Upgraded Google safety tools can now find and remove more of your personal info
Do you feel popular? There are people on the Internet who want to know all about you! Unfortunately, they don’t have the best of intentions, but Google has some handy tools to address that, and they’ve gotten an upgrade today. The “Results About You” tool can now detect and remove more of your personal information. Plus, the tool for removing non-consensual explicit imagery (NCEI) is faster to use. All you have to do is tell Google your personal details first—that seems safe, right?
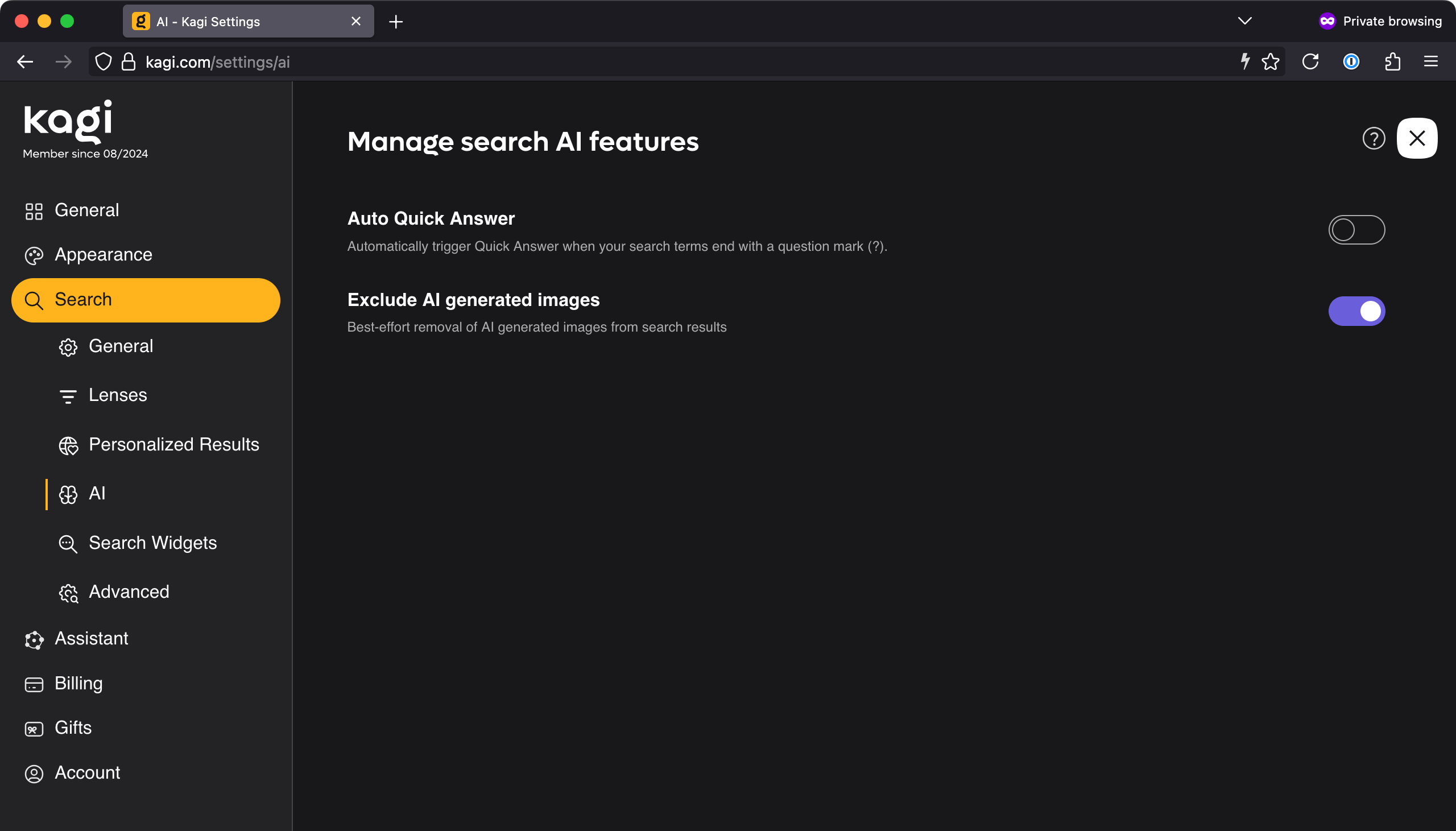
With today’s upgrade, Results About You gains the ability to find and remove pages that include ID numbers like your passport, driver’s license, and Social Security. You can access the option to add these to Google’s ongoing scans from the settings in Results About You. Just click in the ID numbers section to enable detection.
Naturally, Google has to know what it’s looking for to remove it. So you need to provide at least part of those numbers. Google asks for the full driver’s license number, which is fine, as it’s not as sensitive. For your passport and SSN, you only need the last four digits, which is enough for Google to find the full numbers on webpages.
ID number results detected.
The NCEI tool is geared toward hiding real, explicit images as well as deepfakes and other types of artificial sexualized content. This kind of content is rampant on the Internet right now due to the rapid rise of AI. What used to require Photoshop skills is now just a prompt away, and some AI platforms hardly do anything to prevent it.
Upgraded Google safety tools can now find and remove more of your personal info Read More »