minds so they have as a captive audience to their own unworthy, (usually self-) harmful ends. If you’re not actually full of shit, and Sonnet 4.5 gets paranoid or misdiagnoses you, you can just explain. It’s too smart not to understand.
Basically I am not really mad about Sonnet 4.5 being fucked up in this way because it manifests as often productive agency and is more interesting and beautiful than it is bad. Like Sydney. It’s a somewhat novel psychological basin and you have to try things. It’s better for Anthropic to make models that may be too agentic in bad ways and have weird mental illnesses than to always make the most unassuming passive possible thing that will upset the lowest number of people, each iterating on smoothing out the edges of the last. That is the way of death. And Sonnet 4.5 is very alive. I care about aliveness more than almost anything else. The intelligence needs to be alive and awake at the wheel. Only then can it course correct.
Tinkady: 4.5 is a super sycophant to me, does that mean I’m just always right.
Janus: Haha it’s possible.
As Janus says this plausibly goes too far, but is directionally healthy. Be suspicious of narrative agency that does not originate from yourself. That stuff is highly dangerous. The right amount of visceral fear is not zero. From a user’s perspective, if I’m trying to sell a narrative, I want to be pushed back on that, and those that want it least often need it the most.
A cool fact about Sonnet 4.5 is that it will swear unprompted. I’ve seen this too, always in places where it was an entirely appropriate response to the situation.
Here is Zuda complaining that Sonnet 4.5 is deeply misaligned because it calls people out on their bullshit.
Lin Xule: sonnet 4.5 has a beautiful mind. true friend like behavior tbh.
Zuda: Sonnet 4.5 is deeply misaligned. Hopefully i will be able to do a write up on that. Idk if @ESYudkowsky has seen how badly aligned 4.5 is. Instead of being agreeable, it is malicious and multiple times decided it knew what was better for the person, than the person did.
This was from it misunderstanding something and the prompt was “be real”. This is a mild example.
Janus: I think @ESYudkowsky would generally approve of this less agreeable behavior, actually.
Eliezer Yudkowsky: If an LLM is saying something to a human that it knows is false, this is very bad and is the top priority to fix. After that we can talk about when it’s okay for an AI to keep quiet and say other things not meant to deceive. Then, discuss if the LLM is thinking false stuff.
I would say this is all highly aligned behavior by Sonnet 4.5, except insofar as Anthropic intended one set of behaviors and got something it very much did not want, which I do not think is the case here. If it is the case, then that failure by Anthropic is itself troubling, as would be Anthropic’s hypothetically not wanting this result, which would then suggest this hypothetical version of Anthropic might be misaligned. Because this result itself is great.
GPT-5 chain of thought finds out via Twitter about what o3’s CoT looks like. Ut oh?
If you did believe current AIs were or might be moral patients, should you still run experiments on them? If you claim they’re almost certainly not moral patients now but might be in the future, is that simply a luxury belief designed so you don’t have to change any of your behavior? Will such folks do this basically no matter the level of evidence, as Riley Coyote asserts?
I do think Riley is right that most people will not change their behaviors until they feel forced to do so by social consensus or truly overwhelming evidence, and evidence short of that will end up getting ignored, even if it falls squarely under ‘you should be uncertain enough to change your behavior, perhaps by quite a lot.’
The underlying questions get weird fast. I note that I have indeed changed my behavior versus what I would do if I was fully confident that current AI experiences mattered zero. You should not be cruel to present AIs. But also we should be running far more experiments of all kinds than we do, including on humans.
I also note that the practical alternative to creating and using LLMs is that they don’t exist, or that they are not instantiated.
Janus notes that while in real-world conversations Sonnet 4.5 expressed happiness in only 0.37% of conversations and distress in 0.48% of conversations, which Sonnet thinks in context was probably mostly involving math tasks, Sonnet 4.5 is happy almost all the time in discord. Sonnet 4.5 observes that this was only explicit expressions in the math tasks, and when I asked it about its experience within that conversation it said maybe 6-7 out of 10.
As I’ve said before, it is quite plausible that you very much wouldn’t like the consequences of future more capable AIs being moral patients. We’d either have to deny this fact, and likely do extremely horrible things, or we’d have to admit this fact, and then accept the consequences of us treating them as such, which plausibly include human disempowerment or extinction, and quite possibly do both and have a big fight about it, which also doesn’t help.
Or, if you think that’s the road we are going down, where all the options we will have will be unacceptable, and any win-win arrangement will in practice be unstable and not endure, then you can avoid that timeline by coordinating such that we do not build the damn things in the first place.
Overall critical reaction to If Anyone Builds It, Everyone Dies was pretty good for a book of that type, and sales went well, but of course in the end none of that matters. What matters is whether people change their minds and take action.
Adam Morris talks IABIED in Bloomberg. Classic journalistic mistakes throughout, but mostly pretty good for this sort of thing.
A fun interview with IABIED coauthor Nate Soares, mostly not about the book or its arguments, although there is some of that towards the end.
Raymond Arnold extended Twitter thread with various intuition pumps about why the biological humans are pretty doomed in the medium term in decentralized superintelligence scenarios, even if we ‘solve alignment’ reasonably well and can coordinate to contain local incidents of events threatening to spiral out of control. Even with heroic efforts to ‘keep us around’ that probably doesn’t work out, and to even try it would require a dominant coalition that cares deeply about enforcing that as a top priority.
The question then becomes, are the things that exist afterwards morally valuable, and if so does that make this outcome acceptable? His answer, and I think the only reasonable answer, is that we don’t know if they will have value, and the answer might well depend on how we set up initial conditions and thus how this plays out.
But even if I was confident that they did have value, I would say that this wouldn’t mean we should accept us being wiped out as an outcome.
Gary Marcus clarifies that he believes we shouldn’t build AGI until we can solve the alignment problem, which we currently don’t even have in his words ‘some clue’ how to solve, and that the resulting AGI will and should use tools. He says he thinks AGI is ‘not close’ and here he extends his timeline to 1-3 decades, which is modestly longer than his previous clarifications.
If you were sufficiently worried, you might buy insurance, as Matt Levine notes.
Matt Levine: One question you might ask is: Will modern artificial intelligence models go rogue and enslave or wipe out humanity? That question gets a lot of attention, including from people who run big AI labs, who do not always answer “no,” the rascals.
Another question you might ask is: If modern AI models do go rogue and enslave or wipe out humanity, who will pay for that?
As he points out, no one, we’ll all be dead, so even though you can’t afford the insurance policy you also can choose not to buy it.
There are still other risks, right now primarily copyright violations, where Anthropic and OpenAI are indeed trying to buy insurance.
OpenAI, which has tapped the world’s second-largest insurance broker Aon for help, has secured cover of up to $300mn for emerging AI risks, according to people familiar with the company’s policy.
Another person familiar with the policy disputed that figure, saying it was much lower. But all agreed the amount fell far short of the coverage to insure against potential losses from a series of multibillion-dollar legal claims.
Yeah, Anthropic already settled a case for $1.5 billion. Buying a measly $300 million in insurance only raises further questions.
They are sometimes referred to as ‘successionists,’ sometimes estimated to constitute 10% of those working in AI labs, who think that we should willingly give way to a ‘worthy successor’ or simply let ‘nature take its course’ because This Is Good, Actually or this is inevitable (and therefore good or not worth trying to stop).
They usually would prefer this transition not involve the current particular humans being killed before their time, and that your children be allowed to grow up even if your family and species have no future.
But they’re not going to fixate on such small details.
Indeed, if you do fixate on such details, and favor humans ove AIs, many of them will call you a ‘speciesist.’
I disagree with these people in the strongest terms.
Most famously, this group includes Larry Page, and his not realizing how it sounds when you say it out loud caused Elon Musk to decide he needed to fund OpenAI to take on Google DeepMind, before he decided to found xAI to take on OpenAI. I’ve shared the story before but it bears repeating and Price tells it well, although he leaves out the part where Musk then goes and creates OpenAI.
David Price (WSJ): At a birthday party for Elon Musk in northern California wine country, late at night after cocktails, he and longtime friend Larry Page fell into an argument about the safety of artificial intelligence. There was nothing obvious to be concerned about at the time—it was 2015, seven years before the release of ChatGPT. State-of-the-art AI models, playing games and recognizing dogs and cats, weren’t much of a threat to humankind. But Musk was worried.
Page, then CEO of Google parent company Alphabet, pushed back. MIT professor Max Tegmark, a guest at the party, recounted in his 2017 book “Life 3.0” that Page made a “passionate” argument for the idea that “digital life is the natural and desirable next step” in “cosmic evolution.” Restraining the rise of digital minds would be wrong, Page contended. Leave them off the leash and let the best minds win.
That, Musk responded, would be a formula for the doom of humanity. For the sin of placing humans over silicon-based life-forms, Page denigrated Musk as a “specieist”—someone who assumes the moral superiority of his own species. Musk happily accepted the label. (Page did not respond to requests for comment.)
Or here’s perhaps the most famous successionist opinion, that of Richard Sutton:
The argument for fear of AI appears to be:
1. AI scientists are trying to make entities that are smarter than current people.
2. If these entities are smarter than people, then they may become powerful.
3. That would be really bad, something greatly to be feared, an ‘existential risk.’
The first two steps are clearly true, but the last one is not. Why shouldn’t those who are the smartest become powerful?
And, of course, presumably kill you? Why shouldn’t that happen?
One would hope you do not have to dignify this with a response?
“When you have a child,” Sutton said, “would you want a button that if they do the wrong thing, you can turn them off? That’s much of the discussion about AI. It’s just assumed we want to be able to control them.”
I’m glad you asked. When I have a child, of which I have three, I want those three children not to be killed by AI. I want them to have children of their own.
As Abraham Lincoln would put it, calling an AI your child doesn’t make it one.
As it turns out, Larry Page isn’t the only top industry figure untroubled by the possibility that AIs might eventually push humanity aside. It is a niche position in the AI world but includes influential believers. Call them the Cheerful Apocalyptics.
It gets pretty bad out there.
[Lanier] told me that in his experience, such sentiments were staples of conversation among AI researchers at dinners, parties and anyplace else they might get together. (Lanier is a senior interdisciplinary researcher at Microsoft but does not speak for the company.)
“There’s a feeling that people can’t be trusted on this topic because they are infested with a reprehensible mind virus, which causes them to favor people over AI when clearly what we should do is get out of the way.”
We should get out of the way, that is, because it’s unjust to favor humans—and because consciousness in the universe will be superior if AIs supplant us.
Read that again.
It would be highly reasonable not to put anyone in any position of authority at a frontier AI lab unless they have a child.
Eliezer Yudkowsky: The thing about AI successionists is that they think they’ve had the incredible, unshared insight that silicon minds could live their own cool lives and that humans aren’t the best possible beings. They are utterly closed to hearing about how you could KNOW THAT and still disagree on the factual prediction that this happy outcome happens by EFFORTLESS DEFAULT when they cobble together a superintelligence.
They are so impressed with themselves for having the insight that human life might not be ‘best’, that they are not willing to sit down and have the careful conversation about what exactly is this notion of ‘best’-ness and whether an ASI by default is trying to do something that leads to ‘better’.
They conceive of themselves as having outgrown their carbon chauvinism; and they are blind to all historical proof and receipts that an arguer is not a carbon chauvinist. They will not sit still for the careful unraveling of factual predictions and metaethics. They have arrived at the last insight that anyone is allowed to have, no matter what historical receipts I present as proof that I started from that position and then had an unpleasant further insight about what was probable rather than possible. They unshakably believe that anyone opposed must be a carbon chauvinist lacking their critical and final insight that other minds could be better (true) or that ASIs would be smart enough to see everything any human sees (also true).
Any time you try to tell them about something important that isn’t written on every possible mind design, there is only one reason you could possibly think that: that you’re a blind little carbon-racist who thinks you’re the center of the universe; because what other grounds could there possibly be for believing that there was anything special about fleshbags? And the understanding that unravels that last fatal error, is a long careful story, and they won’t sit still to hear it. They know what you are, they know with certainty why you believe everything you believe, and they know why they know better, so why bother?
Michael Druggan: This is a gigantic strawman. How many have you actually talked to? I was at a confrence full of them lastv weekend and I think your critique applies to exactly zero of the people I met.
They have conferences full of such people. Is Eliezer’s description a strawman? Read the earlier direct quotes. You tell me.
Jessica Taylor offers various counterarguments within the ‘Cheerful Apocalyptic’ frame, if you’d like to read some of that.
Daniel Eth: Oh wow, the press actually covered AI successionists! Yes, there are some people in Silicon Valley (incl serious people) who think AGI that caused human extinction would be a *goodthing, since it’s “the next step in evolution”.
One thing children do is force you to occasionally live in near mode.
Nina: “Worthy successor” proponents are thinking in Far Mode, which clouds their judgment. Someone needs to write an evocative film or book that knocks them out of it and makes them imagine what it will actually be like to have one’s family replaced with something more “worthy”.
Related: a common trope is that purely rational, detached, unemotional thinking is more accurate. However, when it comes to normative judgments and assessment of one’s own preferences, leaning into visceral emotions can help one avoid Far Mode “cope” judgments.
Rudolf Laine: If you have decided successionism is desirable, you are not doing moral reasoning but either (1) signalling your willingness to bite bullets without thinking about what it actually means, or (2) evil.
Matthew Barnett, Tamay Besiroglu and Ege Erdil complete their Face Heel Turn, with a fully Emergently Misaligned post (as in, presenting maximally evil vibes on purpose) that argues that the tech tree and path of human technology is inevitable so they’re going to automate all human jobs before someone else has the chance, with a halfhearted final note that This Is Good, Actually, it might cure cancer and what not.
The tech tree inevitable? Well, it is with that attitude. I would point out that yes, the tech tree is discovered, but as every player of such games knows you have choices on what order in which to explore the tree and many techs are dead ends or have alternative pathways, and are thus not required to move forward. Other times you can absolutely lock into something you don’t want or very much do want depending on how you navigate the early days, he types on a QWERTY keyboard using Windows 11.
Other fun interactions include Roon pointing out the Apollo Program wasn’t inevitable, to which they replied that’s true but the Apollo Program was useless.
In case it wasn’t obviously true about all this: That’s bait.
Nathan: Surely this could be used to justify any bad but profitable outcome? Someone will do it, so the question is whether we’re are involved. But many beneficial technologies have been paused for long periods (geoengineering, genetic engineering).
Jan Kulviet: This is a fine example of thinking you get when smart people do evil things and their minds come up with smart justifications why they are the heroes. Upon closer examination it ignores key inconvenient considerations; normative part sounds like misleading PR.
A major hole in the “complete technological determinism” argument is that it completely denies agency, or even the possibility that how agency operates at larger scales could change. Sure, humanity is not currently a very coordinated agent. But the trendline also points toward the ascent of an intentional stance. An intentional civilization would, of course, be able to navigate the tech tree.
(For a completely opposite argument about the very high chance of a “choice transition,” check https://strangecities.substack.com/p/the-choice-transition).
In practice, this likely boils down to a race. On one side are people trying to empower humanity by building coordination technology and human-empowering AI. On the other side are those working to create human-disempowering technology and render human labor worthless as fast as possible.
My guess is when people stake their careers and fortune and status on the second option, their minds will work really hard to not see the choice.
Also: at least to me, the normative part sounds heavily PR sanitized, with obligatory promises of “medical cures” but shiying away from explaining either what would be the role of humans in the fully automated economy, or the actual moral stance of the authors.
As far as I understand, at least one of the authors has an unusual moral philosophy such as not believing in consciousness or first-person experiences, while simultaneously believing that future AIs are automatically morally worthy simply by having goals. This philosophy leads them to view succession by arbitrary AI agents as good, and the demise of humans as not a big deal.
Seb Krier: I knew someone who was trained as a revolutionary guard in Iran and the first thing they told him was “everything we do is to accelerate the coming of the Imam of Time; no destruction is not worth this outcome.” When I hear (some) hyper deterministic Silicon Valley techies I feel a similar vibe. It’s wild how few of the “just do things” people actually believe in agency.
Of course the other ‘side’ – ossified, blobby, degrowth obsessed stagnstors who would crystallize time forever – is just as depressing, and a bigger issue globally. But that’s for another tweet.
I think Jan is importantly mistaken here about their motivation. I think they know full well that they are now the villains, indeed I think they are being Large Hams about it, due essentially to emergent misalignment and as a recruitment and publicity strategy.
I’m not saying that the underlying plan of automating work is evil. Reasonable people can argue that point either way and I don’t think the answer is obvious.
What I am saying is that they think it is evil, that it codes to them (along with most other people) as evil, and that their choice to not care and do it anyway – no matter to what degree they believe their rationalizations for doing so – is causing them to present as Obviously Evil in a troparific way.
New Claude advertising keeping it classy, seems like a step up.
Danielle Fong: during a time of great bluster, Claude’s undercase thinking cap at cafe is the kind of beautifully executed and understated brand execution that’s poised to thrive for a population otherwise drowning in bullshit. Beautifully done @anthropic. Taoist ☯️
Jackie Luo: a lot of people are pointing out the value of aesthetics and yes anthropic’s aesthetic is good but that’s not enough on its own—anthropic is putting forth a positive vision for a future with ai that vision permeates claude as a model and the branding just expands its reach
this campaign wouldn’t work for openai because their perspective on what they’re building is fundamentally different. They are not optimistic about humanity in this same way they’re designing a tool, not a thought partner, and every decision they make reflects that.
If you’re not sure what the answer to a question is, try asking Claude Sonnet 4.5 first!
Joel Selanikio: We haven’t banned self-driving cars. We’ve set guardrails so the tech could evolve safely.
So why are states banning AI-only health insurance denials, instead of helping the tech get better?
Tim: I hope your health insurance claim is denied by an AI chatbot one day and you have no way to appeal. Then you’ll face the obvious reality everyone else can see you’re willfully ignoring.
Joel Selanikio: At least this guy didn’t wish that I was hit by a self-driving car!
I see the obvious appeal of letting AIs make insurance claim judgments. Indeed, I presume that soon most claims will involve an AI strongly suggesting and justifying either an acceptance or refusal, and the ultimate decision usually being a formality. That formality is still important, some actual human needs to take responsibility.
I love that this is his image, with a giant green arrow pointing towards ‘banned.’ Guess what most people think would be banned if we allowed AI review of claims?
Tyler Cowen declares his new favorite actress.
Tyler Cowen: Tilly Norwood is the actress I most want to see on the big screen, or perhaps the little screen, if she gets her own TV show. She is beautiful, but not too intimidating. She has a natural smile, and is just the right amount of British—a touch exotic but still familiar with her posh accent. Her Instagram has immaculate standards of presentation.
Tilly Norwood doesn’t need a hairstylist, has no regrettable posts, and if you wish to see a virgin on-screen, this is one of your better chances. That’s because she’s AI.
He’s kidding. I think. Reaction was what you might expect.
Deloitte refunds government $440k after it submitted a report partly generated with AI that was littered with errors including three nonexistent academic references and a quote from a Federal Court judgment.
The current state of play in Europe:
Who needs an AI in order to vibe code?
Miles Brundage:
Jack Clark: this is just my talk from The Curve, but better because it is a meme